教学场景下的学生课堂状态识别方法研究与应用
2023-11-10刘志刚韩鹏婧
刘志刚,韩鹏婧
(1.东北石油大学应用技术研究院博士后工作站,黑龙江大庆 163318;2.东北石油大学计算机与信息技术学院,黑龙江 大庆 163318)
近年来,智能化教育以人工智能为核心驱动力进行智能化教育环境与生态建设[1]。智能感知是智能化教育的关键技术,旨在利用智能教学系统了解学习者行为、教师的教学、教学环境等物理状态信息,开展教育大数据的分析与决策[2]。在人工智能赋能教育变革的背景下,很多学者对识别学生状态进行了探索性研究。早期主要采用光流[3]、方向梯度直方图HOG[4]等手工设计算子提取学生特征,根据支持向量机[5]等识别行为状态。随后很多学者将卷积神经网络用于学生状态识别,避免手工设计算子的难度[6-13]。这些方法要求视频采集到单个学生具有理想的人体姿态,然而,现实教学场景中学生人体遮挡现象非常明显。因此,研究分布密集的学生状态识别是智能教学评价的关键问题。
1 学生课堂状态识别模型
1.1 学生位置检测模型
开展学生课堂状态识别的研究,要将学生个体从视频中分离,因此个体位置的准确检测是状态识别的首要问题。针对视频中普遍存在的遮挡现象,该文首先设计多尺度注意力模块MAM,抑制学生人体局部遮挡区域的特征噪声;其次,为提高检测速度,引入文献[11]的中心点尺度预测模型(Center and Scale Prediction,CSP)作为嵌入MAM 的基础架构,并将嵌入MAM 的模型记为CSP-MAM;最后,构建联合损失函数进行学生位置检测模型训练。
1.1.1 多尺度注意力模块MAM
注意力机制是一种通过模拟人类视觉系统,聚焦兴趣区域获得细节信息的方法。该文引入注意力机制,在构建的多尺度注意力模块MAM 中,通过外部监督的方式增强学生人体可见区域的特征提取,抑制遮挡区域的噪声干扰。MAM 模块结构如图1所示。
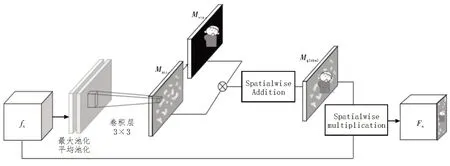
图1 MAM模块结构图
1)空间特征图Matt:对输入MAM 的不同尺度特征图fn,在通道上进行混合池化,利用3×3 卷积核进行滤波,通过非线性前向计算输出Matt;
2)区域增强特征图Mvis:增加可见区域注意力聚焦分支,通过数据集标注作为外部监督信息计算输出Mvis,增强特征图的可见区域特征响应;
3)全局特征图Mglobal:为抑制遮挡区域、增强可见区域特征提取,对Mvis和Matt进行空间叠加构建Mglobal,通过内积作用输入特征图fn,构建可见区域特征增强的全局特征图Fn。
1.1.2 学生位置检测模型
首先,CSP-MAM 利用ResNet-50 作为目标检测模型的特征提取网络,为综合浅层特征图的图像细节特征和深层特征图的抽象语义特征,使用多尺度注意力模块MAM 对ResNet-50 的第3、4、5 层特征图进行特征融合;其次,对增强后的特征图进行L2 Normalization 标准化,使用反卷积统一特征图尺寸;最后,对不同分辨率的特征图进行通道融合,通过三个全卷积分支计算学生人体的目标中心位置、高度和中心位置偏移量。
1.2 学生骨架信息提取模型
根据CSP-MAM 检测的学生位置进行学生个体图像的视频分离,此时若直接通过深度学习进行状态识别,易受到教室背景、学生服饰等干扰噪声的影响,降低识别精度。针对该问题,该文根据学生人体关节点骨架信息特征开展行为识别。提取学生人体关节点骨架信息的方法主要有两种:1)通过穿戴设备或深度传感器提取。该方法具有较高的准确率,但在课堂多人环境下成本较大,易受距离限制;2)采用深度学习的姿态估计技术,提取人体图像的关节点骨架信息。该方法不受设备、人数和距离的限制,具有更好的适用性。该文选用第二种方法,通过姿态估计模型OpenPose 对分离出的学生人体提取骨架信息,包括25 个人体关节点的点位坐标和连接关节点的骨架信息,如图2 所示。

图2 OpenPose检测的人体关节点骨架信息
1.3 学生课堂状态识别模型
该文将学生状态分为四种积极行为和两种消极行为,其中积极行为包括端坐、书写、举手、起立,消极行为包括趴桌子、玩手机。根据OpenPose 提取的学生关节点和骨架信息,为提高学生课堂状态识别的准确率,采用不同的机器学习模型进行状态自动识别,包括支持向量机、极限学习机和卷积神经网络VGG-16、ResNet-50[16]。最后,根据实验对比选择准确率最高的识别模型进行实际应用。
1.3.1 经典机器学习模型
支持向量机(Support Vector Machine,SVM)是由Vapnik 等人提出的经典机器学习模型。极限学习机(Extreme Learning Machine,ELM)是新加坡国立大学黄广斌教授提出的一种快速神经网络模型。由于SVM 和ELM 具有分类速度快、精度高的特点,广泛应用于相关领域的分类识别问题中。采用二者识别学生状态时,输入特征是离散的学生人体关节点坐标。为提高行为识别精度,特征工程阶段包括:1)由于学生受到桌椅、前排学生的局部遮挡,多数学生在课堂视频中仅出现上半身。为保持所有学生的骨架特征一致,降低干扰特征影响,综合考虑“站立”行为的识别,去除膝盖以下的关节点(图2 中第11、14、19~24 点);2)关节点预处理时,采用关节点坐标与1号关节点的相对坐标,避免关节点位置受课堂视频图像帧的绝对位置影响。
1.3.2 卷积神经网络
相对于传统的机器学习模型,深度学习理论在近年来的人工应用研究中获得了更大的成功。该文选用卷积神经网络识别学生状态行为,采用VGG-16 和ResNet-50 模型。与SVM 和ELM 不同,二者的输入特征是根据学生人体关节点截取区域图像。为增强VGG-16 和ResNet-50 特征提取的鲁棒性,将图像分别缩放为224×224 像素和448×448 像素。
2 仿真实验
2.1 实验数据集
实验环 境:CPU Intel Xeon(R) E5-2640、内存8 GB、GPU 显卡NVIDIA RTX2070Super。模型训练验证的实验数据集包括目标检测数据集和行为识别数据集,具体包括:
1)目标检测数据集:为进行学生位置检测模型CSP-MAM 的训练与测试,使用遮挡检测数据集CityPersons。训练集和测试集分别包含2 975 张和500 张图像,每张图像分辨率为2 048×1 024,具有丰富的遮挡形式,并提供人体目标全身边界框和可见部分边界框。
2)行为识别数据集:在实际应用前,需对学生状态识别模型进行训练和测试。由于目前国内外没有标准公共数据集,该文选取某大学400 名志愿者为数据来源,拍摄每名同学的举手、听课、看书、站立、趴桌子、玩手机六个课堂状态动作,通过数据标注构建数据集NEPU-300。
2.2 实验步骤
1)学生目标位置检测:首先,使用CityPersons 数据集完成学生位置检测模型CSP-MAM 的训练与测试,通过迁移学习应用到本实验中;其次,按照视频帧采集频率,获取实时视频流中的图像帧,根据CSP-MAM 对教学视频中的学生位置进行目标检测;
2)学生骨架信息提取:将检测后的单个学生人体目标从视频图像中分离出来,通过OpenPose 完成学生骨架信息提取,保存除11、14、19-24点外的17个关节点的相对坐标,以及17个关节点的骨架区域图像;
3)学生课堂状态识别:首先,根据OpenPose 对NEPU-300 数据集识别的学生关节点、骨架区域特征完成行为识别模型的训练,包括SVM、ELM、VGG-16 和ResNet-50。其 中,VGG-16 和ResNet-50 在ImageNet 上完成预训练;其次,为避免模型训练过拟合,训练过程中采用旋转、平移、翻转的方法对NEPU-300 数据集进行增强;最后,将训练好的状态识别模型应用到学生状态识别任务中。整体流程图如图3 所示。
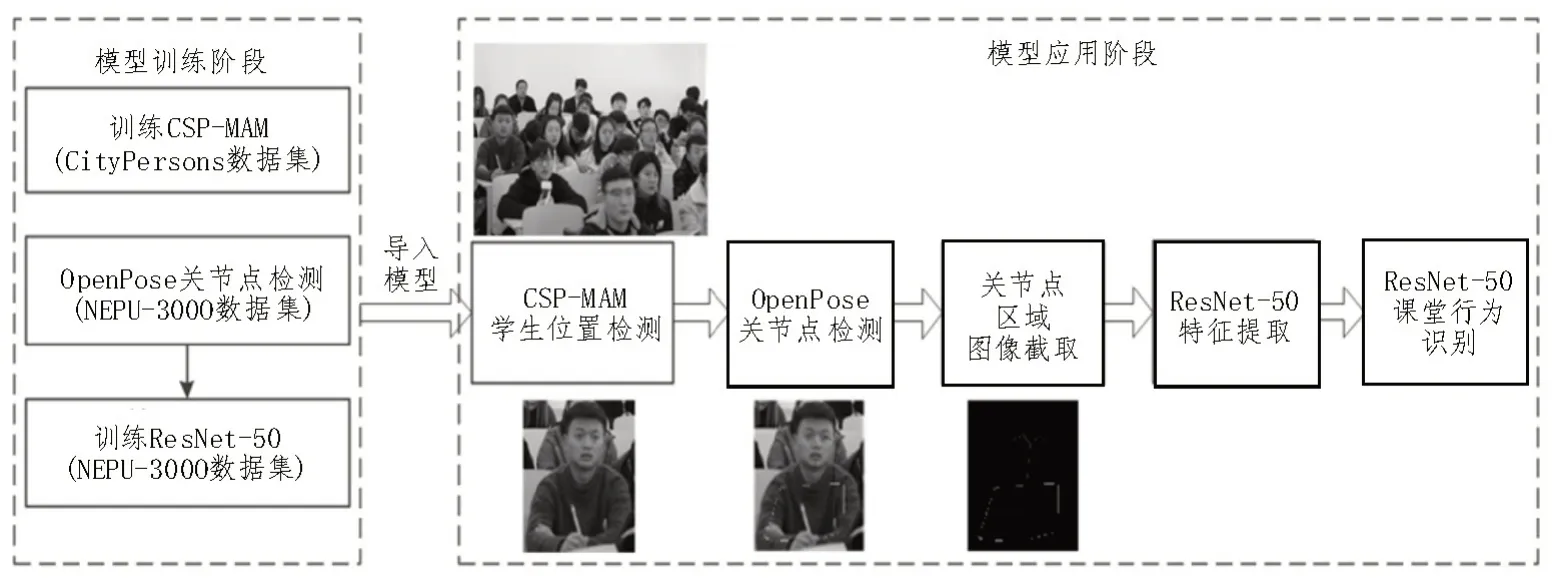
图3 学生课堂状态识别流程图(以ResNet-50为例)
2.3 实验分析
为实验对比有效,在相同实验条件下进行五组独立随机实验,实验结果为多次实验的平均识别准确率。根据实验环境,将Epoch 设为50,Mini-batch设为30,并对比该文所提的CSP-MAM 与其他主流检测模型YOLOv5、SSD 在四种状态识别模型上的性能。观察表1 可知:①在对比的三种目标检测模型中,通过引入CSP-MAM 检测模型,相对于YOLOv5、SSD,四种机器学习模型的学生状态识别精度均有提升,结果表明,CSP-MAM 有效提高遮挡学生的位置检测能力,降低课堂视频分离后的学生个体图像中干扰噪声对模型提取特征的影响;②在对比的行为识别模型中,ResNet-50 和VGG-16 的状态识别准确率均高于传统的机器学习SVM、ELM,并以ResNet-50 的识别精度最为理想。实验表明,采用深度学习方法进行学生课堂状态识别具有更好的识别准确率和泛化能力。
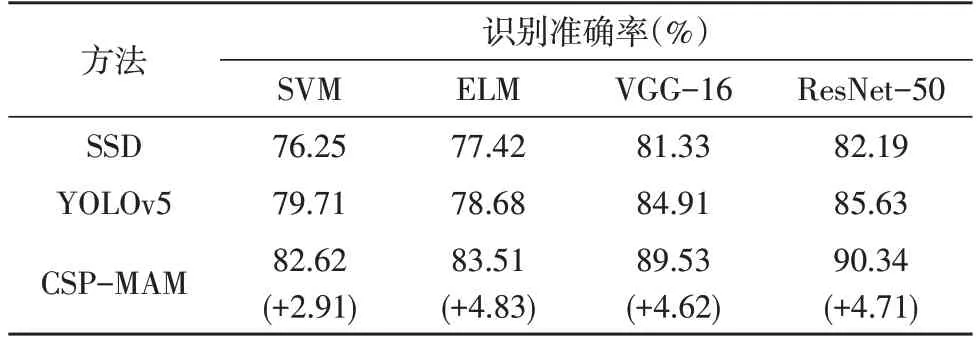
表1 学生状态识别准确率的实验结果对比
如图4 和图5 所示,分别为使用SVM 和ResNet-50 进行六种课堂状态识别的混淆矩阵图。对于“举手”“站立”“趴桌子”三种骨架关节点特征较为明显的行为,识别准确性较高,对于“听课”“看书”“玩手机”三种关节点特征区别度较低的行为,准确性略低。同时,ResNet-50 相对于经典机器学习SVM 模型在六种状态的识别准确性上均明显提升。

图4 使用SVM进行六种课堂状态识别的混淆矩阵图
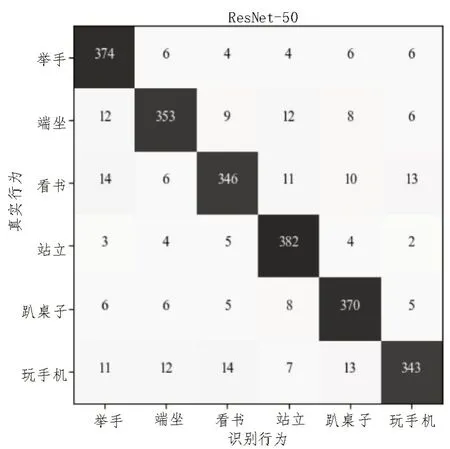
图5 使用ResNet-50进行六种课堂状态识别的混淆矩阵图
3 系统设计与教学评价应用
3.1 学生状态智能辅助分析系统
为辅助教师及时掌握学生学习状态、快速分析教学效果和有效提高课堂教学质量,该文在所提研究方法的基础上,设计学生课堂状态智能辅助分析系统,实现课堂教学信息反馈实时性、传递高效性和处理智能性。该系统包括五大模块,具体如下:
1)课堂录像模块:采用固定摄像机完成课堂教学场景的实时录制,将视频信号通过专用线路传输到主控服务器;
2)图像采集模块:构建RSTP 流媒体服务器,设置视频分帧采集频率,提取课堂视频图像帧,将图像输入给目标检测模块;
3)目标检测模块:通过CSP-MAM 模型对采集的课堂教学场景图像进行学生目标位置检测,从场景图像中分离出检测后的每个学生个体图像;
4)行为识别模块:通过OpenPose 提取学生人体骨架信息,获取关节点区域像素特征,采用ResNet-50 进行学生状态识别;
5)数据分析模块:根据模型识别结果进行教学过程的统计分析,包括抬头率、低头率、课堂参与度、互动活跃度四种评价指标。
3.2 课堂教学效果评价
该研究中的课堂教学评价包括即时评价和总体评价两部分,其中,即时评价采用学习率、低头率两个常用指标实时反映学生听课状态,总体评价则采用课堂参与度、互动活跃度两个指标衡量整体教学过程。综合考虑计算速度与分析效果,设视频分帧采集频率τ=12 秒/帧。为方便描述,记课堂学生总数为N,课堂互动次数为P,学生在各时刻状态依次记为“端坐”:Ai(t)、“看书”:Bi(t)、“举手”:Ci(t)、“站立”:Di(t)、“趴桌子”:Ei(t)、“玩手机”:Fi(t)。其中,Ai(t)为第i个学生在t时刻是否处于“端坐”状态,若是取1,反之取0,其他同理。
1)学习率η(t):根据采集频率τ获取的课堂视频图像进行学生行为识别,以“端坐”“看书”“举手”“站立”四种积极状态为依据,实时反映听课人数比例,具体如式(1)。
2)低头率μ(t):主要统计“趴桌子”“玩手机”两种消极状态,实时反映教学中消极学习的学生比例,具体如式(2)。
3)课堂参与度γ:主要反映学生群体在教学时长内的积极行为、参与学习的比例情况。按照图像采集频率τ,将教学监测视频时长T分内的教学过程离散成60T/τ个视频场景序列,依据四种积极状态计算全体学生的课堂参与度。为降低学生“端坐”“看书”时的心不在焉现象,设置权重因子λ1=0.3、λ2=0.7 调节“端坐”“看书”与“举手”“站立”之间的比例关系。当τ=12 时,参与度计算见式(3)。
4)互动活跃度κ:互动活跃度主要反映学生群体在提问、互动等教学过程中的活跃情况。根据互动环节时长离散后的P个图像场景序列,在“举手”“站立”行为识别的基础上计算活跃度,设置权重因子λ3=0.45,λ4=0.55 调节两种行为对κ的贡献,具体如式(4)。
4 结论
近年来,以深度学习为主导的人工智能理论取得了很大发展,智能视频分析技术逐渐引起研究者的关注。由于摄像机角度、座位前后排、学生密集和人体柔性等因素的影响,人体遮挡问题是学生状态自动识别的难点问题。针对该问题,该文对位置检测、特征提取、状态识别和系统实际应用进行研究,最终实现了利用教学评价指标自动完成教学效果评价。该文的研究能够有效助力于课堂为主体的智能化教育评价,从而促使教师改革教学方法,优化教学策略,不断提高教学效率。
