基于开源文本数据的目标跟踪方法
2023-11-20李嘉琦钟紫凡付阳辉曾泽凡
李嘉琦,钟紫凡,付阳辉,曾泽凡,成 清
(1.国防科技大学系统工程学院,长沙 410073;2.解放军31539 部队,北京 100000;3.湖南省先进技术研究院,长沙 410073;4.国防科技大学大数据与决策实验室,长沙 410073)
0 引言
在互联网时代背景下,央视网、环球网等高质量的新闻网站平台以及微博、脸书等热门社交平台拥有庞大的用户群体,互联网成为人们日常交流、分享、传播和获取信息的重要平台。文本是海量信息数据呈现的重要载体,人们在享受互联网带来便利的同时,也被繁重的信息所困扰。爆炸式的信息增长让人们考虑如何自动化地从繁杂冗余的信息中抽取出感兴趣的信息,同时也为情报分析提供了大量可实时获取的碎片化文本数据,使得实现军事目标相关活动事件及其演化进程的快速追踪成为可能。
近年来,国内外研究机构和学者开展了一系列基于事件抽取的研究,随着深度学习技术的不断发展,越来越多神经网络应用于事件抽取中,如卷积神经网络(convolutional neural network,CNN)[1-2],递归神经网络(recurrent neural network,RNN)[3-4],图形神经网络(graph neural network,GNN)[5],或其他网络。深度学习方法能够捕获复杂的语义关系,可以显著提高事件抽取系统的性能。文献[6]提出了一种基于事件模式及类型的事件检测深度学习模型,阐述了潜在论元概念和论元识别的一种技术方案,文献[7-8]对事件融合、实体对齐的研究做出了详细报告,并对基于知识表示学习的实体对齐方法进行了对比分析,文献[9-10]提出社交文本事件聚类的不同方法,用以辅助进行事件预测与监管。
针对在社交媒体和社交网络场景下跟踪目标事件发展状况的需求,本文提出一种基于开源数据事件抽取的目标跟踪方法,通过构造主题事件线实现目标事件的演化分析,并开发目标跟踪应用。
使用信息抽取的方法从开源情报文本中抽取目标及其活动事件。首先,从原始情报文本中检测出事件类型,并识别出触发词;然后抽取出目标、时间、地点以及其他事件论元,将所有事件元素进行组装得到事件对象
通过实体对齐、等价事件匹配和冲突事件检测对抽取的事件进行融合,去除噪声事件。首先,通过实体对齐技术将目标实体与构建好的装备实体库中的实体对齐;然后,扫描各目标实体的事件集合,综合主体、时间、地点3 个方面的匹配关系判断事件的等价性,将等价事件进行合并;最后,定义不可能事件,将符合不可能事件定义的事件组合判定为冲突事件,并依据情报来源权威性和提及次数对冲突事件的可信度进行评估和对比。
基于事件的隐式语义信息对事件进行聚类并归纳得到事件簇的主题,通过梳理事件簇的时间脉络追踪主题事件的演化过程,首先,依据事件的隐式语义信息对事件集合中的事件进行聚类得到主题事件簇,即故事;其次,依据目标名称对故事中事件进行分组,得到目标事件集合;然后,整合目标事件集合中所有事件的情报文本,提取文本摘要作为事件簇的主题;最后,梳理目标事件时间脉络,生成带主题的目标事件线。
为了解决事件线生成问题,进而以目标为中心实现主题相关的系列事件脉络跟踪,本文设计目标跟踪应用的技术架构如图1 所示,该应用主要包含了三大部分功能。首先,通过事件抽取得到格式化的事件对象,再通过事件融合整合等价事件以及解决事件冲突,最后并为各个目标事件集合生成带主题的故事,从而基于主题事件脉络追踪目标的活动过程。
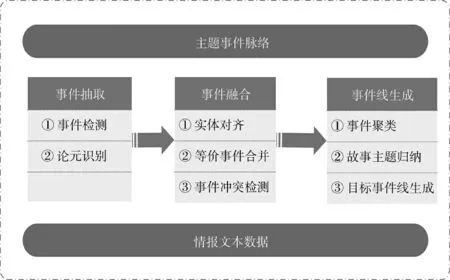
图1 目标跟踪应用技术架构Fig.1 Technical architecture of object tracking application
1 事件抽取
事件抽取组件以目标为中心从情报中提取事件要素并组装为事件对象,为后续目标事件的演化分析提取事件特征,主要需实现事件检测和论元识别两大功能。
事件是发生在某个特定时间点或时间段、某个特定地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变[11]。时间、地点、主体、事件类型是组成事件的基本要素,一个复杂的事件可能还包含了客体等论元,于是用结构化的对象表征事件,可视化事件特征。
在事件抽取的过程中,使用基于标签注意力机制的事件检测模型EDLA[12]从预设的事件类型中检测出与情报语义相吻合的事件类型;然后用基于机器阅读理解的论元抽取方法,提取目标名称及相关事件要素;最后,整合目标名称、事件类型和事件要素得到结构化的事件对象。
为了构造完整的事件对象,使用基于MRC 的论元识别方法,从情报I 中抽取出目标角色r[13]、时间t、地点L 等核心事件要素以及论元集合A 定义的其他论元{a1,a2,…}。该方法通过注意力机制层充分利用问句中的事件类型信息和事件元素类型信息,无需人工构造复杂的问句。因此,可迁移性好、实现简单。另外,针对无答案的情况,该方法使用两个特殊标识符来进行表示,使得模型可以筛选和过滤出无答案的问句,从而获得含有答案的输入数据。基于MRC 的论元识别模型如图2 所示。输入数据经过BERT 和BiLSTM 层之后[14],分别连接两个全连接网络,得到答案或事件元素的开始位置序列和结束位置序列。
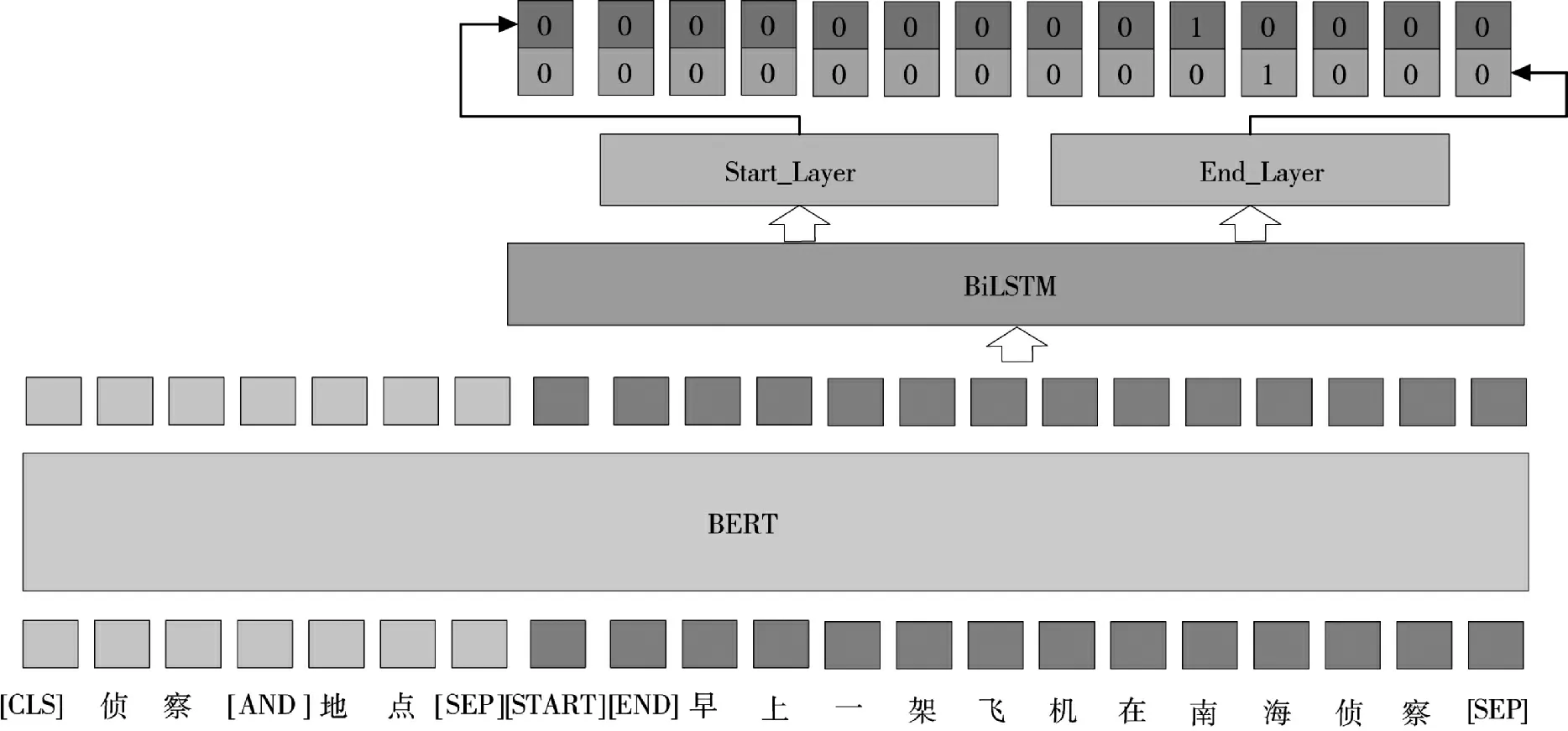
图2 基于MRC 的论元识别模型Fig.2 Argument recognition model based on MRC
基于MRC 的事件抽取方法预测流程图3 所示。
2 事件融合
事件融合旨在实现事件对象的唯一化,通过处理等价事件和冲突事件,去除噪声数据和冗余数据,获得高质量的结构化事件数据集。
在事件融合的过程中,首先使用实体对齐方法将目标实体与装备实体库中的实体进行对齐,将目标分布映射到低维空间;然后,按目标和时间组合事件,并扫描各个事件组,根据地点是否相似判别事件的等价性,进而合并等价事件使事件具有唯一性;最后,针对事件唯一的事件组,依据不可能事件的定义,依次判别两两事件的组合是否构成不可能事件,即冲突事件,通过度量事件可信度剔除冲突事件中不太可信的事件。
2.1 目标实体对齐
在目标实体对齐阶段,构造目标实体显示的字符特征和词组特征,进而计算不同粒度的实体特征间的相似度,并通过加权的方式评估两两实体间的匹配度得分。基于相似度计算的实体对齐方法的伪代码如算法1 所示。通过匹配度得分对实体库中的实体进行噪声剔除、数字归一化、机型归一化[15]操作,将实体特征映射到更低维度空间,去除冗余特征,提高算法性能;然后基于规则快速召回候选实体,减小整个实体对齐算法的复杂度;最后,基于显示特征评估目标实体与备选实体的相似度[16],加权得到候选实体得分,输出得分较高或高于阈值的候选实体作为对齐的对象。

算法1 基于文本相似度的实体对齐算法输入:实体库R={r1,r2,…,rn}、实体r=[c1,c2,…,cm](ci 表示第i 个字符)、数字集Sn、中文字符集Sc、英文字符集Se、大写英文字符集Su、实体得分阈值δ输出:实体库R 中与实体r 相匹配的实体集合M 1.M←Ø 2.使用文本特征降维算法获得更为具象的实体表示,得到r ←clean(r),ri ←clean(ri)∀ri∊R 3.使用实体召回算法快速召回候选实体,得到r←Record(r,R)4.For i=1 to n do 5.按实体得分评定算法计算候选实体得分si=Score(r,ri)6.If si> δ then 7.M.add(ri)8.End If 9.End For 10.Return M
给定实体库R 和待处理的实体r,为实体r 从实体库R 中找出与之对称真实世界中相同对象的实体,并返回与实体r 对齐的实体组成的实体集合M。利用文本特征降维算法对实体库R 中的实体数据进行降维处理,通过实体召回算法获得粗粒度水平的候选对齐实体,最后针对候选实体,使用算法2所示的实体得分判定算法计算其与实体r 的相似度得分,返回大于阈值的实体并组装为集合返回。算法流程图,如图4 所示。
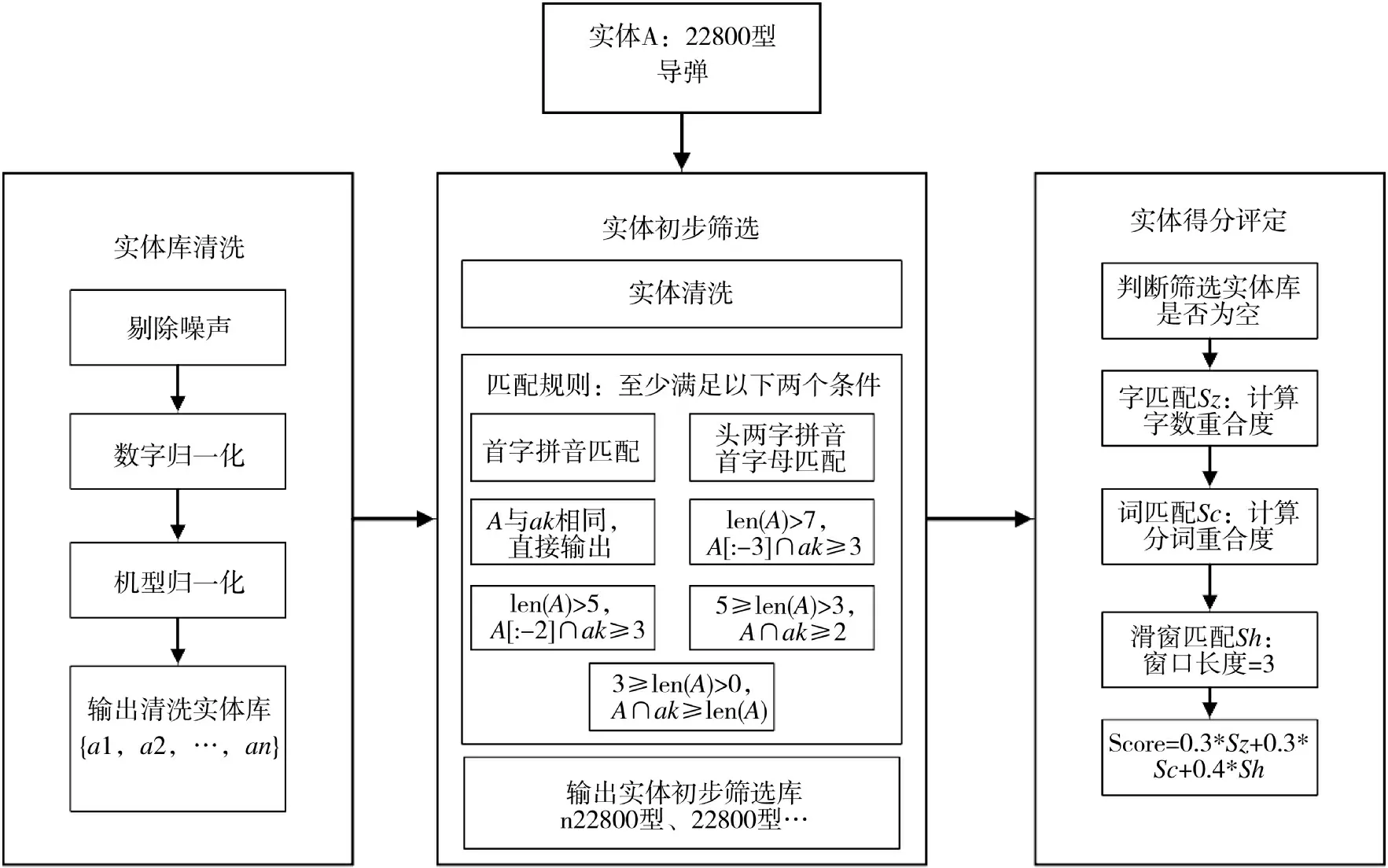
图4 基于规则的目标实体对齐流程Fig.4 Rules-based alignment process for target entities

算法2 实体得分评定算法输入:候选实体集N=[r1,r2,…,rn]、实体r输出:实体r 与各个候选实体的相似度得分si=Score(r,ri),i=1,…,n 1.If R=Ø then 2.Return{“null_enity”:0}3.For i=1 to n do 4.计算si=0.3*LCSSc(r,ri)+0.3*LCSSw(r,ri)+0.4*LCSSwin(r,ri,3)5.End For 6.Return[s1,s2,…,sn]
其中,LCSSc(r,ri)为字数重合度,设实体r=w1,w2,…,wm,其中wi表示第i 个字,那么r 的字符集合为r={w1,w2,…,wm},设实体ri的字符集合为Ci,那么
其中,||表示集合的大小(模)。
LCSSw(r,ri)为分词匹配度,设对实体r 进行分词得到词集W,对实体ri进行分词得到词集Wi,那么
LCSSwin(r,ri,3)为滑动窗口大小为3 时的滑窗匹配度,设实体r=w1,w2,…,wm,其中wi表示第i 个字,那么使用大小为3 的滑动窗滑过字符串“w1,w2,…,wm”可得到A={w1w2w3,w2w3w4,…,wm-2wm-1wm}。设对ri使用大小为3 滑动窗口进行处理Ai,得到字符串集,那么
实体得分评定步骤如下所示:
1)对实体匹配实体库进行判断:
①若实体库为空,反馈{“null_enity”:0}
②若匹配实体不为空:
A)字匹配(计算字数重合度)*0.3
B)分词匹配*0.3
C)滑窗匹配(窗口长度=3)*0.4
D)输出最终的得分;
③最终对链接到的实体通过卡阈值和取top 输出最终的实体;
2.2 等价事件关联
在等价事件关联阶段,按目标和时间进行分组挖掘其中的等价事件(即在不同上下文中拥有差异化表达方式的同质事件),并进行关联合并,如算法3 所示。首先,本文将对齐后的目标角色和时间作为唯一标识符对事件进行分组;然后,扫描每组事件,依据两两事件地点的相似度判断两者是否为等价事件;最后,对等价事件进行合并,即将它们的事件元素组装为集合。

算法3 等价事件关联算法输入:发生在时间t 的目标r 一组事件E={e1,e2,…,en},其中,ei=
2.3 事件冲突检测
在事件冲突检测阶段,本组件定义不可能事件并依据规则进行冲突检测,再通过评估事件的可信度解决事件冲突。首先,使用算法4 获得元素唯一的事件集合;然后结合事件的论元结构归纳出不可能事件,如目标在同一时间出现在不同地点是不可能事件;然后对每一种不可能事件设计规则检测出冲突事件,如按目标和时间进行分组后检测同组事件中是否存在地点冲突的情况;最后,结合事件情报来源的权威性(基于来源性质、用户数量、热点情报数量、风评评估来源的权威性)以及事件在社交媒体上的提及次数,评估事件的可信度,并剔除冲突事件中可信度较小的事件。例如,在2020 年某日美军“尼米兹”号航空母舰的活动轨迹的信息中,有23 处信息来源报告其在太平洋海域演习,而在同权威性级别信息来源中仅有1 处报告其在印度洋海域演习,通过事件冲突检测算法,可以剔除后者可信度较小事件。
3 事件线生成
事件线生成组件旨在通过关联事件组装故事,按目标拆分故事得到故事情节,提取故事主题帮助用户从全景了解故事及其包含的故事情节,构造事件线可视化故事脉络的发展过程。

算法4 事件冲突检测算法输入:发生在时间t 的目标r 一组事件E={e1,e2,…,en},其中,ej=
在事件线生成过程中,首先本文依据事件的隐式语义信息聚合相同主题的事件为簇,从而将事件分到不同故事,并基于故事特征提取摘要形成故事主题,便于用户了解整体故事内容;然后,按目标对故事进行拆分,得到故事子集形成目标相关的故事情节,基于故事情节特征提取摘要形成故事情节主题,用于概括情节整体内容;最后,以故事和故事情节为单位梳理时间脉络生成事件线,追踪主题事件的演化过程,并通过绘制故事情节事件线可视化目标跟踪过程。
3.1 事件聚类
在事件聚类阶段,本文通过两个阶段不同粒度水平的事件特征聚类来组装故事。首先,在预聚类阶段,依据事件的地点、情报内容等显示语义信息使用DBSCAN 聚类方法对事件进行分组,并提取事件的隐式语义特征;然后,在细聚类阶段,基于上一阶段提取的事件隐式语义特征使用LDA 方法进一步将事件关联为故事[17]。
在DBSCAN 预聚类过程中[18],本文先为事件集合E 中每个事件e 学习其情报文本的词向量表示we,然后基于词向量使用DBSCAN 方法将事件聚到类成员P={P1,P2,…,PNs}中,其中P2是一个事件簇。定义DBSCAN 的距离函数为:
在LDA 细聚类过程中,本文先使用DBSCAN聚类结果初始化LDA 中故事的词分布,即将属于同一预簇事件的词向量赋给同一故事;然后,使用Gibbs Sampling 推断LDA 模型的参数、事件的故事向量;最后,将事件赋给概率最高的故事。
3.2 故事主题归纳
在事件主题归纳阶段,本文使用TextRank 方法提取情报中的短文本作为故事主题如,算法5 所示[19]。首先,将故事中所有事件的情报文本进行分句和整合得到故事情报句子集合A,并学习每个句子的词向量表示V;然后,以句子为节点构建无向带权图,其中边的权重为句子间的余弦相似度;最后,使用TextRank 算法计算句子的排名,并将排名最高的两个句子拼接作为故事摘要输出。

算法5 故事摘要生成算法输入:故事S={e1,e2,…,en},其中,ei=
3.3 目标事件线生成
在目标事件线生成阶段,只需将故事中的事件按时间进行升序排列,然后在地图上进行可视化展示即可。若要追踪目标相关事件的发展进程,则可生成目标事件线,若要追踪主题事件的脉络发展,则可生成主题故事事件线。另外还可以绘制故事提及次数趋势图追踪目标事件被提及频次随时间的变化趋势,进而挖掘各个时间段的热点事件。
4 案例分析
随着战争现代化,军事情报伴随新军事革命进入新的发展阶段。随着战争形态和军事斗争形式的多样化,以及军事对抗涉及面的逐步扩大,决策性情报和相关情报将逐步增多,以信息化军队为主导的军事对抗,将使情报系统的信息流量进一步增大。情报的掌握与否,是决定战场胜负的关键。开源情报,作为常规情报监视侦察手段的重要补充,通过对开源信息的分析,挖掘这些媒体信息中有关装备型号、作战部署、战损等军事情报,可以丰富和补充情报信息。
信息时代,新闻报道、公众号、微博等新媒体中蕴含了大量的军事信息,对于这些军事信息中关键实体、关键事件信息的识别,可以有效帮助了解敌机/舰的活动轨迹,便于我方进行军事部署。也就是说,通过事件抽取技术,可以对敌机/舰进行跟踪,了解到敌军从哪里来、到哪里去以及从事相关活动等信息,以便我方作出有效的应对。
本文从环球网、环球时报、新浪军事、微博等数据源爬取了相关军事新闻报道。利用开源数据,通过目标跟踪技术,即通过文本的预处理、事件的关联与组装(事件抽取)、事件一致性检测,完成关键目标实体以及关键事件信息的抽取、事件的丰富与冲突检测,进而完成对航母/战机的关键事件汇总以及实时追踪。
利用基于事件抽取的目标跟踪技术,可以从繁杂、冗余的军事新闻中检测出关键事件信息,如图5所示,即从来自《美舰日报》的原始文本中抽取出包含关键目标实体“‘尼米兹’号航母”的关键事件句子,“7 月17 日,据美太平洋舰队消息,‘里根’号航母打击群与‘尼米兹’号航母打击群再次在南海集结,开展‘高端’(high-end)双航母演训”。对于该文本,还可以抽取出它所对应的目标实体、时间、地点等关键实体信息即从繁杂的文本中得到结构化的事件信息,如图6 所示的事件抽取结果。
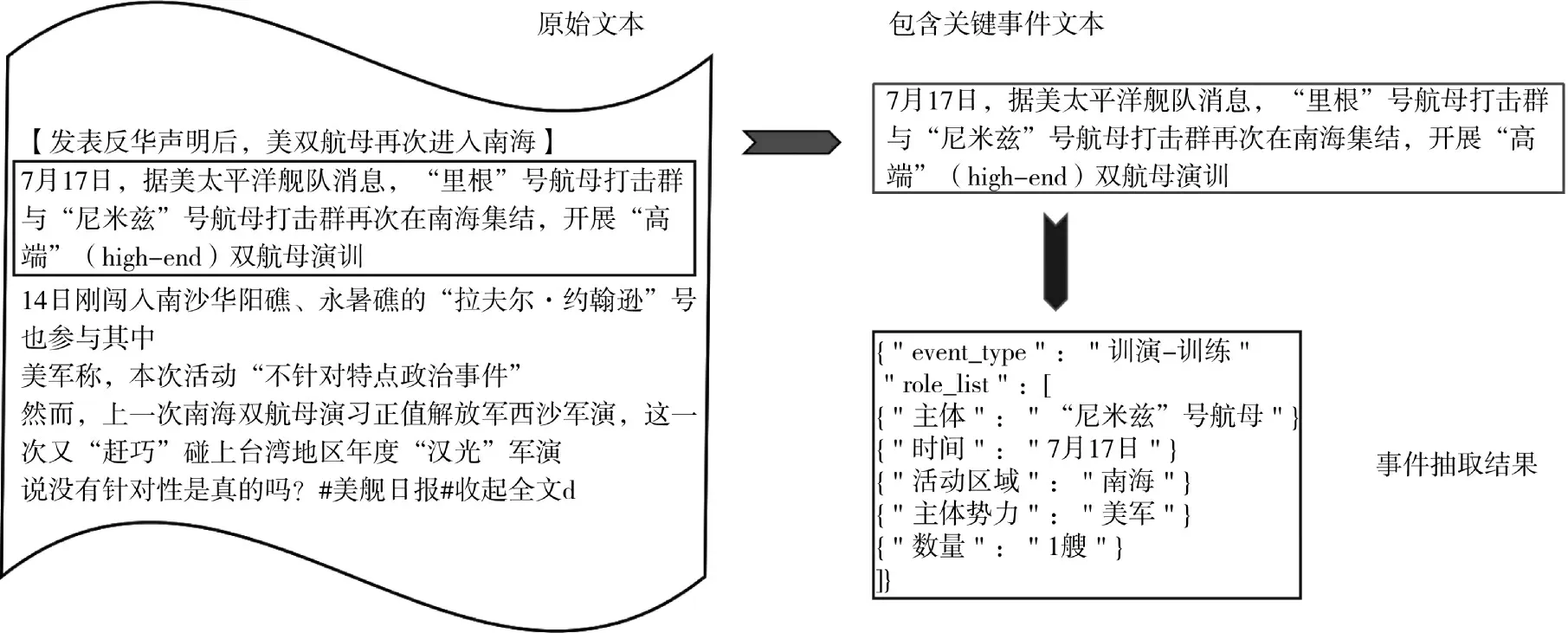
图5 关键事件抽取范例Fig.5 Sample critical event extraction

图6 “尼米兹”号航母关键事件时间线生成Fig.6 Nimitz aircraft carrier critical incident timeline generated
如对于文本“7 月20 日,‘尼米兹’号航母打击群与印海军在印度洋东北部的安达曼群岛附近海域开展联合演习,期间举行实弹训练”,可以抽取出该文本包含“训演-演习”事件类型,该事件的事件主体为“尼米兹”号航母,时间为“7 月20 日”,活动区域为“印度洋东北部的安达曼群岛附近海域”等信息,如表1 所示。可以注意的是,文本“通过C-2A舰载运输机的行动判断,‘尼米兹’号航母上周末仍在冲绳东南海域活动”中只包含了“上周末”这一模糊时间,并未包含具体时间信息,通过新闻的发布时间,对事件的发生时间作出适当的推测,由此得到具体时间信息。

表1 “尼米兹”号航母事件抽取结果Table 1 Extraction results of the Nimitz aircraft carrier
通过观察7 月16 号~7 月21 号关于“尼米兹”号航母目标实体的事件抽取结果,可以看到在这5天当中,它依次出现在冲绳东南海域、南海、新加坡近海、冲绳东南海域、印度洋东北部的安达曼群岛附近海域进行航行、训练、演习等活动。进一步,通过可视化,不仅能够直观地展示“尼米兹”号航母每天的行动轨迹、执行的任务,通过该航母的行动轨迹变化,还可以为预判它的下一步行动提供很好的先验信息,与此同时,通过它前一步的活动地点,可以预测它下一步可能出现的位置。
其次,对于追踪主体“P-3C 反潜巡逻机”,“P-3C 反潜巡逻机”于3 月26 日以及4 月20 日从冲绳嘉手纳基地起飞,先后在南海以及韩国仁川附近上空执行侦察任务。可以得到它较为完整的行动轨迹,包括时间、地点以及所执行的任务等等。可以对于其下一步行动作出更好的应对措施。
5 结论
通过基于事件抽取的目标跟踪技术,不仅可以从繁杂、冗余的军事新闻中检测出关键事件信息,还可以利用信息融合预测敌方活动轨迹,便于我方及时作出部署。
但在本文中,采用的事件抽取模型是流水线式模型,即先做事件类型抽取,再进行事件参数抽取,这样会带来级联误差,下一步可以研究如何减少级联误差。
总体而言,相比于通过人工从浩瀚的信息中寻找关键信息,通过目标跟踪技术,不仅大大减少了人力物力,还大大提高了结果的实效性。可以准确、实时地给我方提供敌方信息,有助于我军在战场上取胜。
