基于知识图谱的远程监督关系抽取降噪方法
2023-11-20赵晋斌马黎雨李学思
赵晋斌,王 琦,马黎雨,李学思
(北京市遥感信息研究所,北京 100193)
0 引言
关系抽取(relation extraction,RE)旨在从无规则的文本数据中提取出结构化知识三元组,可以为知识图谱构建等下游任务做准备。这些结构化的实体关系三元组会被存储于关系型数据库或图数据库中,以便计算机更好地理解和利用这些知识。在关系抽取任务中,目前效果最好的模型是基于有监督的关系抽取方法[1],但该方法的局限性在于数据集的数量和质量,很多领域不具备公开数据集,并且不同领域的文本数据具有不同的特点。在实际生产生活中,很多企业并不想花费过多的成本来标注大量的高质量数据。
为解决上述问题,MINTZ 等提出远程监督(distant supervision,DS)技术[2],其基本假设是:如果在某个知识图谱中,已经证实实体h 与实体t 存在关系R,则所有包含(h,t)的句子都可以表达关系R。该假设被称为Vanilla 假设。基于这种假设,给定一个知识图谱和一个文本语料集,便可以快速构建一个远程监督数据集。远程监督是一种通过文本之外的大量实体对和关系构成的知识库对文本进行关系标注的方法。在这种方法中,“远程”表示利用了文本之外的知识图谱,而“监督”表示提供了关系标签(即监督信息)。通过这种方式,可以自动地标注文本中实体对之间的关系,从而帮助计算机理解和利用这些知识。远程监督方法不需要人工进行标注,节省了时间成本和经济成本,是从无标注的文本语料集中实现自动关系抽取的关键一步,能很好地解决关系抽取领域训练样本极度匮乏的问题[3]。目前,远程监督技术在情感分析、词性标记、对话系统、命名实体识别及其他领域均有广泛应用[4-7],且发挥着前所未有的作用。远程监督思想的运用成功实现了低成本、大规模的快速标注,极大地降低了人力成本,既充分利用了知识图谱,又为知识图谱的进一步扩充做好准备,在关系抽取任务中发挥着越来越重要的作用。
远程监督的强假设使得大批量快速地对文本语料进行标注成为可能。通过命名实体识别技术或者文本强匹配技术,可以快速得到句子中所包含的所有实体,再根据实体对从知识图谱中遍历关系,即可快速完成对数据集的扩充。远程监督为关系抽取提供大规模标注数据的同时,也带来了错误标注问题,由于假设与事实并不相符,使得生成的数据包含大量错误标签,降低错误标注引起的噪声影响对于提高知识图谱的数据质量非常重要。因此,本文探索了一种基于知识图谱的远程监督关系抽取降噪方法,通过丰富的知识图谱实体属性信息,提高关系抽取准确率。
1 相关工作
关系抽取是用于从海量文本数据中快速提取结构化信息的一种有效的方法[8]。它利用机器学习进行建模,从文本中提取实体之间的语义关系,并以<实体1,关系,实体2>的三元组形式存储和展示这些关系。通过这种方式,文本中蕴含的重要信息可以被有效地捕捉和表示。起初,关系抽取任务是指识别命名实体并对其进行关系分类。随着深度学习技术的不断发展,命名实体识别任务被独立地处理。在本文所研究的关系抽取任务中,首先进行了命名实体识别,然后在识别出的实体基础上进行分类任务,即提取实体之间的语义关系。这种分阶段的处理方法,能够更好地捕捉文本中实体之间的关联信息,并有助于提高关系抽取的准确性和效率。
传统基于深度学习的有监督关系抽取方法严重依赖标注数据集,而面向不同行业领域,标注结果可能大相径庭,且数据量的激增也提升了标注难度。为了解决这一痛点,MINTZ 等提出了远程监督的思想,以应对有监督关系抽取数据集严重缺乏的挑战,只需要一个关系信息较为完善的知识图谱,便可对语料集快速进行标注,但远程监督的强假设带来了错误标注问题。
尽管远程监督构建的数据集中的实体对确实存在某种关系,但并非所有句子都能准确地传达这种关系信息。大多时候两个实体出现在同一句子中,是因为这两个实体均和该句子所表达的主题相关联,而不是该对实体有直接的关系,这种现象被称为“共主题”现象。此外,Vanilla 假设一个实体对只有一种关系存在,但在现实情况中,一对实体往往不止一种关系,表达不同关系的句子示例往往具有不同的特征。例如,(约瑟夫·拜登,美国)这个实体对可以是“总统”关系,也可以是“居住于”关系,这种现象被称为“多关系”。如果不考虑“多关系”情况的存在,模型将会学习到错误的句子特征,从而影响关系抽取模型的最终性能。上述问题均属于错误标注问题。
针对错误标注问题的抽取方法,以降低远程监督数据集中的噪声为目的,通过尽可能地识别噪声数据来获得数据质量更高的训练集,以提高关系抽取模型的准确率。根据对噪声数据不同的处理方式,主要分为硬决策方法和软决策方法。硬决策方法对噪声数据态度较为强硬,认为这些噪声数据对模型没有任何帮助效果,直接删除噪声数据。QIN 等针对假阳性问题,提出一种使用强化学习策略来生成假阳性样本的方法,在没有任何监督信息的情况下自动识别每种关系类型的假阳性[9]。FENG 等提出一种从噪声数据中进行句子级别的关系分类的方法,通过强化学习过滤掉低置信度的噪声句子,不断优化关系分类器以获得更好的抽取效果[10]。软决策方法与硬决策方法相反,可以容忍数据中噪声的存在,认为这些噪声数据对模型可能具有一定的帮助效果,但帮助效果较小,故对不同句子或句子包分配不同的权重,以降低噪声数据对模型整体抽取效果的影响。HU 等在关系抽取中采用了多层注意力机制来充分利用关系标签中蕴含的信息。结合了知识图谱的结构信息和实体描述的文本信息,通过门控集成学习标签嵌入的方法,有效地进行关系抽取[11]。同时,运用了注意力机制来降低噪声影响,并选择性地处理实例,以实现更准确地关系分类。这种方法能够提高关系抽取的效果并更好地利用数据集中的信息。
硬决策方法和软决策方法均默认关系标签正确,针对噪声句子进行处理,但实际中存在一种包含该实体对的所有句子均无法体现该关系的特殊情况,即关系标签存在噪声。XU 等统计了NYT 数据集中包括真阴性样本在内的正确标签实例的占比,证明确实存在关系标签错误的情况[12]。WU 等的方法采用基于神经噪声转换器的技术,以缓解噪声数据对关系抽取的影响[13]。通过捕获远程监督关系抽取数据集中的属性信息,利用条件最优选择器来进行更加合理和准确的关系预测。SHANG 等认为噪声标注问题的根本原因是关系标签的缺失,提出一种基于无监督的深度聚类方法,利用句子编码器获取特征表示,利用噪声检测器检测句袋中的噪声句子,利用标签生成器来标记噪声句子的关系标签[14]。李兴亚等提出了一种融合门控机制的远程监督关系抽取方法,首先在词级别上通过自动选择正相关特征,来过滤与关系标签无关的词级别噪声,然后利用门控机制降低硬标签对噪声过滤的影响,最后结合句子级别的噪声过滤[15]。
基于深度学习的远程监督关系抽取方法,可以利用大规模的知识库进行训练,从而可以快速扩展到新的关系类型和领域。深度学习模型具有很强的表征能力和自适应能力,可以有效地提取实体和关系之间的语义信息,从而提高远程监督关系抽取的准确性。然而,上述方法致力于对数据集中句子本身的相关信息进行创新,没有结合实体的信息。因此,本文创新性地使用知识图谱作为外部知识信息,补充完善实体含义,提升模型的特征捕获能力。
2 基于知识图谱的关系抽取模型
2.1 模型架构
本节将对基于生成对抗网络和图注意力网络的降噪方法做详细的介绍,模型的整体框架如下页图1 所示。
1)生成对抗网络:给定一组用远程监督标记好的句子,生成器试图从中生成真正的正样本,但这些生成的样本被视为负样本以训练鉴别器。因此,当完成扫描远程监督阳性数据集一次时,生成器发现的真实阳性样本越多,鉴别器获得的性能就越明显。在对抗训练之后,获得一个强大的生成器,它能够迫使鉴别器最大程度地丧失其分类能力。数据集经生成对抗网络进行清洗降噪后,输入到异构信息图构建模块中。
2)异构信息图构建:数据集经过生成对抗网络清洗后,分别将两个实体的描述、别名、类别等信息和句子的字嵌入和词嵌入拼接到一起,经过ALBERT 进行特征提取,最后拼接为用于输入表示的异构信息图(heterogeneous information graph,HIG)。
3)图编码层:异构信息图包含着两个实体的相关信息,图编码层将图注意力的思想引入到远程监督关系抽取任务中,对异构信息图进行特征提取。GAT 结合了图卷积网络和自注意力机制的优点,对不同邻居节点赋予不同的权重。GAT 网络更关注节点的重要相邻节点,并在保留全局信息的同时提高了节点表示的表达能力。
4)分类层:将图编码层得到的两个实体和句子的表示相结合,输入到模型M 中,对其进行分类。
2.2 生成对抗网络
本文使用远程监督生成对抗网络对数据集进行初步降噪[16],通过生成对抗网络获取基于句子层面的生成器,与传统的生成对抗网络中用于生成新数据的生成器不同,该网络的生成器作用是识别数据集中的噪声数据,对训练集进行降噪来提升后续关系抽取模型的表现效果。
训练生成对抗网络前,首先需要对生成器和鉴别器进行预训练,生成器的训练数据包括了正例数据集P 和负例数据集NG,鉴别器的训练数据包括了正例数据集P 和负例数据集ND,这里数据集NG和ND不重合。预训练后鉴别器能够很好地区分正例和负例数据;此外,生成器要对正例数据集P 过拟合,这样可以在正式训练时尽可能地干扰鉴别器。
正式训练时,将正例数据集P 切割成若干个集合(Bag),分割后P={B1,B2,…,BN},其中,Bi={s1,s2,…,sn},依次将每个集合Bi的数据输入到生成器中,让生成器对于每个输入的句子进行打分,将得分高于阈值的数据标注为负例(该数据由Bi-T 表示)、得分低于阈值的标注为正例(该数据由T 表示),重新标注后的句子输入到鉴别器中,将鉴别器的鉴别结果作为生成器反向求导调参的依据。这里生成器的损失函数如式(1)所示:
鉴别器的损失函数如式(2)所示:
每输入一个集合,生成器和鉴别器都要进行参数更新,鉴别器的梯度和参数更新如式(3)和式(4)所示:
每输入生成器的目标和单步强化学习的目标类似,因此,这里使用基于策略的梯度函数来更新生成器的参数。与强化学习相对应的,sj可以表示成状态,而pG(sj)为该状态对应的策略,为了更好地反映生成器的质量,奖励函数由以下两部分组成:
1)作为生成对抗网络,希望生成器生成的数据在判别网络中能够得到更高的分数,因此,有如公式所示的奖赏函数:
2)将通过鉴别器的性能来判断生成器当前的性能,当生成器性能越好时它生成的数据将难以被鉴别器识别为反例,则鉴别器的性能会逐步下降,因此,有如式(6)和式(7)所示的奖赏函数:

当奖励值计算结束之后,生成器的梯度和参数调整如式(8)和式(9)所示:
当所有的集合都输入完毕后计为一轮的迭代,每一轮迭代后,都要计算鉴别器在数据集ND上的准确率ACCD,当ACCD不再下降时则停止迭代。
在每一轮迭代之前,鉴别器都会重新加载其预训练好的参数,这样做有以下两个原因:第一,训练生成对抗网络的目的是获得一个鲁棒性强的生成器,而不是获得一个鲁棒性强的鉴别器,第二,生成器目的是识别出噪声数据而不是生成新数据。这样一来,鉴别器很容易崩塌(即鉴别器将会无法区别正负例)。对此增加了一个衡量生成对抗网络训练效果的策略:生成器的鲁棒性越强,在一轮迭代过程中会让初始参数相同的鉴别器的表现下降得越快。
在对抗性学习过程之后,每一种关系类型都可以获得一个生成器,这些生成器具有为相应的关系类型生成真正样本的能力。因此,可以使用生成器过滤来自远程监控数据集的噪声样本。模型利用生成器作为二进制分类器。为了达到数据的最大利用率,制定了一个策略:对于一组带注释句子的实体对,如果这些句子都被生成器判定为假阴性,那么这个实体对将被重新分配到负集中。在此策略下,远程监督训练集规模不变。
2.3 异构信息图构建
首先,从Freebase 和Wikidata 知识图谱中提取实体对的实体属性(Ate)。对于知识图谱的上下文信息,使用实体最常用的属性:别名、描述、类别和标签[17]。在图构建步骤中,图1 给出了各种实体属性示例。ALBERT 是采用双向Transformer 获取文本的特征表示。
使用ALBERT 将句子通过连接其词和字符嵌入转换为另一种表示,如式(10)所示:
同理,为每个实体ei创建类似的表示,其中i=(h,t),如式(11)所示:

2.4 图编码层
由于模型期望选择合适的上下文信息,不同属性对关系抽取的帮助效果是不同的,甚至某些属性并不能帮助获取实体特征,因此,在HIG 的基础上,需要对不同特征赋予不同的权重。GAT 将注意力机制应用于空间域中,与使用拉普拉斯矩阵进行复杂计算的其他方法不同,该网络可以仅通过自身文本的图结构来完成内在的特征更新,更简便快捷地精确计算出图结构的向量表示。

式中,hij表示注意力分数,||表示向量拼接操作,a 表示注意力向量,用于拼接节点i 和j 的特征表示,(·)T表示向量转置操作,αij表示注意力系数,Ni表示包括i 节点自身在内的所有一阶邻居。
得到注意力系数后,可以使用邻居特征的加权和更新中心节点的表示,具体更新方式如式(16)所示:
式中,zj为节点j 经过特征变换后的向量表示,σ 为非线性激活函数。
在GAT 中,多头注意力机制被运用以增强学习的稳定性。对于每个中心节点,会进行K 次独立的图注意力计算,然后将这K 次计算的结果合并,得到该节点的最终向量表示,具体如式(17)所示:
2.5 分类层

3 实验与分析
3.1 数据集
本文研究使用的数据集为远程监督关系抽取领域最常用的NYT10 数据集,该数据集由RIEDEL等于2010 年提出[19]。其文本来源于纽约时报(The New York Times)所标注的语料,包含超过170 万篇新闻文章和400 万个实体之间的关系,涵盖了不同类型的实体,包括人、组织、地点、工作、电影等。其中,涉及到的关系包括常见的家庭成员、就职、成立、出生地等,以及一些特殊关系,如“被任命为”的关系。在本文中,命名实体是通过使用Stanford NER工具,并结合Freebase 知识库进行标注的。而命名实体对之间的关系则是通过链接和参考外部的Freebase 知识库中的关系来获得的,这是结合了远程监督方法的结果。数据集共包含53 种关系,包含一种特殊的“NA”关系,表示句子不能体现两个实体之间具有关系。然而,该数据集存在着噪声问题和长尾分布问题,因此,有研究者对其进行了修改。但由于NYT10 数据集更贴合实际生产工作中的数据集情况,故本文依旧选择使用更具原始性和真实性的NYT10 数据集。表1 展示了该数据集的数量统计情况。

表1 NYT10 数据集详细数量统计Table 1 Detailed quantity statistics for NYT10 dataset
由于本文模型需要借助知识图谱中的知识信息,故使用两个标准英文知识图谱数据集Wikidata和Freebase 作为实体上下文信息支撑。
3.2 实验设置
该实验的训练与测试均在Ubuntu18.04 的操作系统上运行,使用的CPU 为Intel(R)Xeon(R)Platinum 8358P CPU @ 2.60 GHz,GPU 为NVIDIA GeForce RTX 3090,Python 版 本 为py3.8,并 基 于Pytorch 1.11.0 版本的深度学习框架,CUDA 版本为11.6。
本实验在模型中选用的ALBERT 为大小只有BERT 的1/25 的ALBERT_TINY,训练速度较BERT提升10 倍,参数大小仅为1.8 M。将句子和实体的字嵌入和词嵌入拼接,作为输入向量送入ALBERT中获得其基于上下文的语义特征,将编码构成的异构信息图与图注意力机制进行结合来获取句子和实体的特征向量,最后经过模型M 进行分类。为防止过拟合现象,采用Dropout 策略随机将神经元的输出设置为0[20]。经过多次实验验证后,模型的最终超参数设置如表2 所示。
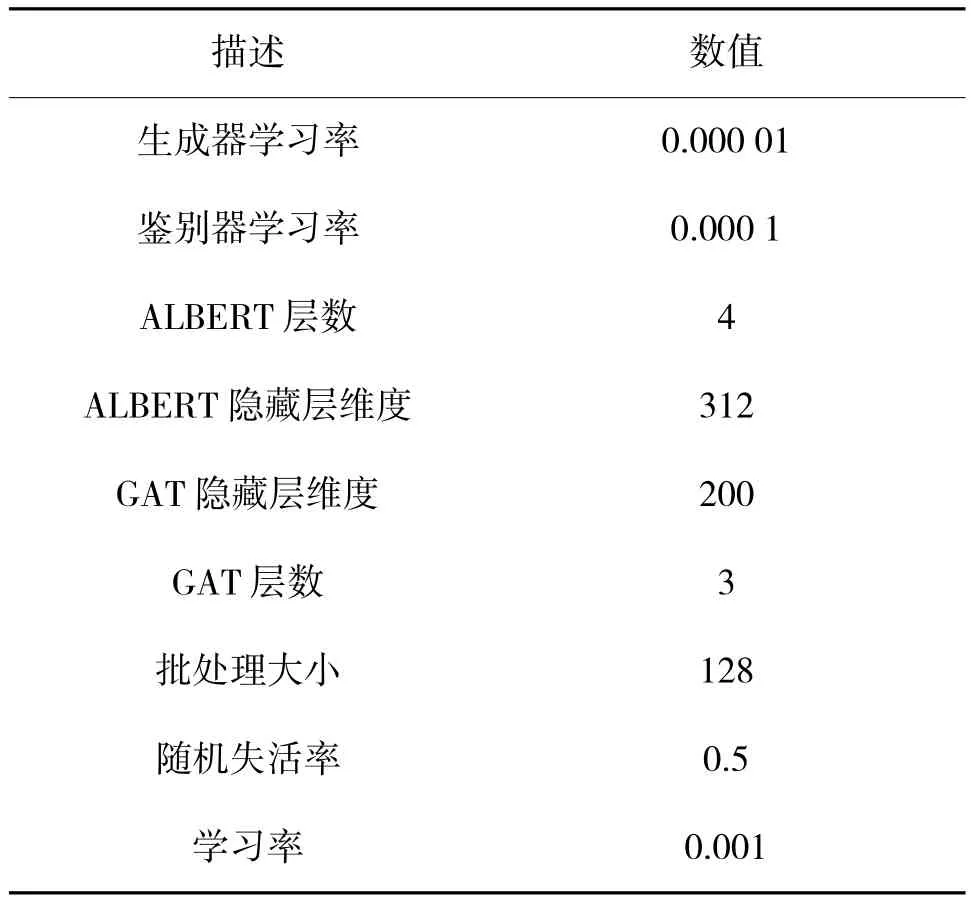
表2 模型超参数设置Table 2 Model hyperparameter settings
3.3 评价指标
本文从准确率(precision)、召回率(recall)与F1值3 个方面全面评估模型的效果。为了进行评估,将测试结果根据真实结果和预测结果的差异分为四大类:真正例(TP)、假正例(FP)、假反例(FN)、真反例(TN)四大类。准确率是指在所有预测结果为正例的实例中真正例的比例,召回率是指在真实情况下正例被预测准确的比例。F1 值基于调和平均综合了准确率、召回率指标,计算方式如公式所示:
3.4 实验结果与分析
3.4.1 模型对比实验
为了更好地评估DSGAN+KGGAT 模型的效果,选择了6 种具有代表性的远程监督关系抽取模型,与本文所提出的DSGAN+KGGAT 模型进行了对比实验,相关模型介绍如下:
1)MINTZ[2]:2009 年MINTZ 等提出远程监督的思想来解决有监督关系抽取数据集严重缺乏的问题,利用关系信息较为完善的知识图谱,对语料集快速进行标注,并对构建的数据集进行关系分类。
2)MIML[21]:2012 年SURDEANU 等提出一种面向关系抽取的多示例多标签学习方法,该方法使用带潜变量的图模型联合建模文本中一对实体的所有实例及其所有标签。
3)PCNN[22]:2015 年ZENG 等按照两个实体位置,将句子分割为3 部分,然后对其分别进行卷积和池化操作,再将其进行拼接后进行关系抽取。
4)APCNN[23]:2016 年,LIN 等提出了一种新的关系抽取模型,该模型基于句子级别的注意力机制。使用卷积神经网络来嵌入句子的语义信息,并通过在多个实例上构建句子级别的注意力来降低噪声实例的权重。
5)BGWA[24]:2018 年JAT 等将基于门控循环单元的词注意力模型、PCNN 和改进的实体注意力3 个模型,使用加权投票法进行组合来进行关系抽取。
6)RECON[17]:2021 年ANSON 等提出的一种能利用知识图谱知识的模型,使用图神经网络来学习句子和存储在知识图谱中实体的表示,提高了整体提取质量。
将上述模型针对NYT10 数据集进行复现,并与本文提出的DSGAN+KGGAT 模型进行实验对比。准确率、召回率和F1 值与其他模型的对比结果如表3所示。从表3 中可以看出DSGAN+KGGAT 模型相比于其他模型达到了F1 值为0.901 的最优结果。
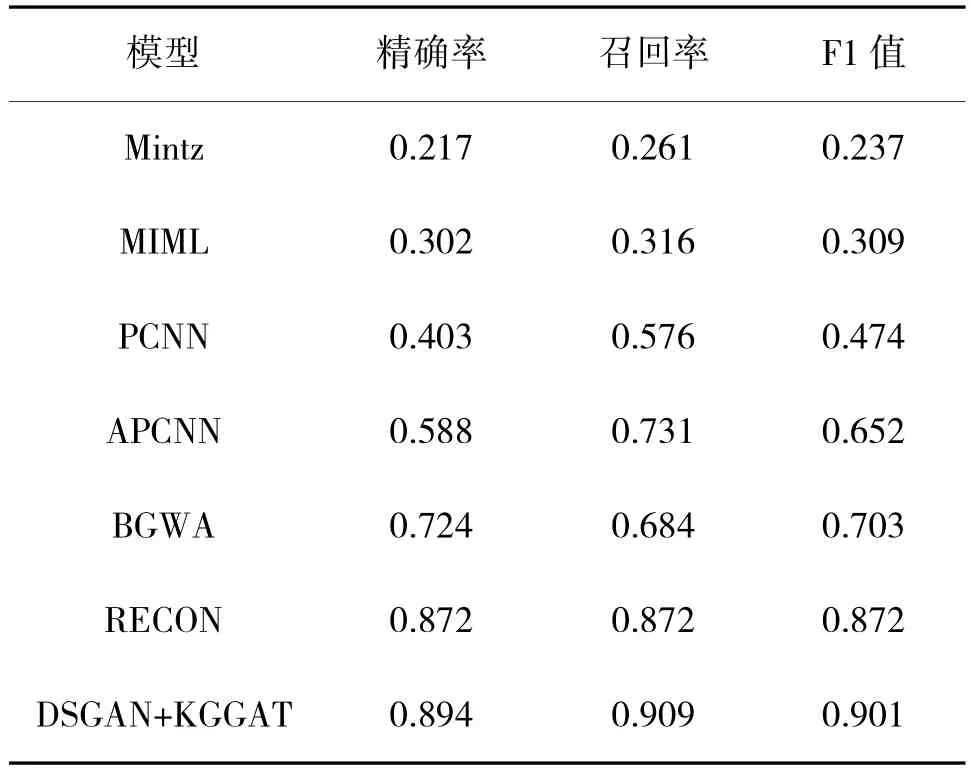
表3 模型对比实验结果Table 3 Model comparison experiment results
采用基于特征模型的MINTZ 和MIML 方法在特征选择和NLP 工具处理数据时容易出现误差传播问题,特征模型的设计和选择需要有一定的领域知识和经验,同时需要对不同模型的优缺点有一定的了解,否则可能会影响模型的效果。因此,其效果表现明显不如基于深度学习的远程监督关系抽取方法。MIML 方法使用多示例多标签的假设,在一定程度上缓解了强假设带来的噪声问题,更加符合实际情况,所以其抽取效果相较MINTZ 模型有了一定的提升。神经网络可以自动学习句子特征,从而避免这种问题的出现,这也是神经网络在关系抽取中表现优异的原因之一。
PCNN、APCNN 和BGWA 模型均为基于神经网络的远程监督关系抽取方法,神经网络可以自动学习句子特征,从而避免人工根据先验知识干预模型,这是神经网络在远程监督关系抽取中表现优异的原因之一。PCNN 模型根据远程监督的特点,根据实体位置将句子分割为3 部分进行卷积操作,更容易提取句子特征,较基于特征模型的远程监督关系抽取方法,有了较大的效果提升。APCNN 在PCNN模型的基础上,融入了句子级别的注意力机制,可以更好地对句子进行降噪,效果进一步提升。BGWA在PCNN 模型的基础上,融入了BiLSTM 模型和实体注意力机制,采用加权投票的方法弥补了每个模型的不足,获得了更好的抽取效果。
RECON 和DSGAN+KGGAT 模型均为利用知识图谱上下文信息的方法,相较于其他未融合知识图谱上下文信息模型,具有较大的优势。知识图谱中蕴含的实体属性信息对远程监督关系抽取降噪任务具有一定的作用,例如属性中的描述可以帮助模型理解实体包含的语义信息,增强实体的特征表达;属性中的实体类别可以帮助限定关系的类别。这证明了结合知识图谱的上下文信息对远程监督关系抽取具有很大的帮助作用。RECON 模型虽然也融合了知识图谱的上下文信息,但其并未用图结构对实体和实体属性的表示进行关联,而是利用一维卷积神经网络对其进行特征提取,这种方式使得后续无法调整实体属性的重要性,一些无关的实体属性会降低模型效果。而DSGAN+KGGAT 使用异构信息图对实体信息和句子信息进行嵌入表示,并利用图注意力机制合理分配节点权重,最终的向量表示更加合理,在F1 值相较于RECON 模型,提高了约2.89%。
综上,DSGAN+KGGAT 模型相较于其他远程监督关系抽取降噪模型更能保证模型预测的准确性,符合实际应用的要求。
3.4.2 消融实验
为证明所提模型的创新性和有效性,在本文所使用的数据集上进行消融实验。本研究针对基准模型——KGPool 进行了消融实验[25]。KGPool 模型首先在图编码层使用BiLSTM 模型作为实体和句子的编码器,然后使用GCN 与池化操作获取异构信息图的向量表示,最后经由多层感知机进行分类。DSGAN+KGPool 表示数据集先经DSGAN 模型降噪,再使用KGPool 模型进行关系抽取;KGPool+ALBERT 表示KGPool 模型在构建异构信息图时,使用ALBERT 代替BiLSTM 进行实体编码和句子编码;KGPool+GAT 表示KGPool 的图编码层使用GAT代替GCN+Pooling 对异构信息图进行编码。所有对比模型在准确率、召回率和F1 值上的对比结果如表4 所示。相较于基准模型KGPool,本章模型在准确率、召回率和F1 值上分别提升了约0.80%、2.26%和1.52%。
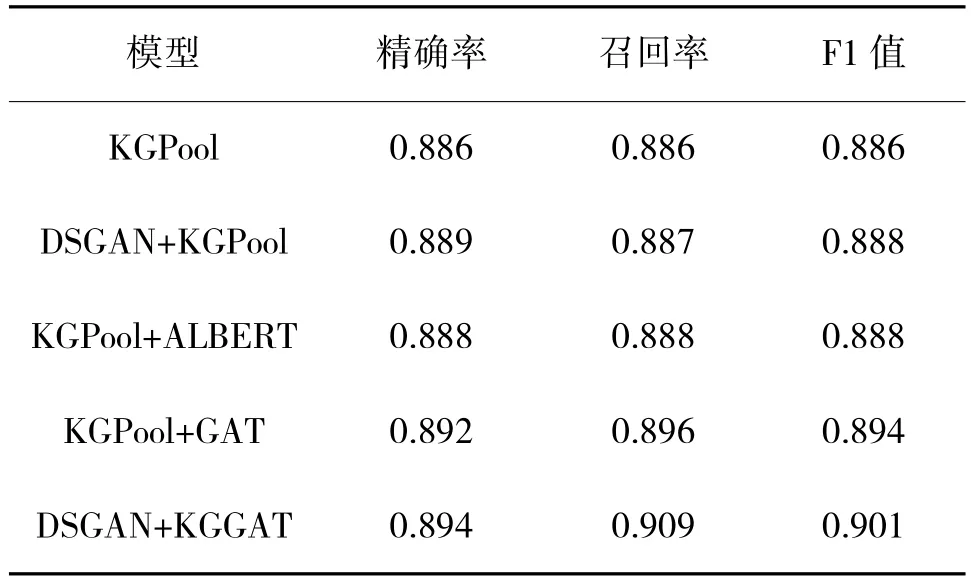
表4 消融实验对比结果Table 4 Comparison results of ablation experiments
DSGAN+KGPool 模型相较于KGPool 模型在准确率、召回率和F1 值3 个指标上均有提升。这表明在模型数据集上进行样本清洗有助于模型效果的提升。DSGAN 可以通过对抗学习得到一个可以对数据进行清洗的生成器,利用该生成器对数据集中所有的句子进行二分类清洗,从而提高数据集整体质量。
KGPool+ALBERT 模型与KGPool 模型仅在实体编码器和句子编码器上存在区别。ALBERT 使用Transformer 模型,可以同时考虑整个句子的上下文信息,而BiLSTM 只能考虑左右各自一定范围内的上下文信息。由于ALBERT 使用参数共享,它比BiLSTM 更具鲁棒性。这表明,经过ALBERT 模型对于提取实体和句子信息具有更强的能力,对解决远程监督关系抽取任务的噪声问题具有一定的帮助。
KGPool+GAT 在图编码层直接使用GAT 对异构信息图进行编码,取得了较优的结果。不同于KGPool 模型使用GCN 对不同属性赋予相同权重,KGPool+GAT 使用GAT 模型进行特征提取,GAT 相较于GCN 模型具有更好的表达能力,GAT 在学习节点嵌入时采用了自注意力机制,可以对每个节点与其邻居节点的重要性进行动态调整,从而更好地捕捉节点之间的关系,提高了表达能力。同时,GAT中的注意力机制避免了全局矩阵乘法操作,改用点乘的形式计算,大幅度减少计算量并提高了计算效率。这表明实体中不同的属性信息对于关系预测的重要程度不同,对异构信息图中不同节点分配不同权重能提高关系抽取模型的整体效果。
本文所提的DSGAN+KGGAT 模型相较于上述4 个模型,取得了最优的准确率、召回率和F1 值。DSGAN 模块能在数据集层面对样本进行初步降噪,获得了质量更高的数据集。在此数据集的基础上,ALBERT 在预训练过程中使用了大量的数据和任务,这使得它能够学习到更通用的语言表示,从而在远程监督关系抽取任务中具有更好的泛化能力,获取实体知识向量表示和句子向量表示方面有着更好的效果,ALBERT 通过参数共享和句子顺序预测任务来减少参数数量,从而在保持性能的同时大幅减少了模型的大小。相比之下,BiLSTM 需要较多的参数,并且计算效率相对较低。GAT 模块利用注意力机制对不同邻居节点分配不同的权重,可以提取异构信息图中更合理的信息表示。相比之下,KGPool 模型的图编码层需要进行卷积和池化操作,具有更高的模型复杂度。ALBERT 和GAT 模型的使用为降低模型的整体复杂度做出了一定的贡献。这3 个模块分别从数据层面、图构建层面、图编码阶段提高模型效果,进而提升远程监督关系抽取降噪任务整体的效果。
4 结论
针对远程监督关系抽取所带来的共主题、多关系等错误标注问题,本文提出一种基于知识图谱的远程监督关系抽取降噪方法。该架构从数据层面和模型层面分别对数据集进行降噪处理。首先利用生成对抗网络中的生成器,对样本数据进行数据清洗;其次结合知识图谱中实体的相关信息,利用ALBERT 对其进行编码,构建异构信息图;然后利用图注意力网络,给不同节点赋予不同权重;最后经由多层感知机对关系进行分类。通过对比实验,此方法在NYT10 数据集上取得了较优的效果,证明了知识图谱蕴含的实体信息,可以帮助降低远程监督关系抽取任务数据集的噪声,提高关系抽取准确率。后续工作可以考虑利用实体类型和关系类型的约束关系,并结合代表同一关系的不同句子的语法特征进行进一步降噪,以提高模型的鲁棒性。
