基于改进YOLO v4和ICNet的番茄串检测模型
2023-11-23刘建航何鉴恒陈海华王晓政翟海滨
刘建航 何鉴恒 陈海华 王晓政 翟海滨
(1.中国石油大学(华东)海洋与空间信息学院, 青岛 266555; 2.中国科学院计算技术研究所, 北京 100094;3.国家计算机网络应急技术处理协调中心, 北京 100029)
0 引言
我国农作物采摘主要以手工为主,采摘工作季节性强、劳动强度大、成本高[1]。随着人工智能和农业机械相互结合,使农作物采摘智能化成为可能,采摘机器人在提高采摘率、推动现代化农业发展等方面具有重要意义[2]。
番茄作为中国种植的主要经济作物,其采收方式分为粒收与串收,串收有着较高的采摘效率,并且串收番茄更容易保存和运输。快速且精确地采摘番茄串是目前串型番茄采摘机器人的重点研究内容。番茄串检测以及番茄茎定位主要通过计算机视觉实现。因此,视觉感知系统的性能直接影响番茄串的采摘率[3]。文献[4]采用颜色分量运算和彩色空间转换实现图像阈值分割和目标特征提取,同时对末端执行器进行了设计,实现了串型番茄的采摘,但采摘时间较长,成熟番茄串果实识别成功率为90%。文献[5]借鉴AdaBoost学习算法在人脸识别中的成功应用[6-7],提出了基于Haar-like特征及其编码和AdaBoost学习算法的番茄识别方法。实验结果表明,单幅图像的处理时间为15 s,正确识别率为93%。文献[8]提出使用Mask R-CNN模型对果园中重叠绿色苹果进行识别和分割,将残差网络与密集连接卷积网络相结合作为骨干网络提取特征,对120幅苹果图像进行检测,结果表明,平均检测准确率为97.31%,但由于数据集太少,仍需增加样本集和丰富样本多样性以更具说服力。文献[9]使用双目视觉技术对番茄进行识别,根据番茄颜色特征用拟合曲线对番茄分割,并通过双目视觉测量原理计算出番茄的三维坐标,测量误差低于4%,但仍有待进一步优化提升检测精度。文献[10]提出一种番茄果实串采摘点识别方法,该方法对垂直向下的番茄果实串采摘点识别效果较好,但不能对其他姿态的番茄果实进行识别。文献[11]提出了一种基于改进型YOLO的复杂环境下番茄果实快速识别方法,能够提取多特征信息,模型对番茄检测精度为97.13%。
综上,国内外研究人员针对番茄串的识别和定位问题提出的研究方法尚未达到理想的精度和工业级实时性的要求,对多样的特征变化鲁棒性不足。因此,难以满足实际需求。为进一步提高农作物的识别率和采摘率,本文以番茄为研究对象,提出一种视觉感知模型,模型包括检测和语义分割2个模块,即番茄串检测和番茄茎分割。采用一种基于深度卷积结构的主干网络,取代残差块结构中的普通卷积运算,降低主干网络的计算量,从而获得更为紧凑的主干特征提取网络,通过K-means++聚类算法获得先验框,并改进DIoU距离计算公式,获得更为紧凑的轻量级检测模型(DC-YOLO v4),在实现模型参数稀疏性的同时提高识别精度。将MobileNetv2作为ICNet分割模型的主干网络,以有效减少计算量,达到实时分割效果。
1 材料与方法
1.1 图像采集
番茄数据集、番茄茎数据集采集于黄河三角洲农业高新技术示范园区的设施农业测试验证平台(山东省广饶县)。通过Intel RealSense D435型深度相机采集番茄样本,图像分辨率为 4 032像素×3 024像素,如图1a所示,相机安装在末端执行器上方5 cm处,通过图1b所示的方式,在移动端遥控机器人进行番茄样本采样,模拟番茄采摘机器人的实际工作场景。

图1 采摘机器人采集番茄样本Fig.1 Picking robot collects tomato samples
采摘机器人的主要结构如图2所示,包括机械臂、可移动装置、机器人控制系统、深度相机和末端执行器5部分。默认状态下,末端执行器的安装位置距地面10 cm。

图2 采摘机器人主要结构Fig.2 Main structure of picking robot1.末端执行器 2.深度相机 3.机械臂 4.机器人控制系统 5.可移动装置
番茄植株种植在桁架上,行距约0.4 m,高约2 m,为保证数据集样本的多样性,分别采集不同光照强度、不同果实数量、不同拍摄角度的番茄串样本共2 000幅,番茄茎样本图像1 000幅。采集的部分番茄样本如图3所示。
1.2 番茄检测网络
1.2.1YOLO目标检测网络
番茄采摘机器人的视觉感知模型包括目标检测和语义分割两部分[12]。针对番茄检测模型,本文借鉴YOLO系列的模型结构[13],其突出特点是快速和精确。与Two-Stage(如Faster R-CNN)使用Region proposal区域建议特征提取方式不同,YOLO的工作原理[14]如下:①对输入图像的全局区域进行训练。②利用主干特征提取网络完成番茄样本的特征初次提取。③融合加强特征提取网络,增大感受野的同时反复提取特征信息。④采用Bounding box预测方式,预测目标类别、置信度和预测框。
YOLO系列网络模型中,YOLO v1存在网络模型检测精度差、目标定位不准确等问题[15];YOLO v2中加入了锚框和批量归一化,并通过更改网络模型结构等操作提升了训练模型性能,但不适用于检测目标重叠的情况[16];YOLO v3中引入了多尺度融合训练、残差结构、改变网络模型结构等操作,使得训练模型性能得到了极大提升,但其主干网络深度达53层且采取了多尺度融合,导致检测速度慢[17];YOLO v4本质上继承了YOLO v3的结构,主干网络更改为CSPDarkNet53优化特征提取性能,采用Mish激活函数使梯度下降过程更为平滑,相较于ReLU、Sigmod等激活函数,Mish在处理负值时不会完全截断,保证了特征信息流动[18],同时加入了更多目前流行的技巧(如Mosaic数据增强、标签平滑、CIOU等)。但实际上,在检测精度和速度方面并没有明显提升,未达到工业级番茄检测的要求。
1.2.2改进的YOLO v4网络模型
在剖析YOLO v4网络结构的基础上,设计了一个基于深度卷积结构的主干网络,用于对番茄串图像的初步特征提取。深度卷积结构如图4所示。
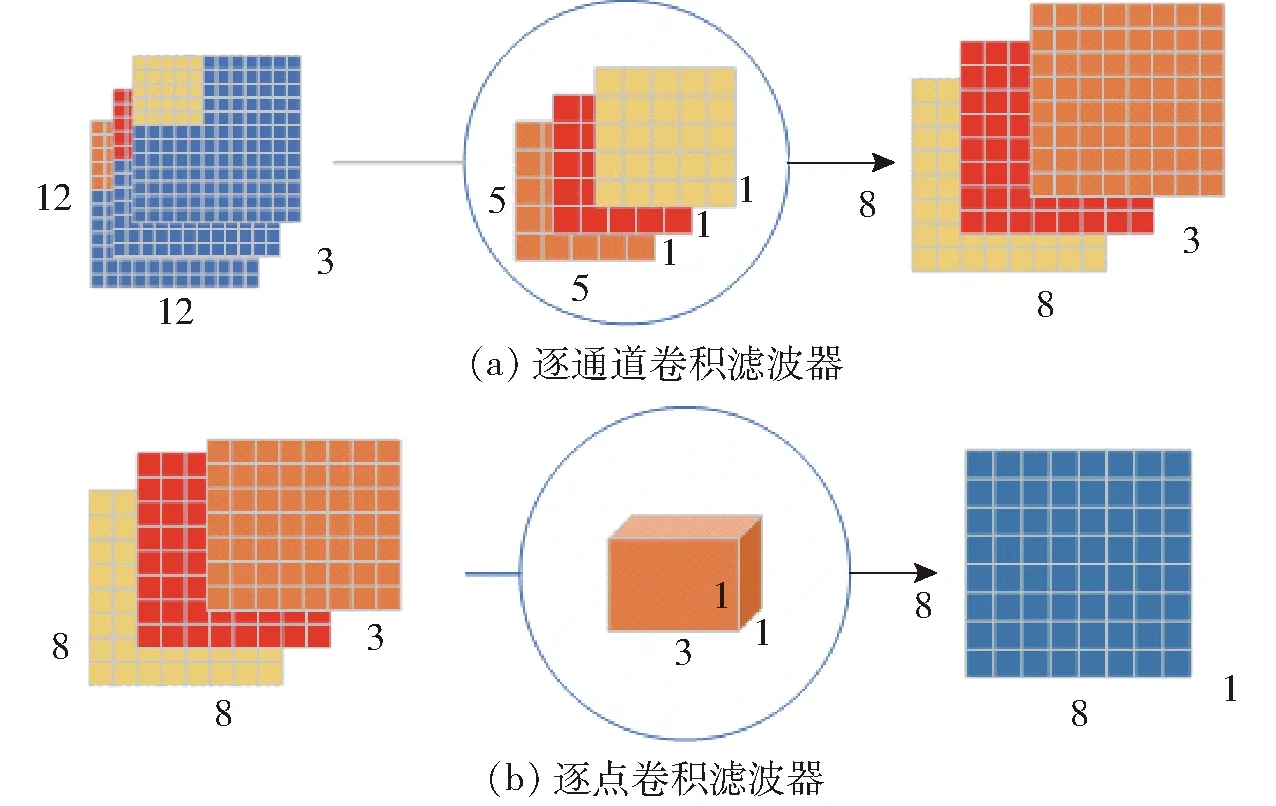
图4 深度卷积结构Fig.4 Depth convolution structure
番茄检测模块由DarkNetBN_Mish模块、主干网络、空间金字塔池化(Spatial pyramid pooling,SPP)、像素聚合网络(Pixel aggregation network,PANet)和YOLO Head构成。如图5所示,将深度卷积结构替换主干网络中Resblock_body的普通卷积,降低主干网络的计算量。
图5 改进后的Resblock_bodyFig.5 Improved Resblock_body
基于深度卷积结构的主干网络提取输入图像的特征信息,并将特征信息通过卷积传递到DarkNetConv2D_BN_Mish模块中,对输入图像进行归一化和非线性操作,SPP和PANet负责对特征信息加强提取。深度卷积结构处理3个通道的特征信息,最后,通过卷积核尺寸为1×1×3的卷积核将 3个通道的属性进行融合,传递给加强特征提取网络。相较于普通卷积,深度卷积结构产生的网络参数少,有效解决了深度学习网络重复学习特征信息造成计算量大的问题,提高了运算速度。网络模型的参数如表1所示。可以看出DC-YOLO v4在参数量、处理速度、模型内存占用量等方面均优于一些主流模型的主干网络。

表1 不同网络模型的主干网络参数Tab.1 Backbone network parameters of different network models
YOLO v4使用K-means设计先验框尺寸,但是它存在预先人为确定k个初始聚类中心的缺点,导致生成的先验框不稳定,难以反映真实框尺寸情况。之后提出的K-means++针对这一问题,进行了一系列改进,不再预先人为确定初始聚类中心,具体实现流程如图6所示。
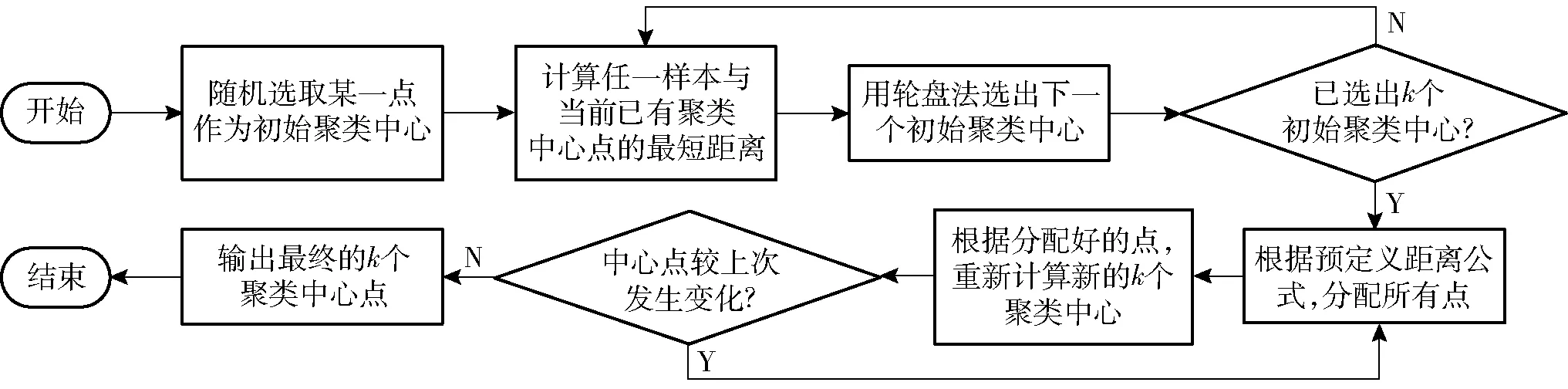
图6 K-means++算法流程图Fig.6 K-means++ algorithm flow chart
本文采用改进的交并比(GIoU)计算公式,通过引入检测框宽高的比例因子vs,避免GIoU在某些情况下退化成IoU的问题,改进的GIoU表达式为
(1)
其中
(2)
式中wgt、hgt——真实框的宽、高
wbb、hbb——预测框的宽、高
C——两框最小外接矩形的面积
A∪B——两框并集的面积
并将式(1)作为K-means++的距离计算公式,提高了网络预测精度。
在网络训练前对数据集进行了聚类处理,共得到9种尺寸的Anchor box,如图7所示,其尺寸分别为(18,20),(28,34),(40,45),(59,50),(45,69),(75,79),(126,55),(55,138),(266,295)。相较于K-means聚类结果,采用K-means++得到的锚框拟合程度更好,便于模型的训练。
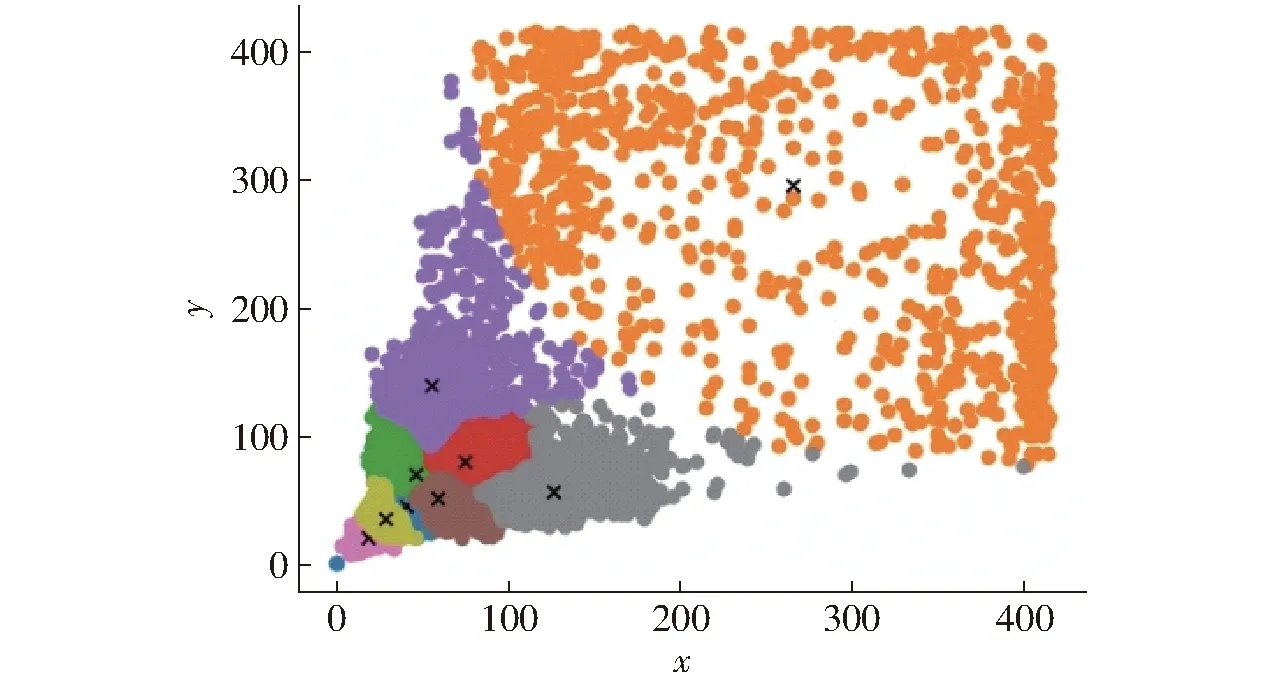
图7 9种尺寸的聚类中心分布图Fig.7 Distribution of cluster centers of nine sizes
1.3 番茄茎分割网络
1.3.1ICNet语义分割网络
番茄串检测问题大部分采用传统图像处理与机器学习相结合的方式,会受到图像本身噪声等多种因素的制约,为了解决番茄串检测中的局限性,本文将基于深度学习的语义分割算法应用于番茄串分割领域。ICNet网络模型[19]是基于高分辨率图像的实时语义分割网络。它利用处理低分辨率图像的效率以及高分辨率图像的高质量。思路是使低分辨率图像先通过全语义感知网络来取得大概的语义预测图,然后提出级联特征融合单元和级联标签指导策略整合中等和高分辨率特征,这逐渐提炼了粗糙的语义预测图。ICNet的网络架构如图8所示。它使用PSPNet的金字塔池化模块融合多尺度上下文信息,并将网络结构划分为3个分支,分别为低分辨率、中分辨率和高分辨率。配合ResNet50使用3个分支进行特征融合形式的训练,前2个分支增加辅助训练,增加模型收敛。对于每个输出特征,在训练时会以真实标签的1/16、1/8、1/4来指导各分支训练,使得梯度优化更加平滑,随着每个分支学习能力的增强,预测没有被某一分支主导。
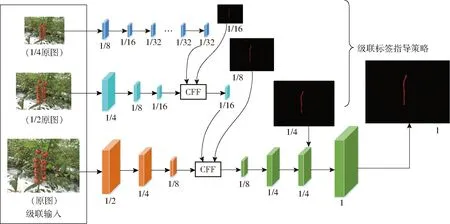
图8 ICNet网络结构Fig.8 ICNet network structure
分支1将原图下采样到1/4尺寸,然后经过连续3次下采样降维到原图的1/32,使用空洞卷积层扩展感受野的同时不缩小尺寸,最终输出1/32原图的特征图。分支1的卷积层数多但特征图尺寸小,速度快,且第2个分支与第1个分支共享前3层卷积的权值。
分支2将1/2尺寸的原图作为输入,经过卷积后降维到1/8原图,得到1/16尺寸的特征图,再将第1个分支中由低分辨率图像提取出的特征图通过级联特征融合单元得到最终输出。
分支3以原图像为输入,经3次卷积后得到原图1/8尺寸的特征图,再将处理后的输出和分支2的输出通过CFF融合。分支3的图像分辨率大,但卷积层数少,耗时较少。
ICNet的损失函数是通过构建多分支loss实现,损失函数表达式为
(3)
式中τ——分支数量,取3
xt、yt——分支的特征图尺寸
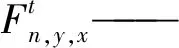
n′——相关的真实标签
λt——每个分支的损失权重
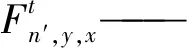
通常,高分辨率分支权重λ3设置为1,中分辨率和低分辨率分支的权重λ2和λ1分别设置为0.4和0.16。
1.3.2改进的ICNet语义分割网络
在一些经典的深度学习语义分割算法中,主要采用VGG系列或者ResNet系列作为主干特征提取网络,虽然二者都能够提取图像的深层信息,但是对于部署到嵌入式设备上而言,其网络模型的参数量过大,分割速度慢。因此,采用MobileNetv2替换ResNet,取消传统的卷积计算,采用深度卷积以及1×1的逐点卷积来提取图像特征,可以成倍减少卷积层的时间复杂度和空间复杂度。同时还引入了倒残差结构,先升维后降维,增强梯度的传播,显著减少推理期所需的内存占用量。倒残差结构如图9所示。

图9 倒残差结构Fig.9 Inverted residuals
在残差结构中,首先通过1×1卷积实现降维,再通过3×3卷积提取通道特征,最后使用1×1卷积实现升维。但在倒残差结构中,先通过1×1卷积实现升维,再通过3×3的逐通道卷积提取特征,最后使用1×1卷积实现降维。调换了降维和升维的顺序,并将3×3的标准卷积换为逐通道卷积,呈两头小、中间大的菱形结构。其次,改变了之前所采用的激活函数。残差结构中通常采用ReLU激活函数,但是,在倒残差结构中,采用ReLU6 作为激活函数,最后1个卷积使用的是线性激活函数。用ReLU6替换ReLU,目的是为了保证在嵌入式设备低精度也能保有很好的数值分辨率。如果对ReLU的输出值不加限制,那么输出范围就是零到正无穷, 无法精确描述其数值,这将带来精度损失。ReLU6激活函数如图10所示。最后1个卷积使用线性激活,则是线性瓶颈结构的内容。瓶颈结构是指将高维空间映射到低维空间,缩减通道数;膨胀层则相反,其将低维空间映射到高维空间,增加通道数。沙漏型结构和梭型结构,都可看做是1个膨胀层和1个瓶颈结构的组合。瓶颈结构和膨胀层本质上体现的都是1×1卷积。线性瓶颈结构是末层卷积使用线性激活的瓶颈结构。ReLU容易导致逐通道卷积部分的卷积核失活,即卷积核内数值大部分为零,这是因为在变换过程中,需要将低维信息映射到高维空间,再经ReLU重新映射回低维空间。若输出的维度相对较高,则变换过程中信息损失较小;若输出的维度相对较低,则变换过程中信息损失很大。因此,末层采用线性激活来避免这一问题。
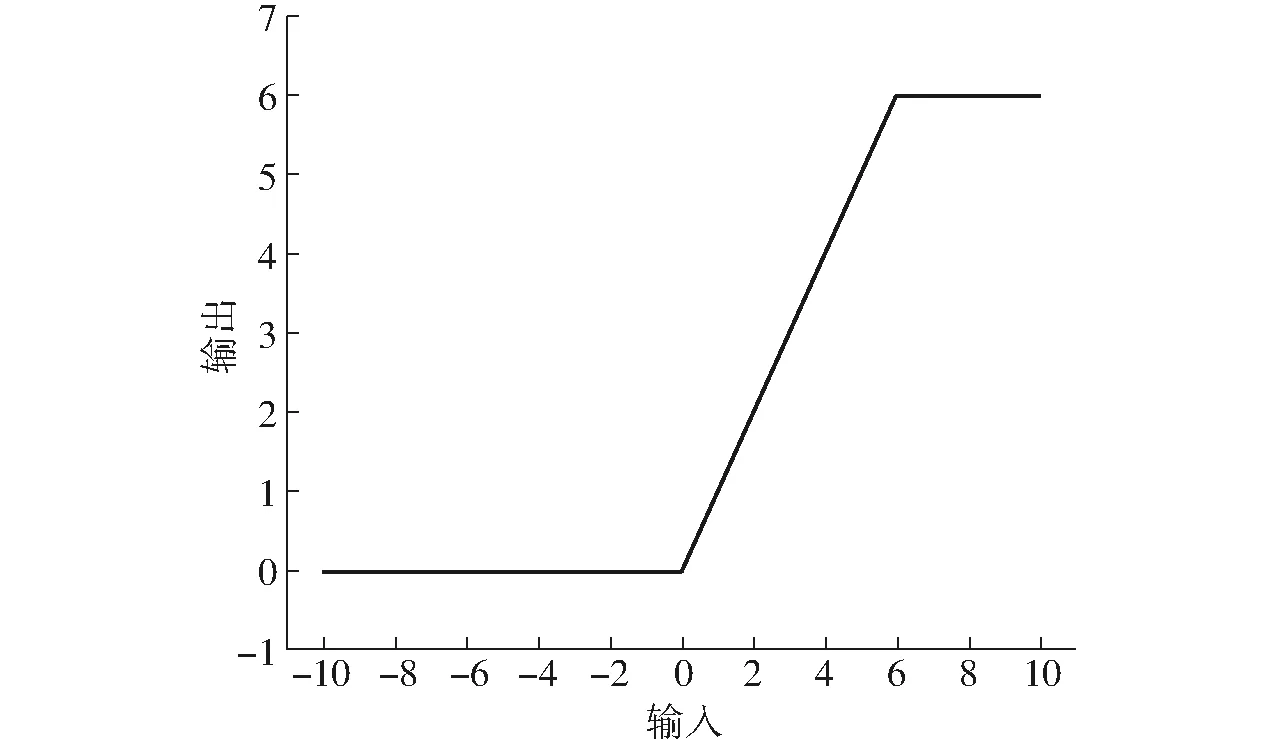
图10 ReLU6激活函数Fig.10 ReLU6 activation function
2 网络模型训练与评价指标
2.1 验证平台
主机操作系统为Ubuntu 16.04,中央处理器为Intel Core i9-10920X GPU@ 3.50 GHz,运行内存32 GB,显卡为Nvidia Quadro P2200(5 GB/戴尔)。神经网络在Anaconda 3虚拟环境下训练,采用Pytorch 1.2.0深度学习框架,配置安装Python 3.8编程环境、GPU并行计算架构Cuda 10.0和神经网络GPU加速库Cudnn 10.0。
2.2 番茄检测网络模型训练
采用PASCAL VOC 2007数据集的预训练权重训练,训练图像分辨率为416像素×416像素,每个批次处理8幅图像,总迭代次数为1 000,前450次采用冻结训练加快训练速度,训练学习率为0.001,每迭代100次,学习率降低0.1,后550次的解冻训练学习率为0.000 1。可以看出前200次迭代中网络快速拟合,200次迭代之后损失函数基本稳定,番茄检测网络开始收敛。图11反映了损失函数的变化趋势。

图11 目标检测模型训练曲线Fig.11 Target detection model training curves
2.3 番茄串语义分割网络模型训练
采用PASCAL VOC 2007数据集的预训练权重训练,输入图像分辨率为512像素×512像素,格式为JPG,对应的标签图像格式为PNG,类别数为2,下采样倍数为16,每个批次处理8幅图像,总迭代次数为500,前100次为冻结训练,学习率为0.000 5,后400次的解冻训练学习率为0.000 005。由图12可以分析出,在前100次迭代中网络快速拟合,100次迭代后损失函数基本稳定,番茄串语义分割检测网络开始收敛。
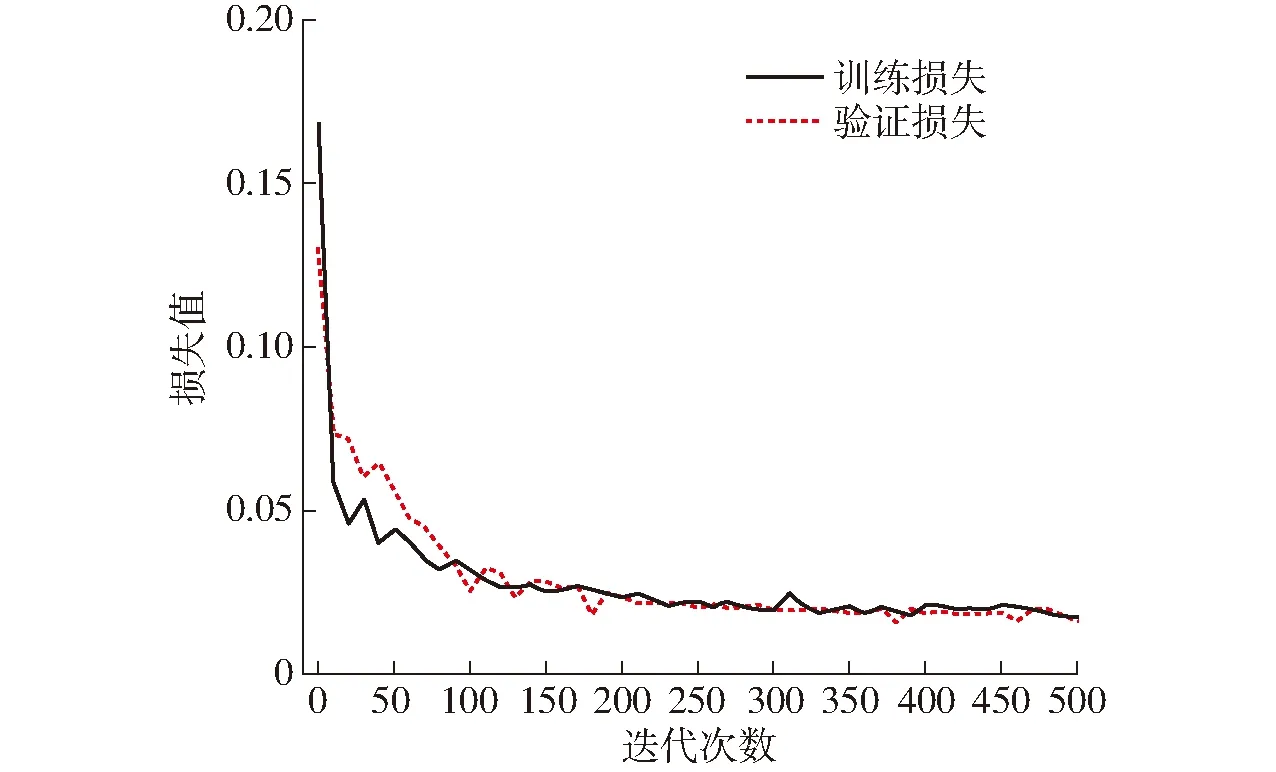
图12 语义分割模型训练曲线Fig.12 Semantic segmentation model training curves
2.4 评价标准
为了客观分析DC-YOLO v4对番茄数据集以及ICNet模型对番茄串数据集的语义分割性能,本文引入平均交并比(mIoU)、准确率(Precision)、召回率(Recall)、平均精度均值(mAP)、综合评价指标(F1值)、类别平均像素准确率(mPA)和检测时间(Time)等评价指标。本文的目的是快速准确识别番茄并分割番茄茎,因此把平均交并比、平均精度均值和检测时间作为主要评价指标。利用IoU阈值为0.5的平均精度来测定番茄识别模型的准确性。此度量标准用于测量目标检测器的精度,因为它平衡了精度和召回率。
3 结果分析
3.1 番茄检测效果
本文设计的检测模块借鉴了YOLO系列的架构,融合了深度卷积结构,因此有必要与传统的YOLO系列算法的番茄识别性能进行对比分析。同时,使用批量为8、尺寸为416像素×416像素的图像,对经过训练的MobileNet-YOLO v4、YOLOX、YOLO v5-m、YOLO v6进行测试和比较,在测试模型中获得的结果存在差异,测试结果如图13所示。DC-YOLO v4模型对番茄和番茄串的识别正确率高于YOLO v4模型,YOLO v4模型深度图中存在大量噪点,导致其识别精度不足,误检率高。MobileNet-YOLO v4检测模型在实际应用中,对番茄串的识别不敏感,且在深度图中,DC-YOLO v4模型的番茄串轮廓更为光滑。YOLOX模型[20]是由旷视科技在2021年提出的全新检测模型,DC-YOLO v4模型与YOLOX模型在实际测试中,并无明显区别。YOLO v5-m模型的检测速度快,但丧失了一定的识别准确度,虽然能够获取图像的高级特征,但这些特征具有平移不变性[21],不利于对目标信息的区域采样。

图13 不同检测模型测试效果Fig.13 Test results of different test models
为论证本研究提出的DC-YOLO v4模型的有效性,又与YOLO v5模型系列中最为主流的YOLO v5-m、YOLO v6以及CenterNet检测模型比较。YOLO v6模型是美团视觉智能部研发的一款目标检测框架,致力于工业应用。CenterNet模型[22]是无锚框目标检测器,由于没有复杂的Anchor操作,检测速度优于Two-Stage及预锚框系列,算法性能良好,对小目标检测具有优势[23]。CenterNet模型只通过FCN(全卷积)的方法实现了对于目标的检测与分类,即使没有Anchor与NMS等操作,它在高效的同时精度也较好。可以将其结构进行简单修改就可以应用到农业场景下的番茄目标检测之中。
表2展示了不同网络模型对番茄串和番茄的检测性能,DC-YOLO v4模型的mAP最大,对于番茄和番茄串的识别准确率及召回率最高,单幅图像预测时DC-YOLO v4模型比YOLO v4模型的mAP高2.04个百分点。比MobileNet v3-YOLO v4模型的mAP高1.08个百分点。原因是卷积层较多,计算量大,检测速度偏慢,神经网络层数过深,因此检测精度较低。与DC-YOLO v4模型相比,CenterNet模型难以对纹理特征进行有效提取,mAP低于DC-YOLO v4模型2.34个百分点,并且检测时间差,不满足工业条件下的实时性要求。
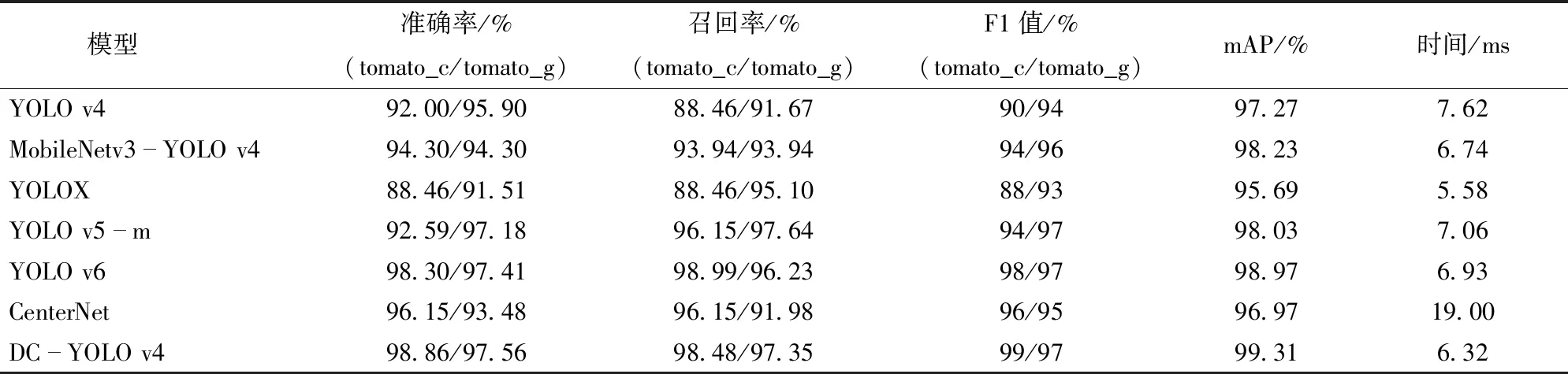
表2 不同识别模型性能比较Tab.2 Performance comparison of different recognition models
另外,DC-YOLO v4模型的召回率稍低于YOLO v5-m模型与YOLO v6模型,原因是YOLO v5-m模型的Backbone是基于CSPNet搭建的,而YOLO v6模型的Backbone则是引入了RepVGG结构[24],二者的主干检测网络较为复杂,对于单番茄果实的特征提取能力强。相对于YOLOX模型,虽然DC-YOLO v4模型的检测时间增加0.74 ms,实时性略低于YOLOX模型,但是检测精度提高3.62个百分点。可以看出,DC-YOLO v4模型能同时兼顾实时性和准确性,满足工业条件下采摘机器人的需求。
3.2 番茄茎分割效果
为了更好地展现改进的ICNet模型性能提升的直观效果,本研究还选取目前有代表性的主流语义分割网络DeepLab_v3+[25]、U-Net[26]和PSPNet[27]进行实际测试实验。对比实验结果如 图14 所示,相较于ICNet,改进后的ICNet能够完整分割出番茄茎,较好地保存逐像素点含有的位置信息和语义信息,U-Net只能捕捉大致外形,且包含大量噪点,PSPNet缺少分割细节,不能很好地表征目标特征,DeepLab_v3+在实际测试中,效果与改进后的ICNet无明显差异。根据本研究提出的量化指标,结合表3可以得出,改进的ICNet网络与其他网络相比分割性能有了一定的提高,本文提出的改进ICNet网络mIoU和mPA分别为81.63%和91.87%,相较于ICNet模型,mIoU和mPA分别提升2.19个百分点和1.47个百分点;相较于DeepLab_v3+模型,mIoU和mPA分别提升7.04个百分点和3.51个百分点;相较于U-Net模型,mIoU和mPA分别提升7.74个百分点和4.88个百分点;相较于PSPNet模型,mIoU和mPA分别提升9.71个百分点和4.66个百分点。结果表明,改进ICNet网络相较于其他网络在番茄茎分割上更有优势。

表3 不同分割模型性能比较Tab.3 Performance comparison of different segmentation models

图14 不同分割模型测试效果Fig.14 Test results of different segmentation models
3.3 温室中视觉感知模型验证
为了验证本文提出的农作物采摘视觉感知模型在实际应用场景下的性能,将模型部署到山东中科智能农业机械装备创新技术中心自主研发的番茄采摘机器人系统中进行采摘实验。如图15所示,采摘机器人核心组成部件包括众为创造xARM型六轴机械臂、Intel RealSense D435型深度相机、可移动吊轨以及工控机。

图15 吊轨采摘机器人Fig.15 Rail picking robot
在实际应用中,当完成检测任务后,控制系统会给机械臂发送一个前移指令,末端执行器带动RealSense D435型深度相机向番茄茎大概方位移动,拉近感受视野,使ICNet能够实时分割出视频流数据中的番茄茎。如图16所示,彩色图中的蓝色掩膜为ICNet模型在视频流中的分割效果,为了满足工程级的实时性要求,采用霍夫变换将其转换为二值图进行处理,加快系统的处理速度。

图16 实际场景中的分割效果Fig.16 Segmentation effect in real scene
本文共进行了80次采摘实验,由于吊轨采摘机器人每次仅能采摘一串红色番茄,故只统计了红色番茄串的采摘成功率,最终的平均采摘成功率为84.8%。RealSense D435型深度相机检测到番茄串后,会计算并返回感兴趣区域的的中心点,控制系统驱动末端执行器移动到中心点前的10 cm处,经过ICNet模型处理后,得到分割番茄茎,末端执行器会根据计算得到的采摘点进行采摘,最后将采摘的番茄串放入收纳篮中,完成上述采摘流程平均用时6 s。影响工作时间的主要原因是番茄茎与背景颜色相近,对于番茄茎的形状特征提取能力差,同时枝叶的遮挡也增加了番茄茎提取的难度。
4 结论
(1)番茄和番茄串测试集上的实验结果表明,检测模块对番茄的识别准确率为98.86%,召回率为98.48%,F1值为99%,对番茄串的识别准确率为97.56%,召回率为97.35%,F1值为97%,模型平均精度为99.31%,模型平均识别单幅图像需要6.32 ms。相比于本研究中选用的一些目标检测对比模型,在性能上有明显的提升,DC-YOLO v4模型的mAP相比于YOLO v4、MobileNet v3-YOLO v4、YOLOX、YOLO v5-m、CenterNet、YOLO v6模型提高2.04、1.08、3.62、1.28、2.34、0.34个百分点。
(2)番茄茎测试集上的实验结果表明,改进的ICNet分割模型对番茄茎的平均召回率为91.87%,mIoU为81.63%,mPA为91.87%,模型平均分割单幅图像需要8.21 ms,改进的ICNet模型的mPA相比于ICNet、DeepLab_v3+、U-Net和PSPNet分别提升1.47、3.51、4.88、4.66个百分点。
(3)将检测模型部署到番茄采摘机器人上,在温室环境下对番茄串进行采摘论证,与人工检验进行对比,结果表明,机器人的准确采摘率为84.8%,平均完成一次采摘动作用时6 s。本文的研究结果可以为复杂温室环境下的其他农作物采摘提供技术支撑。
