Spatial-Spectral Joint Network for Cholangiocarcinoma Microscopic Hyperspectral Image Classification
2023-11-14XiaoqiHuangXueyuZhangMengmengZhangMengLyuWeiLi
Xiaoqi Huang, Xueyu Zhang, Mengmeng Zhang, Meng Lyu, Wei Li
Abstract: Accurate histopathology classification is a crucial factor in the diagnosis and treatment of Cholangiocarcinoma (CCA).Hyperspectral images (HSI) provide rich spectral information than ordinary RGB images, making them more useful for medical diagnosis.The Convolutional Neural Network (CNN) is commonly employed in hyperspectral image classification due to its remarkable capacity for feature extraction and image classification.However, many existing CNN-based HSI classification methods tend to ignore the importance of image spatial context information and the interdependence between spectral channels, leading to unsatisfied classification performance.Thus,to address these issues, this paper proposes a Spatial-Spectral Joint Network (SSJN) model for hyperspectral image classification that utilizes spatial self-attention and spectral feature extraction.The SSJN model is derived from the ResNet18 network and implemented with the non-local and Coordinate Attention (CA) modules, which extract long-range dependencies on image space and enhance spatial features through the Branch Attention (BA) module to emphasize the region of interest.Furthermore, the SSJN model employs Conv-LSTM modules to extract long-range dependencies in the image spectral domain.This addresses the gradient disappearance/explosion phenomena and enhances the model classification accuracy.The experimental results show that the proposed SSJN model is more efficient in leveraging the spatial and spectral information of hyperspectral images on multidimensional microspectral datasets of CCA, leading to higher classification accuracy, and may have useful references for medical diagnosis of CCA.
Keywords: self-attention; microscopic hyperspectral images; image classification; Conv-LSTM
1 Introduction
Cholangiocarcinoma (CCA) is a primary liver cancer that occurs within the bile duct and is highly malignant.CCA constitutes approximately 3% of gastrointestinal cancers, having an annual incidence of 5 000 new cases and exhibiting a high mortality rate[1].The Eastern Hepatobiliary Surgery Hospital at the Second Military Medical University has reported a median survival time of approximately 35 months for patients diagnosed with CCA[2].There are many detection methods for CCA, such as computed tomography, magnetic resonance imaging, and ultrasound examination.However, pathological testing, as the “gold standard” for cancer detection, plays a decisive role in the diagnosis and treatment of CCA.Pathology testing is essential for clinicians to develop treatment plans and predict malignant tumor prognoses[3].
The accuracy of pathological diagnosis depends on the knowledge and expertise of pathologists.Even those who are experienced and senior in high-intensity work environments may inevitably miss or misdiagnose.Researchers from the Hepatobiliary Surgery Team at the Second Military Medical University of the People’s Liberation Army analyzed 100 slices of CCA tissue,comparing diagnoses made by pathologists with varying experience levels.Associate chief physicians with more than 15 years of experience in pathological testing made no errors in their diagnostic results and only identified two cases as suspected diagnoses.The attending physician with more than 5 years of experience had two incorrect judgments and identified seven cases as suspected diagnoses.Inexperienced resident physicians had five cases of misjudgment [2].In clinical practice, judgment errors can have an incalculable negative impact on patient care.
In recent years, the development of deep learning technology has significantly influenced clinical medicine by enabling automatic classification of histopathology images.This advancement is exemplified by Kiani et al.[4] who utilized Convolutional Neural Network (CNN) networks to enable pathologists to discriminate between hepatocellular carcinoma and CCA subtypes on whole slide images with an 84.2% accuracy rate on the test set.Another study conducted by Hashimoto et al.[5] from the Japanese Institute of Physics and Chemistry utilized a model, Multiple Instance CNN network, which integrates multi-entity, domain adversarial, and multi-scale learning frameworks to classify various subtypes of lymphoma.
However, the earlier instances employ traditional optical imaging as an imaging technique,producing RGB images containing only three channels.These images are not able to effectively express the vast spectral information present in pathological tissue, and many classification models which use traditional color pathological images struggle to improve the accuracy of clinical tumor diagnosis[6].In an effort to overcome the limitations of RGB images, hyperspectral imaging has emerged as a way to obtain rich spectral information.Unlike traditional RGB images, hyperspectral imaging collects information from a wide electromagnetic spectrum, producing images that frequently contain dozens or even hundreds of bands.The increased range of bands allows for the capture of more comprehensive spectral information, resulting in the effect of “spatial spectral integration”.In recent years,hyperspectral imaging has found wide application in areas such as food safety[7], water quality monitoring[8], environmental protection[9],and other fields.
The fusion of spatial and spectral information in hyperspectral images allows for the extraction of detailed information from pathological tissues, leading to great potential for its application in pathological image analysis[10].For instance, Chen et al.[11] utilized the TMP model to distinguish between living and dead human ovarian cancer cells (SKVO3) and discovered that utilizing hyperspectral imaging technology resulted in samples with classification accuracy that was 3.87% greater than those gathered using just traditional RGB color imaging.In another study, Duan [12] utilized a 3D-Res-CNN network to classify rat CCA tissue slices, and they found that the accuracy of identifying regions of interest was greater on hyperspectral pictures by 12.5% compared to color photos.Sun et al.[6] proposed a method combining CNN and random forest to classify CCA micropathology images, which demonstrated that HSI had a higher accuracy of 2.2% compared to RGB images.Zheng et al.[13] used the Inception-FSCA model based on 2-dimensional Fourier transform to extract frequency features of CCA micropathology HSI, resulting in an improved accuracy of 5.8% compared to traditional methods.
CNN can extract deep texture features of the target; however, traditional CNNs, such as VGG networks, which rely only on stacking hidden layers to obtain target long-range dependence information, are slow and ineffective in acquiring perceptual fields.Recently, the selfattention mechanism has significantly influenced image classification tasks, with models like ViT[14] achieving superior results.The Transformer model exhibits remarkable proficiency in capturing long-range dependencies, rapid computation, and providing robust interpretability.But training Transformer-based models typically necessitates a substantial volume of sample data.However, medical images are often difficult to obtain and the sample size is small, making it difficult to use transformers to enhance classification performance.To address this issue, the present study employs the conventional non-local module[15] which requires less training data, to extract image self-attention.It then integrates this module with CNN for classifying Cholangiocarcinoma data.Moreover, an excessive focus on spatial information extraction may distort the spectral information in CNN features[16].Therefore, this study introduces a spectral adjustment module into the model to enhance the network's recognition ability.
Currently, CNN-based Hyperspectral images(HSI) classification models encounter various limitations, including subpar classification performance, limited generalization capability, and challenges in capturing long-range dependencies in images.To address these challenges, this article introduces a novel HSI classification model called Spatial-Spectral Joint Network (SSJN).The primary focus of the SSJN model is to extract long-range dependencies from images in both the spatial and spectral domains, thereby improving classification performance.Compared to traditional HSI classification models, SSJN offers several technological innovations and advantages, including:
1) The non-local submodule amalgamates the tensor’s two spatial dimensions in the vertical and horizontal directions via the reshape operation.Subsequently, the correlation between image pixels is computed through the matrix dot multiplication operation, resulting in the autocorrelation matrix.Through the implementation of the non-local module, the SSJN model can efficiently capture long-range dependencies in images, thereby enhancing classification accuracy.
2) The Coordinate Attention (CA) module decomposes the extraction of channel attention into two one-dimensional feature encoding processes, which aggregate features in two directions.While extracting attention from image channels, it can also capture the long-range dependencies of feature maps in both horizontal and vertical directions.Different from traditional CNN channel attention extraction modules, the CA module can mitigate the loss of position information caused by global pooling.
3) The Branch Attention (BA) module captures intricate texture information within the image space by utilizing compression channels and 2D convolution operation, integrating it into the model in a branch form.This module allows for the establishment of complementary relationships between spatial texture information and the long-range dependencies of images, ultimately leading to an enhancement in the classification performance of the model.
4) The SSJN model is better suited for medical HSI applications characterized by small sample sizes compared to the transformer classification model.
2 Proposed Classification Method
Fig.1 illustrates the structure of the SSJN model utilized in this study.The model is based on Resnet18 and consists of two embedded components: a spatial feature extraction module and a spectral feature extraction module.Initially, the CCA hyperspectral pathological images are divided into fixed-size cubes, which serve as the training data inputted alongside the corresponding label data into the training model.In the initial stage, an image self-attention mechanism is preliminarily extracted using a convolutional layer and a non-local submodule.Subsequently,the issue of “degradation” resulting from the deepening of network layers in CNN networks is mitigated through the stacking of residual modules[17].

Fig.1 The architecture of proposed Spatial-Spectral Joint Network (SSJN)
Furthermore, the BA module and CA module are employed to capture the spatial features of the image and extract the long-range dependency relationships within the image space.Finally, the spectral feature extraction module is utilized to extract image spectral features and improve classification performance.
2.1 Spatial Feature Extraction
In computer tasks, attention mechanisms have proven to be effective for image classification.The purpose of attention mechanism is to focus on important features and sup-press unnecessary features, that is, selectively focusing on some related things while ignoring other things in deep neural networks[18].These works contribute to improving the classification accuracy of CNN networks.However, traditional attention modules such as SE Block and Convolutional Block Attention Module (CBAM)[19] obtain limited perceptual fields.They can only capture the longrange dependency relation-ships of images through the continuous stacking of convolutional kernels, which is inefficient, ineffective, and difficult to optimize[15].Therefore, in this paper, the non-local module and CA module are used to capture the long-range dependencies between image pixels, and the BA module is used to adjust the feature map to improve the model’s expression ability.
2.1.1 Non-Local Module
Convolutional neural networks have three main problems when obtaining global information[15]:
1) Capturing long-range dependencies in image space requires stacking multiple convolutional layers, resulting in low learning efficiency.
2) Deepening the network layer to obtain a larger Receptive field may lead to gradient disappearance/explosion.
3) Traditional CNN networks can only obtain partial long-range relationships.Convolutional operations may not be able to obtain the correlation between two distant positions.
Therefore, this paper introduces the nonlocal module to capture image contextual information.The non-local module draws inspiration from the traditional approach Non local means and then applies this idea in neural networks to capture the long-range dependencies of images,rather than just stacking multiple convolutional layers to obtain more global information.The non-local module brings rich contextual semantic information to the network.

Fig.2 The non-local block
The non-local module employs self-attention to model remote dependencies, as shown in Fig.2.Firstly, a 1×1 convolution kernel is used to map the network inputX= [B,H,W,C] toθ,φ, andgfeatures, which correspond to the Query, Key,and Value matrices in the self attention mechanism,with the goal of compressing the channels and reducing computational complexity.Afterwards, the outputθandφare reshaped into a[B,HW,C/2] size, and the spatial dimensions are merged.Next, a matrix dot product operation is performed onθandφto calculate a weight map that is similar to the autocorrelation matrix,resulting in a [B,HW,HW] format.The weight map is then normalized through softmax function to obtain a global weight map that ranges from 0 to 1.The weight map represents the normalized correlation of each pixel in the feature map with all other location pixels, as depicted in Fig.3.Specifically, the value at position (i,j)represents the impact of all other pixel points(including itself) on the pixels at that position.Additionally, the attention coefficient is multiplied back into the feature matrixg, so that a spatial attention mechanism can be applied to all positions corresponding to each feature map of all channels.Finally, residual operation is applied to the original inputX, and the output channel is restored using a 1×1 convolutional kernel to obtain the final output of the non-local module.
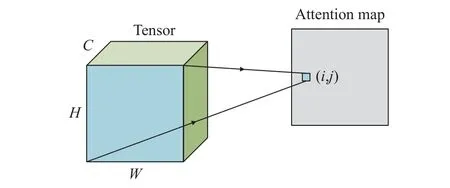
Fig.3 Normalized weight schematic diagram
The non-local module is based on the nonlocal mean filtering operation concept in the field of image filtering, which can capture global information of the image.The design benefits are: 1)Compared with the traditional convolution operation, non-local module can capture the interrelationship between each pixel of the image in a comprehensive and specific way.2) Compared to convolutional operations, non-local modules are more efficient and require fewer convolutional layers.3) The non-local module can ensure that the input and output scales remain unchanged,making it easy to embed into the network architecture.
2.1.2 Coordinate Attention Module
Although the non-local module can efficiently capture long-range dependencies between image pixels, its computation is complex and time-consuming.When there are multiple non-local modules in a network, the computational overhead will increase significantly.Therefore, this paper also introduces the CA module to replace the functions of some non-local modules.Its structure is shown in Fig.4.Wherein, the ‘XAvg-Pool’ and ‘YAvgPool’ refer to the global avgpool in the horizontal and vertical directions,respectively.The CA module can embed the location information into the channel attention mechanism, which proposes a new attention mechanism for convolutional neural networks.Unlike the traditional attention module, the CA module utilizes feature encoding processes along both spatial directions, decomposing channel attention into one-dimensional processes that enable aggregation of features and preservation of positional information.Then, a pair of orientationaware and position-sensitive feature attention maps is obtained, providing an enhanced presentation of the object of interest.This innovation not only optimizes the computationally intensive non-local module, but also provides new flexibility in the attention mechanism of the CNN architecture.

Fig.4 The structure of CA module
Specifically, for a given inputX=[H,W,C],first encode each channel along the horizontal and vertical directions using pooling kernels with dimensions (H, 1) and (1,W), respectively.Therefore, the output of channelcwith a height ofhcan be expressed as
Similarly, the output of channelcwith a width of w can be written as
By using the above transformation, longterm dependencies along one spatial direction can be captured and accurate positional information along another spatial direction can be saved.
Then, through the concatenate operation((Eq.(3)) and the 1×1 convolution operation((Eq.(4)) extracts channel features, and the function achieved in this step is similar to SEBlock.
Finally, by aggregating (Eq.(5)), it is possible to obtain both channel attention of the feature map and long-range dependencies along the horizontal and vertical directions.
Advantages of the CA module:
1) In contrast to the SE-block, the CA module divides channel attention into two parallel one-dimensional feature encoding processes.This division helps to prevent the loss of position information that 2D global pooling can cause.Additionally, the CA module effectively captures channel attention while also capturing long-range feature map dependencies in both horizontal and vertical directions, effectively integrating spatial coordinate information into the generated attention map.
2) The CA module, like the non-local module, can capture long-range dependencies in images.However, unlike non-local module, the CA module has lower computational overhead.As the size of the sample image increases, the computational time of the non-local module increases sharply.Therefore, this paper proposes using the CA module instead of some non-local modules.This substitution not only helps retrieve image channel information but also reduces model computation.
2.1.3 Branch Attention Module
The branch model has been proven to be effective in various convolutional neural networks[20].Although the non-local module and CA module can capture the self-attention and channel attention of the image, they lack detailed description of the local features of the image.So a branching spatial feature extraction module is introduced into the model in this paper, as shown in Fig.5.
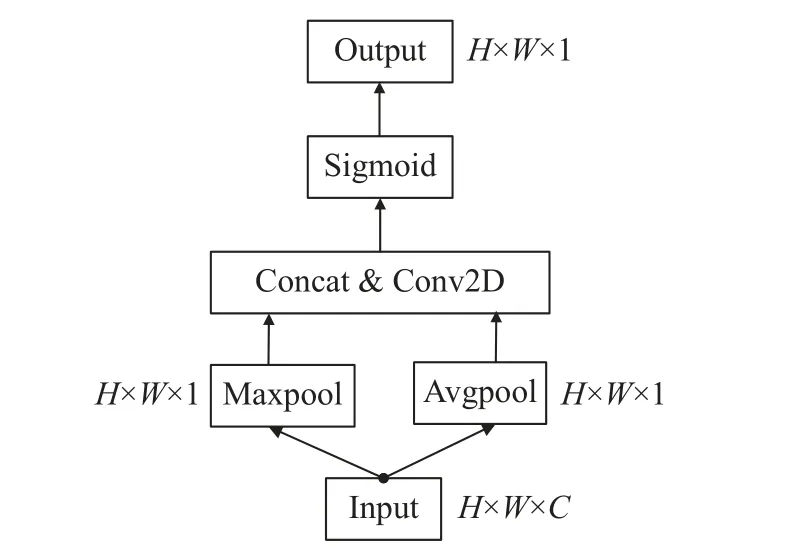
Fig.5 BA block structure
The CBAM method is utilized and integrated into the backbone network.
Initially, the module performs pooling methods, such as channel based max pooling and average pooling, to aggregate channel information.Subsequently, the results are concatenated based on the channel and the dimensionality is reduced to one channel through convolution.Finally, a spatial attention feature is produced utilizing the sigmoid operation.
The BA module can enhance the network's ability to express spatial features of images, focus on areas of interest, and improve network classification accuracy.
2.2 Spectral Feature Extraction
Hyperspectral images contain rich spectral information, but convolutional layers do not consider the dependence on each channel and cannot effectively utilize this information.Therefore, this paper utilizes the spectral feature extraction module to selectively enhance the highly informative features of the network, obtain long-range dependencies between spectra, and guide computing resources towards the most informative part of the input signal.
The dense sampling of sensors results in hyperspectral images that exhibit strong correlation among adjacent bands and long-range dependence among non-adjacent bands.Nonadjacent spectral intervals can exhibit variable correlations between two samples with similar spectra[21].Capturing the correlation between target spectra can enhance the distinguishability of spectral characteristics and increase classification accuracy accordingly.In this study, we employ the Conv-LSTM module[22] to capture the long-range dependencies within the spectral domain of the samples.
The Long and Short Term Memory (LSTM)model is a type of Recurrent Neural Network(RNN) that is capable of learning long-term dependencies in sequences, thereby addressing the issues of gradient disappearance and explosion in network training[23].Although LSTM models are unable to capture spatial information from images and directly apply to convolutional neural networks, the introduction of the Conv-LSTM module addresses this limitation.The Conv-LSTM module shares similarities with the LSTM model structure, including a unit value(ct) and input, forget, and output gates (it,ft,ot),which the network learns to regulate to achieve ideal results.The key difference is thatthe Conv-LSTM model employs convolutional processing,rather than the multiplicative interactions of LSTM, allowing it to operate effectively within convolutional neural networks while extracting spatial features in a similar manner as convolutional layers.The specific formula is
To enhance cross-channel interaction and extract attention to specific channels, this paper incorporates a spectral adjustment module into the backend of a Conv-LSTM model.The module includes one-dimensional convolution and fully connected layers, with a diagram of its structure depicted in Fig.6.
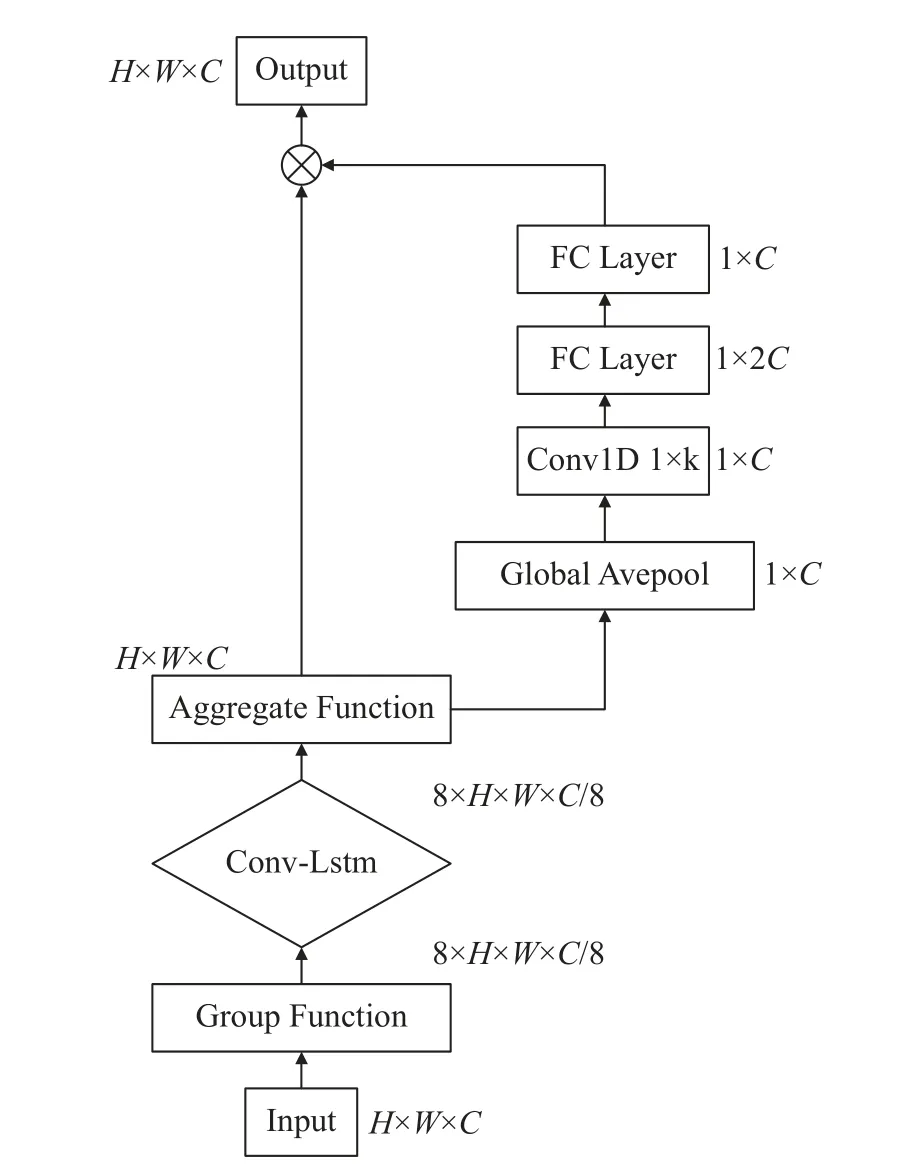
Fig.6 Spectral feature extraction module (The grouping function divides tensor into 8 groups)
3 Experiments
3.1 Dataset
The microscopic hyperspectral image dataset of CCA used in this study was acquired from a multidimensional common bile duct database established by Professor Li Qingli’s team at East China Normal University[6].The experiment utilized three datasets, including 35 cancerous images, 30 non-cancerous images, and 65 benign images.Each hyperspectral image had a size of 1 280 × 1 024 × 60, with a spectral resolution ranging from 2–5 nm and a spectral range of 550–1 000 nm.Images were captured using a 20x objective lens.The study divided the image data into 32 × 32 × 60 samples for the creation of training and testing datasets, as listed in Tab.1.Among them, all samples are 32 × 32 × 60 size,with no overlapping relationships between datasets.

Tab.1 Dataset size used in the experiment
Normal samples were defined as non-cancerous while abnormal samples included all cancerous tissues, including instances with certain cancerous changes.The training set utilized traindata, while the test sets consisted of test-data1,test-data2, and test-data3.The specific dataset size is shown in Tab.1.
The datasets divided by the above samples all come from different images, that is, there is no intersection between them.To perform spectral correction on hyperspectral images, a method based on the Lambert-Beer law was employed.The following formula was used.
Among them, Sample is the original data sample, Blank is the blank slide data collected under the same conditions, andTis the corrected spectral value.The data utilized in the experiment has been subjected to the aforementioned processing methods, and results of the corrected spectral comparison can be observed in Fig.7.

Fig.7 Spectral curves: (a) spectral curve of the original sample; (b) spectral curve after spectral correction
3.2 Experimental Result
3.2.1 Experiments on Different Patches
The size of the sample data also affects the accuracy of classification.The larger the patch, the more information it can provide.However, as the image size increases, the computational complexity of the network also increases.The discussion on different patch sizes is listed on Tab.2.

Tab.2 Effect of patch size on experimental results (using test data1)
As the patch size increased, we observed an increase in the classification accuracy of the network, which reached its peak at 92.62% when patch is 32.However, further increases in patch size resulted in a decrease in classification accuracy.Additionally, increasing image size led to a significant rise in the computational cost of the non-local module, which in turn increased the network's training time.Consequently, all subsequent experiments employed patch is 32.
3.2.2 Comparative Experiments
This section used the train-data dataset for training, the test-data1 dataset for testing, and compared it with current popular classification frameworks.It was found that the SSJN model can achieve good results on this dataset.The algorithms used for comparison include traditional CNN models (Alexnet[24], VGG19[25]),residual networks (Resnet18[17]), attention mechanism networks (RSSAN[26], SpelNet[27]), and transformers (ViT[14]).A brief introduction to these classification algorithms is as follows:
1) Alex net: As a traditional convolutional neural network model, the Alex net algorithm consists of 5 convolutional layers, 3 pooling layers, and 3 fully connected layers.It has a simple structure but good performance, and has been proven in many application scenarios.
2) The VGG19 algorithm consists of 19 hidden layers (16 convolutional layers and 3 pooling layers), characterized by the use of consecutive 3×3 convolutional kernels to replace the larger convolutional kernels in AlexNet.
3) RSSAN: The RSSAN algorithm is an endto-end residual spectral spatial attention network for HSI classification, consisting of 5 convolutional layers and 3 sets of concatenated spatial spectral attention modules (i.e.CBAM modules)
4) SpelNet: The SpelNet algorithm is a spectral interaction network used for HSI classification.It adopts a dual branch structure and splits the CBAM module used for attention extraction into two parts, resulting in complementary spatial and spectral features.
5) Vit: The Vit algorithm directly uses the transformer to classify images, without the need for convolution operations, and can capture longrange dependencies in the sample space.
6) ResNet18: ResNet18 networks use residual modules to mitigate the “degradation” phenomenon that occurs with the deepening of network layers in CNN networks.
The conducted experiments employed identical datasets and experimental settings, with Tab.3 presenting the resulting findings.

Tab.3 Comparison test results of test-data1 dataset
Our experimental results indicate that compared to ResNet18, the SSJN network improves its accuracy by 5.82% and reaches a recall rate of 0.968 4.This indicates the SSJN network’s strong classification performance and recognition capabilities for abnormal samples.Additionally, when compared to other comparative algorithms, the SSJN network shows a significantly improved Kappa coefficient, suggesting a high degree of consistency in the model’s predicted categories and the actual sample categories.Moreover, the classification performance of the Vit model is substantial, demonstrating the effectiveness of extracting long-range dependency relationships from images in hyperspectral image classification.Conversely, the classification performance of both the Alexnet and Rssan networks is poor, likely due to their comparably simple network structures.Moreover, we also compared the classification performance of different algorithms on a single image, as shown in Fig.8.
In order to account for the potential impact of environmental changes and individual patient variations on the accuracy of HSI classification,this experiment validated the model using multiple datasets.In addition to the test-data1 dataset, the model was evaluated using testdata2 and test-data3 datasets obtained from different batches.This method aims to assess the generalization performance of the model.The results of this validation process are presented in Tab.4 and Tab.5, and the roc curve obtained is shown in Fig.9.Supplemental experiments confirmed the SSJN model’s superior performance compared to alternative models.It achieved the highest accuracy rates on both rest-data2 and test-data3 sets, with corresponding accuracy rates of 83.71% and 82.78%, respectively, making improvements of 4.61% and 3.71% over the ResNet18 baseline model.Further, the model’s recall rate outperformed all experimental algorithms, reflecting its increased sensitivity to anomalous sample recognition.Experimental results confirmed SSJN’s robust generalizability,with corresponding AUC values of 0.920 4 and 0.916 0 for test-data2 and test-data3 datasets,respectively.These values exceeded those of all comparison algorithms.Alexnet, Vit, and Spelnet models demonstrated efficient performance on the supplemental dataset, while VGG and RSSAN models struggled to perform.The RSSAN model is a shallow convolutional neural network comprising only 5 layers with limited depth.A single stack of attention modules(CBAM modules) may not achieve the desired results or extract deep image features effectively.In contrast, the VGG model replaces the 11×11 and 7×7 convolutional kernels in the Alexnet model with multiple 3×3 convolutional kernels,resulting in a network that is comparatively deeper.However, reducing the size of convolutional kernels results in a narrower perceptual field, making it harder to capture long-range image dependencies.Moreover, deepening the network model may lead to insufficient data for training all neurons within the hidden layer,resulting in an overfitting state and limited model generalizability.
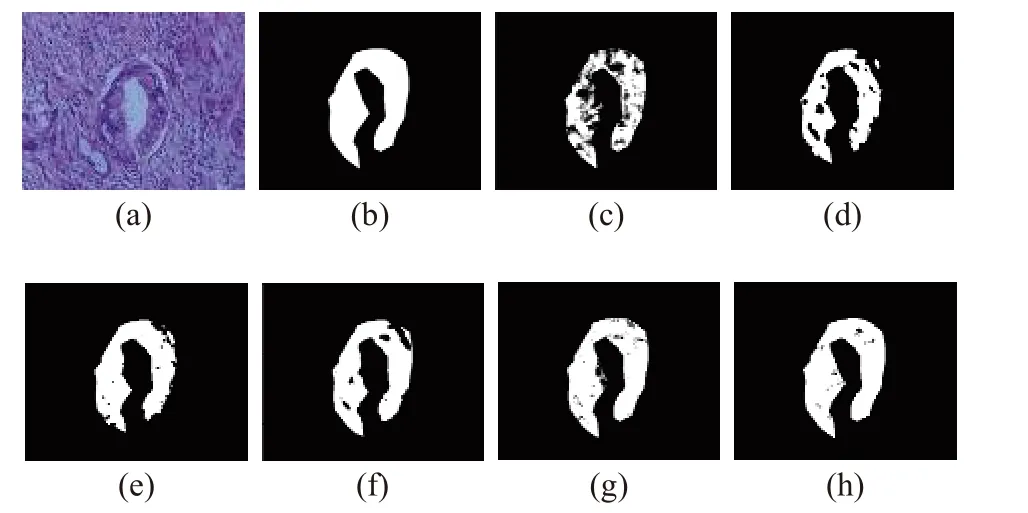
Fig.8 Qualitative results of CCA classification: (a)RGB;(b)ground truth; (c)SpelNet-71.7%; (d)VGG-75.4%;(e)Vit-82.6%; (f)RSSAN-87.8%; (g)ResNet-94.9%;(h)SSJN-98.4%

Tab.4 Test-data2 test results

Tab.5 Test-data3 test results
3.2.3 Ablation Experiments
In this section, ablation experiments are conducted to demonstrate the effectiveness of the design module and its effect on the network.First, this section compares the effects of the non-local, CA, and BA modules on the experiments, and the results are shown in Tab.6.

Tab.6 Ablation experiments based on different spatial attention sub-modules (using test data1)
It can be seen that the non-local, CA, and BA modules all contribute significantly to the network’s classification accuracy.Eliminating any of them reduces accuracy to 88% to 89%.Therefore, these submodules work in unison to improve classification accuracy.The non-local module captures long-range pixel dependencies, while the CA module captures horizontal and vertical longrange dependencies and integrates the coordinate information.The BA module portrays spatial image features and enhances representations.
This section verifies the effectiveness of the spectral feature extraction module based on the above comparison experiments, as presented in Tab.7.Block A represents the spatial feature extraction module, while block B represents the spectral feature extraction module.The spatial feature extraction module improves the classification accuracy of the Resnet18 network by 3.44%on the test-data1 set.Meanwhile, the spectral feature extraction module improves the classification accuracy of the same network by 3.05%.Combining the two modules enhances the classification accuracy of the Resnet18 network by 5.82%.In addition, we prove the efficacy of these two modules on test-data2 and test-data3 sets.

Tab.7 Ablation experiments based on spatial module and spectral module
4 Conclusion
This paper presents a composite spatial and spectral attention mechanism for classifying abnormal regions of CCA based on micro hyperspectral images of CCA pathological sections.The SSJN model extracts the image spatial features through the spatial attention module and channel features through the spectral attention module.Among these, the non-local and CA submodules capture long-range dependency relationships of image pixels and coordinate directions,respectively.Moreover, the BA module enhances the image’s spatial feature representation.The Conv-LSTM module captures long-range dependencies in the image channels and improves the network gradient disappearance /explosion phenomenon.We validate the effectiveness of the SSJN network through comparison experiments,showing that it outperforms commonly used hyperspectral image classification algorithms in generalization, achieving 92.62% accuracy on the CCA hyperspectral dataset.Nevertheless, the model still has several limitations, including its inability to distinguish multiple subtypes of CCA and lack of further comparative experiments for small sample datasets.Future work will focus on addressing these issues.
杂志排行

Journal of Beijing Institute of Technology的其它文章
- Reduced Imaging Time and Improved Image Quality of 3D Isotropic T2-Weighted Magnetic Resonance Imaging with Compressed Sensing for the Female Pelvis
- Analysis of Dynamic Characteristics of Forced and Free Vibrations of Mill Roll System Based on Fractional Order Theory
- Automated Segmentation of the Brainstem, Cranial Nerves and Vessels for Trigeminal Neuralgia and Hemifacial Spasm
- Nitrogen Content Inversion of Corn Leaf Data Based on Deep Neural Network Model
- Application of Opening and Closing Morphology in Deep Learning-Based Brain Image Registration
- Tissue Microstructure Estimation of SANDI Based on Deep Network