融合图卷积网络的花样滑冰动作识别方法
2023-11-15温雪岩谷训开赵玉茗
温雪岩,李 祯,谷训开,赵玉茗
(东北林业大学 计算机与控制工程学院,哈尔滨 150040)
0 引言
人体运动分析的动作识别作为计算机视觉中新兴的研究方向,引领运动分析向智能化方向发展。由于花样滑冰的动作类型多样,同一类型的动作之间又存在细微的差异,现有的动作识别方法对其研究尚未达到令人满意的效果,因此面向花样滑冰动作识别的研究仍有待深入。同时,将基于骨架的动作识别[1-2]应用于人体运动分析已成为科研人员重点关注的研究领域[3]。
在动作识别任务中,早期模型存在噪声干扰和忽略空间信息的问题。卷积神经网络(convolutional neural network,CNN) 的基本方法是将骨架数据转化为RGB图像[4-5],它能够有效地提取视频或者图像的特征,但是容易受到背景噪声的干扰[6];循环神经网络(recurrent neural network,RNN)[7]和由其衍生而来的长短时记忆模型(long short-term memory,LSTM)[8]、门控单元模型(gate recurrent unit,GRU)[9]对骨架信息的坐标采用矢量化[10-11]的处理方式,它们均能充分地获取时序特征,但是忽略了对空间信息的关注。后来,学者们受图论的启发[12]开始对图卷积网络(graph convolutional networks,GCN)进行研究[13-14]。
近年来,图卷积网络取得了许多成功的应用[15-16],在人体动作识别的准确率上也获得了较好的提升。2018年,Yan等[17]提出时空图卷积网络(spatial temporal graph convolutional networks,ST-GCN),通过学习动作的时空特征克服了之前模型的不足。Shi等[18]在ST-GCN的基础上结合骨骼的二阶信息,完善了动作的时空特征。之后提出的方法[19-20]虽然可以自适应地学习人体骨骼的拓扑结构,但是均存在特征提取不灵活、时序特征提取不全面的问题。Cheng等[21]利用参数化拓扑独立地学习每个通道的特征,但是造成了特征的冗余和模型体积的增大。Chen等[22]采用动态建模方法,提高了动作识别的精度。为了更好地解决模型在花样滑冰动作识别任务中存在的特征语义挖掘不充分、空间重要特征关注不足、时序特征提取不全面的问题,提出了共享多分支特征和注意力的多尺度时空图卷积网络的花样滑冰动作识别方法。
1 研究方法
1.1 网络结构
模型网络结构如图1所示,主要分为2个阶段。第一阶段,利用人体姿态估计算法OpenPose[23]提取动作样本的骨架序列后输入网络进行特征提取,消除背景噪声干扰。网络模型分别提取骨架序列的四分支特征,即关节静态流J flow、骨骼静态流B flow、关节动态移动流Dynamic J flow、骨骼动态移动流Dynamic B flow,继而融合为Multi-branch flow的共享特征块。第二阶段,由融合注意力的多尺度时空图卷积网络对Multi-branch flow捕捉人体运动的深层时序特征和关键空间信息。该网络由注意力时空图卷积模块堆叠10层(L1~L10)构成,每层Li(i:1~10)的3个参数分别表示输入通道数、输出通道数、步长。Multi-branch flow通过BN层处理为Rbs×C1×T×N(bs为batchsize大小,C1为关节点x、y、z分量,T为数据的帧数,N为每帧的关节点数量)。每块的输入通道数:L1~L4为bs×64×T×N; L5~L7为bs×128×T/2×N; L8~L10为bs×256×T/4×N。每块的输出通道数:L1~L4为64;L5~L7为128;L8~L10为256。最后,利用Softmax判别出较为精准的动作。研究采用了共享特征块提取模块,使网络可以挖掘更深层次的语义特征。在注意力时空图卷积模块内部,设计了改进的注意力机制,来强化关键信息的关注;同时,构建了多尺度时空图卷积网络,从而更完整地捕捉多尺度时序特征以识别出较为精准的动作。

图1 网络结构图
1.2 共享特征提取模块
1.2.1获取人体运动骨架序列
采用人体姿态估计算法OpenPose[23]进行人体关键点检测,根据优化算法进行关键点的匹配、聚合、拼接多分支特征的骨架结构。由于单分支特征在发掘动作语义表达上有所欠缺,为了对动作描述更加完善,采用多分支特征融合的共享特征建模动作的骨架序列。多分支特征分别为:关节静态流、骨骼静态流、关节动态移动流、骨骼动态移动流。关节静态流、骨骼静态流分别记录关节和骨骼在同一帧内部的坐标信息,关节动态移动流、骨骼动态移动流分别记录相邻时间帧关节和骨骼的动态坐标信息。
假设单一关节点J′的定义为:
J′=(X′、Y′、Z′)
(1)
式中:X′、Y′、Z′分别为关节点J′对应位置的x、y、z坐标值;(X′,Y′,Z′)为J′的关节点坐标。
关节静态流(joint flow,J flow):默认由人体姿态估计算法OpenPose[23]获取的25个关节点坐标得到:
(2)
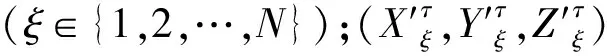

(3)
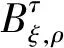
(4)
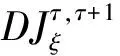
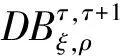
(5)
1.2.2共享特征块
将提取的多分支特征融合为共享特征块,挖掘多分支特征在语义表达上的相关性和互补性特征,通过共享特征块对动作描述更加精确,预测较为精准的动作类型。
共享特征流(Multi-branch flow):通过四分支特征的融合,提取共享特征块:
M flow = J flow⊕B flow⊕
Dynamic J flow ⊕ Dynamic B flow
(6)
式中:J flow、B flow、Dynamic J flow、Dynamic B flow分别为对应的四分支特征;M flow为共享特征流; ⊕为concat操作。
由图2可见,分别提取动作样本骨架序列的多分支特征,再融合为Multi-branch flow输入到网络中,网络可以获取更为丰富的特征语义表示,提取更深层次的特征,从而对动作的表征更加完善,预测结果较为精准。

图2 多分支网络结构
1.3 注意力时空图卷积模块
注意力时空图卷积模块由改进的注意力机制和多尺度时空图卷积网络构成。其中Dropout层缓解了空间图卷积的过拟合现象,模块中的残差连接避免了网络层数过深、模型梯度消失现象的发生,提高模型的稳定性。
1.3.1注意力机制
注意力机制可以将特征和特征之间的关联按照重要性排序,通过这种机制,对动作识别内部的差异性和关键性的特征会占据更大比重。考虑到需要在空间维度上进行关注并提取具有明显差别的特征,引入注意力机制强化关键帧内部空间特征的聚焦与提取。研究在卷积注意力模块[24](convolutional block attention module,CBAM)的基础上进行改进,改进后的注意力机制在通道和空间维度对不同动作的特征显著区分。模块能够抑制冗余特征,实现强化空间特征的表达效果,其结构如图3所示。
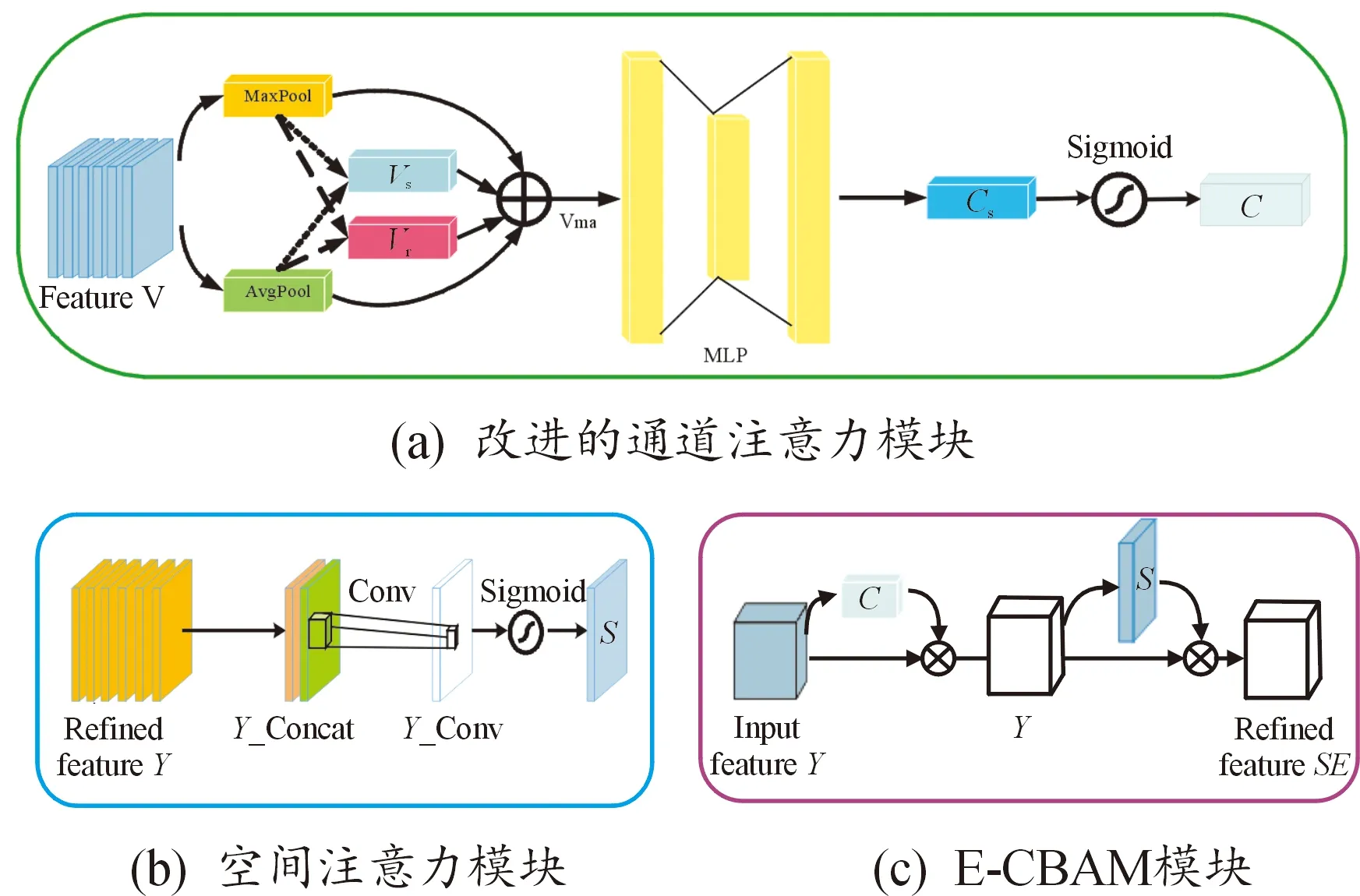
图3 注意力机制模块结构
改进的通道注意力模块(improved channel attention module,Im-CAM):采用改进的通道注意力模块关注空间结构中依次具有意义的特征。由于原CBAM的CAM模块的池化操作会损失重要特征,因此在关键特征识别方面并不具备优势。为了让模型更好地共享数据特征,提高识别性能,改进了通道注意力结构,如图3(a)所示。将输入特征V∈RC1×T×N×M(默认M=1为动作的参与人数)进行以下操作:① 最大池化;② 平均池化;③ 两池化特征作差并取绝对值;④ 两池化特征相乘。综合4种特征最大化地共享数据,有效地解决了原CAM存在的特征损失问题,增强了模型存储重要性特征的能力:
Vs=|MaxPool(V)-AvgPool(V)|
(7)
Vr=MaxPool(V)⊗AvgPool(V)
(8)
Vma=MaxPool(V)⊕AvgPool(V)⊕Vs⊕Vr
(9)
C=ϑ(MLP(Vma))
(10)
式中:⊗为逐元素乘法;ϑ为Sigmoid激活函数;Vs为对V的最大池化和平均池化特征作差取绝对值的特征向量;Vr为两者乘积的特征;Vma为对V的最大池化和平均池化特征、Vs、Vr做维度拼接后的特征向量;MLP为多层感知器。
空间注意力模块(spatial attention module,SAM):网络通过S∈RT×N记录节点位置的重要性程度。
S=ϑ(Conv2D(MaxPool(Y)⊕AvgPool(Y)))
(11)
E-CBAM模块(enhanced CBAM module,E-CBAM):E-CBAM的嵌入,使模块显著地强化了V中关键特征的关注,避免了差异性特征的损失,提升了动作识别的效果。
1.3.2多尺度时空图卷积网络
为了提高模型的时序建模能力,减轻计算量,选择文献[22]基于通道的非共享拓扑结构进行骨架序列的空间特征提取,如图4(a)所示;同时构建多尺度时序卷积网络(multi-scale temporal convolutional network,MTCN),有效地提取骨架序列的时间特征,如图4(b)所示。

图4 多尺度时空图卷积网络
由于动作特征的独特性和特征之间的个体差异性,ST-GCN的特征提取采用共享拓扑,限制了提取的灵活性。为此,在空间维度上,采用了基于通道建模的非共享拓扑结构,使网络可以对不同通道包含的不同信息进行提取,来增强模型特征提取的灵活性。首先,取ST-GCN的邻接矩阵A作为所有通道的共享拓扑;然后,每个动作由其独特性和内部特征结构之间的相关性生成每个通道独立的拓扑结构,通过逐通道调整共享拓扑得到细化的通道拓扑。
空间特征提取如图4(b)Unit-gcn所示,其结构如图4(a)所示,过程如下:
1) 全连接层H(·)将特征Fx∈RN×C1转换为F∈RN×C1,使其尺寸与式(2)中X相匹配。
F=Η(Fx)=FxW
(12)
式中:W为一个可学习的参数矩阵;Fx为经过注意力机制输出的特征向量。
2) 模型根据输入的动作特征序列建立独立的通道拓扑来捕捉不同类型运动特征下关节之间的相关性。根据关节点之间的关系,建立共享拓扑A∈RN×N;E∈RN×N×C1′是不同关节点在通道上的相关性,通过E不断调整共享拓扑A,最终得到细化的通道拓扑集合X∈RN×N×C1′。Xa∈RN×N(a∈{1,…,C1′})为每个通道独立的邻接矩阵。
(13)
(14)
(15)
X=θ(E,A)=A+α·E
(16)
3) 对每个通道的特征F:,a∈RN×1(a∈{1,…,C1′})和邻接矩阵Xa∈RN×N(a∈{1,…,C1′})沿通道卷积,并通过Φ(·)聚合所有通道的特征生成Z∈RN×C1′。
(17)
式中:F为所有通道的特征;X为学习后的所有通道的拓扑集合;X1为第1层通道的邻接矩阵;F:,1为第1层通道上的特征;X2、F:,2以此类推;Φ(·)聚合所有通道的卷积特征;Z包含了不同动作序列的独特信息。
通过建立非共享邻接矩阵,增强了模型提取动作特征的灵活性,最大程度地保留了特征的独特性信息,减少了关键信息的丢失,从而动作特征获得更充分地提取。
图4(b)中MTCN,设置多尺度Di-Convj取代ST-GCN的普通卷积。随着网络层数的加深,特征损失的问题难以避免,通过多尺度空洞卷积,实现增大感受野、捕捉深层时序特征的目标,进一步提高了模型提取多尺度时序特征Mout的能力。
(18)
Mout=γ(M)
(19)
式中:ζ为Dropout操作;γ为ReLU激活函数;Di-Convj为MTCN第j个多尺度卷积操作,j∈(1,4);M为对通道特征集合Z利用不同尺度卷积融合后的特征向量。
Di-Convj(j:1→4)内部含有不同的膨胀系数1、3、4、5,卷积核大小为(u,1),进行时序特征提取。在维持参数和计算量不变的条件下,通过膨胀系数的设置,MTCN映射的感受野发生改变,因而提取的特征在时间跨度上也更加全面,可以提取到更大范围、更深层次的特征。
模型的算法流程如下:
Ours算法
输入:预处理后数据集wg的四分支特征J flow(wg),B flow(wg),Dynamic J flow (wg),Dynamic B flow (wg);注意力时空图卷积模块的层数k,∀k∈{1,…,K};多尺度时空图卷积模块中Unit-gcn的个数i,∀i∈{1,…,I}; MTCN中多尺度卷积的个数j,∀j∈{1,…,J}
输出:数据集对应的概率最高的标签
1) M flow ← Concat(J flow(wg),B flow(wg),Dynamic J flow (wg),Dynamic B flow (wg))//提取共享特征块
2)V←BatchNorm(M flow) //将提取后的共享特征块批量标准化得到V
3) fork=1→k=Kdo //将V输入融入注意力的多尺度时空图卷积网络
4) FX ← E-CBAM(V) //利用注意力机制提取特征得到Fx
5) fori=1→i=Ido //将Fx输入多个Unit-gcn
6)Zi←Unit_gcni(Fx) //Unit_gcni表示第i个Unit_gcn
7)Z←Concat(Zi)//提取i个Unit_gcn的输出特征得到Z
8) end for
9)Z←Dropout(Relu(BatchNorm(Z)))
10) forj=1→j=Jdo//将Z输入MTCN
11)Mj← Convj(Z)//Convj表示第j个多尺度卷积
12)M←Concat(Mj)//利用MTCN提取j个多尺度卷积特征得到M
13) end for
14)Mout←ReLU(M)//获得时序特征Mout
15) end
16) Label_ MaxProp ← Softmax(Mout)//获取概率最高的标签Label_ MaxProp
17) 输出数据集对应的概率最高的标签
2 实验结果与分析
2.1 实验环境
实验环境基于Ubuntu 20.04操作系统,Nvidia GeForce RTX 2080Ti 显卡,深度学习框架为PyTorch 1.10.0,Python 3.7。采用交叉熵损失函数(cross entropy)进行训练,随机梯度下降(stochastic gradient descent,SGD)作为优化器,批量大小(Batchsize)设置为32,数据集迭代次数(epoch)设置为100,初始学习率(learning rate)设置为0.1。
2.2 数据集
实验采用的FSD-10花样滑冰数据集由北京智源人工智能研究院发布,共包含30种动作类型。数据集以7∶1∶2的比例依次切分为训练集、验证集、测试集。利用OpenPose算法[23]提取每帧包含25个关节点的骨架结构,关节点示例如图5所示,其数字详情见表1。
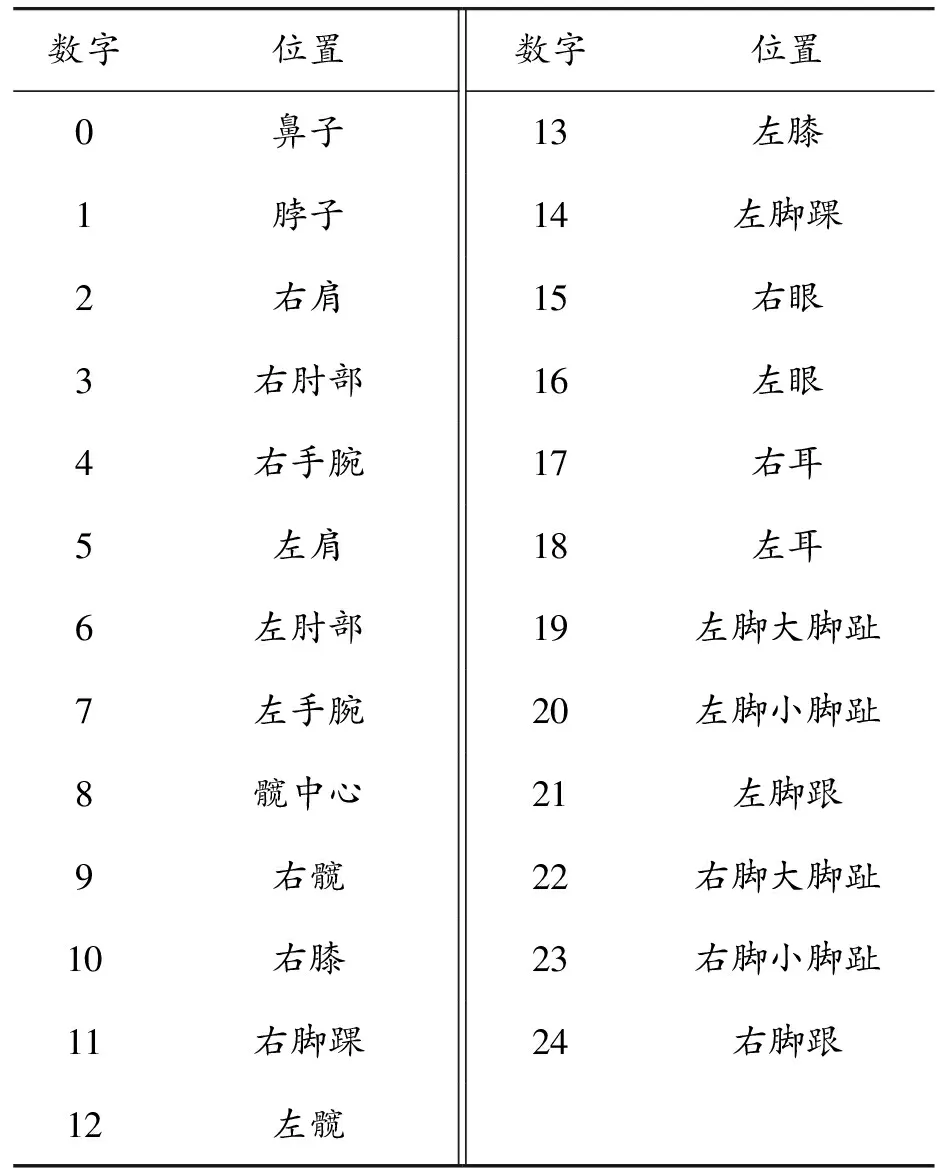
表1 关节点数字对应位置
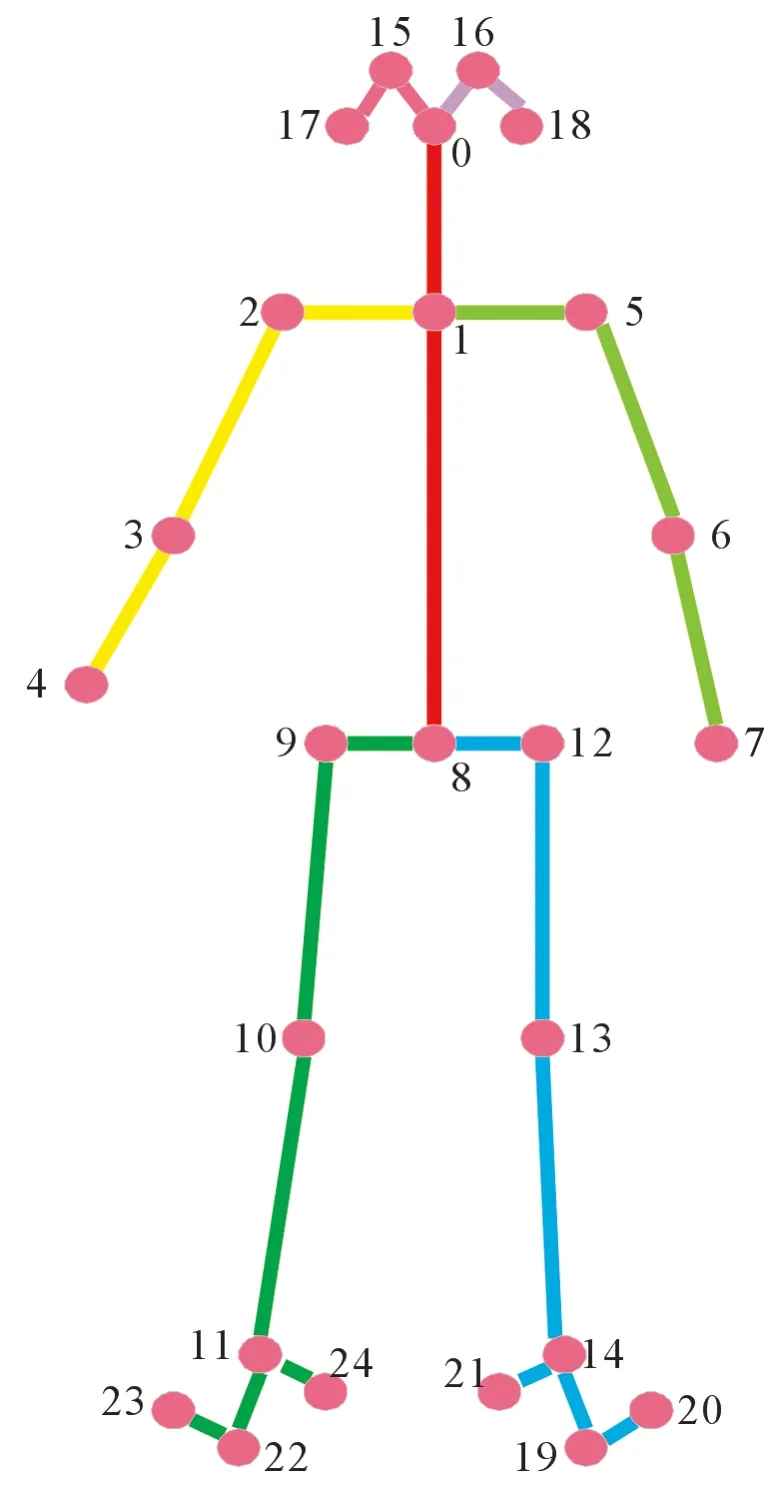
图5 关节点示例图
数据集是W×C1×T×N×M的五维张量。其中,W为样本数量;C1为每个关节点的x、y坐标和置信度;T为动作的持续时间长度,共有1 000帧,对于实际长度不足1 000帧的部分动作,在其后重复补充0~1 000帧,来保证T维度的统一性;N为25个关节点;M为参与人员数量。
2.3 评价指标
使用准确率来评估所提算法的性能。准确率表示模型预测正确的样本数量占测试集样本总数的比例:
(20)
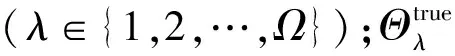
2.4 对比实验
将所提模型与当前的模型进行了对比实验,结果如表2所示。
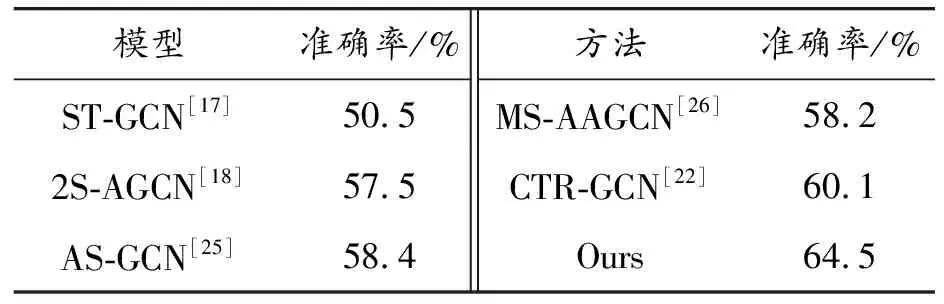
表2 对比实验
由于对花样滑冰动作识别这项任务的研究尚处于起步阶段,因此目前所提出的方法在FSD-10数据集上的准确率相对不高,未来还有进步的空间。在表2的实验结果中,ST-GCN模型的准确率为50.5%,这表示在包含30 种动作类型的测试集中,ST-GCN模型预测正确的样本数占测试样本总数的 50.5%,展现了极低的准确率。而2S-AGCN模型和AS-GCN模型由于完善了动作的时空特征,虽然准确率较低,但是比ST-GCN模型有不错的提升。基于自适应学习的MS-AAGCN模型虽然具有较丰富的语义特征,但是由于捕获的时序特征不全面,导致其准确率甚至低于存在语义特征的AS-GCN模型。CTR-GCN模型的表现均优于ST-GCN模型以及AS-GCN模型。所提模型的准确率可达64.5%,比表现最好的CTR-GCN模型提高了4.4%,更进一步地提升了识别效果。所提模型既通过融合多分支的共享特征得到了更丰富的动作表征,又考虑改进通道注意力结构,克服了现有方法特征语义不充分以及关键特征提取不足的问题。相比ST-GCN模型仅使用普通卷积提取时序特征,所提模型在提取时序信息上通过多尺度空洞卷积的联动配合,缓解了时序特征提取不全面的问题,准确率和ST-GCN模型相比提高了14%,也比其他模型提高4.4%~7%。通过分析数据证明了所提模型的优越性。
2.5 消融实验
为了验证改进的注意力机制、共享特征提取模块以及多尺度卷积模块的有效性,进行了消融实验。
2.5.1注意力机制消融实验结果分析
为验证改进的注意力机制的有效性,进行的消融实验结果如表3所示。由此可知,采用注意力机制的准确率比前4项的模型分别提高了14%、12.2%、1.7%和4.4%。其中,添加CBAM模块的CBAM+CTR-GCN模型和CBAM+ST-GCN模型的准确率又分别优于CTR-GCN模型和ST-GCN模型。删除E-CBAM的准确率为59.6%,比所提模型降低了4.9%,准确率受到较严重的影响。这说明模型是否嵌入注意力机制对于提升模型性能本身就具有不同程度的影响,将改进后的注意力机制作为所提方法的一部分有益于动作识别的研究。通过设计改进后的注意力机制可以有效地关注差异性和关键性特征,减少无关特征的干扰,提高模型提升性能,对准确率的提升具有一定的促进作用。实验结果更进一步地验证了注意力机制的有效性。
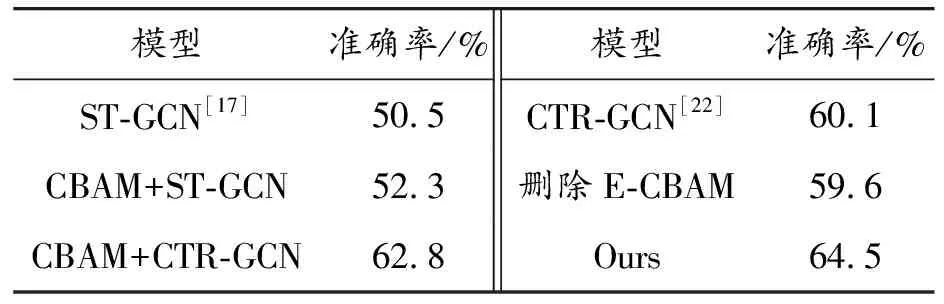
表3 注意力机制消融实验
2.5.2共享特征块消融实验结果分析
如图6所示,模型选择不同的输入分支后识别的准确率也存在差异。前4项的4个单分支中,J flow的准确率最高,达到61.3%,Dynamic B flow的准确率最低,仅为54.3%;采用四分支并行输入,准确率提高到63.2%;当共享特征Multi-branch flow输入时,准确率又能提升1.3%,达到64.5%。实验结果表明,单分支和四分支并行输入难以获得充分的特征,识别效果不显著,导致模型性能提升不明显;而共享特征通过对动作序列挖掘深层语义特征,可以克服语义特征提取不足的困境,较好地提升性能。实验结果验证了共享特征提取模块对模型增强的有效性。

图6 不同分支在FSD-10数据集的准确率
2.5.3卷积核大小消融实验结果分析
如图7所示,在多尺度时空卷积模块内部,不同的卷积核尺寸对性能的影响也不尽相同。卷积核尺寸决定空洞卷积的范围和感受野的大小。卷积核越大,感受野越大,多尺度时空卷积模块提取的时序特征就越多。考虑到细微特征和模型性能两方面因素,对不同的研究对象选择最合适的卷积核大小是多尺度时空卷积模块的关键。由图7可见,随着卷积核尺寸不断变大,准确率曲线呈先上升后剧烈下降的趋势。在卷积核u=9时,该曲线降至最低点,准确率为59.5%;在卷积核u=5时,该曲线达到最高点,准确率为64.5%。卷积核过大,遗漏的细节过多,对动作的表征能力就过弱,识别准确率较低;卷积核过小,捕捉的时序信息就过少,准确率也不高。因此,积核u=5对研究对象准确率的提升起到较优的效果,也从侧面验证了MTCN的有效性。

图7 卷积核大小在FSD-10数据集的准确率
2.6 参数敏感性实验
实验的学习率衰减曲线如图8所示,初始学习率随迭代次数的增加逐渐下降;在第50次以后,学习率趋于收敛,衰减曲线趋向平缓,此时模型的学习效果达到最佳状态。

图8 学习率衰减曲线
3 结论与展望
提出了多分支特征共享和注意力的多尺度时空图卷积网络的花样滑冰动作识别方法,用于解决花样滑冰动作特征提取不足、识别准确率不高的问题。
1) 采用多分支共享特征提取动作特征的多重语义表征;嵌入改进的注意力机制,增强对关键特征的提取;设计多尺度时空图卷积网络获取深层时序特征以提升对不同视频帧数下的动作特征的提取能力,获得更全面的特征,最终能够有效地提高动作识别的准确率。
2) 在30种动作类型的FSD-10数据集上进行了实验,实验结果表明该方法能够更准确地识别花样滑冰动作,与其他图卷积方法的动作识别性能相比,所提方法的性能均优于其他图卷积方法。
3) 在未来的工作中,将进一步提高对不同场景下花样滑冰动作识别的准确率,如考虑改进模型的时空特征提取结构、丰富数据集的数量和动作种类、采集不同拍摄角度下的动作等,以便在实际应用中能够更好地为该运动的爱好者们提供辅助指导,提高实际应用价值。
