科学数据“东数西算”组织机制与传输模式研究
2023-11-08方肖胡正银韩锐郑亮
方肖,胡正银*,韩锐,郑亮
1.中国科学院成都文献情报中心,四川 成都 610299
2.中国科学院声学研究所,北京 100190
3.国家超级计算成都中心,四川 成都 610299
引 言
“东数西算”是国家重大发展战略[1],科学数据作为“数据”的重要组成部分,已成为国家科技创新发展和经济社会发展的重要基础性战略资源,科学研究也已步入数据密集型的“第四范式”时代[2]。现阶段科学数据存储主要集中于东部地区[3],而东部地区资源紧张不能满足科学数据研究分析所需的海量算力、电力资源。科学数据“东数西算”具备较大的经济价值和推动西部地区产业发展的能力,因此有必要对该过程的组织机制和传输模式进行研究,助力国家“东数西算”重大战略。
1 科学数据“东数西算”组织机制
当前,国家“东数西算”工程重点关注布局在政务、金融、交通、企业、医疗、教育等能够快速转化数字经济价值的领域[4]。科学数据“东数西算”在相关研究领域具有经济价值与迫切性,能够为科研机构节省大量科研经费,但科学数据偏向于基础研究,直接转化经济价值较低,拉动地方GDP的效果远低于其他数字经济领域。因此,地方政府会根据科学项目的影响力给予较多的政策支持,但直接资源投入相对较少。从组织机制的角度对科学数据的处理大致可以分为以下3种模式。
1.1 单机构模式
单机构模式是指独立的研究机构依托国家财政支持或自筹经费等形式,开展科学数据的生产、传输、处理。一些大型的基础科学项目、大科学装置例如500 m口径球面射电望远镜(FAST)[5]、锦屏地下实验室[6]等多采用该模式。
单机构模式的优点在于研究机构自建实验探测装置用于科学数据的生成,自建私有数据存储设施进行科学数据的存储和计算,科学数据自产、自存、自用,安全可控,效率高。但也存在一些问题,例如:(1)自建数据存储设施需要投入大量建设资源,消耗研究经费;(2)科学数据每年持续增长,自建的数据存储设施难以进行配套升级;(3)自建数据存储设施选址需考虑政策、安全、地理等多方面因素,如离实验装置所在地较远还需要投入数据传输资源;(4)需要配备专门的运维团队,相关专业人才需要的培养周期较长;(5)每年需要消耗相应的运维经费,所依托的实验项目结题后,后续运维经费来源存在问题;(6)自建数据存储设施所服务的实验项目结题后,相关计算、存储资源难以转化再利用。从科学数据自主安全可控的角度出发,研究机构大多倾向于单机构模式,但该模式的局限性会制约大科学装置、大型基础科研项目的研究与发展。
1.2 公共科学数据中心模式
公共科学数据中心模式是指汇集大量计算、存储、网络资源形成实体机构为科研用户提供一站式科学数据处理服务,通过集中存储计算、统一管理,高效利用软硬件资源,避免资源闲置和数据孤岛。目前,我国已建成了包括国家地震科学数据中心、国家人口健康科学数据中心等20个国家级科学数据中心[7],但这些数据中心多集中于我国东部。
建立公共科学数据中心是科学数据共享、多学科融合发展的趋势[8],但也存在一些问题,例如:(1)资源投入巨大,如表1所示前期投入保守估计达数亿级别;(2)目前科学数据中心主要依托科学数据提供机构建立,研究机构将科学数据存入公共数据中心的意愿不高;(3)缺乏盈利模式,难以维系每年海量的运维费用。
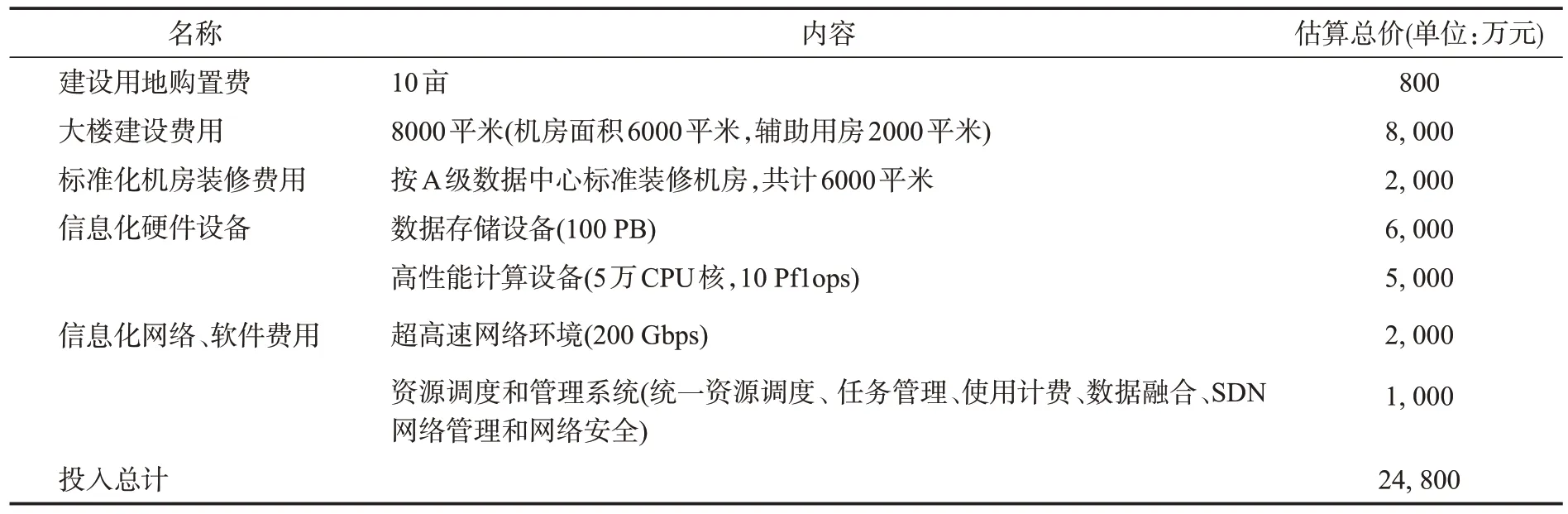
表1 公共科学数据中心投入估算Table 1 Investment estimation for public scientific data centers
鉴于公共科学数据中心模式存在的问题,大多数地方政府对建立公共科学数据中心持慎重态度,希望充分整合利用现有资源,形成具体的科研服务示范之后再逐步推动数据中心的实体建设。
1.3 科研联盟模式
在科学数据“东数西算”过程中,可以通过众多机构利用各自现有的资源来完成科学数据的“东数西算”,各机构之间形成类似联盟的组织。如表2所示,在这个过程中各机构扮演的角色大体可以分为五类,并且各角色的诉求也各不相同。科学数据使用者对科学数据以及相关计算资源服务的需求是促进科学数据在不同机构间流通的重要因素,科学数据的所有者在同意使用者的需求申请后通过传输者将数据传递给科学数据的处理者,处理者将数据进行计算之后将结果返回,存储者在这一过程中提供协助。通过这一过程既利用了西部地区的资源优势,相对低成本地完成了科学数据的计算需求,又为参与的各机构带来了经济收益盘活闲置资源,以较低的投入带动地方产业发展。

表2 科学数据“东数西算”中各机构扮演角色及诉求Table 2 The roles and demands played by various institutions under “East-West Computing Resource Transfer”
科研联盟模式充分整合利用现有资源、前期投入较少、形成示范之后更容易逐步推动项目的升级和发展。相较而言,该模式在科学数据“东数西算”过程中最具经济性和可实施性,当联盟成员较少时机构之间容易协调,但随着联盟成员的不断增多,需要研究构建一种传输模型保证科学数据流通过程清晰明确、可记录、可回溯,才能在界定各方的权责利益时有所依据,保证科学数据的安全可信,形成科学数据“东数西算”的顺畅链条。
2 科研联盟模式下的科学数据传输模型
科研联盟的模式可以有效整合利用现有资源,实现闲置资源的再利用,在不增加大量投入的情况下,完成科学数据的“东数西算”。但是这个过程涉及很多不同的组织机构,需要建立信任机制,使科学数据流动的整个过程有迹可循,确保科学数据安全和权责清晰。本文基于联盟链的相关理论[9],结合科研联盟模式下科学数据“东数西算”的具体应用场景,构建基于科研联盟的科学数据传输模型,以期促进科学数据安全流通与高效利用。
2.1 联盟链在科研联盟场景下的适用性分析
区块链是一种计算机技术的新型应用模式,可以做到点对点传输、分布式数据存储、共识机制、加密算法等。其本质是基于互联网的一种新型的信息传输方式,即可以实现多个信息化系统间的广播式数据交互的技术。区块链技术的主要优势是分布式和去中心化,信息的不可篡改,基于共识机制的信息传输和共享,从而实现在各类型场景下均能确保信息安全的目的[10]。
区块链大体上可以分为3 类,公有链、私有链和联盟链。公有链各个节点可以自由地加入和退出网络,并参加链上数据的读写,读写时以扁平的拓扑结构互联互通,网络中不存在任何中心化的服务端节点;联盟链各个节点一般会有与之对应的实体机构组织,必须通过授权后才能加入或退出网络,各机构组织组成利益相关的联盟,共同维护区块链的健康运转;而私有链的各节点写入权限则收归内部控制,而读取权限可根据实际需求选择性地对外开放[11]。对于科研联盟这种由不同实体机构组成,且科学数据规模有限的情况,采取联盟链的方式进行科学数据传输模型构建是一种合适的选择。
联盟链是一种部分去中心化的、参与节点事先确定好的区块链,其特点介于公有链和私有链之间,信息数据访问只在其内部,交易确认速度较快,其信息数据保有一定程度的隐私性[12]。当前联盟链已经在金融领域、生命健康领域等多个领域有着广泛的应用,根据联盟成员的权限和数据范围对上链信息数据进行监管,保证权责清晰和数据安全。当前比较流行的联盟链项目主要有:区块链服务网络BSN、企业以太坊联盟(EEA)、超级账本(Hyperledger)、中国分布式总账基础协议联盟(ChinaLedger)、R3 区块链联盟等[13]。Yang等[14]构建了联盟链的Hyperledger Fabric 系统,如图1 所示,该系统的逻辑架构主要分为成员管理、共识机制、智能合约三部分。
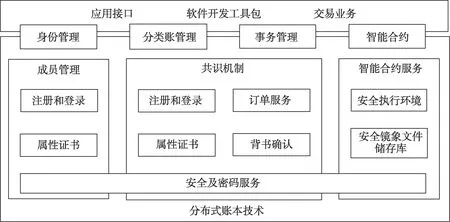
图1 联盟链Hyperledger Fabric系统逻辑架构Fig.1 Logical architecture of the Hyperledger Fabric system in the alliance chain
成员管理可以对科研联盟内部成员的身份、权限进行管理确认,分配相应的登录方式和属性证书。共识机制在科研联盟的应用场景下可以采用BFT-DPoS 共识机制进行轮流记账[15],由联盟的成员机构节点周期性地投票选举出受信任的数个超级节点,由超级节点轮流或者随机进行记账产生区块。同时,这些超级节点也将对产生的新区块进行投票,只有当通过的票数超过阈值才会达成共识。智能合约是一种特殊类型的程序,是情景对应型的计算机程序或事务协议,能够对交互数据开展接受、处理、存储、发送等操作,实现科研联盟内部数据灵活的管理与控制。智能合约需要自动化的数据、过程、系统的组合与相互协调,将科研联盟内部的协议、合约代码化嵌入计算机程序,具有自动化执行、去中心化、不可篡改性、无需信任和高效性等特征,能够部署在数据区块、交互环节、有形或无形资产中,实现基于软件定义的可编程控制系统[16]。
在科研联盟的模式下,需要科学数据可以在不同机构之间根据预先设置的规则快捷地进行传输,数据的流通传递过程需要被记录下来,并且相关的记录数据要保证真实性和完整性,从而为界定各机构权责利益提供依据。同时,科学数据的安全性至关重要,要保证数据提供者对数据的所有权以及数据不被随意篡改和泄露。联盟链技术将记录科学数据流通过程的信息数据按照一定顺序进行存储排列,可以清楚获取信息数据的源头以及科学数据的流通过程记录。信息数据以哈希值的方式存储于区块链上,具有不可逆性,可以保证上链的信息数据无法被随意篡改。通过该机制对数据流通的过程信息进行记录,使科研联盟模式下的科学数据流动具备溯源能力。联盟链具有非对称性加密算法、多通道隔离账本以及智能合约等技术,可以保证存储的信息数据不被篡改,科学数据传输是在联盟成员之间,减少了数据泄露和恶意篡改风险。因此,联盟链的相关技术特征十分切合科研联盟模式下的数据传输需求[17]。
2.2 基于联盟链的数据传输模型构建
如图2所示,HAN等[18]学者提出了一种基于联盟链的数据共享安全保护模型。在该模型下不同的数据存储于不同的数据库,并且集中存放于存储层。区块的创建和广播在区块链服务层完成,接口层为各种信息交换提供接口的连接层。智能合约层为用户提供各种类型的合约服务,包括合约日志记录、数据记录等。应用层为用户成员提供各种服务,实现用户对数据的传输和共享。该模型为提高数据安全水平,进行了层级功能细分,构建出了通用数据传输模型的清晰整体架构,并着重解释了区块链的创建,利用多节点投票机制加强了区块链的抗风险能力。
在科研联盟的应用场景下,涉及科学数据的提供方式、按规则传输机制、数据获取索引上链、科学数据本体另行存储等特征,通用的科学数据共享模型并不完全适用。因此,本文结合通用科学数据共享模型与科研联盟应用场景下的具体特征,构建了科研联盟模式下基于联盟链的科学数据传输模型,以便科学数据在联盟内部能快速流通并且保证数据流通过程有迹可循。
如图3所示,该模型主要分为4层,其中数据提供层描述了科研联盟中科学数据的来源,多是大科学装置、实验探测器等。科学数据的原始数据量庞大,无法上链进行存储,通常采用分布式本地存储方式,同时将数据的获取信息进行上链存储。数据处理者在联盟链内得到数据获取信息之后还需要数据提供者提供外部权限,才能最终访问到科学数据,通过多层监控机制保证了数据的安全。该层补充了通用模型中对科学数据来源部分的不清晰,以此体现原始科学数据的合理性、完整性和真实性。

图3 科研联盟模式下科学数据传输模型Fig.3 Scientific data transmission model under the mode of scientific research alliance
存储层通过云存储等网络存储形式以及加密存储等技术,对科学数据获取信息和联盟链信息进行存储。联盟链数据库分为协议合约数据库、科学数据获取路径数据库、联盟成员数据库、链上数据库,对不同的数据进行分类存储。其中的科学数据获取路径数据库保存了数据的获取信息,在通用模型的基础上进一步对获取路径进行了设置,保证了数据的隐私性,为数据溯源和隐秘传输提供了支持。
数据处理层基于联盟链理论构建,主要包括成员管理、共识机制、智能合约3部分,科研联盟中的机构成员通过联盟授权认证之后才能拥有区块链网络中信息的访问权限,可以凭借联盟成员的身份对联盟链的数据进行新增、使用、更新、维护。共识机制采用BFT-DPoS共识机制进行轮流记账,周期性地投票选举超级节点,由超级节点轮流或者随机进行记账产生区块。科研联盟内部机构之间的协议合约,通过程序化形成智能合约。智能合约是具体的计算程序,在数据流通过程中只有满足合约条件才会执行其中的代码,实现数据的流通、交互、获取等请求。
应用层则是为联盟成员机构提供管理科学数据的相关功能,包括了科学数据确权、科学数据溯源、科学数据获取、科学数据安全几个方面。机构成员可以通过以上功能对数据进行获取和处理,整个过程都会被记录下来,避免了数据被恶意篡改和滥用的风险,使数据的安全得到保证。
2.3 基于科研联盟模式的数据传输模型讨论
成立科研联盟是希望整合各机构分散的资源,共同实现科学数据的“东数西算”。当参与协作的机构较少时,可以通过互签协议等方式明确权责利益。但当参与机构数量众多时容易产生混乱,需要使科学数据的流动有迹可循,以避免不必要的纠纷。为描述科学数据“东数西算”过程中原始科学数据的来源、存储方式以及记录科学数据在不同机构间流动的信息,构建了基于联盟链技术的科学数据传输模型。在这一模型中,科学数据的提供者、使用者、传输者、处理者均需要进行注册登记,基于智能合约进行必要的身份验证。每位机构成员都会获得注册证书和公私密钥,用于验证其在联盟链中的身份和访问权限。数据的提供者还会额外获取数据所有权密钥,用于数据确权。通过严格的成员身份认证,加强数据流通过程的安全性。
由于科学数据体量庞大,难以进行上链存储,数据的提供者只需基于智能合约的标准将数据的获取信息上传至联盟链中进行存储。数据的使用者、传输者、处理者在与提供者协商一致后,可以通过联盟链进行数据访问请求,该请求会被据实记录至联盟链中并启动广播。在数据请求广播之后,会对联盟链中的数据信息进行检索,找到相应的科学数据获取信息,并在广播之后将该信息发送给对应的数据申请者。整个过程都将被联盟链记录且不可篡改,这就使数据在各机构之间流通的过程清晰明确,为各机构间的权责界定提供了依据。
数据申请者在访问科学数据时还需要科学数据提供者外部审核批准才能获取到数据,并且科学数据仅是经传输者提供的网络路径传输至处理者进行处理,处理结果再返回数据申请者。这一过程中,数据是以流的形式进行流通、处理、返回,杜绝了大量实体数据拷贝外泄,进一步加强了数据的安全性。
基于科研联盟模式的科学数据传输模型主要描述了科学数据的来源、存储以及如何记录数据流通信息。通过联盟链的相关技术对联盟内机构进行成员管理,记录不同机构之间数据申请、传输、使用的相关信息,以确保数据流通有迹可循,避免机构众多时产生纠纷。科学数据的实体传输在机构间达成一致且被联盟链记录流通信息后,由数据传输者通过实体网络及相关传输技术完成。
3 科研联盟模式下的示范案例
基于理论研究,联合中国科技云成渝枢纽、中国科学院声学研究所、上海科技大学、国家超级计算成都中心,合作开展科学数据“东数西算”示范验证。并通过签署“合作协议”、利用联盟链记录等方式,确保协作过程权责利益清晰,数据流通有迹可循。
中国科技云成渝枢纽作为中国科技云[19]“十四五”规划“四大枢纽”之一,是一项立足中国科学院,面向成都科学城,辐射成渝双城经济圈重要科研机构与大科学装置的战略性、基础性新型国家级科研信息化基础设施枢纽节点。在示范验证中作为数据传输者为科学数据传输提供节点中转和网络环境支持。
SEANet[20]网络技术是中国科学院声学研究所主导研发的一种新型网络传输协议用来替代传统TCP/IP协议。它通过“一包一路由”的数据传输方式,使外部窃取监听数据流更加困难,最多只能截取到数据包片段,难以获取完整的数据信息,提高了数据传输的安全性。同时基于“一包一路由”,在数据传输过程中可以选择最通畅的网络路径以及多网络路径传输,实现数据传输加速。在示范验证中声学所作为数据传输者为科学数据传输提供网络环境和安全传输技术加持。
上海科技大学硬X射线自由电子激光装置[21]作为科学数据提供者,在示范验证中提供大量相干衍射成像数据。国家超级计算成都中心,是西部地区首个国家超算中心,算力峰值性能300PFlops,具备丰富算力资源和西部地区能耗优势,在示范验证中作为科学数据处理者。
如图4所示,上海的科学数据通过网络经中国科技云成渝枢纽传输到国家超算成都中心进行运算。针对上海科技大学到国家超级计算成都中心的远距离、高通量数据传输需求,充分利用中国科技云成渝枢纽节点的功能,发挥SEANet 网络技术智能多路径传输优势,通过动态多路径优化保证数据传输始终处于最优网络路径,使硬X射线自由电子激光装置相干衍射成像数据日均TB级海量图像数据在广域网上稳定高效传输。如图5 所示,基于SEANet 技术的传输网络与传统网络进行了性能测试对比,在相同出入口带宽情况下,在UDP 协议512B 数据包模式下,传统网络速率仅为90Mbps,而采用SEANet独有的多路径传输后2 条路径可达到250Mbps的传输速率,采用4 路径可达到600Mbps 的速率;在UDP 协议1,250B 数据包模式下传统网络速率仅为100Mbps,而采用多路径传输后2 条路径可达到300Mbps的传输速率,采用4路径可达到900Mbps的速率。由此可见基于SEANet的传输网络传输性能优于传统网络。
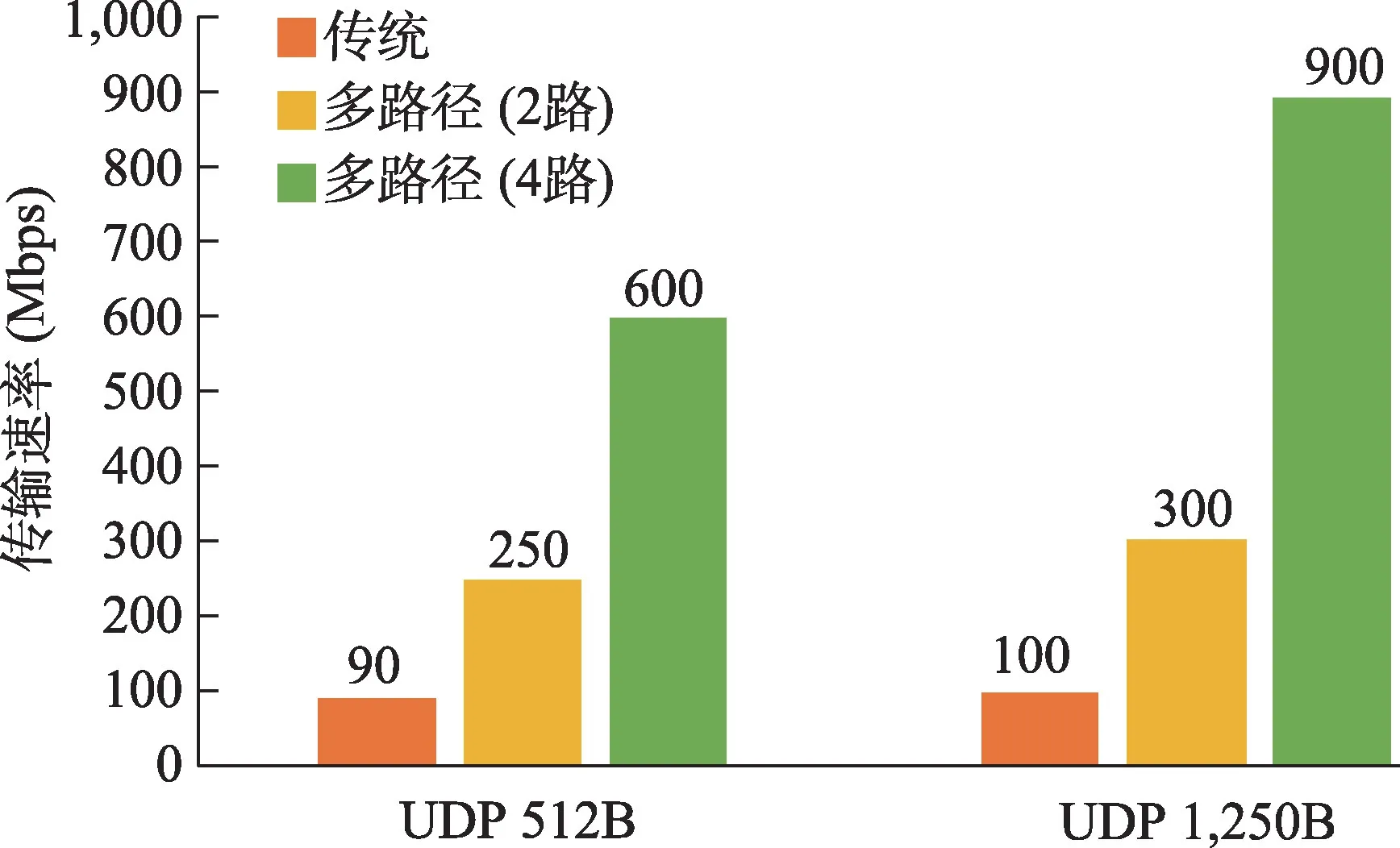
图5 基于SEANet技术的传输速率比较Fig.5 Comparison of transmission rates based on SEANet
整个数据传输过程,充分整合利用现有的网络、计算、存储资源,在相对较少的投入下完成科学数据“东数西算”示范验证,为后续大规模科学数据“东数西算”,充分利用西部地区资源优势,带动西部地区产业发展做出了预研与示范。
4 结论与展望
科学数据“东数西算”具备经济价值和推动西部地区产业发展的能力,通过众多机构整合利用现有资源共同完成科学数据“东数西算”的科研联盟模式最具经济性和可行性。基于联盟链理论构建的科学数据传输模型使得科学数据在各机构间的流通过程清晰明确、可回溯、不可篡改,为机构间权责利益的明确提供了可靠的依据,能够提高不同机构参与科学数据流动的积极性。建立科学的组织机制与传输模式能够减少科学数据“东数西算”过程中的资源投入,提高数据传输效率,促进科学数据安全流通与高效利用。
当前理论模型的研究还不够深入,科学数据“东数西算”示范验证也仅仅是在少数机构间完成,未来需要进一步优化理论模型,联合更多机构进行大规模科学数据“东数西算”,充分利用西部地区资源优势,带动西部地区产业发展。
利益冲突声明
所有作者声明不存在利益冲突关系。
