动态场景下基于注意力机制与几何约束的VSLAM 算法*
2023-11-08陈孟元刘晓晓韩朋朋
徐 韬,陈孟元,3*,刘晓晓,韩朋朋
(1.安徽工程大学电气工程学院,安徽 芜湖 241000;2.高端装备先进感知与智能控制教育部重点实验室,安徽 芜湖 241000;3.安徽工程大学产业创新技术研究有限公司,安徽 芜湖 241000)
同步定位与建图(Simultaneous Localization and Mapping,SLAM)是实现移动机器人完全自主导航的关键技术,传统SLAM 采用激光雷达获取周围障碍物的信息,然而当遇到玻璃环境时易发生激光穿透玻璃导致定位精度较低。 使用视觉传感器作为移动机器人的视觉SLAM 算法可以较为容易地捕捉环境中的信息、跟踪场景中的动态目标,因此视觉SLAM(Visual SLAM,VSLAM)得到了广泛的应用[1-3]。
近年来, 较为成熟的SLAM 系统有ORBSLAM2[4]、LSD-SLAM[5]、RGBD SLAM[6]和RTABMap[7]。 但是,它们的大多数是基于静态环境假设的,在动态场景下的建图效果会大幅下降。 因此,怎样提高SLAM 系统在动态环境下的准确性成为一个重要课题。 目前针对动态场景下的SLAM 算法主要有三类:几何方法、深度学习方法以及几何与深度学习结合的方法。 在几何方法中,艾青林等[8]提出了一种动态环境下基于改进几何与运动约束的机器人RGBD SLAM 算法,先将特征点分为静态、状态未知、可疑静态、动态和错误匹配五类,再利用几何约束对静态特征点进行筛选。 Li 等[9]选择深度边缘点来寻找对应关系,并设计了一种静态加权方法来降低动态点的影响。 在深度学习方法中,通常采用深度学习中的目标检测和语义分割技术。 Li 等[10]使用语义分割网络SegNet[11]对图像进行分割,然后进一步处理以区分动态对象。 Liu 等[12]采用不同的语义分割方法来检测动态对象并去除离群点。 在几何方法和深度学习结合的方法中,由深度学习网络提供有关动态对象的语义先验信息[13],随后通过几何约束进一步细化以过滤动态对象出现的特征。Wu 等[14]针对YOLO[15]进行了改进,提出了Darknet19-YOLOv3 的轻量级目标检测网络获取动态物体的语义信息,然后提出一种Depth-RANSAC 算法筛选动态点,以提高系统的实时性和精度,但是目标检测网络易发生动态物体检测不完整,产生漏检测,导致语义信息缺失,从而难以精确去除动态点,降低了系统定位精度。 Bescos 等[16]提出使用实例分割网络Mask R-CNN[17]精确分割运动目标(人和车等)边界,并结合多视角几何方法检测潜在动态物体。 该算法依据两帧中同一关键点的变化角度判断该点是否属于动态点,但在特征跟踪过程中关键点变化角度易受到噪声影响,并且使用的实例分割网络面对物体外观缺失情况分割效果较差。 Yu 等[18]提出了DS-SLAM,将语义分割网络SegNet 和移动一致性检测方法相结合检测场景中的动态物体,以过滤出场景中的动态信息。 显著提高SLAM 系统在高动态环境下鲁棒性和稳定性,但该方法在剔除动态特征点后,易发生因特征点过少而特征跟踪失败。
综上所述,现有的SLAM 算法易出现动态物体检测不完整以及难以准确判断潜在动态物体的运动状态等问题,本文提出一种动态场景下基于注意力机制与几何约束的VSLAM 算法,本文目标检测网络通过将坐标注意力(Coordinate Attention,CA)机制[19]嵌入YOLOv5 主干网络的残差单元,并引入自适应空间特征融合模块(Adaptively Spatial Feature Fusion,ASFF),实现对相机视野中外观缺失物体的检测,并提出一种双重静态点约束方法以解决潜在运动物体的运动判断问题。 通过在公开的TUM 数据集进行验证,测试结果表明本文算法与ORB-SLAM2 算法、DS-SLAM 算法、DynaSLAM 算法相比,在定位精度等方面有较大优势,表现出了良好的构图能力。
1 系统整体框架
图1 所示为系统整体框架。 本文针对传统SLAM算法易出现动态物体检测不完整以及难以准确判断潜在动态物体的运动状态等问题,提出一种动态场景下基于注意力机制与几何约束的VSLAM 算法。 在潜在动态物体检测阶段,通过本文所提的AFNET(Attention mechanism and adaptively spatial feature Fusion target detection NETwork)目标检测网络对图像信息中的潜在动态物体进行目标检测,并提取图像的ORB 特征点。 在基于双重静态点约束的位姿优化阶段,通过DBSCAN(Density-Based Spatial Clustering of Applications with Noise)密度聚类算法初步提取潜在动态物体的静态点,生成初步静态点集合,并使用其进行初步位姿估计,然后使用双重静态点约束方法,进一步确定物体真实运动状态,并剔除动态点,再使用全部的静态点集合进行二次位姿优化,提升系统精度。
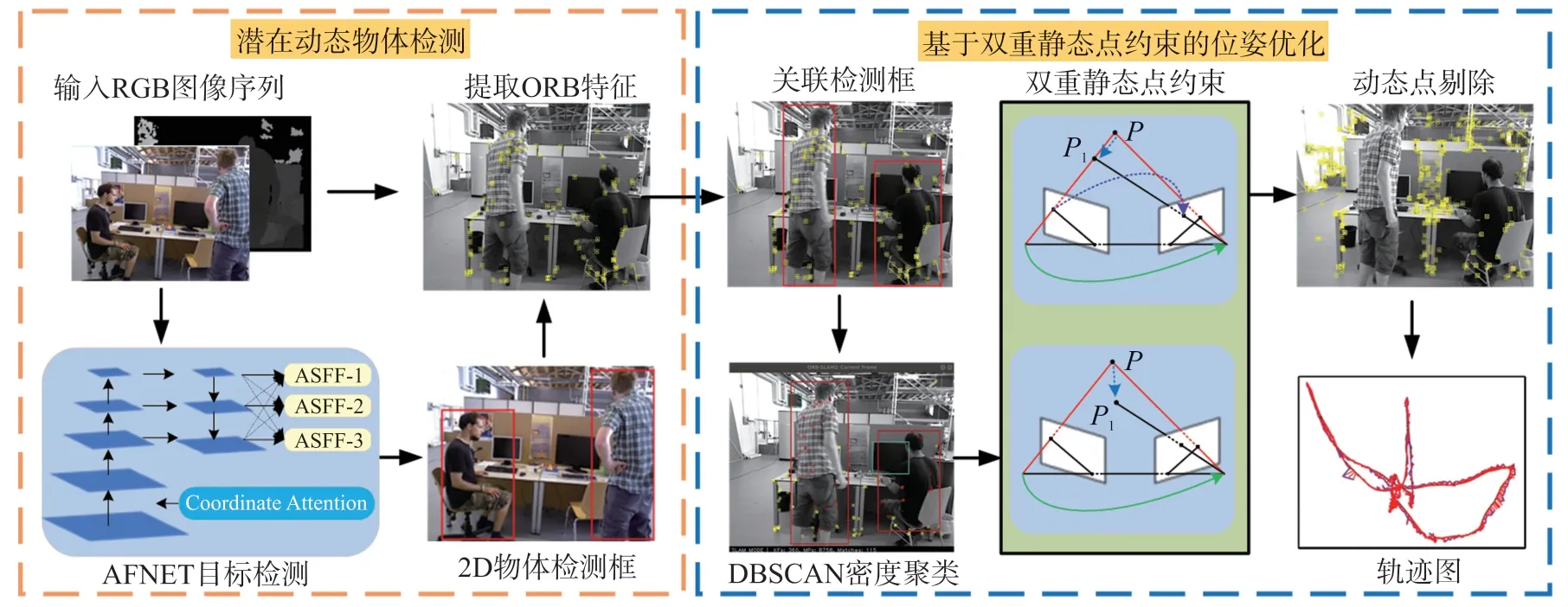
图1 系统整体框架
2 潜在动态物体检测
图2 所示为YOLOv5 目标检测在物体外观严重缺失和物体外观轻微缺失时发生的漏检测,圆圈为本文所作辅助标记。 针对待检测物体在相机视野中的外观缺失易导致漏检测问题发生,本文提出一种聚合注意力机制自适应特征融合的目标检测网络AFNET。 AFNET 网络结构如图3 所示。 该网络将CA 注意力模块嵌入YOLOv5 的主干网络CSP1_X(X=1,2,3;代表网络中残差单元个数)的残差单元中形成CA 残差单元,最终构造对外观缺失区域特征更加关注的聚合注意力模块AttenCSP1_X(X=1,2,3;代表网络中CA 残差单元个数),同时为更有效地进行特征融合,在特征金字塔FPN 的基础上引入自适应空间特征融合ASFF 模块,构造自适应空间特征融合金字塔,增强网络的特征提取能力,提升对外观缺失物体的目标检测精度。

图2 YOLOv5 漏检测
2.1 聚合注意力模块
视觉SLAM 系统运行过程中,相机视野中外观缺失的物体占据环境较大区域,若无法识别出其中的潜在动态物体,将对SLAM 系统的稳定性造成干扰。 针对这一问题,本文在YOLOv5 的基础上引入CA 注意力模块。 注意力模块加入网络层的位置与目标检测网络的学习和表征能力关系密切。 若将注意力模块加入特征金字塔FPN 或检测头部分,不仅难以将冗余信息和关键特征从特征图中区分开来,还会传递错误信息,从而降低网络提取特征的能力。因此,本文对YOLOv5 主干网络进行改进,将CA 注意力模块嵌入到CSP1_X 的残差单元中,构造CA残差单元,最终形成聚合注意力模块。 首先,通过CA 注意力模块突出外观缺失区域特征图的关键特征,同时弱化无关信息,再经过残差网络深入提取特征,最后合并输出以提升目标检测的精度。 聚合注意力模块如图4 所示。

图4 聚合注意力模块
CA 残差单元利用坐标注意力机制对通道信息与空间位置信息均敏感的特性生成对外观缺失区域更具有判别能力的特征表达,该模块不仅增大了感兴趣区域特征通道权重,还能获取感兴趣区域空间位置,充分突出外观缺失区域有效特征信息,同时避免了干扰信息影响。 CA 残差单元具体计算方式如式(1)所示:
式中:M'为上一个CA 残差单元的输出特征,M"为CA 残差单元的输出特征,H(·)表示使用CA 注意力提取特征,f1×1和f3×3分别表示1×1 和3×3 的卷积层,σ(·)表示leakyrelu 激活函数,Bn为归一化参数。
2.2 CA 注意力机制
现有的SE(Squeeze-and-Excitation)通道注意力机制[20]对内部通道信息进行关注,但却忽视了空间位置信息。 而卷积注意力模块(Convolutional Block Attention Module,CBAM)[21]为了引入空间位置信息,使用了在通道上全局池化的方法,但这种方法却又只考虑了局部范围的信息。 因此本文使用CA 注意力机制,如图5 所示。 通过在通道注意力中嵌入空间位置信息,生成对通道信息和位置信息均敏感的特征图从而使得网络更加关注高维特征信息,提高网络对外观缺失区域的注意力。 CA 注意力机制首先对输入的特征图XC×H×W使用尺寸(H,1)和(1,W)的池化核,分别对水平和垂直方向的每个通道进行池化,得到一对大小为C×H×1 和C×1×W的特征图。 因此,高度为h的第c个通道和宽度为w的第c个通道的输出如下:
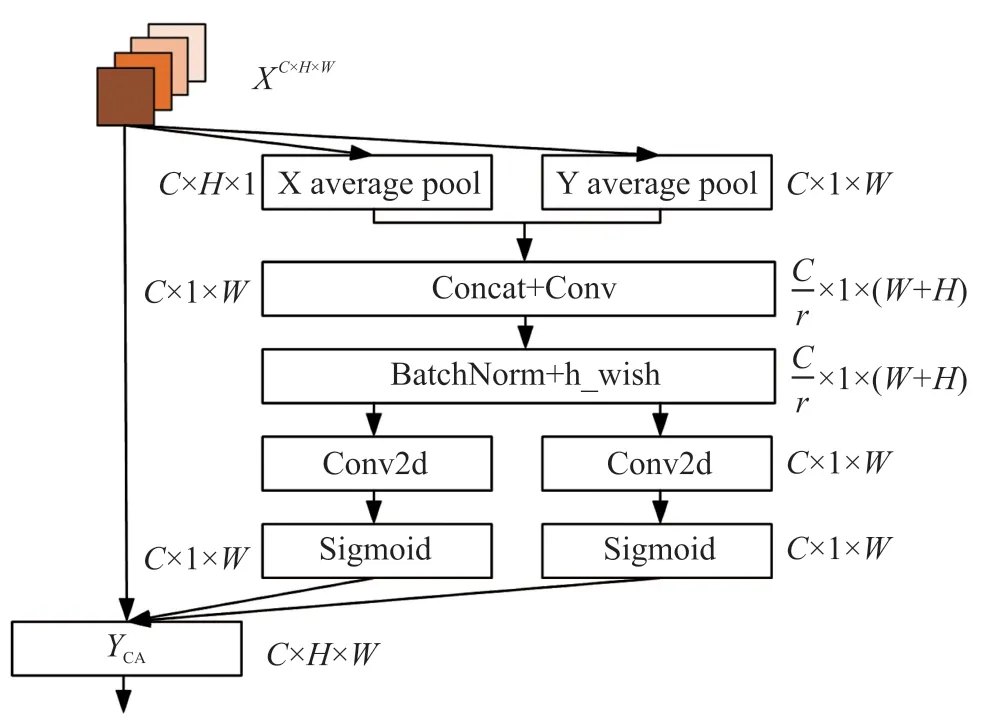
图5 CA 注意力机制
式中:xc(h,i)和xc(j,w)分别为水平和竖直方向的特征,(h)和(w)分别是编码后的水平张量和竖直张量,H,W和C分别代表输入特征图的长、宽和通道数。 接着对这两个张量进行融合操作并且用1×1卷积函数实现降维,如式(4)所示:
式中:[zh,zw]为融合操作,f1×1为1×1 卷积函数,F∈RC/r×(H+W)为空间信息在水平和竖直方向上进行编码的中间特征映射,δ(·)为h_wish 激活函数,r是下采样步长。
接着将F沿着空间维度重新分解为两个单独的张量Fh和Fw,然后分别使用1×1 卷积函数将Fh和Fw通道数变为与X一致,得到如下结果:
式中:σ(·)为sigmoid 激活函数,gh和gw分别为水平方向和竖直方向的权重。 最终CA 注意力模块的输出表示为:
2.3 自适应空间特征融合金字塔
原YOLOv5 网络中的FPN 结构仅将不同特征层调整为统一尺寸后再进行累加,但是不同特征尺度之间不一致易造成融合特征图噪声增大从而导致效果变差。 针对这一问题,本文引入ASFF 模块构造自适应空间特征融合金字塔,该算法使网络能够自适应地学习各个特征层上每个位置的权重,使重要信息的特征在融合时占据主导地位,通过在空间上过滤无用信息进而抑制反向传播时的不一致,改善特征比例不变性。 最终增强目标检测网络对动态物体特征识别能力。 ASFF 结构如图6 所示。 它包括特征缩放和自适应融合两个部分。
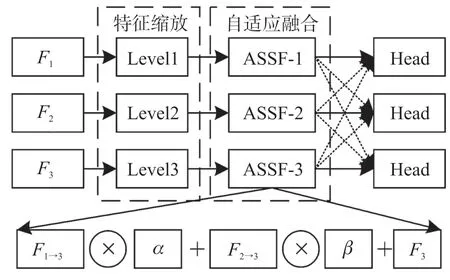
图6 ASFF 结构
F1、F2、和F3为主干网络后的三个特征层,F1和F2经过特征缩放后分别生成与F3尺寸相同的特征层F1→3和F2→3。
AFNET 网络参数设置如表1 所示。 如输入列的[-1,6]表示为来自于上一层和第6 层合并输出,层编号从0 开始,张量信息代表该模块的输入通道数、输出通道数、卷积核大小、步长等参数信息。

表1 AFNET 网络参数设置
3 基于双重静态点约束的位姿优化
目标检测网络仅能识别出潜在动态物体,但是对潜在动态物体的运动状态缺少有效判断。 由于动态物体上也可能存在静态特征点,若直接剔除检测框中的所有特征点会造成很多静态特征点被剔除,影响姿态估计的准确性。 因此,本文首先使用DBSCAN 密度聚类对检测框内的前景点和背景点进行区分,筛选初步静态点集合进行初步位姿估计。 然后提出一种双重静态点约束的方法,进一步准确判断特征点的真实运动状态,从而得到更加精确的静态点集合,并进行二次位姿优化,提升系统的精度。
3.1 DBSCAN 密度聚类
与语义分割方法相比,目标检测网络的实时性更高,但不能提供准确的分割掩码从而导致分类为动态物体的检测框中静态背景众多,静态特征点的误删除将减少相机位姿优化的约束,降低相机位姿估计的准确性。 行人作为前景的非刚体,其深度具有很好的连续性,并且通常与背景深度有很大的断层。 因此,本文引入DBSCAN 密度聚类算法来区分分类为人的检测框的前景点和背景点。 本文采取自适应的方法确定DBSCAN 密度聚类算法的邻域半径eps 和邻域样本数的阈值minPts,聚类完成后,将簇群C={C1,C2,…,Ck}中平均值最低的样本作为检测框的前景点。然后,将背景点内的特征点设置为初步静态点并用集合Uk表示,用于后续的位姿估计。
图7 所示为DBSCAN 密度聚类结果,图7(a)为未使用DBSCAN 密度聚类,检测框内的特征点全部被标记为动态点并剔除,不参与位姿计算;而图7(b)为经过DBSCAN 密度聚类后的特征点分类结果;由图可知,2 个检测框内背景点内的特征点都被正确地归类为静态点,参与位姿计算过程,因此,采用密度聚类区分静态点能在较大程度上提高后续位姿估计的精度。

图7 DBSCAN 密度聚类结果
3.2 初步位姿估计
对检测框内的静态点和动态点进行区分之后,使用当前帧Fk中的初步静态点集合Uk进行初步位姿估计,Uk在三维空间中的集合为Ck。 设空间中点的三维坐标为ci=[Xi,Yi,Zi]T,其对应的投影像素坐标为ui=[ui,vi]T,且ui∈Uk,ci∈Ck,则有:
式中:ξ∈se(3)是相机位姿R,t的李代数形式,di为对应静态点深度,e为误差项,K为相机内参矩阵。式(10)可写成以下矩阵形式:
最后,通过将误差求和构造最小二乘问题并使其最小化,即可得出最小化重投影误差:
3.3 双重静态点约束
若直接使用初步静态点集合解算位姿,则会存在一些在当前场景处于静止状态的对象被错误地归类为动态特征的问题(如坐在椅子上不动的人),为了进一步判断场景中特征点的真实运动状态,如其在当前场景中处于静止状态,则可将其确定为静态特征点,从而增加参与位姿计算的特征点个数。 针对以上问题,本文提出一种双重静态点约束的方法进一步获得特征点的真实运动状态,并对位姿进行二次优化。
图8(a)所示为几何约束示意图,O1和O2分别为前一帧I1和当前帧I2相机光学中心,P为空间中的某一点,其在I1、I2上的投影分别为P1、P2,P1、P2的归一化像素坐标分别为X1=[u1,v1,1]、X2=[u2,v2,1],F为基础矩阵,应该满足:
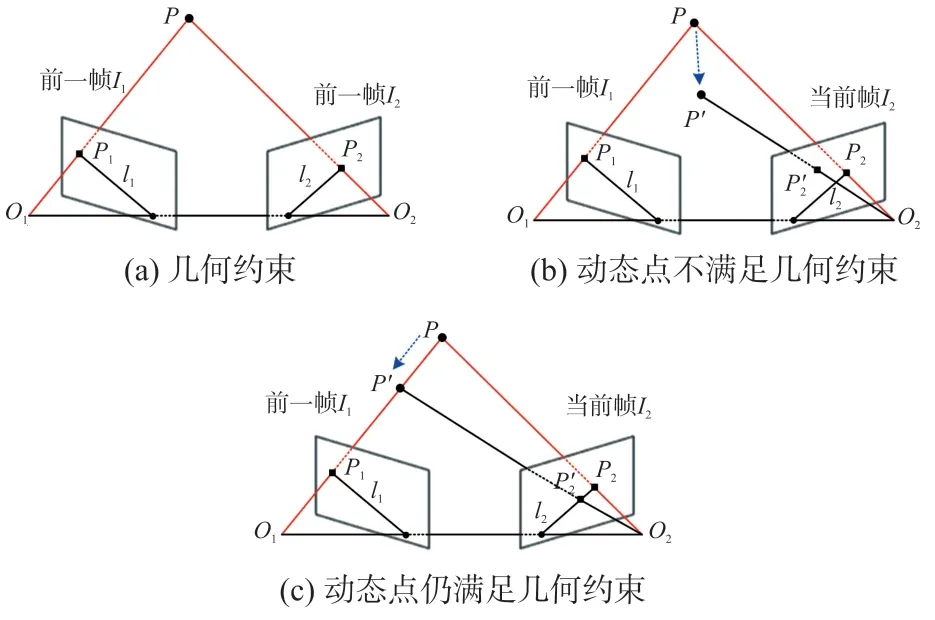
图8 几何约束示意图
若F矩阵的计算足够准确,则P2在极线l2上,满足式(13)约束条件。 设极线方程为Ax+By+C=0,P2到极线的距离为D,则此时满足:
然而在实际情况中,有以下三种情况不能满足以上约束:①由于特征提取和F矩阵估计的不确定性,P2可能不会准确地落在极线l2上,不能满足极线约束。 ②空间点发生运动,如图8(b)所示,相机由前一帧移动至当前帧位置时,P点运动到P',P'在当前帧I2的投影P'2不在极线l2上,不能满足以上约束。 ③当特征点沿着相机光轴方向运动时,如图8(c)所示,空间点P点运动到P',此时P'在当前帧I2的投影P'2仍然在极线l2上,满足极线约束,但实际P点是动态点。 综上所述,只使用极线几何约束来确定动态点并不严谨,具有一定的局限性。 因此本文提出一种双重静态点约束方法准确确定动态点,为位姿估计筛选出良好的静态点。
定义空间中3D 点S在关键帧K上的实际投影点为S1,在当前帧C中的投影点为S2(x1,y1),由当前帧C中与S1匹配得到的点为S'2(x2,y2),双重静态点约束方法如式(15)所示:
式中:T表示静态点得分,D为S2到极线的距离,距离越接近0,说明投影点S2越有可能在当前帧的极线l2上,则该点是动态点的可能性越小;Δd为S2与S'2的欧氏距离,Δz为P点在当前帧的投影深度z1与实际深度z2的差值。λ和μ为权重,当距离D大于设定阈值τD时,取λ=1,μ=0,表示不需计算位置差与深度差便可确定动态点。 否则取λ=0,μ=1,若Δd大于阈值τd或Δz大于阈值τz时,则认为S点为动态点。 最后计算临界点T的得分并设定临界阈值τT,若T>τT,则确定S点为动态点。
3.4 二次位姿优化
为了提升位姿估计的精度,使用双重静态点约束方法确定静态点后,仍然使用最小化重投影误差对位姿进行二次优化,初始值设置为初步位姿估计值,参与优化的特征点为初步静态点集合Uk以及使用双重静态点约束方法筛选出的静态点。
4 实验结果与分析
本文仿真实验平台电脑配置为:Ubuntu18.04 版本Linux 操作系统,Intel(R)Core(TM)i5-11400F@2.60 GHz,显卡为RTX3060,16G 内存。 实验所用的数据集均来自公开的TUM RGB-D 数据集。
4.1 潜在动态物体检测实验
图9 所示为本文所提AFNET 与YOLOv5 的热力图效果对比,由图可知,YOLOv5 未使用聚合注意力模块,难以对外观缺失行人形成有效聚焦。 本文所提聚合注意力模块,对目标物体有所侧重,改善了对目标区域的关注程度,提升了对目标物体的聚焦能力。
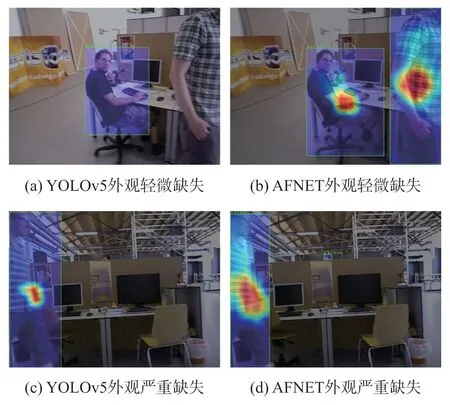
图9 热力图对比实验
在动态场景中,物体外观缺失会造成目标检测网络发生漏检测现象。 图10 所示为本文算法和其他各种算法在物体外观严重缺失和物体外观轻微缺失状态下的检测结果对比。 由于YOLOv4 与YOLOv5 缺少对外观缺失目标区域特征增强网络层,导致在物体外观缺失情况下易造成目标检测失效。 与前两种算法相比,AFNET 设计了聚合注意力模块且进行了空间特征自适应融合,使AFNET 专注外观缺失区域信息,同时抑制无用信息,从而提升对外观缺失物体的目标检测效果。

图10 潜在动态物体检测对比
表2 为AFNET 与不同算法性能对比表,采用全类平均精度mAP(交并比=0.5:0.95)、平均精度AP50(交并比=0.5)、AP75(交并比=0.75),COCO 数据集定义的小中大目标对应的mAP:APS(目标面积<322像素)、APM(322像素<目标面积<962像素)、APL(目标面积>962像素),作为模型精度的评价标准。 由表中数据可知,AFNET 算法mAP 与YOLOv4和YOLOv5 算法相比提高了12.2%、5.5%。

表2 AFNET 与不同算法的性能对比
4.2 动态点剔除实验
图11 所示为特征点提取消融实验图,矩形方框为本文辅助框。 由图可知,虽然ORB-SLAM2 算法使用了BA 优化算法,可将少量外点剔除,但在高动态场景下,ORB-SLAM2 算法明显无法继续剔除动态点。 图11(b)中仅采用DBSCAN 算法将人身上的特征点进行聚类并标记为动态点,但难以区分物体的运动状态,如框中静态物体上的特征点被标记为动态点。 图11(c)仅采用双重静态点约束方法可以将物体的特征点正确归类为静态点和动态点,但仅使用该算法实时性不足。 本文算法结合语义信息,先使用DBSCAN 密度聚类区分动态点和静态点,然后采用双重静态点约束进一步确定特征点的真实运动状态。 因此本文算法能对潜在动态物体进行精准判断并剔除动态物体,且将矩形框内在当前场景为静态的特征点正确保留下来,不仅增加了参与位姿计算的特征点个数,还避免了由于大量使用双重静态点约束导致系统实时性不足的问题。

图11 特征点提取消融实验
表3 所示为本文算法仅采用DBSCAN、本文算法仅采用双重静态点约束和本文算法在TUM 序列的绝对轨迹误差(ATE)和时间对比。 由表中数据可知,由于DBSCAN 不能判断物体的运动状态,所以ATE 较大,但该算法实时性较好,单帧平均处理时间17.04 ms。 仅采用双重静态点约束去除动态点ATE 较小,但是实时性不足,单帧处理时间大于60 ms。 本文算法由于先使用BDSCAN 初步区分动态点,再使用双重静态点约束进一步确定特征点的真实运动状态,不仅ATE 最小,实时性也较好。
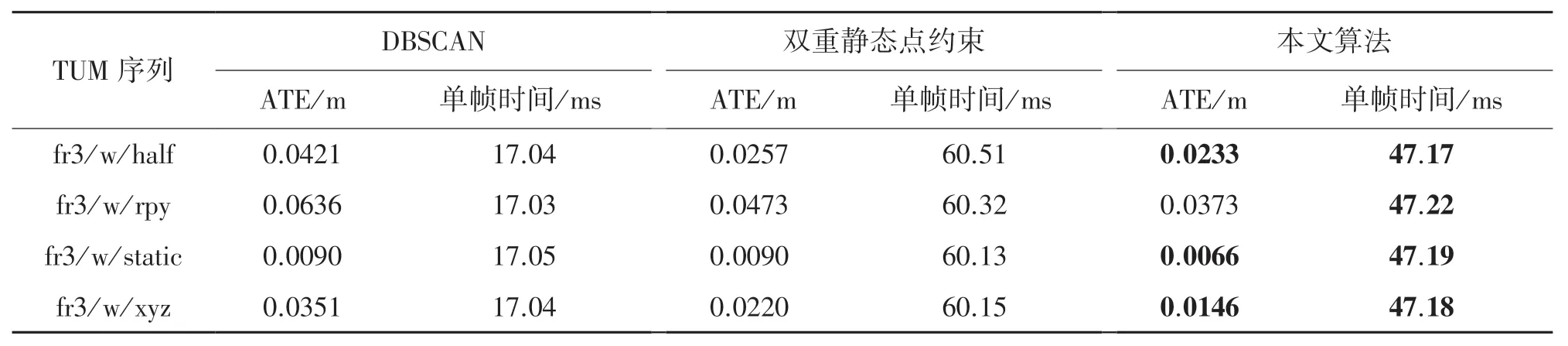
表3 TUM 数据集下三种算法的结果对比
4.3 SLAM 系统评估
本文选取TUM 数据集中含有动态场景的fr3/w/half、fr3/w/static 和fr3/w/xyz 序列验证本文算法的有效性。 图12 所示为ORB-SLAM2、DS-SLAM、DynaSLAM 和本文算法在以上三种序列下生成的轨迹图。 图中ground truth 为相机真实轨迹,estimated为相机估计轨迹、difference 为轨迹误差。 由图可知,由于ORB-SLAM2 算法无法识别场景中的动态物体,所以建图效果较差。 DS-SLAM 和DynaSLAM分别通过实例分割对动态点进行剔除,减小了动态物体对位姿轨迹的影响。 但无法在物体外观缺失环境下准确识别潜在动态物体且难以对潜在动态物体运动状态进行判断,影响系统的定位精度。 本文算法由于融入了AFNET 目标检测算法,能够识别场景中外观缺失的潜在动态物体,且采用基于双重静态点约束的位姿优化进一步确定特征点的真实运动状态,并进行二次位姿优化,进一步提升位姿估计的精度,减少动态物体对建图的影响,生成的轨迹图更接近真实轨迹。 因此本文算法轨迹误差最小,展现出良好的构图能力。
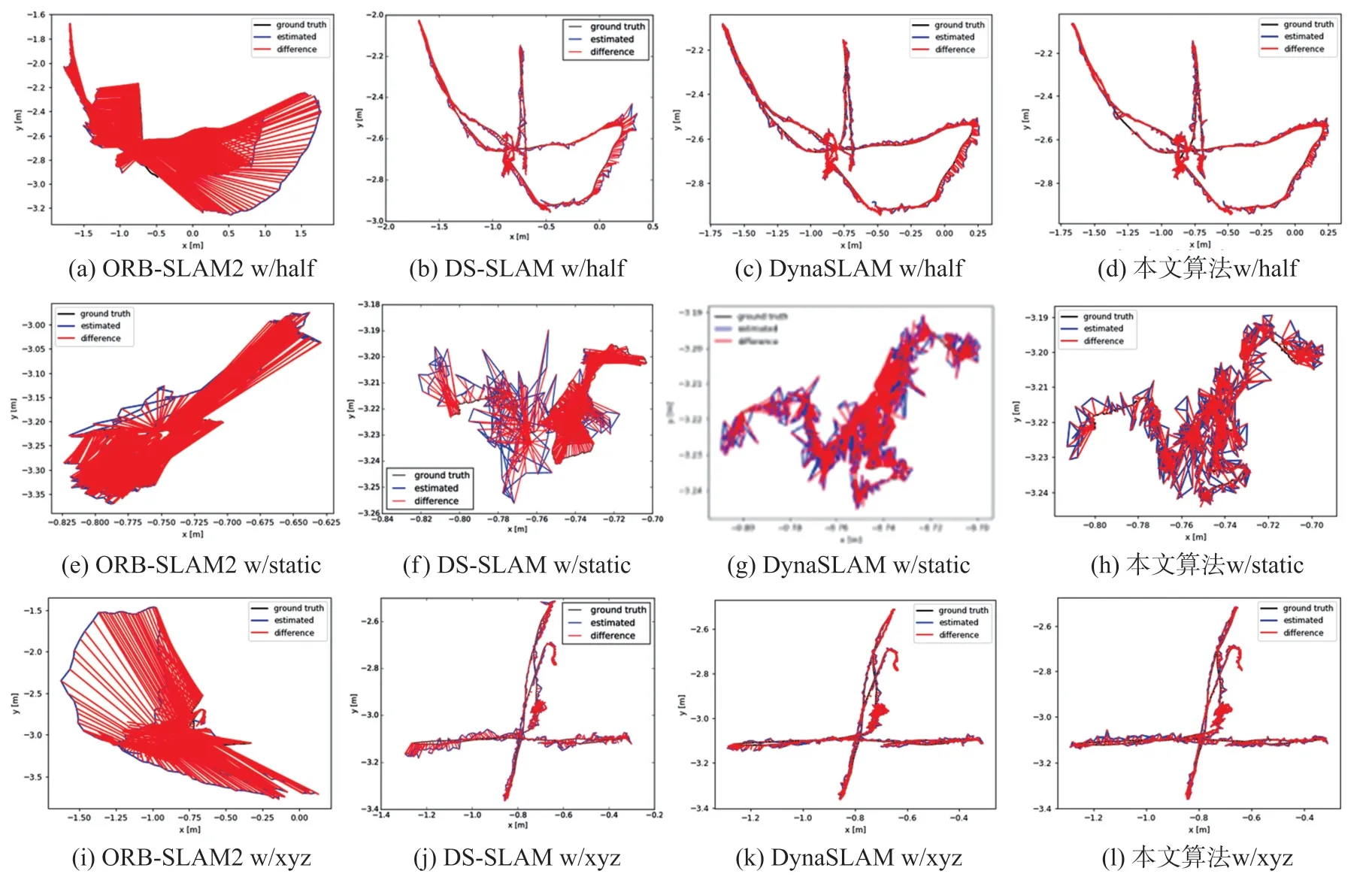
图12 4 种不同算法轨迹对比
本文采用标准差(Standard Deviation,SD)和均方根误差(Root Mean Square Error,RMSE)作为算法的评价标准。 其中均方根误差(RMSE)表示估计值和真实值之间的偏差,误差值越小代表算法所估计的轨迹越接近真实值。 而标准差(SD)表示算法所估计出来轨迹与真实轨迹的离散程度。 表4~表6分别为绝对轨迹误差,相对平移误差与相对旋转误差。 由表可知,本文算法由于融合AFNET 目标检测网络提高对外观缺失物体检测精度,并采用双重静态点约束消除了动态物体的影响。 本文算法绝对轨迹误差与ORB-SAM2 和DS-SLAM 相比在fr3/w/rpy和fr3/w/static 分别减少 93. 08%、 18. 52%, 与DynaSLAM 算法相比除了fr3/w/rpy 序列增加5.4%外, 在 fr3/w/half 和 fr3/w/xyz 序列分别减少20.28%、10.98%,这是由于fr3/w/rpy 序列相机不断进行旋转运动,使得场景中不仅有动态物体,还有自身旋转限制了算法的位姿估计精度。 此外,这四种算法的静态序列fr2/xyz 表现十分接近。
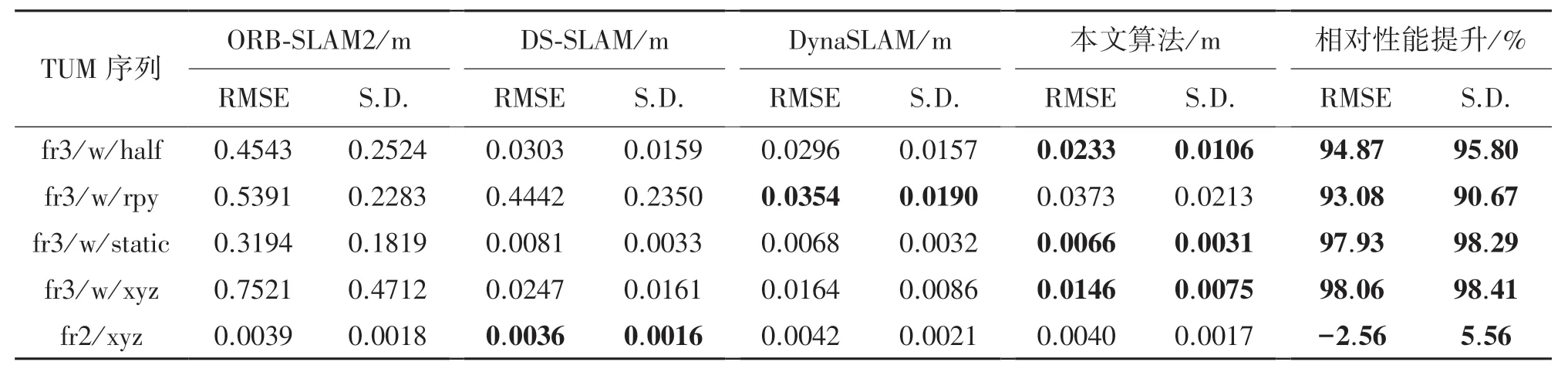
表4 绝对轨迹误差
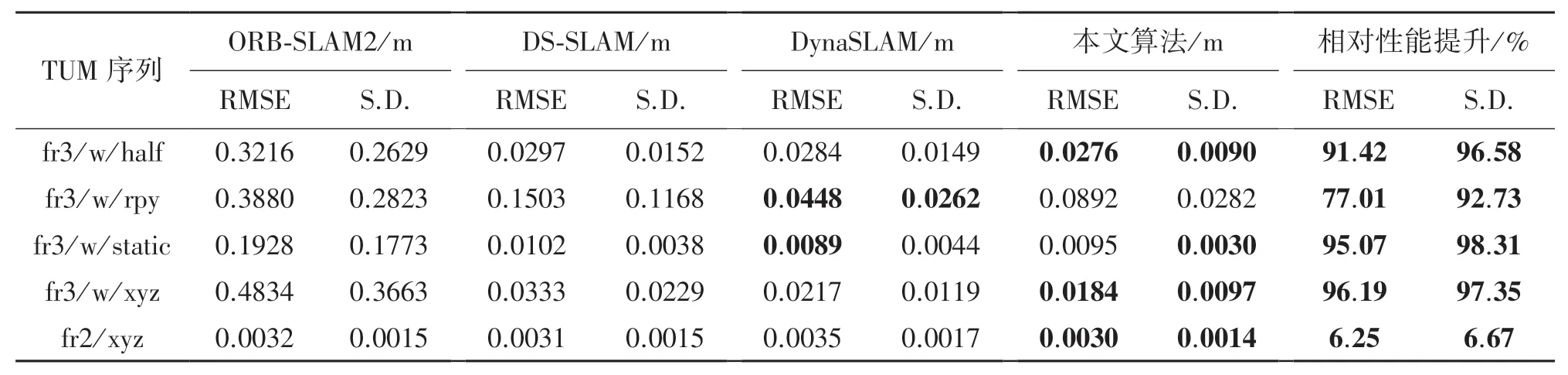
表5 相对平移误差
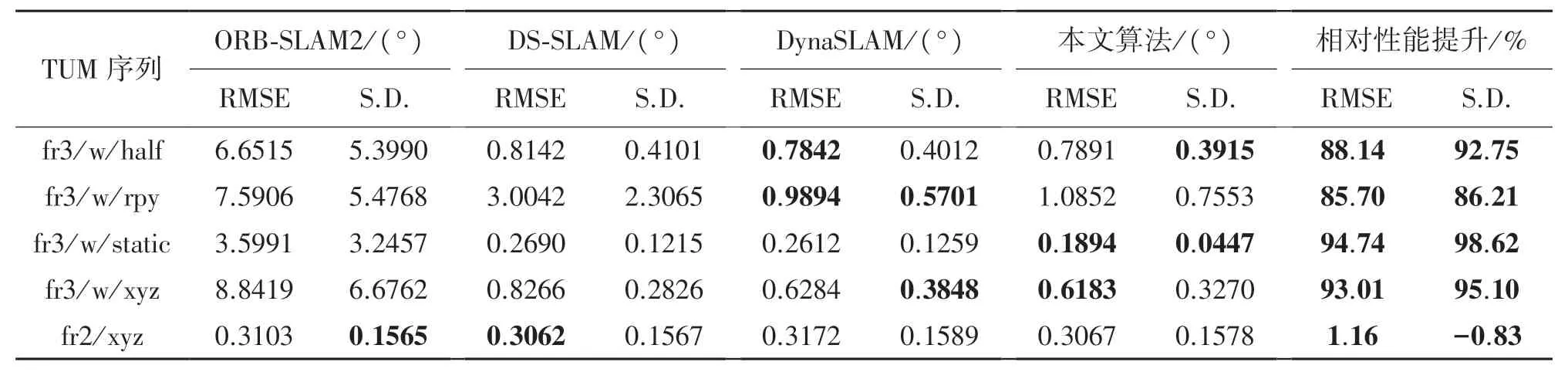
表6 相对旋转误差
表7 为ORB-SLAM2、DS-SLAM、DynaSLAM 和本文算法对单帧图片处理时间的对比结果。 由表可知,ORB-SLAM2 单帧处理总时间最短。 DynaSLAM由于使用Mask-RCNN 实例分割网络导致检测时间较长,单帧总时间大于300ms,DS-SLAM 使用SegNet语义分割处理图片实时性较好,但是单帧处理时间也在65ms 以上,本文算法由于使用AFNET 目标检测网络大大减少了语义线程检测时间,单帧检测时间仅需15.21 ms,同时虽然双重静态点约束由于增加了深度和位置判断单帧处理时间与运动一致性判断相比略微增加,但DBSCAN 每帧处理时间仅需要1.83 ms,因此本文算法单帧总时间仅需47.19 ms,即每秒可跟踪21 帧,能够满足视觉SLAM 的实时性要求。

表7 单帧处理时间对比
4.4 真实场景测试
在真实场景中对本文算法的有效性进行验证,实验平台为Husky 轮式移动机器人,其硬件配置为:CPU i7-10875H 处理器,内存8G,GPU 为GTX1080,操作系统为Ubuntu18.04。 图13(a)、图13(b)、图13(c)所示分别为机器人硬件外观、真实场景实验环境和真实场景平面布局图。 表8 为Husky 轮式机器人的主要参数设置。

表8 主要参数设置

图13 实验平台及真实实验环境场景
4.4.1 潜在动态物体检测实验
图14 所示为移动机器人在运行过程中获取的两帧图像,其中图14(a)为物体外观严重缺失下的目标检测效果,图14(b)为物体外观轻微缺失下的目标检测效果。 由图可知,本文算法AFNET 在物体外观严重和轻微缺失情况下对动态物体检测准确,验证了本文算法对潜在动态物体检测的有效性。

图14 目标检测效果图
4.4.2 动态点剔除实验
图15 所示为动态点剔除效果图。 其中图15(a)为物体外观严重缺失下的动态点剔除效果,图15(b)为物体外观轻微缺失下的动态点剔除效果。 由图可知,本文算法通过对潜在动态物体进行检测,然后对动态点进行有效剔除,增加系统的鲁棒性。

图15 动态点剔除效果
4.4.3 轨迹地图构建
图16 为本文算法和ORB-SLAM2 算法在真实场景中的轨迹对比图。 由图可知,在动态场景中,本文算法的轨迹图与ORB-SLAM2 算法相比更接近于真实轨迹。 本文算法由于加入AFNET 目标检测算法检测场景中的潜在动态物体,利用基于双重静态点约束的位姿优化方法精确剔除动态点,并进行二次位姿优化。 因此本文算法在动态场景下鲁棒性较好。

图16 两种算法轨迹对比
5 结论
为提高移动机器人在动态场景中的定位精度,本文提出一种动态场景下基于注意力机制与几何约束的VSLAM 算法,该算法具有以下优点。 ①针对YOLOv5 目标检测网络易出现动态物体检测不完整的问题,提出一种聚合注意力自适应特征融合的目标检测网络AFNET,提高对物体的检测能力,减少漏检测。 ②提出一种双重静态点约束的方法解决潜在动态点的剔除问题,为位姿估计提供高质量的静态点,提升了系统的精度。 在公开的TUM 数据集和真实场景下对本文算法进行了丰富的对比实验,结果表明本文算法与ORB-SLAM2、DS-SLAM 和DynaSLAM 相比在定位精度方面具有较大优势,并体现出了良好的构图能力。 下一步将在本文基础上,融合惯性测量单元(IMU)数据,为低纹理环境下的相机位姿求解添加约束项,进一步提升算法精度和鲁棒性。
