基于扩散模型的流场超分辨率重建方法1)
2023-11-16朱军鹏郭春雨范毅伟汪永号
韩 阳 朱军鹏 郭春雨 范毅伟 汪永号
* (哈尔滨工程大学船舶工程学院,哈尔滨 150001)
† (哈尔滨工程大学青岛创新发展基地,山东青岛 266000)
引言
在流体力学领域,通过实验或数值模拟手段都难以获得复杂湍流速度场信息,因此如何能简便地获取高保真、高分辨率的流场信息是研究人员长期以来的追求目标.流场的超分辨率重建技术可将低分辨率流场数据通过预先训练好的神经网络模型直接重建成高分辨率的流场数据,相较于计算流体动力学方法(CFD)可以节约大量计算资源和时间成本.在本文中,提出一种具有广泛适用性的神经网络模型,可以将低分辨率的流场信息提高其分辨率并还原各种经典流场的流动细节.
深度学习作为一种新兴技术在图像处理、自然语言处理、语音识别和多模态学习[1]等领域发展迅速.近年来,该技术被应用于实验流体力学方向,处理大量复杂非线性和高维度流场数据[2-3].通过深度学习方法可以对流体运动进行估计,从而提升流体速度场的分辨率.例如,Guo 等[4]研发了一种实时预测的卷积模型,以低错误率为代价,预测速度比CFD快了两个数量级.Lee 等[5]开发了一个4 级回归卷积网络,从输入两张图像中获取速度场.Cai 等[6]基于卷积神经网络对PIV 粒子图像对进行流动估计.然而这些基于卷积神经网络对流体运动估计缺乏先验物理规律.为了弥补基于卷积神经网络对流动估计性能的不足,Lagemann 等[7]提出了基于光流架构的递归全场变换(RAFT)模型,在低密度颗粒密度和光照强度变化的条件下表现良好,并且可以端到端地学习位移场.
除此之外许多研究专注于利用深度学习其强大的流动信息特征提取与数据同化的能力,对低分辨率流场进行超分辨率重建.在计算机视觉领域,超分辨率(SR)是一种通过数字信号处理的方法提高图像空间分辨率的技术.2014 年Dong 等[8]首次在SR 问题上使用深度学习方法,提出用于单图像超分辨率的SRCNN 模型,执行端到端的超分辨率任务.随后多种超分辨率模型被设计出来,例如超深超分辨率网络VDSR[9]、超分辨率生成对抗网络SRGAN[10]、稠密连接超分辨率网络SRDenseNet[11]和深度残差通道注意力网络RCAN[12]等模型.SR 已成为计算机视觉领域的研究热点.受此启发,研究人员将深度学习方法应用于流场的超分辨率重建.
例如,Lee 等[13]提出了基于生成对抗网络(GAN)的湍流小尺度建模方法,该方法可以凭借较少的计算成本对未处理的模拟数据进行结构预测.Deng 等[14]将超分辨率生成对抗网络(SRGAN[10])和增强型SRGAN(ESRGAN[15])应用于流场的超分辨率重建任务中,以增强两个并排圆柱后面复杂尾流的空间分辨率,结果表明可以把粗流场的空间分辨率显著提高42和82倍,能够准确地重建高分辨率(HR)流场.Fukaimi 等[16]开发了一种混合下采样跳跃连接/多尺度模型,对二维圆柱绕流进行测试,仅仅需要50 个训练数据,就可以极大地提高空间分辨率.但是该研究的工况和所搭建的模型都比较简单.Liu 等[17]设计了静态卷积神经网络(SCNN)和多时间路径神经网络(MTPC),可以高精度重建强制各向同性湍流的高分辨率流场.Kong 等[18]做了类似的工作,提出了多路径超分辨率卷积神经网络(MPSRC),可以捕捉温度场的空间分布特征,成功超分辨率重建超燃冲压发动机燃烧室的温度场.Ferdian 等[19]提出一种新型超分辨率4DFlowNet 模型,通过学习从有噪声的低分辨率(LR)图像到无噪声HR 相位图像的映射,能够产生清晰解剖区域的无噪声超分辨率相位图像.2021 年Fukaimi 等[20]开发了用于时空SR 分析的深度学习方法,可以从空间和时间上的少量数据点重建高分辨率流场.但是其模型训练十分复杂,并严重依赖训练数据的时空关系.Bi 等[21]设计由多个多尺度聚合块(LMAB)组成的FlowSRNet 模型,同时做了轻量化设计,提出LiteFlowSRNet 架构,对各种经典流场进行超分辨率重建,达到了先进SR 性能.为了对流场进行物理约束,Raissi 等[22]提出了基于物理的神经网络(PINN),可以用偏微分方程描述给定数据集的物理规律,并在圆柱绕流的示例中展示其解决高维逆问题的能力.随后Raissi 等[23]将流体力学基本方程N-S 方程编码到神经网络里,通过自动微分技术对模型输出求导,并带入N-S 方程计算残差,最终反向传播优化模型参数,实现通过软约束对颅内动脉瘤影像的生物流场重构.Shu 等[24]提出一种仅在训练时使用高保真数据的扩散模型,用于从低保真CFD 数据输入重建高保真 CFD 数据,并且可以通过使用已知偏微分方程的物理信息来提高计算准确性,然而文中并未将扩散模型与其他深度学习模型进行详细的流场重建性能对比.
与上述工作不同,本文提出了一种适用于流场超分辨率重建的生成模型FlowDiffusionNet(FDiff-Net),该模型是基于扩散概率模型提出的.扩散概率模型(扩散模型)[25-26]是一种生成模型,其使用马尔科夫链将简单分布(如高斯分布)中的潜在变量转换为复杂分布的数据.扩散模型已经在诸如图像合成和超分辨率图像重建等领域中大放异彩.其中,谷歌团队提出的SR3[27]模型和浙江大学提出的单张图片超分辨率扩散模型SRdiff[28]均在图像超分辨率上取得了优异的结果.受此启发利用扩散模型对低保真的流场数据进行重建,所提出的模型主要由低分辨率(LR)编码器和模型主体构成,利用残差特征蒸馏模块(RFDB)[29]作为LR 编码器对低保真数据进行编码,模型主体选用Unet 作为架构并增加自注意力层,使得模型在深层次里获得更大的感受野.对所提出的FlowDiffusionNet 模型在多个经典流场数据集上进行了测试,并比较了直接预测高保真流场数据进行流场重建与预测高保真数据残差后进而重建流场的性能.并且在推理过程中,为了加快推理速度,引入了Dpm-solver[30]求解器.总结为以下3 项贡献:
(1)提出了便于迁移训练的FlowDiffusionNet 软约束扩散模型,用于精准地进行流场超分辨率重建,为了更好提取LR 流场的特征,选用了RFDB 模块作为LR 编码器;
(2)提高了模型的流场超分辨率重建速度,将DPM-solver 求解器应用到推理过程,提高了模型的效率;
(3)全面评估该模型的性能,构建了多种经典SR 流场数据集,并根据不同因素对复杂流场进行降采样,从而验证模型的适用性与稳定性.
1 研究方法
1.1 总体框架
扩散模型作为一种新兴的生成式模型,避免以往对抗神经网络难以收敛以及崩溃的问题,因此更适用于处理比较大的流场数据信息.并且扩散模型相较于卷积神经网络与物理神经网络,更易进行不同降采样倍率的迁移学习,其适用性和泛化性更强.本文方法总体框架如图1 所示,包括两个过程: 前向扩散过程在上面用绿色箭头表示,为无参数学习;反向扩散过程在下面用蓝色箭头表示,进行参数优化.图中y0表示预测流场的残差,参数 θ是由神经网络模型拟合的.
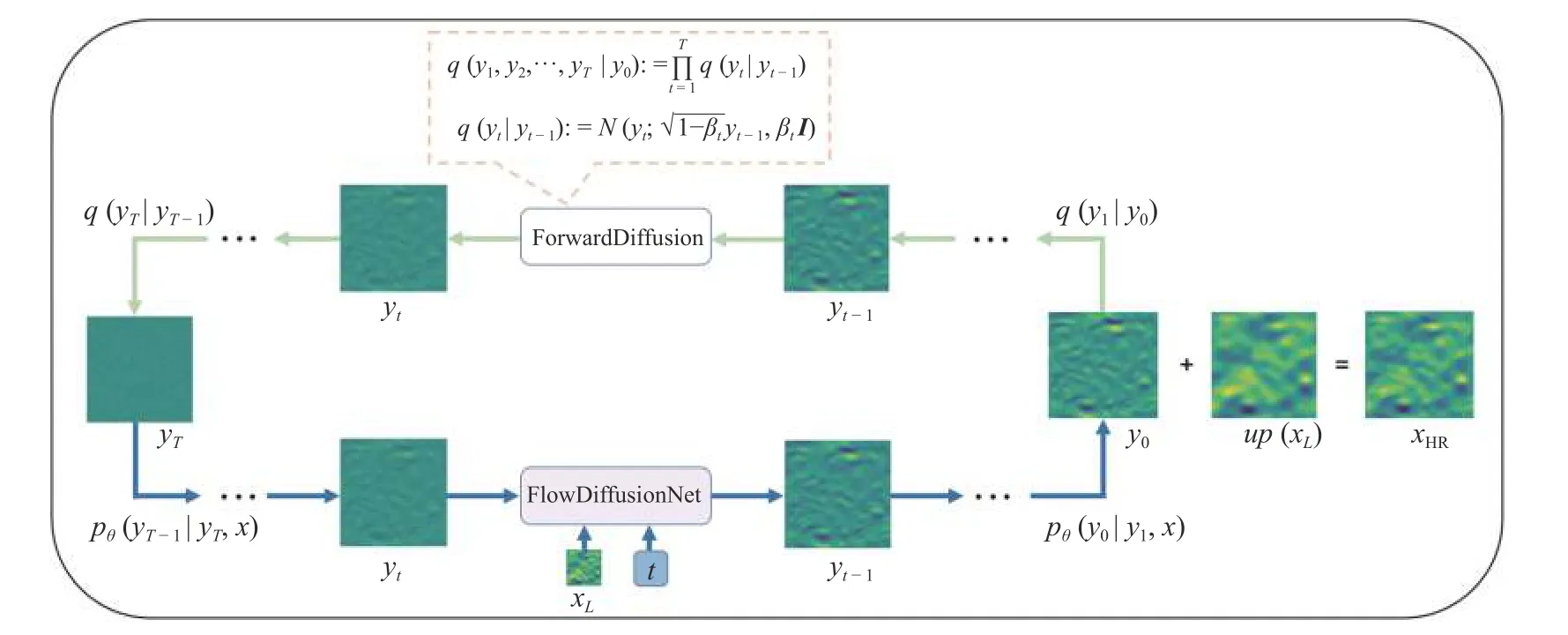
图1 FlowDiffusionNet 模型重建高保真流场的原理Fig.1 The principle of FlowDiffusionNet model to reconstruct high-fidelity flow field
1.2 扩散模型
在本节中,介绍扩散模型的基本概念[25].扩散模型是一类概率生成模型,采用参数化马尔可夫链,通过变分推理训练,学习如何逆转逐渐退化训练数据结构的过程.扩散模型训练过程分为两个阶段: 前向扩散过程和反向去噪过程.
前向扩散过程可以描述为逐渐破坏数据结构的前向加噪处理,通过不断向输入的数据中添加低水平的噪声(高斯噪声),直到全部变成高斯噪声.给定原始的训练样本满足y0∼q(y0),通过预先设置好的一组数据 β1,β2,···,βT∈[0,1),将数据分布q(y)转换成潜在变量q(yT)
其中T是扩散总步数,βt可看作控制扩散步骤方差的超参数,I是与输入数据y0具有相同维度的矩阵,N(y;µ,σ)表示均值为μ且方差为α的正态分布.前向过程可对任意的时间步t处进行采样
反向扩散过程可以描述为学习从噪声输入中恢复原始数据的反向去噪处理,采用类似的迭代过程,通过每一步去除噪声,最终重建原始数据.然而,由于q(yt-1|yt)取决于整个数据分布,扩散模型使用神经网络作如下近似
其中pθ(yt-1|yt)为参数化的高斯分布,他们的均值和方差由训练的网络μθ(yt,t)和σθ(yt,t)确定.
在训练阶段,我们最大化负对数似然的变分下界(ELBO),并引入KL 散度和方差缩减[25]
方程(6)使用KL 散度直接将pθ(yt-1|yt)与前向过程后验分布q(yt-1|yt,y0)进行比较
根据式(3)、式(5)和式(7)得知,等式(6)所有KL 散度是高斯分布之间的比较.当t>1 且C为常量时,可以得到
可将方程(6)简单优化后进行训练,有利于提高样本生成质量
其中ϵθ为噪声预测因子.
在推理过程中,首先从高斯分布 N (0,I),采样潜在变量yT,然后根据等式(5)进行采样yt-1∼pθ(yt-1|yt)其中
1.3 条件扩散模型
在本节中,将在扩散模型的基础上介绍条件扩散模型.条件扩散模型的前向过程与扩散模型基本一致,目的是将原始数据分布y0转换成潜在变量yT.反向过程是从潜在变量yT开始,利用原始数据x的附加信息,来优化去噪神经网络的ϵθ,从而恢复无噪声的原始数据y0.该模型是将原始数据x和由式(4)得到yt数据状态作为输入,通过训练来预测噪声向量ϵ.在训练过程,参数化μθ有许多不同的办法,显然可以使用神经网络预测εθ(yt,t,x),之后通过等式(11)得到μθ(yt,t,x),根据Saharia 等[27]建议,可将训练ϵθ的目标函数设定为
本文选用的参数重整化方法是通过神经网络预测y0,输出的结果可以根据等式(8)和式(11)产生μθ(yt,t,x).其训练fθ的目标函数可以表示为
推理过程是通过神经网络预测在每个时间步长处去除的噪声,从而逐步重建数据来生成目标数据
根据神经网络学习高斯条件分布pθ(yt-1|yt,x)定义整个推理过程.如果前向过程噪声方差设置足够小,那么反向过程p(yt-1|yt,x)近似高斯分布,即证明了在推理过程选择高斯条件可以为真实反向过程提供合理的拟合.并且 1-t应该足够大,使得潜在变量yT满足等式(16).
1.4 FlowDiffusionNet
FlowDiffusionNet 是一种条件扩散模型,总体框架如图一所示.建立在T步扩散模型之上,该模型包含两个过程: 扩散过程和反向扩散过程.不是直接预测 HR 流场,而预测 HR 流场xH和上采样 LR 流场up(xL)之间的差异,并将差异表示为输入残差流场y0.扩散过程通过向残差流场y0不断添加高斯噪声,如方程(4)表示,直到变成高斯分布yT.反向扩散过程通过使用条件残差流场预测器,以低分辨率编码器(简称LR 编码器)对LR 的流场编码输出为条件,在有限时间步迭代去噪,将高斯分布yT变成残差流场y0.SR 流场是通过将生成的残差流场y0添加到上采样LR 流场up(xL)来进行重建的.
在接下来的小节中,将介绍条件残差流场预测器、LR 编码器、训练和推理的框架.
1.4.1 条件残差流场预测器
根据式(15)~式(17)构成条件残差流场预测器,定义x是输入模型里面的条件,在超分辨率流场重构任务中x代表LR 流场xL,根据神经网络学习高斯条件分布pθ(yt-1|yt,x)进行推断HR 流场xH.如图2 所示,使用U-Net 作为主体,以2 通道yt(u,v)、扩散时间步长t以及LR 编码器的输出作为输入,其中“res block”,“downsample”,“attention block”,“upsample”分别表示残差块、下采样块、自注意力块和上采样块;“DS”和“US”分别表示下采样步骤和上采样步骤;其中“DS”和“US”后面括号里(c,2c,4c)表示每个步骤通道数量.

图2 FlowDiffusionNet 的总体网络框架Fig.2 The overall network framework for FlowDiffusionNet
首先通过一个二维卷积层将yt转换到激活状态,之后把隐藏状态yt与经过编码的LR 流场信息在通道上进行融合,并将其输入到UNet 模型里面.通过正弦位置编码将时间步长t编码至隐藏状态te[31],并将te输入到每一个残差模块中.下采样路径由一个残差模块和一个下采样层构成,上采样路径由两个残差模块和一个上采样层构成,这样不对称的设置有利于设置更加密集的多尺度跳跃残差连接,从而保证条件残差流场预测器稳定.第2 和第3 下采样路径中将通道尺寸加倍,并在每个下采样路径中将特征图的空间尺寸减半,以求降低模型的参数量,并提高其采样速度.中间路径由两个残差块和一个自注意力模块组成,这有利于模型在增大感受野同时降低参数量.最后将上采样路径输出,应用swich 函数进行激活,并通过卷积预测yt-1的残差流场.
1.4.2 LR 流场编码器
采用LR 流场编码器对上采样LR 流场up(xL)信息进行编码,并将其添加到每个反向步骤中以引导生成到相应的 HR 流场.在本文中,选择使用残差蒸馏网络(RFDN)模型[29]的RFDB 架构,如图3 所示,“SRB”表示浅层残余模块,“CCA Layer”表示规范相关分析,该架构的特征提取层和信息蒸馏层,可以全面提取上采样 LR 流场up(xL)信息.并且舍弃掉RFDN 模型的最后一个上采样层,因为经过测试证明这样做的效果要优于将直接LR 流场xL输入RFDB 模块,较低分辨率输入会使得不同的特征提取层输出信息更加相似,且在上采样层会破坏原始LR 流场xL信息.

图3 RFDB 架构Fig.3 RFDB architecture
1.4.3 训练与推理过程
在训练阶段,如图4 所示,从训练集中输入相应LR-HR 流场对,用于训练总扩散步长为T的Flow-DiffusionNet.将xL上采样为up(xL),并计算流场残差HR-up(xL).第1 步: 将流场残差y0输入正向扩散模块采样出任意t时刻流场残差状态yt,并输入模型里,值得注意的是这步没有可学习的参数,所有参数都是预先设置好的.第2 步: 通过LR 流场编码器将up(xL)编码为xe,并输入模型.第3 步: 计算模型输出yˆ和目标输出y0的均方误差MSEloss,并反向优化FlowDiffusionNet 的参数.
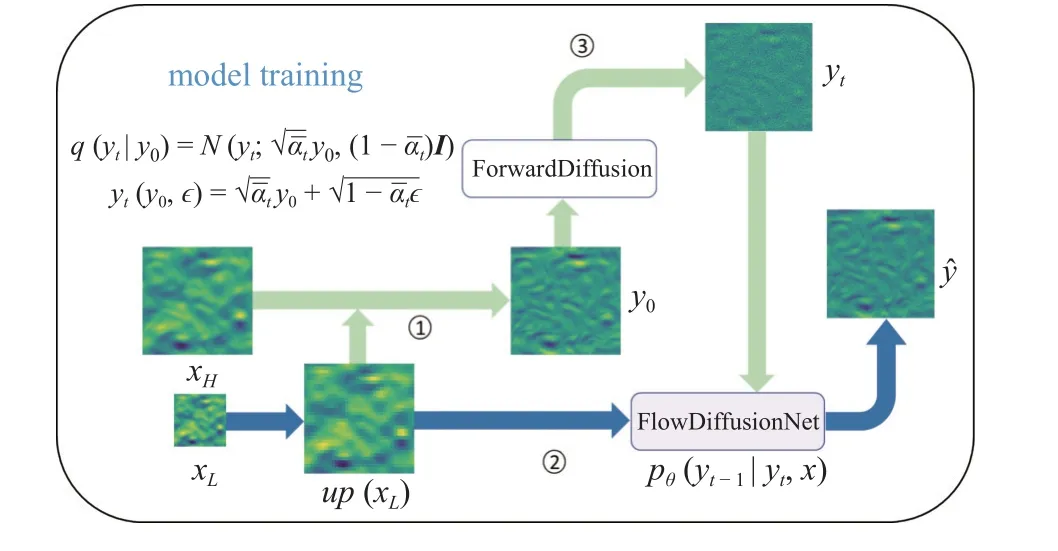
图4 模型的训练过程Fig.4 The training process of the model
推理过程如图5 所示,使用DPM-solver[30]快速采样器,极大加快了模型的采样速度,使得该模型可以在短时间内处理大量流场数据信息.如图5所示,第1 步: FlowDiffusionNet 模型在推理过程中将上采样 LR 流场up(xL)与从标准高斯分布中采样得到的潜在变量yT作为输入,预测t=0 时刻的残差流场;第2 步: 将神经网络预测的流场yˆ输入到DPMsolver 快速采样器里面,从而采样出t时刻的残差流场yt;第3 步: 将残差流场yt和上采样 LR 流场up(xL)再次输入到神经网络里,预测t=0 时刻的残差流场.随后重复第1 和第2 步直至采样出原始残差流场y0.最终在上采样LR 流场up(xL)添加残差流场y0来恢复SR 流场.
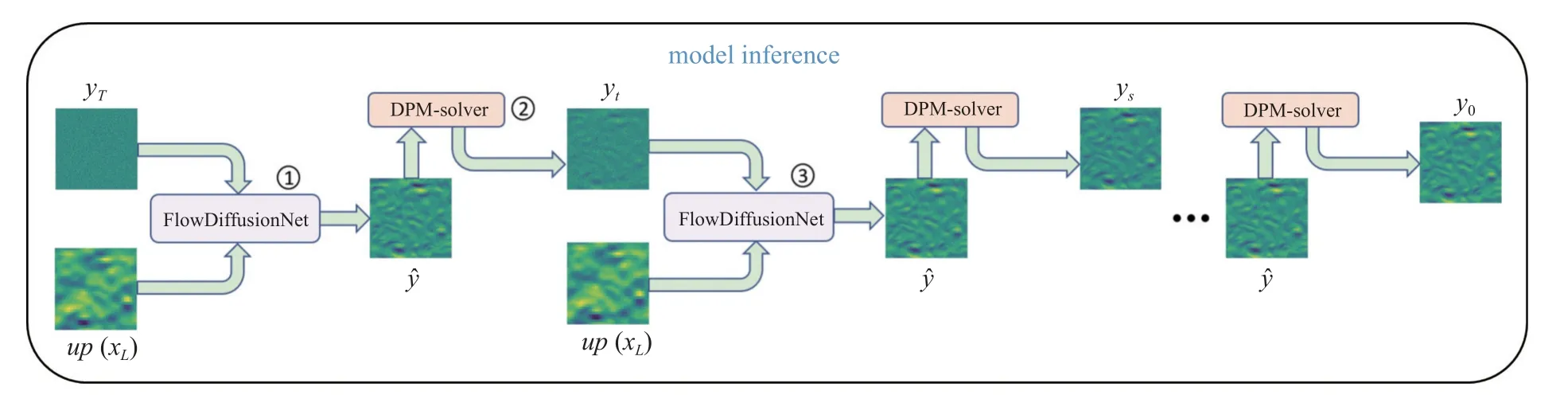
图5 模型的推理过程Fig.5 The inference process of the model
2 数据集构建和训练及采样过程细节
在本节中,首先描述制作数据集的原理和过程,随后介绍模型训练及采样的一些细节.
2.1 数据集构建
本文根据参考文献收集了5 个经典流场,包括:二维湍流运动[32](DNS 湍流)、地表准地转流[33](SQG)和约翰霍普金斯湍流数据库[34](JHTDB)等复杂流场,其可以从公开文献中获得.表1 列出了不同经典流场的用于训练和测试的数据集数量,并且SR 数据集中的流场数据不具有严格时间连续性.
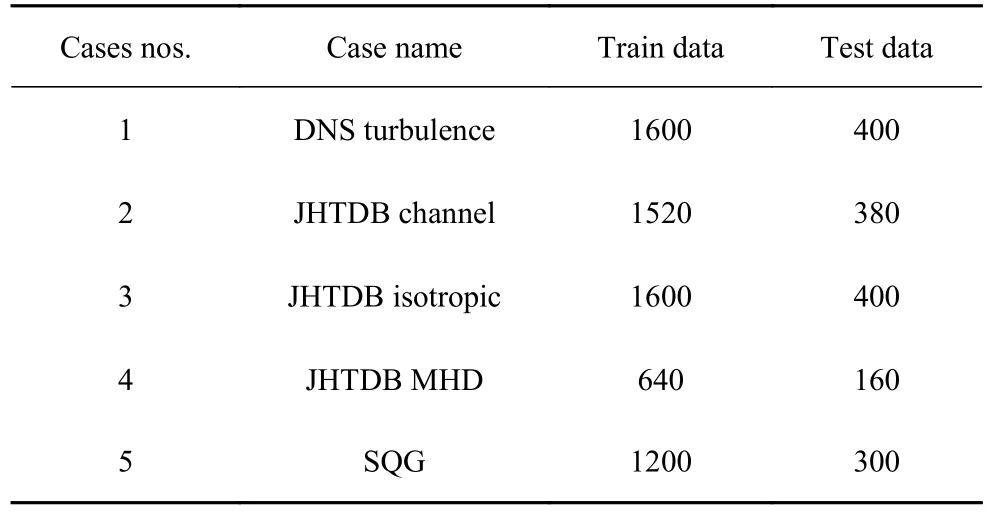
表1 不同流场SR 训练集与测试集数量Table 1 Number of SR training and test sets for different flow fields
接下来我们通过一种常用的降采样策略来降低流场数据的分辨率,生成低分辨率流场数据从而构建LR-HR 数据对
其中G代表退化模糊操作,α代表下采样因子,通过经典的高斯模糊结合双3 次下采样方案,高斯模糊核函数的公式如下
其中 σ设置为5,高斯核大小设置为16×16,HR 流场数据与LR 流场数据之间的差异可以用下采样因子 α表示
其中M表示流向速度矢量的数量,N表示展向速度矢量的数量.为了综合评价模型在不同分辨率下的重建能力,选择了3 种不同的下采样因子,即4,8 和16.构建的SR 数据集包含复杂的湍流结构(DNS 湍流和 JHTDB)和小尺度涡流结构(SQG 和 DNS 湍流),这使得流场重建任务具有挑战性.如图6 所示,展示了在 α=8 下构建的SR 流场数据集.
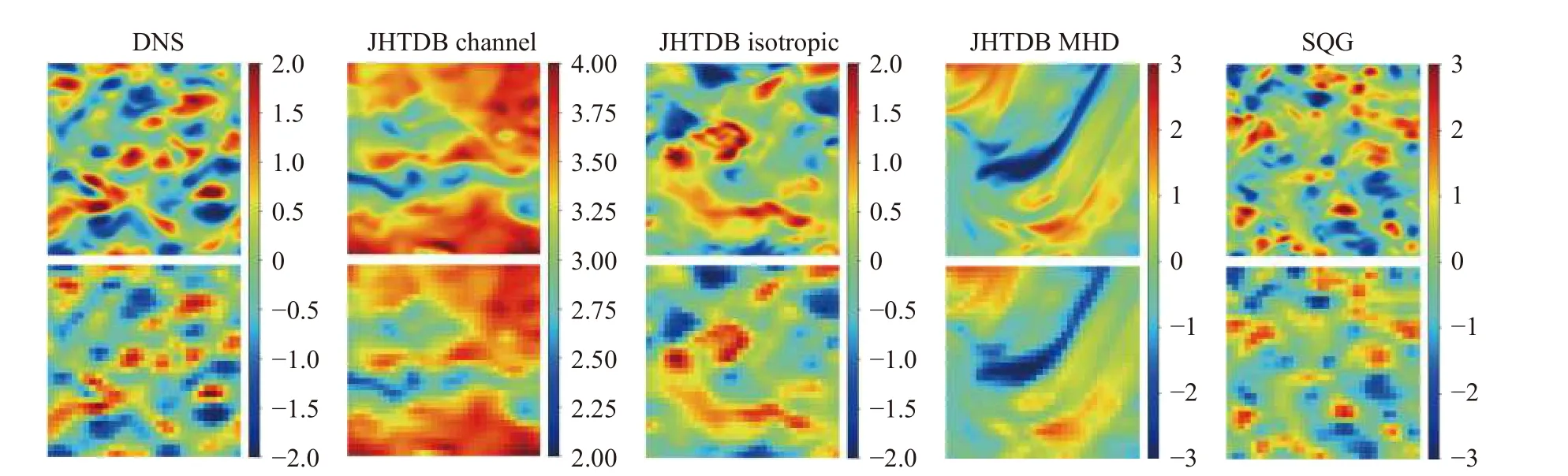
图6 超分辨率流场数据集Fig.6 Super-resolution flow field datasets
2.2 训练细节
FlowDiffusionNet 模型是在一台NVIDIA 3060 GPU 的电脑上面通过pytorch 实现的.在训练阶段,选择MSE 作为损失函数,并应用Adam 优化器,初始学习率设置0.00003,dropout 设置为0.1 来优化模型参数.模型训练超参数设置包括设置扩散步长T=1000,并把前向过程的方差设置成随步长动态增大,从0.000 1 线性增加到0.02.首先在32×32 空间分辨率→256×256 空间分辨率的数据集上训练,随后将在32×32 空间分辨率→256×256 空间分辨率训练好的参数,分别迁移至64×64 空间分辨率→256×256 空间分辨率的数据集上和16×16 空间分辨率→256×256 空间分辨率的数据集上进行训练,模型的总参数量为69.7 M.
2.3 采样细节
在本文的推理过程中,采用了DPM-solver 采样方法[30].该采样方法具有多种优点,包括不需要任何训练即可适用于扩散模型的采样,并且相较于先进的无训练采样方法,可实现约10 倍的加速.DPMsolver 利用扩散常微分方程的半线性,通过由噪声预测模型的指数加权积分,直接近似扩散常微分函数的精确解.该采样器可以采用1 阶、2 阶和3 阶模式来近似噪声预测模型的指数加权积分,其中1 阶模式与DDIM[35]采样过程相同.为了兼顾采样质量和速度,设置了预测xstart的离散噪声序列DPM 2 阶求解器,并应用自适应采样方法.
3 实验
在本节中将对FlowDiffusionNet 模型的性能进行评估,首先介绍定量及定性评估模型的标准,随后比较了不同模型重建流场的精度,最后可视化涡量场并验证其重建效果.
3.1 评估标准
借鉴评估图像相似度的两个重要指标,峰值信噪比(PSNR)及结构相似度指标(SSIM).PSNR表示精度的破坏性噪声功率的比值,是衡量原始图像与处理后图像数据质量的重要标准,一般认为其值高于40 质量极好,30~40 之间质量是可接受的.具体的公式如下
其中MaxI表示原始数据的最大像素值,MSE表示原始数据与重建数据之间的均方误差.
SSIM是感知模型,可以衡量图片的失真程度,也可以衡量两张图片的相似程度.具体的公式如下
其中 µx和 µy分别表示原始数据x和重建数据y的平均值,σx和 σy分别表示x和y的标准差,σxy则表示x和y的协方差,c1和c2是常数避免分母为0.
在定性评估中,通过可视化重建流场数据的速度场和涡量场分布,从而直观地观察到重建流场的详细信息.
3.2 流场重建精度比较
首先,对提出的FlowDiffusionNet 模型进行了评估,比较其在预测流场残差和直接预测原始流场时对于不同流场的重建性能.为了凸显该模型在流场重建方面的优越性,同时选取了几种常用的流场超分辨率(SR)方法进行比较,包括传统的双三次插值方法(bicubic)[36],基于卷积神经网络(CNN)的SRCNN 方法[8]和基于生成对抗网络(GAN)的SRGAN 方法[14].为了评估流场在不同分辨率尺度下的重建能力,选取了 α为4 (中分辨率水平)、8 (低分辨率水平)和16 (超低分辨率水平).
如表2 所示(表中SRGAN 和SRCNN 性能效果来源于文献[21]),其中FDiffNet_res 表示预测HR 流场残差,FDiffNet_Nres 表示直接预测HR 流场,性能最高值加粗表示,所提出的模型在不同的流场数据集中均展现出了最优秀的性能表现.具体而言,对于涉及复杂湍流的流场,双三次插值方法的PSNR普遍难以超过30,且其流场重建效果较差,与深度学习方法相比仍存在显著差距.特别是对于包含小尺度涡结构的流场数据集,例如DNS 和SQG,传统方法在重建精度方面表现最低,相应的PSNR和SSIM评价指标仅分别为20.096/0.758 和22.113/0.728.这说明在局部小尺度涡旋重建任务中,传统方法的性能相对于本文提出的模型仍存在明显的差距.可以看到,SRGAN 和SRCNN 在 α=4 中等分辨率下,流场重建精度SSIM可以达到0.9 以上.同样基于生成的模型,SRGAN 的流场重建效果比FDiffNet效果要差,这是因为生成对抗模型训练需要达到纳什均衡,并且对于超参数较为敏感,需要调整模型是适用的超参数设定.相反,对于同是生成模型的FDiffNet 训练十分简单,只需去拟合反向扩散过程中的条件分布,而且模型不易陷入过拟合.SRCNN模型在 α=4 中等分辨率和 α=8 低等分辨率流场重建精度SSIM相差0.023~0.037,而FDiffNet_res 重建精度SSIM仅相差0.002~0.014,这表示提出的模型在不同分辨率的流场重建上,具有更好的精度保持性.FDiffNet 预测高分辨率流场的残差重建效果要优于直接预测原始高分辨率流场,并且在训练时预测残差能让模型更快收敛.
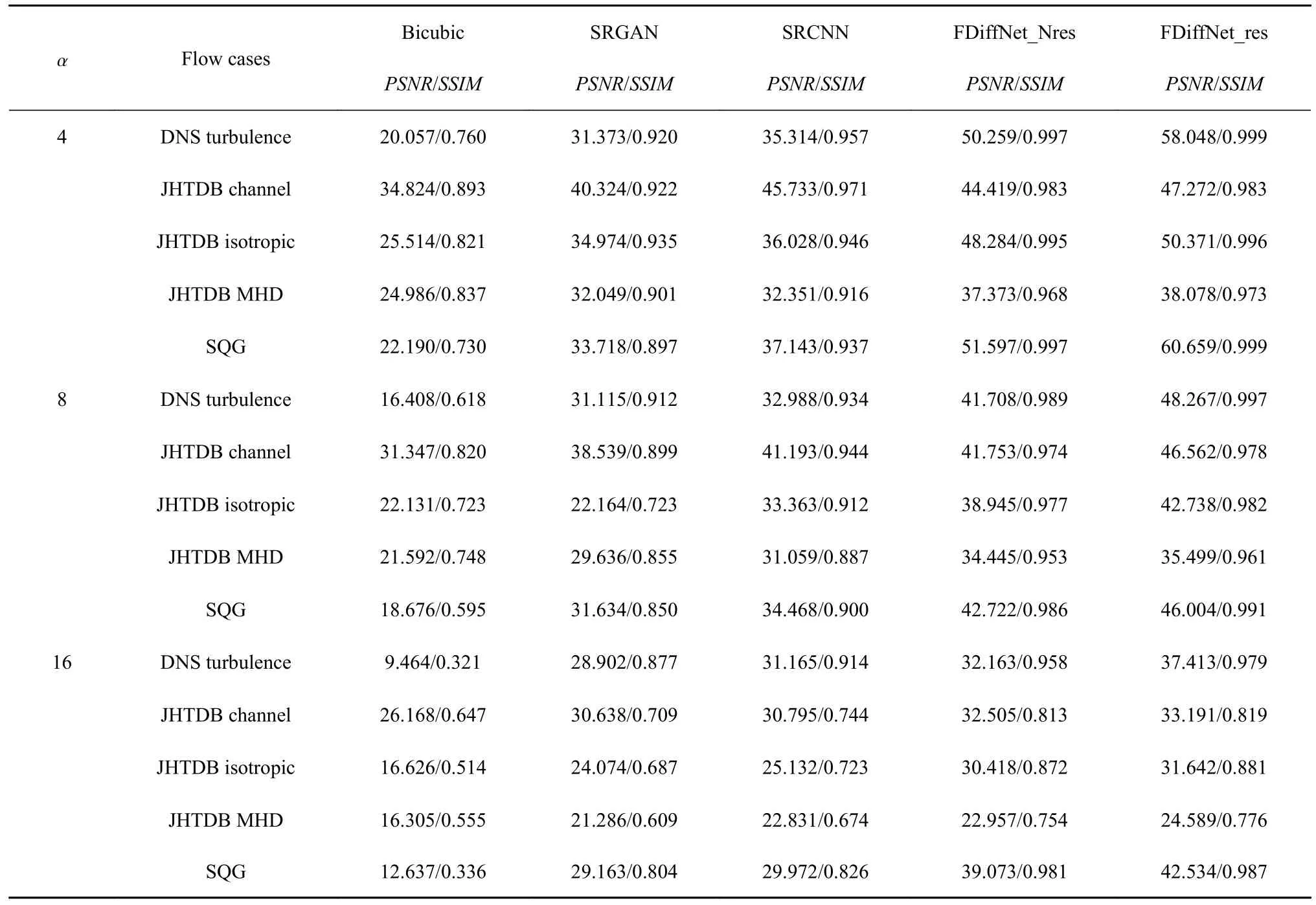
表2 在下采样因子为4,8,16 下不同方法的性能表现Table 2 Performance of different methods with downsampling factors of 4,8,16
FDiffNet 模型主体结构是UNet 模型,输入与输出大小是一致的,因此只需简单改动输入LR 流场上采样倍数,无需修改其他任何参数即可进行迁移学习,这将为训练节省大量时间.为了证明FDiffNet模型在迁移学习方面的优越性,在DNS 流场重建上,对比了FDiffNet_res 直接在 α=4 下训练65000 步与FDiffNet_res 在 α=8 下训练45000 步之后迁移α=4 下训练65000 步的客观评价指标,如图7 所示.经过迁移学习FDiffNet 模型在训练的稳定性提高,相比随机初始化的FDiffNet 模型训练方式,其重建精度PSNR 与SSIM 值提升更快,可以大幅节省模型的训练时间与成本.FDiffNet 模型在训练α=8低等分辨率的流场重建过程中已经学习到该种流场分布规律,因此在迁移到α=4 中等分辨率流场时可以更快适应由下采样因子变化引起学习分布的差异.

图7 FDiffNet 在迁移学习和非迁移学习上性能表现Fig.7 FDiffNet performs on transfer learning and non-transfer learning
3.3 速度场重建精度评价
为直观展示不同方法流场重建能力,选取传统Bicubic 方法、深度学习SRCNN 方法、FDiffNet_Nres 方法以及FDiffNet_res 方法进行对比,在低等分辨率 α=8 下速度场的重建可视化结构如图8 所示,其中颜色条表示速度u的大小.对于每个流动情况,PSNR和SSIM值都在重建的流场下面给出.通过双三次插值方法重建的流场相对平滑,相比之下深度学习方法会展现更多流场细节.其中FDiffNet方法性能表现最优,相较SRCNN 方法可以优化流场中更加精细化的结构,例如在JHTDB channel 流场数据红框内的涡流应是纺锤型,而SRCNN 直接重建成一个点,相比之下FDiffNet 则完整重建了涡结构.这是由于所用LR 编码器充分提取了低分辨率流场特征,并在重建流场的过程中并不是一步重建,而是通过DPM-solver 采样器从噪声中逐步恢复流场的.用FDiffNet 预测HR 流场残差性能略优于直接预测HR 流场,在重建流场数据方面是与原始HR 流场更具有一致性,在图像上也可直观地看出FDiffNet_res 重建的流场更贴合真实流场.

图8 不同方法在 α=8 下重建速度场的比较Fig.8 Comparison of different methods to reconstruct velocity fields at α=8
3.4 涡量场重建精度评价
由于在训练过程中未直接考虑涡度,因此涡度可作为评估模型学习表现的良好指标.在低等分辨率 α=8 下涡量场的重建可视化结构如图9 所示,其中颜色条表示涡量的大小,DNS 湍流和SQG 包含更多的涡结构,可以显著揭示重建流场的细节.类似于速度场的重建结果,使用FDiffNet 预测HR 流场残差,其重建效果最优.相比之下,双三次方法重建的涡量场十分模糊,缺乏流场信息,而SRCNN 方法重建的涡量场很粗糙,并且无法正确估计涡边缘结构.然而,FDiffNet 则可以有效重建涡量场的细节部分,并且和真实涡量场一样平滑,这证明了FlowDiffusionNet模型的实用性.

图9 不同方法在 α=8 下重建涡量场的比较Fig.9 Comparison of different methods to reconstruct vortex fields at α=8
3.5 计算效率对比
根据运行时间和模型大小评估了模型的计算效率,如表3 所示.为了公平比较,每种方法都在同一台机器上配备了相同的 Intel Core i7-12700 CPU 和NVIDIA RTX 3060 GPU.另外,我们以超低等分辨率α=16 的DNS 湍流流场为例.注意运行时间是100 个测试流场的累计时间.

表3 不同方法的计算效率对比Table 3 Comparison of computational efficiency of different methods
如表3 所示,可以看出FlowDiffusionNet 模型在计算效率上存在一定劣势,与基线的生成模型SRGAN 相比,推理过程更加耗时,这是因为GAN的采样只需要一次神经网络前馈过程,而扩散模型则需要多步神经网络前馈.即使本文已经使用了最先进的采样方法将原始的上百步前馈缩小至10 步以内,但在推理100 测试流场所用总时间仍达到了58 s.
4 结论
本文提出了一种基于扩散模型的方法,用于不同流场数据集的超分辨率重建.该模型优化了原始的DDPM 网络结构,增加了自注意力层,并应用LR 编码器高效提取LR 流场信息.为了提高模型重构HR 流场速度,选用了DPM-solver 采样器进行推理.本研究得到以下结论.
(1)针对输入的不同低分辨率流场数据,与传统插值方法、基于深度学习的SRGAN 和SRCNN 方法相比,所提出的FlowDiffusionNet 模型可以高精度地重建流场数据.在各种经典流场重建中,应用提出的模型FlowDiffusionNet 预测HR 流场残差的性能表现比直接预测HR 流场更加优异.
(2)FlowDiffusionNet 模型具有良好的泛化能力,适用于多种复杂湍流流场的超分辨率重建工作.在实验中,FlowDiffusionNet 模型表现十分稳定,在 α=4和 α=8 不同分辨率流场重建任务上,客观评价指标SSIM波动值小于0.014.
(3)FlowDiffusionNet 模型可以高精度地重建涡结构,对于DNS 和SQG 流场,即使在 α=16 超低分辨率下,其客观评价指标也可以达到0.98 以上.FlowDiffusionNet 模型还具有较好的迁移性,在训练阶段可以节省大量时间.
(4)与文中其他方法相比,FlowDiffusionNet 模型在速度场和涡量场可视化中展示了更多流场重建细节.尤其对于在训练中未直接考虑的涡量场,FlowDiffusionNet 模型仍然具有较好的重建效果,而其他方法的重建性能则大幅降低.
该工作证明了扩散模型在流场超分辨率重建任务中的巨大潜力.未来将研究模型轻量化,从而实现低成本和高精度的重建.
