UG_2F2F:多特征深度融合的人脸图像修复
2023-11-10边雅琳
杨 有,边雅琳
1(重庆国家应用数学中心,重庆 401331)
2(重庆师范大学 计算机与信息科学学院,重庆 401331)
1 引 言
人脸图像修复是计算机视觉的一项重要技术.它不仅在诸如照片美化、刑侦勘察、历史人物重塑、古壁画修复和电影娱乐等生活方面广泛应用;而且作为一项计算机视觉底层任务,还有助于人脸图像识别、人脸图像采集和对象检测等中高层任务的发展.
近年来,深度学习极大地推进了图像修复的发展.与通过从已知区域中搜索最相似像素块来逐渐填充缺失区域的传统方法相比,基于深度学习的方法能捕获更多的高级语义,生成具有丰富纹理和合理结构的修复内容.在现有的深度学习图像修复方法中,编码器-解码器结构被多次使用.然而,直接使用这种简单的端对端结构进行训练,可能会产生失真的结构和模糊的纹理.这是由于掩码覆盖区域是完全缺失的,导致在生成过程中缺少图像空间上的引导,以致无法重建整个缺失内容.为此,研究人员尝试利用结构先验进行指导的多阶段编解码结构,用于图像修复任务.但是,这些方法只是将纹理与结构信息分别在单一特征空间内编码,忽略了图像重构时涉及到不同层次特征的事实.而在利用结构先验进行指导时,只是将结构特征与纹理特征进行简单的融合,缺少了捕获空间上下文特征相关性的能力,容易产生不一致的结构和纹理.在实际应用中,图像的结构和纹理是相互关联的;上下文特征之间存在密切的相关性.如果不考虑这两点,修复结果会产生不一致的结构或伪影.
针对修复图像难以保持结构完整以及难以捕获远距离特征间相关性的问题,本研究提出了一种纹理和结构深度融合的人脸修复模型(U-Net+GAN with two features and twice fusions,UG_2F2F).“UG”表示利用U-Net结构采集纹理和结构特征,利用生成对抗网络(Generative Adversarial Network,GAN)训练模型;两个“2F”分别代表纹理和结构两种特征、两次融合.为了实现纹理和结构的深度融合,在多尺度填充纹理结构特征的之后,设计了“注意力_结构纹理融合再融合”模块(Attention obtained after twice fusions of structure and texture,Att-ST2),其作用是增加纹理和结构的耦合性,提高捕获破损图像中远距离特征间的信息相关性能力,使得解码端输出图像的结构完整、纹理丰富.
研究工作的主要贡献体现在如下两个方面:1)提出了一种多特征门控注意力特征融合(Gated Attention Feature Fusion,GAFF),GAFF不仅关注破损区域的上下文之间的关系,而且关注CNN局部和全局特征一致性的关系;2)定义了修正的重构损失函数.度量内容不仅包含输出图像和真实图像之间的差异,而且包含纹理图像、结构图像和真实图像之间的差异;在其实现时,采用L1距离作为度量准则.
2 相关工作
2.1 结构先验
得益于GAN的快速发展,利用结构先验指导图像修复的工作取得了创新性发展.文献[1]通过利用图像的原始结构信息指导修复,能修复出清晰的边缘,有效地提高了修复的效果.文献[2]通过在粗网络中提取到的图像边缘信息,来指导细网络的孔洞填充.文献[3]使用RTV平滑技术预先处理图像,得到图像的平滑边缘.再将其作为图像的全局结构输入到模型中进行指导训练.虽然上述方法取得了进展性的修复结果,但是都缺少对结构与纹理相关性的深度利用,不易保证修复出符合结构边缘的精细纹理.文献[4]提出的先验可学习人脸修复模型LSK-FNet,通过基于GAN生成可学习的先验知识,用于指导修复.尽管该模型的先验信息有效指导了破损区域的填充,但在保持边缘的同时没有很好兼顾纹理.
2.2 特征融合
得益于CNN的广泛应用,多特征融合进行图像修复也日益盛行.文献[5]提出了一种特征均衡方法,用来保持结构特征和纹理特征之间的一致性.文献[6]提出了一种上下文感知的图像修复模型,该模型将全局语义和局部特征自适应地集成到统一的生成网络中,得到了具有竞争性的结果.但是这些网络通常只尝试在同一尺度上对纹理与结构进行简单的线性操作,包括求和、串联,致使特征表达不充分,融合后的指导信息在解码端不能充分发挥作用.文献[7]提出的视觉感知人脸修复模型,利用多列门控卷积提取多元图像特征,修复结果能很好地保持结构,但由于缺乏结构和纹理的深度交融,在大空洞缺失的情况下,容易产生与结构不一致的纹理.
2.3 注意力模型
得益于深度学习的发展,基于上下文位置关系的空间注意力模型被广泛应用于图像修复任务中.文献[8]提出了一种上下文注意层,其工作原理是通过在空间上搜索与图像缺失区域相似度最高的背景块集合来完成修复任务.文献[9]在上下文注意力层的工作基础上,提出一种连贯语义注意力层,通过对空间特征的相关性建模,减少修复结果出现色彩断层或者线条断层的情况.文献[10]提出一种通道注意力DMSCA模块,利用扩张卷积与多尺度操作将编码器中的低级特征传递到解码器,生成更为丰富的纹理.文献[11]提出了一种多尺度注意力,通过共享注意力得分和提取补丁块的矩阵乘法进行多尺度特征的长程迁移,用以提高图像上下文的相关性.但是这些注意力模型只关注破损区域局部的上下文之间的关系,忽略了CNN局部和全局特征具有一致性的思想,导致捕获破损图像远距离特征间相关性的能力存在不足.
3 提出的方法
UG_2F2F的总体框架如图1所示,以 “U-Net + GAN”为基线,融入两个模块:多尺度特征重组与填充模块、特征融合再融合模块,前者在图1中用TE和ST表示,后者在图1中用Att_ST2表示.两个模块共同实现纹理与结构特征的深度耦合,确保修复图像结构完整时纹理丰富.
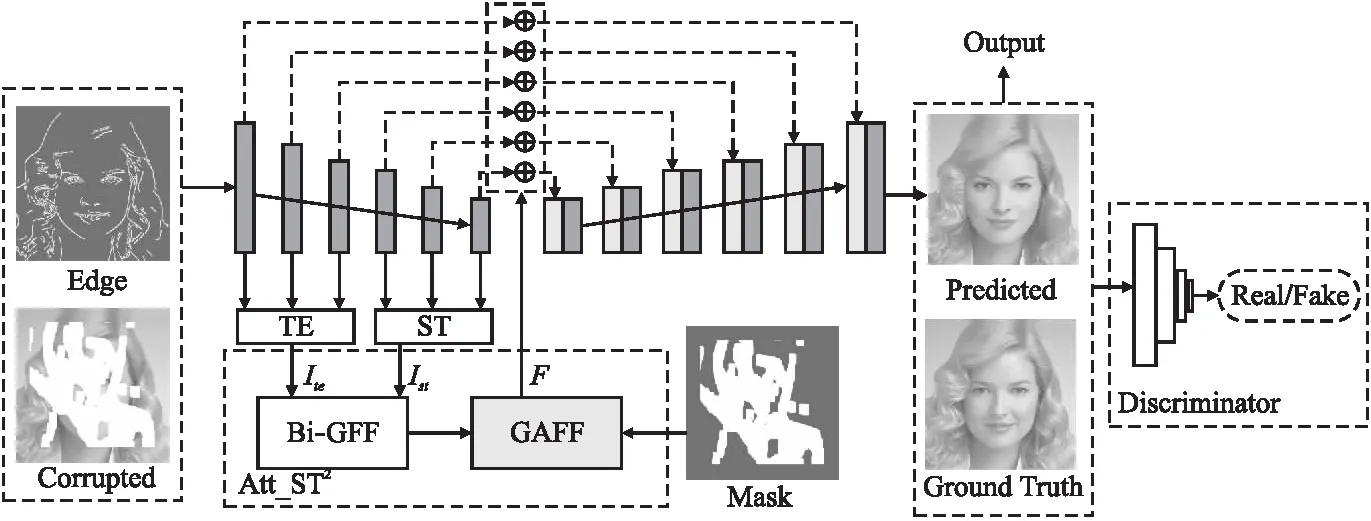
图1 UG_2F2F的网络框架图Fig.1 Network frame diagram of UG_2F2F
3.1 主干网络
在UG_2F2F的基线网络中,下采样的编码器和上采样的解码器各有6个卷积层,使用门控卷积[12]替换原有的普通卷积.因为门控卷积不仅以未损坏的像素为条件进行输入处理,而且可以从数据中自动更新掩码,为不同的有效像素分配不同的权重,有利于不规则破损图像修复.在编码阶段,前3层门控卷积重点关注纹理特征,主要填充图像的局部细节,因此前3层门控卷积经过TE模块处理之后,得到一个具有丰富纹理的彩色图像Ite.后3层门控卷积重点关注结构特征,用来填充图像的全局信息,因此后3层经过ST模块处理之后,得到一个结构填充完整的彩色图像Ist.将Ite与Ist经过 Att_ST2模块进行两次融合得到特征图F.
在解码阶段,使用跳跃连接和逐元素相加将特征图F作为指导信息补充到解码端,这样能在多个尺度上更好地将低级和高级特征组合在一起,使得生成的结构和纹理能相互关联,保持一致.并且在上采样过程中,使用了门控卷积层,有利于模型在修复不规则缺失区域时,获得更佳性能.
TE/ST模块如图2所示,包含两个部分:CNN特征重组和多尺度特征填充.根据文献[5],绘制了如图2所示的TE/ST网络结构.由于在下采样过程中,每层输出的特征图大小不一,因此设计特征重组模块将前3层和后3层的特征图分别转换成相同大小,并将其用一层卷积层连接起来.重组后得到的特征输入到3×3、5×5和7×7的3个并行通道上进行多尺度填充.用不同大小的卷积核进行特征填充,能增加网络的感受野,有利于捕捉到局部与全局信息.

图2 TE/ST模块结构Fig.2 Structure of TE/ST module
3.2 Att-ST2模块
由于TE/ST两个模块是独立学习,Ite和Ist在训练中没有进行特征交互,所以这两者存在不一致的特征表示,不能直接反映修复后的纹理和结构,并且这种不一致性可能会导致缺失区域内部和缺失周围出现模糊纹理或伪影.因此设计了Att-ST2模块.Att-ST2包含双向门控特征融合(Bi-directional Gated Feature Fusion,Bi-GFF)和GAFF两个部分.Bi-GFF是文献[13]提出的一种双向门控特征融合方法,用来交换和重组结构和纹理信息,同时利用软门控控制两种信息集成的速率,有助于特征被细化.
GAFF是UG_2F2F模型中的门控注意特征融合模块,其网络结构如图3所示.GAFF的输入是来自Bi-GFF的输出(图3中的FBi-GFF);GAFF的输出是经过细化的特征图(图3中的F),被用来指导解码端的输出.GAFF包含亲和学习(Affinity Learning,AL)和多尺度空间注意力(Multi-Scale Gated Spatial Attention,MS-GSA)两个部分,亲和学习使用3×3固定大小的卷积模板进行特征学习,增强了图像局部特征之间的相关性.不同于CA[8]使用固定3×3尺度的补丁匹配方案,MS-GSA采用了3个不同尺度进行特征提取与聚合,增强局部与全局信息的相关性;不同于CFA[13]使用普通卷积,MS-GSA采用了门控卷积进行特征融合,在多个尺度上编码出丰富的语义特征,同时在不规则修复中得到更佳的效果.
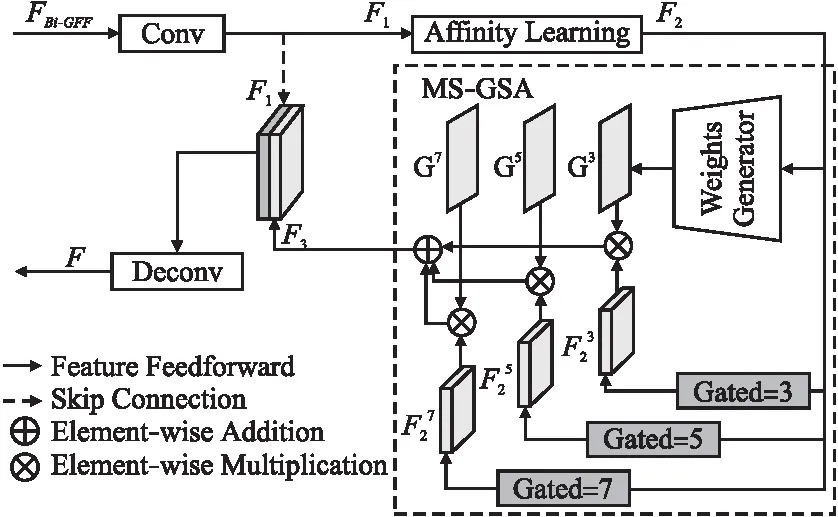
图3 GAFF模块结构Fig.3 Structure of GAFF module
3.3 GAFF模块计算公式
GAFF模块的计算过程描述如下.给定一个特征图FBi-GFF,首先用一个3×3大小的卷积核做卷积操作,用来提取背景与前景中的特征块.为了将前景特征块fi与背景特征块fj进行匹配,使用归一化内积进行度量:
(1)
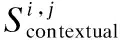
将公式(1)得到的值应用基于通道的softmax操作,以获得每个特征块fi的注意力分数:
(2)
随后,根据公式(2)计算出来的注意力分数,将提取到的像素块fi进行特征块的重构:
(3)
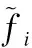
在重构特征块的过程中,使用3组具有不同尺度的门控卷积来捕获多尺度的语义特征:
(4)
其中Gatek(·)表示卷积核尺寸为k的门控卷积操作,k∈{3,5,7}.门控卷积自动学习掩码更新策略,并为生成的像素分配权重,实现对图像中损坏区域和未损坏区域的区别对待.其公式定义如下:
(5)
其中,σ表示sigmoid函数,输出门控值在0和1之间.Φ可以是任何具有激活功能的函数,公式(5)里用的是LeakyReLU激活函数.Wg和Wf表示两个不同的卷积滤波器,可以通过有效像素和图像特征的元素乘法来提取有意义的信息.在门控卷积中,图像和掩码的训练是同步的,而不是按恒定规则转换掩码,因此能在不规则掩码中获得更有效的性能.
针对多列门控卷积提取出来的多尺度语义特征,引入了一种像素级权重生成器PW,更好地聚合多尺度语义特征.在公式(6)中,PW由两个门控卷积层组成,卷积核大小分别为3和1.在每个卷积操作后采用非线性ReLU激活函数,PW的输出通道数设置为3.像素级权重图计算如下:
G=Softmax(PW(F2))
(6)
G3,G5,G7=Slice(G)
(7)
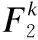
(8)
3.4 损失函数
UG_2F2F采用联合损失进行训练,包括修正的像素重建损失、感知损失、风格损失和相对平均对抗损失.设G为生成器,D为鉴别器.Igt表示真实图像,Egt表示完整结构图,Iin表示输入的破损图像,表示为Iin=Igt⊙Min.Min为初始二值掩码,有效像素区域值为1,无效为像素区域值0.Iout表示网络最终预测输出的图像.
定义了一种修正的重建损失l′re,其计算公式如下:
l′re=λre‖Iout-Igt‖1+λt‖Ite-Igt‖1+λs‖Ist-Iedge‖1
(9)
公式(9)中的3个损失项分别代表重建像素损失项、纹理损失项和结构损失项.Ite代表TE模块的输出,Ist代表ST模块的输出,Iedge代表通过Canny边缘检测器[2]提取到的完整边缘信息.‖Iout-Igt‖1是最终预测输出图像Iout和真实图像Igt之间的L1度量.λre、λt、λs表示各项的权重因子.
修正的重建损失l′re与感知损失Lperc[14]、风格损失Lstyle[15]和相对平均对抗损失Ladv[5]相结合.定义UG_2F2F的联合损失Ltotal为:
Ltotal=l′re+λpLperc+λsLstyle+λadvLadv
(10)
其中λp、λs、λadv表示对应损失项的权重参数.
4 实验结果与分析
4.1 实验环境与实验设置
采用CelebA-HQ公共人脸图像数据集来评估UG_2F2F的性能.该数据集共有30000张图片,选取了29000张进行训练、1000张进行测试.使用两种不同种类的掩码进行了定性和定量比较.其中规则中心方形掩码是一张覆盖图像中心,且覆盖大小为128×128的图像.不规则掩码选取破损比例为10%~50%的任意形状掩码数据集[16],根据其空洞大小,被明确划分成4个区间,分别为10%~20%,20%~30%,30%~40%和40%~50%,观察每个区间内的掩码图像修复结果.实验中用于训练、测试的图像和掩码均先预处理为256×256大小,其中掩码图像同时处理为单通道图像.
UG_2F2F模型在PyTorch框架中实现.计算硬件使用了Intel CPU I9-10920X(3.50 GHz)和NVIDIA RTX 3080Ti GPU(12GB).BatchSize设置为1,使用Adam优化器[17].初始学习率设置为2×10-4.损失函数的权重参数λp、λs、λadv分别设置为0.1、250、0.2.
为了验证UG_2F2F模型在解决产生失真结构或模糊纹理问题上是有效的,将其与代表性模型进行比较,这些模型包括CA[8]、EdgeConnect[2]、RFR[18]、MED[5]和CTSDG[13].
4.2 定性分析
UG_2F2F与代表性模型的视觉效果对比如图4所示.前3行表示规则中心方形掩码下的定性结果,后5行表示在不规则掩码下的定性结果.可以看出,基于注意力的经典模型CA在处理较大的中心缺失时,产生了扭曲的结构和大面积的伪影.基于结构先验指导的两阶段模型EC能够通过使用边缘先验来生成正确的结构,但可能会生成混合的边缘,导致很难生成正确的纹理,图4中第2行的EC修复结果产生了两对眉毛的轮廓.RFR使用循环特征推理模块,在缺失区域比较大的情况产生了具有竞争力的结果,但其在小区域破损时,修复结果会出现破损阴影,如图4中RFR修复图的第4行里存在修复伪影.MED利用平滑图像作为额外的监督来增强破损图片的结构修复,但在大区域破损时修复结果会出现阴影.图4中MED修复图的第6行、第7行.CTSDG采用纹理与结构双编码器结构进行修复,产生了具有竞争力的结果.但其在10%~20%小区域破损区域的修复细节不够丰富,如图4中第5行修复对比图中所示,CTSDG的修复结果中脸颊部分存在明显模糊纹理的问题,并且男人的眼镜被过度平滑,丢失细节.与这些方法相比,本研究的修复结果在较小缺失图像(10%~30%)中能修复出完整的结构和丰富的细节;在较大缺失图像(40%~50%)中,能修复出较完整的结构,并且产生的模糊纹理较少.

图4 CelebA-HQ数据集上不同方法的修复结果Fig.4 Inpainting results of different methods on CelebA-HQ dataset
4.3 定量分析
采用失真度量和感知质量度量来定量评估模型性能.失真度量用于测量结果的失真程度,包括峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似指数(Structure Similarity Index Metric,SSIM),这两个指标预先假设理想的修复结果与目标图像完全相同,再分别计算它们之间的距离或差距.感知质量度量用于表示结果的感知质量,代表一幅图像的主观感知质量.这里选择了Fréchet初始距离(Fréchet Inception Distance,FID).
表1表示不同方法与UG_2F2F模型在CelebA-HQ数据集分别在规则中心掩码和不同比例的不规则掩码(10~50%)下修复结果的客观性能对比.表中符号“↓”表示越低越好,“↑”表示越高越好.表中数据表明,所得结果的PSNR、SSIM和FID均超越了对比项,而且在FID指标上最大下降了28.1%,表明主观感知质量得到显著提升.

表1 CelebA-HQ数据集上不同方法的客观性能对比Table 1 Objective performance comparison of different methods on CelebA-HQ dataset
4.4 消融实验
为了验证GAFF模块的有效性,设计了两种对比验证:1)直接去掉GAFF模块,对应表2中的w/o GAFF;2)用常规卷积替换GAFF中的门控卷积,在模型中融入衍生模块CAFF进行训练,对应表2中的w/CAFF.实验结果表明,使用带门空卷积的特征融合模块GAFF的客观性能指标最优.同时,从主观表现来看,不使用GAFF时,修复图像存在以下困难:难以产生合理的结构与纹理,人脸轮廓存在明显的伪影,眼睛周围纹理模糊等.

表2 特征融合模块的消融定量评估Table 2 Quantitative evaluation of ablation with feature fusion module
为了验证不同边缘信息在模型中发挥的作用,分别用Canny算子[2]、HED算法[19]、RTV平滑技术[20]3种方法提取CelebA-HQ数据集的结构信息,通过实验对比分析它们在UG_2F2F模型中的表现.Canny算子提取出的边缘图为一个二进制掩码,边缘像素宽度固定为1像素.HED算法产生的边缘具有不同的厚度,像素强度在0~1之间.RTV平滑技术产生的图像信息同时具有结构和纹理单元.实验结果如表3所示,使用Canny算子提取图像边缘并作为先验信息指导图像修复,其PSNR和SSIM值达到最大,具有性能优势.
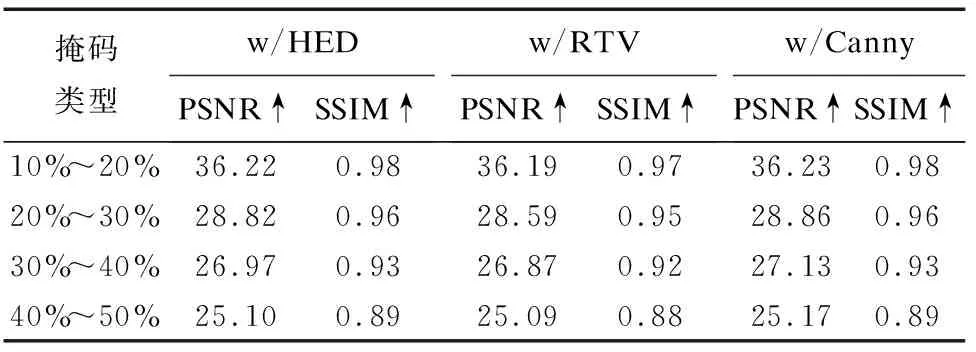
表3 结构先验定量评估,w/表示使用HED/RTV/CannyTable 3 Quantitative evaluation of structural prior,w/means using HED/RTV/Canny
5 结 语
提出了一种多特征深度融合的人脸图像修复模型UG_2F2F,能够在修复过程中将生成的结构和纹理动态地融合在一起.此外,为了克服输入特征之间语义和尺度不一致的问题,提出了一种门控注意特征融合方法GAFF.同时,使用一种修正的重建损失.在纹理重建和结构重建过程中,添加约束.在规则中心掩码和不规则掩码上进行的实验表明,UG_2F2F的性能与代表性模型相比具有竞争力.虽然将门控卷积运用在基线U-Net网络和GAFF模块上,提高了不规则掩码的修复效果,但它也增加了网络的参数,增加了训练的难度.因此,需要优化门控卷积的参数,使其保持轻量化,同时保持相对较高的性能.
