一种基于随机森林的LOS/NLOS基站识别方法*
2023-10-31戢静红张振宇
戢静红,张振宇,邓 平
(西南交通大学 信息科学与技术学院,成都 611756)
0 引 言
如何消除电波的非视距(Non-Line-of-Sight,NLOS)传播对定位精度的不利影响,多年来一直是蜂窝及各种室内/室外无线定位系统迫切需要解决的一个难题。目前,对NLOS传播带来的误差进行消除的技术主要分为两类:一类是直接对测得的到达时间(Time of Arrival,TOA)等数据进行加权或修正来抑制或减弱NLOS误差对定位的不利影响;另一类则是通过检测视距(Line-of-Sight,LOS)环境和NLOS环境中传播信号参数的不同统计特征来鉴别TOA测量数据是否包含有NLOS误差,然后剔除掉包含NLOS误差的NLOS基站测量数据,只采用LOS基站的测量数据进行定位[1]。
对于LOS/NLOS基站进行识别的方法有多种。文献[3]提出利用TOA测量值在先验概率已知和未知的情况下,采用广义似然比检验和一致最大功效检验来鉴别是否有NLOS信号,取得了较好的识别率。文献[4]提出了一种利用到达角(Angle-of-Arrival,AOA)测量值的NLOS识别方法,先采用Neyman-Pearson(N-P)准则计算判决门限,再进行NLOS识别。文献[5]提出了一种基于距离残差检测(Range Residuals Test,RRT)的识别算法,利用在LOS环境下基站到移动台的距离与测量距离的归一化残差值服从卡方分布这一特性来完成NLOS基站的识别。文献[6]提出了一种不需要信道特征的NLOS识别算法,采用距离残差平方和作为特征来进行训练,当只有一个NLOS基站时识别率较高,但对于多个NLOS基站的场景并未进行考虑。文献[7]提出了基于仿射传播聚类的 LOS/NLOS 环境识别算法,通过对多重信号分类算法得到空间谱的极值点进行聚类,根据聚类结果的分散程度来进行NLOS识别。
近年来出现了一些基于机器学习的识别方法。Nguyen等人[8]基于相关矢量机(Relevance Vector Machine,RVM)技术,设计了一种有效的分类器来识别NLOS信号,提高了该系统中基于到达时间定位的准确性。文献[9]提出了一种采用TDOA距离作为特征,通过训练不同数目基站组合的分类器,构成一个分类器网络,将测试样本输入分类器网络,层层检验,输出为1时得到全为LOS基站的数据。该算法通过分类能得到只有LOS基站的测量值进行定位,但是没有给出准确的识别率。文献[10]利用卷积神经网络(Convolutional Neural Network,CNN)来处理信道冲激响应(Channel Impulse Response,CIR)的原始数据,然后通过训练分类器来完成NLOS识别。针对高分辨率CIR信息难以采样的特点,文献[11]设计了一种递归神经网络(Recursive Neural Network,RNN) 模型,它适当地组合了跨层信息,如CIR和RSSI,通过训练数据可有效地代替传统数学计算的方法来识别信道条件,即使对于在很短的时间内获得的数据,该方法也能获得较高的估计精度。文献[12]利用从信道冲激响应中提取的特征参数,使用随机森林(Random Forest,RF)分类算法来处理LOS/NLOS识别问题。在许多应用中,当底层模型难以近似或未知时,机器学习方法被认为是比较有效的。为此,本文提出了一种蜂窝网中通过随机森林进行LOS/NLOS基站识别的方法。RF方法相比文献[9]中的支持向量机(Support Vector Machine,SVM)方法,可以大大减少计算成本,也不用计算CIR的信息,基于各基站TOA测量值之间的相关性,利用机器学习方法准确识别出NLOS基站。与文献[12]方法相比,本文提出的识别方法不需要频谱分析仪等辅助设备,只需要通过获取的发射机与接收机之间的TOA测距值即可实现NLOS信号的识别。
1 距离测量与定位误差的相关性
在蜂窝网络中,假设移动台(Mobile Station,MS)在二维空间中的坐标为(x,y),基站坐标为(xi,yi),i=1,2,…,N,N表示基站总数,则MS到第i个基站的真实距ri(i=1,2,…,N)为
(1)
(2)
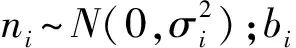
(3)
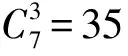
(4)
本文选择TOA测量距离作为分类器的输入特征,利用每一组基站中测量距离在LOS/NLOS场景下的差异,采用随机森林机器学习分类算法训练得到每组基站基于这种相关性的分类器模型,即可实现LOS/NLOS基站的分类。
2 基于随机森林的分类方法
随机森林算法是一种著名的集成学习方法,其核心思想是用随机的方式建立一个森林,该森林由许多决策树组成,以决策树为基分类器构成大型多分类器。将测试数据输入模型时,对多棵决策树的输出类别进行投票得到最终的预测结果。决策树其实就是节点分裂的过程,从根节点开始不断向下分裂,直到数据集不可再进行分裂,则决策树停止生长。常见的决策树分类算法包括ID3算法、C4.5算法和CART算法[13-15],这三种算法分裂规则分别是基于信息增益、信息增益率和基尼(Gini)指数。
图1所示为一个集成分类器工作流程框架,其核心思想是:多个基分类器按规则组合,最后输出一个最终测试结果。每一个基分类器都可以参与决策,对于分类来说,模型的最终结果由各基分类器投票决定,选用分类结果票数最多的类标签。
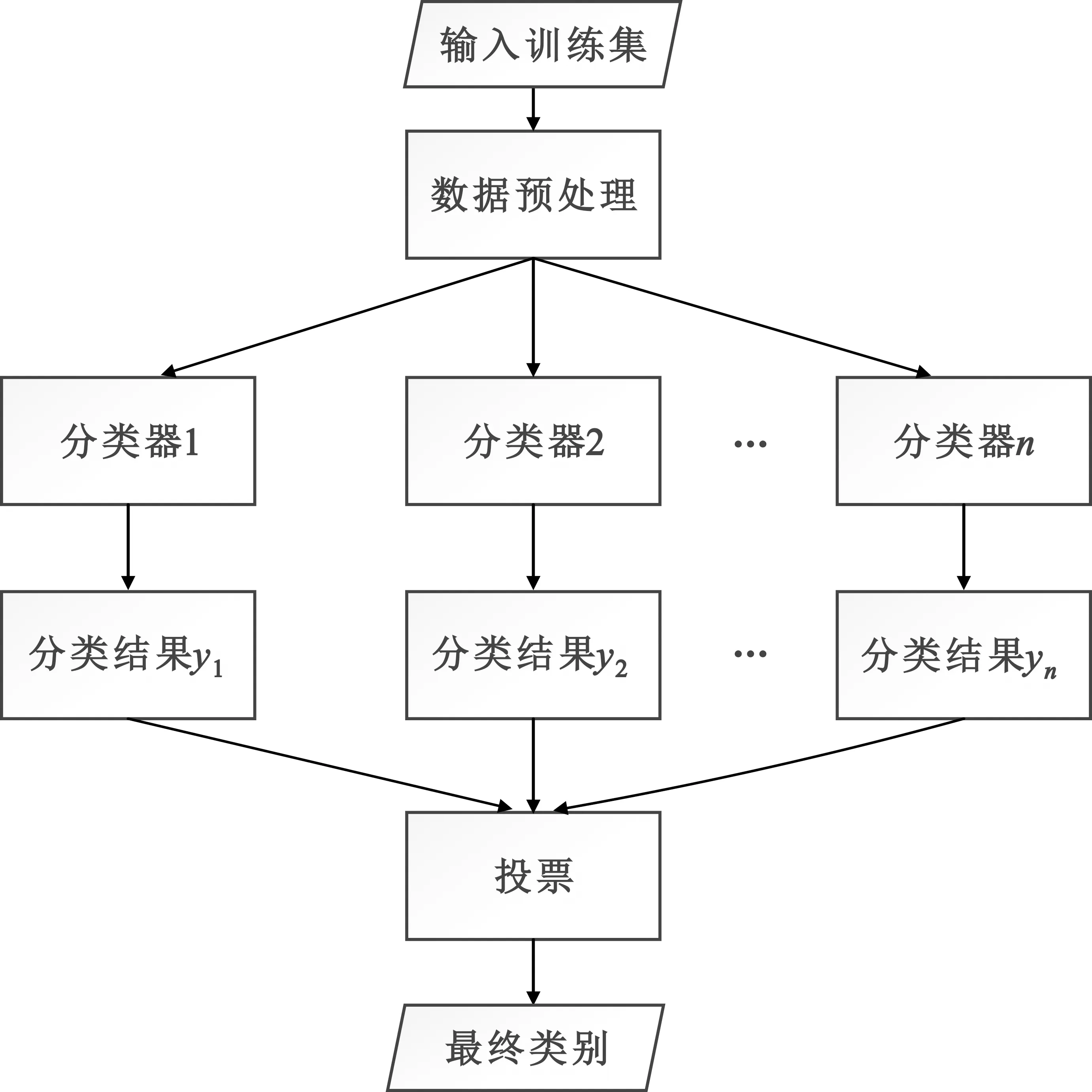
图1 集成分类器框架
本文采用基于CART算法决策的随机森林算法。通常基尼指数较小的属性会被选为节点的分裂属性,基尼指数越小样本的“纯净度”越高,越容易从样本中分离出来。整个分裂过程实际上是使用满足划分准则的特征不断地将数据集划分成纯度更高、不确定性更小的子集的过程。
当样本特征有K类,第k个类别的概率记为pk时,基尼指数的表达式为
(5)
如果样本集合D根据某个特征A被分割为D1和D2两个部分,那么在特征A的条件下,集合D的基尼指数定义为
(6)
若基尼指数值越大,样本集合的不确定性也就越大,与熵的概念比较类似。
本文中对LOS/NLOS基站的区分,若采取将每3个基站分为一组的形式,对应的每一个组合都可以得到3个TOA距离测量值。将这3个距离测量值作为随机森林分类器的特征,分别训练每一种组合的分类器。同一组基站的测量距离在LOS/NLOS环境下存在较大差异,本文采用每组基站的测量距离作为特征,通过测量距离与LOS/NLOS环境的关系,根据每个特征的基尼指数来决定决策树,然后得到基于这些决策树的随机森林分类器,从而进行分类。
在随机森林算法的测试过程中,每一组观测值都需要同时通过森林中所有的树,从其根节点到相应的叶节点。算法输出的预测值是基于每棵树的多数投票,投票最多的类即为预测结果。为了得到算法的输出预测,根据测试数据集的第i次观测结果,树p(p=1,2,…,P)的预测值表示为yip,在本文的LOS/NLOS二分类问题中,yip的取值为“+1”(LOS)或“-1”(NLOS),整个随机森林算法的预测输出为yi,其表达式如下所示:
(7)
分类结果可通过yi的假设检验实现,如下式所示:
(8)
3 LOS/NLOS基站识别算法流程
在蜂窝定位系统中,为了能够确保利用TOA测量距离进行定位,需要假设LOS基站个数至少为3。在此前提下,通过识别出NLOS基站,丢弃掉NLOS基站的测量数据,只采用LOS基站测量得到的距离进行定位。
本文识别算法步骤如下:
Step1 在蜂窝定位区域内布置多个位置坐标已知的基站,确定待测目标移动台在一定范围内移动,测量LOS和NLOS两种场景下移动台与基站之间的距离。
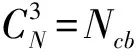
Step3 测试时,对于每一个移动台到各个基站的测量距离进行同样的组合,作为对应的Ncb个分类器的输入,输出“+1”的组合表示该组合为LOS基站组合。由于每个LOS组合中的基站数会多次出现在各个组合中,因此对输出为“+1”的组合进行去重取唯一值。如果得到的LOS基站与事先设置的LOS基站一致,则表示正确识别出LOS/NLOS基站。
将识别后的NLOS基站进行剔除,再利用剩余的LOS基站进行定位,即可得到准确的移动台估计位置。
4 算法仿真与分析
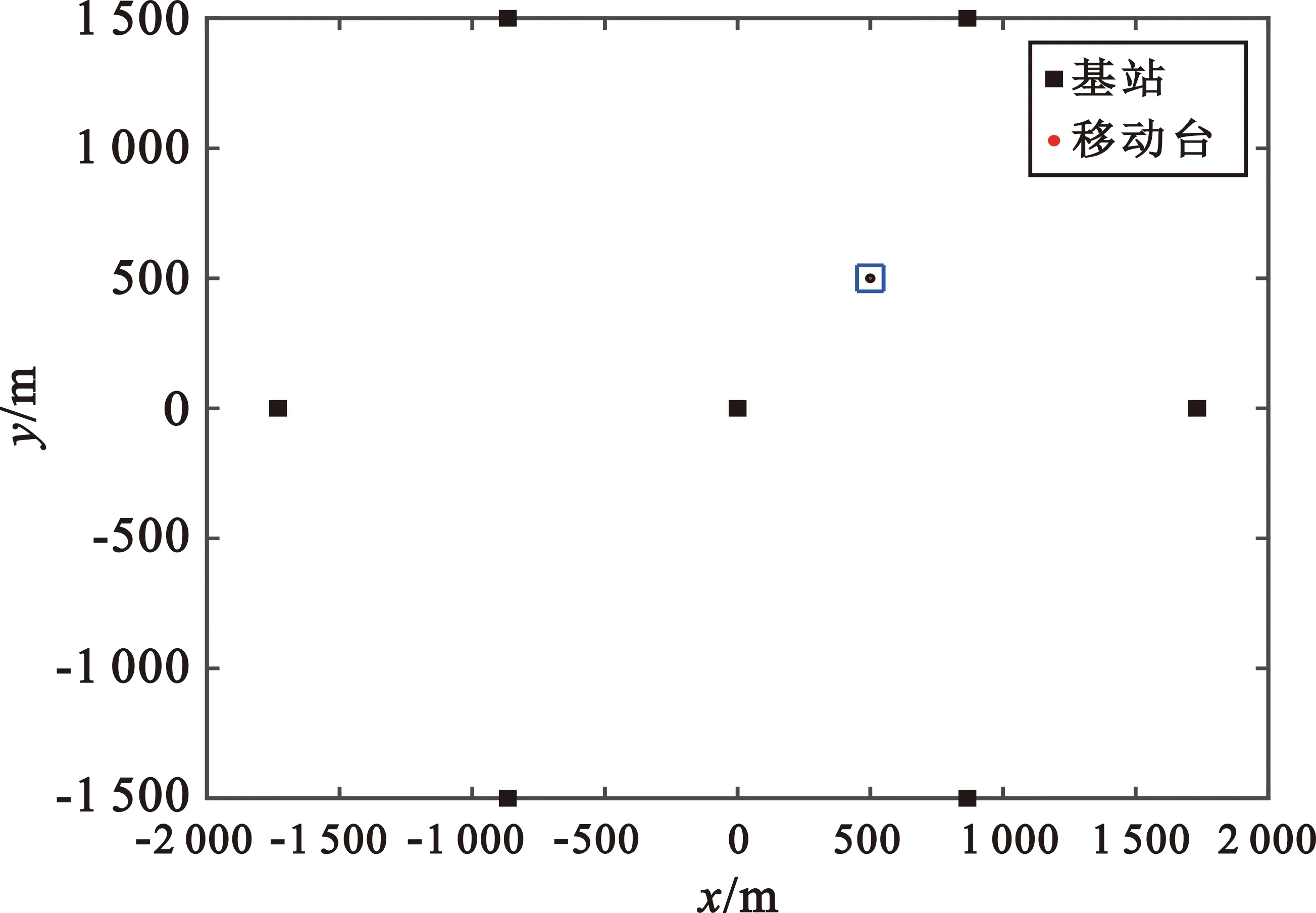
图2 基站与移动台布局
4.1 仿真实验1:分析TOA测量误差大小对算法性能的影响
仿真中对于每一组分类器都采用移动台位置区域内均匀生成的2 000个LOS样本和2 000个NLOS样本进行训练,在同样的移动台位置区域内随机生成10 000个与训练样本不同的待定位目标点作为测试样本,测试样本中LOS和NLOS样本同样各占一半,每一个NLOS测试样本包含的NLOS基站数量为随机指定的1~4其中任何一个。随机森林方法中子树数量设置为100,由于随机森林的特性,分类性能的波动较小。
表1为距离测量误差标准差为σ=1 m,5 m,9 m的情况下,本文随机森林(RF)算法与KNN算法、文献[9]中的SVM算法的识别率比较。
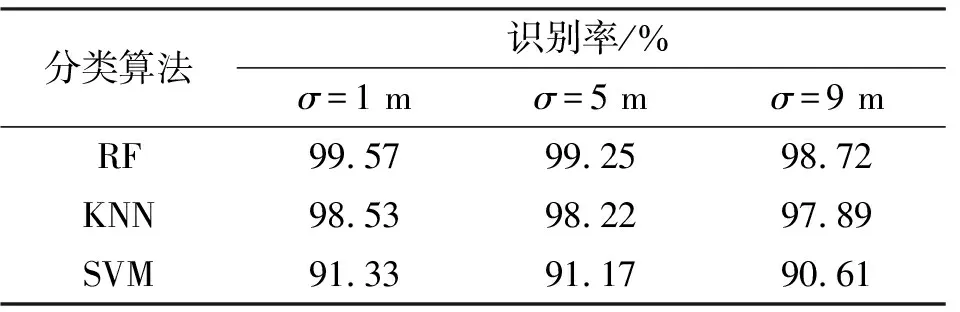
表1 不同TOA测量误差下算法识别率
表1的结果表明,本文算法性能优于另外两种算法。随着TOA测量误差标准差的增大,三种分类识别算法对于LOS/NLOS基站的识别率下降不明显,因此可以看出TOA距离测量误差对于算法性能影响并不大,原因是TOA测量误差值相对于NLOS误差来说过小,而本文采用的是各基站组合的测量距离来作为特征进行分类训练,因此对特征产生的影响较小,因而对于算法的识别性能影响较小。
4.2 仿真实验2:分析NLOS误差大小对算法性能的影响
仿真中NLOS误差服从U(100,BMAX),BMAX表示NLOS误差最大值;TOA距离测量误差标准差σ=1 m;训练和测试样本产生方式与仿真1相同,每一个NLOS测试样本中的NLOS基站个数从1~4随机指定,测试中LOS和NLOS样本各占一半。
表2为NLOS误差最大值分别在200 m,400 m,600 m,800 m,1 000 m情况下三种算法的识别率比较。
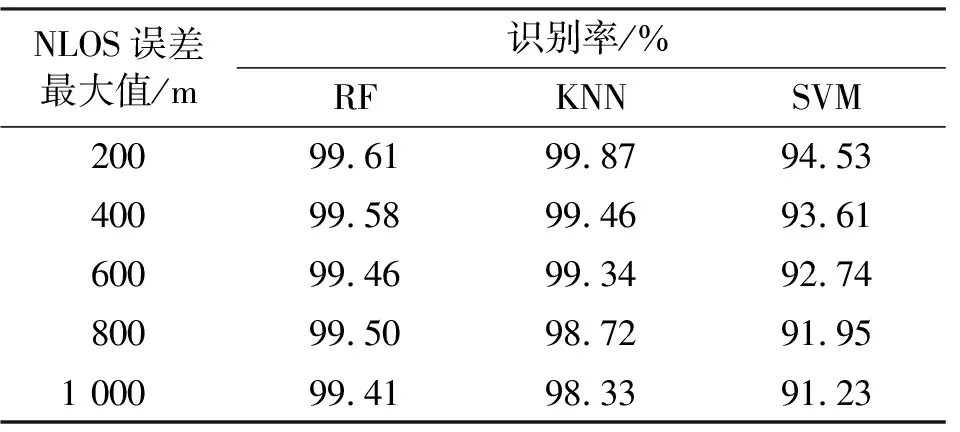
表2 不同NLOS误差下三种算法识别性能
表2的结果表明,随着NLOS误差的增大,KNN和SVM分类算法识别率有一定的下降,而本文RF算法识别率相对稳定性能较好。这是由于RF算法分类过程中会通过Gini指数选择最优的分裂属性,因此只要NLOS误差在一定程度上大于测量误差,即使NLOS误差值再增大对算法性能的影响也不大,且RF算法由多个分类器构成,因此性能比另外两种分类器更好。
4.3 仿真实验3:分析不同NLOS基站个数对算法性能的影响
仿真中训练样本与测试样本与仿真1的产生方式相同。图3为10 000个测试样本点中NLOS基站数为0,1,2,3,4的情况下,三种分类算法识别率的比较。
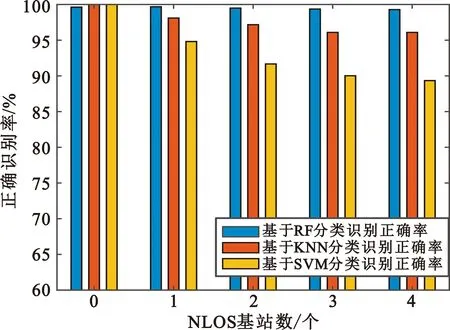
图3 不同NLOS基站个数下三种算法识别率比较
图3的结果表明,当NLOS基站个数增加时本文RF算法与KNN算法的识别率比较稳定且识别率都在95%以上,基于SVM的分类算法性能相对较差,随着NLOS基站个数增加识别率逐渐下降,受到NLOS基站个数影响较大。
4.4 仿真实验4:分析训练样本大小对算法性能的影响
仿真中在移动台位置区域随机产生10 000个测试样本。图4为训练样本大小分别为100,500,1 000,2 000,3 000,4 000的情况下,三种算法的识别性能比较。
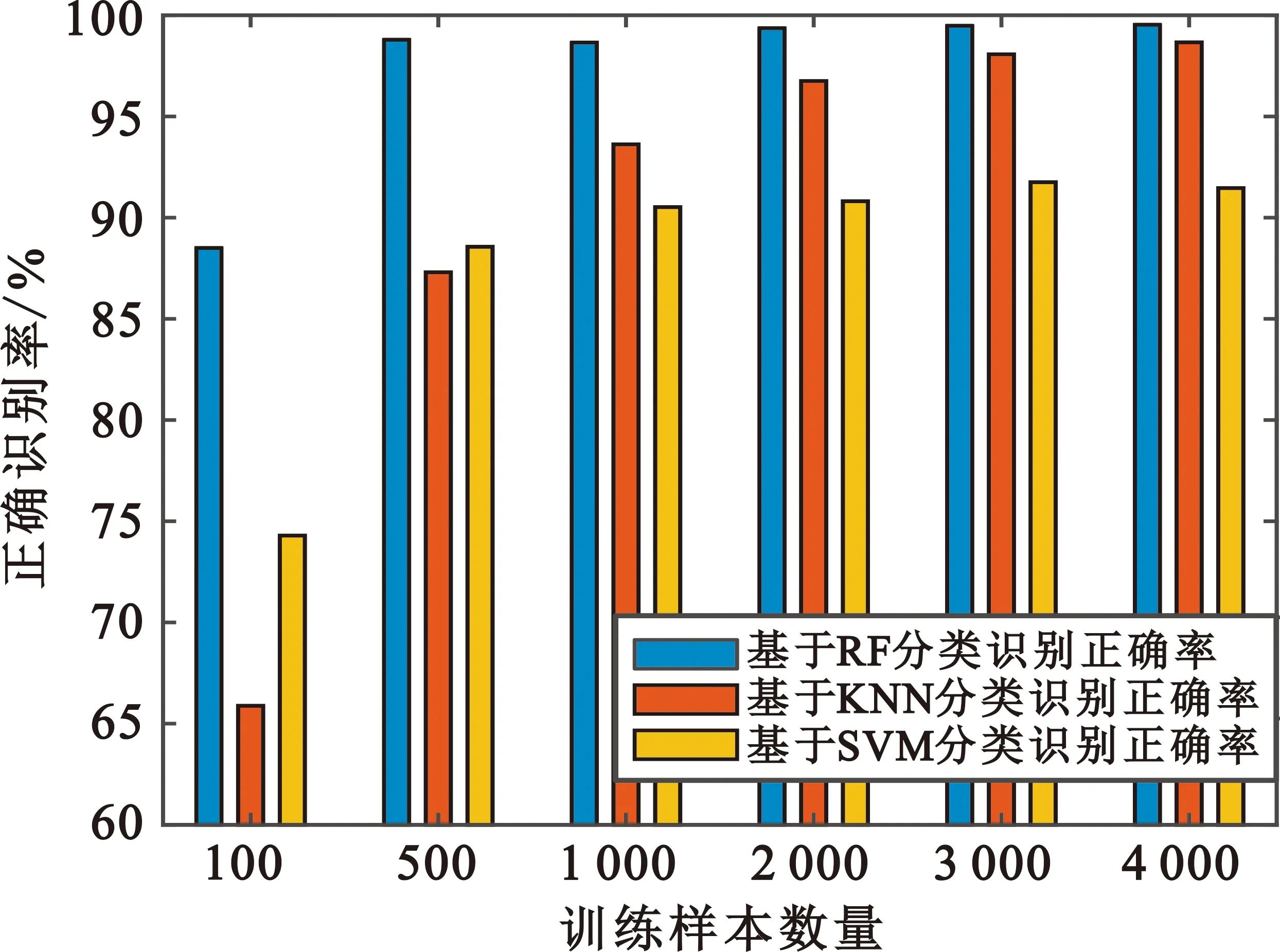
图4 不同训练样本数量算法识别率比较
图4的结果表明,随着训练样本数增加KNN以及SVM算法的识别率也随之增加,RF分类算法性能相对稳定,表现良好。当训练样本数在4 000时,识别率趋于稳定。由于本文算法是通过在移动台位置区域中进行距离的测量,利用各基站组合中距离在LOS/NLOS下的差异来进行分类训练,而不是通过采集信道的参数信息,因此生成训练集时均匀遍历整个定位空间,会使得算法拥有更好的性能,若采集的样本过少,算法性能将会变得很差。
4.5 仿真实验5:分析NLOS样本占比不同对算法性能的影响
在实际场景中,LOS和NLOS信号是混合的。图5为NLOS样本占测试样本比例为0.9,0.5,0.1的情况下,不同算法识别性能比较。
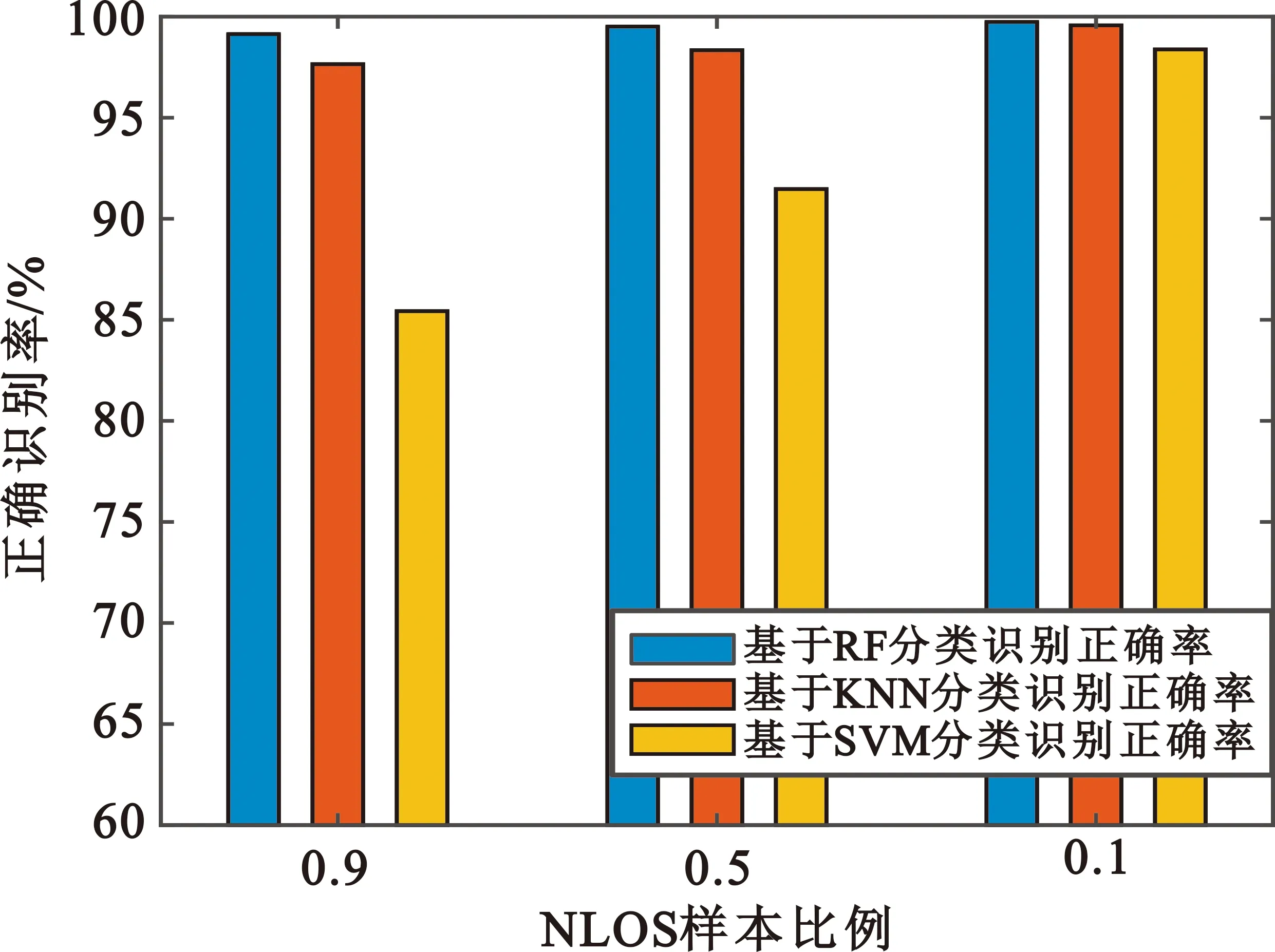
图5 LOS/NLOS不同比例识别率比较
图5的结果表明,SVM算法在NLOS样本占比越大时识别率越低,RF算法以及KNN算法随着NLOS样本占的变化识别率变化较小,RF算法性能最好。
4.6 仿真实验6:分析不同NLOS样本比例经过识别之后再进行定位的定位性能
按仿真1生成训练样本,其LOS/NLOS比例相同;同样采用10 000个点为测试样本,设置测量误差为1 m,每一个NLOS样本NLOS基站随机指定为3个。
图6为经过不同算法识别之后采用Chan算法定位与未进行识别直接采用Chan算法定位的结果。
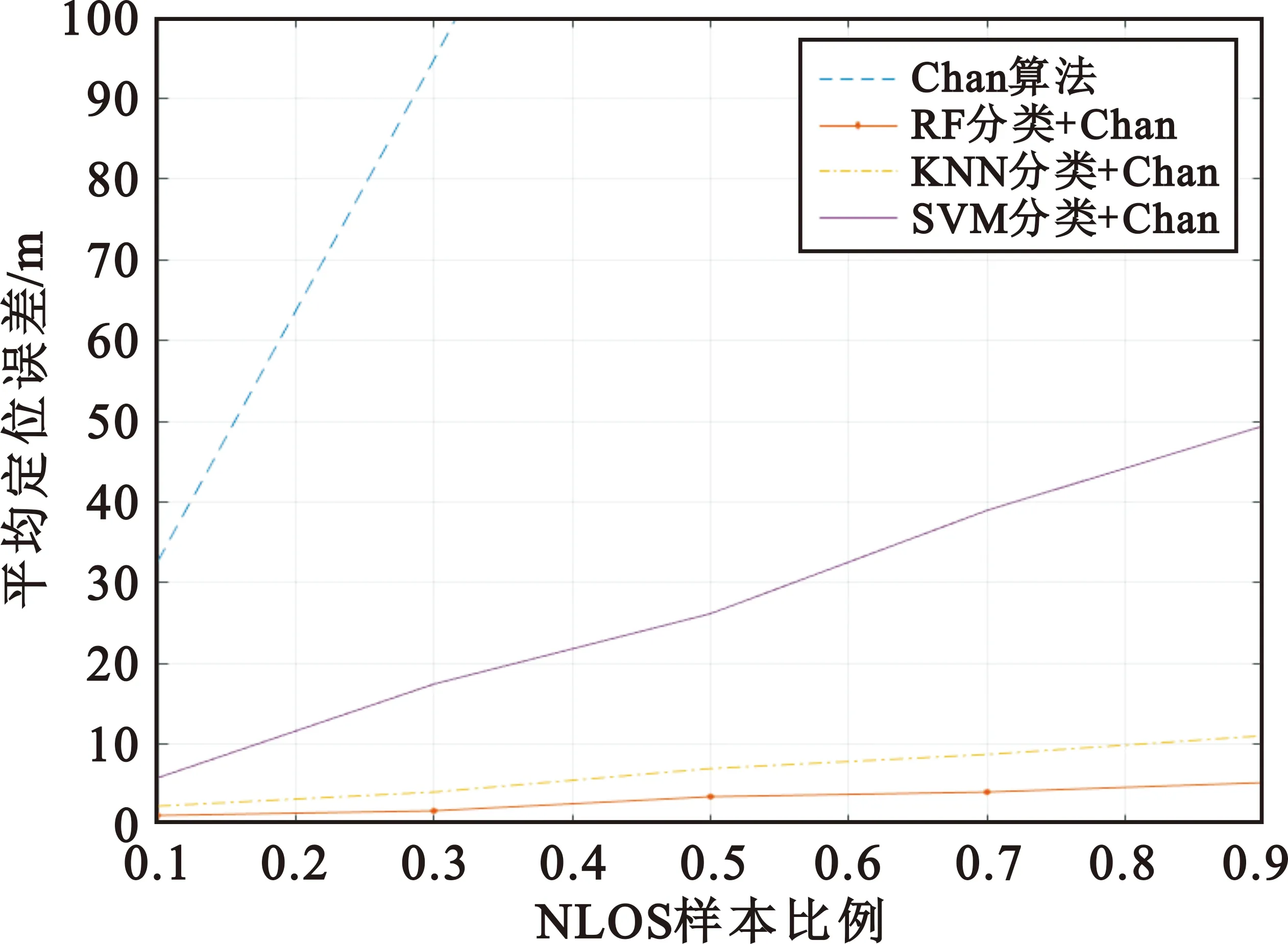
图6 NLOS占比不同算法定位性能比较
图6的结果表明,随着NLOS样本占比增加平均定位误差都在增大,原因是NLOS样本数增加会导致算法的识别率有所降低,导致定位误差增大。其中RF算法进行NLOS识别之后定位误差最小,性能最优。经过不同的分类算法对NLOS基站进行识别剔除后,只采用LOS基站进行定位,相比于直接采用Chan算法定位的性能更好,定位精度得到了很大的提高,表明本文所提出的NLOS识别算法能够准确识别出NLOS基站。
4.7 仿真实验7:分析不同分类算法计算复杂度
仿真中固定测量误差为1 m,训练和测试样本产生方式与仿真1中相同,每一个NLOS测试样本中的NLOS基站个数从1~4随机指定,测试中LOS和NLOS样本各占一半,分别测试不同算法从训练到测试完成的时间开销,结果如表3所示。表3中,n代表样本的总数量,m代表的是用于分类特征的的维度,而d代表RF算法中决策树的最大深度。从表中可以看出基于SVM算法的时间复杂度最高,RF算法次之,KNN算法时间复杂度最低。但是从实际运行时间来看KNN算法时间消耗最大,这是由于KNN算法没有训练过程,是靠直接计算每个测试样本到训练样本的距离进行分类,更加适用于样本数量较少的情况,而本文中样本数量较大,因此预测效率较低,运行时间最长。由表3可以看出RF算法实时性比SVM算法更好。综上所述,基于RF分类的LOS/NLOS算法稳定性和时效性都优于其他两种分类算法。

表3 不同算法计算复杂度
5 结 论
本文提出了一种基于随机森林机器学习的LOS/NLOS基站识别算法,其优点是不需要采集信道特征参数,仅通过发射机与接收机之间的测量距离作为特征,利用机器学习分类算法来进行NLOS识别。仿真结果表明,基于随机森林的分类算法进行分类的识别率要优于KNN分类算法和SVM分类算法,且经过随机森林分类算法识别剔除NLOS基站之后再采用Chan算法进行定位与未进行识别直接采用Chan算法定位相比定位性能得到了很大的提高。
