基于特征选择的GDP 预测研究
2023-11-14程伟CHENGWei余蓓敏YUBeimin
程伟 CHENG Wei;余蓓敏 YU Bei-min
(安徽电子信息职业技术学院电子工程学院,蚌埠 233040)
0 引言
国内生产总值(GDP)是一个国家或地区反映国民经济发展变化情况的核心指标,做好GDP 预测对地方国民经济发展规划及制定各行各业的发展计划具有指导性作用。目前,预测GDP 变化趋势主要有ARIMA 模型[1]、人工神经网络[2]和粒度理论[3]等方法,但利用特征选择预测GDP 变化的却鲜见。
近年来,机器学习和数据所涉及的数据维度呈爆炸性增加,机器学习算法中的训练集包含着许多冗余或无关的特征,这会导致预测模型的复杂化并增加训练的时间。特征选择旨在相关特点中选择或提取一部分最重要的特征子集作为算法的实际输入特征,以求带来更好的学习表现,缩短训练时间,改善模型的通用性,降低过拟合,提高预测准确度等等。因此,特征选择及降维技术成为了机器学习和数据挖掘的一个重要分支和研究领域[4]。本文基于特征选择的方法,利用稳健深度自动编码器(robust deep autoencoders)对地方国内生产总值变化趋势进行了预测。
1 基于特征选择方法构建预测模型
1.1 设计思路
模型设计包含特征选择与预测两大模块。
特征选择模块的目标是探索特征提取方法来优化预测模型并缩短训练时间。
预测模块的主要目标通过结合特征选择模块的输出,来提高预测算法的准确性和可靠性,以获得最佳的预测结果。
在实验阶段对特征选择技术及机器学习算法的交叉应用进行研究分析,从而提炼出最佳组合方法,如图1。

图1 核心模块示意图
1.2 特征选择模块
特征选择主要有稳健的深度自动编码器、灰色关联法[5]等机器学习方法得出最优的特征选择方法。下面主要介绍稳健的深度自动编码器特征选择方法。
1.2.1 自动编码器
自动编码器是一个基本的三层神经网络。输入数据通过一对编码和解码阶段,自动编码器能够捕获隐藏层输入的抽象表示,并重构输出层的输入数据。
其中X 是输入数据,E 是从输入数据到隐藏层的编码映射,D 是从隐藏层到输出层的解码映射,是输入数据的恢复版本。CE 自编码的目标是训练E 和D,使X,之间的重建误差最小化[6]。因此,一个自动编码器可以看作是以下优化问题的解决方案:
1.2.2 深度自动编码器
自动编码器由于其简单的浅层架构,其表示能力是有限的。一个具有多个隐藏层的自动编码器被称为深度自动编码器[7],每一个额外的隐藏层都需要一对额外的编码器E(·)和解码器D(·)。针对高维输入数据,深度自动编码器通过一对对编码和解码阶段从输入到自身学习映射:
其中X 为输入数据,深度自编码器为2n+1 层,共n个编/解码阶段,Ei(i=1,…,n)是从输入数据到隐含层的编码映射,Di(i=1,…,n)是从隐含层到输出层的解码映射,而为重新获取的新的输入数据。通过允许许多层的编码器和解码器,深度自动编码器可以精确地表示输入X 上的复杂分布。
1.2.3 稳健的深度自动编码器(robust deep autoencoders)
根据稳健主成分分析(RPCA)的思想,在深度自动编码器中加入异常正则惩罚项,由此构成稳健深度自编码器[8]。通过加入正则化,稳健自编码器不仅保持了深度自编码器发现高质量、非线性特征的能力,还可以降低特征维数,只提取最有用的特征进行数据预测,因此稳健深度编码器的输出比输入能更好地理解数据特征。学习到的稳健自编码器的特征可以作为另一个机器模型的输入,如支持向量机、神经网络或随机森林,用于数据预测。
在稳健的深度自动编码器中加入一个过滤层,将难以重构的数据中的异常值和噪声值与剩下的数据分离开来,剩下的数据可以用低维隐层来表示。输入数据可表示为:
其中LD表示自编码器隐含层中能很好地表示输入数据特征的部分,S 包含噪声和难以重构的异常值。
其中Eθ(·)表示编码器,Dθ(·)表示解码器,λ 是一个调整S 稀疏度的一个参数。通过这样做,稳健深度自编码器对训练数据集中的异常值和噪声是鲁棒的。利用稳健深度自编码器的隐层进行数据特征选择,可作为预测模块的输入数据,通过支持向量机(SVM)等预测方法进行数据预测。
1.3 预测模块
将选择的特征作为输入提供给预测模块,通过使用验证数据集进行训练和优化,将得到一个含有深度分类器的预测模型。与传统预测模型相比,深度分类器可以更快发现高级特征,缩短训练时间,降低过拟合,改善模型的通用性,由此来提高预测算法的准确性和可靠性。
线性回归(LR)是[9,10]预测中应用最广泛的回归模型之一。它将预测模型与目标变量的观测数据集相拟合以进行预测和相应的特征。支持向量机(SVM)[11]最初用于解决一个二值分类问题,通过构造一个决策平面来分离边界最大的二值分类。支持向量机既可以解决分类[12]问题,也可以解决原理相似的回归[13]问题。神经网络(NN)是由神经元组成的多层网络,通过非线性激活函数来学习输入和输出之间的非线性关系。神经网络在训练过程中使用梯度下降法,试图寻找更适合数据的系数,直到得到模型预测[14]的最优权值。
随机森林[15,16]通过在训练时构造多个决策树,并输出单个决策树的平均预测来进行回归分析。随机森林是一种套装技术,在树之间没有相互作用,因此生成预测时无相互影响。
2 案例研究
2.1 模型及数据
本案例的预测模型通过稳健的深度自动编码器(Robust Deep Autoencoder)来选择最有用的特征,然后利用随机森林(RF)算法对按收入法构成的安徽生产总值(GDP)进行预测。
数据集包括2005-2019 年安徽生产总值(GDP)及按行业、产业和收入法构成的28 个相关因素。本案例以安徽生产总值为系统属性,将行业、产业和收入法构成的28 个相关因素作为一系列相关的特征,由此构成相关的数据集,如表1。其余年份的数据作为训练集,经稳健的深度自动编码器来选择最有用的特征,利用随机森林(RF)算法预测2014-2016 年的安徽生产总值(GDP),其结果如表2。
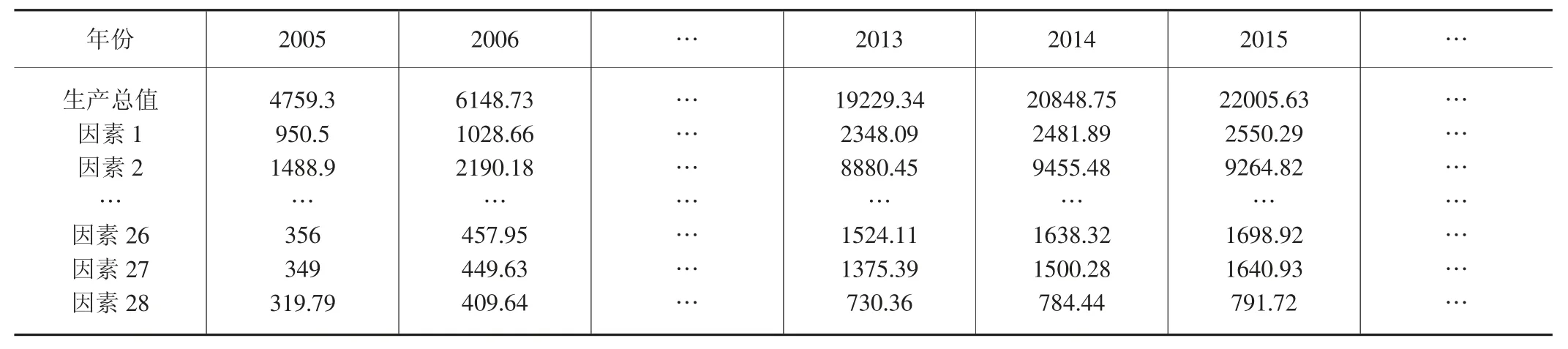
表1 2005-2019 年的安徽生产总值 单位:亿元
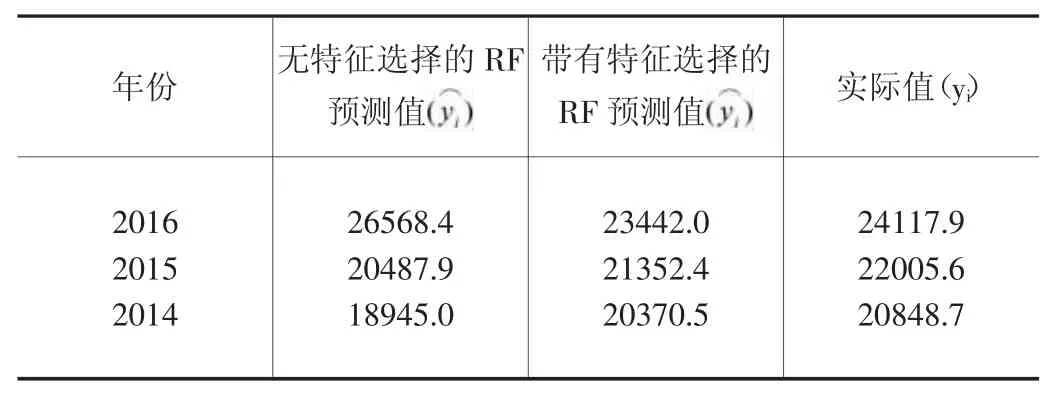
表2 用随机森林(RF)模型预测GDP
其中yi,分别为实际数值和预测数值。
2.2 数据分析
表2 将2014-2016 年安徽生产总值(GDP)预测结果与基于稳健的深度自动编码器的特征选择方法的有效性进行对比。从表2 中可以看出,使用特征选择后的随机森林(RF)预测的安徽生产总值(GDP)与实际数值更加接近,证明了特征选择步骤的重要性。
表3 对随机森林(RF)预测模型误差进行分析。其中包含均方根误差(RMSE)绝对数值分析,希尔不等系数(Theil IC)和平均绝对百分误差(MAPE)相对数值分析[17]。如果平均绝对百分误差的值小于10,希尔不等系数数值小,则认为预测模型可行。而带有特征选择的随机森林(RF)预测模型得到的MAPE 值为2.688162,其值较小且小于10,说明其模型预测精度较高。从表3 看,带有特征选择的RF 预测模型的希尔不等系数值为0.013799,比无特征选择的RF 系数小,且远远小于1,说明此模型的预测准确度较高。同时带有特征选择的RF 预测模型的均方根误差的值为608.875,也比无特征选择的RF 均方根误差小。
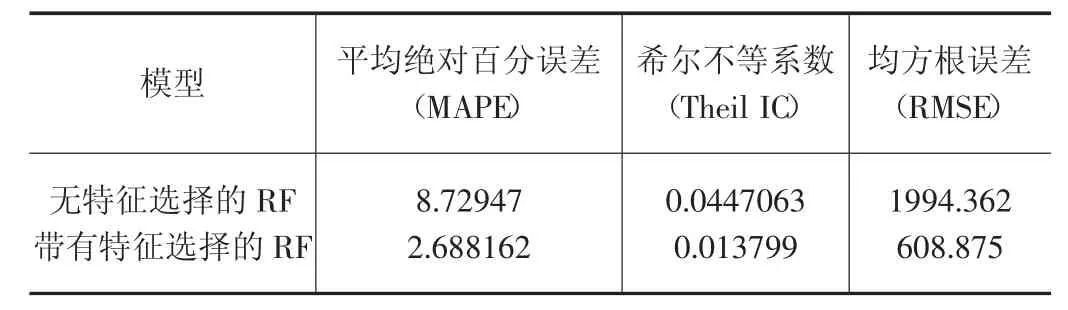
表3 随机森林(RF)模型预测误差比较
综上所述,通过对安徽生产总值(GDP)预测模型的分析,验证了深度自动编码器的特征选择方法在安徽生产总值(GDP)预测中的有效性。
3 结语
提出了一种基于特征选择算法的GDP 预测模型。该模型主要由特征选择模块和预测模块组成。通过计算系统属性与特征属性之间的关联,只有相关性最高的特征属性才能被保留。然后,将选取的特征属性作为输入数据进入预测模块进行预测。以安徽省的生产总值(GDP)为案例,对预测模型进行了验证。结果表明,通过利用提出的特征选择方法选择有用的特征,对GDP 进行预测可显著提高预测模型的准确性和有效性。
