基于文本融合特征的突发事件子话题聚类研究
2023-10-31芦子涵郑中团
芦子涵, 郑中团
(上海工程技术大学 数理与统计学院, 上海 201600)
0 引 言
话题检测与追踪(Topic Detection and Tracking,TDT) 是美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)于1996年开展的语言信息研究项目[1],曾在评测会议上对话题等相关要素进行了定义,认为话题是由一个种子事件或活动,和全部与之直接关联的后续事件和活动构成[2]。 而在国内,曾有学者定义子话题为话题内一组相关事件的集合,是话题内所有事件集合的一个子集[3]。 近年来,突发事件时有发生。 譬如2022 年“3·20”东航航班坠机等事故灾难事件、2022 年6 月河北唐山打人等社会安全事件、2021 年“7·20”河南特大暴雨等自然灾害事件与至今仍时有发生的2020 年新冠肺炎疫情等公共卫生事件。与此同时,随着网民规模的扩大与社交平台的普及,像新浪微博这样传播范围广、普及率高的社交网络平台逐渐成为突发事件的曝光口。 社会大众可自由地在网络平台上发表自身对突发事件的看法或评论,从而形成网络舆情。 由于突发事件具有不确定性、危害性等特点[4],通常会给社会大众带来负面的心理冲击。 如若不能针对性地根据社会大众对于某一突发事件所关注的不同子话题来引导积极的舆论走向,并建立舆情治理机制,则会放大社会大众的负面情绪,引起不必要的激进言论,甚至会对政府机构造成不良影响。 现有研究大多基于事件这一粒度进行话题聚类,而忽略了同一事件下不同侧面的更细粒度子话题的研究。 因此,如何有效地挖掘某一事件中的潜在子话题,逐渐成为了新兴研究热点,也对舆情管控相关部门实现舆情精准化管控具有重要现实意义。
本文针对以往话题聚类大多基于事件这一层次,而忽略了同一事件下更细粒度子话题的研究,且文本特征表示上缺乏上下文语义信息的缺陷,提出一种基于LDA 文档-主题分布与Doc2Vec 句向量融合的文本表示方法与文本相似度计算方法,最后通过Single-Pass 增量聚类算法实现同一突发事件下子话题聚类。
1 相关研究
目前,在话题挖掘领域,多以基于概率主题模型的话题发现、基于文本特征表示的话题聚类两种为主要途径与方法。 概率主题模型是对文本中隐含主题的一种非监督建模方法,其认为一篇文档中的每个词都是通过以一定概率选择某个主题,并从这个主题中以一定概率选择某个词的方式得到的。 早期,为解决TF-IDF 文本模型的缺陷,利用奇异值分解将高维共现矩阵映射到低维潜在语义空间的潜在语义分析模型(Latent Semantic Analysis,LSA)被提出。 因其计算复杂度高且缺乏概率基础,Hofmann[5]在1999 年将LSA 的思想引入到概率模型中,提出概率潜在语义分析模型(Probabilistic Latent Semantic Analysis,PLSA)。 2003 年,Blei 等[6]基于贝叶斯思想,认为文档-主题概率分布是服从狄利克雷概率分布的随机变量,提出了潜在狄利克雷模型(Latent Dirichlet Allocation,LDA)。 在话题挖掘领域,LDA 主题模型也成为目前最为成熟的概率主题模型。 由于概率主题模型以词袋模型为基础,通常忽略了单词与单词之间的语义信息,导致语义缺失、主题可解释性差等问题。 基于此,赵林静等[7]通过HowNet 常识知识库计算单词间的语义相似度,来调整LDA 主题模型中的超参数β, 提出SS-LDA 模型以提高主题挖掘的精度。 居亚亚等[8]为解决LDA 主题模型语义连贯性较差等问题,在LDA框架下引入GRU 模型加入单词—单词和文档—单词语义相似度来引导建模,提出了SDS-TM 模型。闫盛枫[9]利用词嵌入技术进行语义向量编码,以此来合并同语义信息主题词并调整主题词分布及权重,增强了主题模型的语义表达性。 也有学者通过优化LDA 主题建模结果实现子话题的挖掘。 如:周楠等[10]基于PLSA 模型得到每个子话题下不同的词频分布,通过相似子话题合并、子话题更新优化主题建模结果,解决了传统方法的子话题区分度差等缺陷。 夏丽华等[11]将概率主题模型融合词共现关系,提出GPLSA 方法对原始子话题进行合并与更新,解决了描述同一产品的文档十分相似,难以保证子话题差异性的问题。
聚类是一种十分重要的非监督学习技术,其任务是按照某种标准或数据的内在性质及规律实现样本的聚类[12]。 在话题挖掘领域,话题聚类基于文本的特征表示或文本间的相似度,将目标文档分为若干个簇,使得每个簇内文本间的相似度尽可能高,不同簇间文本的相似度尽可能低。 因而,众多研究者基于文本特征表示或文本相似度进行话题发现。 史剑虹等[13]利用隐主题模型挖掘微博内容中隐含主题—文档分布作为文本特征表示,并基于K-means++聚类实现话题发现。 颜端武等[14]针对微博文本高维稀疏与上下文语义缺失等问题,以LDA 文档—主题分布特征和加权Word2Vec 词向量特征构建文本融合特征,并通过K-means 聚类实现主题聚类。肖巧翔等[15]提出一种基于Word2Vec 扩充文本和LDA 主题模型的Web 服务聚类方法,将短文本主题建模转化为长文本主题建模,进而通过K-means 算法更准确地实现了服务内容主题聚类。 赵爱华等[16]针对子话题间文本相似度高的特点,引入主题特征词相关性分析,提出一种改进的文本相似度计算方法,并基于Single-Pass 增量聚类实现新闻话题子话题挖掘。 李湘东等[17]针对LDA 建模结果较泛化的缺陷,将LDA 建模结果主题—特征词分布作为文本较粗粒度的特征,将TF-IDF 向量作为文本较细粒度的特征来融合表示文档,采用知网语义词典得到文本相似度,通过Single-Pass 聚类实现国内各地时事新闻子话题划分。
综上,子话题挖掘多以LDA 主题模型建模、LDA 主题模型建模结果优化、基于文本特征表示的话题聚类为主要方法。 其中,对于评论短文本LDA主题模型具有文本向量高维稀疏、缺乏上下文语义信息等缺陷;改进的LDA 主题模型以引入外部知识库来修改超参数β来引导建模,通用性低且计算复杂度高。 基于文本特征表示的话题聚类多以事件为层次进行主题发现,而忽略了同一事件下更细粒度、更深层次的子话题聚类研究。 基于此,本文提出一种基于LDA 文档-主题分布与Doc2Vec 句向量融合的文本特征表示方法与文本相似度计算方法,通过Single-Pass 增量聚类算法实现同一突发事件下子话题聚类。 一方面,上述文本融合特征不仅通过LDA 文档—主题分布提取了全局主题信息,同时也通过句向量的构建提取了局部上下文语义信息以补充LDA 主题模型语义信息的缺乏。 另一方面,不同于大多话题所基于的事件层次,针对同一事件下子话题相似度高、区分度低的问题,本文给出了一种同一事件下更细粒度、更深层次的子话题聚类方法。
2 预备知识
2.1 LDA 主题模型
主题模型是一种用来发现一系列文档中隐含主题的无监督统计模型,认为一篇文档中的每个词都是以一定概率而选择某个主题,并从该主题中以一定概率而选择某个词所生成的。 如图1 所示,LDA主题模型是2003 年被Blei 等人[6]提出的文档—主题—单词的三层贝叶斯主题模型。 该模型以词袋模型为基础,认为一篇文档是由词所组成的集合,而词与词之间没有语义联系与顺序。 其能够将一篇文档表示为隐含主题的多项分布,即该文档属于每个主题的概率;将主题表示为词集上的多项分布,即该主题下各个词出现的概率。 与其他概率主题模型不同的是,LDA 主题模型基于贝叶斯思想,认为文档—主题分布θd的先验分布为Dirichlet 分布,即θd =。 主题—词分布βk的先验分布为Dirichlet 分布,即βk =。
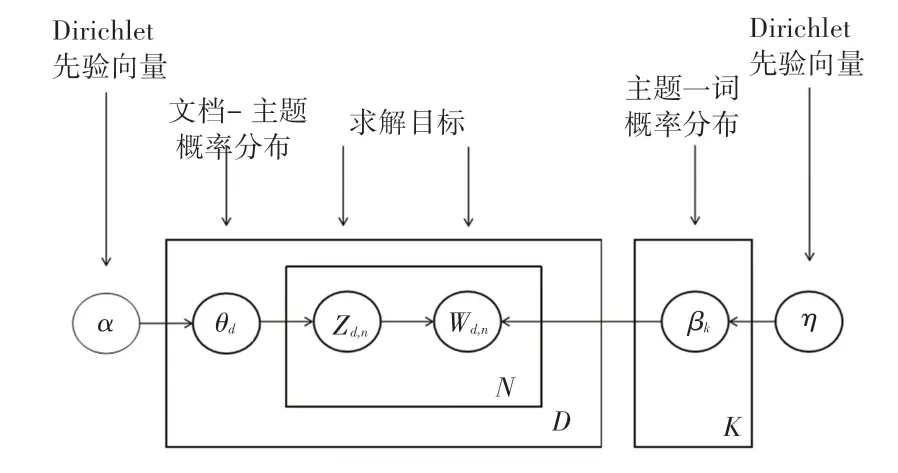
图1 LDA 主题模型Fig.1 LDA topic model
在LDA 主题模型中,通常使用Gibbs 采样算法[18]来进行求解。α,η作为已知的先验输入,目标是得到各个zd,n、wd,n对应的整体文档—主题分布与主题—词分布。
2.2 Doc2Vec 模型
为表达整条文本评论或整篇文档的特征,常将由Word2Vec 得到的词向量进行向量拼接,此方法导致信息损失较大,得到的新向量不能涵盖丰富语义信息内容[19];或将由Word2Vec 得到的词向量进行平均求和,但此方法未考虑到词与词之间的语序信息,一定程度上忽略了文本上下文语义信息。Mikolov 等 人[20]在Word2Vec 的 基 础 上 提 出 了Doc2Vec 模型, 以期构建文档的向量化表示。Word2Vec 模型本质上一个具有输入层、隐藏层、输出层的三层神经网络结构,其包含CBOW(Continue Bag of Words)与Skip-Gram 两种学习模型。 CBOW模型根据所输入的目标词上下文单词的One-Hot向量表示来输出对目标词的预测,而Skip-Gram 则是输入当前词来预测上下文词。
与Word2Vec 不同的是,Doc2Vec 模型在训练过程中增加了段落向量Paragraph id,进而可以结合上下文词训练文本,从而得到句向量和文本向量[21]。在Doc2Vec 模型中,段落向量与单词一样首先将被映射成一个句向量Paragraph Vector,其次将段落向量与上下文词语所映射成的向量累加或拼接起来,作为输出层的输入。 由于Paragraph Vector 在同一个文档的每一次训练中是共享的,因此随着文档每次滑动窗口取上下文单词训练的过程中,Paragraph Vector 作为输入层向量的一部分每次都将被训练,向量所储存的段落信息将会越来越准确。 Doc2Vec模型同样包含PV-DM(Distributed Memory)与PVDBOW(Distributed Bag of Words)两种学习模型。 本文拟采用PV-DM 模型,如图2 所示。 PV-DM 模型根据所输入目标词的上下文单词来预测目标词,而PV-DBOW 则是输入当前词来预测上下文词。

图2 Doc2Vec 模型Fig.2 The model of Doc2vec
3 基于文本主题与语义融合特征的子话题聚类
3.1 思路与流程
本文针对同一突发事件下子话题具有相似度高而区分度低的特点,同时考虑到LDA 主题模型以词袋模型为基础,其构建的单一主题特征常忽略文本语义信息的问题,重点构建基于文本主题特征与文本语义特征的文本融合特征向量,并对上述两种不同特征的文本相似度进行线性结合,从而通过Single-Pass 增量聚类实现突发事件下子话题聚类。首先,以新浪微博平台为数据来源,爬取突发事件评论文本构建语料库,并对数据进行清洗、分词、去停用词等预处理;其次,在全局主题层面通过LDA 主题模型提取文档—主题分布以表达文本主题特征,在局部语义层面通过Doc2Vec 模型提取文档句向量以表达文本语义特征,从而构建文本融合特征;然后将基于KL 距离与余弦相似度线性结合计算融合特征相似度,以度量文本相似度;最后通过Single-Pass 增量聚类实现子话题聚类。 具体流程如图3 所示。
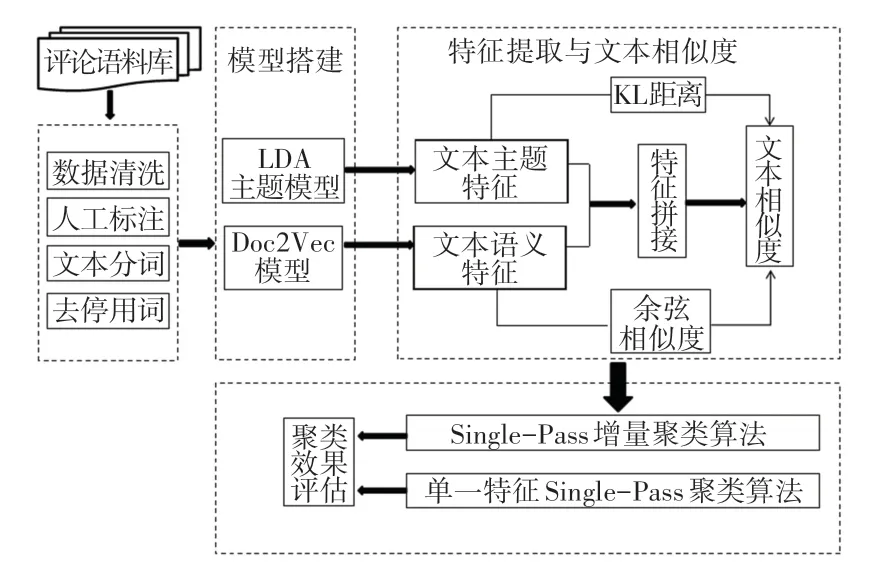
图3 研究思路与流程Fig.3 Research process
3.2 文本融合特征的构建
假设预处理后的突发事件评论文本语料库D ={d1,d2,…,dn},其中n为语料库中评论文本的数目。 首先,通过LDA 主题模型提取文本主题特征。LDA 主题模型所提取的主题信息为T ={t1,t2,…,tk},K为主题个数,通常由人为自主设定,本文将采用困惑度这一指标来确定最优主题个数。 本文采用Gibbs 采样算法求解LDA 主题模型,在初始时刻为每个单词随机地赋予主题,其次,对于每个文本d中的每个词,通过Gibbs 采样公式获取其所对应的主题。 Gibbs 采样公式如式(1)所示:
其中,n(dk)表示在第d个文本中第k个主题词的个数,n(kv)表示第k个主题中第v个词的个数。
重复上述采样过程直至Gibbs 采样收敛,即可得到所有词的采样主题。通过统计每个文本d对应词的主题计数, 每个文本d可表示为θd ={(t1,θt1) ,(t2,θt2) ,…,(tk,θtk)} 的 文 档—主 题 分布,完成文本主题特征的提取。 其次,通过Doc2Vec模型提取文本语义特征。 本文采用Doc2Vec 中的PV-DM 模型,使用Python 中Gensim 库的Doc2Vec接口来训练语料库,从而得到语料库中每个文本d的句向量表示Sd =[s(d,1),s(d,2),…,s(d,m)].
由于基于词袋模型的LDA 主题模型所提取的主题特征往往忽略了文本语义信息,而Doc2Vec 模型所训练的文本句向量能够补充性地提取上下文语义信息,弥补LDA 主题特征的这一缺陷。 因此,本文将基于LDA 主题模型与Doc2Vec 模型所提取文本主题特征与文本语义特征进行横向拼接,构建文本融合特征矩阵ST。
3.3 文本相似度计算
文本相似度的计算是子话题聚类的前提,本文将基于KL 散度与余弦相似度计算文本主题概率分布相似度与句向量相似度,并将二者进行线性组合,从而得到本文所构建的融合特征相似度,即文本相似度,式(2):
其中,di与dj表示评论文本。
3.3.1 基于KL 距离的文本主题特征相似度
KL 距离(Kullback-Leibler Divergence,KL)用来衡量相同事件空间里的两个概率分布的差异情况,又被称为相对熵。 在本文中,评论文本di的文档—主题分布表示为p(t),评论文本dj的文档—主题分布表示为q(t),p(t) 与q(t) 的概率分布越相似,则两者之间的KL距离越小[16]。p(t) 与q(t) 之间的KL距离如式(3) 所示:
考虑到KL距离具有非对称性,交换p(t) 与q(t) 的位置后结果大不相同,参考文献[9]的做法,可采用公式(4)计算文档—主题概率分布之间的距离:
3.3.2 基于余弦相似度的文本语义特征相似度
针对通过Doc2Vec 模型训练所提取的表征文本语义特征的句向量,采用余弦相似度来计算文本语义特征相似度,如式(5)所示。
其中,Sdi、Sdj为评论文本di、dj的文本语义特征。
3.4 子话题聚类算法流程
本文采用Single-Pass 增量聚类[22]实现子话题聚类,该算法是话题检测中一种常用算法,又称单通道法。 在Single-Pass 算法中,需要自主预设一个聚类阈值,对于所输入的评论文本,计算当前评论文本与已有话题聚类簇之间的相似度,若相似度大于预设的聚类阈值,则将该评论文本判为已有话题聚类簇;否则,将该评论文本作为簇核心创建新的话题簇。 本文将所构建的文本融合特征与文本相似度计算嵌入Single-Pass 聚类算法中,具体算法流程见表1。

表1 子话题聚类算法流程Tab.1 The process of sub-topic clustering algorithm
4 实验与分析
本文将以新浪微博为数据来源,以“郑州地铁7.20 事件”为突发事件评论语料库进行3 组实验。第一组实验采用困惑度(Perplexity)评价指标,得出1~10 个主题下的困惑度值,从而确定最优主题数;第二组实验采用F1 值寻找能够使F1 值达到最高的聚类阈值,从而确定最佳聚类阈值σ; 第三组实验生成3 种评论文本特征向量,其中包括LDA 文档—主题分布向量、Doc2Vec 句向量以及本文的融合特征向 量, 采 用查 准 率(Precision)、 召 回 率(Recall) 与F1 值对比3 种文本特征向量子话题聚类效果,以验证基于本文融合特征子话题聚类的有效性。
4.1 突发事件概述与数据预处理
2021 年7 月20 日,河南郑州发生罕见特大暴雨。 当日晚19 时左右,据郑州本地广播官方微博@MyRadio 发布的微博称,郑州地铁5 号线雨水倒灌,车厢内积水已到达乘客胸部,数名乘客被困。 随后该条微博被澎湃新闻官方微博@澎湃新闻转发,转发人次5.2 万,评论人次3.7 万,事件爆发。 截至当日晚间22 时左右,消防救援人员陆续疏散被困人员500 余人。 7 月21 日上午,郑州地铁官方发布称此次事件导致12 人遇难。 随后,两名个人用户发布博文称有乘客邹某、沙某仍失联。 26 日,乘客邹某、沙某确认遇难。 27 日上午,郑州官方发布此次事件最终导致14 人遇难,再次引起一波舆论高潮。 2022年1 月21 日,国务院调查组调查认定郑州地铁5 号线亡人系责任事件,是造成重大人员伤亡与财产损失的突发事件。
本文以“郑州地铁5 号线”、“多人被困”等为关键词,以2021 年7 月20 日19 时—2021 年7 月31日22 时为时间区间,每2 小时为一个时间段,利用Gooseeker 集搜客数据抓取器采集数据,共采集到6 657条评论文本作为语料库。 每条评论文本包含5个字段:用户ID、发布时间、评论内容、点赞数与评论数。 对语料库进行以下预处理操作:
(1)数据清洗。 去除与话题不相关的评论文本,剔除特殊字符如表情、评论图片等;
(2)人工标注。 结合郑州地铁5 号线事件期间微博热搜内容,对评论文本进行话题标注,以便后续有效性验证;
(3)分词。 采用Python 中Jieba 库对评论文本进行分词,同时加载分词词典以识别该事件特定词;
(4)去停用词。 根据停用词表去除标点符号、语气助词等词语。
4.2 评估指标
本文采用查准率(Precision)、召回率(Recall)、F1 值来对比3 种文本特征向量子话题聚类效果,其值越高,说明方法效果越好。
查准率(Precision) 是指预测为属于子话题Ci的评论文本中,实际属于子话题Ci的评论文本比例;召回率(Recall) 为实际属于子话题Ci的评论文本中,被预测为属于子话题Ci的评论文本比例。
其中,C为子话题簇个数。
整体聚类效果采用F1 对各个子话题的聚类效果求平均的方式来度量。
4.3 实验结果与分析
4.3.1 实验1 确定最优话题个数
在LDA 主题模型提取文本主题特征中,主题个数的选取能够直接影响到特征提取效果。 若仅依赖人为设定,LDA 主题模型的性能将无法保证。 因此,本实验采用困惑度(Perplexity)评价指标来确定最优主题个数。 困惑度常被用来衡量概率分布或概率模型样本的优劣性[23]。 在自然语言处理中,可用于LDA 主题模型,确定最优主题个数,如式(8)所示:
其中,V表示语料库D中所有词的集合;N表示语料库中评论文本的数量;Wd表示评论文本d中的词;Md表示每个评论文本d中的词数;p(Wd) 表示文本中词出现的概率。
实验中根据“郑州地铁7.20 事件”期间新浪微博热搜词条,拟定1 ~10 区间内的整数为实验主题数,得到困惑度变化如图4 所示。

图4 确定最优主题个数Fig.4 The determination of the optimal number of topics
通常情况下,困惑度随着主题数量的增加而呈现递减的规律。 困惑度越小,意味着主题模型的生成能力越强[24]。 通过图4 可以看出,当T =8 时LDA 主题模型困惑度最小,因此本文将主题个数T设定为8。
4.3.2 实验2 确定最佳聚类阈值
实验中采用4.2 节所描述的F1 值来计算不同聚类阈值下聚类效果的优劣。 经多次实验,当聚类阈值小于0.3 时,所有评论文本被聚类为同一簇,聚类阈值过小。 因此,本实验中拟定聚类阈值在σ∈(0.3,1) 这一区间内,分别进行6 次实验,得到F1值变化如图5 所示。 可以看出,当聚类阈值σ =0.52时,聚类效果最好,此时的F1 值为0.724,因此本文将确定聚类阈值σ为0.52。
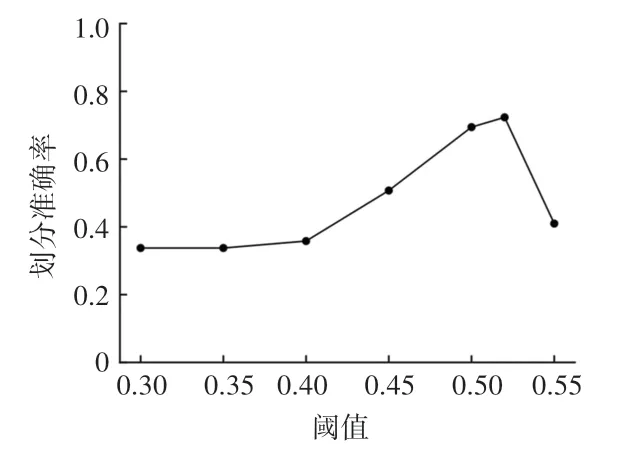
图5 确定最佳聚类阈值Fig.5 The determination of threshold value in clustering
4.3.3 实验3 对比实验与分析
为验证本文基于融合特征表示的子话题聚类方法的有效性,对于LDA 主题模型所提取单一文本主题特征文档—主题分布、Doc2Vec 模型提取单一文本语义特征句向量、3.2 节所表述的文本融合特征分别进行Single-Pass 子话题聚类实验,并采用精确率、召回率、F1 值来度量聚类效果的优劣。 实验结果见表2。

表2 实验3 结果对比Tab.2 The result of test 3
依据表2 中数据分析可知:
(1)基于单一文本语义特征的子话题聚类的F1值为67.3%。 Doc2Vec 模型通过三层神经网络根据所输入的目标词来预测目标词的上下文单词,从而得到副产物句向量与词向量。 一方面,相比将一条评论文本中每个词的词向量进行求和或加权平均求和来表示整条文本评论的方法,Doc2Vec 能够给出整条文本评论的文档向量化表示,能够避免前者忽略单词在句子中的语序问题;另一方面,相比于LDA 主题模型基于词袋模型,Doc2Vec 模型能够有效提取文本中的语序及上下文语义信息。 但未考虑文本的全局信息,因而在F1 值位于另外两种特征子话题聚类之间。
(2)基于单一文本主题特征的子话题聚类的F1值为64.4%,相较于另外两种特征F1 值最低。 LDA主题模型将文本表示为维数为主题个数的多项分布,从而提取文本全局主题特征。 LDA 主题模型所基于的词袋模型忽视了文本中单词的语序与语义表达,对于同一突发事件下相似度高、区分度差的评论文本而言,虽能够提取文本的主题特征,但仅用LDA 主题特征来进行相似背景子话题聚类,则难以发挥LDA 主题模型的优势与作用。
(3)基于融合特征的子话题聚类方法相较于单一特征聚类效果最佳,F1 值达72.4%。 融合特征考虑到同一突发事件下子话题具有相似背景词而导致区分度差的特点,且LDA 主题模型所提取主题特征基于词袋模型,缺乏语义信息,从文本主题层面与语义层面融合LDA 文档—主题分布与Doc2Vec 句向量,改善了单一特征进行子话题聚类的缺陷,能更加全面有效地表达文本特征,从而提高同一突发事件下子话题聚类效果。
5 结束语
本文提出的基于文本融合特征的子话题聚类方法,结合LDA 主题模型提取的文本主题特征与Doc2Vec 模型提取的文本语义特征构建一种文本融合特征,并通过Single-Pass 增量聚类实现子话题聚类。 研究中使用本文方法,以新浪微博为数据来源平台,对“郑州地铁7.20 事件”这一突发事件评论文本进行实验分析。 在对比实验中,采用F1 值与两种单一特征子话题聚类进行聚类效果评估。 实验结果表明,融合特征能更加全面地表达文本特征,改善了单一特征进行子话题聚类缺乏上下文语义信息及忽略语序的问题,有效地提高了突发事件中子话题聚类的准确率。
受各方面因素所限,本文还存在一定的局限与不足。 在突发事件网络舆论中,网民往往带有浓烈的正向或负向的情感色彩。 因此,在文本的特征表达中,如何提取评论文本的情感特征并将其进行融合处理,从而更有效地进行子话题挖掘,在后续的研究中仍有待进一步深入和突破。
