一种区块链支持的联邦学习认知模型
2023-11-22袁媛,袁松
袁 媛,袁 松
(1.武汉体育学院 体育工程与信息技术学院,湖北 武汉 430079;2.杭州电子科技大学 电子信息学院,浙江 杭州 310018)
0 引 言
认知计算[1]是一种模拟人脑的新型智能技术,通过数据驱动建立具有推理、感知和响应的精准模型,对智能制造起到了重要作用。在智能制造场景下,引入联邦学习[2](Federal Learning,FL)方法作为认知计算的学习框架,是实现数据隐私保护和安全的有效方法,其基本思想是以制造数据为驱动,将训练数据模型分配于多个设备上运行,当每轮训练结束后参数服务器收集设备节点的局部模型参数执行聚合,并将更新后的全局模型参数返回给各设备继续迭代训练至模型收敛。但这种通过中心化聚合的方法主要存在2个问题:(1)容易受到恶意攻击行为截获或篡改聚合的中间参数(如:推理攻击[3]、链接攻击[4]、投毒攻击[5]等行为);(2)中心服务器与节点的远程通信容易产生隐私泄露的风险(如:设备节点互信[6]、虚假贡献度[7]、单点失效[8]等问题)。
区块链以其去中心化的特征,使智能认知计算服务器形成一个不可篡改的分布式账本[9],可以针对恶意攻击行为实施有效防御。国内外一些专家学者结合区块链与联邦学习的方法提出了相关模型方法,以解决数据保护和可信计算问题,大部分采用全局模型更新方法和共识算法。其中,全局模型更新方法将分散的联邦学习数据以链路形式连接为一个不可篡改的分布式账本,以确保数据的安全性,如文献[10]设计的点对点网络联邦学习的区块链(FLChain),文献[11]提出的基于智能合约技术支持联邦学习的模型聚合和参数更新方法。但此类方法的局限性在于其数据均以默克尔帕特里夏树(Merkel Patricia Tree,MPT)形式进行存储,并不断计算分散的联邦学习多个空间块,会使模型信息损失较大;共识算法采用工作量证明共识算法维护模型的一致性问题,如文献[12]以分布式哈希表存储数据区块,在雾计算环境下构建的区块链支持联邦学习框架;文献[13]利用深度Q学习,在数据共享上部署联邦学习和区块链,达到物联网场景下的模型共识。但此类方法的局限性在于忽略了矿工挖矿难度对工作量证明的影响,当攻击者哈希率变化对数据影响较大,抗攻击能力较难快速收敛稳定,从而影响数据认知驱动性能和抗攻击能力。
基于上述问题,该文提出了一种区块链支持的联邦学习认知模型(Federal-Block for Data to Cognitive,FB_DC)。其主要贡献和创新:(1)将中心化的参数服务器构建为去中心化的参数聚合器,通过区块链的共识算法构建激励机制和交叉验证机制,生成区块链支持的联邦学习数据驱动认知;(2)利用改进马尔可夫决策过程完成模型聚合实现全局更新的最优策略,并提出Q强化学习方法支持联邦学习的认知计算。旨在提高物联网数据驱动认知性能和抗攻击力,实现数据隐私保护和安全。
1 模型架构
1.1 总体设计
结合项目研究工作,区块链支持的联邦学习数据驱动认知计算框架如图1所示。描述了区块链支持的联邦学习(FB_DC)框架,分为区块链和联邦学习2个部分。其中,区块链作为底层逻辑基础,将智能制造环境下的物联网数据通过基于工作量证明(Proof of Work,PoW)的共识算法分散联邦学习;联邦学习方法用于实现认知计算。
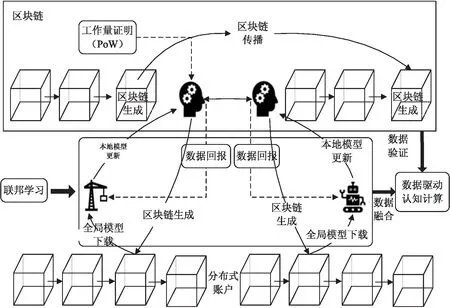
图1 区块链支持的联邦学习数据驱动 认知计算框架
设联邦学习的认知计算由N个设备节点组成,定义为Vi(i=1,2,…,V)。每个设备(Vi)存储了本地数据标签(LDi),所有本地数据遵循独立且相同的分布。由于该文利用区块链来实现分散的联邦学习,在每轮训练中,专用的中央服务器被临时聚合器取代,聚合器和局部设备共同维护相同的学习模型,以实现高性能认知计算能力。每个设备(Vi)通过训练本地数据来维护其本地模型,将模型参数发送至相关的矿工(Mi),所选用的矿工来自矿工群(M={M1,M2,…,MN})。如果矿工数量与设备数量相同,则|M|=|V|,否则|M|<|V|。被选用的矿工(Mi)及其相关设备(Vi)作为聚合器,并根据所有局部模型参数训练全局模型参数。全局模型参数存储于区块后广播至整个网络,并使用更新后的全局参数重新写入所有局部模型。
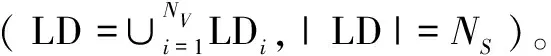
(1)

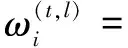
∇f(ω(l))}
(2)
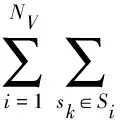
(3)
迭代过程的约束取决于认知计算的精度,采用常数ε表示为约束指数,满足当ω(L)-ω(L-1)≤ε时确定全局参数。
1.2 区块链结构

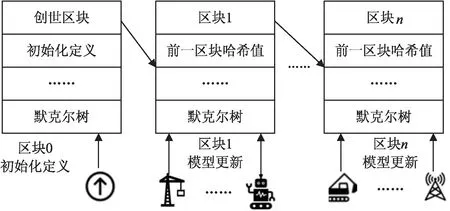
图2 区块链结构
1.3 数据驱动认知算法

算法1:区块链支持的联邦学习数据驱动认知算法
输入:设备节点(Vi)和矿工(Mi)
输出:认知计算模型
1.初始化参数Pks
2.while new LD do
3.Vi训练局部模型;
4. UploadPkstoMi; //上传Pks到Mi
5.Mi进行交叉验证;
6. ifMi找到临时bithen
7. 各方链接bi到局部分类账本中
8. end if
9.获胜的Mw←Mi广播bi//Mw为获胜矿工
10.Mw训练全局模型GM
11. GM中的Pks→Vis
12.end while
2 模型聚合方法
2.1 马尔可夫决策过程
在智能制造的物联网场景中,区块链节点收到训练设备节点的局部模型后进行模型聚合,而现有的聚合方法主要通过联邦平均的方法完成聚合[17](Federal Average,FA)。这种方法未考虑低质量的局部模型会对全局模型聚合的影响。为使FB_DC的准确性和安全性得到优化,引入马尔可夫决策过程(Markov Decision Process,MDP)对每轮聚合器的选择进行建模。MDP是1个在多个有限时间内进行的游戏,该游戏受概率状态转换约束,以1个聚合器和1个攻击者场景为例,MDP表示为六元组模型{S,A1,A2,R1,R2,Pr}。其中,S为状态空间,A1为聚合器行为,A2为攻击者行为,R1,R2:S1×S2×A1×A2→R分别为聚合器和攻击者的回报函数,Pr:S1×S2×A1×A2→δ(S)表示状态转移概率,δ(S)为系统状态(S)上一组概率分布。
2.2 聚合器与攻击者行为

(4)
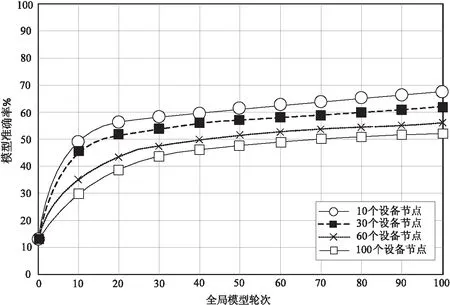
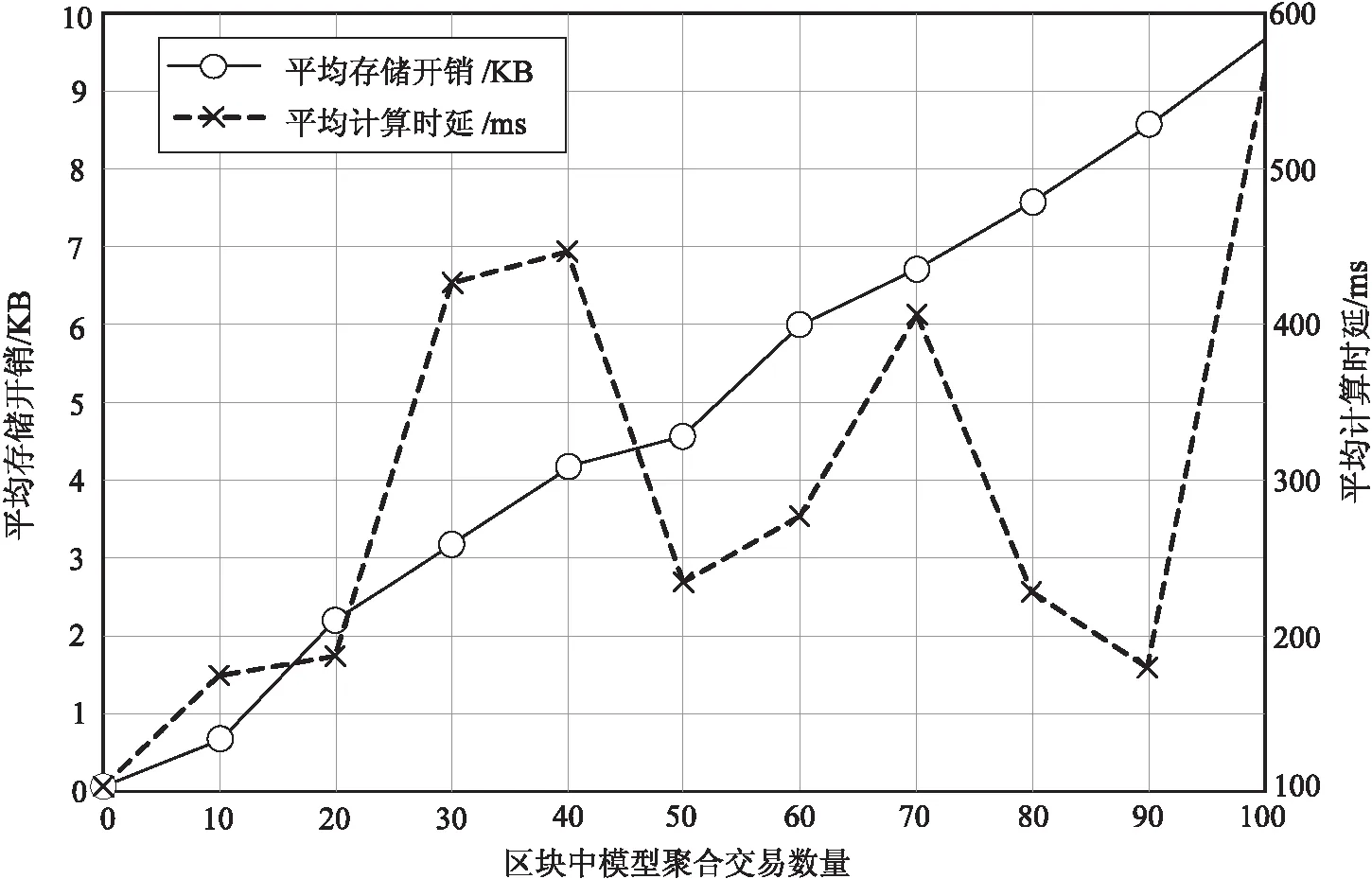
式中,Ψ为攻击者最大计算能力,当Ψ≥t时,攻击者能够分析所有全局更新,当Ψ 在这种情况下,一方面,聚合器充当临时中央服务器,并将全局更新广播至所有终端设备,聚合器的全局更新通过区块链发布,取决于当前系统状态。聚合器只能根据上一次攻击的输出来估计攻击者的行为,而上一次攻击的输出由聚合器识别,最后一次攻击的输出指示攻击者是否成功发起攻击并将伪造数据注入其中。另一方面,当前系统状态为马尔可夫决策过程的最后一个系统状态时,如果聚合器识别出远离收敛的显著反向趋势,它可以相对确定这一轮是否存在攻击行为,以确定区块链存储所有全局更新的记录,尤其是受到攻击的更新记录。在t阶段使用ARt作为攻击输出,如果ARt=1,则攻击成功;如果ARt=0,则攻击失败。总而言之,聚合器当前的操作取决于这一轮的全局更新和上一轮攻击的输出,其系统状态定义为: St={GUt,ARt} (5) 式中,GUt表示t时刻全局更新,状态St的不确定性源于GUt的不确定性,而系统状态取决于双方行为,攻击结果(ARt)由行为决定。基于这种依赖关系,将状态转换表述为: (6) (7) (8) 为使马尔可夫决策过程最终收敛稳定,提出一种改进Q-强化学习方法,通过减少基数来降低计算复杂度,用于推导聚合器和攻击者的最优策略,如算法2所示。 算法2:Q-强化学习算法 输入:Au,Aad, S, R; 输出:最优策略(τ*); 1.t=0, ARt=0=0 2.初始化{τu,τad}; 3.while Convergence not reached do //循环直到收敛 5. 更新输出攻击ARt+1 8. 使用区块链的聚合器选择 9.end while 结合项目研究场景,以武汉市某小规模的柔性车间生产为例,所提的模型会将物联网数据需求回报为全局数据更新。在物联网场景中搭建了简易的实验环境为Intel(R)Core(TM)I7-5300 CPU 2.5 Hz 8 GB RAM Windows 10,代码主要基于Python V3.3/PyTorch V0.4实现联邦学习认知计算。测试数据集选用CIFAR-10[20],包含50 000个训练样本和10 000个测试样本,从模型评估、服务性能和抗攻击能力3个方面评估FB_DC的有效性。采用卷积神经网络[21](Convolutional Neural Networks,CNN)迭代训练全局模型,使用基于MDP的聚合算法实现全局模型更新。 采用CNN测试训练FB_DC,设卷积步长核大小为3×3,步长为1,激活函数为ReLU。如图3所示,采用损失值和精准率2种评估指标,分别评估FB_DC全局模型的训练损失(Loss)和训练准确率(Accuracy),其中损失值用于评估模型训练中的收敛情况,并通过优化损失率提高模型的预测能力;精准率用于判断模型中所有测试数据的准确率。当设备节点数量从10个增加至100个时,随着迭代轮次增加FB_DC训练损失量逐渐降低、准确率逐步提高。这是由于FB_DC将中心化的参数服务器构建为去中心化的参数聚合链,通过共识算法进行验证,并利用马尔可夫决策过程进行模型聚合,得到最优策略,返回各设备节点进行本地模型更新,从而降低训练损失误差,提高模型聚合的准确率。 (b)CNN测试准确率图3 CNN在不同设备节点数的训练损失与准确率 图4 CNN模型准确率误差比较 为进一步描述在受到投毒攻击时FB_DC的MDP的有效性,与联邦平均聚合算法(FA[17])进行比较。如图4所示,当恶意节点数=10、区块生成率(λ)=0.2时,在100次模型聚合下FB_DC的准确率比FA的准确率平均高10%以上。同时,所提出的基于马尔可夫的模型聚合算法可以在支付函数中采用信息熵导出的全局更新(GUt)的训练损失。 主要评估区块链模型聚合服务所需的平均存储开销和收敛时延,基于Python Flask框架实现区块链服务,在区块链中设每个区块存储10次模型聚合交易。首先,将区块模型聚合服务部署于区块链上,开放多个端口模拟设备节点的区块链网络;然后,采用基于马尔可夫过程的策略进行记账,矿工挖矿难度根据每个设备节点挖矿难度动态调整;最终在区块中聚合模型交易数量从10增加至100。 (a)区块链中模型聚合交易数量对模型性能的影响 所需平均存储开销和平均计算时延变化如图5(a)所示。随着聚合交易数量的增加,其通信开销明显增加,这是由于马尔可夫决策过程使聚合器和攻击者始终遵循最佳策略,使各节点消耗了更多的聚合模型参数,使平均开销呈线性增长。图5(b)分析了挖矿难度对文中聚合模型的影响,设备节点的挖矿难度由1增加至10,区块链存储开销呈线性增长趋势。这是由于FB_DC在MDP中设置了支付函数,并采用Q强化学习方法使行为和状态相关的平均累积回报近似。 为说明FB_DC的抗攻击能力,将FB_DC与独立使用区块链和联邦学习的方法进行了比较。如图6所示,随着攻击者的哈希值增加数据动荡的情况,FB_DC在数据动荡幅度上均低于联邦学习方法和区块链方法。这是由于FB_DC提供了激励机制和交叉验证机制,采用PoW作为共识性算法,提高了分散联邦学习系统的可靠性。 图6 攻击者哈希率变化对数据动荡的影响 该文提出了一种区块链支持的联邦学习认知模型(FB_DC)。主要成果是在智能制造物联网场景中生成区块链支持的联邦学习数据驱动认知,并提出模型聚合实现全局更新的最优策略和Q强化学习方法,通过全局模型评估、服务性能分析、抗攻击能力等实验验证其有效性,目的是提高物联网数据驱动认知性能和抗攻击力,实现数据隐私保护和安全。但该文的局限在于现有区块链性能与联邦学习算法的融合较难适应大规模的数据,下一步在保护物联网数据的前提下,提高联邦学习的训练效率和准确率仍然是一个值得深入研究的课题,需要进一步探索研究。2.3 系统状态

2.4 交易支付



2.5 Q强化学习方法


3 实验结果与分析
3.1 全局模型评估

3.2 服务性能分析
3.3 抗攻击能力

4 结束语
