基于YOLO v7-ST模型的小麦籽粒计数方法研究
2023-11-23冯天赐王一博李雨桐
王 玲 张 旗 冯天赐 王一博 李雨桐 陈 度
(1.中国农业大学工学院, 北京 100083; 2.北大荒农业服务集团黑龙江农机服务有限公司, 哈尔滨 150090)
0 引言
小麦是我国重要粮食作物之一,提高小麦产量和品质对保障我国粮食安全具有重要意义。考种作为选育高产高质小麦品种的重要手段,其效率和精度直接影响育种结果。小麦考种涉及植株和籽粒的多种性状参数,如千粒质量、粒型、产量等,而籽粒个数计算是千粒质量测量、产量预估等的基础数据。因此,快速准确的小麦高通量籽粒计数能加快考种效率,对提升小麦产量具有重要意义[1-3]。
然而,在复杂农业生产环境下,小麦籽粒计数存在不同程度的重叠遮挡、密集粘连等问题,严重影响计数精度。近年来,机器视觉技术被广泛应用于农作物品质检测、产量预估和籽粒计数的研究,基于此,研究人员提出了基于传统数字图像处理的籽粒计数方法[4-6]。VISEN等[7]使用分类和凹点检测对遮挡籽粒进行分割,通过确定惯性等效椭圆的重叠程度,将谷物表征为孤立的内核或一组粘连的内核,再通过凹点检测法和最近邻准则绘制分割线。李立君等[8]提出基于凸壳理论的遮挡油茶果定位检测算法,该算法通过颜色特征和凹点搜寻对重叠目标进行粗分割,再利用轮廓提取算法提取出了凸壳上的有效轮廓。相比于人工和传感器的逐个检测方法[9-11],数字图像处理方法大大提高了检测效率和计数精度,然而,该方法高度依赖图像质量和研究人员对目标特征的分析,不同场景的泛化能力及鲁棒性较差。
深度学习方法因其对抽象特征的强大学习能力,在目标物遮挡、粘连情况下仍能够通过关键特征有效识别目标[12-14]。SUN等[15]针对重叠水稻种子计数提出了一种基于轮廓分组预标记的深度学习目标检测方法,该方法以欧几里得距离和散度函数作为综合标准预先标记水稻种子轮廓,并将预标记结果整合到其特征提取层,通过Faster R-CNN进行分类计数,平均错误率1.06%。ZHAO等[16]开发了一种基于改进的YOLO v5的小麦麦穗检测方法,通过添加微尺度检测层,利用置信度系数对多层特征图中的检测框进行融合,以提高遮挡条件下的检测精度,平均检测准确率94.1%。XU等[17]针对自然环境下柑橘的重叠、遮挡问题,将通道注意力机制和预测框筛选算法Soft DIoU NMS引入YOLO v4中,有效地提高了检测精度。龙燕等[18]提出了一种改进全卷积单阶段无锚框网络FCOS的苹果目标检测方法,该网络引入联合交并比损失函数,能更好反映预测框和真实框重合度,使网络能够关注到被果实和树叶遮挡的极难识别的目标,并针对不同密集度和不同遮挡程度进行对比试验,结果表明改进的FCOS准确率可达96.0%。因此,深度学习方法应用于多种农作物重叠、遮挡检测与识别的研究取得了一定效果[19-20],但相关研究多是针对目标与复杂背景之间的遮挡问题,当多个待检测目标相互遮挡且遮挡程度较高,仅显现极小的局部特征时,相关研究的算法模型不能准确从仅有的未被遮挡的局部特征中识别待检测目标,从而将其与粘连的其他检测目标识别为同一目标,造成漏检。
此外,目前基于深度学习的重叠遮挡的研究场景多是针对少量目标的低通量检测,然而,小麦室内考种具有高通量计数需求,大量籽粒存在不同程度的遮挡、粘连等问题,同时小麦籽粒目标较小,遮挡目标的识别难度大幅提高,相关研究中的算法模型无法满足高通量小目标快速准确的计数需求。因此,本文基于Swin Transformer提出改进YOLO v7-ST网络模型,该模型利用移位窗口和多头注意力机制可有效识别被遮挡籽粒与其粘连籽粒的关联特征,并提高对遮挡目标局部特征的识别能力。以此为基础,基于电磁振动原理设计小麦籽粒振动分离装置,并引入二阶离散系数对籽粒离散均匀度进行试验研究,从而对不同程度遮挡、粘连的小麦籽粒进行分级检测,以期实现各级离散度下籽粒的准确快速计数。
1 籽粒振动分离装置设计
1.1 系统组成
小麦籽粒振动分离装置如图1所示,由工业相机、光源、电磁振动器、振动控制器、输送平板、卸料斗、图像采集处理单元和固定支架组成。相机采用华睿科技A7500CG20型彩色CMOS相机,分辨率为500万像素,搭配16 mm焦距镜头,采样视野范围为350 mm×200 mm。光源采用亮度强、光损失少、成像清晰、亮度均匀的同轴光源,为图像采集装置提供稳定的光照环境。

图1 小麦籽粒振动分离装置Fig.1 Wheat seed vibration separation device1.支架 2.工业相机 3.光源 4.输送平板 5.电磁振动器 6.图像处理单元 7.卸料斗 8.振动控制器
由于散落在输送平板上的小麦籽粒呈堆积状态,难以直接进行图像采集与处理,因此,基于电磁振动原理消除籽粒堆积现象,使籽粒离散分布于图像采集范围内,可提高考种测量精度。电磁振动器工作原理图如图2所示,电流在正半周期时,交流电流过电磁线圈产生电磁力吸附衔铁,衔铁带动弹片产生形变存储势能;当位于负半周期时,线圈内没有电流流过,电磁力消失,弹片释放弹性势能产生激振力,输送平板在激振力的作用下向前运动,其中β为振动方向角,取15°,α为输送倾角。电流通过电磁线圈时所产生的激振力F[21-22]为
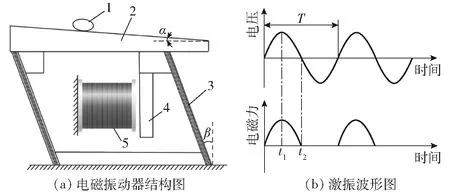
图2 电磁振动器工作原理图Fig.2 Diagram of working principle of electromagnetic vibrator1.小麦籽粒 2.输送平板 3.弹簧片 4.衔铁 5.电磁线圈
(1)
式中f0——振动频率,Hz
H——振幅,mm
m——物料质量,kg
ξ——激振频率与固有频率之比
随电流的周期性变化,与输送平板接触的籽粒沿振动方向向前滑动一定距离,而堆积于表层的籽粒滑落至平板后才能向前滑移。当振动器以一定频率和振幅连续振动时,籽料被连续输送出去。适当的激振力有利于籽粒平稳前进,当激振力较大时,籽粒前进速度过快,表层和底层籽粒在激振力作用下同时快速前进,不能及时分离;而激振力过小时,籽粒分离所需时间过长。待籽粒堆积现象消除后进行图像采集与处理,进而籽粒在电磁振动作用下从输送平板末端滑出,完成卸料。
1.2 小麦籽粒离散度分级方法
1.2.1籽粒离散度影响因素分析
小麦籽粒在电磁振动过程中主要受激振力F、重力G和摩擦力Ff(图3),籽粒在电磁振动作用下随输送平板运动时,所受合力F′和运动加速度a为
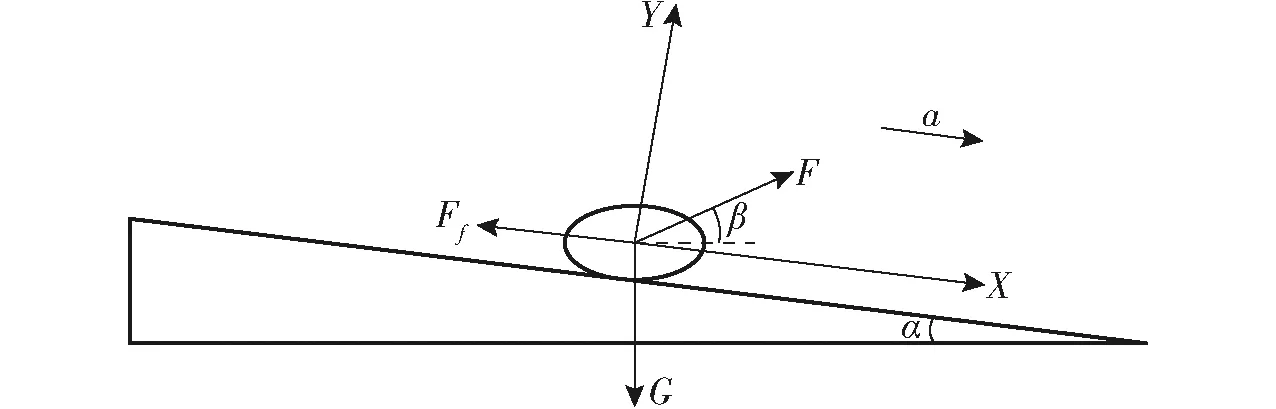
图3 籽粒受力分析图Fig.3 Force analysis diagram of seed
(2)
式中g——重力加速度,m/s2
μ——摩擦因数
由式(2)可知,籽粒的运动加速度受振动频率、振幅、输送倾角和摩擦因数的影响,当电磁振动器振动参数与输送平板表面粗糙度不同时,籽粒在激振力、重力和摩擦力的共同作用下向前运动,籽粒的分离效果即籽粒离散度不同。为探究小麦籽粒高通量计数需求中不同离散度下籽粒粘连和遮挡程度对籽粒计数准确度的影响,以小麦籽粒离散度为评价目标,选择振动频率A、振幅B、摩擦因数C及输送倾角D为试验因素,通过设计正交试验采集不同离散度的试验样本。
电磁振动器振动过程中,当激振频率等于固有频率时将发生共振,此时振幅达到最大值,但振动装置工作不平稳。为达到高效、稳定的工作状态,应使振动电机工作在亚共振区,即激振频率与固有频率之比ξ为0.85~0.98[23]。试验中,采用SDVC31型数字调频振动送料控制器进行振动频率调节,通过固定控制器输出电压并调整激振频率,发现当激振频率为73 Hz时,振幅最大,即振动器固有频率为73 Hz,振动频率f0为62.5~69.4 Hz。
引入机械指数K以计算籽粒振幅。
(3)
机械指数是用来衡量振动强弱的物理量,机械指数越大表明振动越剧烈,为使得物料稳定输送,并保证振动冲击对槽体的损坏较小,通常K取2~5[23]。由式(3)计算可知,籽粒振幅为0.13~0.26 mm。
探究输送平板摩擦因数对籽粒离散度的影响时,采用不同粗糙度的砂纸作为表面材料(所以摩擦因数以砂纸的粒度为度量,即单位为目),基于已有的研究分析和实际作业效果,砂纸分别选择30、60、120、240目。此外,输送平板倾角α为正值时,平板向下倾斜,籽粒运动加速度增大,反之,籽粒运动加速度减小;根据试验效果,平板倾角α为-3°~6°。每个因素选择4个水平进行试验,试验因素和水平如表1所示[24-25]。
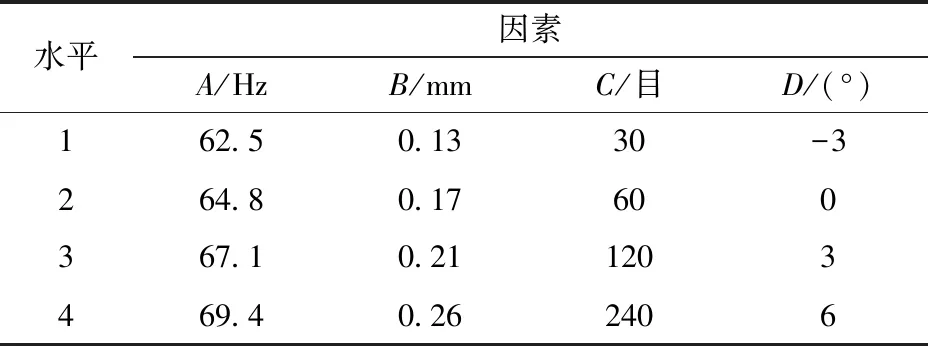
表1 正交试验因素水平Tab.1 Factors and levels of orthogonal test
将50 g小麦籽粒直接导入振动分离装置,采用四因素四水平的L16正交试验方案进行试验,图4为不同影响因素下小麦籽粒的离散分布情况,摄像头采集的图像尺寸为2 448像素×1 604像素。由图4可知,受电磁振动作用高通量籽粒的堆积现象基本消除,籽粒平铺于振动平板上。

图4 基于正交试验方案的籽粒样本离散度分布图Fig.4 Dispersion distribution of seed samples based on orthogonal test scheme
1.2.2籽粒离散度评价方法
由图4可知,受振动频率、振幅、输送倾角和摩擦因数的影响,籽粒的离散分布情况差异明显,进而产生不同程度的籽粒遮挡和粘连问题。评价数据离散度通常采用离散系数,但在籽粒分布图中,局部区域籽粒极度密集或极度稀疏,导致数据极差大,传统离散系数无法反映籽粒分布的真实情况。二阶离散系数对异常值的敏感度较低,受局部离散度的影响较小,因此,引入二阶离散系数作为研究籽粒离散度的评价指标,计算式为[26]
(4)
式中cv——二阶离散系数
σ——数据标准差

为计算原始图像的二阶离散系数,需获取二值图中各局部区域目标像素占比作为基础数据,因此,将对原始图像进行预处理。首先采用Laplace算子和锐化方法对原始图像进行组合增强,增强后的图像像素分布出现明显分界线,如图5所示,再通过自适应阈值分割将图像二值化。
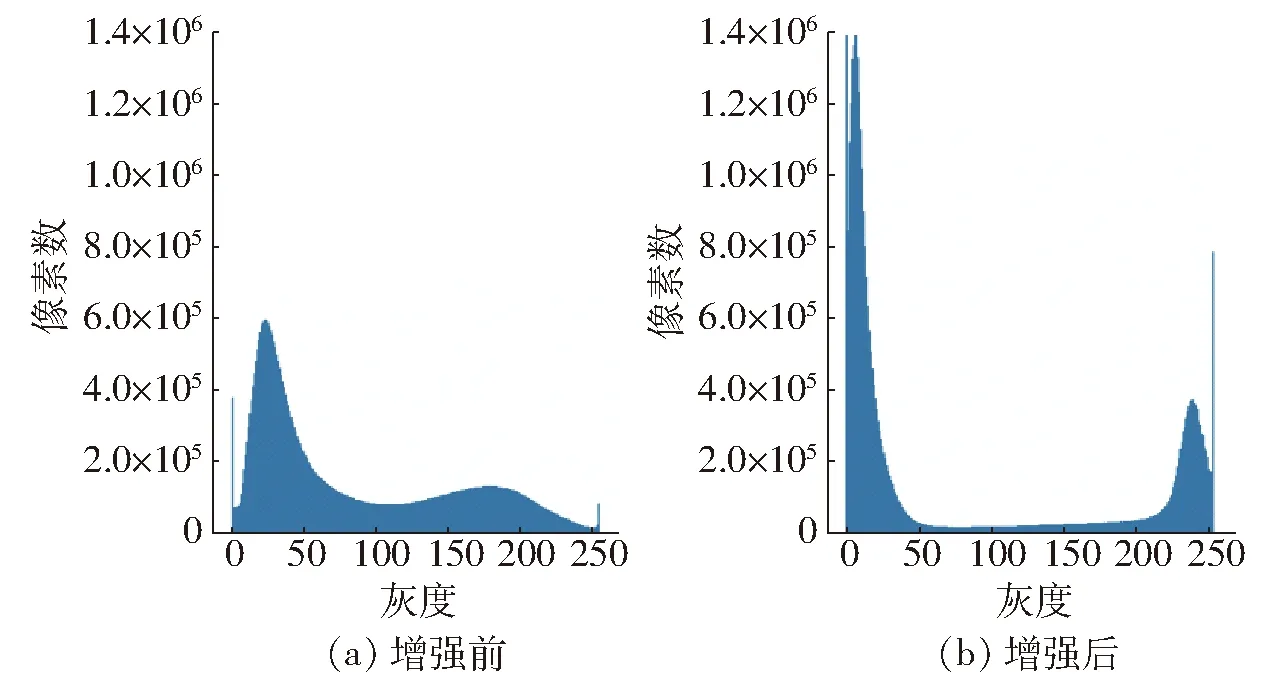
图5 图像像素分布Fig.5 Image pixel distribution
由于光照强度、砂纸晶粒噪声等因素影响,二值图中存在较多尺寸不一的噪声和孔洞,基于传统十字形和矩形卷积操作的形态学处理方式难以同时消除噪声和填充孔洞。因此,分别对灰度0像素和灰度255像素连通域面积进行统计分析,通过面积阈值筛选出目标噪声和孔洞,采用四邻域漫水填充算法分别对其进行反向填充。为衡量籽粒分布特征,将处理后的二值图裁剪为24个408像素×401像素的局部区域,通过统计各区域籽粒像素百分比作为基础数据,再计算该组数据的总体平均值和标准差,即可由式(4)得到原始图像籽粒分布的二阶离散系数,图像处理过程如图6所示。

图6 籽粒原始图像预处理效果图Fig.6 Pre-processing effect of original image of seeds
1.2.3籽粒离散度分级
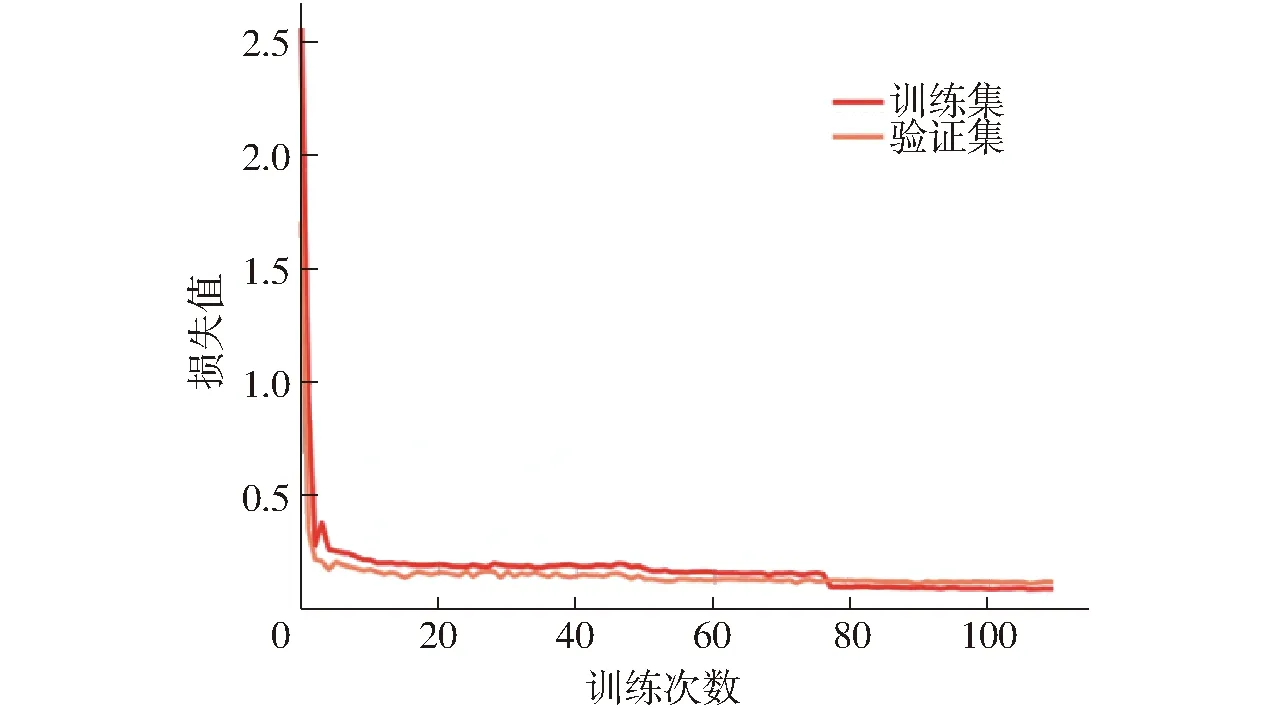
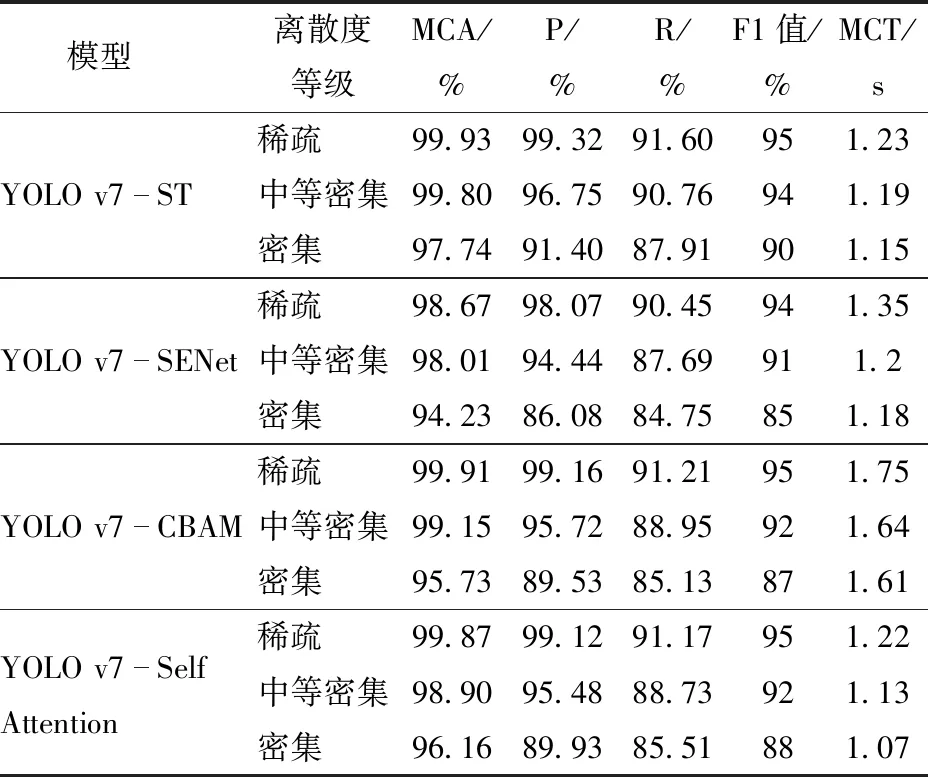
二阶离散系数是衡量一组数据离散度的相对统计量,其值越小,则数据的离散度越低,籽粒分布越均匀;反之数据离散度高,籽粒分布不均匀,遮挡与粘连现象明显。基于籽粒离散度评价方法,对16组试验样本进行离散度系数计算,每组试验重复3次,取平均二阶离散系数为试验结果,籽粒离散度评价如表2所示。结合图4中各组试验样本的籽粒离散分布情况,将籽粒离散度分为3个等级,其中,当平均二阶离散系数cv≤0.4时,离散度等级为“稀疏”,0.4 表2 正交试验结果Tab.2 Results of orthogonal test 试验所用小麦籽粒于2021年6月在北京市小汤山镇国家精准农业研究示范基地试验田获得,千粒质量为36 g,每次试验选取籽粒50 g,约1 400粒。基于籽粒振动分离装置采集不同离散度图像72幅,图像分辨率为2 448像素×1 604像素,并使用LabelImg标注软件手工标记小麦籽粒。为保证测试结果能够真实反映模型泛化能力,均匀选取原始数据集中不同密度等级的32幅图像作为测试集,剩下40幅作为训练集和验证集。由于原始图像分辨率较高,难以满足网络输入尺寸要求,因此,通常采用下采样和裁剪两种方式对原始图像进行处理。由于强制下采样会降低图像分辨率,导致图像特征严重丢失,造成部分籽粒无法识别。因此,本文采用步长为543的重叠滑窗策略将原始训练集和验证集中的高分辨率图像裁剪为640像素×640像素的低分辨率图像,满足模型输入限制,并对重叠部分的预测结果进行融合,以解决传统裁剪方式因边缘籽粒误分割而引入的计数误差。 为在原始图像样本量有限的情况下更好地提取图像特征,本文采用光度失真和几何失真对样本量进行扩充,通过调整图像色调及饱和度,添加随机缩放、平移、剪切和旋转等,将裁剪后小尺寸图像扩充至1 224幅。为进一步提高模型的泛化能力,采用Mixup[27]和Mosaic[28]增强方法,通过从训练图像中随机选取2个样本及其标签进行加权求和以及使用4幅图像分别覆盖不同区域等方法,丰富数据集中图像背景,增加数据的多样性,防止样本扩充所产生的图像特征相似度高而导致的模型过拟合,数据增强方法的实际效果如图7所示。 图7 不同数据增强方法实际效果图Fig.7 Actual effect of different data enhancement methods YOLO v7[29]算法是基于深度神经网络进行对象的识别与定位,通过引入高效聚合网络等多个学习策略提高模型学习能力,并大幅提高检测速度。而小麦籽粒计数任务中,当籽粒粘连严重甚至形成遮挡时,会严重影响卷积神经网络的输出结果,因此,为提高模型对不同离散度下籽粒计数任务的检测精度,本文以YOLO v7作为基线,引入Swin Transformer[30]模块,提出了YOLO v7-ST模型,模型网络结构如图8所示。 图8 YOLO v7-ST网络结构框图Fig.8 YOLO v7-ST network structure YOLO v7在主干网络中采用的多分支堆叠模块E-ELAN可利用分组卷积来扩展计算模块的通道和基数,实现在不改变原有梯度路径的情况下堆叠更多模块,增强网络学习能力。颈部沿用特征金字塔结构对多特征进行融合,头部网络中使用重参数化卷积RepConv,在训练过程中并联3×3卷积、1×1卷积和恒等映射,为不同的特征映射提供了更多的梯度多样性。同时添加辅助检测头,计算网络中间层损失值以监督梯度下降方向,最后将辅助头和检测头的结果进行融合,可有效提高模型性能。 然而,在本文“密集”分布等级下,存在较多因重叠遮挡而产生的小目标籽粒。对于这种高度密集情况下的小目标检测场景,经过主干和颈部网络提取到的特征信息中包含大量干扰信息,由传统卷积模块进行的权重分配会导致小目标特征被视为冗余信息而丢失,因此考虑在检测头中添加Swin Transformer模块以更好地整合从特征融合网络中输出的特征信息。 Swin Transformer block首先通过Patch Embedding对输入图像进行切块编码,经归一化后送入带移动窗口的多头注意力机制层,再经Concat、LayerNorm以及多层感知机MLP后输出特征图。根据本文检测类别数使用1×1卷积对特征图通道数进行调整,得到[20,20,18]、[40,40,18]和[80,80,18]3个输出结果,其中18代表3个先验框的6个参数,分别包括每个特征点的回归参数[x,y,w,h],用于调整获得预测框位置,以及每个特征点是否包含目标和所包含的目标种类。 表3 各离散度等级计数结果评价Tab.3 Evaluation of counting results of each dispersion level 相较于传统的自注意力机制在对当前位置信息进行编码时过度关注自身位置的缺陷,Swin Transformer的多头注意力机制不仅可以帮助模型独立地关注不同的特征子空间,还可通过窗口的移位操作加强局部信息之间的联系,捕获丰富的上下文信息。在公开数据集VisDrone2021中,Swin Transformer模块在高密度遮挡对象上的识别准确率提高了30%~50%[31],这也更加证实了其对遮挡对象的检测能力。 本文模型训练通过NVIDIA RTX3080 GPU加速,显存10 GB,采用Python 3.8及PyTorch 1.7.0完成程序设计,梯度下降采用Adam优化器。为加快模型拟合速度,通过迁移学习加载已在ImageNet数据集[32]中训练完成的主干网络权重参数,且采用冻结训练方式将主干网络冻结,只训练头部网络,初始学习率为0.001,经过50次(Epoch)训练后解冻,共训练110次。冻结训练时占用显存较小,设置Batch Size为8,解冻后设置Batch Size为4。采用余弦退火策略[33]对学习进行动态调整,训练损失值变化曲线如图9所示,模型随迭代次数增加逐步收敛,在80轮训练后达到稳定,将此时的训练结果作为最终权重参数。 图9 训练损失变化曲线Fig.9 Training loss variation curves YOLO v7-ST网络模型输入图像是经过重叠滑窗裁剪过后的640像素×640像素的小尺寸图像,需将小尺寸图像的预测结果拼接成原始图像尺寸。由于图像拼接的重叠部分存在多个预测框,如图10a所示,因此,采用非极大抑制算法(NMS)和Soft-NMS算法[34]对重叠预测框进行筛选。如图10b所示,最右侧籽粒与中间籽粒紧密贴合造成遮挡,两者交并比较大,采用NMS算法导致置信度较低的右侧籽粒预测框被“抑制”,仅留下置信度较高的中间籽粒预测框。而Soft-NMS算法基于交并比的高斯衰减函数降低重叠框的置信度,衰减函数公式为 图10 后处理效果对比Fig.10 Post-processing effect comparisons (5) 式中i——样本索引 Si——置信度分数 bi——第i个预测框 S′i——衰减后的置信度分数 M——置信度最大的预测框 IoU()——交并比,两预测框重叠面积与两预测框并集面积之比 由式(5)可知,与预测框M重叠度越高,即交并比越大的预测框,其置信度衰减越大。重复上述过程更新所有预测框置信度,并设定置信度阈值,删除小于该阈值的预测框,其筛选结果如图10c所示,Soft-NMS算法有效保留了置信度0.55的右侧预测框。 为量化分析网络模型性能,采用平均计数准确率(Mean counting accuracy,MCA)、精确率(Precisoin,P)、召回率(Recall,R)、F1值和平均计数时间(Mean counting time,MCT)作为评价指标。其中,平均计数准确率表示模型预测籽粒数与实际籽粒数的比值,用于表征计数结果的准确性;精确率反映模型的查准能力;召回率反映模型的查全能力;F1值是评价精确率和召回率的综合指标;平均计数时间即单幅图像的检测时间。 采用本文构建的YOLO v7-ST模型对不同离散度等级的32幅测试集图像进行预测,单幅图像籽粒个数约1 400粒,不同离散度等级下籽粒分布情况如图11所示。采用预测框的红色中心点对籽粒进行标记,由表3可知,YOLO v7-ST模型在各离散度等级下的平均计数准确率平均值为99.16%,F1值平均值为93%,平均计数时间的平均值为1.19 s,其中籽粒离散度等级处于“稀疏”时,计数准确率为99.93%;当籽粒处于“中等密集”等级时,籽粒粘连程度增加,计数准确率达99.80%,表明模型对严重粘连籽粒有较好的识别效果;当籽粒处于“密集”等级时,计数准确率下降2.06个百分点,且精确率普遍高于召回率,说明模型具有更强的查准能力,查全能力稍弱,因此模型计数准确率下降的主要原因在于遮挡程度增加造成的漏检,但计数准确率仍可达到97.74%,模型综合评价指标F1值均在90%以上。检测速度方面,由于模型采用重叠滑窗将单幅图像裁剪15次,即需检测15次,当籽粒分布密集度高时,部分小尺寸图像中不存在籽粒,即模型跳过该区域的检测,因此单幅图像检测时间和籽粒离散度呈负相关;单幅图像模型平均计数时间为1.19 s,能够满足高通量快速准确检测的需求。 图11 各离散度等级计数效果Fig.11 Counting effects of each dispersion level 为验证Soft-NMS对拼接后的预测框进行后处理的有效性,在表3中增加了YOLO v7-ST模型不进行后处理的对照组试验结果。结果表明,不进行后处理时模型的计数准确率大幅下降,3个离散度等级下的平均MCA仅有38.74%,下降了60.42个百分点。精确率同样下降明显,但召回率有明显提升,平均召回率95.37%,提升5.28个百分点,这是因为未进行后处理的模型保留了拼接后的所有预测框,因此模型查全能力更强,但其中包含大量裁剪处被误分割的“破损籽粒”检测出的低置信度预测框,导致模型查准能力较差,即精确率低,而添加Soft-NMS可以保留“破损籽粒”完整部分预测出的高置信度预测框,并剔除仅靠破损部分识别出的低置信度预测框。经后处理的YOLO v7-ST模型计数准确率和F1值大幅提升,充分证明了Soft-NMS后处理的重要性。 为验证本文网络模型的检测效果,在相同测试集下,分别与目标检测领域的主流模型YOLO v7、YOLO v5、Faster R-CNN进行对比,结果如表4所示。 表4 不同模型检测结果对比Tab.4 Comparison of detection results for different models 在检测准确率方面,籽粒离散度等级为“稀疏”时,YOLO系列模型均有极高的识别准确率,准确率达到99.90%,Faster R-CNN准确率较低,仅有96.30%;当籽粒离散度等级为“中等密集”时,各模型平均计数准确率相较“稀疏”等级,YOLO v7-ST、YOLO v7、YOLO v5和Faster R-CNN分别下滑0.13、0.91、1.13、9.17个百分点,F1值分别下降1、2、3、7个百分点,由于YOLO v7、YOLO v5和Faster R-CNN模型缺少注意力机制对特征的高效提取,易将多个粘连籽粒识别为同一籽粒而造成漏检,因此YOLO v7-ST模型对于粘连籽粒的检测效果更优;当籽粒离散度等级为“密集”时,籽粒之间产生严重遮挡,各模型均存在不同程度的漏检,平均计数准确率分别为97.74%、95.39%、91.80%和67.73%,F1值分别为90%、86%、82%和62%,相较于另外3种模型,YOLO v7-ST模型的检测准确率分别提高2.35、5.94、30.01个百分点,F1值分别提高4、8、28个百分点,可见Swin Transformer检测头可有效提高遮挡目标的检测效果。检测时间方面,以YOLO v7为基线的模型检测速度更快,由于YOLO v7-ST增加了模型复杂度,但Swin Transformer基于局部移位窗口方法有效降低了参数量,检测时间与YOLO v7检测时间相近。 为验证本文网络模型注意力机制的优越性,在相同测试集下,比较了Swin Transformer与通道注意力机制SENet、双重注意力机制CBAM、自注意力机制Self Attention的效果差异,结果如表5所示。 表5 不同注意力机制检测结果对比Tab.5 Comparison of detection results for different attention algorithms 对比几种注意力机制的检测结果可知,基于自注意力机制的网络模型在“密集”等级下的检测精度更好,这是由于自注意力机制依赖于目标之间的相似度,尽管被遮挡的目标存在一定的特征丢失,但可以通过周围的籽粒特征近似表达被遮挡籽粒,具有较强的可解释性。而SENet和CBAM依赖于通道或空间上的特征重要性,通过卷积的权重学习调整特征的强弱,缺少相互之间的联系。此外,对比Self Attention和Swin Transformer的多头注意力机制,其本质都是通过非线性变换将输入映射在新的空间中,而本文的多头注意力可以将输入映射在6个子空间,再通过特征聚合捕捉所有空间特征信息,信息更丰富,效果更好。 图12为“稀疏”、“中等密集”和“密集”3种籽粒离散度等级下模型检测结果热力图,由图12可知,Faster R-CNN模型识别效果最差,由于其仅关注籽粒中心局部特征,对大部分籽粒轮廓识别不完整,且在图中黄色圆圈标注位置,存在大量密集堆积籽粒的漏检情况。YOLO v5模型对籽粒识别注意力范围较广,对于密集籽粒注意力低,导致该模型在不同离散度等级下的识别泛化性能弱。YOLO v7模型对图像背景和目标的区分度更高,识别效果明显优于YOLO v5;相较于YOLO v7,YOLO v7-ST的Swin Transformer检测头对全局特征以及被遮挡目标具有更强的检测能力,如图中红色圆圈标注位置,该部分热力图颜色更深,表明YOLO v7-ST更能关注到边缘籽粒和遮挡籽粒等检测难点,在4种模型中有最高的识别准确率。 图12 不同模型检测结果热力图Fig.12 Heat map of test results for different models (1)基于电磁振动原理设计了小麦籽粒振动分离装置,通过籽粒受力分析,研究了振动频率、振幅、输送倾角和摩擦因数对籽粒离散程度的影响,并基于多因素正交试验方案建立了不同籽粒离散度的试验样本集。引入二阶离散系数评价方法,结合图像处理结果和籽粒分布特征将籽粒离散度划分为“稀疏”、“中等密集”和“密集”等级。 (2)提出了一种YOLO v7-ST网络模型的高通量小麦籽粒计数方法,并对不同离散度等级试验样本进行了测试,试验结果表明,YOLO v7-ST模型对“稀疏”、“中等密集”和“密集”籽粒的平均计数准确率分别为99.93%、99.80%和97.74%,总平均值为99.16%;模型综合评价指标F1值分别为95%、94%和90%,总平均值为93%;平均计数时间分别为1.23、1.19、1.15 s,总平均值为1.19 s,模型检测精度和效率能满足小麦室内考种的检测需求。 (3)为验证本文模型的优越性,与常用的目标检测模型以及其他注意力机制算法进行了对比。籽粒“稀疏”等级时,本文模型的MCA与YOLO v7和YOLO v5结果相近,相比Faster R-CNN提高3.63个百分点;“中等密集”等级时,本文模型的MCA相较于YOLO v7、YOLO v5和Faster R-CNN分别提高0.76、1.03、12.67个百分点,随籽粒离散度等级为“密集”时,MCA进一步提高2.35、5.94、30.01个百分点,此外,本文模型的F1值分别提高4、8、28个百分点。由此可见,随离散度等级变化,YOLO v7-ST模型的检测精度更高,针对不同离散度等级的泛化能力更强。YOLO v7结合不同的注意力机制时,Swin Transformer的多头注意力机制也比其他通道注意力、空间注意力和自注意力的检测准确率更高。本文模型的MCT与YOLO v7相近,比YOLO v5和Faster R-CNN模型快0.4 s左右。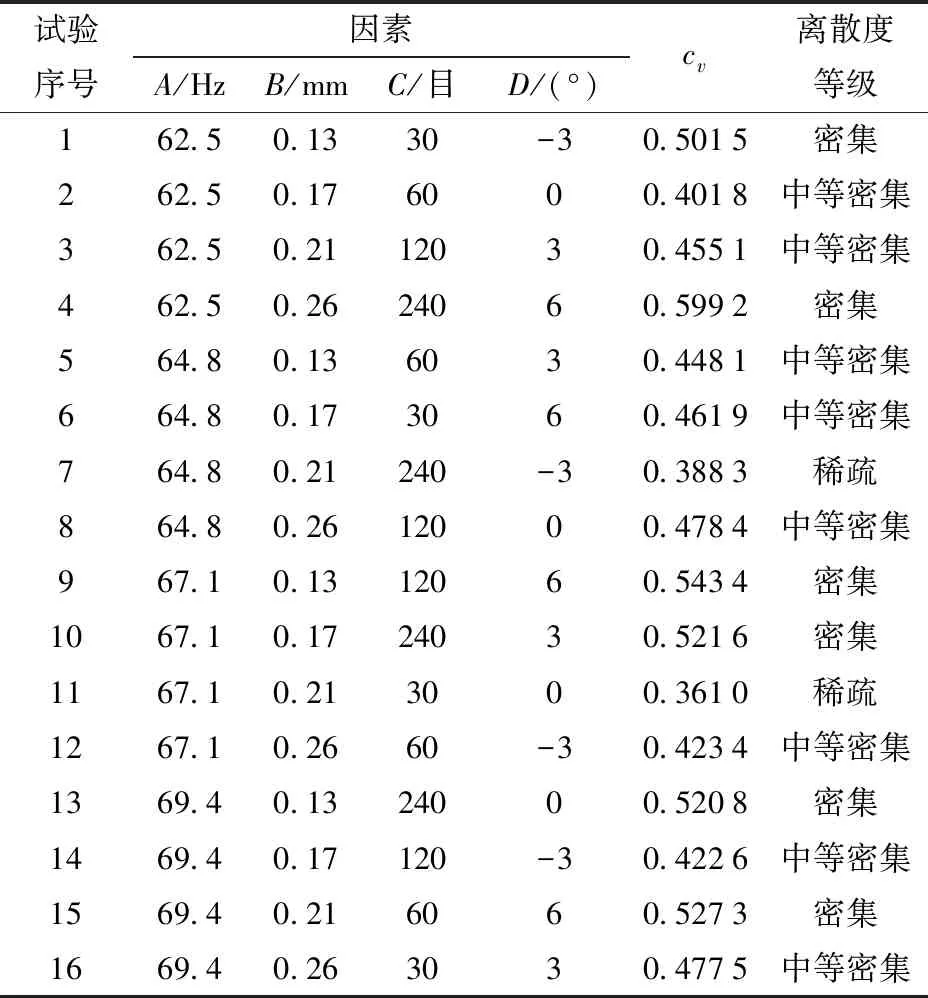
2 小麦籽粒计数算法设计
2.1 数据集构建

2.2 YOLO v7-ST网络模型
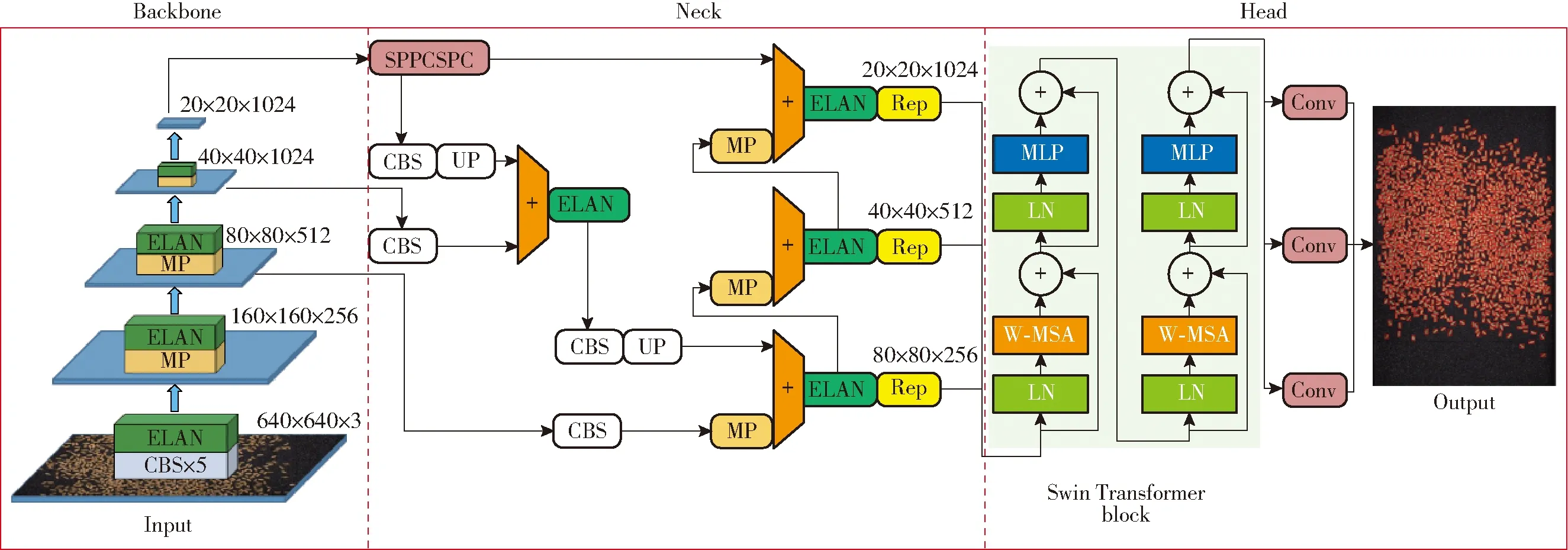
2.3 模型训练及后处理

3 结果与分析
3.1 预测结果分析

3.2 不同网络模型预测结果对比

3.3 不同注意力机制预测结果对比

4 结论
