基于联盟链的数字图书馆用户隐私保护研究
2023-11-21刘浩东王秀红
刘浩东 王秀红
摘 要:
通过分析用户隐私信息在用户、数字图书馆和供应商之间的流动路径、生命周期各环节泄露风险,结合三螺旋理论和联盟链技术,构建包含数据层、网络层、共识层、合约层与应用层五个层级的数字图书馆用户隐私保护模型(LibUPM),以期为数字图书馆用户隐私保护提供新的思路和方法,实现用户信息的开发利用与隐私保护之间的平衡。
关键词:
数字图书馆;联盟链;区块链;三螺旋;可搜索加密;用户隐私
中图分类号:G250.76 文献标识码:A 文章编号:1003-7136(2023)05-0067-10
Research on User Privacy Protection of Digital Libraries Based on Alliance Chain
LIU Haodong,WANG Xiuhong
Abstract:
By analyzing the flow path,link and leakage risk of user privacy information among users,digital libraries and suppliers,combined with triple helix theory and alliance chain technology,this paper constructs a user privacy protection model of digital library( LibUPM)including five levels:data layer,network layer,consensus layer,contract layer and application layer,in order to provide new ideas and methods for digital libraries user privacy protection,and realize the balance between the exploitation and privacy protection of user information.
Keywords:
digital library;alliance chain;blockchain;triple helix;searchable encryption;user privacy
0 引言
隨着云存储、物联网与大数据等新兴技术在数字图书馆领域的广泛应用,我国数字图书馆事业步入了高速发展阶段[1]。数字图书馆是在知识管理的背景下,以数字化、网络化方式存储、共享和利用数字图书馆中各种馆藏文献的知识网络系统,具有资源整合化、存取网络化、跨时空服务等特点,不断增长的数字资源是数字图书馆发展的重要保障[2]。人工智能时代,用户在数字图书馆进行身份登记、文献检索以及参考咨询等活动的信息都会被记录下来,并以数字化形式存储。数字图书馆对用户个人信息进行全面采集和深度分析,以满足用户的多元需求[3];同时数字图书馆为了提高自身数字化建设与服务水平,还需要与供应商共享用户信息[4]。用户、数字图书馆和供应商三者的关系从未如今天一般紧密,但与此同时,联结三者的用户隐私信息也面临着严峻的泄露威胁[5]。
数字图书馆用户隐私泄露主要包括信息采集、信息存储和传输、信息滥用以及业务外包等途径[6]。在信息采集过程中,用户在注册读者证、参加活动时填写的姓名、性别、年龄、职业、联系方式等基本信息,以及使用数字图书馆网站、App等在线服务的日志数据都是潜在风险对象,很容易被保密意识不强的工作人员泄露或是被黑客窃取。目前信息存储和传输主要采用云存储方式,然而云平台较易受网络攻击,数据在云上的迁移带来的残留数据存在着泄露用户隐私的风险[4]。在信息滥用方面,数字图书馆以及供应商为了更为精准地发掘用户的需求,使用分析能力更强的机器学习算法对用户隐私进行分析,却忽略了对敏感数据的加密处理,构成了较大的隐私泄露风险[7]。业务外包时将部分业务交由第三方公司,相应用户隐私数据也被过渡到第三方,使得用户隐私暴露在更大的泄露风险之下[8]。
为应对日趋严重的用户隐私泄露问题,用户、数字图书馆和供应商需要协同合作[9]。数字图书馆用户隐私保护研究迫在眉睫。
1 数字图书馆用户隐私保护研究现状分析
数字图书馆和供应商为了向用户提供更多、更优质的个性化服务,必须获得更丰富、更敏感的用户隐私信息,必须利用更先进的人工智能算法对用户隐私信息进行更深层次的分析,但这极大加剧了用户隐私信息泄露的风险[6]。因此,保障数字图书馆用户隐私安全是进一步开展个性化服务的必要前提。
国内外学者关于数字图书馆用户隐私保护研究集中在两大方向,一是基于法律法规的角度,二是基于技术方法的角度。20世纪中叶,国外就针对图书馆用户隐私颁布了一系列法规政策,在法律和技术上都较为成熟;而国内的相关研究始于21世纪初,起步较晚,缺乏相应的法律规范,技术方法也相对落后,亟待确立符合国情的数字图书馆用户隐私保护法律、标准,利用人工智能、密码学技术形成更高效的隐私保护方法[10-11]。
宋文秀通过调研若干不同类型的数字图书馆,分析数字图书馆用户信息的泄露途径,认为数字图书馆要根据法律法规采取有效手段保障用户隐私安全,并提出了保护用户隐私的七大措施[12]。陆康等通过对我国与欧盟数据安全法律的比较研究,探讨了用户、数字图书馆和数字图书馆业务这三者的权利与义务以及三者间的关联[13]。McKinnon D等基于图书馆与供应商共享用户隐私的视角,调查了加拿大部分高校图书馆的供应商的隐私政策,并分别提出了图书馆和供应商加强用户隐私安全的改进措施[14]。Younghee Noh先后调查了图书馆员在接受用户隐私教育前后对图书馆用户隐私的感知变化,认为在图书馆员群体中开展定期的隐私教育对图书馆隐私保护的发展是极其必要的[15-16]。然而,由于相关的法律法规还未健全,现有法律法规虽然能够在一定程度上缓解隐私信息泄露问题,但无法从根本上解决此问题。
在技术方法上,贾俊杰等提出基于数据属性的匿名方法,利用层级划分和匿名化处理的方式实现对数字图书馆用户隐私数据的保护和高质量发布,但如何确定合适的属性权重仍有待进一步研究[17]。Wu Z D等通过设计行为偏好隐私保护框架模型,将用户的真实行为混杂在伪行为中,一同提交给不可信服务器端,从而实现用户行为偏好隐私保护[18]。Wu Z D等还基于数据加密理论和数据索引理论,在对读者借阅隐私进行事前加密的同时,设计了读者文献流通记录的相关查询方法,借此保障读者借阅隐私的安全性和信息查询的高效性[19]。
综上所述,现有研究虽在一定程度上提出有助于解决数字图书馆用户隐私保护问题的不同见解,但依然存在以下待解决的问题:①研究对象未能同时包括静态用户隐私和动态用户隐私;②研究所立足的场景仅限于数字图书馆本身,未能囊括整个数字图书馆生态,即用户、数字图书馆和供应商;③研究范围未能覆盖到用户隐私信息整个生命周期,偏重于用户隐私信息的安全采集与存储。本文基于三螺旋理论和联盟链技术提出一种数字图书馆用户隐私保护模型,分析信息在用户、数字图书馆和供应商之间的流动路径及泄露风险,为数字图书馆用户隐私保护提供新的思路和方法,最終实现用户信息的开发利用和隐私保护之间的平衡。
2 理论方法
2.1 三螺旋理论
1995年,Etzkowitz H等首次提出三螺旋理论,用以描述政府、企业和大学三者之间的协同创新关系[20]。由于政府、企业和大学有着共同利益,因此他们可以通过密切互动实现合作共赢。三螺旋理论因其可以有效联结各方主体以实现共同利益诉求的特性,被广泛应用于教育、公共政策、区域经济、创新实践等领域[21]。同时,也有学者将三螺旋理论应用于图书馆学研究领域,如梁春慧针对图书馆服务的优化工作,提出了包括图书馆、环境和用户三元主体的三螺旋理论,并以服务高校的协同创新中心为例,验证了三螺旋理论对于图书馆服务的优化作用[22]。
数字图书馆用户隐私信息是将用户、数字图书馆和供应商紧紧联系在一起的数据资源,用户隐私信息在三者间的流动使得三者形成了一个“用户—数字图书馆—供应商”三螺旋模式。在该模式下,数字图书馆和供应商同为用户隐私信息的消费者,在优化信息资源结构、提升信息服务水平的驱动下,迫切需要对其进行采集、传输和深入分析,而用户则希望自己的隐私信息能够被安全地采集、传输、存储、清除以及被有限地开发利用[4]。为了实现各方的共赢,数字图书馆、供应商与用户之间有必要达成对用户信息的开发利用与隐私保护的平衡,这符合三螺旋理论的思想架构。
2.2 联盟链技术
联盟链是由若干节点共同参与管理,数据仅限于各个节点间共享的一种区块链,实现了部分去中心化,兼具去中心化和隐私性特点,适用于多组织间的合作,目前已经被大量应用于解决物联网交易者和病人的隐私信息泄露问题[23-24]。在图书馆学领域,学者们主要着眼于应用联盟链促进图书馆信息资源的安全共享与平台建设,对于用户隐私保护的研究则较少。在联盟链技术的支撑下,基于三螺旋理论形成的“用户—数字图书馆—供应商”利益共同体组成了联盟链的各个节点,从而形成致力于数字图书馆用户信息隐私安全与合理开发的联盟链,有望保证用户隐私的安全共享和适度开发,实现各方的合作共赢。
本文结合三螺旋理论,基于联盟链技术构建一种数字图书馆用户隐私保护模型(user privacy protection model of digital Library,以下简称:LibUPM),可兼具三螺旋模型的互作用特征和联盟链的部分去中心化特点,既能发挥用户、数字图书馆和供应商在用户隐私信息保护方面的积极作用,又能推动用户信息的开发利用和隐私保护达成平衡。
3 模型构建过程
数字图书馆用户隐私信息是指用户在使用数字图书馆提供的服务过程中产生的个人隐私信息[25],包括静态用户隐私与动态用户隐私[18]。静态用户隐私可分为用户身份信息和用户敏感信息[27]:用户身份信息是指姓名、性别、年龄、手机号等身份标识;用户敏感信息是指政治面貌、宗教信仰、社会关系等社会背景信息。动态用户隐私是指用户在使用参考咨询服务、图书借阅服务等数字图书馆服务时产生的个人行为偏好信息。
3.1 用户隐私信息泄露风险分析
3.1.1 用户隐私信息流动路径及泄露风险分析
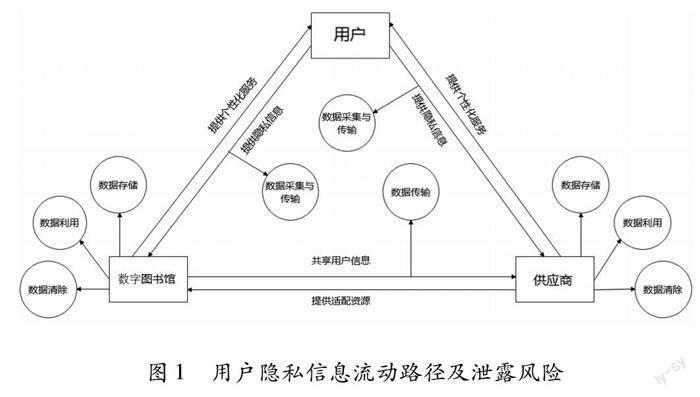
用户隐私信息联结的“用户—数字图书馆—供应商”三螺旋模式下,三者的相互作用及影响主要包括以下三条路径。
(1)用户—数字图书馆:用户向数字图书馆提供自己的隐私信息,促使数字图书馆的服务水平得到提升,进而用户更加愿意将隐私信息提供给数字图书馆。该路径下用户不光要将静态隐私信息交予数字图书馆,也要将动态隐私信息提供给数字图书馆以使用各项服务,用户的所有隐私信息都存储在数字图书馆,丧失了对自身隐私信息的控制权,存在很大的泄露风险。
(2)数字图书馆—供应商:数字图书馆与供应商共享用户隐私信息,使数字图书馆和供应商的资源结构与服务体系都得到优化,推进二者的合作共享。该路径下数字图书馆将用户身份信息和动态用户隐私共享给供应商供其深入分析,而供应商相较于数字图书馆发生贩卖和泄露用户隐私信息的风险更大。
(3)用户—供应商:用户直接向供应商提供个人隐私信息,供应商更加明晰市场需求,为用户提供更优质的信息资源服务,促使用户更主动地将隐私信息提供给供应商[27-28]。该路径下用户将自身的静态隐私和动态隐私信息提交给供应商,供应商掌握了用户所有隐私的控制权,极易给用户带来隐私泄露风险[8]。
用户隐私信息流动路径及泄露风险如图1所示。用户隐私信息的流动路径分为两种:一种是“用户—数字图书馆—供应商”,用户向数字图书馆提交自己的隐私信息,数字图书馆将其存储并进行开发利用,再将整理好的用户隐私信息共享给供应商进行存储和利用;另一种是“用户—供应商”,供应商直接获取用户的隐私信息进行存储与开发利用。
3.1.2 用户隐私信息生命周期各环节及泄露风险分析
结合用户隐私信息流动路径与数据生命周期理论[3],用户隐私信息的泄露风险存在于数据采集与传输、数据存储、数据利用和数据清除等整个生命周期。
(1)数据采集与传输环节:包括用户向数字图书馆、供应商提供隐私信息和数字图书馆对供应商共享用户隐私信息的过程。由于用户隐私信息具有较大的价值,不法分子往往将其作为主要攻击目标,窃取或篡改用户隐私信息[29]。该环节中用户的静态隐私和动态隐私信息暴露在开放的网络中,黑客较易发起网络攻击,造成用户隐私信息的泄露,因此需要做好采集和传输过程中的信息加密工作。
(2)数据存储环节:主要指数字图书馆与供应商存储用户的隐私信息,以待后续进行数据分析。目前我国图书馆大多将用户信息存储在本地系统[30],但随着馆内数字资源的急剧增多,云存储逐渐被图书馆所接受,用户的静态隐私和动态隐私信息被存储在云端,不过云平台自身易受黑客攻击,具有较大的信息泄露风险,需要采取进一步的措施保障数据存储安全[31-33]。
(3)数据利用环节:指数字图书馆和供应商为了向用户提供更加优质和个性化的服务,而对用户隐私信息进行数据分析的过程。用户身份信息和动态用户隐私信息是其分析的重点对象,随着机器学习、深度学习的发展,用户敏感信息的价值日益凸显,数字图书馆和供应商若在未经用户许可的情况下就对用户敏感信息进行挖掘,会对用户的隐私产生极大的威胁[6]。同时也存在数字图书馆或者供应商的部分工作人员为了自身利益向第三方出卖用户隐私信息的风险[4]。因此需要对用户隐私信息进行严格的访问控制,并对利用行为进行实时记录和监督审查。
(4)数据清除环节:指数字图书馆、供应商对过期或无价值的用户隐私信息进行清除,或对用户要求删除的数据进行清除的过程。数字图书馆和供应商需要及时销毁待清除的用户隐私数据,这样既能减少隐私泄露的风险,又能够降低数据存储的成本。该环节中用户信息的控制权在数字图书馆和供应商手中,用户很难监督其是否真正清除自身隐私信息,用户的隐私信息存在未经许可被作为用户历史数据过度分析和长期存储,进而被网络攻击导致泄露的风险。
3.2 模型基本结构
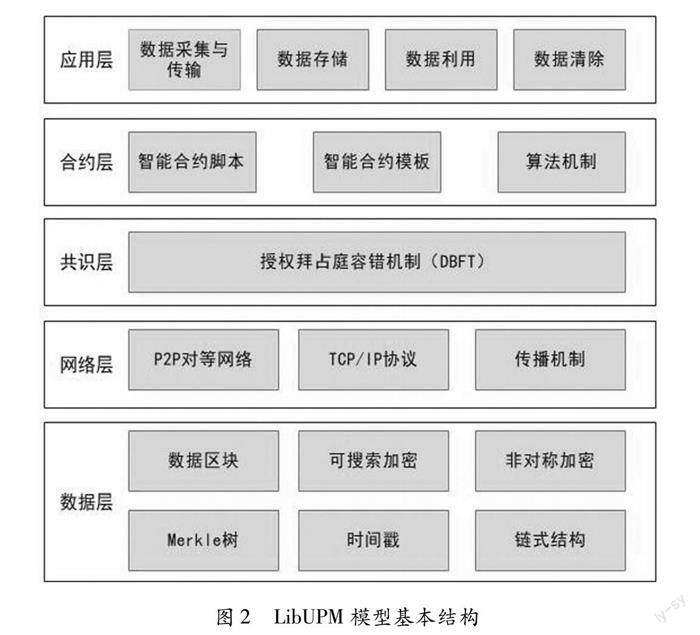
根据用户隐私信息流动路径及泄露风险分析结果,将LibUPM模型的基本结构设定为数据层、网络层、共识层、合约层与应用层五个层级,具体结构如图2所示。
3.2.1 数据层
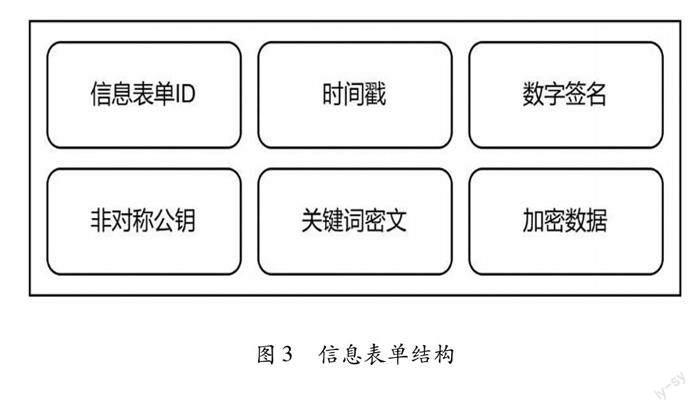
数据层是本模型的底层数据存储空间,包含存储数据的数据区块、时间戳、哈希算法和非对称可搜索加密等技术。基于时间戳技术,数据区块被按时序链接到主链,能够对区块链数据进行追溯操作,为用户隐私信息的流动、更改、清除等操作提供了证明。非对称可搜索加密、Merkle树和哈希算法保障了用户隐私信息分布式存储的安全性与完整性。为了实现关于加密文件的搜索,本文在区块链交易单的基础上增设了由用户利用非对称加密公钥对关键词进行加密而成的关键词密文,进而构造出一个完整的信息表单,如图3。
非对称可搜索加密是可搜索加密的一种,指拥有公钥的用户对关键词加密生成关键词密文,仅允许拥有私钥的用户对该关键词进行检索[34]。其最大的特点是基于加密数据进行检索,因此需要提供由关键词加密而来的密文标签供检索,而密文标签不会泄露任何有关明文的信息,極大地保障了用户隐私信息的安全性。实现非对称可搜索加密算法的步骤如下[35]。
(1)KeyGen(p):给定一个安全参数p,得到可搜索加密公钥为K_pub,私钥为K_pri。
(2)PEKS(K_pub,W_1):用户使用密钥对明文数据加密,使用K_pub对其关键词W_1加密生成关键词密文S_w,上传至数据库。
(3)Trapdoor(K_pri,W_2):数字图书馆、供应商使用K_pri对关键词W_2进行加密,生成陷门T_w,发送给数据库。
(4)Test(K_pub,S_w,T_w):数据库输入K_pub,S_w=PEKS(K_pub,W_1)和T_w= Trapdoor(K_pri,W_2),若W_1=W_2,则Test(K_pub,S_w,T_w)=1,代表成功匹配到加密数据,将该加密数据返回给数字图书馆和供应商;否则匹配失败。
(5)数字图书馆和供应商接收加密数据,利用K_pri密钥解密。
3.2.2 网络层
网络层即节点间进行通信和数据交换的场所,是一个基于TCP/IP 通信协议和P2P对等网络构建的分布式网络系统。用户隐私信息在这个去中心化的分布式网络系统中流动,所有节点通过该网络共享用户隐私信息,同时也负有提供网络服务、维护网络安全的责任。由于数字图书馆的大部分用户都缺乏完备的计算机运算及存储设施,因此将节点分为普通节点和共识节点。数字图书馆的用户都是普通节点,平时不存储区块数据,如果需要使用联盟链上的数据,便向共识节点提出申请;共识节点包含数字图书馆和供应商,存储全网所有的区块数据,参与共识。
3.2.3 共识层
共识层封装的共识机制能够使联盟链的所有节点对区块信息产生一致共识,防止最新区块被添加至错误的链上,抵抗双花等恶意攻击。工作量证明算法(PoW)、权益证明算法(PoS)、实用拜占庭容错算法(PBFT)和授权拜占庭容错算法(DBFT)都是当前主流的共识机制。
本模型使用DBFT机制保障联盟链上的信息达成安全可靠的全网一致共识,抵御恶意攻击。DBFT机制在PBFT的基础上结合了PoS模式特点,同时具有良好的安全性和最终性[36]。一方面,DBFT机制拥有f=(n-1)/3的容错能力,其中n是共识节点总数,足以抵抗联盟链的绝大部分故障;另一方面,新区块的产生必须收到至少2f+1个共识节点的承诺信息且已经发出承诺信息的共识节点不会更换视图,保证了新区块的终局性。DBFT机制的高容错能力、高可用性和最终性,非常契合用户隐私信息的存储与传输要求。
DBFT机制的一轮共识主要由共识节点完成,普通节点可以观察所有的共识过程。设置一个共识节点为议长节点,其他共识节点为议员节点,所有共识节点共同维护一个视图,若在当前视图内未能达成共识,则更换至下一个视图继续进行共识[37]。完成一轮共识的步骤如图4所示。
(1)准备请求:议长节点发起共识,广播新一轮共识的信息。
(2)准备响应:议员节点接收共识信息,验证同意后广播预备响应消息,预备响应消息包含议员节点的数字签名,以表示本节点支持该共识提案。
(3)承诺:共识节点接收到至少2f+1个预备响应消息后,广播达成一致的承诺消息,此步骤用于同步支持该共识提案的节点。
(4)出块广播:共识节点接收到至少2f+1个承诺消息(包括自己的承诺消息),可以确保所有共识节点将同意相同的区块提案,而后产生新区块并广播。
3.2.4 合约层
合约层包括算法机制、脚本代码和智能合约,借助算法与脚本代码,可根据实际需要对智能合约进行编程。智能合约在编码完成后会被上传至联盟链,合约的所有内容都无法被修改。由于智能合约预先制定了所有条款和执行机制,并由计算机自动执行,因此无需第三方监管,且具有极高的执行效率。
3.2.5 应用层
应用层是整个模型的核心层级,封装有数据采集与传输、数据存储、数据利用与数据清除等具体的应用,为用户隐私信息的数据传输、安全存储、数据分析以及防范隐私泄露提供支持。用户隐私信息按照智能合约的规范,经由这些应用在全网节点间流动。
3.3 保护机制
基于联盟链的用户隐私信息保护机制如图5。
3.3.1 数据采集与传输
数据采集与传输分为两个阶段,分别是用户隐私信息采集和用户隐私信息传输。用户隐私信息的采集阶段主要包括:采集个人的姓名、性别、政治面貌、宗教信仰等静态用户隐私,以及使用数字图书馆的智能设备时产生的行为数据、访问数字图书馆线上服务留下的日志记录等动态用户隐私。
用户隐私信息的传输主要包括六个步骤:
(1)LibUPM对采集到的用户隐私信息进行加密,用户对KeyGen (p)输入安全参数p,获得非对称可搜索加密公钥K_pub和私钥K_pri,再使用算法PEKS(K_pub,W_1)生成关键词密文S_w,其中W_1是關键词。然后设置时间戳,分配表单ID,最后利用非对称加密私钥进行数字签名,形成一个规范的信息表单,提交给共识节点。
(2)共识节点接收到信息表单,存放至内存池。在某一轮共识中,议长节点将内存池中的所有信息表单打包至新区块中,并广播新区块提案和验证请求。
(3)议员节点接收新区块提案和验证请求,抽取出若干信息表单,使用其中的非对称加密公钥对数字签名进行验证。若验证通过,就广播预备响应信息;若未通过,则说明该表单信息已经不可信,放弃广播预备响应信息。
(4)共识节点接收到至少2f+1个预备响应消息(包括自己的预备响应消息)后,广播关于同意新区块提案达成一致的承诺消息。
(5)共识节点接收到不少于2f+1个承诺消息(包括自己的承诺消息)后,开始发布新区块并广播,同时将区块内的信息表单从内存池中删除。
(6)用户节点接收共识节点的承诺消息,若接收到至少2f+1个预备响应消息,则代表自己的信息表单被成功上传到联盟链数据库;否则需要再次提交信息表单。
3.3.2 数据存储
数据存储主要指数字图书馆与供应商将所需的数据从联盟链数据库中准确地提取出来,并解密为明文数据进行存储,以待后续进行数据利用的过程。由于数字图书馆和供应商自身就是联盟链上的共识节点,因此他们首先从自身存储的联盟链数据中提取所需的数据。
在联盟链数据库中获取指定关键词相关数据的步骤如下:
(1)数字图书馆与供应商根据目标数据的关键词W_2和可搜索加密私钥K_pri,生成陷门T_w= Trapdoor(K_pri,W_2),接着执行匹配算法Test(K_pub,S_w,T_w),若输出为1,则成功查询到目标数据。其中K_pub为公钥,S_w为关键词密文。
(2)数字图书馆与供应商从提取到的信息表单中得到目标数据,对该加密数据进行哈希值计算,若与信息表单中记录的哈希值一致则说明数据未被篡改,然后用密钥解密得到明文数据。否则,说明自身存储的该部分联盟链数据已被篡改,需要向其他共识节点申请该区块数据,并更新相应区块数据。
在获取到明文数据后,数字图书馆与供应商对其进行数据分类和分级存储:
(1)数据分类。先将获取的用户隐私数据分为两大类,一类是姓名、性别、政治面貌、宗教信仰等静态用户隐私数据,再将其细分为用户身份信息和用户敏感信息两个类别;另一类是图书借阅记录、信息咨询记录等动态用户隐私数据。再将每一类中的每个字段的数据单独分为一小类,相互间保持一定的独立性。最后设置某一特定字段作为所有字段的联结符,以方便快速查找。
(2)分级存储。对已经分类完毕的三个类别以及若干子类,根据其敏感程度和利用情况进行分级存储。为了应对不可避免的数字资源急剧增长问题,如信息检索记录、图书借阅记录等敏感程度低且利用频率较高的字段数据经过匿名化处理后可以存储在安全级别较低的云存储平台中;政治面貌、宗教信仰、社会关系等敏感程度高且利用频率较低的字段数据需要在本地存储,并将隐私数据的存储设备与互联网隔离,防范黑客攻击。
3.3.3 数据利用
数据利用是指数字图书馆和供应商根据自身运营发展的需要,运用大数据分析方法挖掘用户隐私数据的价值,以实现深入了解用户信息资源需求、预测用户行为的目标。数字图书馆、供应商与用户之间存在着前两者意图最大程度地利用用户隐私数据,而后者希望自己的隐私数据能够尽可能低限度地被开发的矛盾,LibUPM采用权限分级和日志公开的方法在对用户隐私数据进行开发的同时兼顾用户隐私数据的合理利用。
(1)权限分级。一方面,数字图书馆和供应商专门授予数据分析人员调取和分析用户隐私数据的权限,避免无权限人员接触用户隐私信息;另一方面,数字图书馆与供应商对数据分析人员的权限进行分级,仅限部分数据分析人员访问政治面貌、宗教信仰、社会关系等敏感程度高的字段数据。
(2)日志公开。数字图书馆与供应商将每一次对用户隐私数据进行开发的时间、原因、数据分析人员、所利用的数据类别和数量等日志信息进行记录,并将日志信息经过数据传输上传至联盟链数据库,全网节点都可查询到该日志信息,实现对用户隐私数据利用工作的有效监督。
3.3.4 数据清除
数据清除是指数字图书馆和供应商将自身存储的用户隐私数据中待清除数据彻底删除的过程,待清除数据包括无效、无价值数据和用户要求删除的数据。
数字图书馆和供应商对数据清除工作中的时间、原因、数据类别、数据数量等信息做好日志记录,并通过数据传输将日志信息上传至联盟链数据库,供全网审查。
4 LibUPM的特点
从上述模型的层级结构、保护机制的运作过程等方面可以看出,本文构建的LibUPM具有以下三个方面的特点。
4.1 安全性
LibUPM的安全性主要表现在数据的完全性、不可篡改、密文标签以及可追溯存根上。第一,LibUPM采用联盟链的分布式构架,全网共识节点——所有数字图书馆和供应商都存储有完整的联盟链数据,保障了联盟链数据的完全性。第二,LibUPM使用哈希算法对每个信息表单进行签名,并采用Merkle树对数据进行完整性验证与一致性验证,一旦数据被篡改就会被共识节点识别并丢弃。第三,LibUPM使用非对称可搜索加密技术对关键词进行加密,信息表单中只有关键词密文,任何人都无法获得任何关于明文数据的信息,确保了用户隐私信息的保密性。第四,联盟链的所有区块根据时间戳按时序链接,全网节点都可以遍历查询联盟链上的所有数据,保证了数据的可追溯存根。
4.2 高效性
LibUPM的高效性是指数据采集与传输、数据存储、数据利用和数据清除环节的运行效率都较高。这一方面得益于LibUPM采用去中心化的分布式网络系统,解决了信用问题,使得数据验证、数据提取、数据审查不依赖第三方,既缩减了用户隐私信息的流动时间,又节省了用户隐私信息获取的成本;另一方面是因为LibUPM提供关键词检索途径,缩小了数据检索范围,使得用户隐私信息检索的时间效率能够保持在一个较高的水平。
4.3 适用性
LibUPM的适用性是指其适用于不同规模的数字图书馆生态,能够满足小型、中型和大型数字图书馆及其不同数量的供应商和用户的需求,提高数字图书馆、供应商和用户的参与度。首先,LibUPM采用DBFT共识机制,每轮共识只需要不少于m=n-f个正常共识节点便可正常运行,因此LibUPM只需3=4-[(4-1)/3]个正常的共识节点,就可以应用于少至n=4个共识节点的系统,能够满足不同规模的数字图书馆生态的需要。其次,DBFT共识机制允许全网节点随时加入、退出,因此LibUPM可以适应于数字图书馆的供应商和用户的新增或退出等情况。最后,LibUPM在用户信息的开发利用和隐私保护之间保持了平衡,数字图书馆和供应商能够获取到自己所需的用户隐私信息,对用户隐私信息进行数据分析,但同时也需要将每一次的数据利用与清除的日志信息进行全网广播,用户能够主动审查自己隐私信息的利用和清除情况,有利于促进数字图书馆、供应商和用户积极参与到LibUPM的运作中。
5 结语
LibUPM具有联盟链的部分去中心化和隐私性等特点,不仅能够提高用户隐私信息采集、传输、利用和清除的效率,满足数字图书馆和供应商进行数据分析的需要,而且可以保障用户对自身信息被利用、清除情况的审查权利,实现用户信息开发利用和隐私保护的平衡。
目前,联盟链技术在数字图书馆用户隐私保护领域的应用处于探索阶段,LibUPM在现实中应用还存在一定的困难。首先,联盟链的信息存储需要占用较大的存储空间,无论是本地硬盘存储或是购买云存储服务都是一笔不小的开支,这对于一些经费紧张的图书馆来说难以维系;其次,目前图书馆行业缺少同时具有计算机和图书馆学背景的复合型人才,难以迅速组织人员构建、运行联盟链;最后,关于区块链的应用,图书馆行业仍然没有明确的标准规范,难以大规模普及。
这些挑战的产生是由于图书馆行业正处于数字化转型阶段[38],这些困难也必将随着图书馆的數字化、智慧化深入发展而被克服。随着图书馆行业在“十四五”时期的发展,图书馆的数字基础设施将不断完善,也将得到更大的财政资金投入[39];图书馆学伴随着新文科建设的浪潮,将与计算机科学、数据科学等学科交叉融合,培养兼具管理学思维和大数据素养的复合型人才[40];而随着图书馆行业更为积极主动地拥抱区块链,相关的应用标准规范将在不断的探讨、应用、再探讨中逐步确立。
参考文献:
[1]王涛,刘利军,李翔宇.发展驱动技术 技术赋能服务:湖北省数字图书馆建设回顾(2008—2018)[J].图书馆论坛,2021,41(3):145-155.
[2]杨莹.数字化图书馆的概念界定与要素分析[J].现代情报,2007(11):87-89.
[3]谢珍,陆溯.智慧图书馆视域下用户数据应用与隐私保护平衡研究[J].国家图书馆学刊,2020,29(2):49-59.
[4]赵文慧,赵润娣.图书馆数据开放服务中用户隐私保护问题探讨[J].图书馆学研究,2020(13):64-67.
[5]HAN Z B,HUANG S Q,LI H,et al.Risk Assessment of Digital Library Information Security:a Case Study[J].The Electronic Library,2016,34(3):471-487.
[6]赵天昀.数字图书馆个性化信息服务中用户隐私保护研究[J].图书馆理论与实践,2018(2):101-103.
[7]马崇环.现代信息技术环境下图书馆读者隐私保护策略研究[J].河南图书馆学刊,2021,41(12):112-114.
[8]王建.大数据环境下图书馆用户隐私权保护路径研究[J].河北科技图苑,2021,34(3):57-61.
[9]《现代图书情报技术》编辑部.新的隐私准则鼓励图书馆和内容供应商一起保护读者隐私[J].现代图书情报技术,2015(9):16.
[10]俞德凤.美国康奈尔大学图书馆隐私保护服务及启示[J].农业图书情报学报,2021,33(11):28-37.
[11]王家玲.近十年国内图书馆用户隐私保护研究综述[J].图书馆工作与研究,2017(2):24-28.
[12]宋文秀.数字时代图书馆读者个人隐私保护现状与策略探析[J].图书馆工作与研究,2019(3):78-81,87.
[13]陆康,刘慧,任贝贝,等.智慧图书馆用户数据隐私保护研究:基于《中华人民共和国网络安全法》和《一般数据保护条例》的文本启示[J].图书馆理论与实践,2020(3):17-21.
[14]MCKINNON D,TURP C.Are library vendors doing enough to protect users? A content analysis of major ILS privacy policies[J].The Journal of Academic Librarianship,2022,48(2):102505.
[15]YOUNGHEE NOH.Digital Library User Privacy:Changing Librarian Viewpoints Through Education[J].Library Hi Tech,2014,32(S1):300-317.
[16]YOUNGHEE NOH.A Study on the Changes in Librarians′ Perception before and after User Privacy Education[J].Library and Information Science Research,2020,42(3):101032.
[17]贾俊杰,陈菲.数字图书馆个性化匿名发布方法[J].计算机工程与科学,2017,39(11):2109-2114.
[18]WU Z D,LI R C,ZHOU Z F,et al.A User Sensitive Subject Protection Approach for Book Search Service[J].Journal of the Association for Information Science and Technology,2020,71(2):183-195.
[19]WU Z D,SHEN S G,LU C L,et al.How to protect reader lending privacy under a cloud environment:a technical method[J].Library Hi Tech,2020,40(6):1746-1765.
[20]ETZKOWITZ H,LEYDESDORFF L.The Triple Helix of University-industry-government relations:A laboratory for knowledge based economic development[J].EASST Review,1995,14(1):14-19.
[21]楊倩倩.三螺旋理论研究综述[J].合作经济与科技,2022(9):122-124.
[22]梁春慧.基于“图书馆-环境-用户”三螺旋理论的图书馆服务:以面向协同创新中心的专利信息服务为例[J].新世纪图书馆,2015(4):31-34.
[23]鲁晔.一种基于联盟链的物联网匿名交易方案[J].计算机应用研究,2021,38(1):23-27.
[24]巫光福,余攀,陈颖,等.基于联盟链的电子健康记录隐私保护和共享[J].计算机应用研究,2021,38(1):33-38.
[25]吴高.人工智能时代公共数字文化服务个人隐私保护的困境与对策[J].图书馆学研究,2021(10):39-45,54.
[26]姜明芳,赵奇钊.《公共图书馆法》视阈下读者个人信息保护路径研究[J].高校图书馆工作,2020,40(4):15-17.
[27]赵丽梅,张花.基于全链路平台构建的高校数字图书馆联盟运行体系研究[J].图书馆学刊,2019,41(4):112-116.
[28]赵树旺.国际数字出版商的用户策略及启示[J].现代出版,2015(2):38-41.
[29]钱平,朱光剑,曹劲.网络传输中数据安全及加密技术[J].电脑知识与技术,2019,15(35):33-34.
[30]颜斌.图书馆信息服务转型的若干技术路径初探[J].新世纪图书馆,2017(11):44-48.
[31]黄鲲翔.数字图书馆云存储技术服务安全问题及解决策略[J].图书馆学刊,2018,40(7):125-129.
[32]童忠勇.国家数字图书馆特色资源云平台的建设与实践[J].国家图书馆学刊,2018,27(5):99-105.
[33]鲍劼,李丕仕,都平平,等.高校图书馆面临的数据安全问题及防护策略研究[J].现代情报,2017,37(7):93-96.
[34]刘格昌,李强.基于可搜索加密的区块链数据隐私保护机制[J].计算机应用,2019,39(S2):140-146.
[35]BONEH D,CRESCENZO G D,OSTROVSKY R,et al.Public key encryption with keyword search[C]//2004 International conference on the theory and applications of cryptographic techniques.Berlin,Heidelberg:Springer,2004:506-522.
[36]COELHO I M,COELHO V N,ARAUJO R P,et al.Challenges of PBFT-inspired consensus for blockchain and enhancements over neo dBFT[J].Future Internet,2020,12(8):129.
[37]VITOR N C,RODOLFD P A,HAROLDO G S,et al.A MILP Model for a Byzantine Fault Tolerant Blockchain Consensus[J].Future Internet,2020,12(11):185.
[38]张娅琼.“十四五”时期公共图书馆促进数字包容路径探赜[J].图书与情报,2022(1):118-123.
[39]潘颖,郑建明,孙红蕾.“十四五”时期公共文化发展沿革与融合创新:基于省级政策文本内容分析视角[J].图书馆建设,2022(2):150-158.
[40]金波,杨鹏,王毅.“十四五”图书馆、情报与文献学学科发展态势与前瞻[J].图书馆杂志,2022,41(1):4-16.
作者简介:
刘浩东(2001— ),男,江苏大学科技信息研究所硕士研究生在读。研究方向:知识管理、专利分析。
王秀红(1975— ),女,博士,研究館员,任职于江苏大学科技信息研究所、江苏大学图书馆。研究方向:专利分析、用户信息行为。
