基于卷积神经网络的钢箱梁裂缝检测算法研究
2023-11-01沈俊凯张令心朱柏洁
沈俊凯,张令心,朱柏洁
(1. 中国地震局工程力学研究所 地震工程与工程振动重点实验室,黑龙江 哈尔滨 150080;2. 地震灾害防治应急管理部重点实验室,黑龙江 哈尔滨 150080)
0 引言
随着建筑工业化的发展,装配式钢箱梁在钢结构建筑和大跨度桥梁建设中得到了广泛应用。这类桥梁结构在服役过程中不可避免的受到车辆动载的持续冲击或地震作用影响,钢箱梁表面,尤其是焊缝处极易出现裂缝损伤。为确保钢箱梁工作的安全,需要定期对钢箱梁开展健康诊断和安全评估工作[1]。然而,这种采用钢箱梁的桥梁结构跨度较大,裂缝常出现在工程师难以直接使用肉眼观察到的位置[2],人工检测难度很大。此外,由于震后地震现场安全状况不明,工程师直接进入钢箱梁内部进行观察与评判存在较大的安全隐患。随着无人机技术的飞速发展,目前已经实现了利用无人机近距离地采集裂缝图像,工程师仅需根据采集到的图像即可完成对钢箱梁的健康诊断和震后损伤判别。但这种诊断过程依然费时费力,诊断准确度高度依赖于工程师的专业知识储备,主观性较强,无法达到快速诊断的目标。因此,为了能够更加高效、精确地检测出图像中的裂缝损伤,有必要引入计算机视觉技术对采集的图像开展裂缝识别和提取研究,为桥梁结构的健康诊断和震后损伤判别提供依据。
针对这一需求,国内外众多学者开展了广泛的研究,尤其是近几年,随着人工智能的快速发展,基于深度学习方法的计算机视觉技术被广泛的应用于结构损伤检测领域[3]。例如,CHA等[4]提出了一种基于卷积神经网络的混凝土裂缝检测算法,结果表明:该算法的检测精度远高于传统的边缘检测方法;ZHANG等[5]提出了一种基于You Only Look Once (YOLOv3)的混凝土桥梁表面损伤检测算法;XU等[6]提出了一种基于融合卷积神经网络检测钢结构表面裂缝和笔迹的方法;李良福等[7]提出了一种基于深度学习的桥梁裂缝检测方法,利用卷积神经网络对切割好的小尺度子图像进行分类实现对裂缝的检测。然而,上述这类检测方法都是通过对小窗口内的子图像进行分类实现裂缝检测,检测精度仍停留在窗口级,无法实现像素级的裂缝检测,也就无法对裂缝开展量化分析。
为了实现像素级的裂缝检测,Alipour等[8]提出了基于全卷积神经网络的CrackPix模型,像素检测精度明显优于窗口级模型;肖创柏等[9]提出了一种基于Faster R-CNN的铁轨裂缝检测算法,通过结合深度学习算法和数学形态法实现了裂缝的像素级检测;ZHANG等[10]构建了四种不同尺度的U-Net的模型,研究了模型尺度对像素级裂缝检测精度和效率的影响。上述像素级裂缝检测方法均为基于编码器-解码器框架的单一模型。这类模型所能处理的图像尺寸较小。然而,现实世界中采集的图像尺寸较大,裂缝只占原始图像中的小部分区域,直接使用像素级检测模型检测整幅图像会造成大量计算资源的浪费,降低检测效率。
综上所述,窗口级检测方法在检测效率方面优势明显,但检测精度不足。像素级检测方法的检测精度更高,但检测效率较低。因此,本文提出了一种将窗口级方法和像素级方法级联的钢箱梁裂缝检测算法,使用窗口级分类模型准确地定位并提取出原始图像中包含裂缝区域的子图像,再利用像素级分割模型对裂缝子图像进行像素级的检测,从而高效、精确地完成对任意尺度图像的像素级裂缝检测。
1 方法概述
本文所提出的钢箱梁裂缝检测算法的实现框架如图1所示。首先,通过分类模型在原始图像中定位出裂缝所在区域,提取出裂缝子区域;然后,将裂缝子区域输入到分割模型中,实现像素级的裂缝检测;最后,将分割出来的像素级检测结果依次拼接,得到最终的检测结果。
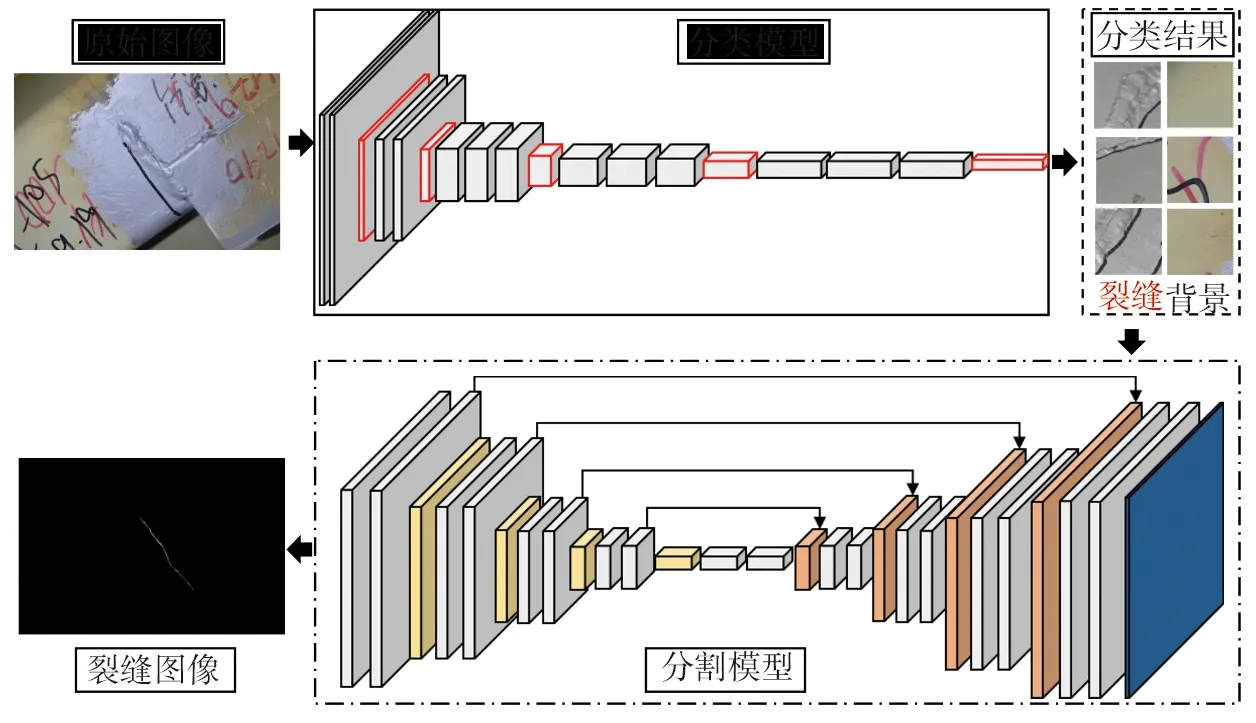
图1 本文方法实现框架Fig. 1 Implementation frame work of the proposed method
1.1 分类模型
分类模型主要负责在整体图像中定位出裂缝所在的区域。首先,需要将整体图像采用滑动窗口的方式划分为若干个子区域,滑动窗口的尺寸为512×512像素,滑动步长为512像素;然后,采用分类模型对每个子区域进行判别,剔除大量无裂缝的背景区域,提取出含有裂缝的子区域。为了节省图形存储空间,用于训练分类模型的子区域尺度可以压缩为256×256像素,图2(a)展示了将整体图像划分为子区域的过程;图2(b)展示了经过分类模型检测后的裂缝子区域的定位结果。

图2 裂缝子区域定位Fig. 2 Crack sub-region location
1.1.1 模型结构
该研究中所使用的分类模型的骨架为VGG16[11]并根据分类任务的复杂度,将原来的3个全连接层减少为1层包含256个神经元的全连接层,模型架构如图3所示。卷积层中的卷积核以给定的步幅在输入张量上滑动,在训练过程中通过不断调整卷积核中的参数实现对特征的提取。最大池化层负责进一步提取特征和减少模型复杂度。同时,为了提高模型的非线性映射能力并降低反向传播时求导的难度,本文采用了非线性激活函数(ReLU),计算公式如下:
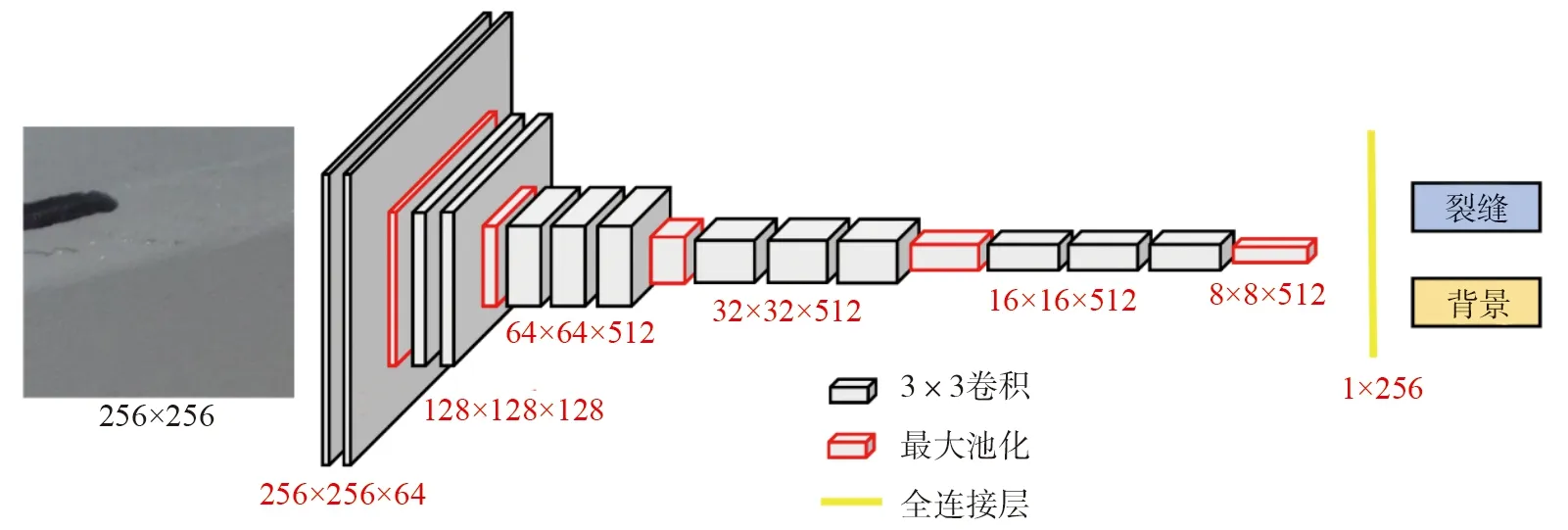
图3 分类模型的结构Fig. 3 Structure of classification model
(1)
式中:x是提取到的特征;f(x)是激活函数。

(2)
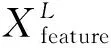
(3)
式中:y0和y1分别为裂缝和背景的预测类别概率。
1.1.2 分类模型的损失函数
本文采用二元交叉熵作为评价预测类别与真实类别之间差异的损失函数,计算公式如下:
(4)
式中:N为分类的类别数,此处N=2;p0和p1分别代表分类对象的真实类别。
1.2 分割模型
本文基于U-Net搭建了实现像素级裂缝检测的分割模型[12],模型架构和各层特征图尺度如图4所示。分割模型是一个基于编码器-解码器框架的全卷积神经网络。编码器类似于VGG Net16中的特征提取单元,由卷积层和池化层负责提取裂缝特征。解码器则包含了反卷积层和卷积层,负责将编码器提取到的高维特征还原为具有与输入向量相同尺度的像素级检测结果。
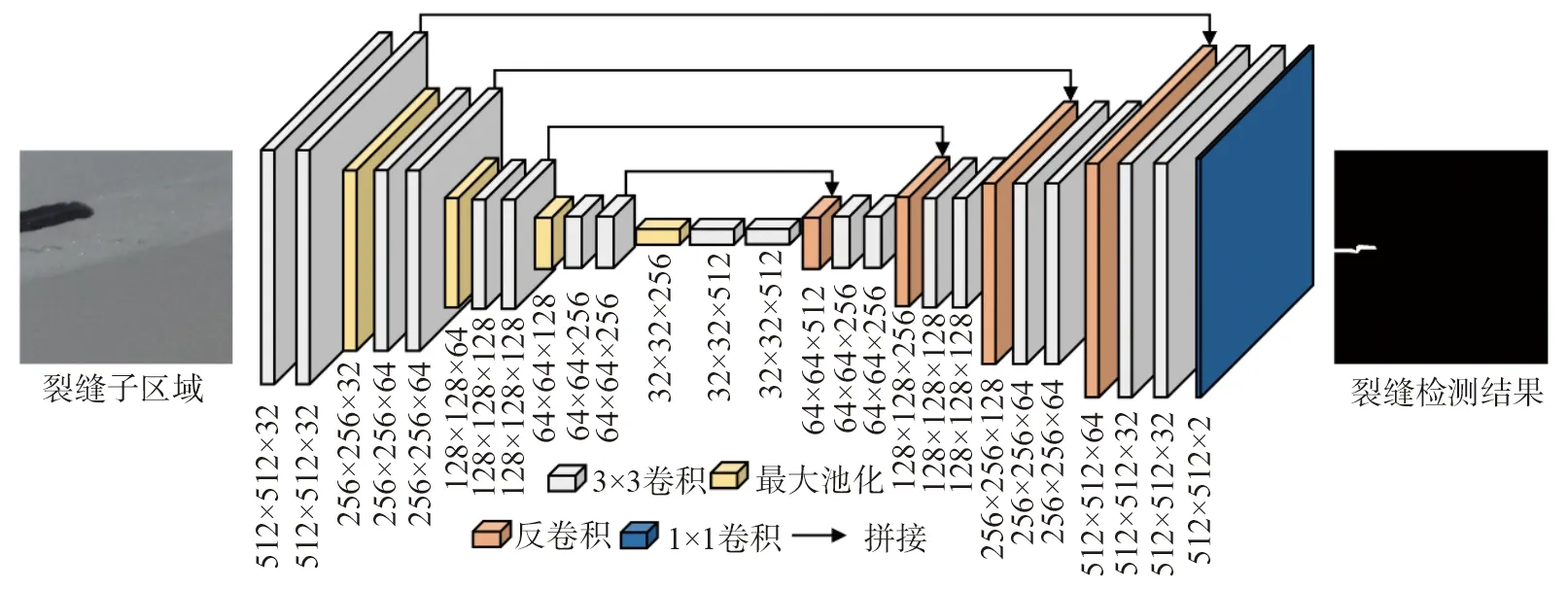
图4 分割模型的网络结构Fig. 4 Network structure of segmentation model
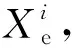
(5)
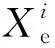
(6)
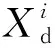
(7)
1.2.1 边缘填充与特征图拼接
在编码阶段,若不采用边缘填充的方式对输入图像进行补全,特征图的尺度在卷积的过程中将不断缩小,导致解码后的输出图像尺度缩水,难以计算预测结果与真实标签之间的损失值。因此, 本文将采用边缘同值填充的方式为图像四周进行补全,如图5所示。从图5可以看出,对输入进行边缘填充后,输出尺度与输入尺度将会保持一致。特征图拼接操作是通过通道连接的方式将编码器的特征和解码器的特征进行融合,从而达到提高检测精度的目的,而特征图拼接的前提是两个特征图的宽高尺度一致。因此,边缘填充的加入也为编码特征图与解码特征图相互拼接提供了便利。

图5 卷积中的边缘填充Fig. 5 Edge padding in convolution operation
1.2.2 反卷积
在解码阶段,需要将提取到的高维特征向量重新还原成与输入图像相同尺度的向量。本文采用反卷积对高维特征进行还原,如图6所示。在反卷积过程中,卷积核与输入向量中的每一个元素相乘,生成中间特征图,之后将所有的中间特征图按照卷积的方向和步长进行合并,得到输出。相比于插值上采样,反卷积操作中卷积核中的参数可以在训练过程中动态调整,兼具特征提取的作用。
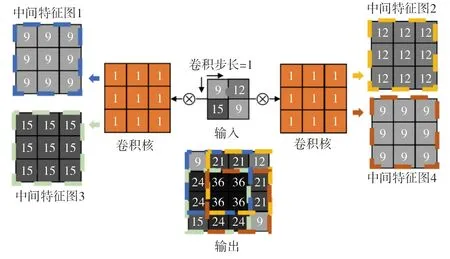
图6 反卷积操作示意图Fig. 6 Schematic of deconvolution operation
1.2.3 分割模型的损失函数
在训练分类模型时,裂缝图像样本和背景图像样本是均衡的,可以采用常规的二元交叉熵作为损失函数。与分类模型不同,训练分割模型所使用的图像中存在裂缝像素和背景像素样本严重不平衡的问题。由公式(6)计算得到的预测结果p和真实标签r中的裂缝像素与背景像素间存在着数量级的差异,常规的损失函数无法有效的描述预测结果与真实标签之间的差异。为了解决问题,本文引入了generalized dice loss (GDL)作为损失函数,该函数通过给不同类别的数据赋予不同的权重来提高裂缝像素在损失函数中的比重,计算公式如下:
(8)
(9)
式中:i是真实标签里的类别的总数,以本文的裂缝检测任务为例,i为2,分别包括裂缝像素和背景像素;rin是像素n中类别i的真实值;pin是相应的预测值;wi是每个类别的权重;N是一张图像中的像素总数。例如,在一张尺寸为512×512像素的图像标签中,裂缝像素数量为5000个,背景像素数量为257144。裂缝像素值为1,背景像素值为0。按照公式(8)计算,裂缝像素的权重为1/50002,背景像素的权重为1/2571442。
2 实验与分析
2.1 实验数据集和超参数设置
本文所有代码运行的硬件平台为:CPU:i7-7800x,GPU:2×Nvidia GeForce GTX-1080Ti。代码均采用Windows下的Pycharm平台开发,使用基于Python语言的Keras深度学习框架。本文所采用的数据集是由IPC-SHM提供[13]。数据集中包括120张分辨率分别为3264×4928和3864×5152的原始图像和裂缝标注图像。原始图像与标注出的裂缝图像如图7所示。选取其中的100张图像用于训练模型,20张用于测试训练好的模型。

图7 原始图像与标注后裂缝图像样例Fig. 7 Samples of original image and annotated crack image
首先将100张原始图像切割成5145个512×512像素的子图像,其中447张裂缝子图像,背景子图像与裂缝子图像的比例为10.5∶1。为了解决两类子图像之间数据不平衡的问题,需要对裂缝子区域进行数据增强,对裂缝子图像进行拉伸、旋转等操作以获取更多裂缝子图像。最终用于训练分类模型的数据集中包含4000个裂缝子图像和4000个背景子图像。用于训练分割模型的数据集中包含447张裂缝区域的子图像和其对应的裂缝标签。两个数据集都按照8:2的比例分别划分为训练集和验证集。
本研究采用Adam优化器来优化分类模型和分割模型。Adam优化器中的一阶和二阶矩估计的默认指数衰减率分别设置为0.9和0.999。初始学习率设置为0.0001,学习衰减率设置为0.01,每一个epoch的学习率根据下式确定:
(10)
式中:lrepoch为该epoch下的学习率;lr初始为初始学习率。分类模型的batch_size设置为120,分割模型的batch_size设置为6,epoch均设置为100。分类模型和分割模型在训练阶段的损失函数变化情况如图8所示。
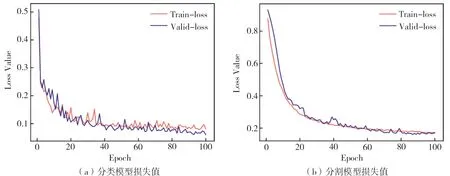
图8 分类模型和分割模型的损失Fig. 8 Loss value of classification model and segmentation model
2.2 分类模型结果分析
测试集中共包括20张原始图像,经过裁切后,共有1080张子图像,其中裂缝子图像112张,背景子图像968张,表1展示了训练好的分类模型在该数据集上的表现。
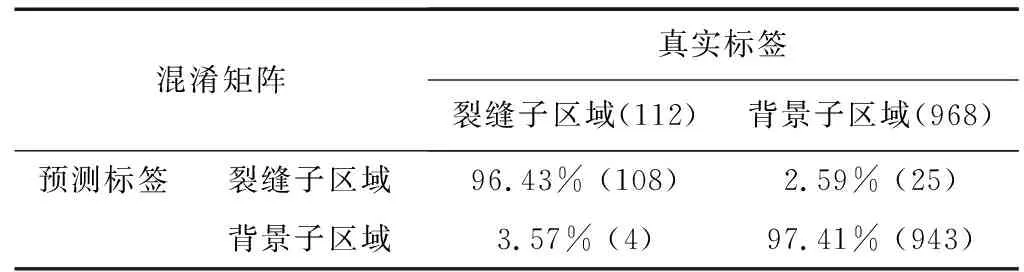
表1 分类模型在测试集上的混淆矩阵Table 1 Confusion matrix of the classification model on the test set
从表1中可以看出:分类模型对于裂缝和背景子图像的分类精度均达到了96%以上。图9展示了分类模型的部分预测结果。从图9中可以看出:大部分裂缝子图像和背景子图像能够被准确的识别出来。但是,也有少数背景区域由于受到字迹和阴影的干扰而被误识别为裂缝(图9(a)红色虚线方框内),还有少数处在子图像边缘或过细的裂缝也未能被正确识别(图9(b)红色虚线方框内)。

图9 分类模型预测结果Fig. 9 Prediction results of classification model
2.3 分割模型结果分析
用于检验分割模型的测试集中共包含112个裂缝子图像及其对应的标签图像,分割模型的部分检测结果如图10所示。从图10中可以看出:大部分的裂缝都能够被分割模型精准的检测出来,只有少数处于图像阴影处和非常细微的裂缝未能被完整的检测出来。

图10 分割模型检测结果Fig. 10 Detection results of segmentation model
2.4 整体检测结果
为了更精确的评估所提出方法的裂缝检测性能,本文选取F1分数和均交并比(Mean_IoU)作为评价指标。F1分数的计算公式如下:
(11)
(12)
(13)
式中: TP为标签标注为裂缝且检测结果也为裂缝的像素点的个数;FP为标签标注为背景但检测结果为裂缝的像素点的个数;FN为标签标注为裂缝但检测结果为背景的像素点的个数。Mean_IoU的计算公式如下:
(14)
式中: DR为检测结果中裂缝像素点的个数,GT为标签中裂缝像素点的个数。
本文所提出的方法在测试集20张图上的F1分数和Mean_IoU如图11所示,两个评价指标越接近1说明检测的效果越好。从图11可以看出:除对少数图像中的裂缝检测效果较差外,本文方法对于多数图像均可以精确地检测出裂缝。为了更清楚地观察对于不同裂缝的检测效果,本文将检测出的裂缝图像与真实裂缝图像进行叠加。若检测出的裂缝与真实裂缝图像中的裂缝重叠,表明裂缝检测结果是准确的,将该像素标记为黄色;若不重合,表明检测结果与真实裂缝存在误差,将该像素标记为蓝色。图12展示了4张裂缝图像的检测结果。
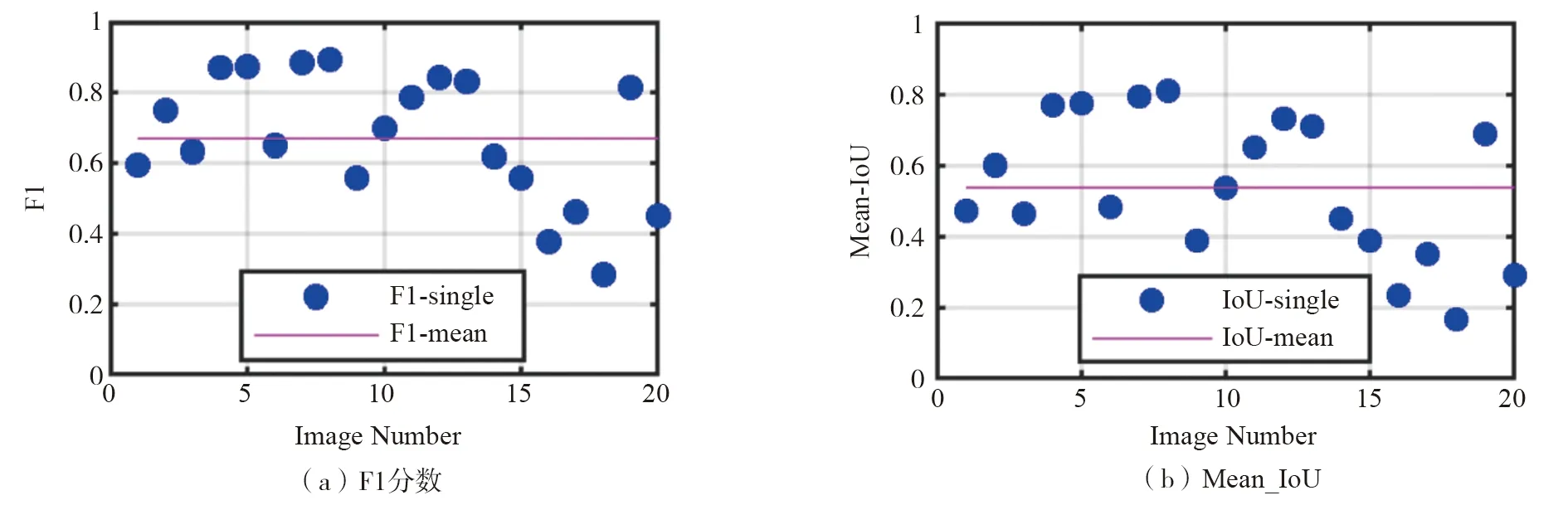
图11 测试集检测结果的F1分数和Mean_IoUFig. 11 F1 score and Mean_IoU of detectionresultontestingset

图12部分测试集裂缝检测结果Fig. 12 Partial crack detection results on testing set
从图12可以看出:无论是长裂缝还是短小裂缝,本文所提出的方法都可以有效的进行精确检测。从图12还可以看出:本文所提出的方法可以有效地分辨出裂缝与笔迹之间的区别,不会出现将笔迹误认为裂缝的情况。但本文方法对于两块高低不平整的钢板之间所形成的狭小阴影区域容易出现误判。总体而言,本文方法对于大部分常规裂缝都能实现精确检测。本文方法的检测效率和检测精度与仅使用分割模型的对比见表2。从表2可以看出:本文方法检测一张千万像素级的完整图像中的裂缝平均仅花费9.25 s,而仅使用分割模型需要花费15.86 s。相比于仅使用分割模型,本文所提出的基于级联的检测方法的检测速度提高了70%。同时,本文方法的检测精度也明显高于仅使用分割模型的方法,F1分数和Mean_IoU分别提高了0.12和0.10。
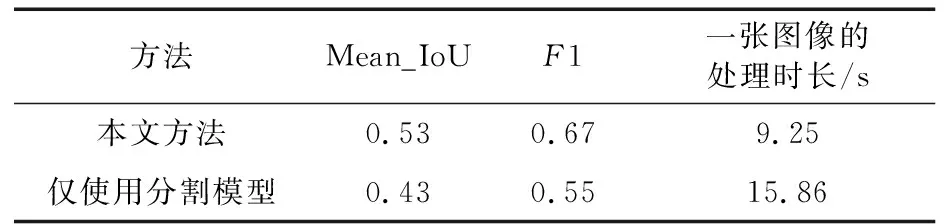
表2 两种检测方法的检测效率对比Table 2 Detection efficiency comparison of two methods
3 结论
为精确和快速的实现对桥梁钢箱梁内部裂缝的像素级检测,本文提出了一种基于深度学习的级联式混合方法,得出以下结论:
1)所提出的方法结合了基于深度学习的分类模型和分割模型,利用分类模型效率高、定位准确的特点快速定位裂缝区域,利用分割模型检测精度高的特点对裂缝区域进行像素级检测,解决了窗口级算法精度低和像素级算法效率低的问题。
2)相较于现有方法只能检测固定尺度图像中的裂缝,本文采取的级联策略可以实现任意尺度图像裂缝的像素级检测。
3)本文方法在测试集上的结果表明:训练好的级联模型可以对大部分图像中的裂缝进行像素级检测,不仅精度高于仅采用分割模型的精度,提取效率也提高了70%,处理一张千万像素级的图像平均用时仅为9.25 s。
4)本文方法具有提高检测效率,降低人工成本的特点,后续可对提取出的裂缝进行量化分析,进而对其进行更为精细的健康诊断。
