基于自注意力和类监督的遥感图像跨模态检索*
2023-11-20刘姝妍李润岐
何 柳,刘姝妍,李润岐,陶 剑,安 然
(中国航空综合技术研究所,北京 100028)
0 引言
随着科技的进步和武器的发展,战争的形态也在不断发生变化,联合作战也发展成为在陆、海、空、天、电、网及认知领域的一体化战争。随着联合作战维度的全域化,战场态势信息呈现出模态丰富、结构复杂、规模庞大、时效性强等特点,为战场信息的融合处理、高效决策提出了巨大挑战[1]。与此同时,大数据、人工智能技术的飞速发展,为联合作战中多源、异构、海量信息的处理提供了新的思路,智能化的联合作战将是未来发展的新趋势[2]。在智能化联合作战中,无人机作为战场中情报获取的重要装备,利用可见光或红外图像对战场环境、装备部署等情况进行侦察、识别和跟踪。与利用雷达进行目标探测相比,无人机携带的光学设备因为不易暴露自己和不易于受电磁干扰,而在获取地理空间情报任务中成为更可靠的手段。
在无人机侦查广泛应用的趋势下,遥感图像呈现出了爆炸式的增长。然而,这些图像具备数据量大、图像特征不明确、图像内容价值密度低的特点,具备大数据的属性特征,给情报分析任务中的关键目标获取与分析带来了巨大的挑战。
针对该问题,传统的做法主要分为两类,一类是以人工的方法,由专业情报分析人员通过经验,对遥感图像的内容进行研判,找出关键目标的大致位置,然后选取一定数量的锚点进行配准,实现基于作战目标的遥感图像定位。这种基于人工的遥感图像信息检索与筛选,严重受限于情报专家的经验和对地理区域的熟悉程度,在对陌生的地理区域处理时效率低、误判率高。同时,面对现代战争中海量数据的处理,完全依赖人工的方法会对信息与决策的时效性产生影响。因此,遥感图像处理的另一个趋势是利用大数据、人工智能的方法,通过基于内容的图像检索技术来实现遥感图像的信息过滤与分析[3-6]。此类方法的总体思路是提前建立一些典型的遥感图像场景库,场景库中的图像具备一些具有作战指挥意图的地理空间特征基准图像,以这些图像为锚点,在战场中采集到的海量数据中,查找相似的场景,利用大数据检索技术辅助进行地理空间情报分析[7-13]。
上述思路的核心是构建一个高效、可靠、准确的检索算法模型,用以对典型场景图像和候选图像进行特征表达。随着深度学习的发展,深度神经网络因其具有强大特征表达能力,在计算机视觉和自然语言处理等领域中取得了广泛应用。基于深度神经网络完成遥感图像的检索任务以提升联合作战信息过滤与检索速度,从而加快整个决策过程,成为了当前最受关注的研究方向之一。现阶段的研究主要集中在利用图像到图像的检索技术,来实现对遥感图像中特定场景的筛选[14],但是这种方式还存在两方面的问题:1)图像到图像的检索方式依赖已有的典型场景图像,如果在使用过程中没有合适的可表达检索意图的场景图像,将严重影响检索效果;2)情报分析人员或作战指挥人员在时效性较强的场景下,无法用自己最熟悉的检索方式——自然语言到图像的检索来完成遥感图像的筛选,这样会导致信息过滤和指挥决策效率下降。
跨模态的文本-视觉检索模型作为自然语言处理和计算机视觉交叉的新兴研究领域,能够同时考虑自然语言和相关图像的特征信息,对此提供了更加有效的解决方案。当前遥感领域的跨模态检索方法大体可以分为两类,第1 类是基于图像描述的方法,主要采用生成式的方法生成用以描述输入图像的关键词标签,再基于关键词的文本检索方法来查找匹配图像。例如,为了使生成的标签可解释,文献[15]设计了一个可解释的词句框架,将任务分解为词分类和排名两个子任务。第2 类方法是基于文本-视觉双模态表征的方法,对输入图像和文本分别采用单独的编码器进行特征表示并映射到统一的空间中,核心在于如何缩短相似文本和图像间的向量距离。VSE++模型是基于双模态表征完成跨模态检索的先驱之一[16],其应用三元组损失来优化训练目标。SCAN 模型使用目标检测器提取局部特征来增强VSE++模型[17]。CAMP 模型提出了一种消息传递机制[18],可以自适应地控制跨模态消息传递的信息流。MTFN 模型基于秩分解的思想设计了多模态的融合网络[19],通过重排序过程来提高检索性能。AMFMN 模型采用基于三元组损失的非对称方法[20],该方法使用视觉特征来指导文本的表达。
在对跨模态检索方案充分调研的基础上,本文基于文本-视觉双模态表征的方法,面向情报分析和指挥作战的场景,对主流模型中关键的检索算法进行了改进和验证,构建了更高精度的融合文本-视觉的遥感图像跨模态检索系统框架,本文的主要贡献有以下3 点:
1)提出了一套面向遥感图像的文本- 视觉跨模态检索技术框架,旨在为情报分析员、作战指挥员面对海量的遥感图像信息时,提供更快速过滤情报的能力,支持自然语言场景描述与遥感图像之间的检索。
2)面对遥感图像的大数据特征,传统通过人工给图像添加标签的检索方式,无法满足情报分析快速响应的要求,本文基于文本-视觉双模态表征模型,通过深度神经网络对遥感图像中关键内容信息进行特征提取,并与自然语言中的语义信息特征对齐融合,从而完成跨模态的检索,最终取得了优于主流模型的效果。
3)在模型的设计上,本文模型包含视觉、文本的单模态以及用于跨模态对齐的多模态特征提取模块,所有模块均基于主流的自注意力模型构建,以充分考虑长距离的遥感语义上下文信息,并针对性地引入了类监督的指导机制。实验结果证明了本文方案的可行性。
1 面向遥感图像的文本-视觉跨模态检索技术框架
面向遥感图像的文本- 视觉跨模态检索的主要技术流程如图1 所示,整个框架可以分为3 部分,首先要对以往获取的遥感图像进行清洗、对内容进行文本描述,其次是利用处理好的典型场景图文数据进行跨模态深度学习模型的训练。在得到收敛的模型之后,投入到遥感图像的文本-视觉跨模态检索场景中使用,完成情报分析人员和作战指挥人员快速获取遥感图像信息的目的。
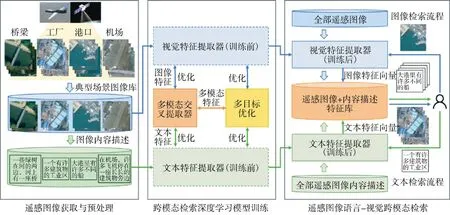
图1 面向遥感图像的文本-视觉跨模态检索技术框架Fig.1 Framework for text-visual cross-modal retrieval technology of remote sensing images
1.1 遥感图像获取与预处理
遥感图像的获取与预处理过程,主要是建立可以支撑训练跨模态检索模型的高质量数据集,用于针对具体应用场景的模型训练和算法调优。遥感图像的获取途径可以是无人侦察机的航拍图像,也可以是遥感卫星的监测图像,针对不同的任务,可以将图像缩放、裁剪至适合的尺度。无论是哪种渠道获取的图像,由于在作战场景中,有价值的军事目标(如桥梁、工厂、港口、机场等)通常是少数,前期需要情报分析人员从全部遥感图像中抽取出与之相关的典型场景,并用自然语言对此场景的特征进行文本描述,分别生成典型场景图像库和与之对应的图像内容描述文本库,用于后续的模型训练。在遥感图像典型场景图像库的构建过程中,需要针对作战任务的重点进行设计,选取的图像应该具备典型的分类特征,如地理特征(沙漠、海岸、城市等)、目标特征(桥梁、机场等)等,每类典型场景下的遥感图像可以具备一定的差异,用于增强模型的泛化性。同时,在对每张典型场景图像进行描述时,可以一幅图像对应多个文本描述,分别选择不同的侧重点来对特征进行表达,如下页图2 所示。高质量、多种类、细粒度的典型场景图像库及其内容描述文本库是训练跨模态深度学习模型的基础保障。

图2 遥感图像典型场景库与文本描述Fig.2 Typical scene library and text description of remote sensing images
1.2 跨模态检索深度学习模型训练
跨模态检索深度学习模型是整个技术框架的核心,一个稳定、高效、精确的检索模型需要通过针对性的设计以及高质量数据的不断迭代训练来得到。本文设计的模型主要包括4 部分:视觉特征提取器、文本特征提取器、多模态交叉提取器和多目标优化模块。其中,构建视觉特征提取器模型和文本特征提取器模型分别对图像和文本进行特征抽取,利用多模态交叉提取器对两种特征进行融合,在多个优化目标函数的监督下,不断迭代更新视觉和文本特征提取器的参数,达到最优的特征提取效果和跨模态特征对齐能力。模型的设计细节将在第2 章进行详细介绍。
1.3 基于语义特征的遥感图像文本-视觉跨模态检索
训练完成后的视觉和文本特征提取器就可以投入遥感图像的文本-视觉跨模态检索场景中使用。构建此检索系统主要分为两步,第1 步先分别利用视觉和文本特征提取器,对获取的所有遥感图像和所有典型任务场景文本描述进行特征提取,生成遥感图像和内容描述的特征库,图像和文本特征通常表现为维度相同的向量。第2 步情报分析人员可以通过4 种检索方式来获取目标信息,分别为文本到图像,图像到文本,图像到图像和文本到文本。文本到图像的检索为最高效、实用的方式,情报分析人员输入对战场环境的自然语言描述,通过文本特征提取器的特征提取,与特征库内其他信息进行向量相似性判断,找出最接近情报分析人员意图的遥感图像,为战场态势分析提供信息支援。除此之外,本文提出的跨模态检索场景还支持输入图像,查找相似的场景以及合适的场景描述,为情报分析人员提供多元化的应用模式。
2 方法
2.1 模型整体架构
文本-视觉跨模态检索模型的研究在自然图像领域已经取得了重要进展,然而在遥感图像感知领域,尚未得到充分的探索与验证。因此,本文在现有文本-视觉跨模态检索模型研究的基础上,面向遥感图像与内容描述文本,提出了一种基于自注意力和类监督联合训练的跨模态检索模型,主要包含类监督指导的全局-局部视觉特征提取模块、主导语义掩码建模的文本特征提取模块,以及融合视觉-文本语义信息的交叉提取模块,如图3 所示。
自注意力模型现已被广泛地应用于自然语言处理领域相关的典型任务中[21],其通过对全局上下文信息的整合捕获长距离的语义依赖关系,可以从大量复杂的目标信息中捕获到少量特定重要的信息。自注意力模型在自然语言任务的成功也启发了计算机视觉任务。视觉自注意力模型首先将输入图像划分为若干个小尺寸的子图像块,因此,能够将视觉问题转化成序列到序列的建模问题,之后的编码操作与文本处理类似,在输入序列中同样会引入相对的位置编码,最终生成自注意力矩阵来获取输入图像中关键目标信息的权重分布,如下页图4 所示。考虑到遥感图像往往蕴含着复杂的信息场景,本文设计的3 个模块均被拓展为更适应遥感图像特点的基于自注意力机制的模型。同时,为了融合自然语言和图像内容中的目标信息,本文利用基于关键信息的语义掩码模型,对文本描述中的目标分类等信息进行选择性的遮挡,以增强文本特征提取器对关键信息的表征能力。语义掩码模型的处理方法如图5 所示。
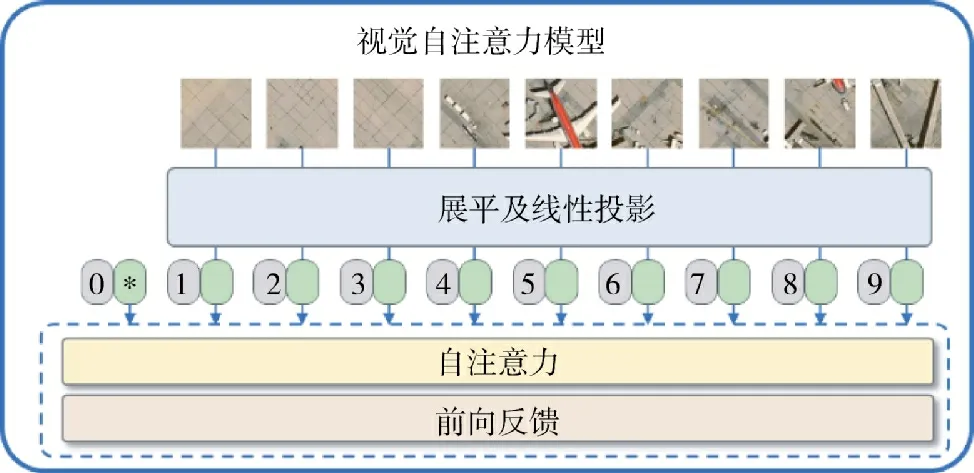
图4 视觉自注意力模型Fig.4 Visual self-attention models

图5 基于关键信息的语义掩码模型Fig.5 Semantic mask model based on key information
2.1.1 引入类监督指导的全局-局部视觉特征提取模块
在文本-视觉跨模态交互任务中,视觉端编码的语义信息通常远远多于文本端,因此,需要更复杂的视觉特征提取模块来提取全面的特征。为此,本文构建包含全局语义特征抽取模块和局部语义特征增强模块两部分的视觉特征提取器,同时考虑到类别信息对于遥感图像的解译至关重要,针对全局抽取模块引入了类监督的指导。全局特征抽取模块基于残差卷积神经网络(ResNet)模型构建[22],在内部存在浅层与深层特征的交互连接,主要用于显著类别特征的抽取以增强局部特征表示。如式(1)所示,输入遥感图像I∊RH×W×C经过变换后将得到全局特征FG,Mres表示采用ResNet 模型完成特征提取的过程,θ 为模型具有的一系列可学习的参数。
多变的拍摄高度和视角使得遥感图像通常包含大量的小目标和密集目标,提升视觉编码模块对于此类目标的表征能力对于检索效果的提升同样重要。而基于视觉自注意力机制的Vision Transformer(VIT)模型可以在观察到远距离的上下文信息的同时,更精细地保留图像的局部细节信息[23],有利于上述细粒度小目标特征的提取。因此,设计基于VIT 的局部特征提取模块。
具体来说,输入遥感图像I 被展平为一个二维的图像块向量N×(P2·C),其中,P×P 为图像块的尺寸,N=HW/P2表示被切分的图像块数量,也即输入到VIT 模型的序列长度。在VIT 内部,图像I 将经过多头注意力层(MSA)、多层感知机层(MLP)以及层归一化(LN)等模块,如下所示:
构建完成的全局特征FG和局部特征FL在视觉端的尾部进行整合,整合后其携带的丰富全局和局部特征信息能够显著提升遥感图像的解译效果。
2.1.2 主导语义掩码建模的文本特征提取模块
对于遥感文本语义信息的解析同样是检索系统的重点任务。为了更好地表征文本特征,本文选择在自然语言处理领域的典型模型BERT 构建文本特征提取模块[24]。BERT 模型同样基于自注意力机制,其能够很好地联合网络模型层中所有的上下文信息以完成遥感文本语义的全面解析。同时,考虑到文本端相比于视觉端通常蕴含的语义信息较少,本文选取BERT 模型的前6 层构建文本特征提取模块,以尽可能地降低文本端模型的复杂度。BERT 模型的后,6 层将被用于构建后续的文本-视觉交叉融合模块。
具体来说,输入的遥感文本描述T 首先会被编码或被拆分为词向量和位置向量的序列。其中,n 表示输入文本序列的长度,d 表示每个词向量的维度。之后文本向量T 将经过构建完成的BERT 模型,内部为多个MSA、MLP 以及LN 层的叠加。
为了充分利用类别监督信息,同时增强与视觉编码模块在同一类遥感目标上的协同表征能力,本文对文本描述中的特定类别词(如机场、工厂、港口等)、关键目标词(如飞机、桥梁、船只、车站等)等进行了针对性的掩码处理,同时也保留了以往方法中的随机掩码策略。具体来说,对于处理后的文本序列,首先以15%的概率随机地进行位置标记,其次找到对于序列解析至关重要的上述词的位置进行标记,最后对于所有的已标记位置,以一定的概率进行掩码遮挡操作和随机的单词替换,未选中则不进行额外处理。通过如上“针对性”与“随机性”结合的方式,不仅能够加强检索模型对于遥感文本本身具有目标的解析,同时也能够提升模型对于异常目标的对抗能力。
2.1.3 融合视觉-文本语义信息的交叉提取模块
在视觉和文本特征的交互方面,尽管存在跨模态相似性计算模块用于指导检索系统将视觉和文本特征关联,但独立的双模态分支仍然无法充分地对齐视觉和文本特征,为此,本文在特征提取模块的尾部级联一个交叉提取模块,用于增强跨模态特征间的融合。该模块利用BERT 模型的最后6 层构建,仅用作视觉和文本特征的语义校准和对齐,不直接参与检索系统的最终推理。
交叉提取模块主要包含两个子模块,第1 个是相似度计算子模块Msim,与常规的双分支检索模型一致,利用向量相似性计算方法(如欧氏距离、余弦距离等)构建相似度计算模块。第2 个是视觉-文本融合子模块Mmul,主要目标是加强跨模态特征的交互。该模块可以被形式化如下:
其中,相似性计算子模块首先计算图像特征FV和文本特征FT之间的相似度,并使用三元组损失优化单模态特征提取模块中的参数。视觉-文本融合子模块则应用掩码语言损失和图像-文本匹配损失,来优化双模态特征间的交互。掩码语言损失对文本包含的语义采用针对性掩码的策略,同时借助视觉特征来预测真实的文本内容。图像-文本匹配损失则能够预测给定的图像和文本对是否匹配。视觉-文本融合子模块通过上述两种损失优化策略,来优化局部特征增强模块和文本特征提取器的表达。
2.2 多目标损失函数优化
为了获取跨模态检索模型的最佳权重组合,需要应用4 个损失函数,来从不同维度指导每个模块的性能优化,分别为三元组损失、用于类监督的交叉熵损失、掩码语言损失和图像文本匹配损失。主要的损失函数是三元组损失,通过增大匹配图文对的特征距离,减小非匹配图文对的特征距离来增强特征表示,如式(10)所示:
其中,α 代表距离的边界参数以增大正例对和负例对之间的差距。整体包含两部分,第1 部分表示以图像特征FV检索文本特征FT的损失,cos()表示经过跨模态相似性计算模块得到的相似距离,T'为图像I 的负例文本。后部分为以文本特征FT检索图像特征FV的损失,I'为文本T 的负例图像。
此外,本文还引入了用于类监督的交叉熵损失以指导全局特征提取模块的显著性类别特征生成。如式(11)所示,yi为图像的实际类别,pi为经过模型输出的类别的预测概率。
最后,针对融合视觉-文本语义信息的交叉提取模块构建用于捕获基于主要类别目标特征的MLM 损失,以及用于图像-文本成对相似性学习的ITM 损失,如式(12)和式(13)所示。MLM 的优化目标是最小化交叉熵损失,T^为经过掩码策略的文本向量,pmask(I,T^)为模型考虑图像特征后对于掩码文本的预测概率。考虑到图像-文本匹配任务可以被看作是二分类的预测问题,因此,ITM 通过引入一个全连接层来给出图像-文本对的匹配概率pmatch(I,T),整体的优化目标仍是最小化交叉熵损失。
2.3 算法流程
算法的训练过程主要优化视觉特征提取模块、文本特征提取模块以及视觉-文本交叉提取模块3 部分,如下页图6 所示。给定遥感图像数据集,首先经过数据清洗、数据增强等预处理步骤,以提高数据的质量和数量,之后对训练集进行多次迭代训练,其中,图像数据经过视觉特征提取模块得到FG、FL并整合形成FV,文本数据经过文本特征提取模块生成FT,整个训练过程采用4 种损失优化策略来指导,Lmlm和Litm通过交叉提取模块间接影响单模态特征模块的效果,最终构建最优的跨模态检索模型。

图6 文本-视觉跨模态检索模型训练流程Fig.6 Training flow of text-visual cross-modal retrieval model
对于模型推理过程,首先构造大规模的特征检索数据库,存储所有的遥感图像、文本经过训练好的单模态特征提取模块后生成的特征向量,以提升后续实际检索过程的效率。之后当输入给定的遥感图像、文本时,采用相似性计算模块将其生成的对应特征与特征检索数据库中的向量进行比对,给出排名在前的召回结果完成检索任务。
3 实验分析
3.1 数据集和评价方法
为了验证本文方法在遥感领域的跨模态检索效果,本文在两个主流且公开的遥感图像-文本对数据集RSICD 和RSITMD 上进行实验验证[20-25]。RSICD 数据集是一个大规模的遥感图像-文本对数据集,共包含10 921 个图像-文本对,其中图像大小为224×224,是目前已知的数量最多的遥感图像检索数据集。相比于RSICD 数据集,RSITMD 数据集具有更细粒度的文本描述,包含4 743 个图像-文本对,图像大小为256×256。两个数据集的每张图像均对应5 个文本描述,且RSITMD 数据集的文本描述重复更少。在类别划分上,RSICD 数据集直接提供了类别描述,共包含如飞机场、火车站、桥梁在内的31 个类别。RSITMD 数据集的类别划分标识在文件名称之中,类别划分与RSICD 数据集相似,共包含33 个类别。
在评价指标的选取上,本文采用R@k 和mR 指标来评估提出的检索系统在文本至图像和图像至文本检索两个方向上的排序性能。R@k(k=1、5 及10)表示系统召回的前k 个结果中包含真实结果的比例。mR 表示对于所有R@k 结果的平均值,其被作为模型整体性能的最终评价指标。
3.2 实现细节
本文提出算法的所有实验均基于Python 编程语言及PyTorch 深度学习框架,并在单张Tesla V100 GPU 的硬件环境上展开。所有图像都被统一地变换至256×256 的输入大小,并应用随机旋转、翻转、颜色变换等数据增强方法,以使模型可见更多的数据分布变化,从而更加适应真实的遥感场景。视觉全局特征提取模块基于ResNet 模型构建,视觉局部特征、文本特征以及交叉特征提取模块均基于Transformer 自注意力模型构建,最终生成的视觉和文本特征以512 维的一维向量进行表征。在模型的训练流程中,本文应用的批处理大小为64,学习率被初始化为2e-4,并每经过10 轮迭代过程衰减一次。整个模型通过Adam 优化器进行优化,共训练30 轮。最终获取在测试集上效果最佳的模型用于后续的实际检索系统中。
3.3 实验结果与分析
在此部分,将本文提出的方法与其余4 种相关的文本-视觉跨模态检索方法(SCAN、CAMP、MTFN、AMFMN)在RSICD 和RSITMD 数据集上进行对比分析[17-20],通过定量和定性结合的方式,全面验证本方检索方案的先进性和有效性。
对于其他主流方法,本文直接采用在文献[20]中报告的结果,如表1 所示,结果展示了本文提出方案的优越性。具体来说,对于RSIMD 数据集,mR指标达到34.47%,显著超越了其他模型。同时,在RSICD 数据集上也取得了更加先进的结果,如下页表2所示。

表1 RSITMD 数据集对比实验分析Table 1 Comparative experimental analysis on RSITMD dataset
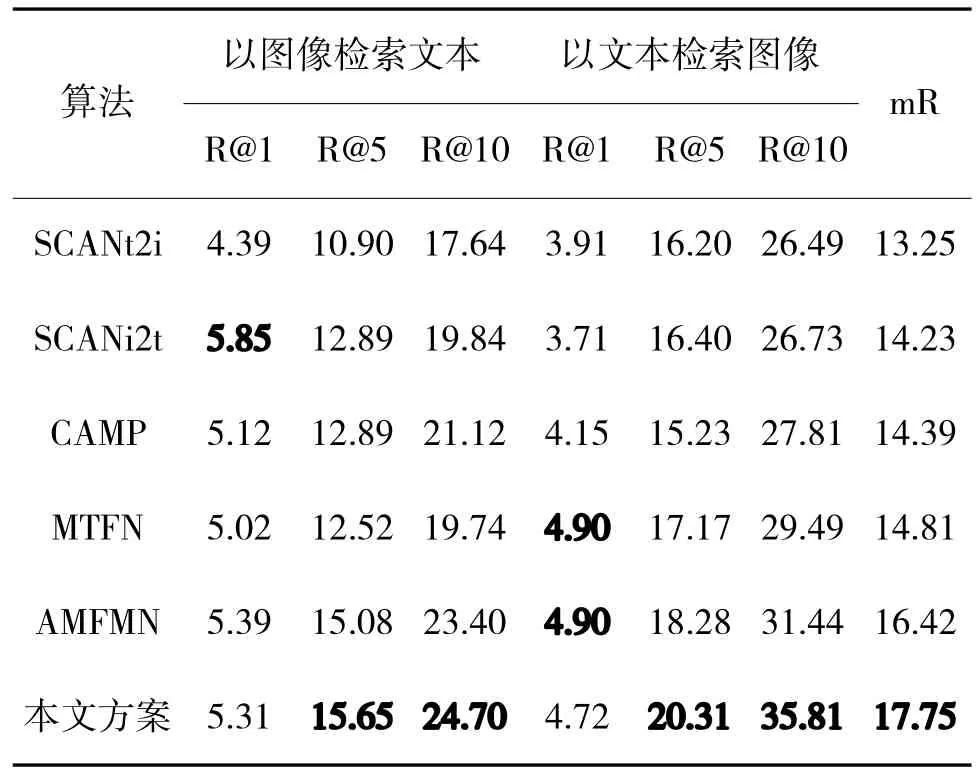
表2 RSICD 数据集对比实验分析Table 2 Comparative experimental analysis on RSICD dataset
接下来对本文提出模型的检索效果进行定性分析。下页图7~图10 分别为以文本检索图像和以图像检索文本的检索结果。二者展示的均为通过相似性计算模块返回的排名前5 的召回检索结果。
在实际使用场景中,文本到图像的检索是最常用的方式,在此模式下,图6 验证了本文提出模块的有效性,返回的遥感图像检索结果与输入文本的内容高度一致。图7 则表明了本文任务的挑战性,由于遥感数据集中存在大量的分布相似的图像数据,其中蕴含的目标类别差异性较小,致使无法对真实图像实现精准的命中。虽然本文模型在一些相似的遥感场景下的效果有一定损失,但是通过返回的结果可以发现,检索结果整体上仍然与描述文本呈现出了语义上的近似匹配关系。
对于以图像检索文本,图8 的文本检索结果与图像呈现出了较强的相关性,证明本文模型能够建立起文本和图像之间的关联关系。然而,图9、图10展示了不匹配的检索结果,甚至出现了错误的类别划分,这一现象是由于图像及其对应的文本描述蕴含的语义关系更为复杂,在建立类监督机制时,无法对图像和文本的所属主要类别进行精确地区分。

图8 文本到图像的检索示例2Fig.8 Text-to-image retrieval example 2

图9 图像到文本的检索示例1Fig.9 Image-to-text retrieval example 1

图10 图像到文本的检索示例2Fig.10 Image-to-text retrieval example 2
3.4 消融实验
为了更清晰地验证提出的各个模块的有效性,本文在RSITMD 数据集上进行了3 组消融实验,主要验证在主流跨模态检索框架下引入类监督、类别定向掩码策略以及交叉提取模块的有效性。
1)类监督:在主流双分支单模态编码器,也即图像端采用视觉自注意力模型、文本端采用文本自注意力模型的基础上,引入ResNet 模型构造全局视觉特征提取模块并引入类监督指导。
2)交叉提取模块:在上述类监督模块设计的基础上,将BERT 模型的后6 层构建为跨模态特征交叉提取模块,以促进单模态特征间的关联。
3)类别定向掩码策略:在文本端随机掩码训练的基础上,引入遮挡主要类别目标的定向策略,以促进同视觉端的类别监督更好地关联。
表3 展示了消融实验的结果,进一步印证了本文提出的各个模块的有效性。在遥感数据集上,本文算法通过对于图像和文本语义信息的充分解译,能够显著提升遥感场景下的检索效果。
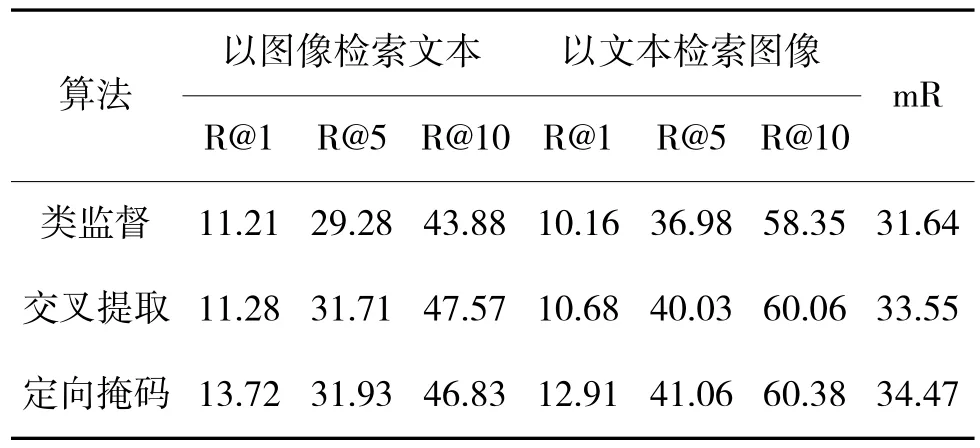
表3 RSITMD 数据集消融实验分析Table 3 Analysis of ablation experiments on RSITMD dataset
4 结论
本文面向智能化联合作战场景中,情报分析人员对无人侦察机采集的海量无标签遥感图像信息进行检索过滤时的大数据问题,提出了针对遥感图像内容的文本-视觉跨模态检索技术框架,整个技术流程分为遥感图像获取与预处理、跨模态检索深度学习模型训练和基于语义特征的遥感图像文本-视觉跨模态检索3 部分组成。与此同时,本文还对整个流程中最核心的跨模态检索模型进行了设计和改进,提出了一种基于自注意力和类监督联合训练的跨模态检索模型,通过引入类监督指导的全局-局部视觉特征提取模块、主导语义掩码建模的文本特征提取模块,以及融合视觉-文本语义信息的交叉提取模块,利用多个损失函数来从不同维度指导每个模块的性能优化,对整体检索的效果进行了提升。最后在公开数据集上与相关算法进行对比实验,证明了本文算法的合理性与先进性,定性分析实验证明了整个技术框架的可行性与实践效果。
在面向遥感图像的跨模态检索研究中,后续的研究重点包含两方面:一方面是针对遥感图像的特点,对模型专项能力的提升,例如遥感图像小目标细粒度识别、高噪声情况下的图像特征提取、不同尺度的自适应图像处理等能力,使得模型在更多的场景下具备精准的检索能力。另一方面是尝试利用生成式大模型对于多模态任务的处理能力,提升语言和视觉融合的效果,进一步增强图像-文本语义对齐,填补自然语言到视觉的语义鸿沟。
