“东数西算”下的高效数据流通策略研究
2023-11-08沈林江仇树卿崔超许俊东李兆滨耿晓巧
沈林江,仇树卿,崔超,许俊东,李兆滨, 耿晓巧
浪潮通信信息系统有限公司,算力网络研究院,山东 济南 250100
引 言
互联网、边缘计算等技术的快速发展,使得数据成为促进数字经济发展的重要因素。基于文本、图片、视频等海量数据,人工智能、大数据、大模型等技术得以蓬勃发展,并在金融、安防、娱乐等众多领域发挥重要作用。
海量数据处理需要以云数据中心、智算中心、超算中心等提供的巨大的存储和计算能力为基础。从区域位置上,我国当前面临着东西部数字经济、算力资源、绿能供给等不平衡问题。相比于西部地区,东部地区数字经济存在一定优势,与此同时,东部地区数字经济的发展与有限的算力供给和较高的能耗水平矛盾日益凸显。基于此,国家正式提出东数西算工程,充分发挥东部经济优势和西部能源优势等,以促进东西部协调发展,提升区域算力调度水平,加快推进数字基础设施建设[1]。
东数西算工程需要将东部省份部分调用频率较低的冷数据流通到西部省份提供的存储资源池内,将调用频率较高的热数据存储在本地资源池内,并在业务发生时实时调用相关数据进行服务[2]。当前,产业界和学术界在智慧交通[3]、视频渲染[4]、跨资源池存储[4]、气象行业[5]等展开了广泛分析和验证。
从数据流通的角度,推进东数西算工程有利于推动实现数据要素的跨区域融通,解决东西部数据要素市场发展不均衡问题[6]。东数西算需要解决的关键问题主要包括:(1)东数西算场景下,尽管大多数情况下不涉及数据主体的变更,但存储位置和维护权限会发生变化。东部省份需要保证流通数据符合相关数据安全要求,并进行数据加解密等操作保证传输安全[7]。西部省份一方面需要保证存储、销毁等数据管理的安全性,另一方面需要保证数据服务过程中的安全性。(2)相比于本地化的数据处理,东数西算下的数据搬迁、安全保障、异地处理等,会导致时延、能耗、成本等变化,并且数据的冷热分级标准和安全标准会随着业务的动态调整而变化[7]。相关数据迁移的策略需要均衡多个系统指标进行实时优化,否则会导致业务服务质量的下降或能耗与成本的上升,与东数西算工程目标背道而驰。
在安全性方面,当前研究方向主要包括存储安全、传输安全以及流通安全等[8]。结合数据管理的分类分级策略[7],存储安全相关研究主要集中于访问控制、数据加密、数据校验以及备份策略等[9],传输安全主要集中于数据加密、身份认证、密钥管理等方面[10];在流通安全方面,隐私计算由于所具备的“数据可用不可见”的特性,成为解决数据流通安全问题的主流方法,在金融、政务等场景中有广泛应用。隐私计算主要包括联邦学习、可信计算(TEE)等,其中可信计算当前依赖于硬件支持[11],联邦学习以密码学为基础[12]。当前隐私计算相关技术存在数据治理困难、计算效率低下、部署复杂等问题[12-13],在联邦学习方面,相关研究重点聚焦于模型压缩、计算策略优化等方面[14-15];在TEE方面,学术界主要聚焦于对其计算效率的性能分析以及为应用开发提供容器化环境支撑等[16-17]。论文[16]和论文[17]详细讨论了TEE 环境下对应用的时延影响,结果表明,相比于REE 环境,TEE 下的计算时延损耗较小,而在内存访问方面可能导致较大的时延差异,在应用访问总数据量相同的情况下,内存访问与访问的数据范围、缓存空间等密切相关。
在数据流通策略方面,相关学者对边缘计算场景下的增强现实、元宇宙等数据密集型应用的数据分级、数据传输和数据缓存策略进行了广泛的研究[18-20]。其中,论文[18]基于用户访问频次等行为实现边缘计算环境下的热点数据缓存策略优化,论文[19]通过对边缘计算中的数据缓存、路由策略、计算卸载等的控制,实现了系统时延、吞吐率和资源利用率的最优化,论文[20]通过在线强化学习,对边缘节点的缓存分配策略进行动态优化以实现系统效能最优。相比之下,当前东数西算相关应用主要基于访问频次、存储时间等单一业务规则制定相关策略,需要进一步分析能耗、成本、时延、安全性等相关因子,进行灵活、综合的策略生成[21]。
基于此,本文从数据的冷热标准定义角度分析东数西算下的数据流通策略控制问题。其主要挑战在于建立东数西算的系统模型以及构建综合时延、能耗、成本等多个维度的系统优化策略。本文主要贡献在于:基于东数西算的关键流程,系统分析其中涉及的能耗、成本、时延等关键业务指标;引入深度强化学习,对东数西算中的数据流通策略进行求解,实现对系统综合业务指标的最优化;基于仿真数据验证了本文方法的有效性,并对本文中方法展开总结和研究展望。
1 系统分析
如图1所示,本文将东数西算的关键流程划分为数据分类分级、数据传输以及数据服务三部分。
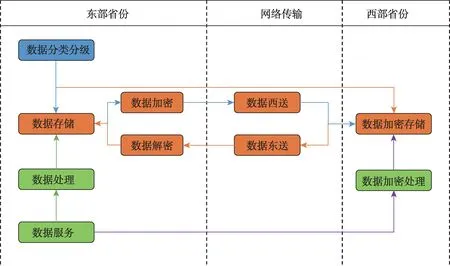
图1 东数西算数据要素流通关键流程Fig.1 Architecture of data element circulation under the “East-West Computing Resource Transfer” project
数据分类分级:如图中蓝色框图所示,东部省份需要根据数据安全标准体系确定能够传输到西部省份的数据,并且根据业务需求,定义冷热数据标准[2]。业务调用次数通常与数据存储时间有关,在数据存储周期一定的情况下,可以通过确定百分比阈值的形式,将存储时间较长的数据定义为冷数据,其余数据定义为热数据。
数据传输:如图中橙色框图所示,数据的冷热标准会随着业务的动态调整而变化,本文将数据传输看作双向流程,在数据分类分级标准调整使得冷数据体量变大时,东部省份首先需要进行数据加密,然后传输到西部,在西部进行加密存储,如图中蓝色流程;反之需要将部分数据回传到东部,将数据进行解密后进行存储,如图中橙色流程。
数据服务:如图中绿色框图所示,数据服务请求需要根据业务访问的数据位置实时下发到东部省份和西部省份,为了简化分析过程,本文将数据存储和销毁等数据管理和应用调用统一为数据服务过程。为了保证数据服务的安全性,西部省份通常采用加密形式进行数据处理,如可信执行[11]等,一般而言,对于安全性的要求会导致时延增大,因此导致西部省份的处理时延相对较大[12]。
由于加解密、网络传输等会导致时延、能耗、成本的增加,数据分类分级、数据传输与数据服务通常为异步执行,即在多次数据服务后,根据访问的数据位置以及服务质量,调整数据分类分级标准,并进行数据传输。
由上述流程可见,东数西算过程中的时延主要包括数据传输时延和数据处理时延。能耗方面,尽管西部省份的处理能耗、存储能耗要小于东部,但系统能耗还需要考虑数据传输能耗,如果频繁地进行大量的东西部数据传输,数据应用能耗难以弥合数据传输能耗,导致系统整体能耗增高。成本方面与能耗相似,需要从传输和存储、调用的整体进行分析。由于数据服务过程中传输的指令和回传结果数据量相对较少,本文忽略该部分导致的时延、能耗、成本等因素。
作为东数西算任务发起方的东部省份,为了实现系统整体能耗、成本和服务时延的最优化,需要动态调整冷热数据的划分标准,以平衡数据传输和数据服务在能耗和成本中的矛盾。因此,本文将东数西算下数据流通策略定义为冷热数据的数据分类问题。
2 系统模型
东数西算场景下,设数据总量为T,大多数业务场景下要求数据存储周期固定,因此可以近似地认为数据总量T不变。首先按照存储时间由短至长对数据进行排序,并将数据按照百分比等分为N段,即T={Tp1,Tp2…TpN} ,设当前冷热数据分类阈值为ps(ps∈{p1,p2…pN} ),则将数据{Tp1,Tp2…,Tpi} (pi=ps)定义为热数据,保存在东部省份,将数据{Tpi+1,Tpi+2…,TpN} ,(当ps=pN时,为空)为冷数据,将其发送至西部省份。
当分类阈值ps发生变化时,设上一个分类周期的分类阈值为pold,当前分类周期的阈值为pnew(pnew≠pold)。则如果pnew>pold,冷数据减少,热数据增多,则将{Tpold+1,Tpold+2…,Tpnew}回传到东部省份,反之需要将{Tpnew+1,Tpnew+2…,Tpold}发送到西部省份。
定义数据服务任务为S,S主要由服务需要访问的数据范围ds、需要访问的最大数据位置as以及服务时延要求ts组成,即S={ds,as,ts} 。对于给定数据服务,首先对比最大数据位置as与当前数据分类策略ps,如果as≤ps,则只需将数据任务下发至东部省份,否则将数据任务同时下发至西部省份。需要注意的是,数据范围ds不等同于应用处理的数据量,例如,某个应用可能多次访问同一个内存空间的数据提供服务,尽管其数据处理数据量较大,由于其访问范围小,能够充分利用芯片缓存技术,有效降低系统IO负担[16-17],在涉及数据加解密等处理流程中对系统性能有较大影响。实际系统中,M个数据服务任务组成系统待处理的任务队列Q,即Q={S1,S2,…SM} 。
一般而言,数据分类与数据服务可以异步进行,例如在进行多次数据服务后调整数据分类策略。本文主要分析数据分类策略对系统时延、能耗等的影响,为简化系统,认为数据分类与数据服务同步进行。仅需调整系统优化目标计算方法和分类策略的执行频次,即能够进一步推广到异步情况。
从时延、能耗、成本评估当前分类分级策略下的整体性能,系统时延主要由数据传输时延和数据处理时延组成,设分类阈值ps发生变化时需要传输的数据量为T′,单位数据传输时延为t0,则数据传输时延为t0T′,设数据处理时延为t1,则系统时延可以表示为:
设单位数据传输能耗为e0,数据处理能耗为e1,则系统整体能耗可以表示为:
设单位数据传输成本为c0,数据处理成本为c1,则系统整体成本可以表示为:
则对于某次数据服务,评估系统整体性能的回报函数可以定义为:
回报函数第一项衡量实际数据服务时延是否能够满足任务要求,第二项和第三项分别衡量系统的能耗和成本性能。其中α,β,γ分别为时延、能耗、成本的权重系数,在实际应用中,需要根据不同目标的数据量级、东西部差异性以及业务场景对目标的偏好程度定义。
3 求解策略
公式(4)所示的回报函数综合了系统时延、能耗、成本等多个业务指标,本文采用深度强化学习(DRL)对上述策略进行求解。基于当前生产实践中采用访问频次、存储时间等分类标准[2],分别采用随机算法、贪心算法作为基线模型,以验证深度强化学习算法优化系统回报函数的优势。
3.1 随机算法
对于每次数据分类周期,随机算法(Random)随机生成一个分类阈值ps。随机算法不需要任何系统自身和外部任务信息,相比于其他算法,尽管其可能表现效果较差,但随机探索能力能够在一定程度上反映系统性质,可以作为其他算法的基线模型。
3.2 贪心算法
在新的数据服务请求到达时,系统存在两种贪心选择,选择1:保持pnew=pold,该策略能够尽可能避免数据搬迁导致的额外成本、时延和能耗负担,但其可能导致时延服务质量的降低;选择2:令pnew=as,即总是保持将应用访问的数据搬迁到东部,以减少西部采用加密形式进行数据处理导致的处理过程中时延负担,但由于其不考虑传输因素,可能导致系统整体成本和能耗增大。除此之外,考虑到数据传输需要一定时延,从长期收益的角度,该策略也难以保证整体时延最优。
本文定义两种贪心算法,贪心算法1(Greedy-1):新的数据服务请求到达时,分别评估选择1和选择2 的系统整体性能(公式4),取两种选择中的最优。贪心算法2(Greedy-2):令pnew=as。两种算法的对比能够体现由数据搬迁导致的能耗、成本、时延负担对于系统整体性能的影响。
3.3 深度强化学习
深度强化学习基于神经网络模型,通过定义模型的动作空间、环境空间、回报函数等,在不依赖于系统模型的情况下进行策略优化,当前在边缘计算[22]、联邦学习[23]等场景中有广泛的应用。本文选择DQN[22]构建由神经网络Q组成的智能体,将东数西算系统作为外部环境,从而根据外部环境状态动态生成最优策略。
智能体的环境空间由当前待处理的任务队列以及当前的分类策略组成,即:
设系统队列长度为M,则DQN 的输入层大小为3M+1。公式(5)中环境仅取决于当前数据分类策略和队列中的任务情况,因此满足马尔可夫性要求。
定义动作空间为分类阈值的可选区间,即:
相比于随机算法和贪心算法,强化学习需要首先进行模型训练,然后将获得的模型部署到相关系统中进行策略生成。
智能体与外部环境的交互流程为:智能体感知系统当前状态sold,包括任务队列Q和当前数据分类策略pold等;将系统状态输入神经网络Q,生成最优分类阈值a,并将策略下发到系统中;系统根据分类阈值进行数据搬迁和任务处理,并根据公式(4)返回当前回报r以及新状态snew;将状态、行为、回报<sold,a,r,snew>组合输入到回放池中;从回放池中批量选择状态、行为、回报组合进行神经网络Q参数更新,其系统架构如图2所示,算法流程如表1所示。
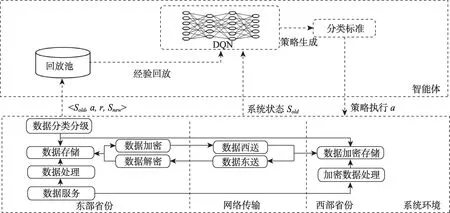
图2 智能体与系统环境架构图Fig.2 Architecture of the agent and the environment

表1 DQN算法流程Table 1 The Algorithm of DQN
4 模拟仿真
通过系统仿真模型对四类数据分类策略求解方法进行验证。假定每次应用类型和处理数据类型相同,而其处理的数据范围不同。由于应用消耗能耗和成本主要与其处理的数据量和当前算力情况相关[24],因此可以假定同一部署环境下,各个应用之间消耗的能耗和成本相对稳定,仅受部分外部环境因素影响,如动力环境、单位电价、服务器差异、利用率波动等。东部算力中心存在大量老旧数据中心,西部算力中心以新型数据中心为主,数据存储和处理能耗更低,且西部省份电力资源丰富,电价相对较低,因此单位能耗下成本更低。对仿真系统单次数据服务的能耗和成本仿真参数设定如表2所示,其中传输表示单个数据段传输能耗和成本。

表2 仿真系统能耗和成本参数Table 2 Energy and cost parameters of the simulate system
动作空间为11%~100%之间按照1%的等间隔分布,即最少保持11%的数据位于东部省份;任务设置方面,假设任务处理的数据总量相同,任务访问的数据范围在(0,100]MB 之间均匀分布,任务对于处理时延的要求在[0,0.15]间均匀分布;目标权重方面,令α=2,β=1,γ=1。
在计算时延方面,假设西部省份基于通用k8s 平台,采用基于TEE 的可信容器提供数据服务[13]。将西部省份提供数据服务相比于东部本地化处理的相对时延关系设定如表3所示。

表3 仿真系统时延参数Table 3 Time delay parameters of the simulate system
图3 为强化学习方法训练过程中单次数据服务的系统整体回报变化(公式4),训练次数为10,000次。由于基线模型(包括贪心算法和随机算法)没有模型训练过程,因此将强化学习方法训练过程与基线算法实际部署后的策略表现作对比。可见,由于贪心算法2(红色曲线)仅仅基于数据处理导致的时延负担进行策略生成,没有综合考虑能耗、成本以及数据传输过程的时延损耗,因此其系统整体性能表现相比于随机算法(黑色曲线)几乎没有改善。贪心算法1(绿色曲线)在一定程度上考虑了数据搬迁导致的能耗、成本、时延负担,因此其系统整体性能相比于贪心算法2 和随机算法的系统性能有较为明显的提升。强化学习算法(蓝色曲线)在训练初期接近于贪心算法和随机算法(<1,000次),随着训练次数增加(1,000~2,000次),深度强化学习的系统性能迅速提升,并在后续的训练过程中(>2,000次)趋于收敛,系统整体性能稳定,且明显优于其他基线算法,证明本文中方法具有较高的收敛性和稳定性。

图3 训练过程的系统回报Fig.3 System Rewards of the training process
对深度强化学习模型与基线算法生成的策略进行1,000次测试,其累计收益[∑r,公式(4)]对比如图4 所示,可见,深度强化学习的累计收益明显优于其他基线模型,其长期回报在其他基线算法的两倍以上。贪心算法1 表现优于贪心算法2 和随机算法,后两种算法的表现基本相似。

图4 系统累计回报Fig.4 System cumulative rewardst
相比于基线模型,深度强化学习性能优势的主要原因可以归结为:(1)通过整体系统指标定义回报函数(公式4),深度强化学习有效平衡了数据处理和数据搬迁过程中的能耗、时延、成本等性能指标;(2)在环境空间设计中(公式5)不仅考虑了当前的数据服务任务,还综合考虑了队列中其他待处理任务的性质,因此更加倾向于长期回报优化;(3)通过神经网络算法,深度强化学习技术能够挖掘到数据、时延等对于数据分类的隐含关系。
图5 为某次测试的系统累计时延回报,可见,深度强化学习算法(蓝色曲线)在时延方面要略优于贪心算法2(红色曲线),主要原因为贪心算法2仅考虑数据处理时延,未考虑数据传输时延,而深度强化学习算法通过综合处理、传输时延以及队列中的长期任务情况,获得较高长期回报。由于综合考虑能耗和成本指标,贪心算法1(绿色曲线)和随机算法(黑色曲线)在时延维度上表现略差于贪心算法2。
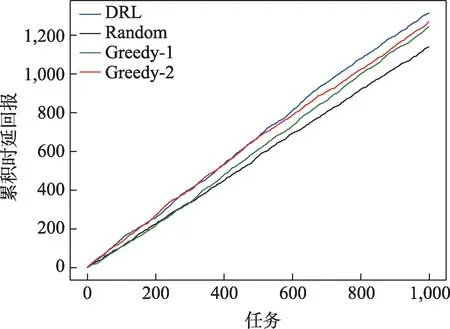
图5 系统累计时延回报Fig.5 System cumulative time delay rewards
图6和图7分别为某次测试的系统累计能耗和成本回报。可见,深度强化学习算法(蓝色曲线)在能耗和成本方面要明显优于其他基线算法。由于综合考虑能耗和成本指标,贪心算法1(绿色曲线)要略优于其他两种基线算法。而贪心算法2(红色曲线)仅考虑时延因素,其整体能耗和成本在4 种算法中表现最差。综合系统时延、能耗、成本指标,可见深度强化学习能够实现对多目标的均衡,从而达到系统整体性能最优。

图7 系统累计成本回报Fig.7 System cumulative cost rewards
5 总结与展望
发展东数西算工程,有利于落实碳达峰碳中和要求,促进东西部算力资源合理布局和数字经济的协同发展。数据流通作为东数西算下的关键要素,在传统的安全维度基础上,需要进一步综合考虑能耗、成本、时延等因素,实现系统整体最优。
本文通过对东数西算下数据流通的关键流程进行分析,并定义数据流通的主要控制因子,在此基础上对数据流通的系统优化问题进行建模,构建融合能耗、成本、时延多因素的回报函数,最后通过深度强化学习进行策略求解,系统仿真验证了本文方法在收敛性、系统长期收益和目标均衡上的优势。
基于深度强化学习的数据流通策略具有较高的通用性,在不同业务场景下,通过对环境空间和动作空间以及系统性能指标进行定义与优化,可以进一步推广到跨境数据流转[25]等相关应用场景中。
在算法选择上,本文选择通用性较高的基础算法。在东数西算等新型业务初期,使用通用性较高的基础算法即能在系统整体性能和收益等方面能够较传统方法有明显提升,并且能够有效平衡开发、设计、推广应用等开销,快速获得业务红利。在业务发展后期,随着环境复杂性和业务需求等提高,为了提升策略质量,保证业务服务水平,可以进一步采用复杂度更高的DDPG[26]、TRPO[27]等算法。
由于缺少生产系统数据,本文主要对相关理论方法进行了讨论,并采用仿真数据进行验证,同时为了便于分析,本文中方法对相关系统进行了合理的简化建模。在实际生产中,数据总量、类型、时延、能耗、成本等因素等可能受外部环境影响而实时变化,并且面临着多样化的业务需求。对本文中方法进一步推广优化,并与生产系统进行对接应用,是本文作者的下一步研究内容。
利益冲突声明
所有作者声明不存在利益冲突关系。
