引入位置信息和Attention机制的诈骗电话文本分类
2023-11-10周俊杰许鸿奎卢江坤张子枫李振业郭文涛
周俊杰,许鸿奎,2,卢江坤,张子枫,李振业,郭文涛
1(山东建筑大学 信息与电气工程学院,济南 250000)
2(山东建筑大学 山东省智能建筑技术重点实验室,济南 250000)
1 引 言
据CNNIC(China Internet Network Information Center)发布报告,截止2021年6月,我国网民规模达10.11亿,较2020年12月增长2175万,智能设备使用规模也随之增加,如今拥有全球最为庞大的数字群体.在手机和互联网普及的今天,手机诈骗案件频频发生,科技给人们的生活带来了便利,但也增加了与科技相关的犯罪隐患,无意之间接到的电话可能蕴含着诈骗的风险.据相关数据显示排名前10的诈骗手法分别为交易诈骗、兼职诈骗、交友诈骗、返利诈骗、低价利诱诈骗、金融信用诈骗、仿冒诈骗、色情诈骗、免费诈骗和盗号诈骗.这些手段被交叉运用在电话诈骗之中,颇具威胁[1].因此,有必要对电话诈骗进行研究与治理.
早期对诈骗电话的识别一般基于诈骗号码库[2]、诈骗语音模板和用户通信行为[3]数据.国内的一些运营商通过构建诈骗电话号码库,在运营商的服务端对诈骗电话号码进行标记,在一定程度上遏制了电话诈骗,但这种方法的成本过高,并且当诈骗分子修改电话号码便可继续实施诈骗;基于语音模板进行匹配识别诈骗电话,其核心思想为匹配呼入电话的语音内容,如若匹配到诈骗语音数据,则对其进行拦截,这需要一定数量的诈骗语音模板数据,较为依赖诈骗语音的数量与质量,并且对一些表述变化的诈骗语音不易识别;通过用户的通信行为即呼出号码、呼出地点等信息结合机器学习可以分析判断呼入用户是否为诈骗用户,具有灵活的特点,但这种方法依靠大量的用户行为数据且无法检测通话内容的语义,对于一个全新的号码并不能识别.运营商也采用了基于大数据的诈骗电话分析技术[4]用以防范电话诈骗.文献[5]提出了一种高效的基于并行图挖掘的诈骗电话检测框架,能够自动为诈骗电话号码贴上诈骗标签,从而生成电话号码信任值.
含有诈骗语义的语句属于文本的范畴,其内容与文本的前后文、语句序列、局部相关内容以及显著关键词语相关,本文采用深度学习的方式,通过对诈骗电话文本进行分类在用户端识别诈骗电话.文本分类[6]根据文本内容,按照规则依次将文本归属于一类或多类,整个分类过程可以看作是一种函数关系,对于诈骗文本,文本分类可以将其归属于诈骗类别,从而达到识别的目的.
本文的主要工作总结如下:
1)引入了位置编码,将文本中各类字词所处位置的信息表示出来,体现出文本空间方面的信息,从而更为准确的表示出句子的语义,丰富了文本的特征表示,这对具有诈骗语义的文本极为重要;
2)文本的诈骗语义体现在前后文的相关内容,或与句子本身的结构有关.为提取电话文本的前后文相关性、文本序列特征以及局部相关性等多种深层文本信息,将双向门控循环单元与多尺度卷积神经网络的输出融合,使得模型通过训练能够学习到丰富的诈骗语义知识.
3)将包含关键信息的向量表示赋予较大的权重可以使得诈骗文本更容易被识别出来.通过Attention机制将神经网络提取出的信息重新分配权重,突出关键词语的作用,提高模型分类性能.
4)在两个数据集上进行实验,验证提出的模型相比于对比模型在分类性能上的提升,对诈骗电话文本分类的各项指标均在0.91以上,显示出对诈骗电话文本识别的有效性.
2 相关工作
诈骗电话文本本质上是一些包含诈骗语义的文本内容,可通过文本分类的方法捕捉诈骗语义信息,从而识别诈骗电话文本.分布表示方法通过神经网络技术对上下文,以及上下文与目标词之间的关系进行建模,相比独热编码和TF-IDF[7](Term Frequency-Inverse Document Frequency)等分布式表示方法,获得的词向量更加丰富了文本的语义信息,使得语言特征表示更为准确,且解决了维度灾难[8]和数据稀疏带来的问题,这一方法又被称为词嵌入,采用词嵌入的方式能够将电话文本的信息内容准确的表示出来.具有代表性的模型如Word2Vec[9]、GloVe[10],其中Word2Vec采用两种不同的训练方式,即CBOW(Continuous Bag-of-words)用一个单词的上下文来预测该单词,Skip-Gram用一个单词来预测该单词的上下文.Zhou等人[11]将Word2Vec做为词嵌入结合双向长期记忆模型处理微博情感分析任务.
位置编码[12]可以捕获到文本的位置信息,这一能力在Transformer[13]中得到了应用,使其能够学习句子的结构信息,从而提升模型性能.常见的位置编码有正弦、余弦位置编码以及学习位置编码,正弦、余弦位置编码首先对句子的每个字符编号,处于偶数位置的字符采用正弦函数编码,处于奇数位置的字符则采用余弦函数编码,以此表示字符的位置信息,模型Transformer中应用的正是这种编码;学习位置编码与词向量的生成方式有些类似,每个位置上的字符都学习一个向量,这种方法的句子长度不能超出位置编码范围,并且数据集中短句子较多的情况下影响长句子的位置表达.
门控循环单元[14]通过更新门、重置门两个特殊的门结构解决了递归循环神经网络(Recurrent Neural Network,RNN)的梯度爆炸、梯度消失等问题,拥有更简单的网络结构,节省训练时间,采用双向门控循环单元通过每一时间步中前向隐藏层输出和后向隐藏层的输出能够提取出文本的上下文相关性以及文本的长距离依赖关系,这有利于提取出文本的诈骗语义信息.Yang 等人[15]对金融领域的文本进行提取,通过实验表明BiGRU相比于BiLSTM在信息提取方面更加有效;文献[16]提出一种分层和横向结构相结合的门控循环单元,将其结构中的慢速单元和快速单元组合,用以解决长文本分类问题;文献[17]基于双向门控循环单元构建了一个4层的自动编码器网络,用于情感分析任务.
Kim[18]在2014年提出了TextCNN模型,该模型采用卷积操作对文本局部特征进行提取,取得了不错的效果.不少研究将CNN与RNN相结合,通过将全局依赖信息与局部相关信息融合的方式,将两种模型的优势共同发挥出来,提升分类性能.Li等人[19]将BiLSTM与CNN相结合,采用一种综合性表达法表示语义,并用于新闻文本分类;Zhou等人[20]首先采用不同卷积核处理文本向量,之后的组合处理后的向量,对照原始文本的顺序输入LSTM中得到结果;王凯丽等人[21]提出了一种结合多通道卷积与双向门控循环单元的多特征融合方法用以处理新闻推荐任务.
Attention源于对大脑处理信息过程的研究,人脑从大量接收到的信息中重点关注一部分较为重要的信息,同时弱化其他信息的重要程度,这便是Attention[22].从本质上讲,Attention机制实现了信息资源的高效分配.Attention机制能够进一步增强模型捕获远程依赖信息的能力,在减少层次深度的同时提升模型精度[23].Liu等人[24]提出了一个层次化的注意网络,通过两层Attention捕获到重要的、全面的以及多粒度的语义信息;Rina等人[25]通过将Attention机制与CNN、RNN以及LSTM组合进不同的子模块,构建出多模态的假新闻检测框架,实现多模态信息共享表示;文献[26]在卷积神经网络的卷积层前后嵌入Attention机制,将高、低维特征重新分配权值,以此优化特征提取过程,提升分类性能;文献[27]对Attention在自然语言处理任务训练时的变化进行了可视化,描述了最深层的基于分类的Attention以及各层Attention如何在输入单词中流动.
本文结合位置编码、双向门控循环单元、卷积神经网络以及Attention机制,提出一种用于识别诈骗电话文本的模型PEAGCNN,首先构建诈骗电话文本的数据集,Word2Vec词向量用于表示诈骗电话文本,不同频率的正弦、余弦函数将文本中各个字词的位置进行编码并融入词嵌入向量,分别利用BiGRU和卷积神经网络学习文本前后文的关系、句子的序列结构以及句子中词语之间的局部相关性从而理解句子的语义;Attention机制对上层网络学习提取出的信息重新分配权重,突出关键信息的作用,最后将两种信息融合,将含有诈骗语义的特征信息多层次的表示出来,从而提升模型的分类性能.
3 PEAGCNN电话文本分类模型
电话文本的诈骗语义较于一般的语义信息相对难以分辨,故而需要多层次的语义特征挖掘.模型PEAGCNN整体结构如图1所示.模型主要分为4个部分,即词嵌入层、特征提取层、注意力层和分类层.
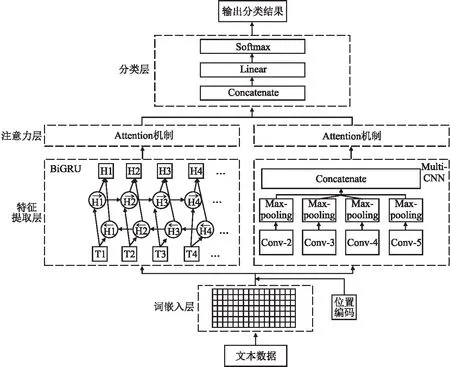
图1 PEAGCNN整体结构图Fig.1 Overall structure diagram of PEAGCNN
3.1 位置信息与词嵌入层
模型PEAGCNN在词嵌入向量中加入位置编码信息生成新的词嵌入向量,采用Word2vec作为词嵌入向量.文本中包含m个字词的语句可以表示为x=[x1,x2,…,xm],经过词嵌入层后,字词序列将被转化为词向量,即w=[w1,w2,…,wm],wi∈Rd,表示第i个词的维度为d的向量,w∈Rn×d为句子的输入词向量表示.
一个相同的字词在一句话中所处的位置不一样,表达的整句话的意思就会大不一样,如“我欠了他500元”与“他欠了我500元”,在这句话中我们可以看出,字词的所处位置对句子语义的表达是极为重要的.为了捕获到文本的位置信息,模型加入了位置信息编码.
对于位置信息的编码,模型中采用sin函数和cos函数来计算,其计算公式如式(1)、式(2)所示:
(1)
(2)
在式(1)、式(2)中,pe表示字词在句子中所处的位置,如“我欠了他500元”,“我”的pe此时为0,“欠”的pe为1,“了”的pe为2,其余字词都以这种方式表示;e表示位置参数,处于句子中的偶数位置用式(1)计算,处于句子中的奇数位置用式(2)计算,dmodel表示位置向量的维数.每个维度位置上的编码表示都有一个正弦波或者余弦波与之对应,波长有规律的周期性变化,以此记录位置信息,波长从2π~10000·2π,通过正弦和余弦函数便可以得到位置向量的编码,以此让模型学习到相对位置信息.最终形成的词嵌入向量如式(3)所示:
T=w⊕p
(3)
⊕表示按位加,p=[p1,p2,…,pm]为文本位置编码后的向量,T=[T1,T2,…,Tm]表示加入位置编码后的词嵌入向量.
3.2 特征提取层
模型的输入一般是由语料产生的词库组成,这样的形式仅仅是浅层的表示,并不能将文本深层次的隐含关系表示出来,面对诈骗语句难以分辨的语义,特征提取层主要采用神经网络对文本的输入词嵌入向量多层次处理,提取出深层次的文本信息,双向门控循环单元用以挖掘文本的上下文相关性以及文本序列特征,卷积神经网络用以提取文本的局部相关特征,即诈骗语句中不同长度的短语特征.
GRU采用更新门与重置门两个门结构,相较于LSTM的结构更加简单,以此提升了训练速度,图2为其单元结构.

图2 GRU单元结构Fig.2 Structure of GRU unit
式(4)~式(7)为GRU的相关计算公式:
Ri=σ(TiWir+Hi-1Whr+br)
(4)
Zi=σ(TiWiz+Hi-1Whz+bz)
(5)
(6)
(7)
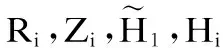
如图2中的GRU单元结构,本文将该单元最后时刻的前向隐藏层输出与后向隐藏层输出连接,提取出前后两个方向的传递信息,从而获取上下文相关性以及文本序列信息.式(8)为双向门控循环单元的输出表示.
(8)

诈骗文本中短语所包含的信息对文本的语义同样重要,如“在我们网站上修改密码”,倘若拆开来看,单个词向量并不能表示整句语义,而对词向量进行卷积可以得到短语向量,利用多种类型的卷积核,便会得到多种长度不一的短语级特征向量,融合这些短语的特征向量之后会得到相比于单词更加丰富的文本信息,卷积神经网络利用不同大小的卷积核对输出向量进行卷积操作,从而提取出词语间的相关性,其卷积过程如图3所示.

图3 卷积过程Fig.3 Convolution process
采用卷积核K来对输入向量T∈Rd×m卷积如公式(9)所示,K∈Kd×h,h表示为卷积核的宽度,d为输入向量的维数.
gi=tanh(
(9)
其中,<·>为卷积计算,gi为所得卷积特征,i∈{1,2,…,m-h+1}.
卷积之后,进行池化运算,采用公式(10).
(10)
其中yi∈R.
s个不同的卷积核,K1∈Kd×h1,K2∈Kd×h2,…,Ks∈Kd×hs,经过卷积操作后得到s个不同的输出y1,y2,…,ys.连接这些输出得到不同尺度的融合特征Y=[y1,y2,…,ys],Y∈RS.
3.3 注意力层
Attention机制可以将提取出的信息重新分配权重,突出关键信息的作用.Attention机制源于人类大脑信号特有的处理机制,人类通过这种机制能够高效地分配有限的注意力资源以关注重要的信息,文本分类中的Attention机制也采用了这样的思想,主要的作用是为了突出当前任务目标的关键信息.
Attention机制如图4所示.多个键值对
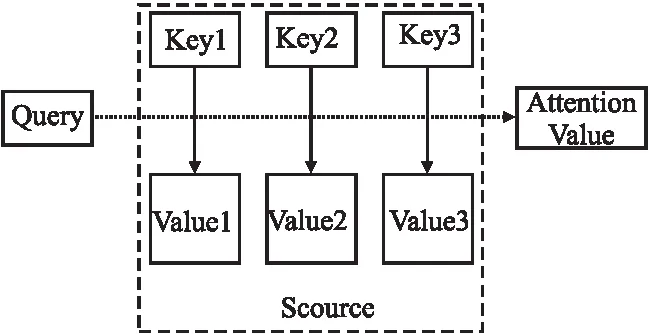
图4 Attention机制Fig.4 Attention mechanism
(11)
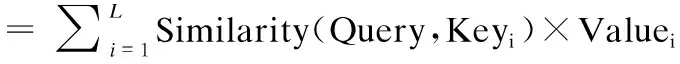
(12)
其中,Query和各个Key的相似性计算采用余弦相似度,如式(11)所示.
在训练过程中双向门控循环单元每个时刻的隐藏层输出以及卷积神经网络的池化输出被Attention机制动态的调整权重,计算提取信息的权重系数,对于关键信息分配较大权重,从而突出其作用.计算过程如下所示.
Mt=tanh(Hi)
(13)
(14)
(15)
其中,Hi表示双向门控循环单元各时刻隐藏层的输出,为训练所得权重矩阵的转置,αt表示注意力权重系数,St为Attention机制作用后的输出.
Mtc=tanh(yi)
(16)
(17)
(18)

3.4 分类层
为了融合上述网络层输出的多种深层信息,将来自注意力层的输出向量进行拼接处理,如式(19)所示:
(19)

(20)
其中WT为训练参数矩阵,bo为偏置参数,此时形成融合多种文本信息并经Attention机制加权后的输出向量O,同时降低了向量的维度,减少了模型的参数,最后通过softmax函数实现分类.
4 实验及分析
4.1 实验环境
实验基于Windows10 64位操作系统,CPU为Intel(R)Core(TM)i7-10700H CPU @2.90GHz,内存容量为16GB,GPU为NVIDIA GeForce RTX 2060,显存容量为6GB,Python版本为3.7.9,基于Pytorch深度学习框架.
4.2 数据集
本文在两个数据集上进行了实验,用以验证PEAGCNN模型的效果.
THUCNews数据集:公开数据集THUCNews,共 10 个类别的新闻标题,共20万条数据,每个类别数据1万条,其中训练集18万条,验证集1万条,测试集1万条.
诈骗电话文本数据集:从百度、知乎、微博、搜狐等各大网站获取数据,同时人工编写修改部分诈骗文本数据集,内容包括金融、教育、邮递、银行、交友、刷单、中彩票、冒充警察等多类诈骗事件,几乎涵盖了所有的诈骗类型.数据共10200条,数据分为诈骗和正常两种类别,诈骗类数据5101条,正常类数据5099条,其中训练集6000条,验证集3000条,测试集1200条.诈骗电话文本数据集统计如表1所示.

表1 诈骗电话文本数据集统计Table 1 Fraudulent phone text data set statistics
本文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-Score来对模型进行评价.
4.3 参数设置
经过大量实验确定了超参数,实验设置的超参数如表2所示.
表2 实验超参数Table 2 Experimental hyperparameters
4.4 实验结果
在设置上述超参数之后,在两个数据集上进行了实验,实验在训练集和验证集上拟合数据,在测试集上评估模型的性能.诈骗电话文本数据上模型PEAGCNN分类结果的混淆矩阵如图5所示,图中表示了模型PEAGCNN对各类数据的分类具体情况.

图5 模型PEAGCNN混淆矩阵图(诈骗电话文本数据集)Fig.5 Confusion matrix chart of model PEAGCNN (fraudulent phone text data set)
从图6、图7中可以看出,模型在两个数据集的测试集上均取得不错的实验结果.在诈骗电话文本测试集的分类结果中,精确率、召回率以及F1值都在0.90以上,这说明模型对诈骗电话文本的分类性能出色.在THUCNews数据集上股票、科技以及时政的召回率和F1值都在0.82~0.90之间,其余几类数据的精确率、召回率以及F1值则都在0.90以上,分析数据的内容,科技和时政的内容较为抽象且描述并不直接,股票则与其他类别的联系密切,如与财经、房产有部分内容极为相似,容易产生分类错误,因此这几类的评价指标较低.
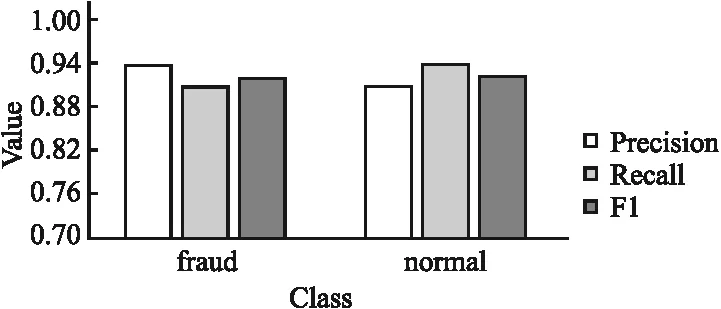
图6 诈骗电话文本数据集实验结果Fig.6 Classification result on fraudulent phone text data set

图7 THUCNews数据集实验结果Fig.7 Classification result on THUCNews data set
为探究位置编码信息对实验结果的影响,进行了去除位置编码信息的实验,以准确率作为评价指标进行比较,结果如表3所示.诈骗电话文本训练过程中验证集上有无位置编码准确率曲线如图8所示,图中Position Embedding代表加入位置编码信息的准确率曲线,Non Position Embedding代表不加入位置编码信息的准确率曲线,横轴代表迭代次数,纵轴代表准确率的值,从图8中可以看出加入位置编码信息模型准确率的提升较为缓慢,模型需要更多次数的迭代学习位置信息,但在最终训练完成之后模型较无位置编码的模型准确率高.

表3 位置编码嵌入准确率Table 3 Accuracy of position embedding

图8 准确率曲线对比图(诈骗电话文本数据集)Fig.8 Comparison diagram of accuracy curve (fraudulent phone text data set)
从位置编码准确率在两个数据集上的对比实验结果中可以看出,位置编码信息的嵌入能够提升文本分类准确率,文本中每一句话的字词经过位置编码都有一个正弦、余弦波长与之对应并形成位置向量,波长周期性的变化记录了不同的位置信息,将这些信息加入到文本的表示当中,使得文本表示更加丰富,通过训练,模型学到这些相对位置信息,从而提升了分类准确率.
4.5 结果分析
本文采用几种经典的深度学习模型进行了试验,以下是对这些模型的介绍.
BiGRU[15]:将神经网络的最后时刻的前向隐藏层输出与后向隐藏层输出拼接,全连接层输出分类结果.该文献中的实验表明BiGRU相比于BiLSTM在信息提取方面更加有效.
CNN[18]:一种多通道的TextCNN模型,由Kim提出,卷积核大小选择(2,3,4,5),用以提取不同尺度的文本局部特征,将各卷积核提取之后的特征向量经过池化处理进行向量拼接,通过全连接层和Softmax层输出结果.
BiLSTM[28]:将双向长短时记忆网络的前向隐藏层输出和后向隐藏层输出拼接,通过全连接层和Softmax层输出结果.
BiLSTM-ATT[29]:采用与BiLSTM相同的结构,引入注意力机制突出关键信息,通过全连接层和Softmax层输出结果.
BiGRU-ATT[30]:采用与BiGRU相同的结构,之后通过注意力计算突出关键信息,通过全连接层和Softmax层输出结果.
RCNN[31]:双向长短时记忆网络的前向隐藏层输出和后向隐藏层输出拼接向量,之后经过最大池化层,再经全连接层和Softmax层输出结果.
PEAGCNN:本文提出的双向门控循环单元与多尺度卷积融合并引入位置信息和Attention机制的神经网络模型.
各模型分类准确率和F1值如表4、表5所示.
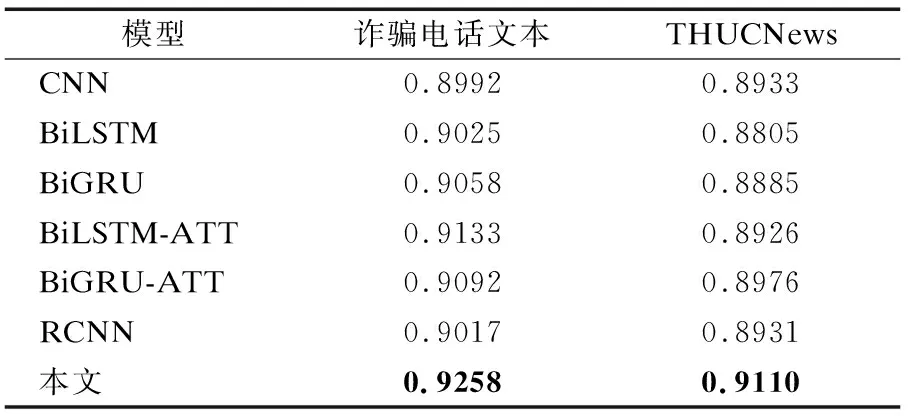
表4 不同模型在两个数据集上的准确率Table 4 Accuracy of different models on two data sets

表5 不同模型在两个数据集上的F1值Table 5 F1-Score of different models on two data sets
从表4和表5可以看出本文提出的模型PEAGCNN在准确率和F1值上均取得了高于0.90的结果.在诈骗电话文本数据集上模型PEAGCNN的准确率为0.9258,F1值为0.9258,在THUCNews数据集上模型PEAGCNN的准确率为0.9110,F1值为0.9107,均高于其他对比模型.
CNN通过不同大小的卷积核提取文本的局部相关特征,BiLSTM则提取文本的上下文相关性以及文本序列信息,这两种模型单独使用在文本分类的结果上较为接近.在诈骗电话文本数据集的实验结果中,BiLSTM的准确率和F1值比CNN分别高出0.0033和0.0034,而在THUCNews数据集的实验结果中,CNN的准确率和F1值比BiLSTM分别高出0.0128和0.0127.这是因为THUCNews是一个短文本标题数据集,而诈骗电话文本数据则相对较长,因而在两个数据集上模型的分类性能不同.
RCNN利用BiLSTM提取文本的特征并经过最大池化层输出文本的最终特征向量,在THUCNews数据集的实验结果中较BiLSTM分类性能有提升,而在诈骗电话文本数据集的结果中,RCNN的准确率和F1值均低于BiLSTM,表明该模型并没有提升分类性能,在处理诈骗电话文本的分类任务时,BiLSTM性能更高.
BiLSTM与BiGRU在两个数据集上的实验结果极为接近,在诈骗电话文本数据集的实验结果中,BiGRU的准确率和F1值比BiLSTM分别高出0.0033和0.0036,在THUCNews数据集的实验结果中,BiGRU的准确率和F1值比BiLSTM分别高出0.0080和0076.BiLSTM通过遗忘门、输入门和输出门3个门结构提取文本上下文相关性以及文本序列信息;BiGRU的结构则更为简单,只采用更新门和重置门两个门结构提取特征,这使得BiGRU能够节省训练的时间,从数据可以看出,BiGRU的分类性能略高于BiLSTM.
两个数据集上的实验结果中,BiLSTM-ATT的准确率和F1值均高于BiLSTM,BiGRU-ATT的准确率和F1值也都高于BiGRU.其中在诈骗数据集的实验结果中,BiLSTM-ATT的准确率和F1值比BiLSTM分别高出0.0108和0.0111,BiGRU-ATT的准确率和F1值比BiGRU分别高出0.0034和0.0033.这体现出了Attention机制的作用,Attention机制在训练过程中对向量序列包含的信息进行加权,将关键信息赋予较大权重,突出其作用,从而提升了分类的效果.
从实验数据可以看出,本文提出的模型PEAGCNN在准确率和F1值上均是最高的,与对比模型中的BiGRU-ATT相比,在诈骗电话文本数据集的实验结果中,PEAGCNN的准确率和F1值分别比其高出0.0166和0.0170,在THUCNews数据集的实验结果中,PEAGCNN的准确率和F1值分别比其高出0.0134和0.0135,有效的提升了分类的性能.模型PEAGCNN在诈骗电话文本的训练过程中,电话文本在词嵌入向量表示之后,首先融入了位置编码信息,此时文本有了空间上的信息,这使得诈骗电话文本的特征增加了一个层次的表示,再分别经过CNN和BiGRU神经网络进行特征提取,CNN提取出文本的局部相关性特征,捕获诈骗语句中的短语信息,BiGRU则提取出上下文相关性特征以及文本的时序特征,分别经过Attention机制的作用,将关键特征信息加权突出,之后将这两部分的特征进行拼接处理,文本在经过模型PEAGCNN的特征提取之后,最终输出富含诈骗电话文本信息以及加权关键信息的特征向量,因此本文提出的模型较其他几种对比模型能够具有最高的分类性能.这也体现出在处理诈骗电话文本分类任务上,模型PEAGCNN的有效性.
5 结束语
本文通过文本分类的方法对电话文本进行分类从而识别诈骗电话,提出了双向门控循环单元与多尺度卷积融合并引入位置信息和Attention机制的神经网络模型,首先构建诈骗电话文本数据集,数据从各大互联网网站获取以及人工编写修改部分诈骗数据,本文提出的模型在诈骗电话文本数据集上性能较好,评价指标均高于其他对比模型,在公开的数据集上也验证了本文提出模型的优越性.诈骗案件一直在社会中发生,其诈骗手段一直多变,今后将持续关注社会中的诈骗案件,更新数据内容,近年来预训练模型在处理自然语言的任务中有着出色的表现,今后将尝试中文预训练模型在诈骗电话文本分类任务上的应用.
