基于人工智能的故障诊断方法应用研究
2023-11-21尤建祥魏孔鹏
尤建祥 魏孔鹏
(盘锦职业技术学院,辽宁 盘锦 124000)
近年来,科学技术的蓬勃发展使工业逐渐向着现代化、智能化、精密化、自动化的方向转变[1]。工业互联网已成为当前高新技术与传统制造业相结合的重点发展领域[2]。《中国制造2025》报告中指出,针对发电、先进轨道交通和航空发动机等装备,需要开发出具有故障诊断和预测等先进的管理系统[3]。轴承在各种机械设备的运行过程中具有重要作用。当轴承的运行状态出现异常时,会导致其驱动的设备发生故障。因此,如何快速识别和诊断轴承故障,采取有效措施进行维护检修,已经成为当前工业发展中的一个重要问题[4-5]。文章以轴承为研究对象,提出了一个基于CNN[6]和BiGRU[7]的双通道模型。CNN提取振动信号的信息特征、BiGRU提取信号的时序特征,通过改进的压缩激励网络对提取的特征进行加权融合,Softmax分类器[8]对融合后的特征进行故障分类。结果表明,该模型在机械故障诊断方面具有高精确性和鲁棒性。
1 故障诊断模型
1.1 CNN和BiGRU融合模型
提出的双通道特征融合模型包含特征提取层、特征融合层和故障分类层。特征提取层由上通道CNN和下通道BiGRU组成,CNN可以提取样本数据中的信息特征,BiGRU可以在时间维度上充分提取正向和反向两个方向的时序特征。特征融合层改进了SENet模块,将两个通道提取出的特征进行加权融合。故障分类层采用Softmax分类器对融合后的特征向量进行故障分类。
1.1.1 特征提取层
在故障诊断模型中,特征提取层是一个重要的组成部分,主要是对输入的振动信号进行预处理,使其更容易被上、下通道利用。在特征提取层中,上通道采用了CNN来提取出信号中蕴含的信息特征,下通道使用了BiGRU从时序角度充分挖掘信号的时序特征。两个通道提取的特征均被输入特征融合层,通过加权融合的方式进行整合,以便进一步进行故障分类。
CNN可以自动地从原始数据中学习到特征,广泛应用在分类、检测、识别等方面。CNN的核心是卷积层和池化层,卷积层采用卷积操作对输入数据进行特征提取;池化层用于下采样和特征压缩,增强模型对位置变换的不变性。
卷积层的数学表达式为:
式中:hi——卷积层输出的第i个元素;f——激活函数;ωj——卷积核中的权重;xi-j+1——输入数据中的第(i-j+1)个元素;b——偏置。
池化层的数学表达式为:
式中:x——输入数据;y——池化层输出的结果;p、q——池化操作的大小。
通过卷积和池化操作,CNN可以将输入数据转换为高级的特征表示,实现对图像、语音等信号数据的分类、识别等。
BiGRU是一种适用于序列数据的深度学习模型,主要特点是在时间维度上采用双向结构提取时序特征。BiGRU模型具有循环神经网络的优点,可以自适应地学习序列数据中长期的时序特征,还可以通过双向结构充分利用过去和未来的信息。在双向结构下,一个BiGRU模型由两个独立的GRU单元组成,分别处理正向和反向的输入序列,且每个时刻的状态由两个方向的GRU单元共同决定,以便准确地预测下一个时刻的状态。
BiGRU模型可以表示为:
式中:xt——输入序列在时刻t的特征向量;ht——隐藏状态向量;zt、rt——更新门、重置门;~ht——新的候选隐藏状态向量;Wz、Uz、bz、Wr、Ur、br、W、U、b——可 学习 参数;tanh(Wxt+U(rt⊙ht-1)+b)——双曲正切函数;σ——sigmoid函数⊙表示向量的逐元素乘积。
1.1.2 特征融合层
SENet模块结构如图1所示。
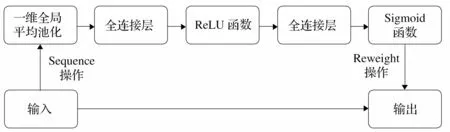
图1 SENet模块结构
特征融合层将从双通道故障检测中提取的特征向量合并,以提高故障分类准确性。采用了SENet模块进行特征融合,该模块能够自适应地学习特征向量,强化关键特征并减弱无用特征,删除冗余特征,从而提高分类效果。SENet模块最初是为图像分类任务而设计的,因此需要进行修改以适应本模型的一维特征向量输出。文章将二维全局平均池化替换为一维全局平均池化,对其进行了改进。
1.1.3 故障分类层
使用Softmax对故障做分类能够将输入向量映射到概率分布。在机器学习和深度学习领域,Softmax通常用于对模型输出的向量进行归一化处理,以便将其解释为类别概率。Softmax函数的输入是一个向量z,并对向量z中的每个元素进行指数化,除以所有元素的指数和,从而将向量转换成一个概率分布p。Softmax函数表示为:
式中:σ(z)j——输出向量中第j个元素的概率;zj——输入向量中第j个元素的值;K——向量的维度。Softmax函数的输出是一个概率分布,其中每个元素的值均介于0和1之间,且所有元素的和等于1。
2 实验与分析
2.1 实验配置
计算机配置操作系统为64位Windows11,处理器为11th Gen Intel (R) Core (TM) i7-11700@2.50 GHz,显卡NVIDIA GeForce RTX 3060Ti 8 GB,内存容量为64 GB。编程语言采用Python3.7,深度学习框架选用TensorFlow。
2.2 数据集
文章使用的实验数据来自美国凯斯西储大学数据中心的滚动轴承故障数据集。该数据集是研究轴承故障研究的标准数据集,使用此数据集进行实验具有权威性[9-10]。该数据集包含了4种不同的滚动轴承故障,包括外圈故障、内圈故障、滚珠故障和铁皮隔离器故障以及正常工作状态的数据。数据集采集了从加速度传感器和接收器中采集的振动信号,其中外圈故障、内圈故障和正常状态的振动信号数据由12个不同工况的试验采集而成,滚珠故障和铁皮隔离器故障的振动信号数据由3个不同工况的试验采集而成。
2.3 模型训练过程
将原始轴承振动信号进行预处理和滑动窗口切割,将数据集按照8∶1∶1的比例划分为训练集、验证集和测试集。
初始化模型参数,将训练集数据分别输入到CNN和BiGRU中进行特征提取,利用SENet模块将提取的特征进行融合,计算输出向量与期望值之间的损失函数,利用Adam进行调优。
根据损失函数判断模型是否满足要求,若满足则保存模型的训练参数,否则需要重新训练模型。
模型训练结束后,利用测试集进行测试,将提取的特征向量输入到Softmax层进行故障分类,最后输出诊断结果。
2.4 实验结果分析
研究轴承在实际工作中可能出现的9种故障类型以及1种正常工作类型。
选择每种故障类型的2 000个样本进行研究,对每个样本进行了2 048个数据采样点的采集。使用onehot编码标记每个样本的标签。在样本预处理过程中,将样本输入形式设置为2×1 024,其中2是GRU单元个数,1 024是每个单元的输入长度。该设置可以有效避免样本序列过长无法直接处理,提高计算效率。
迭代中准确率变化曲线如图2所示。
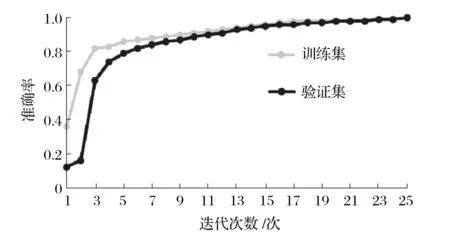
图2 迭代中准确率变化曲线
由图2可知,在前5次迭代中,训练集和验证集的准确率快速提升。在第10次迭代时,两者的准确率均稳定在90%以上。当迭代达到20次左右时,模型的训练趋于平稳,且准确率值接近100%,损失函数值接近0.01。对比训练集和验证集的准确率,发现训练集比验证集更快地收敛,且初始值更高。结果表明,数据量对模型的收敛有影响。由图中曲线变化可知,除了验证集前几次迭代出现折线外,整体曲线基本平滑,表明模型的稳定性良好。
为了排除实验结果偶然性,进行了10次试验并计算平均值。结果显示,10次试验中有7次故障分类准确率达到100%,只有3次出现误判,说明模型具有良好的鲁棒性。模型的平均准确率为99.83%,平均误判样本数为0.9个。准确率最低为99.4%,对应的误判样本数为0.9个,即平均每次试验可能会有0.9个样本出现误判,表明模型具有较好的故障分类性能。
3 结语
文章提出了一种用于轴承故障诊断的模型,该模型由三层组成。特征提取层将输入的样本数据分别传递给上下通道CNN和BiGRU进行特征提取。在特征融合层中对SENet网络进行了改进,将全局平均池化从二维替换为一维,并将两个特征向量进行加权融合。在故障分类层中使用Softmax分类器对融合后的特征进行故障分类。结果表明,提出的故障诊断方法在性能和鲁棒性方面表现良好。
