基于神经网络的渣油浆态床加氢产物分布预测模型
2023-11-06郗荣荣李吉广侯焕娣申海平
郗荣荣,赵 飞,李吉广,侯焕娣,申海平
(中石化石油化工科学研究院有限公司,北京 100083)
全球常规原油资源日益枯竭,原油黏度、硫含量、金属含量日益增高,呈现重质化、劣质化趋势[1]。重质油(特别是渣油)加工过程的清洁化和加工效率的高质化成为炼油企业关注的焦点[2],也是炼油企业提高自身竞争力的重要手段。浆态床渣油加氢工艺可以将重质、劣质渣油高效转化为轻质清洁燃料和化工原料,具有原料适应性强、渣油转化率高、轻油收率高等优点,成为现代炼化企业重要的重油加工技术之一。目前,浙江石油化工有限公司、中国石化茂名分公司等陆续建立了渣油浆态床加氢装置。
多年来,为了预测渣油加氢过程产物分布,研究人员开发了机理模型、数据驱动模型等反应模型。目前,渣油加氢的机理模型研究已经趋于成熟。曹彦锴[3]基于对渣油加氢催化剂加氢性能和失活规律的分析,提出了渣油加氢催化剂失活动力学模型、加氢精制反应动力学模型和加氢裂化反应动力学模型。葛海龙等[4]利用两集总一级反应动力学模型模拟了渣油加氢脱金属的反应过程,发现加氢产物脱镍率、脱钒率的计算值与实际值的平均相对误差分别为2.65%和2.61%。刘传文等[5]针对铁系催化剂作用下的孤岛渣油加氢裂化体系,建立了气体、馏分油、减压渣油四组分(饱和分、芳香分、胶质、沥青质)和苯不溶物(焦)的七集总动力学模型,模型预测结果与试验数据吻合性好。张萍萍等[6]针对克拉玛依常压渣油浆态床加氢裂化过程建立了六集总动力学模型,该模型预测产物收率的误差在5% 以内。
渣油浆态床加氢是一个复杂的化学反应过程,涉及的变量多且耦合度高。渣油加氢是复杂的混合物反应体系,在复杂模型的构建过程中常常进行简化并设定假设条件,导致模型出现构建难度大、计算量大、收敛速度小、预测精度低等问题。因此,采用机理模型难以实现过程的精确模拟,研究人员利用计算机深度智能学习技术,建立数据驱动模型对渣油浆态床加氢过程进行模拟研究。
神经网络模型具有强大的自适应、自组织、自学习和非线性拟合能力,在复杂工业过程中得到了广泛应用。田水苗等[7]利用反向传播(BP)神经网络建立了用于预测蜡油加氢产品的数据驱动模型,其对产物分布及硫、氮含量的预测具有较高精度。Ma等[8]针对中国石化茂名分公司的渣油加氢反应过程建立了BP神经网络模型,其对产物中金属、S、N、残炭的预测平均相对误差在6%以内。卷积神经网络(CNN)模型主要应用在石油勘探开发[9-13]、故障识别[14-15]、产量预测[16]、污染物排放预测[17]等方面。孙国庆[18]以加氢裂化装置新氢流量为目标变量,以LeNet为基准,建立了CNN模型,并对其进行深层重构训练。相较于普通CNN模型,该深层CNN模型预测更准确,其均方误差降低了9.11%。为了模拟工业加氢裂化过程,Song Wenjiang[19]基于自组织图和卷积神经网络开发了一种深度学习框架SOM,将输入变量映射为二维数据以提取数据特征,进而进行CNN模型训练。结果表明,SOM-CNN模型具有更好的拟合能力和外推能力。
为了进一步推动渣油浆态床加氢过程的数据化、智能化,本课题利用实验室小试数据,基于不同神经网络建立渣油浆态床加氢产物分布和氢耗预测模型;鉴于试验数据量较少且数据不平衡,采用关联式模型的方法进行数据扩充,以降低模型预测误差;利用遗传算法优化神经网络模型,进一步提高预测精度,以期为渣油浆态床加氢装置操作优化及原料拓展提供支持。
1 数据收集与处理
1.1 渣油加氢数据收集
试验数据来源于中石化石油化工科学研究院有限公司(简称石科院)渣油浆态床加氢课题组小试数据。根据渣油浆态床加氢工艺,采集数据包括输入变量数据和输出变量数据。输入变量主要包括6种原料油(减渣VR-1、减渣VR-2、减渣VR-3、减渣VR-4、减渣VR-5、减渣VR-6)性质和操作变量(催化剂用量或浓度、工艺参数),输出变量包括裂化气、汽油、柴油、蜡油、残渣、不溶物的收率和加氢过程氢耗。其中,加氢过程氢耗是指单位质量新鲜进料的氢气消耗量。
1.2 数据预处理
数据样本可能存在文本数据、空值、无关数据等,需要进行数据预处理:①删除文本数据(如分析方法、原料名称、添加剂名称等);②删除全部为空值和残缺项目较多的数据样本;③删除无关变量(如模拟馏程与输出目标无关);④对残缺项目较少的数据样本进行填充处理。
填充数据的方法主要有Linear插补、Quadratic插补、Spline插补、Akima插补、最邻近插补、均值/中值/众数填充、前向/后向填充等。分析渣油浆态床加氢小试数据可知,不同样本数据之间的差距较大且数据之间不存在特别联系。因此,综合不同填充方法优缺点和原始数据特点,确定采取“最邻近插补”法进行数据填充。
结合实际生产工艺要求,采用Min-Max法剔除不符合要求的样本数据,根据箱线图法寻找样本数据的异常值并利用最邻近插值法对数据进行插补处理。预处理后的原料油性质、操作变量数据和输出变量数据分别见表1~表3。
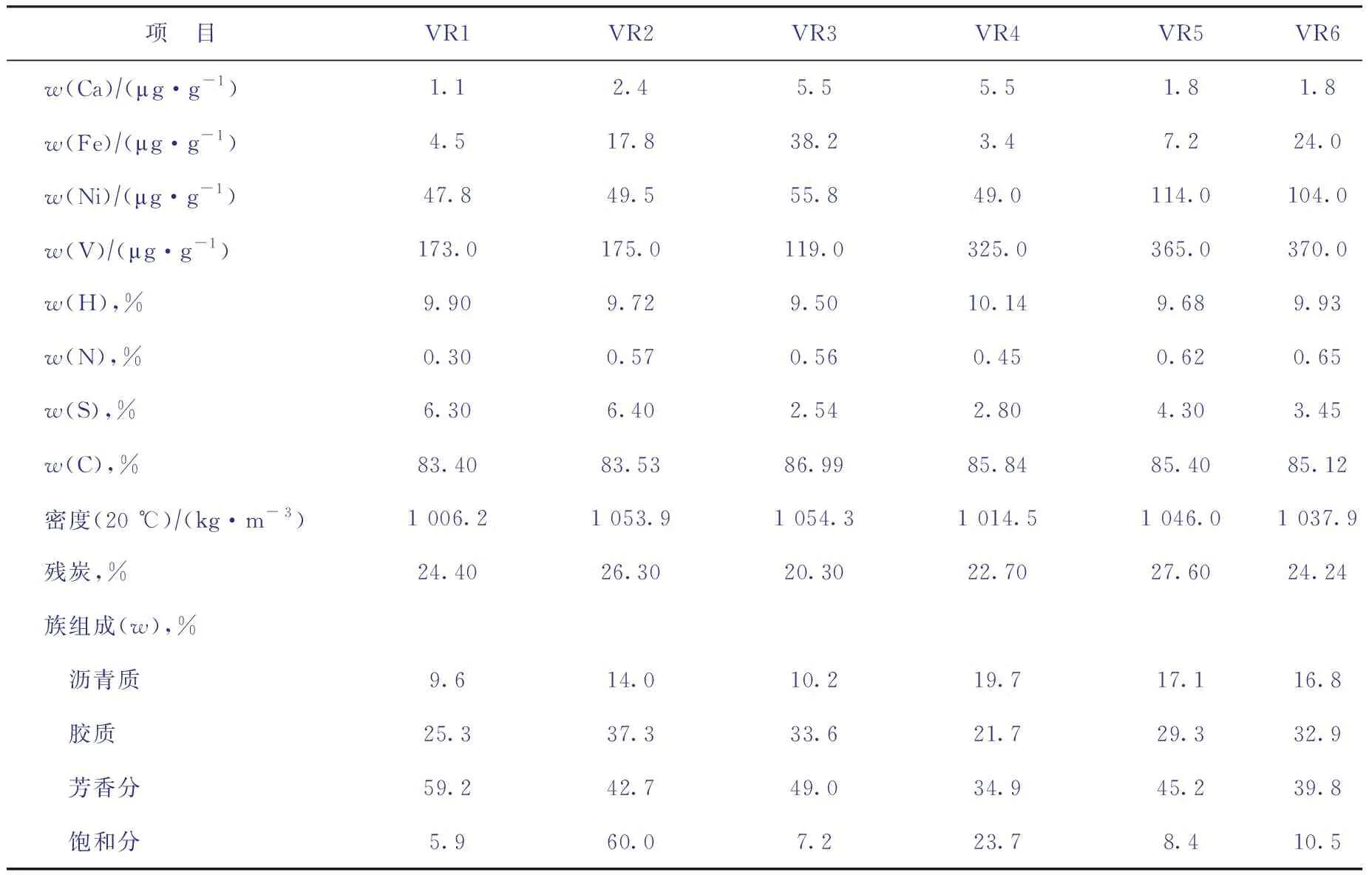
表1 预处理后的6种原料油性质

表2 预处理后的操作变量数据

续表
由于不同变量的量纲不同,无法直接进行分析比较,因而采用式(1)对不同变量数据进行归一化处理,得到0~1无量纲数据。
(1)
式中:Xmax是样本数据的最大值;Xmin为最小值。
2 变量相关性分析
输入变量的线性相关性直接影响模型的训练效果,需保证输入变量间弱相关或不相关、而输入变量与输出变量(目标变量)显著相关。因此,采用Pearson相关系数法对输入变量进行特征选择,不同输入变量间的线性相关系数(r)由式(2)计算。
(2)
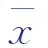

表4 变量相关关系与相关系数大小间的对应性
r取值区间为-1~1,r为-1,1,0分别表示完全负相关、完全正相关、不相关;|r|越接近于1,则表明变量间的相关性越强。已知原始样本为22组数据,因此相关性分析结果来自于少量样本,结果可能存在偶然性。为了确定分析结果的可靠性程度,需要对相关结果r进行显著性检验。显著性检验水平(p)一般为0.05,表示显著性检验结论错误率必须低于5%。若p<0.05,则表示分析结果具有可靠性;若p>0.05,则表示结果没有统计学意义,可能是偶然因素导致的。
输入变量与目标变量的相关系数如表5所示。由表5可知,部分原料油性质变量(包括Fe含量、Ni含量、V含量、H含量、N含量、密度、残炭、沥青质含量、胶质含量、饱和分含量)和操作参数变量(包括反应时间、氢初压、原料油质量、催化剂质量、助剂质量)与目标变量之间的相关系数均大于0.4,说明其与目标变量间存在显著线性相关关系,显著性检验p<0.05表示分析结果r能够通过95%的显著性检验,分析结果是可靠的。
进一步采用Pearson相关系数法分析原料油性质变量之间的相关关系,结果如图1所示。由图1可知,原料油残炭与元素Ca,Fe,Ni,V质量分数之间高度线性相关,因而需排除Ca,Fe,Ni,V质量分数4个变量,但根据工业生产实际情况,Ni质量分数、V质量分数对渣油加氢结果影响很大,需要保留并进行调控。因此,共保留密度、残炭和C、H、S、N、Ni、V、沥青质、胶质、芳香分、饱和分的质量分数共12个原料油性质作为输入变量。

表5 输入变量与目标变量的Pearson相关系数和显著性检验

图1 原料性质变量间的相关关系
操作变量间的Pearson相关系数如图2所示。由图2可知,原料油质量与助剂质量间的|r|为0.73,因而去除原料油质量而保留助剂质量。因此,操作变量保留5个:反应温度、反应时间、氢初压、助剂质量、催化剂浓度。
综上,基于变量间Pearson相关关系、浆态床技术特点、实际工业操作经验,确定了浆态床渣油加氢过程模拟模型包括17个输入变量(12个原料性质变量和5个操作变量)和7个目标变量(6种产物收率和氢耗)。
3 神经网络模型建立
3.1 BP神经网络模型框架
基于BP神经网络,构建了渣油加氢模型的3层神经网络模型,其结构如图3所示。
模型的输入层变量数为17,输出层目标数为7,隐含层神经元数由式(3)确定[20]。
(3)
其中:H为隐含层神经元数;m、n分别为输入层和输出层变量数;L为1~10。
3.2 模型性能评价指标
常见的模型性能评价指标主要包括:MSE、平均相对百分比误差(MRPE)和R2。
MSE为真实值与预测值间误差的平方和,评价预测数据变化幅度。其计算式见式(4)。
(4)

MRPE为真实值与预测值的绝对百分比误差相对于样本真实值的平均偏离程度,其值越小表示模型的预测性能越好。MRPE计算式见式(5)~式(6)。
(5)
(6)
R2表征模型对于数据的拟合程度,其值越接近于1,拟合效果越好。R2计算式见式(7)。
(7)
3.3 BP神经网络模型建立和训练优化
为了保障数据样本的平衡性,在每种原料对应的数据样本中各取一组作为测试集,其余数据为训练集。因此测试集数据共6组,训练集数据共16组,测试集数据完全不参与模型的构建和训练。当原始数据样本有限时,模型容易过拟合,即模型对训练集数据的预测误差很小,但在测试集上的预测误差较大。为了避免上述问题,引入K折验证法(一般取3~10折),即在训练集中分出一部分作为验证集数据,用于评估模型的训练效果并确定模型相关参数。本实验选取K=10,即将训练集数据任意划分为10份,其中以9组为训练,剩余1组数据用于验证,循环10次,以最终的平均评价指标作为最终结果。
由式(3)计算得知,模型隐含层神经元数在6~15之间。基于不同隐含层神经元数,进行模型构建和训练,通过比较验证集数据的均方误差,找到最佳隐含层神经元数,结果如图4所示。由图4可知,当隐含层神经元个数为14时,模型均方误差(MSE)最小。因此,隐含层神经元数优选为14,所建BP神经网络模型结构为17-14-7。

图4 隐含层神经元个数与模型预测均方误差间的关系
利用测试集样本数据进行测试,结果表明:目标变量(裂化气、汽油、柴油、蜡油、残渣、不溶物的收率及氢耗)的预测值与试验值间的MRPE分别为32%,30%,37%,15%,51%,66%,37%。模型预测误差大的原因主要在于原始样本数据不平衡,由模型构建的基础数据(表1)可知,采用的试验数据原料油包括减渣VR-1、减渣VR-2、减渣VR-3、减渣VR-4、减渣VR-5、减渣VR-6共6种原料,其中减渣VR-5对应12组数据样本,其余原料只各自对应2组数据样本。
针对数据样本量少、数据不平衡的问题,利用关联式模型实现数据扩增。其中关联式模型法是指基于原始样本数据和神经网络构建关联式模型,实现输入端和输出端数据非线性关系的构建,而后在原始输入数据的基础上添加一个随机扰动并利用之前构建的模型进行预测得到对应输出,至此便获得多个新的数据样本。基于关联式模型的数据扩充法,将原始样本的22组数据扩增至242组。将其分为训练集、测试集和验证集,其中训练集数据样本为196组,测试集数据样本为25组,验证集数据样本为21组。基于数据扩充后的训练集和验证集数据样本,对包含不同隐含层神经元数的神经网络模型进行训练对比,结果如图5所示。

图5 数据扩充后隐含层神经元个数与模型预测均方误差间的关系
由图5可知,当节点数目为15,训练集的训练均方误差MSE最小,为0.035%;此时,验证集数据拟合优度(R2)最高,为0.99。因此将BP神经网络模型结构优化为17-15-7。鉴于该模型在训练集和验证集数据样本上表现良好,后续将利用测试集数据进行模型测试。
数据扩充后,改进BP神经网络模型对测试集数据样本的预测效果如表6所示。由表6可知,相较于17-14-7结构的原BP模型,改进后17-15-7结构的BP神经网络模型预测裂化气、汽油、柴油、蜡油、残渣、不溶物的收率及氢耗的相对误差分别降低了93.2%,78.1%,97.4%,88.9%,91.4%,93.8%,93.8%,MRPE均值从38.28%降至3.15%,模型预测值与试验值间的最大MRPE降为6.57%。这意味着利用关联式模型实现数据扩充具有可行性,数据扩充对提高模型精度具有较好作用,同时也说明扩充数据具有良好的代表性。
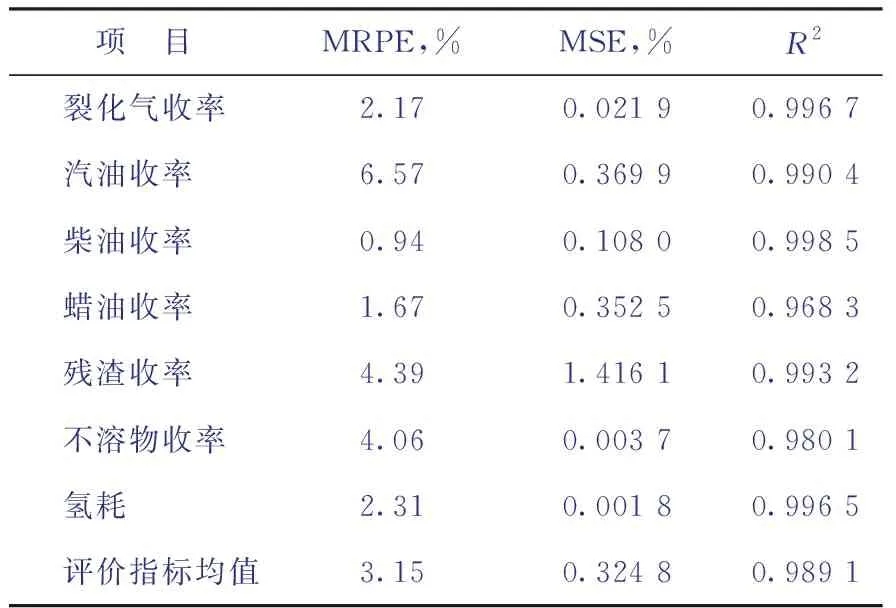
表6 数据扩充后改进BP神经网络模型的预测结果
3.4 卷积神经网络模型的建立
数据扩充后,改进BP神经网络模型的预测误差仍较大;而且随着模型参数增多,模拟计算量大幅增加,模型易出现训练效率低和过拟合现象。因此,为了进一步提高预测精度,需要尝试和探索构建其他神经网络模型。卷积神经网络[21](CNN)能够充分挖掘数据的空间相关性,通过局部感知区域提取相关特征,具有局部连接、权重共享等结构特性,可使模型参数减少、计算效率和预测精度提高。卷积神经网络的结构如图6所示,可见其由卷积层、汇聚层、全连接层交叉堆叠而成。

图6 卷积神经网络模型结构
xwyxw
y=w*x
(8)

图7 一维卷积层示意
汇聚层旨在通过特征选择来减少特征数量,从而减少参数量。最大汇聚是指以区域内所有神经元的最大活性值作为该区域的值,如图8所示。

图8 汇聚层中最大汇聚过程示意
卷积神经网络中的卷积层可以提取输入数据的相关特征,减少参数数目;汇聚层可以对特征向量进行压缩,增强了抗畸变性能。因此,卷积神经网络具有更高的计算效率。
构建CNN模型也采取3层结构设计,其中输入和输出变量确定不变,汇聚层为最大汇聚,因而待定参数仅有卷积单元滤波器个数和卷积核尺寸。其中,滤波器数量通常为2的幂次,其数目越多则神经网络越强大,但参数数目过多易导致过拟合;卷积核尺寸是指卷积矩阵大小,通常一维卷积可用一个整数来表示。设定滤波器数量为4,8,16,32,64,卷积核尺寸为2,3,4,5,6,7。基于扩充后的数据集,对新建CNN模型进行训练,考察模型模拟的MSE和R2。当验证集MSE不再降低时,停止训练。训练结果见图9和图10。由图9和图10可知,所建CNN模型卷积单元的滤波器数为64,卷积核尺寸为6。
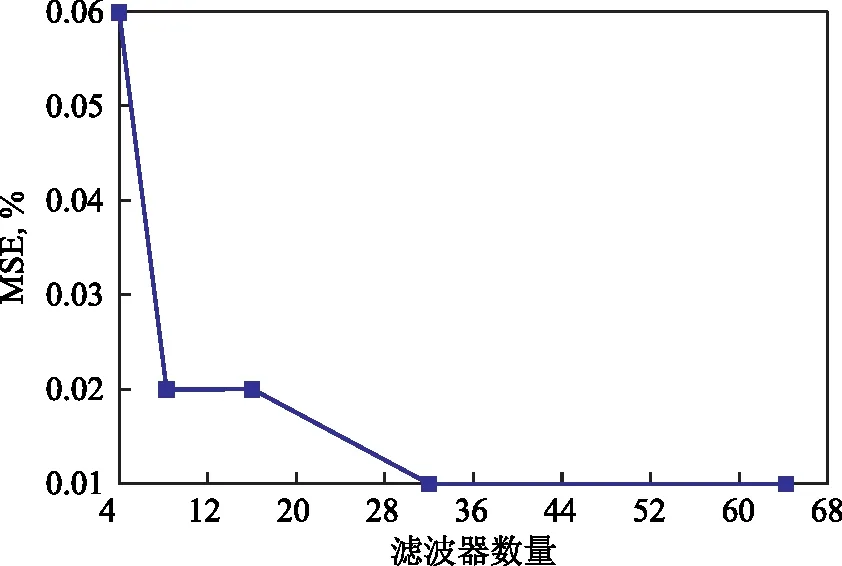
图9 不同滤波器数量对应的CNN模型训练误差
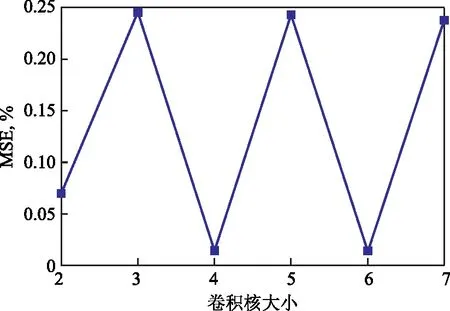
图10 不同卷积核尺寸对应的CNN模型训练误差
3.5 CNN模型性能评价
利用CNN模型对测试集数据样本进行预测,结果如表7所示。结合表6与表7可知,CNN模型的预测性能较改进后的BP模型有了显著提高,其预测相对误差均值较BP模型降低了21.58%。

表7 CNN模型的预测效果
3.6 BP模型和CNN模型的遗传算法优化
虽然CNN模型的预测性能较改进后的BP模型有了显著提高,但其预测精度仍有待进一步提升。遗传算法(GA)是受自然界“优胜劣汰,适者生存”进化原理的启发而开发的一种随机搜索优化方法,其可以扩大寻找最优解的搜索范围。神经网络模型初始值的设定具有随机性,若将遗传算法与神经网络模型相结合,利用遗传算法的训练结果作为神经网络模型的初始权重和阈值,优化神经网络模型的初始参数,可以有效改善神经网络模型的预测精准度和稳定性。
设定GA迭代次数为500,种群数为100,交叉概率为0.8,变异概率为0.1。采用GA优化BP神经网络模型和CNN神经网络模型的预测结果如表8所示。由表8可知:经GA优化后,BP神经网络模型预测值与试验值的MRPE均小于5%,比优化前降低40.32%;经GA优化后,CNN模型预测值与试验值的MRPE均小于2%,比优化前降低47.77%。

表8 遗传算法优化模型的测试结果
4 结 论
(1)基于实验室22组小试数据,开展浆态床渣油加氢工艺变量的相关性分析。参考实际生产经验,采用Pearson相关系数法确定了工艺模型建立的17个输入变量(包括12个原料性质变量和5个操作变量)和7个输出变量。进而建立了17-14-7结构的浆态床渣油加氢BP神经网络模型,并对其预测精度进行了评价,结果显示该模型预测值与试验值间的平均相对误差均较大(>20%)。
(2)针对数据样本少、数据不平衡导致模型预测偏差大的问题,采用关联式模型方法进行数据扩充,将数据样本由22组扩充至242组。基于扩充的数据样本,建立了17-15-7结构的浆态床渣油加氢BP神经网络模型,结果表明,数据扩充后所建BP神经网络模型的预测准确性显著提高,预测值与试验值间的最大平均相对误差降为6.57%。
(3)为了进一步提高预测精度,基于扩充后的数据建立了CNN模型,其预测值与试验值间的最大平均相对误差降为5.38%。
(4)为了进一步提高所建模型的预测精度,采用遗传算法进一步优化神经网络模型,结果显示,采用GA优化后BP神经网络模型预测值与试验值平均相对误差均小于5%,CNN模型预测值与试验值平均相对误差均小于2%。
