基于改进U-Net 的不同容重小麦籽粒识别检测
2023-11-14吕宗旺王玉琦孙福艳
吕宗旺,王玉琦,孙福艳
(1.河南工业大学信息科学与工程学院,河南 郑州 450001;2.粮食信息处理与控制教育部重点实验室,河南 郑州 450001)
国家储粮在粮食安全、农民收益保障以及国家经济稳定等方面具有重要的作用,是保障国家粮食安全和促进农业发展的重要手段[1-3]。由于小麦在食品工业发展中有着其他粮食产品不可替代的作用,小麦的质量等级检测也成为重要的研究内容之一[4-5]。目前,传统的小麦质量等级检测方法精度和检测效率仍有提升空间。随着深度学习的发展,以深度学习的方法实现小麦质量分级成为可能,逐渐成为研究热点[6-8]。
早期,在粮库和质检部门小麦的检测都采用人工操作仪器检测的方法[9]。但该操作步骤繁琐,检测效率低,从而影响粮食的进出口等进度。利用X射线可以断层扫描小麦籽粒在发芽之后的内部结构,但仍需寻找更为有效的三维重建方法[10]。多光谱成像技术具有计算机视觉和光谱分析的优点,但数据量大、系统昂贵等问题是不可避免的[11]。传统的机器学习方法可以通过计算机视觉系统捕捉作物图像,根据颜色、形状、面积和纹理提取特征[12-13],但人工提取的特征依赖于人类的先验知识,且特征之间相互关联容易造成冗余,不能满足小麦质量等级的快速准确评价[14]。
目前,一些国内外研究人员已经利用语义分割技术实现了一些粮食作物的品质、病害和不完善粒的识别检测[15-17]。王梁等[18]提出了一种基于Mask-RCNN 的油茶果目标识别与检测算法,油茶果目标识别的平均检测精度达到89.42%;戴雨舒等[19]提出了基于改进Deeplabv3+的小麦赤霉病识别模型,以轻量化网络MobileNet V2为网络编码模块建立基于深度学习网络的小麦赤霉病发病麦穗的识别与检测模型,该模型的平均精度为0.969 2,平均交并比(MIoU)为0.793;陈鹏等[20]提出一种融合卷积神经网络和注意力机制的小麦赤霉病语义分割网络模型UNetA,其MIoU 值达到83.90%;ZHANG 等[21]提出了一种名为Ir-UNet 的改进算法,结果显示,具有5个原始波段的Ir-UNet优于基本U-Net,在各种输入中取得了最高的总体准确度(OA),得分97.13%;邓杨等[22]提出了一个轻量级的语义分割网络IMUN,实现对大米上垩白区域的像素级分割,大米上垩白区域的分割准确率可达到94.11%。可见,用深度学习方法可以实现小麦等粮食籽粒的识别检测。本研究提出了一种结合残差堆叠主干网络和注意力机制的改进U-Net 模型,以实现更准确的小麦图像分割。在小麦图像的分割过程中,充分考虑到如小麦目标尺寸较小、特征不明显和边缘分割不清晰等问题,在网络结构中引入了残差堆叠模块来减少特征损失,并增强了网络对小麦细微特征的提取能力;为了进一步改进网络性能,在编码器部分嵌入了CBAM(Convolutional block attention module)注意力机制模块,该模块能够自适应地调整特征融合的权重,使网络能够更好地聚焦于小麦图像中的重要区域,提高分割的精度和鲁棒性;同时,在解码器部分嵌入了自注意力机制模块,提高网络模型的特征还原能力,使分割结果更加准确和清晰。通过采用语义分割技术,可以实现从图像层面对小麦图像进行更精确的分割,更准确地识别出小麦籽粒的位置和形状,为不同容重小麦籽粒的识别检测奠定基础。
1 材料和方法
1.1 原始U-Net模型
本研究采用语义分割技术的思想,通过小麦籽粒图像与背景之间的像素级差异,建立小麦图像分割模型。 通过对比 U-Net[23-24]、SegNet[25]、PSPNet[26-27]、DeepLabv3+[28]网络结构的优缺点,结合研究对象小麦籽粒自身的特点,选择较适合的UNet 网络结构进行改进[29-31]。如图1 所示,U-Net 具有对称的编码器-解码器结构。在编码器部分,输入的图像通过一个卷积操作、激活函数和归一化处理进行特征提取和下采样;编码器部分的输出被传递到解码器部分,并通过跳跃连接(Skip connections)在2 个对应层之间建立连接;解码器通过上采样(增加分辨率)和卷积操作来还原图像的尺寸,通过一个最后的卷积层,经过适当的激活函数后,在输出层生成最终的分割结果。
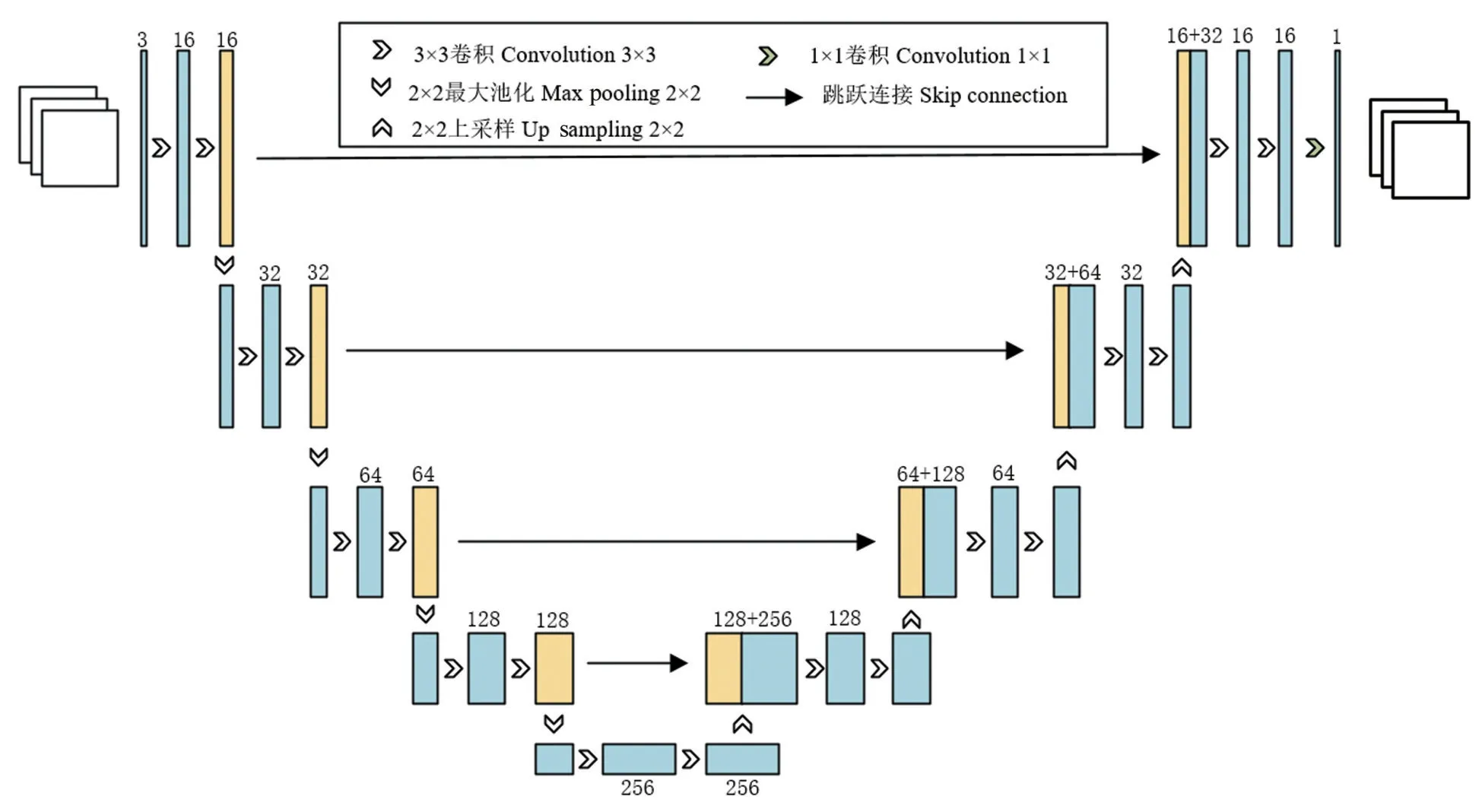
图1 U-Net网络模型Fig.1 U-Net network model
1.2 残差结构
残差结构(Residual structure)是一种解决深度网络训练中梯度消失和梯度爆炸问题以及加速网络收敛速度的结构[32]。残差网络是由一系列残差块组成的,如图2 所示,输入的x 被复制成两部分,一部分输入到层(Weight layer)之中,进行层间的运算得到输出F(x);另一部分作为分支结构,输出原本的x,最后分别将两部分输出进行叠加[F(x)+x],再通过Relu 激活函数处理,这便是整个残差块的基本结构。
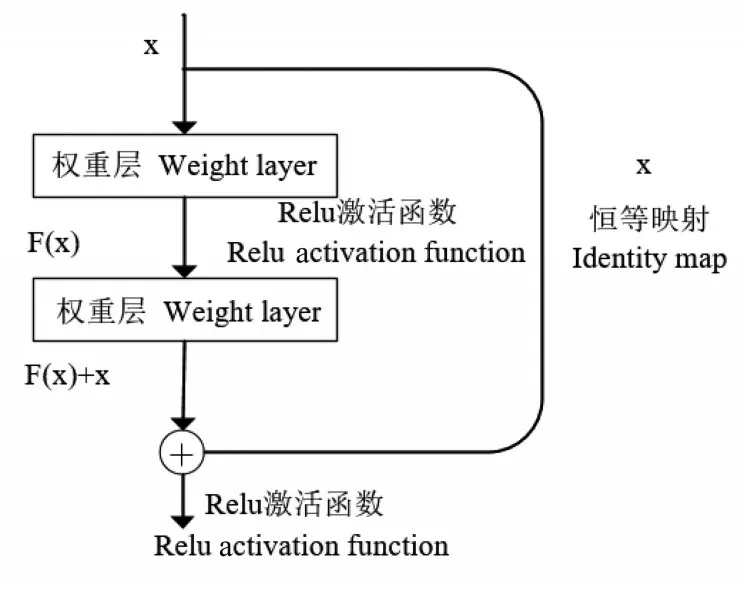
图2 残差结构块Fig.2 Residual structure block
1.3 CBAM注意力机制模块
CBAM 是一种基于注意力机制的轻量级卷积神经网络模块[33],用于增强模型的特征表示能力。CBAM 由2 个部分组成:通道注意力和空间注意力。通道注意力机制(Channel attention)用于自适应地调整不同通道特征的权重;空间注意力机制(Spatial attention)用于自适应地调整不同空间位置的特征融合权重。如图3 所示,输入特征F∈RC*H*W,然后是通道注意力模块一维卷积Mc∈RC*1*1,将卷积结果乘原图,将通道注意力模块的输出结果作为输入,进行空间注意力模块的二维卷积Ms∈R1*H*W,再将结果与原图相乘。
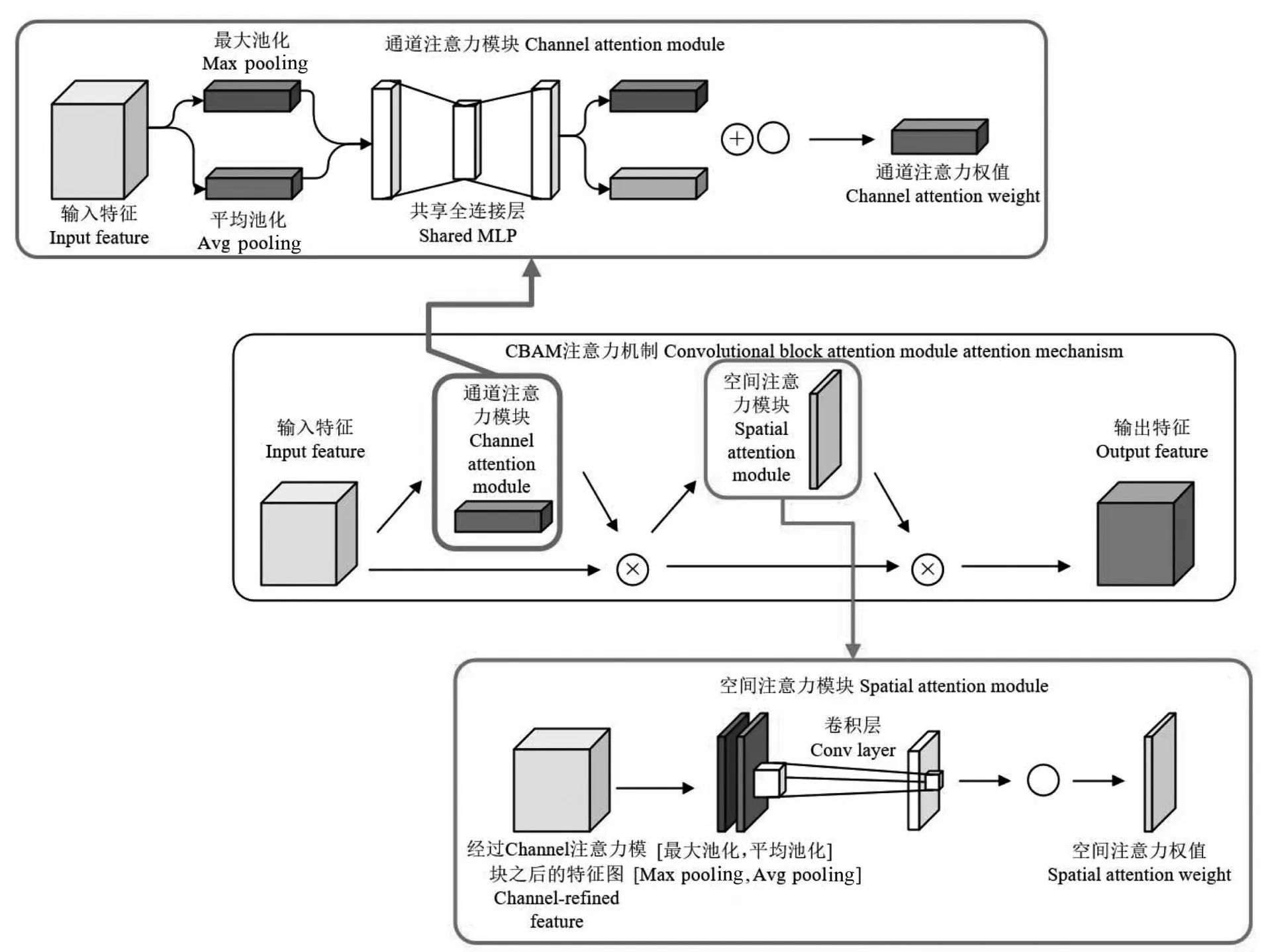
图3 CBAM注意力机制Fig.3 CBAM attention mechanism
1.4 自注意力机制模块
自注意力机制(Self-attention mechanism)是一种用于建模序列或图像中不同元素之间关系的技术[34]。如图4 所示,在图像中,自注意力机制可以学习像素之间的依赖关系,从而增强模型的特征表示能力,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
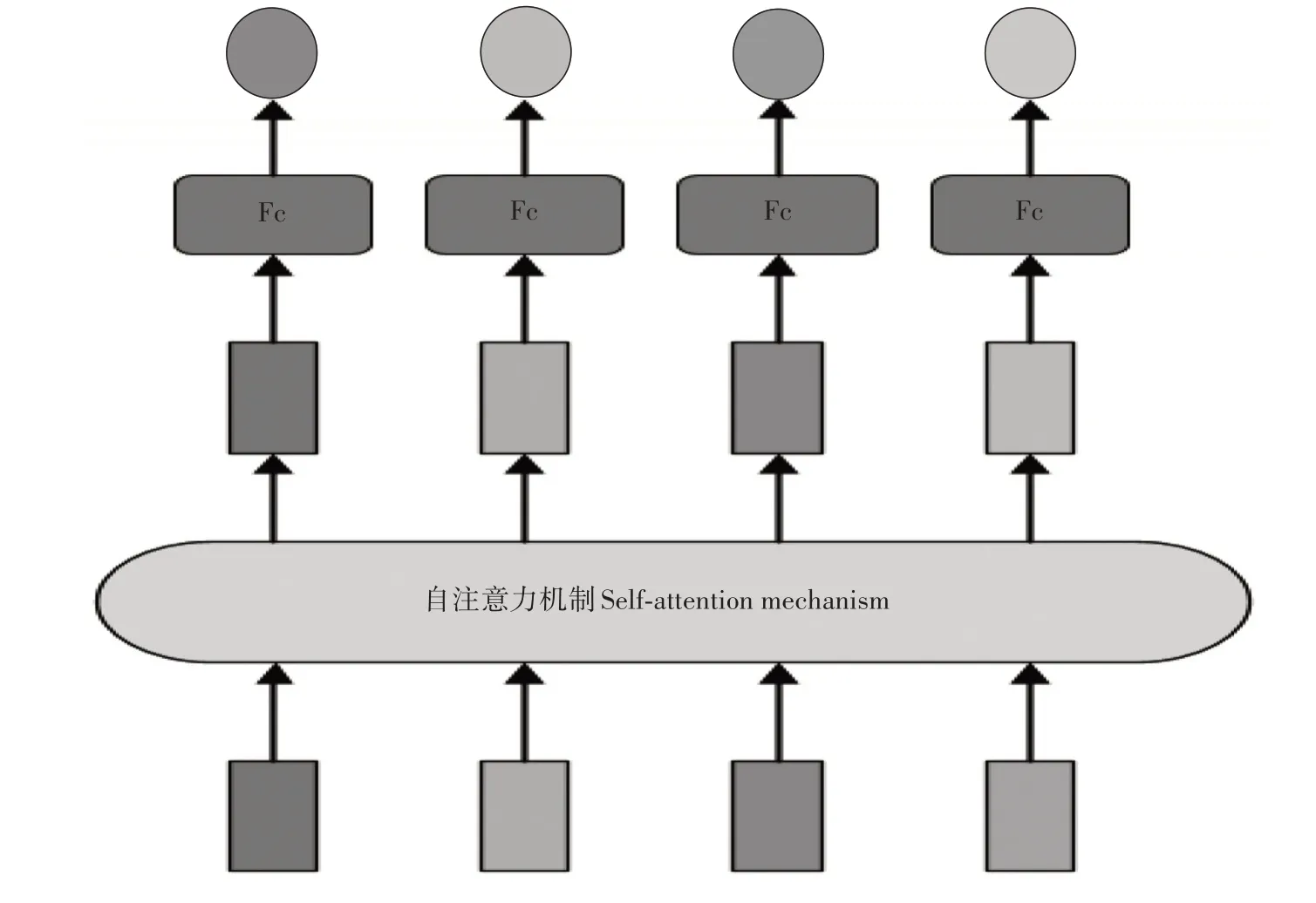
图4 自注意力机制Fig.4 Self-attention mechanism
1.5 CBSA_U-Net模型构建
本研究对U-Net 网络进行改进,提出了基于残差网络的双注意力融合模型CBSA_U-Net,如图5所示。该模型在U-Net 的基础上进行了修改,将编码器(Encoder)部分的特征提取网络替换为残差堆叠模块,减少下采样过程中的特征损失;为进一步提取特征,在初级特征图后嵌入CBAM 注意力机制模块并在解码器部分加入自注意力机制增强不同目标之间的相关性,从而还原细节信息,实现小麦的精确分割。
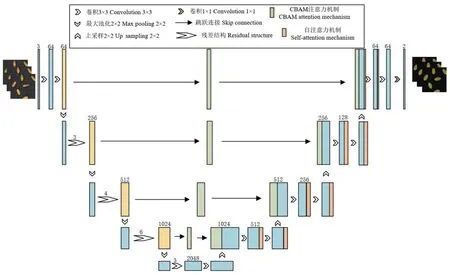
图5 CBSA_U-Net模型Fig.5 CBSA_U-Net model
首先,在编码器部分,结合小麦籽粒目标较小的特点,将所采集的小麦籽粒图像进行卷积操作,使用ResNet50 卷积神经网络初步提取小麦籽粒图片的特征,采用残差传播,减少小目标在下采样过程中损失的特征,生成初级特征图。
其次,在U-Net模型中,特征融合模块的目的是将编码器中的初级特征图与解码器(Decoder)中的高级特征图进行融合,以提高对小目标的分割能力。当目标较小时,初级特征图可能无法捕捉到足够的细节信息。为了解决这个问题,在ResNet50 输出初级特征图之后嵌入CBAM 注意力机制。从通道和空间位置以自适应地调整不同像素点的特征
融合权重,从而更好地提取小麦籽粒的细节信息,这有助于增强初级特征图的表达能力,提高对小目标的分割准确性。
最后,在解码器部分中,由于经过一系列的下采样操作使得与目标之间呈现弱相关性,导致对小目标的细节信息抓取不足,因此在解码器部分中嵌入自注意力模块,通过减少对外部信息的依赖,更多地捕捉特征的内部相关性,加强上下文之间的联系,还原细节信息。通过引入残差网络和双注意力融合机制,CBSA_U-Net 模型在小麦图像分割任务中表现出更好的性能。
通过以上改进,CBSA_U-Net 模型能够准确地分割小麦图像,并还原小麦籽粒的细节信息。它能够更好地处理解码器部分的弱相关性问题,提高分割模型的性能。
1.6 数据集及预处理
本研究利用专业工业摄像机人工搭建的图像采集平台,对小麦籽粒图像进行采集,所选用的小麦样品来自于河南郑州兴隆国家粮食和物资储备库。选取3种容重等级(790、805、810 g/L)的小麦籽粒作为研究对象,并将其放置在黑色不反光的密胺材质托盘上,采用在同一光源下定点拍摄的方法获取了150张小麦籽粒图像。对采集到的小麦籽粒图像进行打点连线标注得到标注后的掩膜图像。其中,背景像素值为0,790 g/L 小麦籽粒的像素值为1,805 g/L 小麦籽粒的像素值为2,810 g/L 小麦籽粒的像素值为3。再对图像采用中值滤波的方法进行降噪处理,随后对数据集以512为步长进行裁剪,得到尺寸为512×512大小的图像,经过图像裁剪操作,原始的150 张小麦籽粒图像被划分为3 527 张。如图6 所示,其中图6a 表示的是经过处理后的训练集中部分小麦籽粒图像及其对应的标签,从左到右依次为容重是790 g/L(红色标签)、805 g/L(绿色标签)、810 g/L(黄色标签)的小麦籽粒图像及其对应的掩膜图像;图6b 表示的是测试集中的3 种小麦籽粒图像及其对应的掩膜图像。

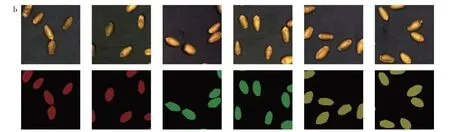
图6 部分小麦籽粒图像及其标签Fig.6 Some wheat kernel images and their labels
1.7 数据增强
由于小麦籽粒样本较小,容易产生泛化能力不足的问题,为防止网络过拟合,提高识别精度,对小麦籽粒图像的原始图和标签图通过数据增强的方式进行样本扩充[35-36]。依次通过向左、向右旋转90°,水平和上下翻转,调节亮度等方式进行8 次扩充,增强后的数据集扩增为原来的9倍,数据集共计31 743 个,把图像增强后的数据集按照8∶1∶1 划分为训练集、验证集和测试集,共25 395 个训练集、3 174 个验证集和3 174 个测试集。数据集中部分图像及标签如图7所示。
1.8 试验设置
试验环境使用的操作系统为Windows 10 专业版,64 G 内存,显卡型号为NVIDIA GeForce RTX 3060,CUDA 版本11.0,使用Pytorch 框架搭建模型。模型训练选用Adam 优化器,其中动量设置为0.9,权重衰减设置为0.000 5;学习率衰减策略使用指数衰减,初始学习率设为0.001;在小麦图像数据集上进行训练,批处理设置为8,最大迭代次数为100。模型训练使用多损失函数交叉熵损失函数和Dice损失函数,总损失为二者加权平均。交叉熵损失函数的表达式如式(1)所示,其中p(x)为真实值的概率分布,q(x)为预测值的概率分布,n表示类别总数。
Dice 损失函数的表达式如式(2)所示,其中|x∩y|表示真实样本与预测集的交集,|x|和|y|分别表示真实值和预测值的个数。
1.9 评价指标
采用MIoU(Mean intersection over union)作为分割结果的评价指标[37-38],IoU(Intersection over union)是指某个类别预测结果与真实标签之间交集与并集之间的比值,MIoU就是这些比值的平均值。其中TP(True positive)=pii,表示一个样本被预测为正例,并且真实标签为正例;FN(False negative)=pij,表示一个样本被预测为反例,但是真实标签为正例;FP(False positive)=pji,表示一个样本被预测为正例,但是真实标签为反例;TN(True negative)表示一个样本被预测为反例,并且真实标签为反例。MIoU 和IoU的计算公式如式(3)(4)所示。
2 结果与分析
2.1 小麦图像分割结果及分析
在搭建的图像采集平台基础上,采用改进的CBSA_U-Net 模型,对17 634 粒小麦进行分割,各种小麦籽粒的分割结果如表1 所示。其中,错误分割的小麦籽粒中,被错分为其他籽粒的数量最多,占错分比例的很大一部分,主要是因为在小麦籽粒特征提取过程中,小麦的大小形状差异不大,但是需要通过很多不同的局部信息进行分类,然而在模型训练过程中,随着任务的变化,注意力区域往往会发生变化,会检测更多无意义的信息使网络冗余且效率低下。

表1 小麦图像分割结果Tab.1 Wheat image segmentation results
2.2 不同模型对比试验结果
使用PSPNet、DeepLabv3+、U-Net 模型作为对比模型,在训练过程中,输入图像的大小为512×512。为验证模型的有效性,所有试验均在同等参数设置下进行对比,表2 展示的试验结果为样本集多次不同划分下的平均精度。如表2 所示,基于UNet 的改进网络CBSA_U-Net 在MIoU 指标上达到81.5%,与原模型U-Net 相比提升了1.8 百分点,相较于PSPNet、DeepLabv3+都有明显的提升。容重为810 g/L 的小麦籽粒大小和纹理特征较明显,分割精度最高;而790 g/L 的小麦籽粒分割精度提升较小,可能原因是容重为790 g/L的小麦籽粒目标较小,并且可能存在一些干瘪的籽粒,影响了小麦籽粒的分割效果;805 g/L 的小麦籽粒相比于原模型提升了0.4 百分点,可能是由于容重为805 g/L 的小麦籽粒大小、纹理等介于上下2种等级小麦之间,容易造成误分割。
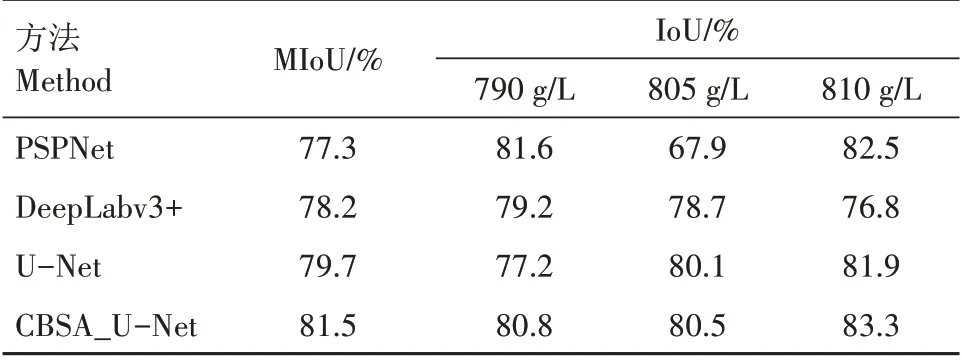
表2 不同模型在不同容重小麦籽粒数据集上的分割精度Tab.2 Segmentation accuracy of different models on wheat kernel data sets with different volume weight
从图8 可以看出,U-Net 和Deeplabv3+模型分割结果中的破碎图斑较多,这主要是因为CNN 的特征提取特性使网络更关注局部信息,未关注足够的上下文信息而使目标的分割呈现碎片化,但加入自注意力机制的CBSA_U-Net模型,无明显破碎图斑。CBSA_U-Net 模型相较于其他网络边缘分割更平滑,归结于CBSA_U-Net 模型的解码器部分多了一个自注意力机制,该结构通过减少对外部信息的依赖,更多地捕捉特征的内部相关性,加强上下文之间的联系,还原细节信息和边缘特征的提取。此外,U-Net 和Deeplabv3+模型对810 g/L 的小麦籽粒分割效果较差,出现了不同程度的误分,而CBSA_U-Net 模型相较于这2 种模型有更好的分割效果,预测结果更完整、更准确,说明基于残差结构加入双注意力机制的U-Net结构在提高分割精度和保持小麦籽粒完整性上是有效的。

图8 不同模型预测结果对比Fig.8 Comparison of prediction results of different models
2.3 消融试验结果
为了验证加入模块的有效性,分别对U-Net 等模型进行消融试验,精度评估结果如表3 所示。从表3 可以看出,加入CBAM 注意力机制模块的CBANet 模型相对于原始U-Net 模型有了略微的提升,MIoU 提升了0.8 百分点,CBAM 注意力机制模块结合了通道注意力和空间注意力,可以提取特征图中的重要信息,对于小麦籽粒分类任务,CBAM 注意力机制帮助网络集中注意力在最相关的特征通道上,提取小麦的形状、纹理、颜色等与分类有关的信息,从而提升网络对小麦籽粒不同特征的感知能力;在通道注意力之后,对特征图的空间维度进行注意力权重的计算,CBAM 注意力机制进一步聚焦在特定的空间位置上,如麦粒的中心或边缘,从而突出小麦籽粒的局部特征,以便更准确地区分不同类型的小麦籽粒;最后,CBAM 注意力机制能够帮助网络更敏锐地捕捉小麦籽粒间的微小差异,通过提取和强调重要的特征,CBAM 注意力机制能够使网络更好地区分小麦籽粒的类别。
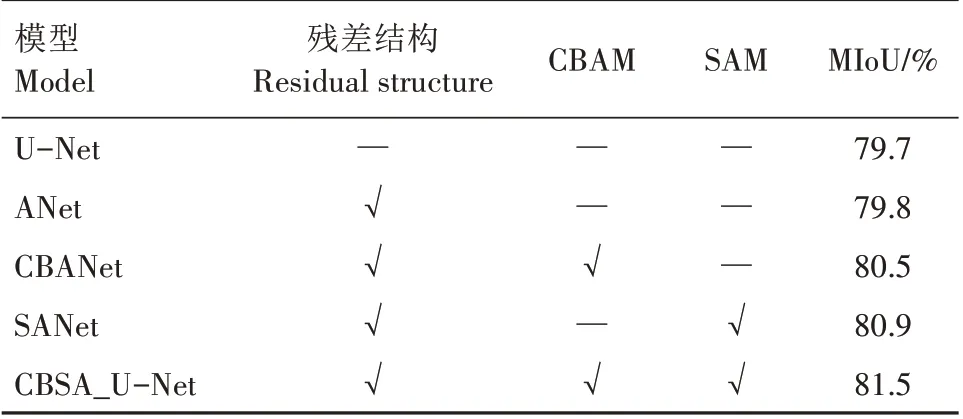
表3 消融试验的分类精度Tab.3 Classification accuracy of ablation experiment
本研究在模型改进过程中还加入了自注意力机制,加入自注意力机制的SANet模型相比原始UNet 模型精度提升了1.2 百分点,自注意力机制在解码器部分帮助网络更好地理解小麦籽粒的整体结构和上下文环境来恢复小麦籽粒的细节和形状;通过计算特征之间的相似性,增强重要特征的表示,并抑制不相关的特征,这使得解码器更好地捕捉小麦分类任务中的关键特征,提高分类准确性;在解码器中,某些细节特征可能与较远的上下文相关,自注意力机制可以通过学习特征之间的依赖关系,使网络能够更好地捕捉小麦籽粒的边缘或纹理信息这些长距离的依赖关系,从而提高小麦分类的性能。自注意力机制在U-Net网络的解码器部分对于小麦分类任务具有重要作用。它可以通过上下文信息建模、特征融合和长距离依赖建模等方式,增强解码器对小麦籽粒特征的感知能力,提高分类准确性,并帮助网络更好地理解小麦籽粒的形状、纹理和上下文环境。
由图9 可以看出,加入了双注意力机制模块的CBSA_U-Net 模型相较于U-Net 模型在790、805、810 g/L 3 种小麦籽粒的分割精度上都有明显提升。3 种小麦之间大小、纹理差别较小,CBAM 注意力机制在通道和空间上帮助网络更好地集中于小麦的最相关特征通道上,自注意力机制模块通过特征融合和长距离依赖建模,增强对小麦籽粒特征的感知能力,进而提高分类准确性,故加入双注意力机制后提升效果明显。结合图9 可以看出,加入CBAM注意力机制的CBANet对790 g/L和805 g/L 2种小麦籽粒分割精度有较大的提升,原因是这2 种小麦特征、纹理相对清晰明显,加入注意力机制后提升了模型对特征的提取能力,从而提高了分割精度。
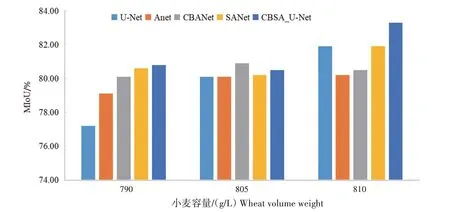
图9 不同模型在3种小麦籽粒上的分割精度Fig.9 The segmentation accuracy of each model on three kinds of wheat grains
3 结论与讨论
在小麦的质量等级检测中,利用深度学习方法进行小麦籽粒的识别检测是一种新的趋势,其中主要挑战是小麦籽粒目标较小且特征不明显。为了解决上述问题,本研究通过搭建图像采集平台,采集不同等级的小麦籽粒图像。在图像采集过程中,特别注意避免小麦籽粒之间的相互粘连,以确保采集到清晰的、单独的小麦籽粒图像。这有助于提供更准确、可靠的训练数据,为模型的训练和性能评估提供基础。通过优化图像采集过程,可以获得更具代表性的小麦籽粒图像数据集,有助于提升模型对小麦籽粒的识别和检测能力。这为进一步改进和优化基于深度学习的小麦质量等级检测方法奠定了基础,并为实际应用中提供了更可靠的检测结果。
本研究中小麦图像有25 395个训练集、3 174个验证集和3 174 个测试集。结合小麦籽粒目标小、特征不明显的问题,比较了PSPNet、DeepLabv3+、U-Net 的优势和缺点:PSPNet 采用金字塔池化的方法,将不同尺度的特征图进行池化和拼接,这样会导致一些细节信息丢失,特别是在处理小目标时容易出现分割不准确的情况。改进后的U-Net在特征提取时主干结构采用残差堆叠模块对局部特征进行初步提取,减少了小目标在下采样过程中损失的特征,这有助于提高对小麦籽粒的分割准确性;DeepLabv3+ 采用 ASPP(Atrous spatial pyramid pooling)的方法来融合多尺度特征,但是只考虑了不同尺度的特征融合,没有考虑不同层次的特征融合,导致模型对于一些细节信息的分割效果不理想。改进后的U-Net在输出的初级特征图之后嵌入CBAM 注意力机制,从通道和空间位置以自适应地调整不同像素点的特征融合权重,从而更好地提取小麦籽粒的细节信息,进一步增强分割性能;U-Net在解码器部分通过上采样和跳跃连接来恢复之前被压缩的特征图,但是这种方式会导致分辨率的降低,影响模型的精度。改进后的U-Net 在解码器部分中嵌入自注意力模块,通过减少对外部信息的依赖,更多地捕捉特征的内部相关性,加强上下文之间的联系,还原细节信息,从而实现更精确的小麦分割。通过对不同模型的分析和改进,本研究旨在提高小麦图像分割的准确性和效果,为小麦质量等级检测方法的发展做出贡献。
尽管本研究提出的方法在小麦籽粒分割方面表现出较快速和准确的特点,并具备实际应用的价值,但在将该方法真正应用于市场时仍然面临一些困难。首先,为了实现小麦籽粒的分割,需要配置适当的检测设备。这包括高质量的图像采集设备和计算资源,以确保能够捕捉到细微的小麦籽粒特征,并进行高效的图像处理和分割。其次,搭建大型图像采集平台是一个复杂而昂贵的任务。为了获得具有代表性的数据集,需要建立一个完善的采集系统,以确保小麦籽粒的不同等级能够得到准确的标注和分类。这涉及到人力资源、设备投资和数据管理等方面的挑战。分割、检测和识别的速度和准确率也是应用面临的问题。尽管本方法在速度和准确性方面取得了一定的改进,但仍需要进一步提高算法的效率,以满足实时应用的需求。此外,计算结果的呈现方式也需要考虑。在将小麦籽粒的分割结果用于质量等级划分时,应该结合多视角图像采集的信息,提高识别的精度和可靠性。为了克服这些困难,应严格构建更大规模的不同等级小麦籽粒数据集,并提高数据的标准化水平。此外,还可以将传统的分割方法、语义分割方法和实例分割方法深入结合,以应对更复杂的分割情况。最终的目标是实现小麦籽粒的高精度、快速和准确的分割,为小麦质量等级划分提供科学依据。这需要不断优化算法,并继续开展研究,以推动该领域的发展和应用。
