融合Stacking 和深度学习的中文产品评论情感分析
2023-11-16蒋广杰李德生沙雷雨馨
方 红, 蒋广杰, 李德生, 沙雷雨馨
(1. 上海第二工业大学a. 数理与统计学院;b. 资源与环境工程学院;c. 计算机与信息工程学院,上海 201209)
0 引言
近年来,电商平台飞速发展,网上购物已成为用户的主流消费方式, 研究表明, 81% 的用户在进行网购前至少一次在网络平台上搜索过该商品[1],产品评论为浏览者提供了意见参考。对平台上的大量用户评论进行情感分析,可以有效帮助企业了解用户的产品偏好,提高用户满意度[2]。情感分析(sentiment analysis, SA) 也叫观点挖掘(opinion mining,OM),是自然语言处理研究的热点问题之一,主要是判别给定文本中蕴含的情绪、观点或意见[3]。情感极性二分类是情感分析中的基础任务之一[4],即识别文本数据中情感持有者的情感极性是积极的还是消极的, 除此之外, 还有多分类情感极性分析任务,例如情感极性三分类任务在二分类的基础上将数据集中增加了识别情感极性为中性的文本数据。而从文本角度来看,进行情感分析的文本可以是一篇文章、几句话、一个特定的词语(方面),因而又可将文本情感分析任务划分为篇章级、句子级、方面级3个级别[5]。
情感分析应用领域十分广泛,目前的情感分析方法主要有以下3 类:
第1 类情感分析的方法是基于词典,即针对某一特定领域建立专门的情感词典用于情感分析。对英文的情感分析研究早于中文,国外最早出现的英文情感词典是SentiWordNet,其他常用的有Opinion Lexicon 和MPQA (Question and Answer from Multiple Perspectives) 等, 中文应用比较广泛的情感词典有知网词典HowNet 和大连理工大学的中文情感词汇本体库等, 此外, 也有一些其他语种词典研究。Tran 等[6]提出一种适用于越南语的情感词典,涵盖了超10 万个越南语的情感词汇;Wu 等[7]利用网络资源建立了一部俚语词典SlangSD, 来判别用户的情绪。但基于情感词典的研究方法通常具有领域局限性,迁移性不好,在一些新兴领域,词典的更新与维护还要耗费一定的人力与物力。
第2 类情感分析法是基于机器学习算法, 比如朴素贝叶斯[8](naive bayesian,NB)、支持向量机[9](support vector machine,SVM)、极限梯度提升树[10](extreme gradient boosting, Xgboost) 等机器学习算法。其中,SVM 是早期业界公认在使用传统机器学习算法处理文本情感分析任务中具有良好性能的模型[11]。Ahmad 等[12]使用SVM 在3 个推文数据集进行情感极性多分类任务并取得了不错的效果;Cai 等[13]使用基于Stacking 集成思想的混合模型将SVM 和GBDT 集成在一起进行情感分析, 取得了比单一模型更好的分类效果。但使用传统的机器学习算法对文本进行情感分析任务时有时并不能充分利用文本中的语境信息,因此对预测效果有一定的影响。
第3 类情感分析方法是基于深度学习, 比如卷积神经网络[14](convolutional neural network,CNN)、长短期记忆网络[15](long short-term memory,LSTM)、双向长短期记忆网络[16-17](bi-directional long short-term memory,BiLSTM)、基于transformer的双向编码器[18](bidirectional encoder representation from transformers,BERT)等。2020 年,Li 等[19]提出了一种具有自注意机制和多通道特征的双向LSTM 模型SAMF-BiLSTM, 并在5 个公共英文数据集上进行情感极性二分类、情绪五分类和十分类任务, 其分类准确率相差较大, 模型效果并不稳定; 2021 年, Behera 等[20]建立了一个与领域无关的情感分析模型CO-LSTM 模型, 并在4 个公用英文数据集上进行情感极性二分类和三分类任务,实验取得了较好的准确率;2021 年,Basiri 等[21]提出融合不同算法的混合集成模型,在百万规模的推文数据上进行情感分析实验,实现了不错的分类准确率; 2020 年, Cai 等[22]提出了BERT-BiLSTM 的模型用于10 万条中国能源市场中投资者和消费者评论的情感极性二分类, 实验达到86.2% 的准确率;2021 年,Li 等[23]提出了BERT+FC 模型用于9 204条中国股票评论进行情感极性二分类任务,达到了92.56%的准确率。2022 年,杨春霞等[24]提出基于BERT 与注意力机制Attention 的方面级隐式情感分析模型DCAB 模型, 该模型首先用AABERT 生成与方面词相关的词向量, 接着使用DBGRU 进行编码,再使用语境感知注意力机制提取上下文中与给定方面词相关的深层特征信息,实验效果优于基线模型。2023 年, 胡晓丽等[25]提出一种融合ChineseBERT 和双向注意力流(bidirectional attention flow,BiDAF)的中文商品评论方面情感分析模型,该模型主要将Transformer 和双向注意力流的输出同时输入到多层感知机中,进行信息级联和情感极性的分类输出,并在其中一个数据集上达到82.90%的识别准确率。深度学习算法在处理海量文本数据时比较有优势,而且能够取得不错的分类效果。
由上述分析可知,相较于英文,当前中文情感极性分类任务以二分类居多,其分类任务细粒度和分类准确率还有很大的上升空间。针对该问题,本文依托京东网站上真实的手机评论建立了一个中文电商产品评论数据集Q, 该数据集包含积极评论、消极评论和中性评论,3 类评论,其中的中性评论定义为包含积极情绪与消极情绪的复合语句。同时,一些机器学习算法和深度学习算法在许多工程应用的分类问题中取得了不错的效果,但单一模型的效果并不稳定, 模型的泛化能力有待进一步提升。针对该问题,文中提出一种新的混合深度学习算法和机器学习算法的中文情感分析方法, 该方法使用Stacking 集成学习思想, 在第1 层使用Chinese-BERT-wwm、TextCNN、BiLSTM 对训练集数据进行特征信息提取, 捕获中文文本数据上下文的语境、语义、语序重点特征信息,得到具有不同中文评论特征信息的句子代表向量,将其进行拼接得到含有丰富句子特征信息的特征融合向量,然后将SVM 作为第2 层添加到模型中,对第1 层得到的特征向量进行分类, 实现最终的情感极性分类。通过在数据集上验证,新的方法使得情感分析过程中提取到的每条文本数据的信息更加丰富,提高了中文情感极性分类的准确率,能够为后续方面级别的情感分析任务提供更好地支撑。
1 融合Stacking 集成学习和深度学习技术的模型
1.1 Stacking 算法与模型框架
集成方法是一组结合了个体预测(单个模型)的学习模型。根据三向决策[26]理论,属于一个分类器的低置信度决策区域的数据样本可能属于另一个分类器的高置信度决策区域。使用不同的分类器可以提高分类系统的整体置信度,提高结果的准确性,提升模型的泛化能力。Stacking 集成算法在1992 年被Wolpert 提出[27],包含基学习器和元学习器2 层。其基学习器结构理论上要求是异构的,即所采用的基学习器来自于不同的学习算法,并且分类结果具有的一定的准确性[28]。如图1 所示,3 个不同类型的基学习器使用相同的数据集来训练,其他算法可以作为元学习器。其中元学习器对基学习器的输出y1、y2、y3进行进一步学习得到最后的输出结果yc。
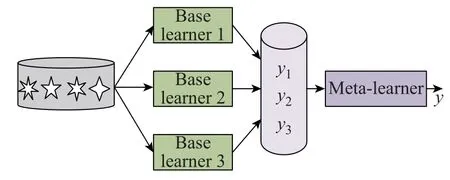
图1 3 个基学习器的Stacking 集成示意图Fig.1 Stacking integration diagram of three base learners
为了评价中文电商产品评论文本中情绪的整体表现, 本研究提出了一种新的融合Stacking 集成学习和深度学习技术的情感分析模型,模型结构如图2 所示,该模型总体分为2 层: 第1 层为文本特征提取层, 包括3 个深度学习算法, 主要是取得丰富的文本信息特征,通过将句子分别输入Chinese-BERTwwm、TextCNN、BiLSTM 三基分类器学习,分别提取评论中的语义、语序等重要信息特征并将其融合,形成最终的表示向量作为元分类器的输入; 第2 层是一个经典的有监督分类算法SVM,实现对其特征的情感极性分类,SVM 应用在文本情感情感分析中有较好的分类效果,但SVM 未能深入提取文本中的语义信息,应用集成学习思想同时结合深度学习算法可以克服这个问题,进一步提高分类准确率。
1.2 文本信息特征提取层
文本信息特征提取层使用深度学习算法, 关键是如何提取语义特征并融合信息,本研究在该层考虑了Chinese-BERT-wwm、TextCNN、BiLSTM,3 个基学习器。评论文本输入到中文BERT 即Chinese-BERT-wwm 得到768 维度的句子表征向量,取倒数第2 层记作Vi1。
对于TextCNN 和BiLSTM,首先使用Tokenizer编码将预处理后的中文电商产品评论文本序列化,然后经过embedding 层进行向量化, 设置最大句子长度128, 词向量维度128, 将该128×128 的句子向量矩阵分别输入到TextCNN 和BiLSTM 中进行文本特征信息提取,其中TextCNN 利用一维卷积法提取文本情感极性分类任务中的重要字词语义特征信息,卷积层共设置3 个不同大小的卷积核,每个通道中卷积核的数量设置为256 以学习不同的特征和获得更多的特征信息,核大小分别为3、4、5。然后通过最大池化操作进一步抽取局部关键语义特征信息,将3 个向量矩阵进行拼接,经过Flatten 一维扁平化和dense 层降维,取倒数第2 层维度为128 的特征向量Vi2。
BiLSTM 用于从前后2 个方向捕获更深层次的上下文语义信息,将embedding 后的向量矩阵输入到BiLSTM 中, 经过dense 层降维, 取倒数第2 层128 维度的句子表征向量Vi3。
将Vi1、Vi2和Vi3拼接融合,该1 024 维的文本信息特征向量记为Vi。特征提取层引入Dropout 层,设置dropout 值为0.1,随机丢弃一些激活参数,选择一些神经元将其设置为零,迫使神经元在不相互依赖的情况下独立提取合适的特征,有助于缓解模型过拟合问题[29]。
在接下来的小节中,将描述每种分类方法。
1.2.1 Chinese-BERT-wwm
最初的BERT 预训练模型[30]由谷歌于2018年提出, 在SA 的任务中, BERT 在面对一些陌生且更复杂的句子上取得了比以往的词向量模型更好的性能[31]。后面谷歌为中文提供了BERT 模型BERT-base, Chinese, 并使用全词Mask 技术(whole word masking, WWM)作为预训练阶段的训练样本生成策略,在BERT-base,Chinese 中,中文是以字为粒度进行切分, 没有考虑到传统NLP 中的中文分词(Chinese word segmentation, CWS), 模糊了中文完整词语的边界。2021 年, Cui 等[32]基于谷歌的研究工作针对中文提出了一系列中文BERT 模型,Chinese-BERT-wwm 就是其中之一。Chinese-BERTwwm 模型考虑了中文分词, 将WWM 技术应用在中文环境中, 使用中文维基百科(包括简体和繁体)进行训练, 并且使用了哈工大的语言技术平台LTP(http://ltp.ai)作为分词工具。
Chinese-BERT-wwm 模型中, WWM 是指如果一个词语的部分字被Mask 替换,则对应词语的剩余汉字部分也全被Mask 替换。Mask 包括用[MASK]标签替换、保留原始字词, 或随机替换为另一个字词, 这增强了Chinese-BERT-wwm 模型捕捉词语间边界关系的能力。对于中文文本数据, Chinese-BERT-wwm 模型具有更灵活和稳健的中文文本特征信息提取能力。以一个中文句子中一个词其余部分被替换为[MASK] 标签为例展示使用WWM 的句子生成样例, 如表1 所示。Chines-BERT-wwm 的输出是一个768 维的动态向量, 以[CLS]作为整个句子开始的向量化表示。

表1 1 个分词后的中文句子使用WWM.的样例Tab.1 Example of using WWM.for a Chinese sentence after a word break
1.2.2 TextCNN
TextCNN 模型由Kim 等[14]提出,是CNN 模型的变体,在CNN 的基础上增加了不同卷积核大小的卷积通道,增强了其捕获文本不同长度字词关键特征信息的能力,TextCNN 主要结构包括以下4 层。
TextCNN 的第1 层为输入层,包含1 个句子向量矩阵E ∈Rn×d,n表示固定的最大句子长度,d表示词向量维度,ei表示句子中第i个字词,ei ∈Rd表示句子中第i个字词的d维词向量,长度为n的句子E可以表示为
TextCNN 的第2 层为卷积层,TextCNN 中可以使用不同高度的卷积核进行多通道局部语义信息特征的提取,保证特征的多样性,本文设置3 个不同的卷积核高度。将卷积核K ∈Rk×d由上至下滑动与句子向量矩阵E中全部词向量进行一维卷积操作输出特征映射(Feature mapping)
式中,卷积核宽度与输入层中词向量维度保持一致,均为d,k代表卷积核高度。
TextCNN 的第3 层是池化层。池化对C进行压缩以保留主要特征,同时去除冗余信息,提高速度。标准的池化方法包括最大池化(Max pooling)、均值池化(Mean pooling)等。本文使用1-Max pooling 最大池化方法取C的最大值C′=max{C},并拼接所有卷积核的池化结果得到更具代表性的新的特征向量Z作为输出层的输入,即
式中,t为卷积核总数量。
TextCNN 的第4 层是输出层。输出层通过Softmax 函数计算每个类别的概率分布,使用交叉熵损失函数。
1.2.3 BiLSTM
与传统的RNN 相比,LSTM 通过引入一种特殊设计的门机制和单元状态确定输出特征信息的有效性。1 个LSTM 单元包含1 个输入门、1 个遗忘门、1个输出门和1 个贯穿整个时间步长的单元状态,其结构可分别表示为:
式中:t时输入记为st;t时输出记为ht;oi表示输出门t时输出;Ct表示当前的单元状态; ~Ct当前时刻待更新的单元状态;it表示输入门t时输出;ft表示遗忘门t时输出;w表示在计算过程中不断更新的权重;b表示在计算过程中不断更新的偏差项;σ代表Sigmoid 函数;⊙表示对应位置元素乘法。
而BiLSTM 由前向LSTM 和后向LSTM 组成,在BiLSTM 中,后向LSTM 可以逆时间顺序捕获后文对前文影响的特征信息并与前向LSTM 编码的特征信息进行拼接,因此,BiLSTM 可以更好地提取到双向语义特征,它们是真正基于上下文从而使得提取的特征更具有代表性,一个BiLSTM 神经元输出二维隐层状态向量的连接向量为
式中:为t时刻前向LSTM 编码的前向隐层向量,包含从左到右的序列信息特征;为t时刻后向LSTM 编码的后向隐层向量,包含从右到左的序列信息特征;Ht是双向LSTM 单元在t时刻的隐藏状态的输出拼接向量,包含双向序列特征。
1.3 文本情感极性分类层
本研究选择SVM 作为情感极性分类层中的元学习器。SVM 由Vapnik 等[9]提出, 是经典的统计机器学习算法之一,它通过寻找最优超平面实现样本的二分类,同时可以使用核函数将原始的特征空间映射至更高维空间解决非线性样本分类问题,在文本情感极性分类任务中相对高效。本文给出核函数及其超参数组合,通过三折交叉验证和网格搜索方法选出该层最优的参数组合, 如表2 所示。其中,rbf 是径向基核函数;C 和gamma 是SVM 的超参数;实验表明当C 取10;gamma 取0.001 时,SVM 在训练样本数据上有更好的效果。

表2 情感极性分类层参数选择Tab.2 Selection of affective polarity classification layer parameters
2 实验和分析
2.1 数据集
本文数据集来自从京东网站上爬取多个品牌手机购买的真实用户评论,经人工标签校正构建了一个新的中文电商产品评论数据集,该数据集共3 万条, 包含消极评价、中性评价和积极评价3 种情感极性各1 万条,其中消极评价与积极评价定义为只包含消极、积极各一种情感极性的评论,中性评价定义为包含用户消极评价与积极评价的复合评论,可广泛用于中文情感分析领域。消极评价、中性评价和积极评价标签分别是0、1 和2,部分评论展示如表3 所示。

表3 电商产品评论数据集部分数据Tab.3 Partial data of E-commerce product review dataset
2.2 评价指标
本文按照2:1 划分训练集与测试集,并使用宏平均准确率值Acc_macro 和宏平均F值F-macro 作为模型的评价指标,其计算式分别为:
2.3 实验环境及对比模型
为了评估所提模型的有效性与泛化能力, 文中从特征提取层和分类层2 个方面设置了对比实验,对比实验考虑了直接对文本信息特征提取层用Softmax 函数进行分类和在分类层使用Xgboost[10]作元学习器时模型的性能变化, 并对比了基学习器算法TextCNN、BiLSTM、Chinese-BERT-wwm,元学习器SVM 单独的模型分类效果及基学习器中Chinese-BERT-wwm 不使用训练集进行预训练对模型分类效果的影响, 实验均基于Python3 中的Tensorflow 框架进行,训练批次为128,各个对比模型及其实验编号设置如表4 所示。

表4 对比模型列表Tab.4 List of comparison model
2.4 实验与结果分析
表5 展示了基线模型与本文提出的模型在1 万条电商产品评论文本测试数据集上预测的情感极性分类效果。为了更直观的观察模型效果,做柱状图如图3 所示。

表5 提出的模型与基线模型性能对比Tab.5 Performance comparison between the proposed model and the baseline model

图3 基线模型与提出模型分类效果柱状图Fig.3 Baseline model and proposed model classification performance bar chart
由表5 和图3 可见,在第0 组实验中,本文提出的模型Acc_macro 值可以达到93.04%, F-macro 值达到93.02%, 与第1、第2 组实验相比, 使用SVM做分类层比使用Xgboost 和直接对特征提取层的融合特征向量直接分类的评价指标均有所提高, 而与第5~8 组TextCNN、BiLSTM、Chinese-BERT-ww 和SVM 单个算法的分类效果相比,Acc_macro、F_macro 值最大可以提高10% 以上,这表明使用集成思想将深度学习算法与监督学习算法SVM 相结合的思路是正确并有效的,本文提出的模型具有更好的分类准确性和稳健性。另外,将第0组与第9 组实验、第1 组与第3 组实验、第2 组与第4 组实验结果依次两两相比发现,在集成模型特征提取层使用微调后的Chinese-BERT-wwm 对模型效果有着显著的提升,Acc_macro 值、F_macro 值从87%~88%提高到92%~93%,这证明了使用相关的语料库对Chinese-BERT-wwm 进行预训练可以提高模型预测的准确度,增强模型的泛化能力。
进一步对文中提出的模型在各类别分类预测的效果进行统计,1 万条测试数据中,其中消极评论和中性评论各3 333 条,积极评论3 334 条,得到混淆矩阵(Confusion Matrix)如表6。

表6 提出的模型中对不同极性评论的预测效果Tab.6 Prediction of different polarity comments in the proposed model
在表6 中,测试集中3 333 条消极评价数据预测为积极评价仅有2 条,预测为中性评价267 条;3 334条积极评价预测为消极评价是0 条, 预测为中性评价是53 条; 3 333 条中性评价预测为真的数据量是2 959, 误判374 条, 其中276 条被误判为消极评价, 98 条被误判为积极评价, 可以看出积极评论与消极评论互相误判的概率很小,而二者与中性评论误判的概率稍大,计算得到模型预测消极评价的准确率是91.93%, 预测积极评价的准确率是98.41%,而预测中性评价的准确率是88.78%, 可见模型对积极评论最为敏感, 预测准确率最高, 对中性评价最不敏感, 预测的准确率最低, 拉低了模型最终的Acc_macro,分析数据集可知文中用到的中性评论包含用户对商品的积极情绪和消息情绪两种情绪,相对于积极评论和消极评论情感词多有变化且句式更加复杂,这在一定程度上可能增加模型对中性评价学习与预测的困难程度,因此导致了预测中性评价的误判率高于另外2 类。
3 总结与展望
针对当前中文电商产品评论数据多为2 种单极性的情况, 本文依托电商平台构建了一个真实的3 类别中文电商产品评论数据集, 并提出了使用Stacking 集成学习将能够多维度提取丰富的文本数据信息特征的Chinese-BERTwwm、TextCNN、BiLSTM 3 类深度学习算法与传统高效的有监督机器学习算法SVM 相结合构建新的模型的思想,和基线模型的实验结果比较,提出的模型在分类预测准确度和泛化能力上表现更好,使用相关领域的语料库预训练Chinese-BERT-wwm 对提高模型性能也是必要的,通过该模型可以有效识别出电商产品中的积极评论、消极评论和中性评论三类评论。但不足之处在于模型对于中性评论的识别准确率还有待提高,需要进一步的研究与探索,并且使用Chinese-BERT-wwm 训练文本数据的时间相对其他模型长,未来可以研究轻量化的中文BERT 以提高模型运行效率。
