基于MCMC和ES-MDA方法的地下水数值模型非均质参数场及开采量的反演研究
2023-11-11刘墉达孟详博刘维翰黄日超
刘墉达,陈 喜,高 满,孟详博,刘维翰,黄日超
(天津大学 地球系统科学学院 表层地球系统科学研究院,天津 300072)
1 研究背景
对于复杂的多层含水层,根据有限的地下水水位等观测数据,反演水文地质参数、开采量等通常存在不唯一性、不确定性问题,且在调用地下水数值模型进行参数反演时,随着调用次数和参数维度增加,反演计算成本变高。解决这些问题对提高地下水数值模拟精度、增加地下水资源开发利用评估的可靠性具有重要意义。
模型参数调试和反演方法早期较多采用试错法。随着计算机发展,基于最优化理论的确定性和随机优化方法得到快速发展。相对而言,梯度下降法等确定性寻优方法对参数初值要求较高,优化结果容易陷入局部最优解。随机优化方法推求参数的概率分布,特别适用于解决多参数反演问题[1-2]。如采用蒙特卡罗方法在参数变化范围随机抽样,构建马尔科夫链生成参数样本集合,即马尔科夫链蒙特卡罗方法(MCMC),可以处理高维参数空间和模拟非线性问题,因此被广泛应用于地下水数值模型参数反演。Yan等[3]基于MCMC算法对理想均质含水层非稳定流下的污染源位置和污染物泄露时间进行了反演;李雪利等[4]以二维非均质含水层区域为研究算例,基于MCMC方法反演了地下水污染源,且对比了MCMC不同建议分布对参数反演结果的影响。MCMC方法需要多次调用地下水数值模型,随着待反演参数增多,地下水数值模型调用次数随之增加,产生较高的计算代价。
近年来发展的替代模型(Surrogate model),通过构建一个拟合函数(如克里金法[3,5](Kriging)、径向基函数法[6-7]、支持向量机[8-10]、多项式混沌展开[11]以及贝叶斯网络[12]等),模仿复杂的物理模型输入-输出过程,可大幅减少计算成本。其中,Kriging法采用回归多项式的确定性分析和不确定随机分析,描述全局和局部的统计特性,建模方便、精度较高。Yan等[3]针对理想均质含水层,采用Kriging法建立了非稳定流数值模型的替代模型,验证结果表明建立的替代模型具有较高精度。替代模型与MCMC结合可提高参数优选的计算效率,如张江江[13]采用自适应稀疏格子插值法构造了替代模型,并与MCMC结合优选监测井分布、反演模型参数。
另一种参数反演途径是数据同化,通过融合观测数据与模型预测值信息,自动调整模型参数、状态和运行轨迹,实现对模型参数的反演估计[14]。常用的数据同化方法包括集合卡尔曼滤波[15](EnKF)、集合平滑器[13](ES)和多重数据同化集合平滑器[16](ES-MDA)等。EnKF使用当前时刻观测值对上一时刻的参数和状态进行更新的实时算法,需要多次调用地下水模型,计算过程较为繁琐,且EnKF对模型参数和状态同时更新,可能导致更新后的参数和状态的不一致性。ES作为一种批处理算法,一次性使用所有时刻的观测值更新模型参数和状态,且只更新参数以避免参数和状态的不一致性。ES-MDA通过多次迭代进行数据同化,可有效地避免了观测数据过拟合,具有调用模型次数少、计算成本低的优点。陈冲等[16]基于MODFLOW构建的黑河流域中游地下水模型,使用ES-MDA方法反演了模型中13个参数最优取值,对比了ESM-DA不同超参数对反演结果的影响。周念清等[17]利用ES-MDA方法融合高密度电阻率法采集的观测数据,实现了对污染源参数和渗透系数场的联合反演。然而ES-MDA也存在不足,如敏感度低的模型参数反演精确度低。
目前常用的地下水数值模拟软件一般包括GMS、Visual MODFLOW和FEFLOW等。这些软件具有较为实用的交互界面,可以直接在图形界面构建模型,由于它们无法与优化算法直接耦合,在过去的研究中更多倾向于先优化后模拟,即先选出待优化参数的可能取值,再将参数输入地下水模型进行验证,还有研究采用松散耦合进行参数反演[18]。这些方法无法利用计算机内存在优化算法和模型之间快速共享数据,极大地降低了计算速度和求解效率,FloPy[19]是由Mark Bakker等基于Python编写的第三方库,可以和其他优化算法紧密耦合反演地下水数值模型参数。
针对地下水数值模型和参数反演各方法的优缺点,本文以复杂三维含水层(潜水、承压水)为案例,假设某一含水层渗透系数为异质性空间变化场,在各含水层开采量未知情形下,建立地下水数值模型和基于Kriging方法的替代模型,模拟含水层分层地下水水头变化,建立基于替代模型的MCMC、替代模型和数值模型相结合的两阶段MCMC以及ES-MDA反演方法,对比各方法对参数和随机场反演精度,为复杂含水层参数反演方法的选择提供借鉴。
2 研究方法
2.1 地下水数值模拟及参数反演问题对于潜水、承压为水多层含水层,地下水流运动的一般表达式为:

(1)

根据监测井地下水水位的观测值,记为d=(d1,d2,…,dn),以模型模拟值F(θ)与观测值d之间误差(ε=d-F(θ))为目标函数,推求ε最小时的模型参数θ(如K等),即为参数反演问题。
2.2 随机参数场的Karhunen-Loève展开对于某一非均质孔隙介质含水层,如渗透系数K值空间变化,形成参数反演的高维问题。相比于裂隙和岩溶介质显著的非均质性,孔隙介质在一定尺度上可以认为相对连续并具有自相关性。对此,可利用Karhunen-Loève(K-L)展开[20],将K值的空间变化表述为确定性函数和随机场的线性叠加,以达到降低维度,即:
(2)

在地下水数值模拟中,K的自然对数(lnK)的协方差函数C(S1,S2)服从指数分布,即任意两点(S1和S2)满足:
(3)
式中:η1和η2分别为x和y方向上的自相关长度;σ2为方差。

(4)
式中:G(θ)为θ的已知全局函数;Z(θ)为高斯随机函数,为系统局部偏差,其满足E(Z)=0,Var(Z)=σ2,且任一两点Z(θ)的相关函数可表示为:
cov[Z(θ(i)),Z(θ(j))]=σ2R(θ(i),θ(j))
(5)
式中:R(θ(i),θ(j))为任意两个样本之间的协方差函数(常用有线性函数、高斯函数、指数函数等)。
Kriging替代模型实现步骤如下:
(1)建立模型输入(参数θ)-输出(水头y)集合。在各参数先验分布上抽取N组样本作为输入集合,调用地下水数值模型,模拟每个监测井不同时段水头值y作为样本输出集合。
(2)Kriging替代模型训练。将步骤(1)样本的输入和输出集合代入替代模型进行训练,建立每个监测井的水头替代模型

2.4 参数反演方法
2.4.1 贝叶斯方法 从观测数据中推断出未知参数的可能取值,即后验概率分布p(θ∣d)表述为:
(6)
式中:θ为待反演的参数;d为地下水水头观测值;p(θ)为θ的先验概率密度函数;p(d∣θ)为似然函数,表示模拟值与观测值d的接近程度;p(d)为归一化积分常数。
通常根据野外调查、试验等信息得出参数某一取值范围,并假设其服从某一分布,即参数的先验分布p(θ)。假设模型中未知参数共有n个,即θ=(θ1,θ2,…,θn),服从均匀分布,则参数θi的p(θ)为:
(7)
式中ai、bi分别为参数θi先验分布的下限和上限。
如果各参数独立,总先验分布P(θ)可定义为:
(8)
根据水头观测值d与模拟值F(θ)之间的总误差(ε=d-F(θ)),假设ε=(ε1,ε2,…,εn)服从n维高斯分布,得出ε的条件概率密度函数(似然函数)p(d∣θ)为:
(9)

由于p(d∣θ)计算中需要调用正演模型F(θ),当参数维度较高时,一般无法得到p(θ∣d)的解析解。可采用基于MCMC的概率抽样方法和ES-MDA数据同化方法,推求p(θ∣d)的统计量(如均值、标准差等),当作参数反演问题的解。
2.4.2 基于MCMC的参数后验分布求解 MCMC通过随机采样构建一个马尔科夫链,当马尔科夫链收敛后的采样就相当于在后验分布p(θ∣d)上抽取样本,利用样本的统计量就可以得到参数均值和标准差。
常用实现MCMC方式是Metropolis-Hastings(M-H)算法[21],其基本思想是通过构造一个接受-拒绝准则,以保证采到的样本服从参数后验分布p(θ∣d),具体步骤如下:
(1)初始化参数。采用蒙特卡罗方法,随机生成一组参数初值θi,i=0;
(2)生成参数的候选值。从建议分布(如正态分布)q(θ)中随机生成一个候选值θ*。
(3)计算接受概率:
(10)
式中:log(p(d∣θ))为对数似然函数;在建议分布为正态分布时,q(θi,θ*)=q(θ*,θi)。
(4)接受或拒绝候选状态。从均匀分布U(0,1)中抽取随机数u,若u≤α(θi,θ*),则令θi+1=θ*,否则令θi+1=θi。
(5)令i=i+1,返回步骤(2),重复多次,直到采样得到足够的参数样本。
2.4.3 基于ES-MDA的参数后验分布求解 ES-MDA在每次迭代中对观测误差引进一个膨胀系数αi,以较低的计算代价解决高维非线性的参数反演问题,便于实现多次数据同化。具体步骤如下:
(1)给定数据同化次数Na,集合样本N,第i次数据同化时的膨胀系数αi,其中αi满足:
(11)
(2)根据各参数的先验分布p(θ)抽取N个样本,组成初始参数集合θ1:
θ1=[θ1,1,θ1,2,…,θ1,N]
(12)
(3)初始i=1,对集合中每个样本进行正演模型计算,得到模拟值集合:
di,j=F(θi,j),j=1,2,…,N
(13)
(4)对样本参数集合进行更新:
(14)
θi+1,j=θi,j+CMD(CDD+R)-1(duc,j-di,j)
(15)
式中:dobs为观测值;duc为添加αi扰动后的观测值;z为修正引入服从高斯分布的随机误差;CMD为模型参数θi与模拟值di之间的协方差矩阵;CDD与R分别为模拟值和观测误差的自协方差矩阵。
(5)i=i+1,重复执行步骤(3)和(4)直到完成Na次数据同化,得到最终样本集合θNa=[θNa,1,θNa,2,…,θNa,N],以及参数的后验估计。
2.4.4 反演参数的精度评估 根据各参数的后验分布,统计各参数的均值及标准差。对比各参数均值与真值,两者越接近说明反演的参数误差越小;同时对比不同反演方法各参数的标准差,标准差越小,说明参数反演结果的不确定性越小。
对于反演的参数空间分布场,采用均方根误差(RMSE)和结构相似性指标(SSIM)作为评估依据,其定义如下:
(16)
(17)
式中:u和v分别为参数标准场和反演参数场;Np为网格个数;μ和σ分别为参数场均值和标准差;C1=0.01和C2=0.03是稳定计算的常数。SSIM的阈值范围为[-1,1],SSIM值越接近1,反演参数场与参数标准场越趋近一致。
3 研究算例
3.1 研究区及模型构建
3.1.1 地下水数值模型及参数设置 假定研究区为边长1000 m、厚度50 m的5层立方体,其中第1层为潜水含水层,第3、5层为承压含水层,第2、4层为隔水层。西部边界与东部边界为定水头边界,水头分别为10 m和5 m;北部边界与南部边界为隔水边界(图1)。

图1 研究区平面和剖面示意图
将研究区剖分为50行、50列、5层有限差分网格,单元边长为20 m、高为10 m,模拟期10 d,计算时间步长1 d,所构建的模型具有一定的代表性。在本案例中模型的不确定性来自第一层承压含水层非均质渗透系数场和5个开采井的开采量,其他参数给定,潜水含水层水平渗透系数(5 m/d)、第二层承压含水层水平渗透系数(4 m/d)、隔水层水平渗透系数(1×10-5m/d)、给水度(0.2)、入渗补给强度(1×10-6m/d)和承压含水层储水系数(1×10-4),假设垂向与水平向渗透系数比值为0.1,初始水头分布为开采量是0时的稳定流水头。
研究区内共有5个开采井(W1—W5)和10个监测井(O1—O10),其中W1—W3开采第一承压含水层,W4开采潜水含水层,W5开采第二承压含水层;O1监测潜水含水层水位,O2—O9监测第一承压含水层水位,O10监测第二承压含水层水位。本次研究开采井分散布设,以减少各开采井的相互影响。监测井布设在开采井附近,旨在捕捉开采井附近水头变化情况。
使用Flopy调用地下水数值模型MODFLOW,计算逐网格单元水头,选择10个监测井所在位置10 d逐日水头,作为参数反演的观测值。后续将10个监测井的模拟值与观测值的误差最小作为目标函数,使用基于MCMC和ES-MDA方法反演模型参数。
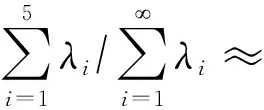

表1 参数的先验分布区间和真值

表2 开采井开采量 单位:m3/d

3.2 基于MCMC方法的参数反演为了权衡模型计算成本与反演精度,本研究对比基于替代模型的MCMC参数反演与两阶段的MCMC参数反演结果。前者在参数整个变化范围内抽取大数据样本(链条长度为50 000,且建议分布方差较大),基于替代模型的MCMC确定参数的后验分布;后者在前者基础上根据替代模型参数后验分布缩小参数取值范围(链条长度为10 000,且建议分布的方差较小),使用基于地下水数值模型的MCMC反演参数后验分布。假设误差ε服从正态分布ε~N(0,0.1),使用马尔科夫链接受采样中最后的1 000组样本,反演的各参数后验分布。
基于替代模型MCMC和两阶段的MCMC参数反演结果统计值见表3,以q1、q2、q3为例,反演的参数后验分布如图3。可以看出,两种反演方法得出的各参数均值与表1中参数真值十分接近。相对而言,两阶段的MCMC各参数均值与真值更为接近,且标准差更小,反演的后验分布峰值也更集中于真值。
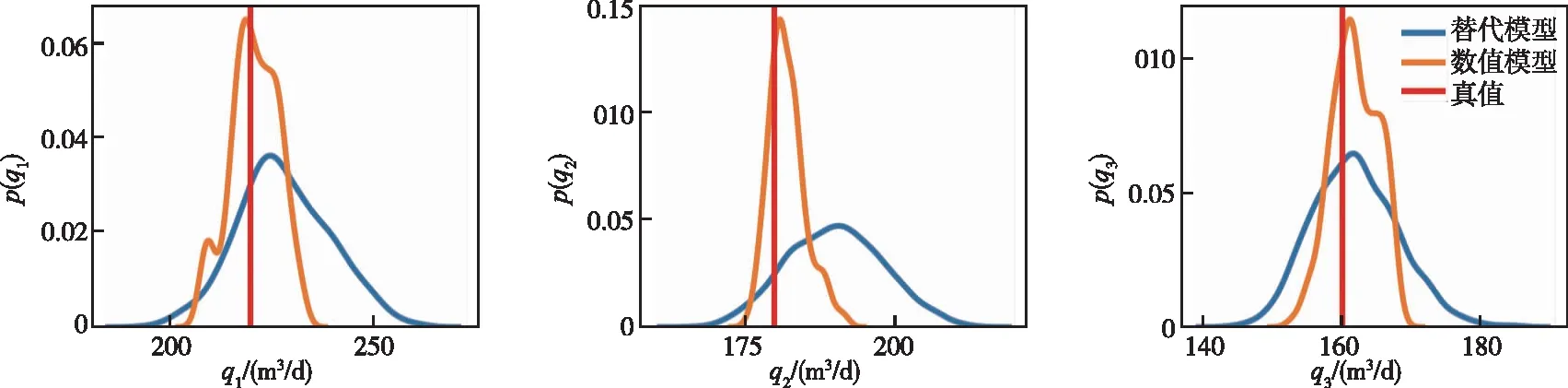
图3 基于替代模型的MCMC和两阶段的MCMC反演参数的后验分布
图4分别为(a)参数K3标准场、(b)反演前随机生成的初始参数场、(c)基于替代模型和(d)两阶段的MCMC反演K3参数场。基于替代模型和两阶段的MCMC反演参数场与参数标准场之间的RMSE分别为8.3×10-2和2.6×10-2;SSIM分别为0.88和0.98,两种方法反演的参数场都较为准确,但两阶段的MCMC反演的参数场精度更高。说明仅使用替代模型的MCMC参数反演,虽然计算费时少,但替代模型的误差影响反演参数值的可靠性。而两阶段的MCMC通过第一阶段缩小参数范围,第二阶段再调用数值模型,可在实现减小计算成本的同时提高反演参数的精度。
3.3 基于ES-MDA方法的参数反演在使用ES-MDA方法反演地下水模型参数过程中,存在某些超参数的选择(如同化次数Na、集合样本N、膨胀系数αi),直接影响同化算法对模型参数的更新效果。本文借鉴前人经验[16],取Na=2,N=100,α1=α2=2,采用模型参数的先验分布(表1),使用ES-MDA方法反演模型参数的后验分布。
ES-MDA两次同化反演参数结果的对比见表4,以q1、q2、q3为例,反演参数后验分布见图5。第一、二次同化反演结果各参数均值与表1中参数真值十分接近。但第二次同化各参数均值与真值更为接近,且标准差均小于第一次同化标准差,反演的后验分布峰值位于真值附近(图5)。
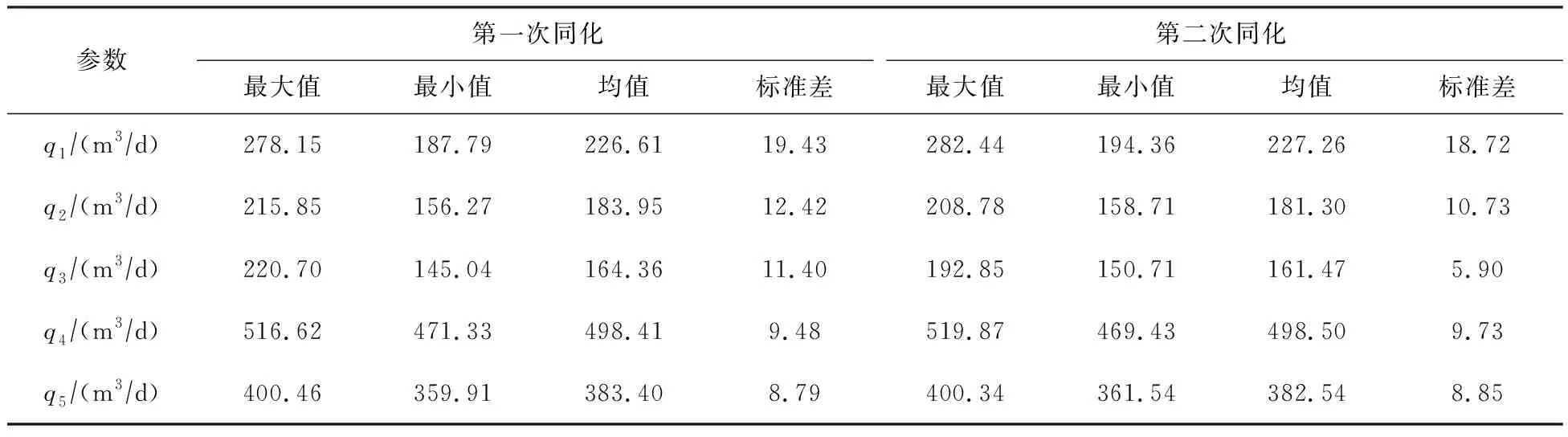
表4 ES-MDA两次同化模型参数统计值

图5 基于ES-MDA方法两次同化反演参数的后验分布
图6分别为(a)参数K3标准场、(b)反演前随机生成的初始参数场、(c)基于ES-MDA第一次、(d)第二次同化反演的参数场。两次同化反演参数场与参数标准场之间的RMSE分别为1.8×10-2和9.1×10-3,SSIM分别为0.93和0.96。两者都较为准确,且第二次同化反演参数场精度更高。说明增加数据同化次数可以增加ES-MDA方法的参数反演精度,第二次同化反演的后验分布更为精确。

图6 渗透系数场K3
3.4 正演模型验证在非均质参数场和开采量的校验后,还要进行正演模拟,用来验证预报水头场的能力。通过将基于两阶段的MCMC和ES-MDA所反演出的非均质参数场和开采量输入到地下水数值模型中,与监测井真实水头值和真实水头场进行对比。如图7所示,其中红色实线为真实水头,绿色虚线和蓝色点划线分别为基于两阶段的MCMC和基于ES-MDA参数反演后正演模拟得到的监测井水头。
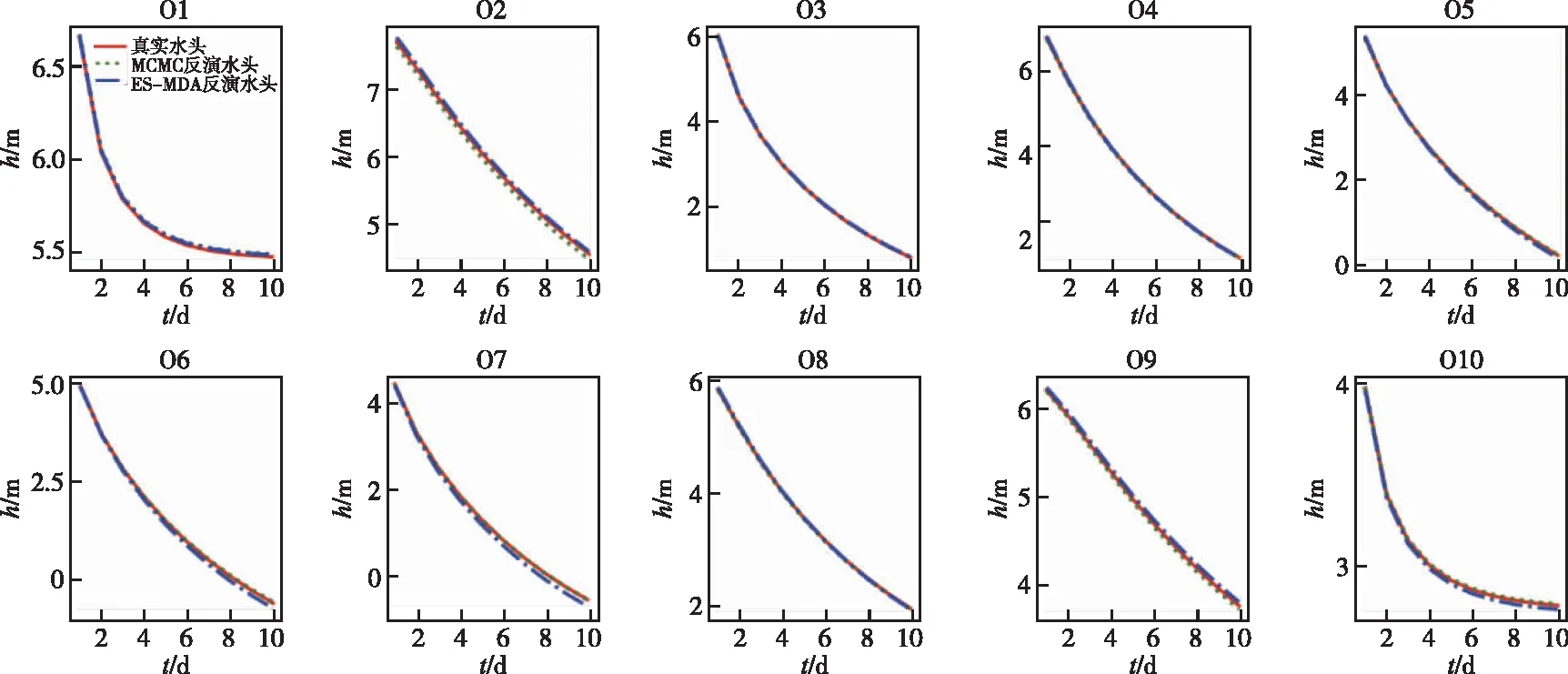
图7 基于两阶段的MCMC和基于ES-MDA反演后正演模拟得到的监测井水头与真实值的水头过程线
根据图7可以看出,基于两种方法反演的非均质参数场和开采量进行正演模拟的监测井水头过程线与真实水头过程线十分接近,两种方法都充分捕捉到了监测井位置的水头变化情况,说明监测井水头模拟效果较好。
图8—12展示了基于两种方法反演的非均质参数场和开采量在进行正演模拟不同时间节点的第一承压含水层水头场以及与真实水头场之间的误差。其中图8表示在同一个应力周期3个不同时间节点(3 d,6 d,9 d)的真实水头场。在相同时间节点,图9表示基于两阶段的MCMC反演后正演模拟得到的水头场,图10表示基于两阶段的MCMC反演后正演模拟得到的水头场与真实水头场的之间误差场。图11表示基于ES-MDA反演后正演模拟得到的水头场,图12表示基于ES-MDA反演后正演模拟得到的水头场与真实水头场的之间误差场。

图8 第一承压含水层真实水头场

图9 基于两阶段的MCMC反演后正演模拟得到的水头场

图10 两阶段的MCMC正演场与真实场之间的误差场
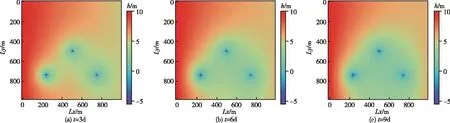
图11 基于ES-MDA反演后正演模拟得到的水头场

图12 ES-MDA正演场与真实场之间的误差场
由基于两阶段的MCMC和ES-MDA正演水头场与真实水头场的误差场可看出,基于两阶段的MCMC反演后在正演模拟水头场误差较小,误差值基本控制在0.1 m以内。基于ES-MDA反演后在正演模拟水头场效果一般,在开采井附近误差较大,误差值可达到0.4 m,局部水头场模拟与真实水头场相差较大,这与ES-MDA对开采量反演精度较低有关。两阶段的MCMC反演准确度更高,而且更为均匀,在不同时期对水头场的模拟都相较于ES-MDA更为准确。
3.5 不同反演方法结果对比分析对于开采量(q1—q5)反演结果,不同方法反演的参数后验分布,均值及峰值均接近真值;从非均质产生的高维渗透系数K3场反演精度来看,与K3实际分布相比,不同方法都能较好地反演出参数随机场的空间分布,RMSE都较小;以SSMI为评价指标时,基于替代模型的MCMC方法、ES-MDA方法反演的参数场精度低于两阶段的MCMC反演参数场精度。说明先使用替代模型的MCMC反演缩小参数场分布范围,再调用地下水数值模型,可调和复杂模型参数反演中降低计算成本与提高反演精度之间的矛盾。
对比计算成本,基于替代模型的MCMC方法需要先调用1000次数值模型用于训练Kriging替代模型,再调用50 000次替代模型进行后验分布采样;两阶段的MCMC方法还需再调用10 000数值模型进行MCMC精确采样;而ES-MDA方法仅设定2次同化次数,集合样本为100,总共调用数值模型次数为300(1个初始集合加2个同化集合)。因此,ES-MDA方法计算效率更高,而两阶段的MCMC方法计算效率较低。由此可见,在进行地下水数值模型参数反演时,可以根据参数反演精度和计算效率要求,选择合适的反演方法。
4 结论
基于设定的多层含水层水文地质条件,建立了地下水数值模型和Kriging替代模型。基于贝叶斯理论,使用随机抽样的MCMC算法和数据同化的ES-MDA算法,反演模型非均质渗透系数场及开采量。对比替代模型-MCMC方法、替代模型-地下水数值模型的两阶段MCMC以及ES-MDA同化算法反演的模型参数精度及计算效率。得出如下主要结论:(1)Kriging替代模型可以有效地模仿地下水数值模型模拟的水头,由此可减小模型参数反演中计算量。但对于高维渗透系数场,如仅根据建立的有限观测值(如本文中10个监测井地下水水头),基于替代模型MCMC反演的渗透系数场误差相对较大。(2)在基于替代模型MCMC反演的参数后验分布基础上缩小参数变化范围,再采用MCMC降低地下水数值模型调用次数,这种两阶段MCMC反演的参数精度更高,不确定性小。(3)ES-MDA算法反演的参数后验分布计算效率最高,但对高维参数场和开采量的反演效果不及两阶段的MCMC。
本文仅基于设定的含水层水文地质条件,并采用地下水数值模型模拟的各含水层中地下水水头作为真值,实际水文地质条件更为复杂,且观测的地下水水头存在误差;因此,未来可利用实际区域观测资料,权衡不同反演方法的精度及计算效率来选择合适的方法,本研究为大范围地下水数值模拟和地下水资源评价等提供适宜的方法。
