基于深度学习的地铁车站站台层实时客流检测应用研究
2023-11-08吴俊演李雅卓
吴俊演,刘 霞,李雅卓
(江汉大学 智能制造学院,湖北 武汉 430056)
0 引言
城市轨道交通具有安全环保、占地面积小、运量大等优点,已逐步成为城市出行的首选交通方式。2021 年中国内地地铁总客运量达到236 亿人次,其中上海市地铁客运量达到35 亿人次以上,位居全国第一。然而,在获得便捷出行方式的同时,安全隐患也随之潜伏。由于地铁车站是一个密闭空间且人流量巨大,一旦发生火灾或恐怖袭击将会对乘客的人身和财产带来严重损害。因此,保障地铁运营安全,实时获取车站内各关键位置的客流信息十分必要。目前车站内常采用现场人工监控与视频监控相结合的方法。地铁站台处有工作人员对乘客进行引导与管理,车站值班员只能通过安防监控系统实时获取车站内客流信息,但无法直接得到乘客的准确数量,因此无法对客流量进行有效统计。
随着计算机视觉技术与深度学习技术的发展,行人检测算法已经取得了很大的进步并逐步得到应用。Zheng 等[1]从摄像头中捕捉视频,并设计一个名为CircleDet 的无锚物体检测网络来检测乘客的头部,速度可以达到每秒111 帧(FPS),精度高达97.1%;Shen 等[2]引入一种基于深度学习网络的Mask R-CNN 对象检测方法,并引入多帧处理结果的融合,以降低检测误差,单帧检测的平均准确率为73.43%,融合时间序列帧的检测结果,平均准确率为88.85%,提高了21%;Liu 等[3]提出了一种地铁乘客检测算法(MPD)来跟踪乘客的上下车情况,能够在较小的模型尺寸下快速、准确地检测地铁车厢和乘客状况;Dong 等[4]改进SSD 网络,提出针对小目标数据的过采样增强算法,准确率比原始SSD 提升了5.82%,能够适应于地铁中小目标检测;王敏[5]基于YOLO-V3 改进算法,对地铁客流的人物头肩进行检测;周慧娟等[6]将人脸检测的方法与YOLO 结合,实现在地铁复杂的人流环境下仅对人物脸部进行识别,但由于地铁站内部环境复杂且光影效果有时较差,往往无法准确提取监控画面中人物的脸部特征;Valencia 等[7]利用tinyYOLO-V4 和DeepSORT 跟踪算法来监控人群数量和社交距离;Ahmed 等[8]提出了基于5G 基础设施的多人跟踪框架。以上方法均是仅对客流进行检测,但并不具有追踪功能,无法准确统计特定时间内的客流量。何宇等[9]将YOLO-V5s 与DeepSORT 算法相结合应用到地铁场景中,对客流量进行实时检测,但未考虑人流量巨大时,行人相互遮挡引起的漏检问题,而且未对检测系统的速度与精度进行系统评估。
为了更好地应对地铁站台层复杂的环境以及更准确地统计站台层的实时客流量,本文采用了YOLO-V5 目标检测算法与DeepSORT 追踪算法相结合的方法。首先,在目标检测算法方面,将行人全身检测改为头肩部检测,以减小在客流量较大时,因行人相互遮挡导致的检测误差;然后,重新训练DeepSORT 中的ReID 模型,只提取行人头肩部特征,从而减小追踪过程行人ID的频繁切换;最后,将优化好的行人检测追踪模型应用到地铁站台层客流检测中,根据实际检测场景提取并统计客流信息。
1 行人检测与追踪模型优化
为实时获得地铁站台层的行人人数、拥挤程度、进出人数以及行人速度等信息,需要利用目标检测算法对摄像头拍摄视频的每一帧图像进行目标检测,得到图像中的行人信息。之后,利用目标追踪算法,对行人进行实时追踪,实现客流信息的统计。因此要提高检测性能,需分别对行人检测模型与追踪模型进行优化。
1.1 行人检测模型优化
在地铁车站中,摄像头一般布设在一些关键位置的天花板上,由于地下站台层高度有限,摄像头离地面距离一般在2.5~ 6 m。当客流高峰到来时,站台层的客流密度可达到8 人/m2,此时行人之间存在大量互相遮挡,若采用检测人体全身的方式采集客流信息,将产生极大误差,影响地铁站台层客流信息的检测精度。图1(a)为站台层进出口位置图片,图中实际有22 人。当使用传统基于COCO 数据集的YOLO 预训练模型检测人体全身时,仅能检测到14 人,如图1(b)所示。因此,本文自制Headshoulder 数据集,将检测模型改为仅检测人体头部和肩部位置。

图1 基于YOLO 算法的行人全身与行人头肩部检测对比图Fig.1 Comparison figure of whole-body and head-shoulder detection based on the YOLO algorithm
首先在武汉地铁各车站中的主要场景与客流密集的瓶颈位置进行图像与视频采集工作,如车站站台、站台上下行通道、换乘通道、车站进出通道、安检口、闸机等处;之后使用Labelme 标注工具对行人头肩部进行标注;然后通过旋转、平移、镜像等手段来增加训练样本的数量以及多样性,提升模型的鲁棒性;最后将数据集划分为训练集、测试集、验证集,其中训练集中样本数量4 566 个,测试集样本225 个,验证集样本450 个。
使用YOLO-V5 的s6 训练模型对Headshoulder 数据集进行训练,验证站台层行人检测效果,结果如图1(c)所示。图中,检测模型仅框选行人头部肩部信息,避免了因身体遮挡导致的行人漏检情况,实际行人22 人,测得行人18 人,召回率从63.6%提升至81.8%。
本文采用YOLO-V5 目标检测算法对站台层的客流量进行实时检测,该算法为不同应用场景提供了多种预训练模型框架。为考查不同框架在地铁站台层行人检测中的性能,使用Headshoulder 数据集对7 个不同的预训练模型进行训练,分别为YOLO-V5n、YOLO-V5n6、YOLO-V5s、YOLO-V5s6、YOLO-V5m、YOLO-V5m6、YOLO-V5l。
本文训练的硬件配置采用Intel I7-10700 处理器,系统内存32 GB,显卡为NVIDIA RTX3060,显存12 G;软件环境是Windows 10,开发语言为Python3.9 和Pytorch 深度学习框架。训练不同大小模型时保持超参数一致,batch-size 设置为16,epoch 设置为200,置信度阈值设置为50%。为考查训练得到的各模型性能,分别对同一地铁站台层场景进行检测,检测结果见表1。由表1 可知,预训练模型越大(Params),模型准确率(mAP)越高,检测相同场景时的召回率(Recall)越高,但速度(FPS)较慢。其中,YOLO-V5s 模型综合性能较强,在保证准确率较高的同时,处理速度也较快。检测结果如图2 所示,其中图2(a)为地铁站台行人原始场景图,YOLOV5s 与YOLO-V5l 模型的检测结果分别如图2(b)、图2(c)所示。
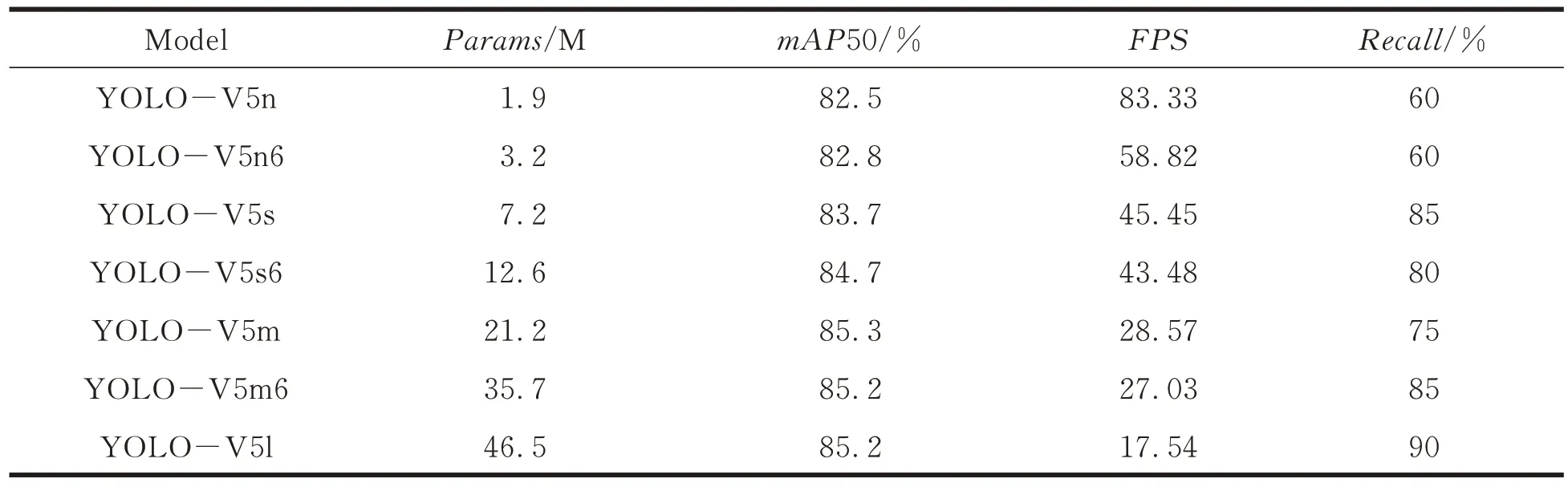
表1 不同YOLO 模型在地铁车站站台层检测性能汇总表Tab.1 Detection performance summary of different YOLO models at the subway station platform

图2 YOLO-V5s 与YOLO-V5l 模型行人检测效果对比图Fig.2 Pedestrian detection effect comparison between the YOLO-V5s and the YOLO-V5l model
1.2 行人追踪模型优化
使用目标检测算法能获取监控视频每帧图像的行人人数信息,但无法对车站人流量和行人速度进行统计,因此还需要引入目标追踪算法。DeepSORT[10]作为目前主流之一的多目标追踪算法,相较于EAMTT[11]、POI[12]、SORT[13]等其他算法综合性能较好。DeepSORT 延续了SORT 中卡尔曼滤波和匈牙利算法(IOU 匹配)两个核心算法,在此基础上引入了外观模型ReID[14]以改善追踪目标被遮挡之后再出现从而导致的ID 频繁切换问题。在SORT 算法中当一个目标被遮挡后再次出现时,其计算得到的相似度矩阵差异明显,轨迹匹配失败导致追踪中断。DeepSORT 算法在IOU 匹配之前进行级联匹配,利用ReID 计算得到追踪器中的预测结果与当前检测所有结果的相似度矩阵,计算两者之间的马氏距离;利用马氏距离筛选掉相似矩阵中不匹配项,之后进行IOU 匹配,增强在追踪过程中的鲁棒性。
DeepSORT 中ReID 读取的权重模型是由PersonReID 数据集训练得到的,该数据集中的图像均为行人全身图。在复杂的地铁环境中,往往存在人群相互遮挡的情况,无法对行人全身特征进行提取与关联。因此将Headshoulder 数据集转化为Mars 数据集格式[15],利用Wide Residual Network[16]进行特征提取。
将训练好的ReID 模型应用于实际场景,考查其检测性能。图3(a)为使用PersonReID 模型的追踪结果,红框中行人在立柱遮挡前的ID 为22,绕过立柱重新出现后的ID 变为25,追踪丢失重新分配新ID。使用HeadshoulderReID 模型的追踪结果如图3(b)所示,红框中行人ID 在立柱遮挡前后没有发生变化,ID 编号始终为17,成功保持追踪。由此可见,使用HeadshoulderReID 模型能够降低行人ID 的频繁切换,减小客流信息的统计误差,有效提高追踪性能。

图3 PersonReID 模型与HeadshoulderReID 模型追踪效果对比图Fig.3 Tracking comparison between PersonReID and HeadshoulderReID model
2 站台层客流拥挤程度检测
在地铁车站中,乘客一般通过扶梯或楼梯进出站台,并停留在站台候车区等待接驳。不同位置的客流具有不同特点,可采集不同信息。站台候车区人员流动性不高,但在高峰时段人群密集,容易发生互相遮挡,影响检测精度。在进出口扶梯处,乘客流动性很高,需要实时统计进出站台人数、行人速度等信息。因此,不同场景应采用不同检测模型和方法。
站台候车区域的客流检测无需实时追踪行人,可以选择检测精度高、FPS较低的模型。根据表1 中各模型的检测参数,将YOLO-V5l 模型应用于站台候车区域客流检测中。
检测结果如图4 所示,检测系统每隔两帧对候车区的画面进行处理,检测行人头肩位置,统计乘客数量,再根据人数给出当前站台的拥挤程度,当人数超过阈值时,向车站运营部门发出报警信息。
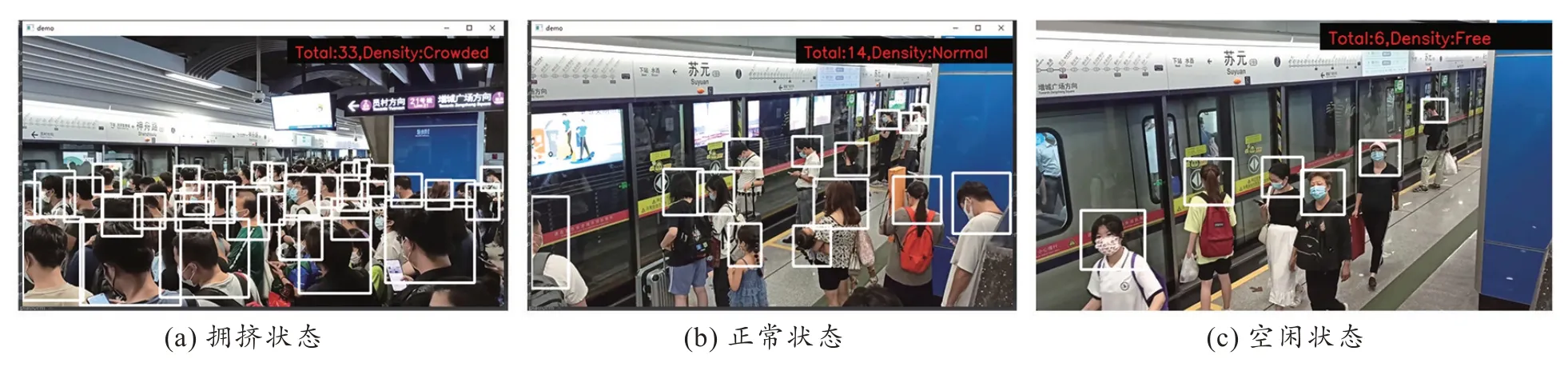
图4 站台候车区客流检测图Fig.4 Passenger flow detection map of the platform waiting area
3 站台层出入口客流检测
对于站台层出入口扶梯处,检测系统不仅需要检测每帧乘客人数,还要对每个乘客进行追踪,实现进出站台人数统计和乘客步行速度统计。因此,选择FPS和mAP均较高的YOLO-V5s模型用于行人检测,将检测结果代入DeepSORT 进行行人追踪。将该算法应用于站台层扶梯处的客流信息检测,结果发现,当乘客人数增加时,检测画面出现明显卡顿。考察目标检测与目标追踪算法的耗时情况,如图5 所示,当客流较小时,追踪算法和目标检测算法用时相当;当出现客流高峰时,追踪算法可达目标检测算法耗时的4 倍以上,因此需要对目标追踪算法进行优化。
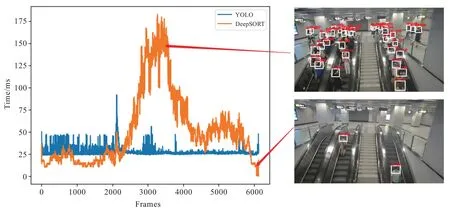
图5 检测算法与追踪算法耗时对比图Fig.5 Time-consuming comparison between detection and tracking algorithm
在DeepSORT 算法中,需要计算两帧之间检测框的距离以及相似度,并对输入检测框与自身Tracker 中已存在的所有轨迹进行一一比对。因此检测框数量越多,其算法处理的速度就越慢。为减少待追踪检测框的数量,规定只对进入指定区域的行人进行追踪匹配,超过该区域则放弃追踪并将其对应的轨迹ID 从Tracker 中删除,减少Tracker 中已存在的轨迹数量以降低匹配计算量。设定的区域范围为客流的必经区域(楼梯处),因此对最终的客流检测统计结果无影响。通过上述优化,DeepSORT 在追踪进出口通道客流的效果如图6 所示。原DeepSORT 算法平均FPS为12 左右,优化之后平均FPS提升至38,速度大幅提升。
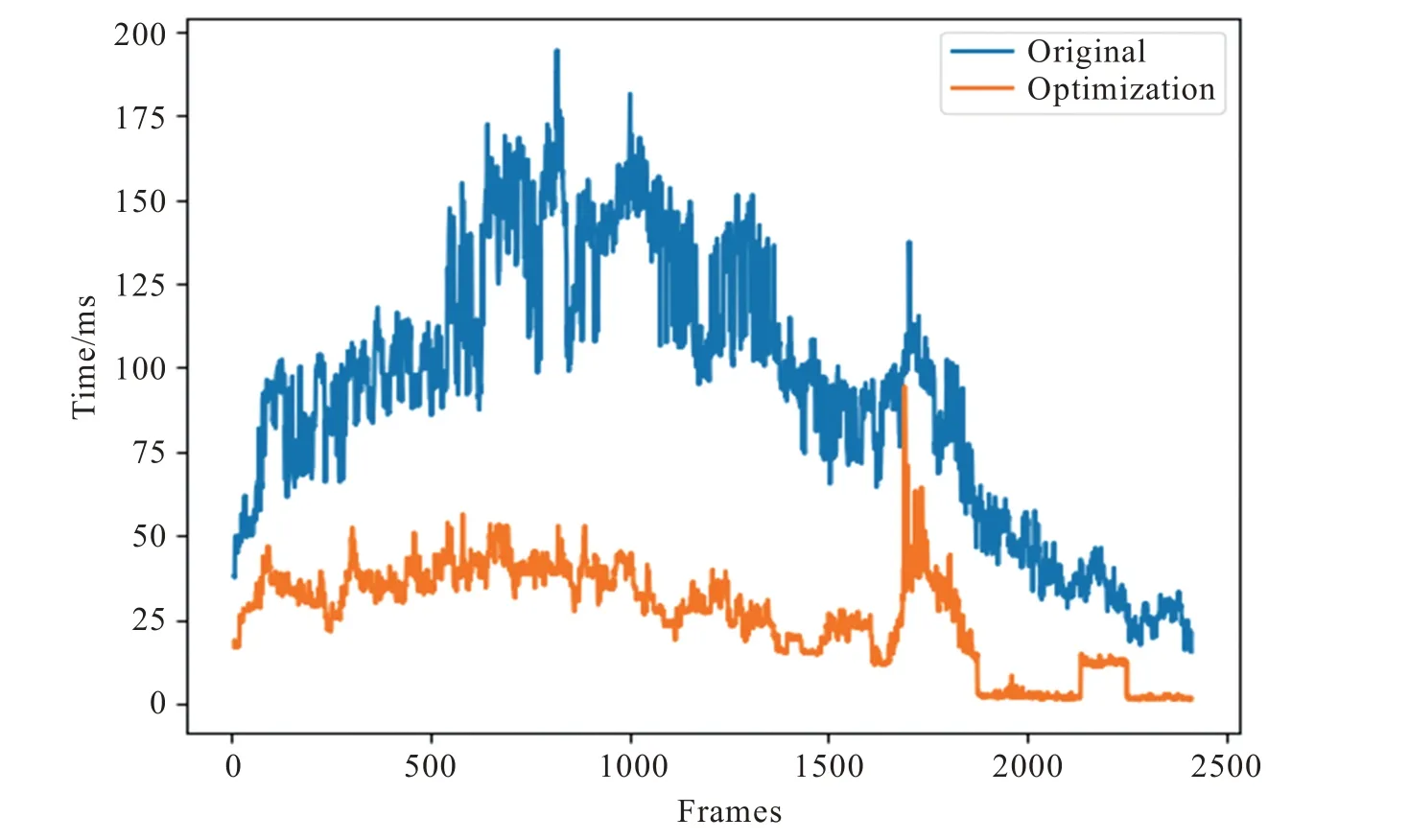
图6 DeepSORT 追踪算法优化效果图Fig.6 Optimization effect diagram of DeepSORT tracking algorithm
在站台层进出口扶梯处,利用优化后的客流信息检测算法,对当前上行人数(current uplink number)、当前下行人数(current downlink number)、上行总人数(total uplink number)、下行总人数(total downlink number)、平均上行速度(average uplink speed)和平均下行速度(average downlink speed)进行检测与统计,结果如图7 所示。结果表明,在地铁站台层出入口处,上下行人数统计准确率达到86%,平均FPS为35,能够满足客流信息实时检测的应用需求。

图7 站台通道客流信息检测结果图Fig.7 Passenger flow information detection results of platform corridor
4 结语
使用YOLO-V5 检测算法对站台层候车区客流进行统计,直观地展示候车区的客流情况以及拥挤程度;结合DeepSORT 追踪算法对站台层出入口进行客流统计,并对客流速度进行计算和显示,能帮助地铁工作人员对客流量进行实时监控。该方法相较于传统监控方法可以实时准确获得多种地铁客流信息,且投入成本、运营成本均较低,具有较好的应用价值。目前,使用YOLO-V5 目标检测算法依然会存在漏检情况,在目标追踪过程中也存在ID 切换的情况。如何提高目标检测的精度并提高追踪性能,需要进一步研究与探索。
