基于时序分解和SSA-LSTM-Attention模型的尾矿坝位移预测
2023-11-06唐宇峰陈星红蔡宇杨泽林蒲顺哲杨超凡
唐宇峰, 陈星红, 蔡宇, 杨泽林, 蒲顺哲, 杨超凡
(1.四川轻化工大学机械工程学院, 宜宾 644005; 2.重大危险源测控四川省重点实验室, 成都 610045;3.四川省安全科学技术研究院, 成都 610045)
尾矿库是矿山安全生产领域的重大危险源,通过分析其坝体的表面位移是评估尾矿坝安全性的重要方式[1],因此对尾矿坝的位移监测数据进行预测分析具有重要意义。在对坝体位移变形数据分析处理上,将监测的时序数据进行分解为具有物理意义的分量是常用方法[2]。谢博等[3]通过经验模态分解算法(empirical mode decomposition,EMD)对监测数据分解后进行预测;周兰庭等[4]采用自适应噪声完备集合经验模态分解算法(complete ensemble empirical model decomposition adaptive noise, CEEMDAN)对监测数据进行分解,以此对监测数据的变形规律进行分析;鄢好等[5]通过移动平均法提取边坡位移趋势项和周期项。以上通过对监测数据进行分解再预测的方法最终对预测结果的精度提升都有较好的效果,但都有各自一些无法克服的缺陷,如残留噪声、模态混叠、不适合大量数据样本等。
由于尾矿坝的位移变形是一个动态变化的过程,近年来,基于机器学习对坝体位移进行预测研究成为一个热点。张炎等[6]通过反向传播(back propagation,BP)神经网络并结合多元宇宙算法对大坝位移进行了预测,具有一定的预测效果,但BP的计算速度慢,容易陷入局部极小值;Jiang等[7]采用极限学习机预测周期项位移,但极限学习机对于尾矿坝的动态变化来说效果还有待改进。宁永香等[8]采用广义回归神经网络对露天矿边坡变形预测,相较于BP网络,其收敛速度更高,泛化能力较强,但网络容易陷入梯度消失和梯度爆炸的困境。长短时记忆(long short-term memory,LSTM)神经网络由于其“门”控机制在模型训练过程中,能较好处理时序信息问题。在对坝体变形预测问题上,文献[4]、文献[9]采用LSTM对坝体监测数据进行预测,均有较高的预测精度,但未解决LSTM超参数优化问题,选择不同超参数其预测结果具有较大的差异性。且当时间序列过长时,LSTM可能会出现信息丢失问题,影响预测精度[10]。
基于以上方法的优势和不足,现提出一种基于改进的自适应噪声完备集合经验模态分解算法(improved complete ensemble empirical mode decomposition with adaptive noise,ICEEMDAN)和麻雀搜索算法-长短时记忆-注意力机制(sparrow search algorithm-long short-term memory-attention mechanism,SSA-LSTM-Attention)模型的尾矿坝体位移预测方法。首先将ICEEMDAN用于时序数据的分解处理,将监测数据提取为趋势项位移和周期项位移,然后,通过高斯拟合预测趋势项位移,采用LSTM神经网络对相关影响因子作用下的波动项位移进行预测,并结合注意力机制(attention mechanism)加强模型处理长时间序列数据间相互关系的能力。通过麻雀搜索算法(SSA)优化模型超参数,提升模型的预测精度[11]。最后将趋势项位移、波动项位移的预测值叠加,得到尾矿坝累积位移预测值。并通过实例验证方法的可行性。
1 尾矿坝位移预测模型
1.1 基于时间序列的ICEEMDAN分解
尾矿库坝体位移是一个非线性的时间序列,若直接对原始累积位移进行建模会产生较大误差,尾矿坝的变形规律难以分析。对原始序列采用先分解,再预测的方式既能有效利用数据信息,也能降低数据的复杂度,提高了预测的精度。采用ICEEMDAN算法将坝体累积位移分解为趋势项和波动项,即
S(t)=φ(t)+η(t)
(1)
式(1)中:S(t)为累积位移时间序列;φ(t)为趋势项位移,受坝体结构、地质构造等自身条件决定;η(t)为受库水位、降雨量等外界因素影响。
ICEEMDAN是Colominas等[12]在EMD的基础上提出的一种新的信号分解方法。该方法改进了传统的方法在对信号分解时存在模态混叠的不足,极大地减少了本征模态函数(intrinsic mode function,IMF)分量中的残余噪声。分解后,会得到一组频率从高到低的IMF和一个残差项。其中,IMF包含了原位移监测数据不同时间段的局部特征信息,为波动项位移,而残差项可以反映时间序列的主要趋势,为趋势项位移。
1.2 基于SSA-LSTM-Attention的波动项位移预测模型
1.2.1 麻雀搜索算法
SSA是Xue等[13]受麻雀种群觅食和反捕食的群体智慧的启发,提出的一种新的群体优化算法,该算法在搜索精度、收敛速度等方面均有很好的表现,因此将其用于预测模型的参数优化中。
在麻雀种群整个觅食过程中,分为发现者和加入者两种不同的类型。发现者在觅食和遇到捕食者的过程中,位置不断发生变化,其位置更新方式为

(2)
式(2)中:Xi,j为i个麻雀在j维中的位置信息;Imax为最大迭代次数;α为(0,1]内的一个随机数;R2∈[0,1]、S∈[0.5,1]分别为预警值和安全值;Q为服从正态分布的随机数;L为大小1×d、元素均为1的矩阵。
加入者的位置更新为

(3)
式(3)中:Xp为发现者觅食的最优位置;Xworst为当前全局最差的位置;A为一个大小为1×d、元素随机为-1或1的矩阵,且有A+=AT(AAT)-1;n为种群规模。
当麻雀种群发现捕食者时,会发出警告,其位置更新为

(4)
式(4)中:Xbest为整个麻雀种群中最优位置;β作为步长控制参数;K为麻雀移动方向同时也是步长控制参数;fi和fg分别为全局最好和最差适应度值;ε为最小常数,以避免分母出现零。
1.2.2 基于LSTM及注意力机制的波动项位移预测模型
LSTM是一种特殊的递归神经网络(recurrent neural networks,RNN),与RNN相比,LSTM在RNN的基础上新增了细胞状态,让相关序列信息连续传递下去,并引入“门控机制”,实现信息的添加和剔除,使得LSTM具有长期或短期的记忆能力,避免了RNN可能出现的梯度爆炸和梯度消失等问题[14]。LSTM的门控机制和细胞状态的计算过程如下所示。
ft=σ(Wf[ht-1,xt]+bf)
(5)
it=σ(Wi[ht-1,xt]+bi)
(6)
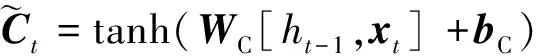
(7)

(8)
ot=σ(Wo[ht-1,xt]+bo)
(9)
ht=ottanh(Ct)
(10)
式中:W为各门控机制对应的权重矩阵;b为各门控机制对应的偏置向量;ft、it、ot分别为遗忘门、输入门和输出门的输出结果,遗忘门对信息进行丢弃或保留,输入门对细胞状态的信息进行选择性的更新,输出门确定下一个隐藏状态的值;xt为当前时刻的输入;Ct-1和Ct为前一时刻和当前时刻经过遗忘门和输入门后的细胞状态的输出结果;ht-1和ht为前一时刻和当前时刻的隐藏层状态;σ和tanh分别为Sigmoid函数和双曲正切函数。
传统的LSTM神经网络对于时间序列数据波动性具有较好的预测能力,但对于长序列的样本可能遗忘较早学习的内容,丢失一些重要信息,影响预测的精度。而注意力机制是一种模拟人类视觉接收信息的大脑信号处理机制,在某些特定的情况下,人脑会将注意力分配在需要重点关注的某些方面,对不需要重点关注的方面减少和不分配。这种机制可以从有限的注意力资源中快速筛选出大脑所需要的信息[15]。预测模型输入的数据在不同时间点对尾矿坝位移预测的重要性不同,注意力机制将输入的特征赋予不同的权重,能有效地突出LSTM网络预测结果中影响尾矿坝位移变形的关键特征,提高了模型的预测性能。
故将Attention机制引入LSTM中,以此建立模型对监测样本进行训练预测。模型结构如图1所示,分别为输入层、LSTM层、注意力机制层、输出层。
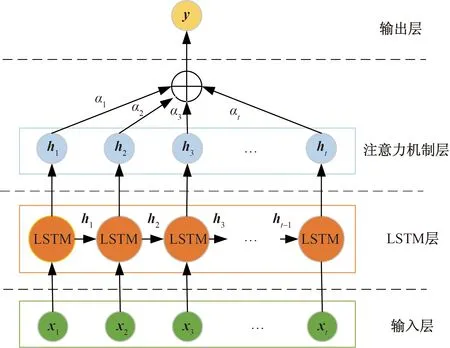
图1 LSTM-Attention模型结构图Fig.1 LSTM-Attention Model structure diagram
输入层将与波动项相关的影响因子监测数据xt作为模型的输入,传入LSTM神经网络;LSTM层负责对样本特征进行学习,得到对应隐藏层的输出ht;在隐藏层加入注意力机制,注意力机制层则对模型输入特征赋予不同的权重并不断更新,权重系数的计算方式如下。
et=utanh(w1ht+b)
(11)

(12)
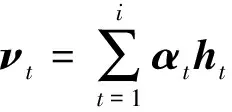
(13)
式中:et为t时刻的隐藏层向量;αt为注意力权重;u、w1为权重系数;νt为注意力机制层的输出;b为偏置向量。输出层通过全连接层输出下一时刻的预测结果,表达式为
yt=σ(w2νt+b)
(14)
式(14)中:yt为预测输出值;w2为权重矩阵,决定了模型在给定输入时预测输出的能力;b为偏置向量;σ表示Sigmoid函数。
1.3 尾矿坝位移预测流程
基于ICEEMDAN和SSA-LSTM- Attention模型的尾矿位移预测流程如图2所示。

图2 预测流程图Fig.2 Forecast flow chart
步骤1对原始监测数据进行预处理后,采用ICEEMDAN算法对位移时间序列进行分解为趋势项位移和波动项位移。
步骤2对趋势项位移利用其单调的增长特性采用高斯函数拟合预测;对于波动项位移,用灰色关联度筛选与其密切相关的影响因子,采用LSTM-Attention进行动训练预测,并利用SSA对该模型的超参数进行优化。
步骤3将趋势项位移和波动项位移的预测结果叠加得到尾矿坝累积位移预测值,并评价模型预测效果。
1.4 模型评价指标
采用均方根误差(RRMSE)、平均绝对误差(MMAE)和决定系数R2指标来评估模型的预测性能。各指标的计算公式如下。

(15)

(16)

(17)
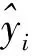
2 算例分析
所研究尾矿库位于攀西地区,尾矿库初期坝为碾压透水堆石坝,堆积坝采用上游法尾矿砂筑坝工艺。以尾矿库的北斗在线监测系统的历史数据为样本,监测数据包括坝体表面位移、降雨量和库水位。选择其中以位移变形较大、监测时间较长的监测点为实验数据,监测时间段为2020年5月1日—2021年7月31日,设备采样频率为1 h,共10 968个监测样本数据,选择前7 968个监测数据为训练集,其余数据作为测试集,训练集和测试集比例约为7∶3。由于北斗监测存在设备仪器及数据的误差,对于缺失值,进行3次样条曲线插值补全,对于明显异常游离的数据进行剔除。尾矿库监测点位坝体形变位移、月降雨量、库水位如图3所示。

图3 坝体累积位移、月降雨量和库水位关系图Fig.3 Relationship between volume displacement of tailings dam, monthly rainfall and reservoir water level
从图3中可以看出,坝体位移受库水位和降雨量双重影响,2020年5—8月处于雨季月份,降雨量增多,库水位上升幅度大,坝体位移变化加剧,平均位移变化速率为0.38 mm/d;2020年9月—2021年4月在非雨季月份,降雨量较少,坝体变形过程中库水位起主要影响,库水位变化变缓,坝体位移相对于雨季,平均变形速率为0.04 mm/d,位移变化趋于平缓。而在2021年5—7月,此时坝体位移的平均变化速率为0.26 mm/d,从监测数据可以看到降雨有逐渐增多的趋势,但总体降雨较少,因此库水位和坝体位移变化速率相比非雨季月份虽然有所增加,但增长较为缓慢。由此,可推断尾矿坝体的变形与降雨量和库水位有较大的相关性,在坝体位移预测过程中需要考虑库水位和降雨量的影响。
2.1 位移序列分解
对位移序列采用ICEEMDAN进行分解,得到1个残差项和11个IMF项。将分离出的残余项作为趋势项位移,其他IMF项相加作为波动项位移,如图4所示。
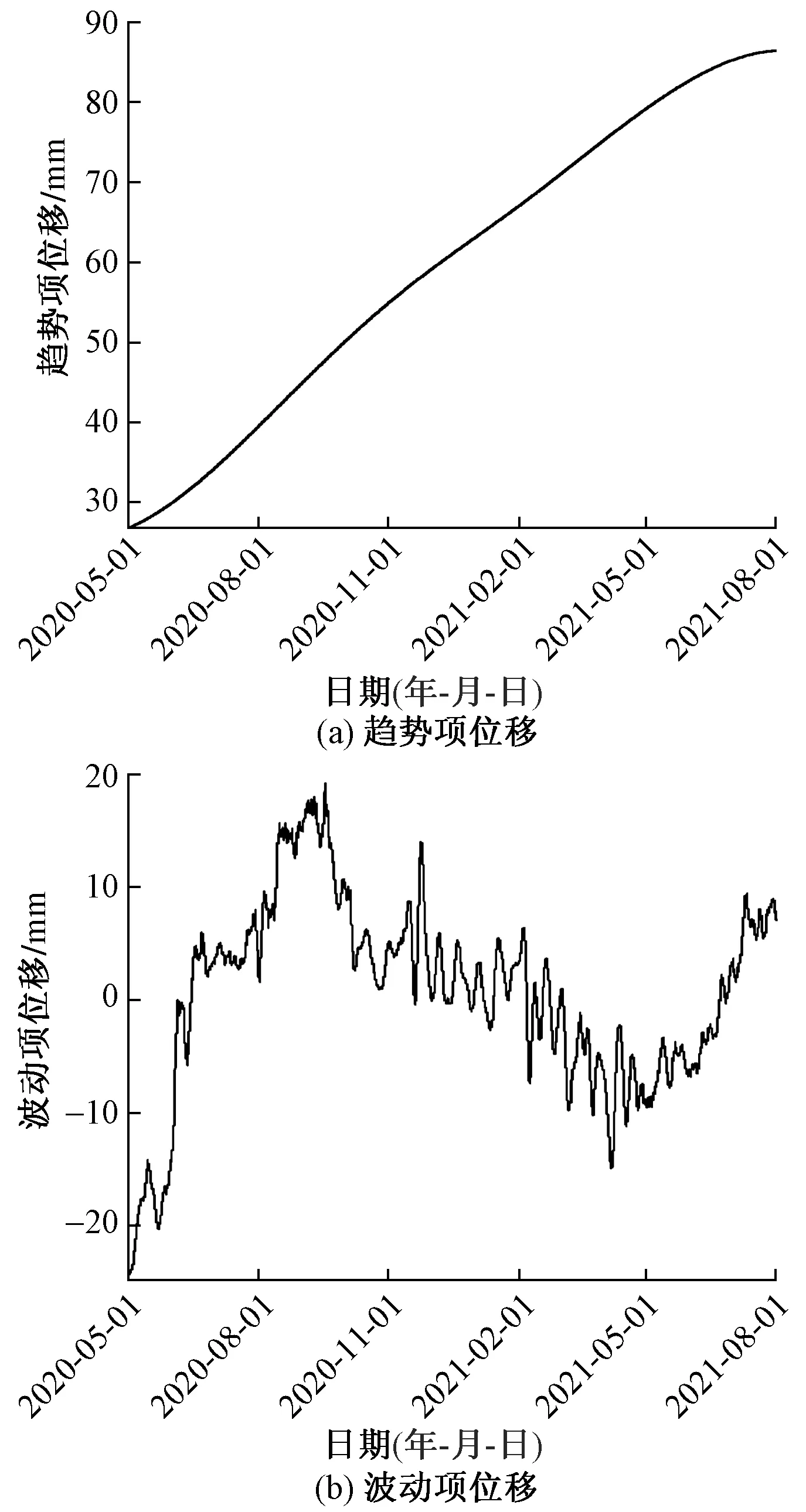
图4 ICEEMDAN分解的趋势项位移和波动项位移Fig.4 ICEEMDAN decomposition of trend term displacement and fluctuating term displacement
2.2 趋势项位移预测
受坝体势能、坝体特性影响,趋势项位移随时间表现出单调递增的趋势。因此用高斯拟合对趋势项拟合预测。拟合以高斯函数系为基础,采用3个高斯函数相加对训练集进行拟合,并将得到的拟合函数用于测试集的预测。拟合高斯函数表达式为
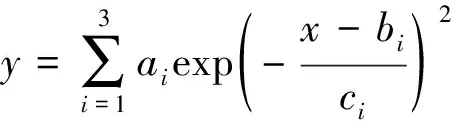
(18)
式(18)中:ai、bi、ci为高斯函数的参数。预测结果如图5所示,R2为0.91,MMAE为0.93 mm,RRMSE为1.1 mm。
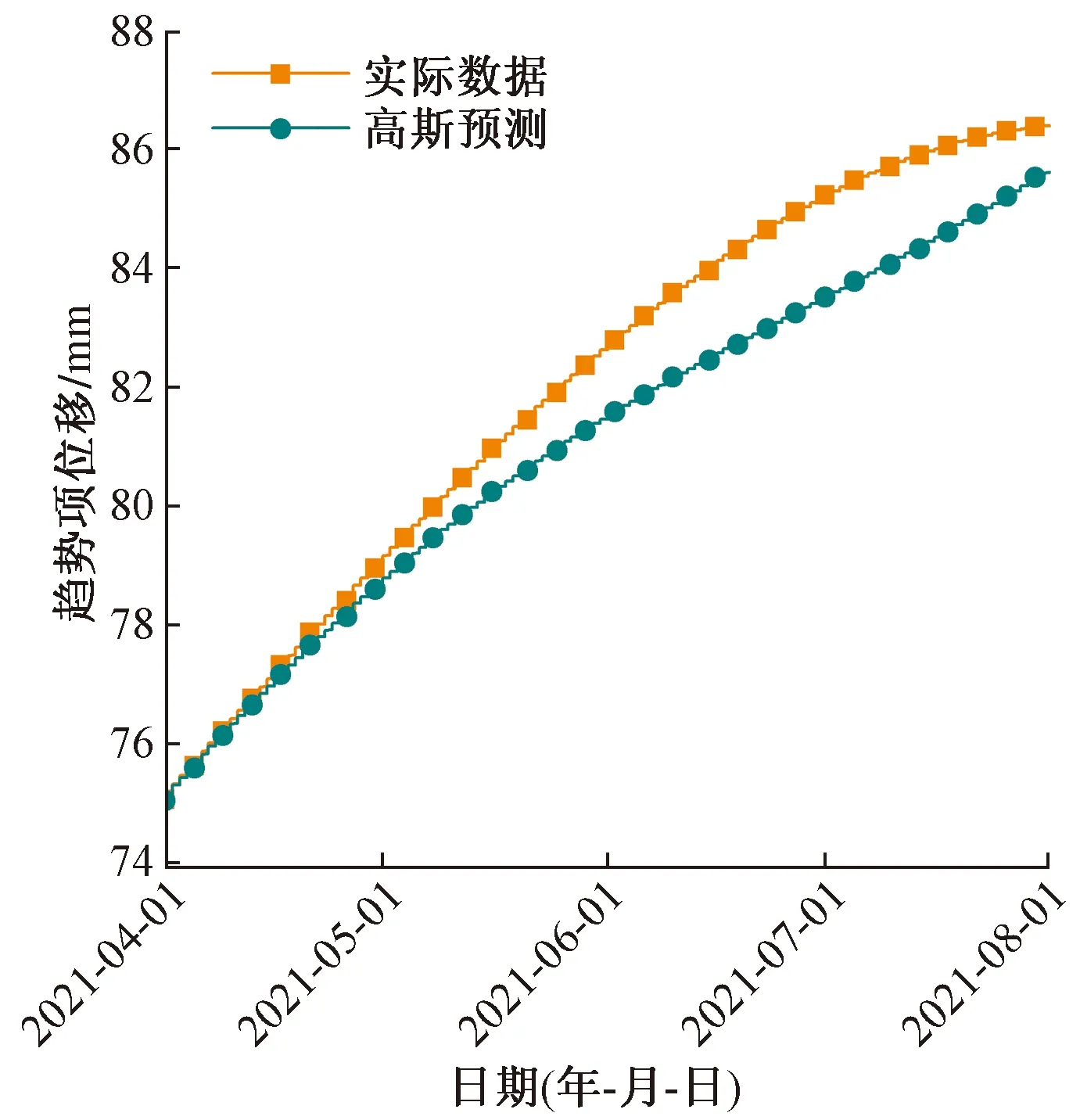
图5 趋势项预测结果Fig.5 Trend term forecast results
2.3 波动项位移预测
2.3.1 影响因子选取
考虑到降雨量和库水位对坝体位移影响的滞后性,以及坝体本身的演化趋势。因此将影响因素初步用趋势项位移变化量f1、当前库水位f2、每小时库水位变化量f3、前一月库水位f4、当前降雨量f5、每小时降雨变化量f6、前一月降雨量f7等7个影响因子表示,并采用灰色关联度对影响因子进行筛选。灰色关联度ri计算公式如下。

(19)
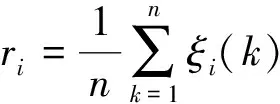
(20)
式中:Δmin为参考数列和比较数列的最小绝对差值;Δmax为参考数列和比较数列的最大绝对差值;Δ0i(k)为参考数列和比较数列的插值;ρ为分辨系数,取ρ=0.5;ξi(k)为关联系数。影响因子和波动项位移间的关联度如表1所示。

表1 波动项位移与影响因子的关联度
一般认为当关联度ri>0.6时,即可认为影响因子与波动项位移具有较强的相关性。因此选择f1、f2、f3、f4、f6、f7用于波动项位移的预测。
从表1关联度可以看出,库水位相关的影响因子与波动项位移的关联度基本上都密切相关,降雨量的影响因子中,当前降雨量、前一月降雨量的与波动项位移的关联度较低,而当前降雨变化量与波动项位移的关联度较高。结合图5监测数据,分析其原因,首先,所选监测时间内,降雨的变化主要对库水位影响较为明显,而对坝体位移的直接影响相对较低,主要通过库水位来间接对坝体位移产生影响。库水位对坝体位移的影响在降雨后加剧,改变了原降雨量对坝体位移的影响的相关性。其次,研究中尾矿库降雨量监测与坝体位移监测位置不一致且降雨具有随机性,使得降雨量与波动项位移的相关度较低。说明库水位是所研究尾矿库坝体变形的主要影响因素,而降雨量是次要影响因素。
2.3.2 预测结果对比和分析
将筛选的影响因子作为输SSA-LSTM- Attention的输入,波动项位移作为模型的输出,通过SSA对模型的超参数优化,得到的学习率为0.001 1,迭代次数为112,第1隐含层节点数为92,第2隐含层节点数为35。训练模型时采用Adam优化器作为模型的优化函数。分别采用BP、LSTM、LSTM-Attention、SSA-LSTM-Attention进行预测对比。波动项位移预测结果对比如图6所示。相比与其他模型,SSA-LSTM-Attention预测结果更为吻合。
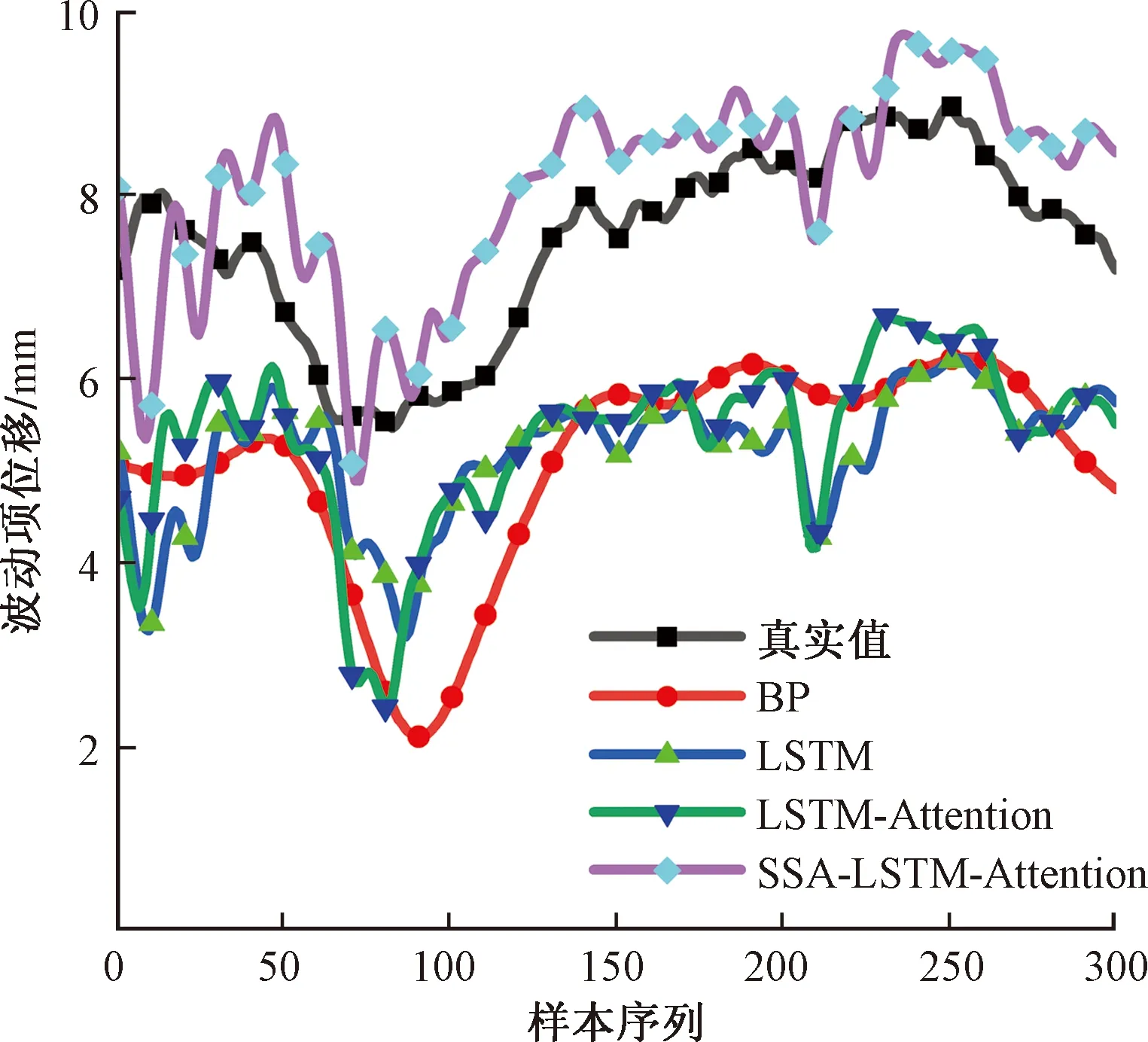
图6 波动项预测结果Fig.6 Fluctuation term prediction results
不同模型下波动项位移预测精度对比如表2所示。

表2 不同模型下波动项位移预测精度
由表2可以看出,在波动项位移预测中,BP预测精度最低,这是因为BP是一个静态模型,对于尾矿坝位移这一动态时变过程进行预测具有局限性,相较于传统的BP、LSTM模型,加入注意力机制的LSTM模型能显著提升其与时序特征相关的提取能力,而结合SSA优化及注意力机制的LSTM模型,通过搜索其最佳训练参数,可以使预测精度更高,效果更好。
2.4 尾矿坝体累积位移预测
将预测得到的趋势项位移和波动项位移相加即得到坝体累积位移,最终得到的累积位移预测值的MMAE为0.553 mm,RRMSE为0.742 mm,R2结果为0.994,预测结果对比如表3和图7所示。

表3 累积位移预测精度对比表
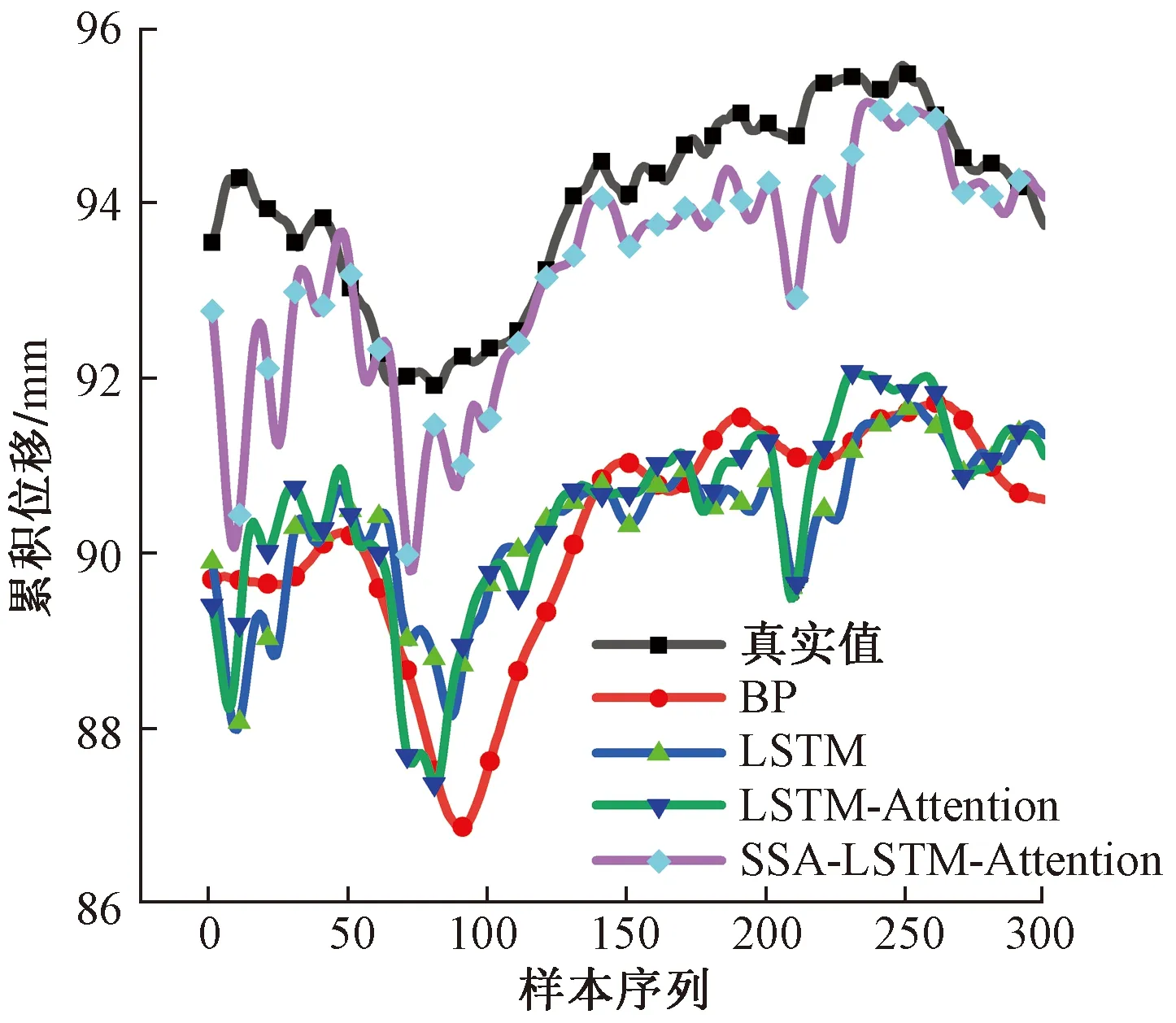
图7 累积位移预测结果Fig.7 Cumulative displacement prediction results
从表3可以看出,在累积位移预测中,SSA- LSTM-Attention模型的RRMSE和MMAE与LSTM-Attention相比,分别下降了57.5%和57.8%,R2提升28.2%,从图7中可以看出,SSA-LSTM-Attention能更好地预测出坝体表面位移变化,对于后续预警研究有较好的实用价值。
3 结论
(1)以攀西地区尾矿库坝体监测数据为例,提出了一种基于ICEEMDAN的时间序列分解方法和SSA-LSTM-Attention的尾矿坝累积位移预测模型,对比分析了SSA-LSTM-Attention的预测模型相对于BP、LSTM、LSTM-Attention模型在进行位移预测时的优势。RRMSE、MMAE、R2结果表明,SSA-LSTM-Attention模型预测效果最好,具有较高的工程应用价值。
(2)通过灰色关联度对波动项位移相关影响因子进行定性分析的结果可知,影响尾矿坝变形的主要因素是库水位,降雨量次之。在条件允许的情况下,可根据工程实际,加入更多的尾矿坝影响因素的北斗监测数据(如浸润线、内部位移)等可以对坝体变形进行更进一步的分析。
