基于BERT语义分析和CNN的短文本分类研究
2023-11-21景永霞苟和平
景永霞,苟和平,刘 强
(1.琼台师范学院 信息科学技术学院,海南 海口 571100;2.琼台师范学院 教育大数据与人工智能研究所,海南 海口 571100)
文本分类是自然语言处理的主要任务之一,应用在很多场景,如人机对话、情感分析、垃圾邮件过滤和搜索引擎等领域,特别是近年来智能化应用的不断发展,文本分类受到许多学者的广泛关注。短文本作为一种特殊的文本类别,主要存在口语化、文本短小和语法不规范等特点,这为文本特征的有效学习带来很大困难。传统的机器学习方法,如支持向量机(SVM)[1]和k最近邻算法(kNN)[2]等算法都是常用的文本分类模型,但这些传统的机器分类模型没有获得文本上下文的语义关系,特别是针对短文本数据,产生高维稀疏数据表示等问题,造成分类计算开销大。目前,深度学习技术已经成为主流的文本分析模型,如研究人员采用CNN[3]、RNN、RNN与CNN融合等模型[4],将深度学习应用到短文本分类中,采用基于深度学习的良好特征选择算法,提高文本分类的精度。但是对于短文本来说,单纯地通过增加网络深度来获取文本表示特征,难以提高分类效果。研究人员采用基于词向量的短文本分类方法[5],融合基于词向量和主题模型,提高文本特征向量的语义表征能力。基于Transformer的BERT预训练模型能够很好地获取文本上下文语义信息,特别是获得长距离的语义信息,如采用BERT和特征投影网络的特征提取方法[6]。采用基于深度学习的文本分类算法是目前流行的文本分类算法,但需要大规模的语料进行训练。本文提出一种基于BERT预训练模型文本分类方法,通过领域数据集的微调,获得文本向量表示,然后将文本向量送入到CNN网络中进行文本分类,使得CNN获取更好的分类特征,提高分类效果。
1 文本表示模型
在文本分类过程中,将文本输入分类模型前需要实现文本向量化表示,才能实现后续文本分类模型的相关计算操作,核心是获得的向量能够充分实现文本语义表达。
1.1 基于统计的表示模型
传统的文本向量化方法有独热(One-hot)模型、词袋(Bag of Word)模型、TFIDF模型等,存在问题主要表现为:① 文本表示稀疏,形成稀疏矩阵,造成计算开销大;② 文本语义分析不足,难以解决一词多义在文本分类中的干扰现象;③ 上下文语义关系理解不够。
特别是对于短文本,随着文本数量的增加,文本表示更稀疏,且由于文本数量巨大,而每一条文本的词量少,文本之间的语义关系挖掘困难,文本分类效果不佳。
1.2 基于神经网络的表示模型
通过神经网络模型获取文本特征,能够有效地解决文本特征语义问题,特别是预训练模型的使用,能够更好地获得文本语义表示,有效解决文本分类过程中的一词多义带来的分类问题。
目前广泛使用的基于神经网络文本表示模型是根据上下文与目标词之间的关系进行建模,常用的模型有Word2Vec和BERT。
Word2Vec是一种浅层神经网络,根据给定语料库,通过网络训练将文本数据中的每个分词(token)转化为k维空间上的向量,Word2Vec采用CBOW和Skip-gram两种训练模型。CBOW模型是根据目标单词(token)的上下文,输出目标单词的预测。Skip-gram模型根据已知目标单词(token),预测其上下文。
BERT是谷歌公司2018年提出的一种基于深度学习的语言表示模型,与Word2Vec类似,是一种预训练语言模型,通过给定语料库训练获得文本向量表示,很好地捕获文本上下文之间的语义关系。BERT模型是基于是Transformer多层双向编码器[7],结构如图1所示。

图1 BERT模型架构
Ei(i=1,2,3,…,N)是文本向量表示,是经过字符向量、字符类型向量、位置向量相加获得向量表示。Trm表示Transformer处理,多个双向Transformer进行文本处理,主要获得文本上下文信息。Ti(i=1,2,3,…,N)表示经过多层双向Transformer进行编码后输出的文本字符向量。BERT模型采用两种无监督任务进行预训练[7]:掩码语言模型(Mask Language Model,ML),随机屏蔽每个句子一定百分比的输入标记,然后再根据上下文(剩余的标记)预测那些被屏蔽的标记;下句预测(Next Sentence Prediction,NSP),许多重要的下游任务都是基于对两个句子之间关系的理解,如问答系统和自然语言推理,为了训练一个能够理解句子关系的模型,训练数据选择两个句子,其中选择一定比例的数据表示一个句子是另一个句子的下一句,剩余的是随机选择的两个句子,判断第二个句子是不是第一个句子的下文。
2 基于BERT和CNN的短文本分类
获取短文本中良好的文本特征、实现文本向量化表示是实现分类的关键,CNN的应用能够很好地获取文本特征,但需要大量语料库进行训练模型,以获取良好的特征。BERT模型能够获得文本词之间的深层语义关系,解决一词多义问题。本文提出了一种融合BERT和CNN的短文本分类模型,通过BERT模型通过微调获取短文本词向量表示,再将文本词向量送入CNN模型去实现文本分类。基本流程如图2所示。
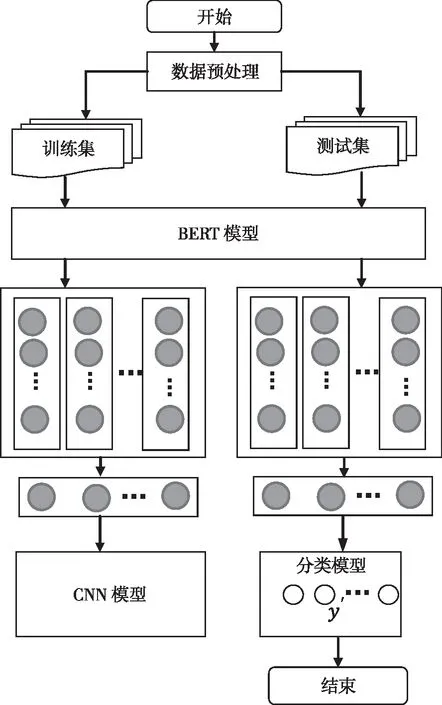
图2 基于BERT和CNN的短文本分类流程
CNN模型的基本结构如图3所示,分别采用256个大小为3加5的卷积核对文本表示向量进行两次卷积,同时采用256个大小为2的卷积核对文本表示向量进行卷积操作,最后对两个卷积结果进行连接操作。
采用BERT和CNN的短文本分类方法,把BERT关注文本上下文语义信息和CNN模型关注局部信息二者结合起来,实现文本特征的加强语义表示。对于包含K个类别的短文本数据集D={Ci{i=1,2,…,K},实现分类过程如下:
(1)首先采用数据集D对 BERT模型的微调,使其能够更好地适应应用数据集。
(2)根据微调后的BERT模型实现短文本数据的向量化表示。对于包含m个分词(tokens)的任意文本d∈D,其表示为
d={w1,w2,…,wm}
(1)
对于分词wi,其表示向量为
(2)
则文本d通过BERT模型的输出d′表示为
(3)
式中:d′的维度为m×n,即数据集D中的每一条文本数据的维度为m×n;m表示文本的长度(tokens的数量),长度超过m的文本将会被截断,少于m的进行补齐;n表示向量的长度,就是BERT模型最后一层隐层的hidden_size。
(3)获得文本数据集的向量表示,即一条文本就表示为二维向量,将其作为CNN模型的输入,CNN分别采用不同卷积核进行卷积操作,获得不同层面的文本特征,最后对特征进行连接操作。
(4)通过全连接层(FC)和Softmax处理,获得最后的分类结果。经过全连接层处理获取的输出
y=WTd′+b
(4)
W为768×15维的权重矩阵,b为偏置项。则有
(5)
(6)
3 实验与分析
3.1 实验环境及数据
实验采用Anaconda集成环境、Python 3.9。文本预训练模型为:BERTBASE(L=12,H=768,A=12,Total Parameters=110 M),模型微调实验数据来自今日头条短文本数据集。
今日头条短文本数据集(TNEWS),包含 15个类别共382 691条数据,其中训练集267 882条,验证集57 404条,测试集57 405条。BERT训练和CNN分类相关参数如表1所示。

表1 参数设置表
3.2 评价指标
短文本分类算法评价采用精确率precision、召回率recall、综合评价指标F1(F1-measure)、宏平均及其加权平均。
3.3 实验结果
基于BERT和基于BERT与CNN的文本实现的文本分类算法,算法的训练损失和验证损失、训练准确率、验证准确率如图4和图5所示。
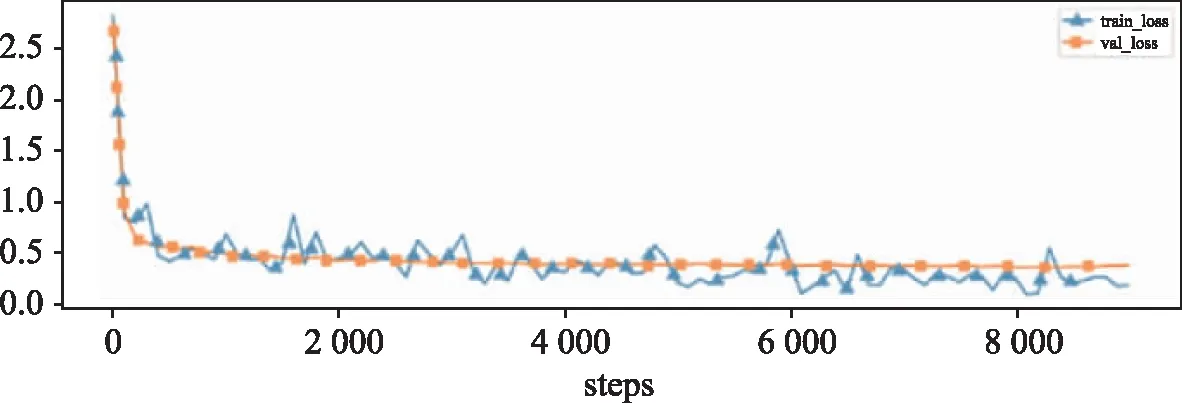
(a)损失
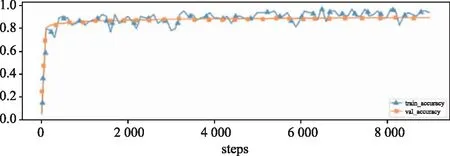
(b)准确率

(a)损失
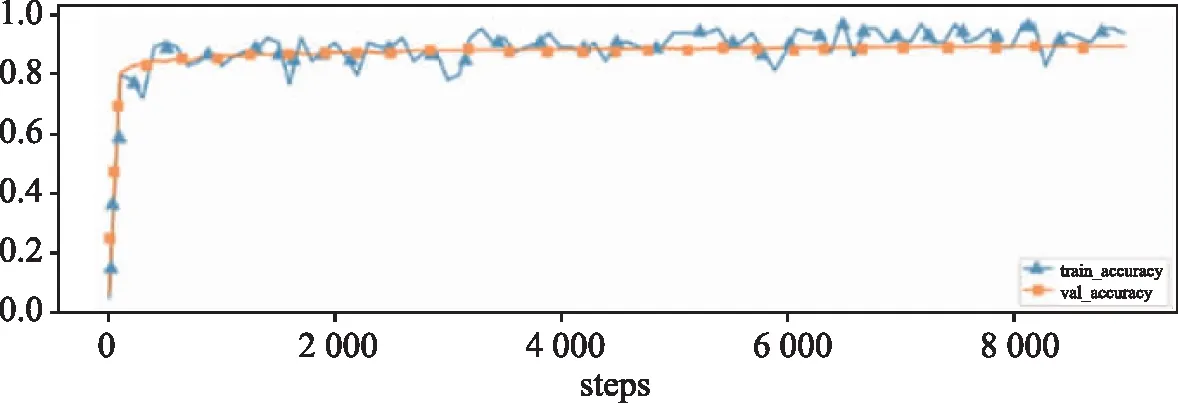
(b)准确率
对比分析基于BERT的文本分类算法和基于BERT和CNN的文本分类算法,其测试的精确率、召回率、F1值的宏平均(Macro avg)和加权平均(Weighted avg)如表2和表3所示。

表2 基于BERT的文本分类测试结果

表3 基于BERT和CNN的文本分类测试结果
与BERT分类相比较,本文实现算法的分类准确率(accuracy)达到89.42%,高于单纯采用BERT算法的分类准确率。15个类别的F1-score值的宏平均和加权平均达到82.93%和89.38%。采用本文提出的结合BERT模型和CNN的短文本分类算法,能够很好地把短文本中的全局和局部语义信息结合起来获取文本特征,有效地提高算法的分类效果。
4 结 语
提出的短文本分类方法采用BERT预训练模型微调获得文本特征抽取,主要目标是解决数据量小的情况下采用BERT模型可获得文本语义表征的向量,再将这些经过特征提取后的数据特征向量作为CNN模型的输入,采用不同大小卷积核进一步提取分类语义特征,此方法能够有效地提高文本分类效果。
