基于Python的异常数据处理与分析实践探究
2023-11-06蔡振海
蔡振海
(江苏经贸职业技术学院,江苏 南京 211168)
0 引言
随着技术的发展,生活中处处有数据,处处用数据。但因为种种原因,经常会存在一些异常数据,比如采集手段、仪器精度、存储运输不当等造成数据精度不够、数据项缺失、数据单位不对等,这些异常数据对结果有着极大的影响[1]。如何消除异常数据并替换为合理数据在大数据分析中是一项十分关键且重要的工作[2]。大数据时代,对数据和大数据进行分析和可视化是一项重要的工作,也是一项重要的技能。对于数据的处理和分析需要借助专业的软件和相应的编程软件,Python 拥有非常强的扩展性、运行速度非常快、代码量少、易上手、数据处理包丰富等特点,被广泛运用到人工智能、大数据分析、网络爬虫等方面[3]。本文使用Python 的开源发行版本Anaconda3 对数据进行处理分析。Anaconda 是专门为了方便使用Python 进行数据研究而建立的一组软件包,涵盖了数据科学领域常见的Python库[4]。
1 Anaconda简介
Python 由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于20世纪90年代初设计,作为一门叫作ABC 语言的替代品。Python 提供了高效的高级数据结构,还能简单有效地面向对象编程,其简单、易学、易读、易维护、用途广、速度快、免费、开源、可移植性、可嵌入性、丰富的库等优点深受广大使用者喜欢[5]。但Python 对于初学使用者来说由于版本和环境配置等问题,往往会让初学者花费许多时间来配置环境,经常因为配置环境或者版本等原因使得Python 程序无法运行[6]。Anaconda是一个用于Python科学计算和机器学习的开源工具,它是Python 的发行版本,支持Linux、Macocy 以及Windows 系统,包含numpy 等许多工具包和依赖项,提供了管理包和管理环境,能用于解决开发过程中可能遇到的Python 多版本问题和第三方库的安装、使用等问题。
Anaconda是基于conda的Python数据和机器学习的开发平台。conda是虚拟环境工具和包管理工具集合体,可以用于各种开发语言。其资源库上有上万个第三方库供学习和开发者使用[7]。Python是Anaconda自带的,无须使用者再次安装,并且配置好了运行环境,免去了麻烦的配置环境步骤,因此受到广大使用者的喜欢。Anaconda 由于其自带的大量数据科学包和依赖项,使用者可以在安装后立即进行数据处理。
2 数据读取
采集的天气数据以CSV格式进行保存,包含温度和相对湿度两个数据项。表1和表2显示了天气数据表的前15 行和后15 行,需要读取的温度数据在数据表的第二列。从数据表中可以看出存在数据缺项以及数据异常的情况,比如序号5的温度值为空格,序号8 的温度值为100 摄氏度,正常天气温度应该在40 摄氏度以下。为了方便处理数据,使用NumPy读取采集的天气数据。

表1 天气数据前15行
NumPy(Numerical Python)是Python 的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python 自身的嵌套列表(Nested List Structure)结构要高效得多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。在数据分析和机器学习中,大量地使用科学计算,Numpy[8]提供了大型矩阵计算的方式,而这些是Python标准库中所缺少的。Numpy也是许多优秀的第三方库的基础,依赖于Numpy的库非常多。
在进行数据分析时,最重要的一步就是数据的获取,即如何读取到已有的数据。常用的保存数据文件的类型有TXT、CVS、JSON、Excel、XML 等。读取这些类型的数据常用Numpy 包中的已有函数loadtxt(),并根据需要将读取到的需要处理的数据保存为某一种格式。
Anaconda平台中已包含有Numpy包,不需要再进行第三方的安装操作,但在使用时需要进行导包操作,然后使用loadtxt()函数读取数据表中的温度数据。从数据截图中可以看出温度数据在第2列,所以设置loadtxt()函数中控制读取列的参数usecols 的值为1。具体代码如下所示:

print("读取的温度数据是: ",str_temperature)
从Anaconda3 控制台可以看到读取的温度数据,每个数据值前面都有b’这个字符串,说明此时是以字符串的形式读取了数据表中的温度数据。缺项值以空字符串的形式读取,异常值正常进行读取,结果如图1所示:
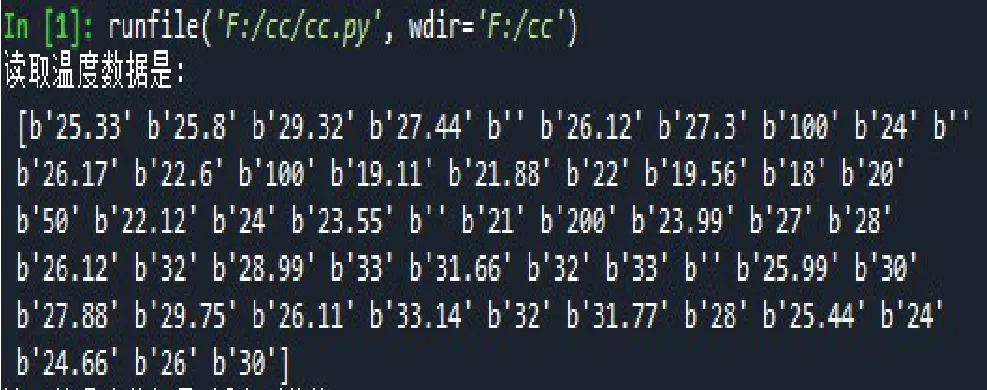
图1 读取的温度字符串值
由于字符串形式的数据在处理和分析具有一定的局限性,为了便于后期数据的处理,将读取的字符串数据转换为浮点型数据,并将空值项用None代替。代码和结果如图2所示:
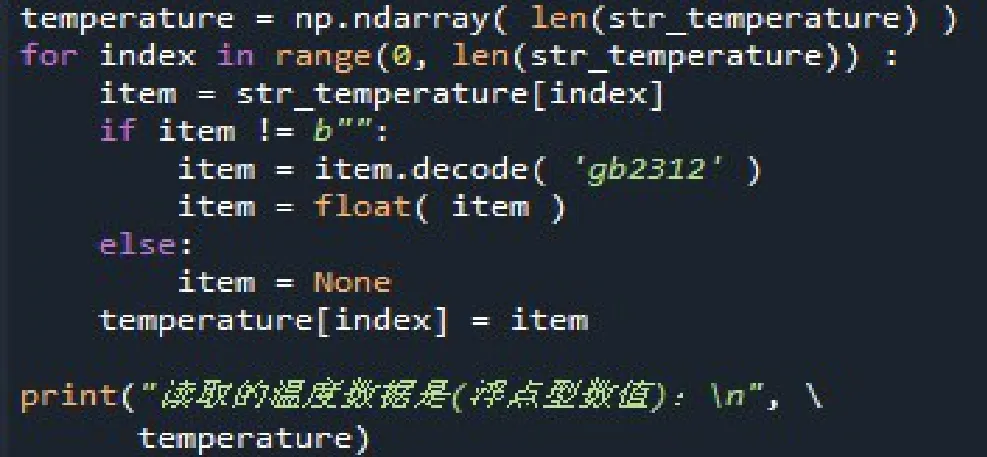
图2 处理控制代码图
从图3 中可以看出,所有的温度数据已经转换为了浮点型数据,切空值项也用None 进行了替代。但是很难直接从上面的浮点型数据进行分析、处理。为了便于对数据进行分析并直观查看异常温度数据对于整个数据分析的影响,使用Matlab 中的plot()函数将结果绘制成图。在Anaconda3 中使用plot()函数需要导入matplotlib.pylot。具体代码和绘制的图形如图4、图5所示:

图3 读取的浮点型温度值

图4 绘制温度曲线代码

图5 含有异常值和缺省值的温度曲线
从图5中可以看出,由于异常值和缺项值的存在,绘制的图形存在明显错误,且不合理。比如曲线不连续、曲线明显过高等。为了尽可能地使数据更加符合实际,需要对异常值和缺项值进行一定数学方法的处理,这样得出的数据进行分析才具有科学性,并能产生一定的实际意义[9]。
3 异常值处理
对于存在的异常值,要先读取异常值,然后针对异常值进行处理。本文先将异常值读取,用None 进行代替,形成缺省值。再统一对缺省值进行相应的数学处理。从温度图表中可以看出,此地采集的温度数据值范围处于春夏季之时,由于正常天气一般不超过40摄氏度,且从采集的数据表中可以看出温度应在16~40摄氏度。对于大于40摄氏度的值作为异常值进行处理,用None 替代。使用for 循环对异常值进行处理,处理异常值的代码如下:

在控制台输出的结果如图6所示:

图6 用none替代异常值的温度数据
从图6中可以看出,所有的异常值已经用None进行替代,但为了便于查看、分析数据,将异常值处理后的数据使用上文提到的方法,用Anaconda3 将其绘制成如图7所示的图形:

图7 处理异常值后的温度曲线
从图7中可以看出,数据的范围已在合理的范围之内。但由于存在许多缺省值,绘制的图形不完整,点与点之间的连线不连续。为了使数据具有科学性,便于进行数据分析,要将缺省值通过一定的方法将其补充完整。同时补充的数据应具有一定的科学性、合理性,这样才能在实际工作中具有指导意义。
4 缺省值处理
对于缺省值的处理主要通过数学方法进行。即使用缺省值的前后的值进行简单求平均得出该缺省值,此方法简单易实现,但对于数据的精度和科学性有一定差距。当然,对于对数值精度和严谨性非常高的数据分析上,可以采用诸如多项式插值、线性插值、二次插值、Cubic 插值、拉格朗日多项式插值等数学方法[10]。
插值法就是在一些离散的数据基础上补充缺省的数值,即给定m 个离散的数据值,这些数据值中存在一些缺失的值,通过m个数据值用特定的数学方法来估算出缺失的数值后补充进去,使得用这些数值绘制的曲线是连续平滑的。插值是离散函数逼近的重要方法,利用它可以通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值。
本文为了简便说明问题,采用平均值插值技术。简单平均公式如下:
代码实现如下:

在Anaconda3控制台输出的结果如图8所示:

图8 最终温度值
为了便于查看、分析数据,将处理后的数据使用Anaconda3绘制如图9所示。从图9中可以看出,在经过一系列的处理后,温度值已是在合理范围内,没有异常值和缺省值,且绘制的曲线连续无断点。

图9 最终温度曲线
5 结束语
本文基于Python 对温度数据中的异常值进行了处理与分析,通过实践探究说明Python在异常数据的处理以及数据分析中的作用,并对处理后的数据绘制温度曲线来直观对比数据处理前后的差异。结果表明,Python 语言在数据处理上有着极大的优势,且对数据清洗、分析简单易上手,效率十分高效。
