一种加权最大化激活的无数据通用对抗攻击
2023-11-15刘依然
杨 武,刘依然,冯 欣,明 镝
(重庆理工大学 计算机科学与工程学院,重庆 400054)
0 引言
早期研究表明,在正常样本中人为添加微小扰动形成的对抗样本可以严重干扰卷积神经网络(convolutional neural network,CNN)在执行图像分类任务时的准确率[1]。与正常样本相比,对抗样本不但难以区分,隐蔽性强,而且能够影响不同结构的模型,即具有迁移性。由于对抗样本的特性,一方面它被用于检测并评估模型的缺陷,另一方面它被视为CNN模型在实际应用过程中的严重威胁。
为探索对抗样本对模型产生的影响,研究者们提出了许多制作对抗扰动的对抗攻击方法[2-5]。然而许多迁移性良好的对抗攻击方法[6-8]通常会专门为每个正常样本制作其相应的对抗扰动,这种制作对抗样本的方式被称为基于样本的对抗攻击方法,如快速梯度符号法(fast gradient sign method,FGSM)[9]和其改良方法 SegPGD[10]、VMI-FGSM[11]等,它们利用输入的对抗样本直接干扰模型的梯度,进一步影响损失函数,导致模型预测准确度下降。这类方法也被称为基于梯度的攻击,最初是在白盒设置下提出,设想攻击者知晓目标模型的所有信息(如模型结构、参数等),攻击难度低,适合用来检测模型缺陷。在攻击者对目标模型一无所知的黑盒攻击设置下实用性稍差。一些改良方法[11-14]将基于梯度的攻击移植到了黑盒设置下,也针对超参数进行了探索[15],但仍需要较高的时间成本进行迭代训练。黑盒设置下通常使用输入样本到目标模型进行查询[16-18]的方式或者空间几何理论[19-20]探索决策边界,为提高样本的多样性,生成式模型[21]也被用于对抗攻击中。
随着对抗样本研究的深入,提出了另一种新型的对抗攻击方法——通用对抗攻击[22]。通用对抗攻击会根据对样本和模型的先验知识制作通用对抗扰动(universal adversarial perturbation,UAP)。将通用对抗扰动添加到不同的正常样本上可以在短时间内产生大量的对抗样本。通用攻击利用代理模型和大量样本作为先验知识制作UAP,比如最早的UAP方法将样本扰动看作矢量,聚合了许多样本扰动的方向形成UAP[22]。后续的F-UAP[23]、Cosine-UAP[24]等使用代替的数据集进行了改良,对于UAP在实验中的某些现象给出了相应的解释,这些使用真实数据集训练UAP的方法也叫基于数据先验的通用攻击。UAP的提出极大地提高了对抗样本的制作效率,满足了对模型算法检测的对抗样本的数量需求,也更加符合黑盒攻击设置和模型真实应用场景下[25]对抗样本攻击模型的情况。
但是,上述基于样本的攻击方法和基于数据先验的通用对抗攻击需要大量标注好的训练数据。在实际的攻击场景中,尤其是对安全要求较高的应用场景中,攻击者尝试获取大规模的模型训练数据十分困难,在短时间内寻找标注标签的代替数据集也不切实际。为了克服通用对抗攻击方法对数据的过度依赖,近几年提出了无数据通用对抗攻击方法[26-29]。与先前基于真实数据的通用攻击不同,无数据通用攻击考虑在黑盒设置下初始化随机扰动,最大化卷积神经网络中的卷积层激活值得到UAP制作对抗样本。有研究认为最大化卷积层的激活值(比如通过ReLU函数后的输出)能够强化训练的UAP本身携带的特征,从而使其制作的对抗样本能过度激活干扰模型提取特征,达到良好的攻击效果,因此也将无数据通用攻击称为一种基于特征的攻击方法。但是,现有的无数据通用攻击仅仅只是最大化所有卷积层的激活值,没有考虑不同的卷积层提取特征的差异性。而关于不同卷积层对UAP的影响,模型的浅层卷积层,也就是靠近输入端的卷积层提取的局部图像特征更加具有泛化性。而深层卷积层,即靠近输出端的卷积层中则会形成与图像样本相关的全局特征,并且缺乏真实数据作为先验知识,这些都导致了无数据通用攻击方法迁移性差,在目标模型上的攻击效果较差。
为了加强无数据通用攻击的迁移性,本文中提出了一种新的无数据通用攻击方法,加权最大化激活(weighted activation maximization,WAM)来制作UAP。WAM方法采用代理模型(黑盒设置下由于攻击者缺乏对目标模型的了解而寻找的代替品)制作UAP,为模型中所有卷积层激活值都赋予相应的超参数作为其对应的权重,控制UAP在训练过程中利用不同卷积层形成更多具有泛化性的局部特征。本文增加了浅层卷积层在训练中的权重以提高对抗样本的迁移性。另外,为了增加输入的多样性,WAM方法采用高斯噪声制作了随机噪声图像作为模拟样本与UAP一起输入至模型中,达到过度激活卷积层,劣化提取特征的目的。本文在ImageNet验证集进行了大量的消融实验,结果表明,相比于深层卷积层,利用浅层卷积层的激活值得到的UAP具有更好的迁移性,印证了此前研究中浅层卷积层抓取特征更加泛化的观点。与其他经典无数据通用攻击进行比较,实验结果说明了WAM方法制作的UAP具有良好的攻击效果。
1 加权最大化激活(WAM)攻击方法
本文中设计了加权最大化激活方法来制作UAP以解决无数据通用攻击迁移性差的问题。该章节先介绍了总体的攻击方法示例,然后定义加权最大化激活的优化目标,介绍基于高斯噪声伪造样本的攻击增强,最后展示整个算法流程和细节。
1.1 问题背景与定义
为了攻击目标模型,通用攻击会通过攻击算法生成一个通用对抗扰动[22]向量v,将向量v与正常样本x结合生成对抗样本,最大化模型损失函数L(如交叉熵损失)在数据分布下的期望D:
(1)
式中:S为UAP向量v的扰动空间;y为样本x的真实标签,(x,y)来自D;f为分类器;δ为常数,作为向量v的p范数约束(p=0,1,2,∞),以满足对抗样本x+v的隐蔽性需求。考虑最常用的对抗攻击问题设置,选取无穷范数l∞作为UAP的约束条件。
由于缺少真实样本数据,无数据通用攻击仅仅将扰动向量v输入模型中,通过最大化卷积层激活值训练得到扰动:
(2)
式中:li(v)=ReLU(Convi(v))为将向量v输入模型后第i层卷积层产生的激活值;L为卷积层总层数。
1.2 加权最大化激活方法
1.2.1加权最大化激活目标
现有的无数据通用攻击[26-27,29]主要以式(2)为优化目标,没有考虑到不同卷积层提取的特征有较大差异。浅层卷积层提取的特征更具有泛化性,容易被不同的模型学习利用。近两年有关UAP的研究[23-24]表明,模型更容易将UAP本身视为样本特征,而图像样本真正的特征被模型当成噪声所忽视。
受上述观点启发,为提高无数据通用攻击的迁移性,本文中提出了加权最大化激活来制作对抗扰动:
(3)
式中:wi为第i层卷积层的权重超参数,值域为[0,1]。式(3)采用了与现有无数据通用攻击类似的做法,即为了避免卷积层激活值过大,对每层激活值进行对数化处理。WAM的优化目标为每个卷积层都赋予了对应的权重。WAM方法尝试利用泛化特征提高UAP的迁移性,使其在目标模型上具有更好的攻击效果。
1.2.2利用高斯噪声初始化的攻击增强
无数据通用攻击在黑盒设置下采用随机初始化扰动训练UAP。仅凭借UAP所携带的信息去激活模型,产生对应的特征激活值。它减少了对样本数据的依赖,更接近实际应用下的攻击场景。但缺少真实数据也导致其制作的对抗样本迁移性差,攻击效果欠佳。为提高输入多样性,增强攻击效果,采用了由高斯噪声生成的噪声图像代替真实图像与UAP一起输入到模型中,因此,更新式(3)为:
(4)
式中:p=v+xg,xg为高斯噪声生成的噪声图像,模仿基于数据先验的通用攻击,增加输入多样性,激活更多特征值,提高攻击强度。为方便UAP训练过程中的优化,将式(4)的目标函数取负并求最小值,视为训练的损失函数。
1.3 算法流程
在UAP训练过程中遵循黑盒攻击设置,因此采用一个代理模型作为目标模型的代替品,将UAP输入代理模型进行训练。WAM方法虽然为无数据通用攻击,但是为了验证UAP的训练是否收敛,仍使用了代理数据集χsub进行验证,当迭代次数达到最大迭代次数或者代理数据集验证达到收敛要求时结束训练。为了保证UAP满足隐蔽性约束条件无穷范数的限制,本文效仿了现有的对抗攻击的做法,每次更新UAP向量v之后就对其进行裁剪,保证收敛时UAP的取值在该优化问题的可行域内。为进一步优化UAP的训练过程,引入了饱和度设置来衡量UAP向量中元素值达到约束常数δ的比例,每H迭代就会计算饱和度,当UAP内元素值小于约束常数的元素个数越来越少并低于饱和度阈值r时,会将当前UAP向量中的元素数值压缩到原来的一半,使UAP不会因为裁剪导致后续训练信息丢失。WAM算法流程如下。
Algorithm:WAM-UAP
Input:surrogate CNN modelf,a datasetχsub,for training UAP,the limitation valueδ,maximum iterationsT,convergence thresholdFmax,saturation thresholdr,validation test hyperparameterH.
Output:Image-agnostic adversarial perturbationv
Randomly initializev0~u(-δ,δ).
1:Do
2:t=t+1
3: Compute Loss by target in (4)
4: Updatevt=vt-1-η*▽Loss
5: Clipvt=min[δ,max(vt,-δ)]
7: Fooling rate testfrift%H==0 andF=F+1 iffrnot the best fooling rate
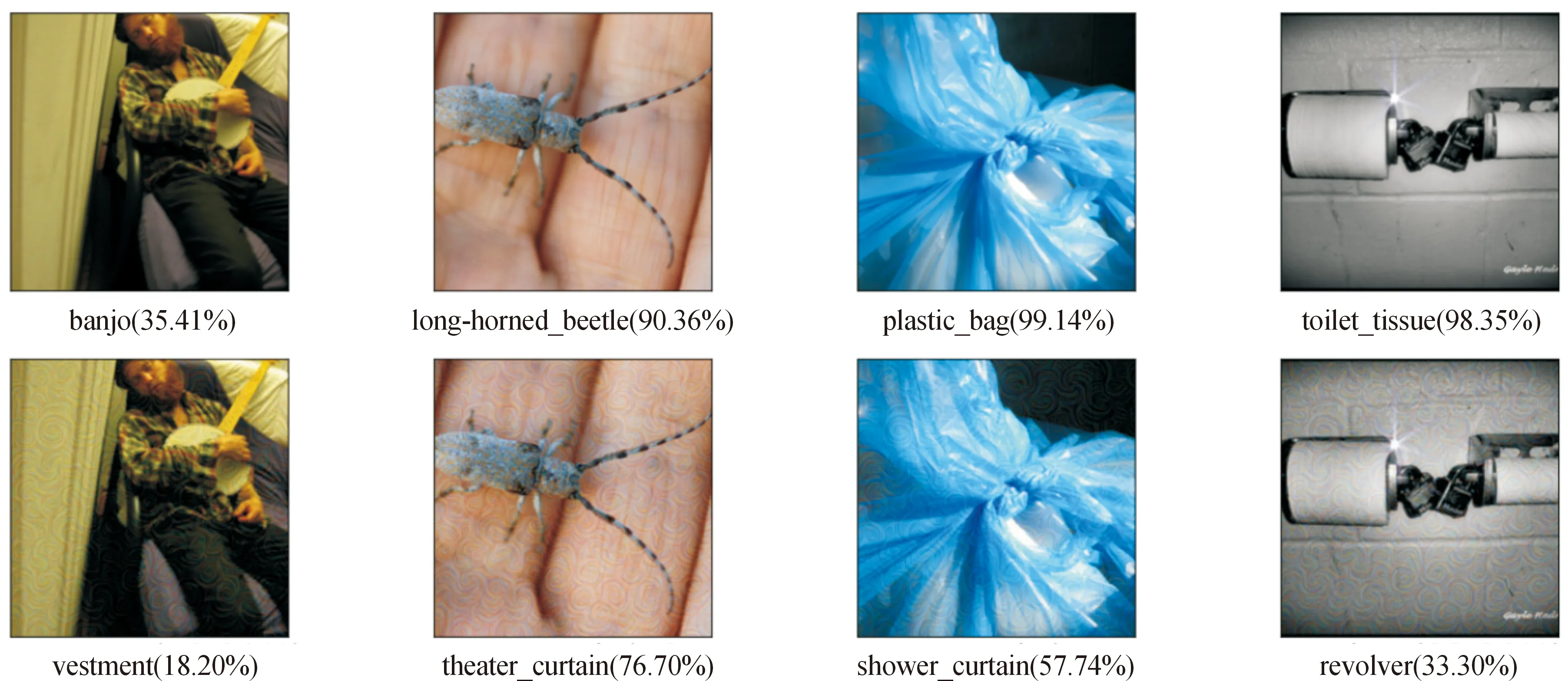
8:Whilet 9:Returnvt 图1展示了WAM方法在一个有L层卷积层的模型中的训练流程。每轮迭代都会输入UAP向量与模拟样本进入模型中,提取每层卷积层的输出值进入WAM模块,通过ReLU激活函数与每层的权重wi点乘并在最后求和形成WAM损失函数,即式(4)的目标函数。 图1 WAM方法训练流程 本文通过Python3实现了WAM攻击算法,实验硬件环境为单核NVIDIA GeForce RTX3090Ti GPU,运行平台为Pycharm,以Pytorch作为主要深度学习框架。 2.1.1数据集与模型 为了和现有的无数据通用攻击方法实验设置保持一致,本文在ImageNet 2012验证集[30]上进行WAM攻击实验。选用了AlexNet[31]、VGG16[32]、VGG19[32]、ResNet152[33]、GoogleNet[34]5个经典CNN模型进行实验,模型参数均为Pytorch官网下载的预训练模型参数。 2.1.2评估指标与比较方法 根据最常用的对抗攻击设置,实验选取欺骗率(fooling rate,FR)作为评估指标: FR=Nchange/N 式中:Nchange表示模型对原始样本和其对抗样本给出不同标签的样本个数;N表示样本总数。欺骗率FR越高,表示对抗样本在模型上的攻击效果越好。 将WAM方法与近几年经典的无数据通用攻击进行比较,包括FFF[26]、GD-UAP[27]、PD-UA[29]方法。这些方法中只有GD-UAP使用作者提供的模型在Tensorsflow框架下进行训练。为了公平比较,本文根据WAM的实验设置复现GD-UAP在Pytorch框架下的实验结果。 2.1.3执行细节 与比较方法的设置保持一致,实验取约束常数δ=10/255。设置最大迭代次数T为10 000,饱和度阈值为0.001%。为简化设置,实验中第i层卷积层的权重wi的取值为0和1。具体每层的权重设置为2.2.3节消融实验的最优设置。 2.2.1对比实验 在ImageNet 2012验证集上测试了WAM方法的攻击效果,并且与其他方法进行了比较。具体结果如图2所示,重复训练5次计算FR均值,取每个测试模型中攻击效果最好的FR进行展示,GD表示GD-UAP方法,由于实验条件限制(如代码未公开等),未能实现极少数方法在个别模型上的攻击效果。从图2中可以看出,WAM方法制作的UAP在所有模型上都达到了最高的FR值,取得了良好的攻击效果。在深度学习模型如ResNet152的效果提升比较明显。在结构比较简单的小模型上提升幅度较小,这可能是由于许多对抗攻击在结构简单的小模型上具有较高的FR,UAP的性能提升接近瓶颈。 图3展示了WAM方法制作的UAP的攻击效果,5个子图的标题代表制作UAP的代理模型,也就是制作UAP的模型,每个子图的横轴坐标代表测试模型,即目标模型。从图3中可以看出,除了少数因为模型结构差异巨大而导致的FR值较低的情况,大多数由代理模型制作的UAP在攻击其他模型时表现出良好的迁移性,在2个结构相似的模型中尤为明显,比如VGG16和VGG19。并且可以发现,在对ResNet152模型的测试中,VGG16制作的UAP达到了最高的FR值,而不是ResNet152模型本身制作的UAP取得最优效果,说明了WAM方法良好的攻击效果和迁移性。 图3 WAM攻击方法迁移性分析 2.2.2UAP可视化 实验中将不同代理模型制作的UAP进行了可视化分析,如图4所示,5个子图分别是由不同的代理模型制作的UAP的可视化展示。为了便于分析,将每个扰动的值放大到[0,255]。从图4中可以看出,训练的UAP具有丰富的语义特征。可视化分析还在ImageNet 2012验证集中随机选取模型分类正确的正常样本,用WAM方法制作攻击实例进行分析。产生的对抗样本的攻击实例如图5所示,图中第1行是原始样本、模型的预测标签和其对应的概率,第2行是与之对应的对抗样本和相关信息。从图5中看出,人眼难以辨别正常样本和WAM方法制作的对抗样本,具有良好的隐蔽性。模型对正常样本的正确分类具有较高概率,在部分对抗样本中被扰动干扰给出了高概率的错误分类,也说明了WAM攻击方法的有效性。 图4 WAM-UAP可视化结果 图5 利用WAM方法制作的对抗样本攻击实例 2.2.3消融实验与分析 根据现有研究[23-24]对UAP的观点,CNN模型中浅层的卷积层抓取局部的、泛化的特征,深层卷积层形成跟整个样本全局相关的特殊图案,因此浅层卷积层抓取的特征更容易被对抗攻击利用,制作的UAP也更具迁移性。为了进一步验证这个观点,调整每层卷积层权重设计了消融实验。具体方案就是将模型所有卷积层的权重先初始化为0,每次增加卷积层的增长步长为该模型总卷积层的10%(向上取整),从接近输入端的卷积层开始,取10%、20%…100%的卷积层将其权重置1,分别训练UAP并在白盒设置下进行测试,观察UAP的攻击效果,实验结果如图6所示。由于Alex-Net只有5层卷积层,因此,使用10%、30%…90%的卷积层训练的UAP结果不存在。从图6中可以看出,所有模型取得最高FR的值为保留部分浅层卷积层的结果,在ResNet152深度学习模型上甚至仅使用了约前10%的卷积层就能达到最优攻击效果,而随着使用卷积层的增多,UAP的攻击效果逐步变弱,这也符合现有观点对深层卷积层的解释,由于深层卷积层主要关注有关样本的全局特征,一定程度上导致了UAP的“过拟合”,过度适应代理模型使得它制作的对抗样本在目标模型上的效果不佳。 图6 采用模型不同占比卷积层训练UAP的消融实验结果曲线 针对现有的无数据通用攻击迁移性差的缺陷,提出了加权最大化激活(WAM)攻击方法,为每一层卷积层设置相应的权重,从而控制训练过程中不同卷积层提取的特征对UAP产生的影响。通过权值调整,使卷积层提取的泛化特征的激活值更容易被UAP学习。使用ImageNet验证集与近几年的无数据通用攻击方法进行比较,WAM攻击方法取得了良好的攻击效果。消融实验验证了浅层卷积层提取的特征具有泛化性的观点,利用这些泛化特征学习的UAP具有更好的迁移性。在未来的工作中,浅层卷积层的特征与UAP的关系有待进一步研究。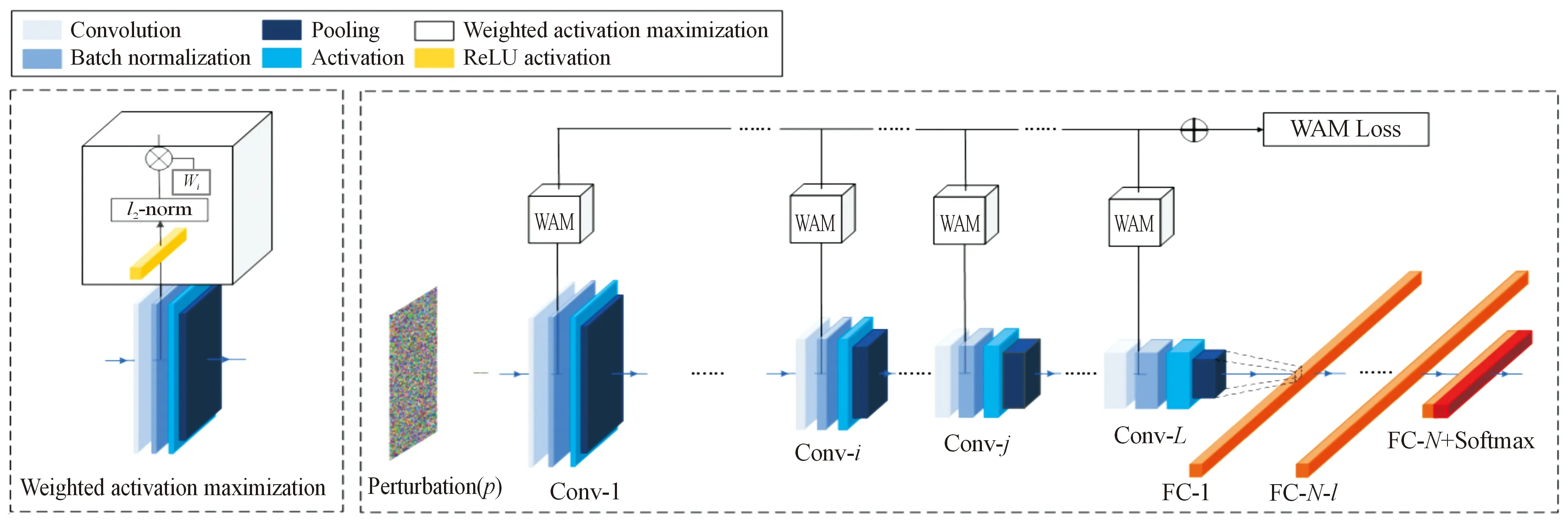
2 实验结果及分析
2.1 实验设置
2.2 实验结果分析



3 结论
