基于注意力机制的GRU模型的豆粕期货价格预测
2023-11-21石榕
石 榕
(兰州财经大学 统计学院,甘肃 兰州 730020)
豆粕是全球畜牧和鱼类生产的重要投入产物。近些年,世界豆粕消费呈跳跃性的增长,豆粕期货的交易价格也逐渐在金融界被重视,其未来价格预测的准确度变得尤为重要。目前,学者们一直尝试使用基于深度学习的神经网络方法来解决这一时间序列预测问题。相比传统的ARMA 、GARCH 和向量自回归等计量模型,GRU模型构建简单,参数量相对较少,训练速度快,训练准确率高,并且能提高模型的预测准确率,能有效抑制梯度消失或爆炸问题。Kou等[1]开发卷积神经网络(CNN)和门控循环单元(GRU)的联合模型,以预测涡轮机位置的风速。为了提高预测精度,注意力机制也可以通过设置不同的权重来突出重要的信息,Heo等[2]将依赖输入的不确定性概念引入注意力机制,以便它根据给定的输入为每个具有不同程度噪声的特征产生注意力。Hu等[3]指出多阶段注意力网络模型可以有效地学习历史数据中不同时间序列在不同时间阶段对目标序列的影响信息。传统方法无法满足中长期预测任务的要求,往往忽略了时间信息对预测性能的影响。为了解决这个问题,Cao等[4]提出了一种新的深度学习框架,具有残差自注意力机制的时间卷积网络,它可以学习信号的时频和时间信息。在大规模金融时间序列数据上,Yang等[5]为了提高投资技术预测的准确性,提出了一种由股价分形演化特征辅助的技术交易方法,称为FAT。Goo等[6]通过使用增强的遗传算法和人工神经网络模型来比较宏观经济和技术分析之间股票指数的预测效率。技术指标被整合到深度学习和机器学习的方法中,并对交易者的行为进行建模,以提高金融市场方向预测的准确性。张茂军等[7]结合技术指标分析螺纹钢期货的涨跌幅进行量化时交易的影响,通过利用决策树方法值特征选择,构建CLBIL-VSD-CART模型制定交易策略。本文从技术层面分析,利用互信息、相关系数、随机森林树RF模型3种方法相结合筛选出基本行情和技术指标并输入到模型中对豆粕主力合约的未来价格进行预测。在GRU预测模型中加入了注意力机制训练模型,并且突出特征的有效性和重要性,使预测更加精准,为之后的交易提供参考意见。
1 模型构建
1.1 技术指标
技术分析法是将期货市场现在和过去的市场行为作为分析对象,再通过统计方法来设定固定算法,对分析对象找到价格波动规律,来判断期货价格趋势的技术方法。技术指标不仅能有效地描述股市的变化,而且能为模型的建立提供有效信息。用金融资产的成交量、最高价、最低价等历史交易数据计算技术指标来预测未来价格,常用的金融技术指标分为能量类、运动趋势类、成交量能类、超卖超卖类等,下面介绍几种重要的技术指标:
1.1.1 BIAS
乖离率BIAS属于超卖类指标,由移动平均指标衍生而来,能够表现股票交易收盘价与设定间隔内的移动平均线指标的离散程度。
1.1.2 MOM
动量指标MOM,是一种研究股票价格波动速度的技术指标。股票价格的涨跌幅会随着时间的推移而慢慢减小。
1.1.3 OBV
成交量净额指标OBV,属于成交量类指标,通过数字化股票市场中单只股票每日的需求量与供给关系进行累加,并以累加的结果绘制成趋势曲线,再与股票价格趋势线结合,从选定的股票价格趋势波动与成交量增减的对应关系中判断出在股票交易中关注度高低的一种技术指标。
1.1.4 RSI
RSI是一种研究股票价格波动幅度的技术指标,最早被用于期货交易中。计算一定时间内的涨幅与跌幅的比值,可用来判断行情的变化及预测未来价格的走势。
1.1.5 MACD
平滑异同移动平均线MACD是一个著名指标,基于均线的构造原理。计算一个时间序列中不同时期的两个指数移动平均线的差值,周期较小的移动平均线称为快速移动平均线,周期较大的移动平均线称为慢速移动平均线。指数移动平均线是在MACD线上计算的,称为信号线。当MACD线在信号线之上时,这是时间序列中上升走势动量的指示,当MACD线在信号线之下时,这是时间序列中下降趋势动量的指示。
1.1.6 EXPMA
指数平均数指标或指数平滑移动平均线EXPMA,一种利用率非常高的趋向类指标。该指标在计算中非常重视对当天价格因素的控制,能够及时反映出当前价格走势,克服了如MACD等指标对价格走势的不及时而引起的滞后效应或者是背驰的现象。同时在一定程度中消除了DMA指标在某些时候对于价格走势所产生的信号提前性,在实际操作中是一种非常实用的技术指标。
1.2 门控循环单元(GRU)
GRU网络在处理具有时间属性的数据时,按照时间序列对输入的数据进行权重计算并输出结果。输出结果与目标数据进行对比计算后得出预测误差。在下一次学习时将预测误差输入GRU网络,实现通过预测误差的反向传播对GRU网络中的权重进行更新,达到提高预测精度的目的。GRU模型的神经元主要由更新门zt和复位门rt两个部分组成,GRU预测模型:
(1)
(2)
两个门:
zt=σ(Wzxt+Uzht-1+bz)
(3)
rt=σ(Wrxt+Urht-1+br)
(4)
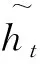
GRU中的门控机制在参数化方面是简单RNN的副本。与这些门相对应的权重也使用时间反向传播随机梯度下降来更新,因为它寻求最小化损失/代价函数,每个参数更新都将涉及有关整个网络状态的信息。因此,所有关于当前输入和之前隐藏状态的信息都反映在最新的状态变量中。
1.3 注意力机制
目前,注意力机制已经成为选择有意义信息以获得更好结果的有效方法。注意力机制把GRU输出的隐层向量表达进行加权求和计算,权重的大小表示每个时间点上的特征重要程度。图1中的输入为加入技术指标后的各组数据的向量表示x1,x2,x3,…,xi,经过GRU模型计算之后会得到对应输出k1,k2,k3,…,ki,然后在隐藏层引入注意力机制,计算各个输入的注意力概率分布值c1,c2,c3,…,ci。注意力机制的计算公式:
v=∑ciki
(5)
ai=witach(Wiki+bi)
(6)
(7)
式中:ai表示第i时刻隐层状态向量ki所决定的注意力概率分布值;wi和Wi表示第i时刻的权重系数矩阵;bi表示第i时刻相应的偏移量。
通过上面的公式可以计算出最后包含文本信息的特征向量v。输出层的输入为上一层注意力层的输出。最后利用softmax 函数对输出层的输入进行相应计算,评估其对输出的影响程度,其计算公式如下:
y=softmax(wiv+bi)
(8)
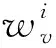
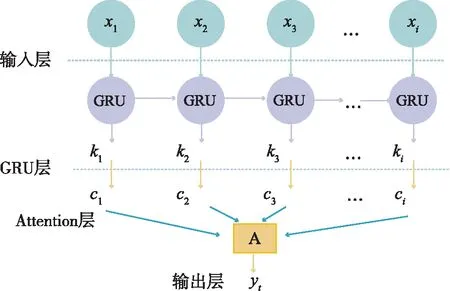
图1 引入注意力机制的GRU模型
2 实证研究
2.1 数据来源及指标评估
选用大连商品交易所中豆粕主力合约在2017.1.10—2022.5.19期间的日度数据作为研究对象,并选取基本行情和技术指标两大类作为预测模型的输入特征。为了检验输入指标的有效性,采用互信息、相关系数、随机森林树RF模型3种方法的结合对所选指标的得分进行评估排序,对筛选指标得分排序可视化如图2所示。
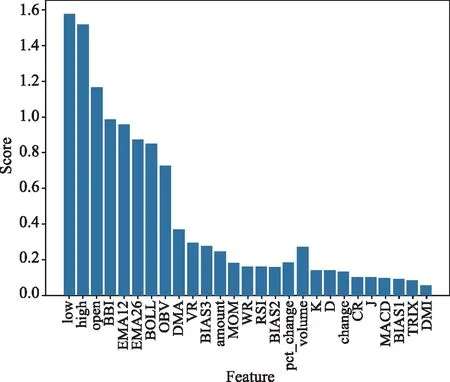
图2 输入特征得分排序
将排好顺序的指标作为输入,并按照7∶3的比例划分为训练集和测试集,为验证引入注意力机制的GRU有效性,基于深度学习框架实现该模型,并与基础模型作对比实验。通过设定相关指标来评估所选的预测模型的有效性,统一选取了R2、MAE、MAPE来评估指标衡量模型性能。
2.2 模型参数设置
选用GRU网络加全连接层,正则化值取0.001,学习率设置为0.005。学习率设置偏大会导致偏离值偏大到后期无法拟合,学习率过小,收敛速度会下降,所以选取不同的学习率并取合适的迭代次数有利于得到较好的预测效果。为了提高预测精度,突出特征指标的有效性,在GRU模型上引入了注意力机制,通过搭建GRU模型设置超参数后加入了注意力机制进行训练。利用注意力机制的特点实现多变量时间序列预测,训练次数由模型误差损失情况来确定的。经过多次训练,最终将复合模型的训练次数设置为500,两层神经元个数统一设置为150,学习率为0.001,滞后期设置为2。
2.3 结果分析
对豆粕主力合约的数据进行描述性统计分析,如表1所示。偏度值都大于0,说明概率分布图右偏。峰度都较小,表示离群值较小,在投资中意味着它是一种低风险的投资。
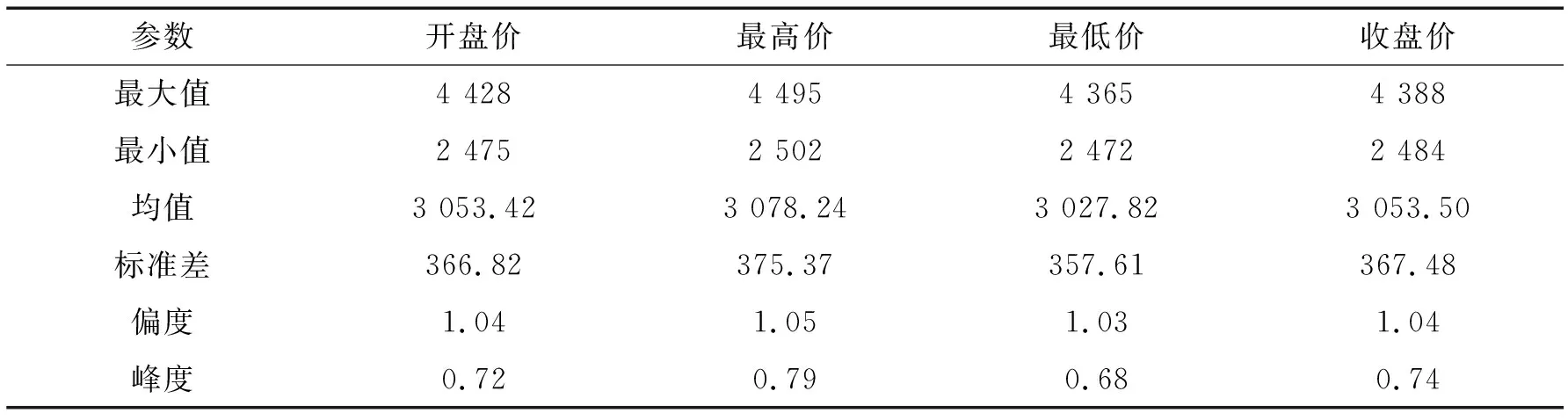
表1 豆粕期货价格指数的描述性统计
通过不断调整到模型最优的参数和结构,旨在获取较优的预测精度,来构造添加注意力机制的GRU模型,Attention-GRU模型输出的预测值与真实值对比如图3所示。为了验证复合模型在预测未来价格上的有效性,将GRU基准模型与Attention-GRU复合模型通过水平指标进行效果评估,引入注意力机制的GRU模型在MAPE、MAE和R2三类指标中结果有所提升且均优于基准模型,如表2所示。引入注意力机制对未来价格预测的精度上有一定作用。
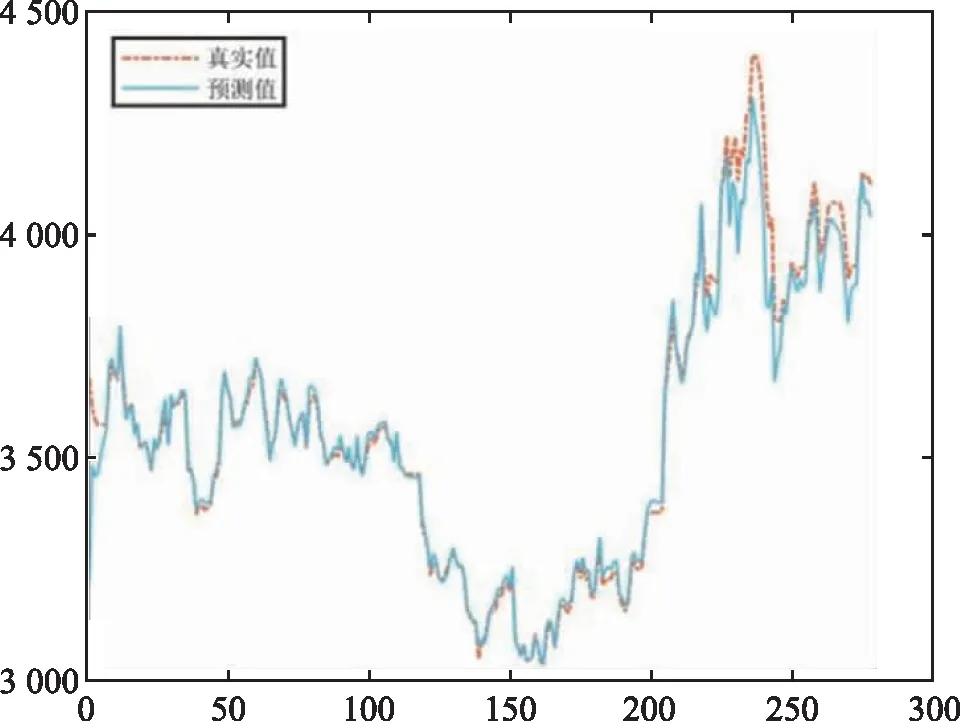
图3 Attention-GRU模型输出的预测值与真实值对比图

表2 模型预测效果比较
3 结 语
针对豆粕主力合约的未来价格进行预测,为了更精准地进行预测,对数据集加入的技术指标进行筛选评估,选用15种常见的金融技术指标进行分析,将基本行情和技术指标利用互信息、相关系数、随机森林树RF模型3种方法相结合筛选指标,进行排序后将其作为输入到预测模型中进行训练。为了过滤掉无用信息并且可以捕捉输入数据的长期依赖关系来处理时序问题,选用了GRU模型进行预测,为了提高预测精度,引入注意力机制调节GRU时间维度的特征表达,使模型获取更全面的特征信息,从而学习到当前局部序列特征的重要程度。引入了注意力机制的Attention-GRU模型在豆粕未来价格预测上具有更优表现。
