基于OAT架构的审计凭证数字化方法
2023-11-03何梓源张仰森成琪昊
何梓源,张仰森,向 尕,成琪昊
(北京信息科技大学 智能信息处理研究所,北京 100192)
0 引 言
目前,对于审计流程数字化的研究还处于初级阶段。有许多的国内外学者对多源、异构、异质的审计信息进行研究[1,2]。Rezae等[3]提出使用数据仓库技术,将数据格式进行统一,以应对频度要求更高的审计工作。审计过程的数字化阶段主要需要用到OCR光学字符识别技术[4-7]。王兴等[8]对OCR用于票据识别的算法进行研究,通过关键字匹配与字符大小匹配相结合的算法,可以在自然场景下对火车票据有很好的识别效果。正如王兴的研究所述,OCR识别可将数据结构化展示,并利用数据分析工具检索出有价值的信息[9-13]。
本文通过研究审计凭证数字化及文本分类技术,构建了OAT(optical character recognition attention for text)审计数字化架构,极大提升了文档关键信息检索效率。在数据获取阶段,首先通过相关审计部门获得部分高质量审计凭证文档,用于OCR识别准确率的测试及OCA(optical character with attention)模型调优,然后通过爬虫技术获取网上的审计文本,并构建审计联合知识库。在OCR识别阶段,构建OCA多阶段光学字符识别模型,对审计凭证纸质文本进行数字化转换,并利用模型蒸馏技术,提升OCA模型的处理速度。在文本过滤阶段,利用ACPmarked(attention convolution polling marked)架构提取与审计任务相关的语句,形成数字化的高质量审计文本。实验结果表明,基于OAT的审计凭证数字化架构可以极大提升文档关键信息的检索效率,验证了本文提出的OCA模型与ACPmarked架构综合应用的有效性。
1 基于OCA的多阶段光学字符识别模型
目前OCR的应用场景主要分为,自然场景文本检测与识别、手写体文本检测与识别、文档文本检测与识别,审计凭证属于文档文本检测与识别。文档文本的处理方法分为单阶段与多阶段处理。传统的单阶段文本识别,准确率不高,存在丢失文本内容的现象。传统的多阶段文本识别精准度较好,但检测时间过长,对于篇幅较长的审计文本识别效果不佳。本文在传统多阶段文本识别模型的基础上,引入图像增强算法及注意力机制,提升模型的准确率,并通过模型蒸馏技术优化模型参数,降低检测时长。
1.1 位置检测模型
纸质文本数字化的首要任务,是在复杂的场景中定位文字的位置,即文字检测。CTPN[14](connectionist text proposal network)算法通过改进的vertical anchor方法,只预测文本竖直方向上的位置,将方格的宽度固定,不对水平方向进行预测。其中方格水平长度为16像素。纵向长度为11像素至283像素,将此区间每次除以0.7得到10个anchor,具体数值为:11,16,23,33,48,68,97,139,198,283。随后利用循环网络对检测的小尺度文本进行连接,得到文本行。检测效果如图1所示。

图1 CTPN文字检测
其中,卷积神经网络使用VGG[15]提取图像特征;循环神经网络使用双向长短期记忆网络对特征进行拼接;最终利用全连接神经网络以及RPN网络得到CTPN文字检测结果。
1.2 文字识别模型
通过1.1节所描述的CTPN文字检测算法,可以定位图像中文字的具体位置,随后利用CRNN(convolutional recurrent neural network)算法对文字进行识别。CRNN模型主要分为3部分:卷积神经网络层、循环神经网络层、转录层。卷积神经网络层,通过CNN(convolutional neural network)网络提取图像特征;循环神经网络层,利用双向长短期记忆网络提取文本的序列化特征;转录层引入CTC[16](connectionist temporal classification)Loss计算方法,对识别内容进行无需对齐的损失值计算;最终经过softmax层得到字符输出。
1.3 OCA多阶段光学字符识别模型
1.3.1 引入注意力机制
注意力机制最早广泛用于计算机视觉领域,传统无注意力机制的Encoder-Decoder框架将隐含信息统一处理,因此会丢失关键信息,使得模型整体水平下降。不同于无注意力机制的模型,带有注意力机制的模型将输入语句中的每个单词,都依据其语义信息,获得不同的注意力概率分配。
本文利用Soft Attention机制,构建Context Vector环境向量,并将其嵌入到模型中与模型共同训练,其原理公式如式(1)、式(2)所示
(1)
(2)
其中,Q为查询向量,K与V通常为序列本身。在进行注意力运算时,首先通过向量Q与每个向量K进行相似度计算,并通过SoftMax函数对结果进行归一化操作,随后使用得到的权重和对应的向量V进行加权求和,获得最终的Attention注意力值。
1.3.2 知识蒸馏
知识蒸馏通常用于模型压缩,提升模型运算效率,其流程如图2所示。
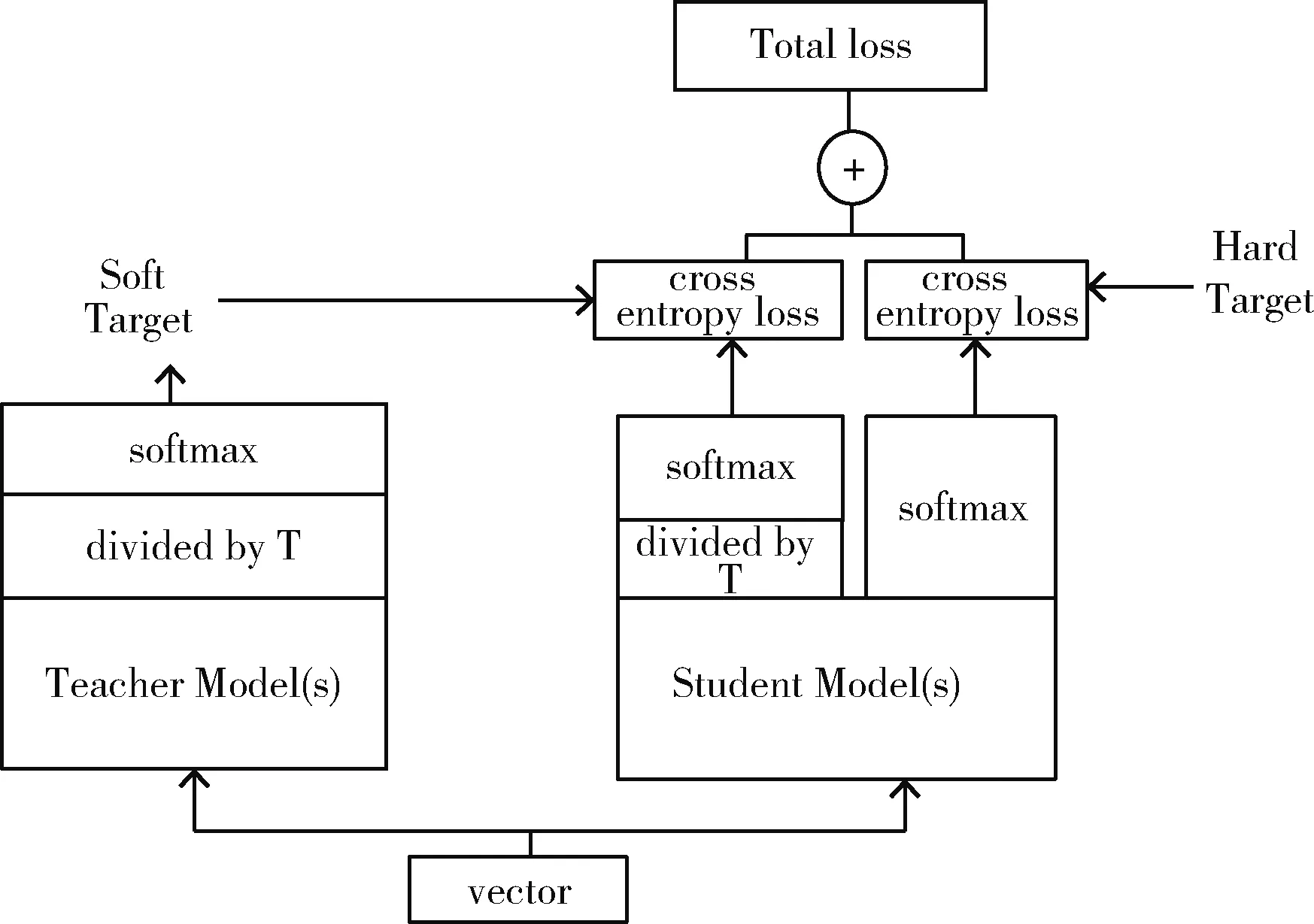
图2 知识蒸馏模型
此方法将参数庞大的模型知识,转移到参数量较小的模型上,极大提升了模型运算效率。因此,针对多阶段OCR模型运算时间过长的问题,本文利用知识蒸馏技术,在保证准确率的同时提升模型整体效率。知识蒸馏可考虑成一个广义的Softmax函数,如式(3)所示。交叉熵损失公式如式(4)所示
(3)
(4)
其中,T为调节参数,当T无限趋近于0时,结果接近于one-hot向量。当T趋近于无穷时,模型可学习更多的可能性。zj为新模型产生的logits,qi是真实概率,pi为预测概率。
1.3.3 OCA多阶段光学字符识别模型
为了在保证模型准确度的基础上解决模型运算效率问题,本文构建了OCA多阶段光学字符识别模型,模型流程如图3所示。

图3 OCA模型流程
图像增强阶段主要分为3个步骤:①图像矫正;②凸显文字特征;③文字锐化。在图像矫正阶段,首先对图像进行二值化处理,将文字部分转换成白色,图像背景转换为黑色。其次计算包含全部文字在内的最小旋转文本边框,此边框的旋转角度与文本的旋转角度相一致。最终调整图像角度对其进行仿射变换。过程如图4所示。

图4 审计文本图像矫正
在文字特征凸显阶段,首先对图像进行对比度增强,随后利用直方图正规化技术对图片进行细节效果处理,直方图正规化公式为式(5)、式(6)
(5)
(6)
直方图正规化是一种线性变换方式。输入图像为I,I(r,c) 表示I的第r行第c列的灰度值,将I中出现的最小灰度级记为Imin, 最大灰度级记为Imax。 在文字锐化阶段,通过对图像中文字的锐化操作,有利于提升模型最终的识别准确率,实验见3.3小节,最终获得的图像如图5所示。

图5 图像增强阶段效果对比
在文字检测与文字识别阶段,利用Soft Attention机制,构建Context Vector环境向量,并将其嵌入到模型中共同训练。使得模型当前输出的单词得到不同的注意力概率分配,有助于提升模型识别准确率。
文字检测知识蒸馏阶段,Teacher模型在卷积层并行使用VGG16与ResNet50网络结构,并将两者的运算结果进行拼接。在循环网络层,使用基于注意力机制的双向长短期记忆网络,对序列化特征进行提取。最后,通过全连接层与RPN网络得到运算结果,并将其进行知识蒸馏得到软知识。Student模型使用VGG16网络并增加了dropout机制。在循环网络层,使用基于注意力机制的双向长短期记忆网络,并通过单个全连接层与RPN网络得到运算结果。在设计损失函数时,Student模型同时学习硬知识(hard tag)与软知识(soft tag)如图2所示。
文字识别知识蒸馏阶段,Teacher模型在卷积层使用VGG16卷积神经网络提取图像特征。随后利用基于注意力机制的双向长短期记忆网络,提取文本序列化特征。最后将向量传入带有CTC损失函数的转录层得到结果,并将结果进行知识蒸馏得到软知识。Student模型使用3层CNN卷积单元对图像特征进行提取。随后将所得向量通过基于注意力机制的双向长短期记忆神经网络。最后利用带有CTC损失函数的转录层得到向量结果。在设计损失函数时,Student模型同时学习硬知识(hard tag)与软知识(soft tag)。
综上所述,OCA多阶段光学字符识别模型首先对输入图像进行图像增强,其次利用Teacher文字检测模型和Teacher文字识别模型,训练Student文字检测模型和Student文字识别模型。最后依次将图像增强、Student文字检测模型和Student文字识别模型进行串连,得到OCA多阶段光学字符识别模型。
2 基于ACPmarked的语义分类架构
目前,在网络平台上通过爬虫技术获得的审计报告,存在大量与审计业务本身无关的信息,例如:公司介绍、渠道广告等。本文利用ACPmarked多语义融合架构,对数字化后的文本进行文本分类,有效去除审计业务无关的信息。ACPmarked架构主要包括3个模块:Transformer模块、基于注意力的双向长短期记忆模块、卷积与池化模块。首先将Transformer模块与基于注意力的双向长短期记忆模块并行排布,丰富审计报告的词向量表达,随后通过卷积与池化模块进一步提取文本特征。最终通过全连接层输出预测结果。
首先,通过爬取百度百科及头条新闻约28 G的文本作为Transformer模块的预训练语料,并利用word2vec模型进行训练。随后,引入位置编码矩阵,得到带有位置编码的词向量。然后,利用多头自注意力机制,对传入的文本向量进行编码,得到词向量表示。基于注意力的双向长短期记忆模块,利用wiki50维预训练词向量对文本进行向量化,随后通过引入注意力机制,对双向长短期记忆网络的输出结果进行注意力强化,提升模型分类准确率。卷积与池化模块,首先将Transformer模块与基于注意力的双向长短期记忆模块所输出的结果进行拼接,随后利用不同尺寸的卷积核提取文本间的关系。通过设置卷积核尺寸为kernel=2、kernel=3、kernel=4进而提取两个字、3个字以及4个字之间的相互关系,提升模型识别的整体效果。ACPmarked多语义融合架构如图6所示。
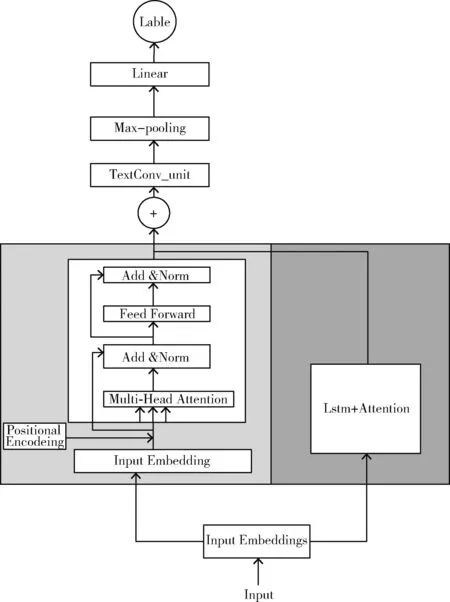
图6 ACPmarked多语义融合架构
3 实验设计与数据分析
为了获取真实的实验数据,本文通过相关审计部门获得了高质量的审计文档,并利用爬虫技术爬取了百度文库、百度贴吧的相关审计工作报告。为模拟传统审计流程,本文对审计文档及工作报告进行打印,并利用扫描仪对纸质版审计文件进行扫描,构建图像数据资源库。利用OCA模型对图像数据资源库中的数据进行识别,得到数字化可编辑的审计工作报告。利用ACPmarked架构对审计工作报告进行文本分类,去除文本中与审计无关的内容。
3.1 图像数据资源库构建
传统审计流程是依靠工作人员手工作业的办法,对纸质文件进行审计。本文利用扫描仪,对待审计文本进行扫描,获得图像。在扫描纸质文件时,不可避免的会出现:①曝光过度;②图像模糊;③图像旋转角过大等问题。如图7所示。

图7 扫描过程中的问题图像
其中,曝光过度与图像模糊会极大影响后续模型识别的效果,需要对图像重新进行扫描。图像旋转角过大等问题不用重新扫描,可作为后序工作的图像来源。
3.2 OCA多阶段光学字符识别模型参数选择
3.2.1 OCA图像增强阶段的方法选择
图像资源库中的图片可能会出现图像旋转角度过大、图片文字不清晰等问题,本文针对5000张问题图片进行实验,并利用未引入完整图像增强阶段的OCA模型,对图像中的文字进行检测与识别。准确率如式(7)所示,其中,其中TP为正例预测结果也是正例的个数,TN为负例预测结果也是负例的个数,FP是正例预测结果为负例的个数,FN是负例预测结果为正例的个数,分子为所有预测正确的个数,分母为所有数据的总个数。实验结果见表1~表5

表2 OCA图像增强阶段的方法选择-凸显文字特征

表3 OCA图像增强阶段的方法选择-文字锐化
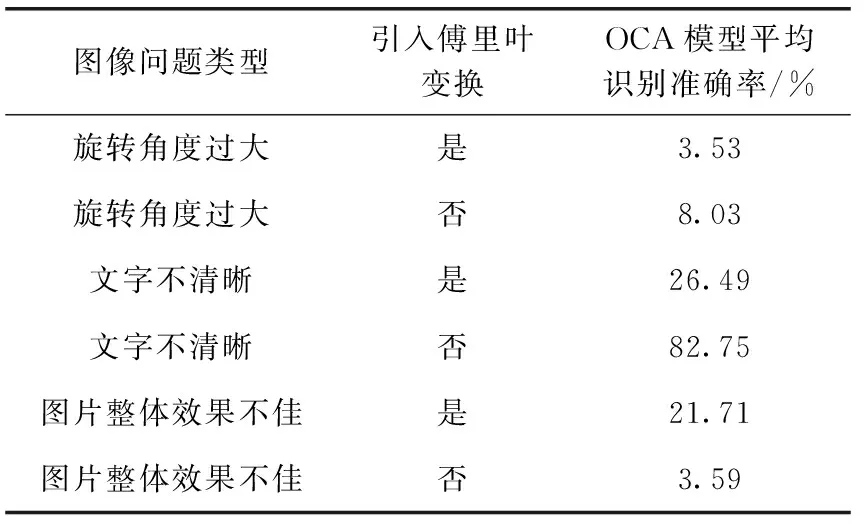
表4 OCA图像增强阶段的方法选择-傅里叶变换
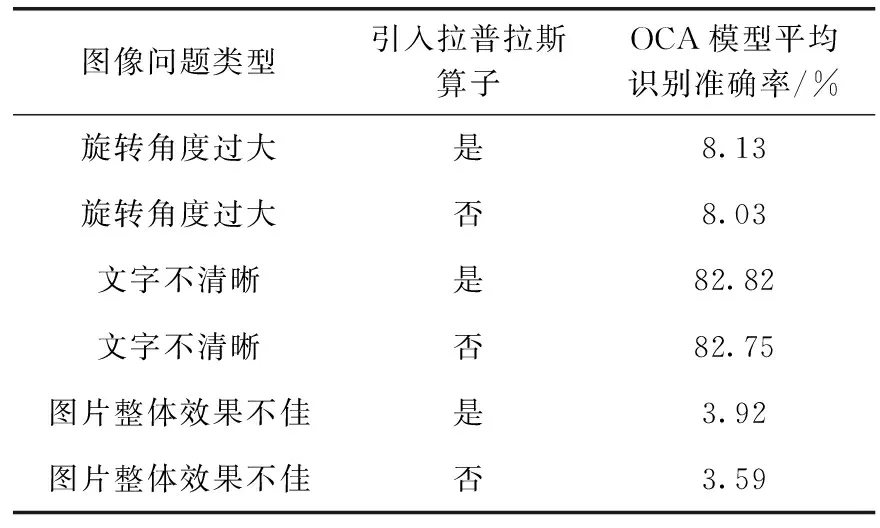
表5 OCA图像增强阶段的方法选择-拉普拉斯算子
(7)
综上所述,本文在图像增强阶段使用:①图像矫正;②凸显文字特征;③文字锐化,其中图像矫正阶段本文使用图像二值化、计算最小旋转文本边框、仿射变换等操作处理图像数据。在凸显文字特征阶段对图像进行对比度增强及直方图正规化处理。在文字锐化阶段使用锐化算法对图像进行锐化操作。最终结果见表6。
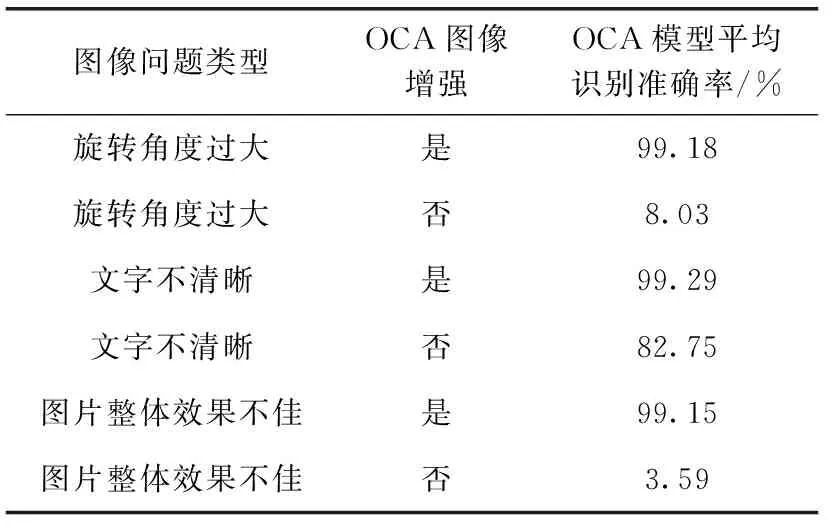
表6 OCA图像增强识别结果
上述结果表明,利用OCA图像增强技术在审计文本的图像增强方面取得了很好的结果,并为后续OCA模型识别做出明显贡献。因此本模型使用OCA图像增强技术对待检测图像进行处理。
3.2.2 OCA知识蒸馏参数选择
本文通过知识蒸馏的方法,可以在保证模型准确率的情况下,提升模型的运算效率。针对原文本与识别文本间的区别,通过平均精确率P、平均召回率R与平均F1值(分别如式(8)~式(10)所示)对OCA多阶段光学字符识别模型运算结果进行计算
(8)
(9)
(10)
其中,xi表示人工标注标签个数,yi表示算法获取的标签个数,N为审计文本总数。分别使用不同的温度T对模型知识进行蒸馏实验结果见表7。
通过表7可知在温度T=8时,学生模型平均准确率最高。通过阅读相关论文中的调参技巧,对学生模型的全连接层引入rulu激活函数。调节参数T与激活函数所对应的实验结果见表8,实验过程准确率变化图如图8所示。

表8 调节参数T与激活函数所对应的实验结果

图8 测试数据集准确率
结合表8与图8所示,本课题最终选用知识蒸馏温度T为8,并且对全连接层使用relu激活函数。
3.3 OCA多阶段光学字符识别模型算法评估
在图像数据资源库中,随机选择20 000张人工扫描的审计工作报告,利用PaddleOCR、tesseract、EasyOCR作为对比模型进行实验,实验结果见表9。

表9 图像识别平均F1值计算结果
数据表明,OCA-student模型相比于其它模型在综合处理效率上取得了最好的成绩。此结果的根本原因在于,人工扫描的审计工作报告并非完全水平,其存在人工扫描中不可避免的旋转角度。以PaddleOCR为例,其识别水平文本的效果很好,但对于人工扫描的审计工作报告则得不到很好的结果,模型结果可视化对比如图9所示。因此定义OCA-student模型为最终OCA多阶段光学字符识别模型。

图9 模型结果可视化对比
3.4 ACPmarked多语义融合架构算法评估
ACPmarked架构主要由Transformer模块、基于注意力的双向长短期记忆模块、卷积与池化模块所构成。其目的在于,对数字化后的审计文本,提取文件中与审计任务相关的语义信息。通过总结广告宣传语和公司介绍所涉及的关键词,本文进一步构建了基于审计工作报告的停用词词典。最终,基于ACPmarked架构与停用词词典的共同处理,形成数字化的高质量审计文本。由于审计工作的时效性要求,需要在短时间内给出审计结果。因此,本文所涉及的审计凭证数字化流程十分注重模型的效率。这里引入时效比公式,用于衡量模型准确率与其所需时间的效率比,公式如式(11)所示。其中TP为时效比,t为cup计算每条数据的平均时间。本文利用Bag-of-word、LSTM、Attention based Bi-LSTM、BERT-Attention作为对比模型进行实验,结果见表10
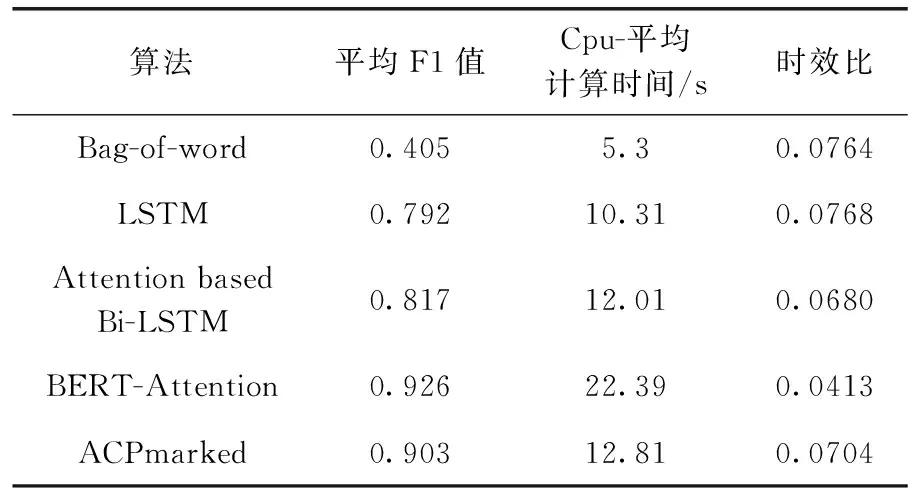
表10 文本分类平均F1值计算结果
(11)
由表10可以看出ACPmarked模型在平均F1值上远超于Bag-of-word、LSTM、Attention based Bi-LSTM模型。在时效比上远超BERT-Attention模型,且cup计算每条数据的平均时间约比BERT-Attention模型减少了一倍。因此,利用ACPmarked多语义融合架构对数字化后的审计文本进行处理。
4 结束语
本文将传统审计流程与信息化技术相融合,提出了基于OAT的审计凭证数字化架构,以实现审计凭证的数字化。OAT架构主要由OCA多阶段光学字符识别模型与ACPmarked多语义融合架构所组成。不同于传统的OCR识别方法,OCA多阶段光学字符识别技术融合图像增强技术与注意力机制,并利用知识蒸馏技术,在保证准确率的基础上,提升模型处理速度。随后利用ACPmarked架构提取与审计任务相关的句子,形成数字化的高质量审计文本。OAT架构可以有效实现审计凭证的数字化,减轻审计专业人员的劳动强度,对提高审计效率和质量具有重要意义。
