基于深度学习的红外目标检测综述
2023-11-22李允臣王家宝
张 睿,李允臣,王家宝,李 阳,苗 壮
(陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引 言
目标检测是指获得图像或视频中物体的位置坐标,并判断其类别。红外目标检测是目标检测的一个重要分支,在自动驾驶、安防监控、军事侦察等领域都有广泛的应用。尤其是在军事领域,红外目标检测可用于对武装人员、军事车辆等各类目标进行侦察监视,有着非常重要的军事价值。
2014年以来,基于深度学习的目标检测算法通过构建复杂的神经网络,并运用反向传播算法更新网络参数,自动高效地提取物体的复杂特征,在目标检测领域取得了巨大成功。基于深度学习的目标检测算法通常可分为两阶段目标检测算法和单阶段目标检测算法。两阶段目标检测的代表算法主要有R-CNN(Region-based Convolutional Neural Network)系列,包括:R-CNN[1]、Fast R-CNN[2]、Faster R-CNN[3]、FPN[4]、Cascade R-CNN[5]等。其检测流程为先将图像输入神经网络提取特征,再采用一定算法生成大量候选区域并筛选,然后对筛选的区域内可能包含的目标进行分类和定位,如图1(a)所示。两阶段检测算法精度较高,但速度较慢。为了提高检测速度,出现了以YOLO(You Only Look Once)系列[6-13]和SSD(Single Shot multi-box Detector)系列[14-15]为代表的单阶段目标检测算法。单阶段目标检测算法省去了候选区域生成阶段,用神经网络对图像提取特征后,直接通过回归分析得到目标的类别和位置坐标,如图1(b)所示。单阶段目标检测算法精度虽然略低于两阶段目标检测算法,但具有明显的速度优势,可进行实时检测。

(a)两阶段目标检测算法

(b)单阶段目标检测算法图1 基于深度学习的目标检测算法
上述深度学习算法最初均应用于可见光领域。近年来,人们开始将深度学习算法引入红外目标检测领域,并取得了不少成果。虽然在可见光目标检测领域,已有较多文章对深度学习目标检测算法进行了系统综述,但在红外目标检测领域,相关综述还比较缺乏。因此,该文主要围绕针对红外目标的深度学习检测算法研究进展进行综述,以促进红外目标检测技术的发展。
1 红外目标检测面临的困难和挑战
红外图像是由红外成像设备通过测量物体向外辐射的热红外线得到的,与可见光图像的成像原理差异较大。受红外图像的成像机制影响,红外目标检测面临的困难和挑战主要有五个方面:
(1)数据集资源缺乏。由于红外成像设备价格较为昂贵,且红外图像数据集大多用于特殊领域,导致研究者可获取的红外图像数据集资源较少。近年来,虽然有一些红外目标检测数据集公开发布,但数据规模与可见光数据集相比,差距还很大。
(2)背景干扰大。在城市环境中,背景热源多,红外目标与背景热源难以区分,而在野外环境中,树木植被的红外影像较为杂乱,红外目标的形状轮廓等特征易被破坏,红外目标很容易淹没在背景中而难以辨别。
(3)图像分辨率低。可见光成像设备大多采用高清摄像头,拍摄的可见光图像分辨率较高。而红外图像的分辨率一般在640×512像素甚至更低,导致红外目标的像素分辨率较低,占有的像素面积小,可利用的目标特征少。
(4)纹理细节不足。由于红外图像类似于灰度图,缺乏颜色信息,且物体的温度分布大多是渐变的,导致红外目标纹理细节信息不足,成像较模糊。
(5)弱小目标检测难。在高空或远距离拍摄条件下,红外目标尺寸非常小,有时呈现为点状或斑点状,不仅缺乏颜色、纹理信息,还缺乏形状信息,特征信息极少,导致漏检及虚警率较高。
2 红外目标检测研究改进方向
基于深度学习的目标检测算法在诞生之初主要用于可见光目标检测,而红外目标与可见光目标成像差异较大,因此,相应的深度学习检测算法并不完全适用。所以,在将可见光领域深度学习目标检测算法用于红外目标检测时,应针对红外数据集和红外目标特点进行改进。
2.1 数据增强
深度学习方法高度依赖大规模数据集,而红外数据集规模一般较小,可供训练的目标样本少。对此,可进行数据增强处理,通过水平/垂直翻转、旋转、缩放、随机裁剪、改变对比度、增加噪声干扰、图像混合和利用GAN生成伪红外图像等方法,设法增加图像数量和目标样本数量。
赵晓枫等[16]、Zhang X X等[17]在自建的小规模红外目标数据集上,采用旋转、裁剪、改变对比度等方法来扩充样本数量。李北明等[18]则引入Mosaic和Copy-paste两种方法进行数据增强。Mosaic数据增强是使用多张图片经过随机裁剪、缩放,拼接在一起,Copy-paste数据增强则是将原图中的目标经过随机尺度的缩放后,重新粘贴到图像的任意位置,两种方法均可有效增加训练样本数量。吴晗等[19]则尝试使用CycleGAN通过风格迁移生成伪红外图像,并在CycleGAN中添加了通道和空间注意力,从而实现了红外数据样本的有效扩充。但基于GAN的图像生成方法,还存在模型崩塌的问题,训练较为困难,且生成的伪红外图像与真实红外图像存在一定差异。
数据增强的方法虽然可提升网络模型的泛化能力和鲁棒性,但可能改变数据的真实分布,引入数据噪声,造成目标的误检。
2.2 迁移学习
对于规模较小的红外数据集,即使经过数据增强,可能仍然无法满足复杂的神经网络对大量训练数据的需求。对此,可采用迁移学习的方法来进一步弥补训练数据的不足,提高模型的泛化能力和检测精度。
迁移学习是将其他领域的知识转移到新的领域的一种方法。通过将模型在大规模的数据集上预训练,使模型具备一定的先验知识,而后将预训练模型在其他领域的数据集上进行再学习,进一步调整网络参数达到最优,即可使模型适应新的任务。Zhang X X等先在大规模的航拍可见光车辆数据集上进行预训练,然后将预训练模型在航拍红外车辆数据集上进行再训练。由于所利用的数据均为航拍车辆数据,目标相似度较高,取得了较好的检测效果。王悦行等[20]利用计算机仿真生成大量的边缘、轮廓、纹理等特征相似的仿真红外舰船,然后利用特征自适应迁移学习方法,实现从仿真红外舰船到真实红外舰船的跨域知识迁移。李维鹏等[21]在利用大规模的可见光数据集预训练的基础上,还进一步利用大量的未标注红外图像对网络进行半监督学习调优,并提出了特征相似度加权的伪监督损失函数,从而更充分地利用了未标注红外图像数据。
迁移学习的方法能够利用其他领域的数据,辅助提升模型在红外领域的检测性能。但在将其他领域的数据知识迁移到红外领域时,需要考虑跨域知识的匹配问题,否则,可能将错误的知识引入模型,给模型带来不确定性。
2.3 视觉注意力机制
针对红外目标特征较弱且背景干扰大的问题,引入视觉注意力机制,可较好抑制背景噪声干扰。同时,注意力机制还能在一定程度上弥补数据样本的不足,即使只有少量的数据样本,也能提取到有效的红外目标特征。
人类视觉在观察整幅图像时,会将注意力聚焦于某些关键目标区域,而忽略大部分背景区域。深度学习中的注意力机制通过模仿人类视觉,将重要的通道或位置区域赋予更大的权重,从而获得通道或空间位置注意力,相关注意力模块如图2所示。
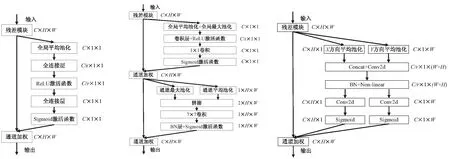
Hu J等[22]提出SE(Squeeze and Excitation)注意力模块,也称通道注意力模块,如图2(a)所示。其通过全局平均池化将特征图压缩,并通过全连接层和激活函数学习得到不同特征通道的权重,再对各通道加权,从而增强有效通道的信息。李向荣等[23]在YOLOv4的特征金字塔融合过程中加入SE模块,来增加有效特征通道的融合比重。代牮等[24]则在YOLOv5的骨干网中添加SE模块,在特征提取过程中抑制森林等复杂背景对红外弱小目标的干扰。
SE注意力模块只考虑了通道的重要程度,没有考虑空间位置的重要程度,而位置信息是捕获目标结构的关键。Woo S等[25]提出CBAM模块(Convolutional Block Attention Module),如图2(b)所示。其在通道注意力中增加了一个并行的最大池化层,进一步增强了通道注意力,而后在通道维度进行最大池化和平均池化压缩,从而获得空间注意力信息。陈皋等[26]在YOLOv3骨干网DarkNet-53中加入CBAM模块,在仅使用小规模红外数据集训练的情况下,检测精度超过了大规模数据预训练的模型。Du S J等[27]将CBAM中的7×7普通卷积改为空洞卷积,设计了Dilated CBAM,减少了对目标纹理细节的依赖。
(a)SE注意力模块 (b)CBAM注意力模块 (c)CA注意力模块
Hou Q B等[28]认为CBAM模块无法获得长程依赖关系,于是将通道注意力分解为水平和垂直注意力,并沿两个方向获取特征图的远程依赖关系,将空间坐标信息整合到通道注意力中,得到坐标注意力(Coordinate Attention)。胡焱等[29]在YOLOv5s中特征信息丰富的Dark5阶段引入坐标注意力模块,对低分辨率的红外行人目标检测取得较好效果。
除以上注意力机制外,杨其利等[30]模仿人类视觉,采用滑动窗口对图像进行扫描采样,以缓解弱小点状红外目标检测中的正负样本不平衡问题。杨子轩等[31]提出解耦注意力机制(Factor Decoupled Attention),其先通过分子因解机获取全局通道注意力,再通过局部平均池化和局部最大池化获取更细粒度的局部注意力,最后通过多尺度卷积获取不同感受野的空间注意力。FDA方法通过将全局和局部注意力机制融合,对红外弱小目标检测效果较好。
相关注意力模块可灵活嵌入网络模型中,对提升模型性能有较好效果,而且其参数量和计算量成本也不大,性价比较高。但在模型不同位置,注意力模块带来的性能提升并不相同,有时效果提升并不明显,还可能降低检测速度。
2.4 多尺度特征融合
由于红外图像本身分辨率低,红外弱小目标特征少,而且神经网络在提取特征的过程中,还会对图像不断进行下采样处理,导致目标信息出现丢失,给红外弱小目标检测带来不利影响。对此,采用多尺度特征融合的方法,可以有效增强红外弱小目标的特征,提高对弱小红外目标的检测精度。
多尺度特征融合方法可分为两类:一是将网络模型不同层次的多尺度特征图进行融合。在深度神经网络中,深层次的特征图包含丰富的全局语义信息,而浅层次的特征图包含丰富的局部细节信息。通过将深层与浅层的特征图融合,可兼顾获取目标的全局语义信息和局部细节信息。二是在网络同一层次中构建具有多感受野的多分支结构,提取目标的不同尺度的局部特征,然后将多尺度特征进行融合,从而更全面地捕获目标特征。
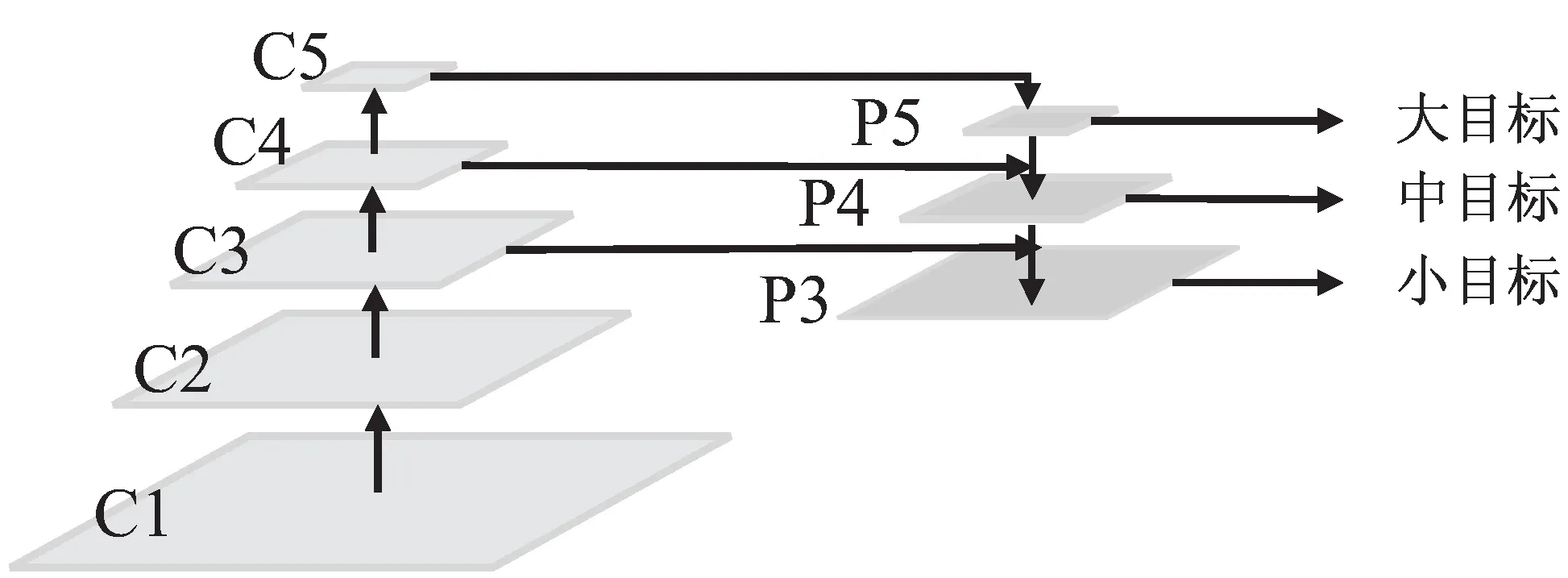
图3 特征金字塔网络

图4 路径聚合金字塔
Lin T Y等提出特征金字塔网络FPN(Feature Pyramid Network),如图3所示。其将深层特征图自上而下逐层上采样后与浅层特征图融合,并在高分辨率的浅层特征图上检测小目标,有效提高了小目标的检测精度。Liu S等[32]提出路径聚合网络PANet(Path Aggregation Network),其在FPN自上而下融合的基础上,增加了自下而上的融合路径,将底层的细节位置信息进一步传至上层特征图。YOLOv4借鉴PANet结构,设计了PAFPN(Path Aggregation Feature Pyramid Network)结构,如图4所示。刘杨帆等[33]、林健等[34]进一步将金字塔层数扩展为4层,以检测红外弱小目标。舒朗等[35]将特征金字塔中的残差连接改为DenseNet式的密集连接,以保留更丰富的特征信息。朱子健等[36]则将特征金字塔的上采样操作改为反卷积,以更好地还原红外弱小目标的细节特征。盛大俊等[37]针对红外装甲车辆边缘轮廓较清晰的特点,设计了语义特征提取模块、上下文聚合模块、边缘感知融合模块,对特征金字塔的多尺度特征进一步融合,以提取装甲车辆的轮廓细节信息和边缘语义信息。
Liu S T等[38]通过采用不同尺寸的卷积核和不同膨胀系数的空洞卷积构成多分支结构,提出感受野网络RFBNet(Receptive Field Block Net),如图5所示,有效增强了网络的特征提取能力。顾燕等[39]在Faster R-CNN骨干网中使用膨胀系数为1、2、3的空洞卷积,从而获得3×3、5×5、7×7三种不同大小的感受野。朱子健等在YOLOv3骨干网的残差模块中并行添加一个3×3最大池化分支和一个1×1卷积分支,提出了PaRNet(Parallel Residual Network)。蒋昕昊等[40]则在特征金字塔融合之后引入RFB模块,并减少膨胀系数,以适应红外弱小目标检测任务。高凡等[41]则借鉴Inception网络的多分支结构,设计了PMFPSNet(Parallel Multi Feature Path Network)。楼哲航等[42]将YOLOX的骨干网改为Swin Transformer,以获取全局感受野特征,并在颈部和检测头采用卷积模块提取局部特征,通过融合全局和局部特征,对红外小目标检测取得较好效果。

图5 感受野网络
多尺度特征融合的方法,虽然能够有效增强红外弱小目标特征,提高检测精度,但多层金字塔结构和多分支结构都会增加模型的参数量和计算量,降低训练和推理速度。
2.5 多模态图像融合
红外目标受红外成像机制的制约,其本身的特征信息不足。对此,通过融合可见光图像或其他模态图像,利用不同模态图像的互补信息增强红外目标的特征,可使红外目标检测更加准确可靠。

图6 双分支融合检测网络
Geng K K等[43]基于Faster R-CNN进行改进,设计了一个由红外分支和可见光分支组成的双分支融合检测网络,如图6所示。其采取特征级的融合方式,将两种模态图像的特征图拼接后,通过卷积模块融合,有效提高了低辨识度条件下的红外目标检测精度。Liu J Y等[44]采用基于GAN的方法,设计了一个目标感知对抗学习网络(TarDAL Network),实现了对红外与可见光图像的自适应融合。该网络由一个生成器、两个目标感知鉴别器以及YOLOv5检测网络组成。其中,生成器用于对红外与可见光图像融合,两个鉴别器分别用来鉴别红外图像的目标信息和可见光图像的纹理信息,实现了红外特征和可见光特征的自适应融合。Sun Y M等[45]基于Faster R-CNN提出了一个由可见光分支、红外分支和融合分支组成的三分支检测网络UA-CMDet。其同时采用特征融合和决策结果融合的方法,同时利用单模态分支和特征融合分支进行检测,并根据检测结果进行联合决策,取得了最优效果。赵明等[46]则采用基于CycleGAN的方法,先利用红外图像生成伪可见光图像,再对红外和伪可见光图像分别提取特征,并构建特征金字塔,而后对特征金字塔进行加权融合,在自动驾驶红外目标检测上取得了较好效果。赵兴科等[47]则利用BASNet生成红外图像的显著图,再将显著图与红外图像融合。由于显著图有较清晰的边界,融合后的图像使红外目标更加清晰,对复杂背景环境下的红外目标检测效果较好。
多模态图像融合的方法,能够有效弥补红外图像特征信息的不足,但成对的多模态数据集的采集、筛选、标注等工作量大,数据资源获取成本较高。同时,多模态图像融合检测网络一般由多个单模态检测网络构成,整体参数量和计算量较大,检测速度较慢,在实际应用时存在一定局限性。
2.6 轻量化改进
深度神经网络虽然性能优异,但其模型复杂,参数量、计算量大。为了将红外目标检测模型部署在资源受限的移动端,就必须对模型进行轻量化改进。目前,研究者主要是借鉴MobileNet[48]、EfficientNet[49]、GhostNet[50]等轻量级网络的设计方法,设法减少网络深度和模型大小。
针对航拍红外车辆实时检测任务,Liu X F等[51]基于YOLOv3进行改进,除最大池化下采样层外,Dark 1/2/3/4只保留1层卷积,Dark 5保留5层卷积,将53层的DarkNet压缩为只有15层的极简模型。秦鹏等[52]用EfficientNet代替YOLOv3骨干网,提出Effi-YOLOv3模型,其在FLIR数据集上的检测精度超过了YOLOv3,而参数量仅为YOLOv3的1/3。李北明等则用GhostNet代替YOLOv5的骨干网,并运用特征知识蒸馏的方法,使用Scaled-YOLOv4[53]指导该网络学习。其仅有1.9 M的参数量,但在红外数据集上的精度和速度都超过了YOLOv5-s模型。赵兴科等借鉴MobileNetv2网络,提出了轻量的YOLOv3-MobileNetv2模型。
目前,相关轻量化改进方法虽然减小了模型规模,提高了检测速度,但在模型精度和泛化能力上,与大模型仍有一定差距。
3 红外目标检测数据集
现有的目标检测数据集多为可见光图像数据集,例如PASCAL VOC数据集、MS-COCO数据集、UA-DETRAC数据集等,而红外数据集资源相对较少,制约了红外目标检测的研究开展。为便于其他研究者开展研究,现将可公开获取的红外目标检测数据集资源梳理汇总如下,如表1所示。
(1)OSU Thermal Pedestrian Database[54]:是美国俄亥俄州立大学制作的道路监控红外行人检测数据集。
(2)VEDAI[55]:是卫星航拍目标检测数据集,提供了512×512和1 024×1 024两种分辨率的图像。
(3)KAIST[56]:是韩国科学技术高级研究院下属实验室制作的自动驾驶红外行人检测数据集。
(4)CVC-14[57]:是西班牙巴塞罗那自治大学发布的道路红外行人检测数据集。
(5)SCUT FIR Pedestrian Dataset[58]:是由华南理工大学制作的夜间道路行人检测数据集。
(6)FLIR ADAS:是由生产红外热成像仪系统的FLIR SYSTEMS公司制作的夜间道路红外目标数据集。
(7)NPU_CS_UAV[51]:是西北工业大学制作的无人机航拍车辆检测数据集。
(8)LLVIP[59]:是北京邮电大学制作的微弱光线条件下的道路行人检测数据集。
(9)Dim-small Aircraft[60]:是国防科技大学制作的小型无人机目标检测数据集。
(10)DroneVehicle[45]:是天津大学制作的无人机航拍车辆检测数据集。
(11)M3FD[44]:是大连理工大学制作的自动驾驶道路目标检测数据集。
4 未来发展方向
基于深度学习的红外目标检测研究虽取得一定进展,但距离满足人们需求仍有差距,未来还有很大的发展空间。结合当前发展现状,就未来发展方向展望如下:
4.1 大规模的红外目标检测数据集基准
深度学习的发展高度依赖大规模数据集,而目前公开的红外目标检测数据集规模还比较小,且种类较少,与可见光领域相比差距还很大,难以支持大型模型的学习训练。因此,从红外目标检测的长远发展来看,建立红外目标检测的大规模数据集基准是必不可少的基础性工作,尤其是在自动驾驶、视频监控、军事侦察等重要应用领域。
4.2 面向特定领域的跨域知识迁移检测方法
在军事等某些特殊领域,获取红外图像的难度较大,可供训练的数据样本比较有限,采用迁移学习的方法可有效弥补数据的不足。但不同领域的数据通常有不同的域知识,如何实现跨域的知识迁移是迁移学习面临的重要问题。因此,寻找不同数据域之间的某些共同特征,以及不同域知识自适应迁移的方法,将是未来应用迁移学习的关键。
4.3 多模态图像融合的红外目标检测方法
多模态图像融合的红外目标检测方法,可有效提高目标检测的准确性和鲁棒性,也是未来的一个重要发展方向。未来可关注以下几个方面:(1)多模态图像的跨域自适应融合。可见光图像虽然可以为红外图像提供互补信息,但当可见光图像质量较差时,如果盲目的融合,可能对检测产生负面影响。未来可基于GAN的方法,或借鉴图像融合领域的一些先进做法,探索多模态图像的自适应融合检测方法。(2)基于GAN的伪多模态图像融合检测。多模态图像数据不仅获取成本较高,而且在军事等特殊领域,获取目标的多模态图像难度较大。对此,基于GAN的方法生成伪多模态图像,而后进行融合检测,有很大的发展潜力。(3)单分支的融合检测网络。多分支的融合检测网络,难以在移动端部署,单分支的融合检测网络在未来更有发展潜力。
4.4 面向终端设备的轻量化红外目标检测模型
在实际应用中,目标检测模型往往需要部署在存储及计算资源受限的边缘终端设备上。目前,模型轻量化研究虽取得一定进展,但检测精度较低,还有很大提升空进。因此,如何在保持较高检测精度的前提下实现红外目标检测模型的轻量化,是未来应用部署的一个重要发展方向。对此,可借鉴可见光领域的轻量化改进方法,例如网络剪枝、参数量化、重参数化方法、知识蒸馏等。
5 结束语
红外目标检测可适应弱光、无光、逆光等复杂光照环境,能够有效弥补可见光目标检测的不足,在民用、军事的诸多领域都有非常重要的应用价值。该文对红外目标检测面临的困难和挑战进行了详细分析,并从数据增强、迁移学习、视觉注意力机制、多尺度特征融合、多模态图像融合和轻量化改进等方面,系统分析了基于深度学习的红外目标检测改进方向。在实际任务中,应根据任务需求和红外数据集特点,灵活采用多种方法,以达到模型大小、精度和速度的均衡。针对红外数据集资源获取困难的问题,对现有的公开数据集资源进行了系统梳理汇总。最后,结合当前发展现状和未来实际需求,对基于深度学习的红外目标检测发展方向进行了展望,可为其他研究者提供参考。
