一种知识网络个性化检索方法
2023-11-14贾金娜JIAJinna
贾金娜 JIA Jin-na
(西安工商学院,西安 710032)
0 引言
当前随着信息化手段的普及和运用,高校在教学过程中不断产出海量的数据和信息,已经形成规模化的知识网络。网络中拥有海量的传统数据库、报表、文档、多媒体等资源,但普遍存在数据分散管理、知识挖掘不足等问题,教职员工和学生针对性检索能力还比较弱。因此,需要一种针对个性化检索需求的方法,解决当前检索效率低下问题。
1 知识网络中资源之间关系及知识地图建模
在分析典型高校知识网络现状基础上,系统分析各类知识资源节点属性,将其主要关系归纳为组合、聚合、继承、依赖、属性关联、类别关联、推理关联、关键词关联、目录关联、行为关联、自关联等,如图1。例如,组合关系是指知识整体和部分之间的关系,整体和部分不可分割,如学生整体成绩与其单科成绩之间的关系;行为关联关系是指用户特定行为所涉及的知识资源之间的关联关系,如学生搜索“Python 工具”时,往往同时检索“*.py”,这两种知识之间存在行为关联关系。这些关系是知识网络中的边集合(关系集合)ESet={e1,e2,…,em}的具体取值。同时,使用XML Schema 作为中间层,可构建出知识的层次化地图模型(如图2),在此模型中:
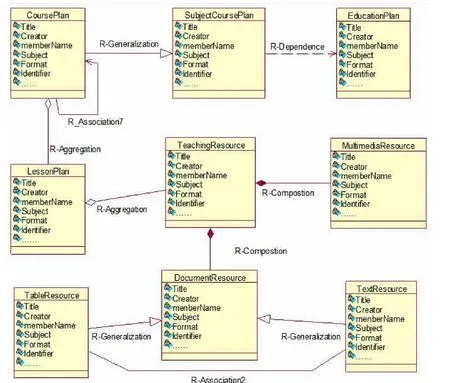
图1 知识资源间的主要关系
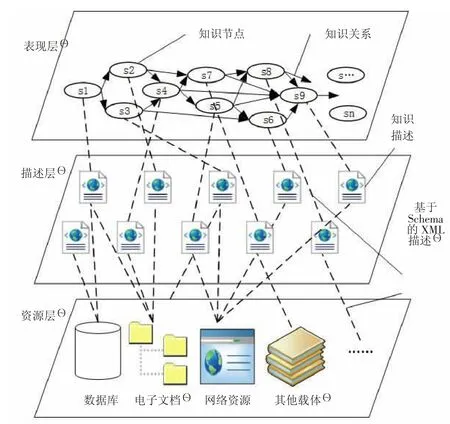
图2 层次化知识地图模型
①资源层,即各种实体,例如各种DB 二维表,doc、mp4 等不同后缀的文件;
②表现层,即基于上述关系的可导航的地图模型,其中资源即节点,连接即关系;
③描述层,即实体为数据(Data)文件,以XML 描述形成业务(Business)文件。
2 基于Schema 的知识网络结构树建模
将知识网络形成的结构树以XML Schema 进行规范,形成其描述文件KRP-t,后续检索可以通过XML 文件中的各类Tag 进行。相关Tag 之间构成具体检索路径K-p:①K-p 为: KN1/KN2/…/KNi/KN(i+1)/…/KNn;②KN1、KN2、…、KN(n-1)∈KNSetE(节点集合),KNn∈KNSetE(边集合)∪KNSetA(属性集合),使得KNi 是KN(i+1)的父节点,则称KNn 是KN1 的上级,KN1 是KNn 的下级;③将这些点依次连接,即可构成一条从KN1 到KNn 的路径KR_Path(KN1, KNn)。若KRP-t 中存在一个节点序列{KR_TSeq:KRN1, KRN2,…, KRNi, KRN(i+1),…, KRNn},使得KRNi是KRN(i+1)的上级,则称该节点序列是从KRN1 到KRNn 的标签序列,记为KR_TS∈KRP-t。基于上述定义,可基于Schema 对其进行检索,如图3。
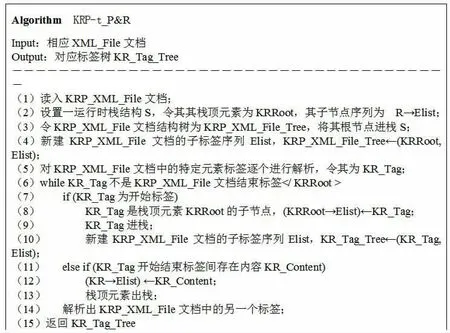
图3 XML 描述文件解析算法
3 知识地图层次化检索建模
将知识检索按照一般检索、复杂检索进行分类。一般检索类:
①对于简单检索项集合SW(S1, S2, …,Sm),如“Title = *.py”、“Subject = python 代码;管理系统”等,利用Boolean 运算实现。
②对于复杂检索项,借鉴前期同类研究成果,形成知识网络中基于知识地图的层次化检索模型如图4 所示。检索的主要流程包括:
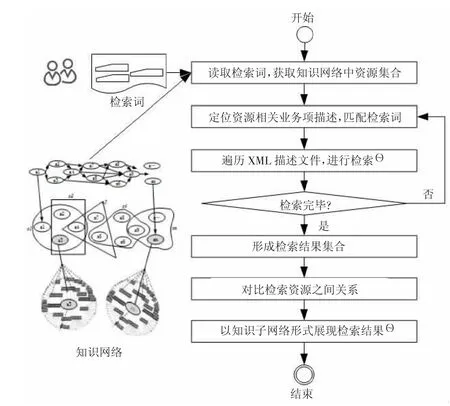
图4 知识地图层次化检索过程
1)对检索项汇总形成想要集合SW,汇总相应资源形成集合KR_Set;
2)查找到具体的实体资源文件所关联的业务项的描述文件,即可找到其对应的XML Meta-data 文档,按照简单检索模式查找其对应的资源;
3)基于KRP_t_P&R 算法解析XML 文档,通过遍历各标签生成对应XML 文件的标签树KR_Tag_Tree,获取Tage 对之内的字符串,构建生成待检索的文本集合,按照文本匹配等简单检索方式对其内容进行查找定位;
4)在检索完所有XML 文件后,形成一个检索的结构矩阵;
5)对比所有检索结果之间对应的不同关联关系,即可获得一个按照特定关系形式组合的文件资源对之间的网络,最后以集合形式进行存储即完成所有工作。如图5 所示。

图5 XML 描述文件中关键词搜索算法
4 基于关联规则的知识排序推荐模型
用户的直接需求(如以检索词、订阅关键词等形式)和间接需求(来源于知识节点的潜在关系)决定了知识推荐的表现形式。笔者所提出的知识推荐方法是“以检索词检索+以规则关联”。在不同的检索需求下,可基于用户个性化检索词进行知识推荐形成知识资源集合,对比整个知识网络,筛选出相应的知识子网络。基本实现过程为“文件预处理→基于向量空间进行表征→基于改进N-Gram 进行分词→基于多属性融合方法选取特征→基于改进Apriori 算法分析关联规则→进行推荐给出结果”。这里重点对其中的文本分词、特征选择和关联规则等关键步骤进行分析和设计:
①基于预切分改进设计N-Gram 方法。针对Gram 方法中Gram 数量偏大、部分无实际意义等问题,使用预切分方式对其进行改进,具体步骤是:
1)用StopWordsList 切分文本,形成由不同长度的字串组成的集合U0,将每个词的词频记入词频表集合W;
2)将U0按长度2、3、…、k-1 进行分类,形成集合U1、U2、…、U(k-1);
3)对U2中的每个字串直接切分为两个长度为2 的字串,并将结果合并到集合U1,同时更新相关字串的词频;
4)对U3、…、U(k-1)继续切分,形成相应的集合并将每个字串的词频记入W;
5)将U1、U2、…、U(k-1)取并集得到U,归并U 中相同字串,更新W 中词频;
6)应用“长词优先”的原则对U 中的冗余字串进行消减(即一个短词含在一个长词之中,则将其减去),并更新W 中字串的词频。
7)输出特征项集合U 和W。
②基于多属性融合的文本特征选择方法。按照相关文献提出的文档频、特征项词频、特征项词性、特征项在文本中位置等多种属性,按照W(f)=a×Wdf+b×WF+c×WP进行文本特征的选择。其中:
1)W(f)表示特征项f 的综合权重。a、b、c 分别表示三个属性值的权重系数,其取值范围为(0,1),且满足a+b+c=1。
2)Wdf为特征项文档频属性值,其值是集合里具有某特征项的文本数量与总数n 之比,Wdf∈(0,1)。
3)WF为特征项词频属性值,分词过程中进行特征项频率统计,可获取到不同特征项词频,令其取值为Nd,具体特征项的WF=TotalNd/TotalNdmax。
4)WP为特征项词性属性值,对文档中其关键作用的名词、动词、形容词、副词外的其他进行剔除,如某文档集合中名词所占比例数值为Pmax,且在四类词中占比最高,设P 为某特征词所属词性占比值,则WP=P/Pmax。
③基于改进Apriori 算法的文本关联规则提取方法。将上述集合存储到关系数据库(或表格文件)之后,对其进行关联规则分析和提取。关联规则的提取主要步骤如下:
1)找出事务库中所有大于等于最小支持度的频繁项集。
2)利用频繁项集生成所有的关联规则,根据预先设定的最小置信度进行关联规则的取舍,最终得到强关联规则。
④检索结果推荐按照上述关联关系,将指定范围内“item→item”形式的关联规则所对应的文档进行关联,自动关联到相应类别中,并可由相关用户需求修订该类别,为形成知识网络提供输入。上述规则中,按照置信度和最小支持度进行选取,截取长度为N 的序列,形成Top-N 知识规则,即可直接访问到这些规则中后项所对应的知识资源。
5 结语
本文通过对知识网络中的节点关系进行分析,构建了包含资源层、表现层和描述层的层次化知识地图模型,设计了基于XML Schema 的知识结构树模型及其检索方法,基于关联规则设计了一种个性化的知识资源网络检索方法,为知识网络信息个性化检索和推荐奠定了方法基础。
