基于多任务自编码器的MOOC课程推荐模型
2023-11-03董永峰王巍然王雅琮
董永峰,王巍然,董 瑶+,史 进,王雅琮
(1.河北工业大学 人工智能与数据科学学院,天津 300401;2.国家开放大学数字化学习技术集成与应用教育部工程研究中心,北京 100039;3.河北工业大学 河北省大数据计算重点实验室,天津 300401)
0 引 言
在课程推荐领域,由于课程数量众多,学习者个体选择的课程较少。因此,如何解决数据稀疏性及数据噪声的问题成为研究者关注的焦点[1-3]。
最新的研究表明,在不同任务之间共享嵌入参数功能,可以有效缓解数据的稀疏性。阿里巴巴团队提出的全空间多任务模型(entire space multi-task model,ESMM)[4],以及该模型的强化版(entire space supervised multi-task model,ESM2)[5],通过对学习者行为进行分解产生额外的辅助信息来有效利用已有的数据,学习者的相关行为使共享模块的参数训练能够更准确挖掘学习者行为偏好。
本文通过分析学习者学习课程的行为,对ESMM模型进行改进,提出基于多任务自编码器的课程推荐模型(multi-task autoencoder course recommendation model,MAEM),充分挖掘学习者在线学习的行为特征,为学习者提供个性化的课程推荐。本文主要贡献如下:
(1)针对数据稀疏问题,MAEM充分挖掘学习者的行为信息,包括学习者注册课程、学习者浏览章节列表和学习者学习完毕课程行为之间的隐含关系。由此构建多任务模型,通过实验分析将课程推荐任务分为两个子任务:任务一是学习者浏览课程章节列表行为,任务二是完成课程50%的学习行为,主要在共享嵌入层学习通用特征表示,再分别计算子任务的概率,更好地预测学习者所需的课程,提高泛化能力。
(2)针对数据高噪声、高维度和低质量的问题,在有监督的子任务训练中使用相同的无监督的自编码器网络进行数据处理,解决不同子任务的输入数据无法统一处理的问题,从而达到共同优化训练共享嵌入层参数,构建提取特征与行为分解一体化的深度神经网络。
1 相关工作
推荐算法用于帮助人们准确找到需要的信息,当前的主流研究以深度学习为基础,在模型中嵌入特征处理、注意力机制、多任务学习、自编码器完成推荐任务。
特征处理能够有效的提取特征,并自动过滤无效信息与噪声。在对特征的捕捉上,神经因子分解机(neural factorization machin,NFM)[6]、深度因子分解机(deep factorization machine,DeepFM)[7]和极限因子分解机(eXtreme deep factorization machine,XDeepFM)[8]结合了因子分解机(Factorization machine,FM)建模二阶特征交互中的线性结构,以及深度神经网络(deep neural networks,DNN)建模高阶特征交互中的非线性结构,将数据集原始特征传递给深度神经网络,以显式或隐式地学习特征交互。在高阶特征的学习上,深度交叉网络(deep &cross network,DCN)[9]和基于项目的神经网络(product-based neural networks,PNN)[10]保留了DNN的优点,能够自动且高效的学习高阶特征交互。然而有用的交互通常是稀疏的,因此Liu B等[11]提出了一种基于卷积的特征生成网络结构,自动从原始特征中拼接提取的特征。
注意力机制能够表达用户自身偏好的重要性程度。Xiao J等[12]提出注意力因子分解机(attentional factorization machine,AFM),AFM通过注意力机制来自动学习每个二阶交叉特征的重要性,调节交叉特征对于预测结果的贡献度。Alfarhood M等[13]提出协作式双注意力自动编码器(collaborative dual attentive autoencoder,CATA++),CATA++利用科学文章的内容并通过两个并行的自编码器学习其潜在空间。
多任务模型可以学习不同任务的共性和错误,这将提高所有子任务的训练效果和可靠性。Ma J等[14]提出了多门专家混合的多任务学习方法,从数据中明确学习任务之间的关系。Gao C等[15]提出了神经多任务推荐的模型,学习不同类型行为之间的级联关系。Ni Y等[16],提出构建学习跨多个任务的通用用户表示模型,实现更有效的个性化推荐。
自编码器是一种使用反向传播算法使输出值等于输入值的神经网络。对于自编码器在推荐算法中的应用,Li X等[17]提出了协同变分自编码器,通过无监督方式学习内容信息的隐含表示,可以在复杂的多媒体场景下完成复合推荐任务。Liang D等[18]提出了基于变分自编码器的生成模型,将变分自编码器应用于基于隐式反馈的协同过滤算法中,通过多项式似然生成模型克服线性因子模型在推荐算法中的局限性。
2 模型设计与实现
基于多任务自编码器的课程推荐模型(MAEM),旨在解决课程推荐中的数据稀疏、数据噪声、数据低质量和高维度问题。模型的总体任务分为学习者浏览课程章节列表行为和完成课程50%的学习行为两个子任务,由共享嵌入模块、自编码器与分解预测模块、任务组合模块3个模块组成。该模型将学习者的在线学习课程行为作为辅助信息,推断学习者对课程的偏好。基于多任务自编码器的课程推荐模型如图1所示。

图1 基于多任务自编码器的课程推荐模型
2.1 共享嵌入模块
共享嵌入模块嵌入所有来自学习者字段和课程字段的稀疏ID特征和密集数值特征。其中,学习者字段包括学习者的ID、年龄、性别、学历、注册课程、浏览章节列表、学习50%以上课程、成绩、学习理由、参与积极性、学习时长、首次学习时间、最后学习时间、与课程交互数、学习课程天数、浏览模块比例、发帖次数;课程字段包括课程的ID、科目、作业数量、开始日期、结束日期、开设天数。
子任务的嵌入层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数数量占整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。池化层把所有实体嵌入向量求和得到一个唯一的向量。改进的模型中共享参数机制能够使两个子任务从各自的目标中共同训练网络参数。流程如下:
(1)提取嵌入向量E。首先将离散特征进行独热编码,连续特征做离散化再进行独热编码。通过嵌入将高维稀疏向量转为低维稠密向量。对于所有嵌入向量E如式(1)所示
(1)
式中:E为全体特征向量,e为每名学习者特征向量,n为特征向量数量,D为向量维度。
(2)对嵌入向量E进行卷积提取其重要特征,第一层卷积层的输出C1如式(2)所示
(2)
式中:k为卷积核大小,s为步长。再将该层的输出C1使用最大池化层来捕捉最重要的交互特征。
(3)再将该层的输出C1使用最大池化层来捕捉最重要的交互特征,那么第一层池化层输出P1如式(3)所示
P1=(C1-Psize+2×Ksize)÷Ssize+1
(3)
式中:Psize为池化窗尺寸,Ksize为填充值,Ssize为步长。池化后的结果有两处去向:
第一处:直接提取该层特征。对提取特征进行重组,将该层的结果乘以权重矩阵WS和偏置BS来打乱特征的输入顺序,由此保留全局特征,避免了CNN的局部特征感知对结果的影响。使用打乱后的特征来产生新特征R1如式(4)所示
R1=tanh(P1·WS+BS)
(4)
式中:WS表示提取特征矩阵参数,BS表示提取特征矩阵偏置。由此,R1为第一层卷积层产生的新提取特征。
第二处:继续重复上述步骤直至第m层卷积层。产生新的提取特征为R1,R2,…,Rm,m为卷积层层数。最后拼接所有卷积层提取特征,形成用于深度学习分解预测模块的特征提取嵌入矩阵E′,如式(5)所示
E′=(R1,R2,…,Rm)D
(5)
2.2 自编码器与分解预测模块
自编码器操作可以自动从数据样本中进行自监督学习。通过训练自编码器,可以使卷积结构自动提取到的特征输入编码器再通过解码器解码后,保留尽可能多的信息,由此来提高模型的泛化程度。
自编码器第一层为编码层,用于接收提取特征;第二层为隐藏层,用于学习隐藏特征,并对提取特征进行降维与降噪;第三层为解码层,用于完成自监督训练。其编码过程的隐藏层hidei如式(6)所示
hidei=σe(Wi·E′+bi)
(6)
式中:i是隐藏层的数量,σe为编码器对特征的距离度量,Wi为编码的权重,bi为编码的偏置。权重与偏置用于神经元记忆学习者的行为特征。解码结果E″如式(7)所示
E″=σd(W·hidei+b)
(7)
式中:σd为解码器对特征的距离度量;W为解码的权重;b为解码的偏置。损失函数j(W,b) 如式(8)所示

(8)
自编码器的训练过程使用传统的基于梯度的方式进行训练。对处理后的数据进行分解预测操作,进行模型的参数训练。
分解预测操作的总体任务PBrowse to Study旨在预估学习者能够学习完毕该课程的概率,PBrowse to Study如式(9)所示
PBrowse to Study=P(Study|Browse,Show)
(9)
根据学习者在线学习过程,学习者先点击符合自己需要的课程,再浏览课程的章节列表,最后学习完毕该门课程。所以在分解预测模块中,将这一在线学习行为分为两个训练任务:子任务1(PBrowse):学习者浏览课程名称→学习者浏览章节列表的概率;子任务2(PStudy):学习者浏览章节列表→学习者学习课程超过50%的概率。拥有学习50%以上课程行为的学习者在数据集中被标记为正样本。
在总体任务中,E″是高维稀疏多域的特征向量,y表示是否浏览章节列表,有浏览行为则y取值为1,无浏览行为则y取值为0。z表示是否学习完毕50%课程,学习完毕50%课程z取值为1,未学习完毕z取值为0。y→z揭示了学习者行为的顺序性,即浏览课程章节列表行为一般发生在学习完毕课程之前。通过对这两个相关子任务的划分,分别进行参数训练,达到充分挖掘学习者偏好的目的。
在MAEM模型中,子任务之间的关系如下所示
PBrowse=P(y=1|E″)
(10)
PStudy=P(z=1|y=1,E″)
(11)
(12)
自编码器与分解预测模块通过两个独立的预测网络来估计点击并且浏览、浏览并且学习的概率,然后将结果传输到任务组合模块。
2.3 任务组合模块
从模型的整体来看,对于一组给定的输入数据,模型能够同时输出学习者浏览课程章节列表的概率和学习者真正学习完毕这门课程的概率。子任务1与子任务2的网络结构完全相同,将输出数值相乘得到学习者既浏览课程章节列表,又真正学习完毕这门课程的概率。在任务组合模块中,根据自编码器与分解预测模块获得的一个取值为0到1的实数值,得到整体任务的输出结果。模型的损失函数为两个子任务的损失加和。子任务损失使用交叉熵损失函数。最后输出结果连接到只有一个神经元的输出层。总损失函数LOSS如式(13)所示
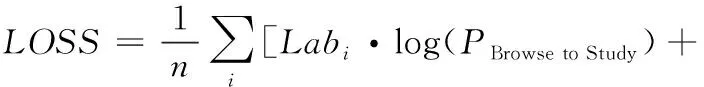
(13)
式中:Labi是样本标签,表示第i条记录的学习者是否拥有完成课程50%的学习行为,n表示所有样本数。
3 实验结果及分析
3.1 实验设置
模型采用Python3.6编程实现,深度学习框架选用Tensorflow1.6.0。模型的初始学习率设置为0.001。3个隐藏层中的神经元数量分别设置为512、256和128,Dropout大小设置为0.5,训练批次大小为256。共享嵌入模块提取特征有4层卷积层和池化层,4个卷积核,每个核的大小依次为9、11、13、15。池化窗尺寸大小为2,在自编码器中,编码器和解码器中的神经元数量为256,隐藏层中的神经元数量为128。每组实验进行300次迭代。将数据集随机划分为训练集、验证集和测试集。训练集包含70%的数据。验证集与测试集分别包含15%的数据。
3.2 数据集
实验选用两个公开教育数据集CNPC(canvas network person C-ourse)和HXPC(HarvardX person course academic),均为哈佛大学公开发布的学习者在线学习数据。CNPC数据集包含HarvardX-MITx2014年1月至2015年9月学习者的课程数据,包括10类学科238门课程,一共有325 199条学习者课程行为数据。HXPC数据集包含edX平台上哈佛大学课程第一年2013学年:2012年秋季,2013年春季和2013年夏季的学习者数据,共有338 224名学习者行为数据。在CNPC和HXPC数据集上,有浏览章节列表行为的样本占总样本数量的21.94%和49.53%,而学习完毕50%课程样本占总样本数量的2.99%和6.09%;由此可见训练数据存在着严重的稀疏性。详细的实验数据集统计数据见表1。

表1 实验数据集的统计数据
3.3 评价指标
实验选用准确性(ACC)、ROC曲线下方的面积大小(AUC)、平均绝对误差(MAE)3个指标来评估推荐算法的性能。
(1)准确性(ACC)是指正确预测的样本占预测样本总数的比例。通常来说,准确率越高,模型效果越好。准确性ACC如式(14)所示
(14)
式中:TP表示预测为正样本,而实际为正样本。FP表示预测为正样本,但实际为负样本。TN表示预测为负样本,但实际为正样本。FN表示预测为负样本,但实际为正样本。
(2)ROC曲线下方的面积大小(AUC)是指ROC曲线下与坐标轴围成的面积,这个面积的数值大于0小于1。计算ROC曲线下方的面积大小AUC如式(15)所示
(15)
式中:ranki代表第i条样本的标号。从小到大对概率得分排序在第rank个位置。M,N分别是正样本的个数和负样本的个数。 ∑i∈positiveclass只把正样本的序号累加。
(3)平均绝对误差(MAE)是绝对误差的平均值,能更好地反映预测值误差的实际情况。MAE的值越小,说明预测模型描述实验数据预测的误差越小。计算平均绝对误差MAE如式(16)所示
(16)
3.4 消融实验
本文设计3组消融实验来分析MAEM中每个模块的影响:①子任务设置数量的影响;②特征提取的影响;③自编码器的影响。
3.4.1 子任务设置数量的影响
本文设计3种任务划分模型:①单任务模型(MAEM-NF-SS)不做子任务划分,使用分解预测操作,直接判断学习者学习超过50%的课程概率;②双任务模型(MAEM)如2.2节所述;③三任务模型(MAEM-NF-ThS)划分为学习者注册课程→学习者浏览课程名称概率、学习者浏览课程名称→学习者浏览章节列表概率、学习者浏览章节列表→学习者学习超过50%的课程概率3个子任务。实验结果见表2。
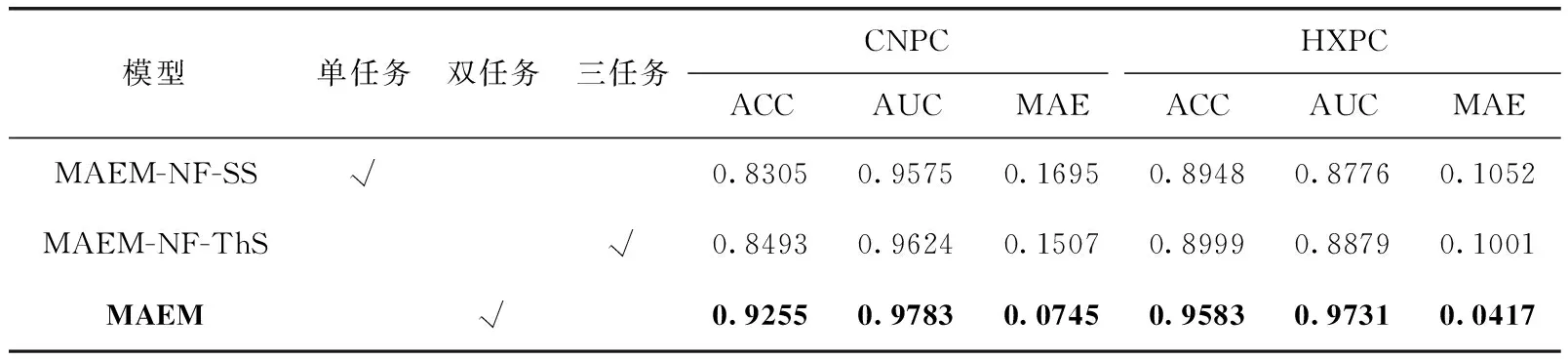
表2 CNPC和HXPC数据集上的单任务和多任务模型实验结果
从表2中可以看出,在CNPC数据集上MAEM要优于单任务(MAEM-NF-SS)和三任务模型(MAEM-NF-ThS),相较于单任务和三任务模型,MAEM在ACC上分别提高了11.43%、8.97%;在AUC上分别提高了2.17%、1.65%;在MAE上分别降低了56.04%、50.56%;同样的,在HXPC数据集上,MAEM相较于单任务和三任务模型在ACC上分别提高了7.09%、6.48%;在AUC上分别提高了10.88%、9.59%;在MAE上分别降低了60.36%、58.34%。
由此,多任务比单任务模型的性能更优越。因为多个任务之间可以共享一些学习者与课程的特征信息这是单任务学习所不具备的。
具体来说,引入多任务学习有3点好处:①单任务学习时,网络有可能陷入局部极小值。多任务学习通过不同任务的相互作用,有利于优化损失跳出局部极小值;②多个相关任务并行学习,包含任务相关部分与无关部分。进行某个子任务的训练时,与该任务无关的部分相当于自动引入噪声,可以提高学习的泛化效果;③通过添加子任务改变权值更新的动态特性,使同一权重根据不同任务做出改变。多任务并行学习,提升了共享嵌入模块的学习速率,能够以较大的学习速率提升学习效果。
但是并非任务越多效果越好,当设计的多任务网络中超过3个任务,需要平衡不同类型的任务,同时兼顾特征共享部分和任务特定部分。这既需要学习任务间的泛化表示,也需要学习每个任务独有的特征。否则在训练过程中,整个网络被简单任务主导,导致任务之间的性能差异巨大。因此MAEM选择使用两个子任务构建整体结构。
3.4.2 特征提取的影响
在模型训练中,如果对特征直接建模,则会忽略掉特征与特征之间的关联信息,且真正有效的特征交互往往只占少部分,因此模型在这种情况下进行学习极为困难。本文设计3组实验:不含提取特征数据和自编码器模型(MAEM-NF-NA)、含提取特征数据与原特征数据模型(MAEM-AF-NA)和仅带提取特征数据的模型MAEM之间的性能,其对比结果见表3。
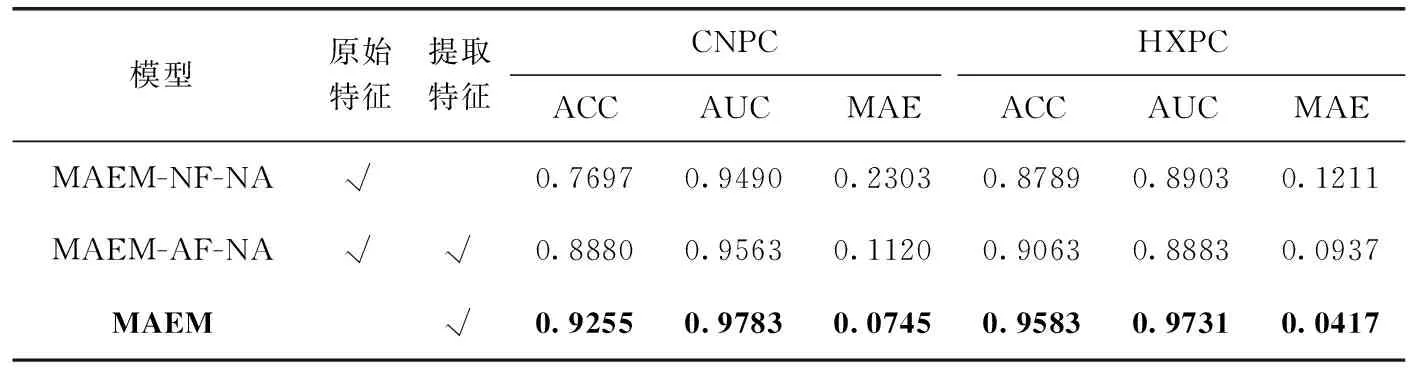
表3 CNPC和HXPC数据集提取特征的实验结果
从表3中可以看出,在CNPC数据集上MAEM优于MAEM-NF-NA和MAEM-AF-NA,相比于MAEM-NF-NA和MAEM-AF-NA,MAEM在ACC上分别提高了20.24%、4.22%;在AUC上分别提高了3.08%、2.3%;在MAE上分别降低了67.65%、33.48%。同样的,在HXPC数据集上,相比于MAEM-NF-NA和MAEM-AF-NA,MAEM在ACC上分别提高了9.03%、5.73%;在AUC上分别提高了9.3%、9.54%;在MAE上分别降低了65.56%、55.49%。
从对比结果可以看出,提取后特征更有利于模型训练,即把m层卷积层提取出来的m组特征相拼接,作为子任务的输入数据,模型的性能有所上升,直接将新提取的特征作为子任务模块的输入,能够解决数据高噪声、高维度和低质量的问题。
3.4.3 自编码器的影响
为了探究自编码器对模型的影响,依据自编码器的作用设置了两组实验:未采用自编码器的MAEM-NA-TwS模型,采用自编码器的MAEM模型,实验结果见表4。

表4 在CNPC、HXPC数据集上自编码器的实验结果
从表4中可以看出,MAEM要优于MAEM-NA-TwS。在CNPC数据集上,MAEM相比MAEM-NA-TwS在ACC上提高了3.22%;在AUC上提高了1.27%;在MAE上降低了27.94%。同样的,在HXPC数据集上,MAEM相比MAEM-NA-TwS在ACC上提高了5.65%;在AUC上提高了8.7%;在MAE上降低了55.16%。
采用自编码器可以通过对数据进行降维来减少冗余信息,提高算法的精度。将拥有自监督特性的自编码器嵌入在多任务学习中,每个子任务间共享降维去噪后提取到的特征,解决不同子任务输入数据无法统一处理的问题,从而优化数据内部的关联特征,更好实现了数据的参数共享。
3.4.4 三模块协同的影响
从表3和表4中可以看出,模块之间的配合有助于模型训练,MAEM要优于无特征提取的MAEM-NF-NA和无自编码器的MAEM-NA-TwS。在CNPC数据集上,相比于MAEM-NF-NA和MAEM-NA-TwS,MAEM在ACC上分别提高了20.24%、3.22%;在AUC上分别提高了3.08%、1.27%;在MAE上分别降低了67.65%、27.94%。同样的,在HXPC数据集上,相比于MAEM-NF-NA和MAEM-NA-TwS,MAEM在ACC上分别提高了9.03%、5.65%;在AUC上分别提高了9.3%、8.7%;在MAE上分别降低了65.56%、55.16%。
特征提取与自编码器处理后的数据用于不同的子任务,实现了数据参数的共享。这表明提取特征模块和自编码器模块能够相互补充,模块间相互支撑的效果优于单独作用的效果。
3.5 基准模型对比实验
本文选用当前最热门7个推荐算法进行对比。所有实验重复5次,并记录平均结果,对比的7个算法如下:NFM[6]、AFM[12]、DeepFM[7]、DCN[9]、PNN[10]、ESM2[5]、CATA++[13](https://github.com/liulin7576/DL_CTR)。其中,NFM、DeepFM、DCN、PNN注重模型的特征学习能力;ESM2注重于挖掘用户行为辅助信息;AFM、CATA++注重于挖掘用户不同的兴趣偏好。在公共数据集上不同模型的结果见表5。

表5 公共数据集上不同模型的比较
MAEM在所有数据集和评价指标中的性能最佳,与次优的CATA++推荐算法相比,模型性能有很大的提高。在CNPC数据集上,MAEM比CATA++在ACC上提高了0.41%;在AUC上提高了1.94%;在MAE上降低了4.85%。同样的,在HXPC数据集上,MAEM比CATA++在ACC上提高了2.97%;在AUC上提高了1.04%;在MAE上降低了39.91%。
与其它算法相比,大多数现有的推荐算法忽略了数据中存在的噪声和行为间丰富的关系。AFM、NFM、DCN和CATA++模型更多的是把注意力放在自动学习每个二阶交叉特征上,DeepFM和ESM2更关心的是理解学习者点击行为背后隐藏的交叉特征,PNN模型则把重点放在了自动捕捉离散特征的潜在高阶模式,它们都没有考虑到数据稀疏性导致模型训练困难的问题。
MAEM比其它热门推荐算法在稀疏数据的环境下具有更好的性能的原因是MAEM将学习者的学习行为分解为两个子任务,对共享嵌入层公共参数进行训练。不同任务的局部极小值处于不同的位置,子任务的交互可以帮助隐藏层跳出局部极小值。多个子任务的相关部分有助于在共享嵌入层学习学习者通用特征表示。此外,MAEM这3个模块的配合进一步提高了模型的效果,从而解决数据稀疏问题。
4 结束语
本文提出了一种基于多任务自编码器的课程推荐模型(MAEM)。MAEM通过分解学习者在线学习行为,建立双子任务学习结构,有效缓解了数据稀疏问题。采用自编码器协同两个子任务,解决不同子任务输入数据无法统一处理的问题。MAEM优化了数据内部的关联特征,构建了提取特征与行为分解为一体化的深度神经网络。训练效果的提高得益于共享两个子任务的行为参数。对比实验结果表明,3个模块协同工作比单个模块有效。通过与7种热门推荐算法对比,有力地验证了MAEM在课程推荐中的有效性。
