基于机器学习算法的喀斯特峰丛洼地石漠化程度评估
2023-10-30张亚丽田义超王栋华
张亚丽, 田义超,2†, 王栋华
(1.北部湾大学资源与环境学院,535011,广西钦州;2.北部湾大学北部湾海洋地理信息资源开发与利用重点实验室,535011,广西钦州;3.桂林理工大学环境科学与工程学院,541004,广西桂林)
石漠化是岩溶区受自然因素和人为活动干扰而形成的一种土地退化类型[1]。石漠化广泛分布于我国西南部,面积约54万km2,其中位于滇黔桂的峰丛洼地类型石漠化面积最大,为12.5万km2[2]。石漠化区域由于长期受到可溶性碳酸盐岩的影响,成土极为缓慢,土层薄且不连续,水文过程响应迅速[3]。石漠化导致的土壤侵蚀、地表水流失、生物多样性丧失等一系列的生态环境问题,严重影响当地人民的生存环境和可持续发展[4];准确定量的石漠化的程度,对于喀斯特区域的水土保持工程和生态建设工程精准化调控具有重要的参考意义。
国内外学者基于遥感数据,采用监督分类、非监督分类和构建石漠化指数等方法,对不同区域不同尺度石漠化程度的空间分布状况和演变趋势开展大量研究[5],为喀斯特区域生态工程与治理措施提供科学参考。然而,由于喀斯特区域地表复杂且峰丛叠嶂,从而造成遥感影像阴影较多,传统的石漠程度评估方法存在一定的弊端[6]。近年来,相关学者将机器学习算法和特征数据相结合实现石漠化程度评估。与传统方法相比,机器学习算法,具有较强的自主学习能力和解决复杂非线性问题的优势,能够更准确地做出预测。基于机器学习模型评估石漠化程度目前已有众多研究成果,在评估石漠化时学者们多采用某一个机器学习模型算法中的默认参数,但往往机器学习中的默认参数评估出的石漠化与实际石漠化的分布存在着一定的差异性,这限制了机器学习模型在石漠化中的进一步应用[7-9]。鉴于此,如何采用优化算法对机器学习模型参数进行优化,从而精确的评估石漠化程度是亟需解决的问题。
桂西南峰丛洼地流域位于贵州高原向广西盆地过渡的斜坡地带,流域内喀斯特地貌广泛发育。受碳酸盐岩地质背景制约,岩溶发育强烈景观异质性高,水土流失和石漠化问题长期存在,生态环境极其脆弱[10]。该流域地表起伏较大,峰丛、谷地、洼地、塔峰、锥峰等交错分布,传统的石漠化程度评估方法困难。鉴于此,笔者基于石漠化影响因素数据和实地调查数据,构建7种基于优化算法的SVM的混合模型,用于石漠化程度与其影响变量之间的关系建模。采用Boruta、最大互信息数和极限学习3种特征选择方法提取的特征数据集。最后,选择最优模型评估桂西南峰丛洼地石漠化程度,以期为生态工程建设和石漠化治理提供数据支撑。
1 研究区概况
桂西南峰丛洼地流域介于E 104°33′~108°43′,N 21°35′~24°39′ 之间,面积6万1 485.16 km2,位于贵州高原向广西盆地过渡的斜坡地带(图1)。流域的上游为滇东南岩溶高原区,平均海拔高于1 200 m,年均气温16.7 ℃,年平均降水量1 056.5 mm,属中亚热带高原季风气候,代表岩性为从晚泥盆世至早、中二叠世持续发育的灰岩、白云质灰岩,以峰丛洼地、谷地、溶丘洼地等岩溶地貌形态为主,是云南严重石漠化最为典型代表区域[11];流域的中游以山地地形为主,海拔介于600~1 000 m,年均气温为 19.5 ℃,平均降雨量为1 634.2 mm,属亚热带季风气候,岩性背景属中泥盆世-二叠纪发育的连续性碳酸盐[12],地貌形态以峰丛洼地和峰林洼地组合为主,是全国喀斯特地貌发育最典型的区域之一;流域的下游为丘陵地带,平均海拔低于400 m,年均气温22 ℃,平均降雨量为1 361.1 mm,位于属亚热带季风气候区,岩性背景为石炭纪-早三叠世发育的碳酸盐岩,地貌形态以锥峰谷地、塔峰谷地和低山丘陵组合为主,是浅碟型锥塔峰洼谷地区[10]。该流域在气候条件和地貌类型具有显著的空间分异性,地势呈西北高、东南低,喀斯特地貌广泛发育,生态系统较为脆弱,是中国西南典型的峰丛洼地喀斯特地区之一[13]。该地区既是珠江流域重要的生态屏障,是我国重要的水源涵养区和生物多样性优先保护区,也是中国通往东盟国家最便捷的海陆通道,在“一带一路”倡仪实施中居于重要枢纽的地位。

图1 桂西南峰丛洼地流域研究区域
2 数据来源与方法
2.1 数据来源
笔者使用的石漠化影响因子数据(表1),并基于ArcGIS平台对石漠化因子数据进行投影变换,统一采用WGS-84-UTM-zone-48坐标系,以研究区边界为掩膜进行裁剪,重采样至为250 m的栅格数据。

表1 桂西南峰丛洼地石漠化影响因素
样地调使用手高精度手持GPS面采集,记录裸露岩石和植被覆盖的面积,用于计算样本点的植被覆盖度、岩石裸露率等指标。另外对于高海拔区域采用无人机航测和RTK采集,制作正射影像图,基于ArcGIS平台矢量化统计岩石裸露面积[14]和植被面积,用以确定石漠化程度。共采集526个调查数据,其中75%(395个)用于训练模型,25%(131个)用于测试模型。按照HJ 1174—2021《中华人民共和国国家生态环境标准》,将石漠化程度分为无石漠化、轻度石漠化、中度石漠化、重度石漠化和极重度石漠化5种程度(表2)。

表2 喀斯特石漠化程度划分依据
2.2 特征选择方法
特征选择对基于机器学习算法的运行效果有着重要的影响。对于机器学习模型,输入过多的影响因子会导致模型效率低下;输入不相关的因子增加数据噪声导致模型的预测能力下降[15]。采用有效的特征集构建模型,不仅能够使模型泛化能力更强,减少过拟合,还能提高模型的运行速度和精度。笔者采用Boruta、最大互信息系数(MIC)和极限学习(ELM)3种算法进行特征选择[16-18]。
2.3 机器学习方法构建评估模型
支持向量机是较新的机器学习算法,在解决高维特征的分类和回归问题时,无需依赖所有数据即可实现高精度超平面决策。SVM模型有2个非常重要的参数惩罚因子(c)与核参数(g),用于确定特征空间最优线性回归超平面。由于c、g的参数取值具有不确定性,并且对评估结果有着较大的影响[19]。因此,为了提高桂西南峰丛洼地石漠化程度评估模型的准确率,需要对其参数进行优化。鉴于笔者采用以下7种优化算法确定参数c和g。7种智能优化算法,包括人工蜂群(ABC)、布谷鸟搜索(CS)、粒子群优化(PSO)、差分进化(DE)、引力搜索算法(GSA)、萤火虫(FA)和鲸鱼优化算法(WOA)用于SVM超参数调整。基于优优化算法[19-25]和SVM型构建ABC-SVM、CS-SVM、PSO-SVM、DE-SVM、GSA-SVM、FA-SVM、WOA-SVM模型,对桂西南峰丛洼地石漠化程度评估模型如图2。
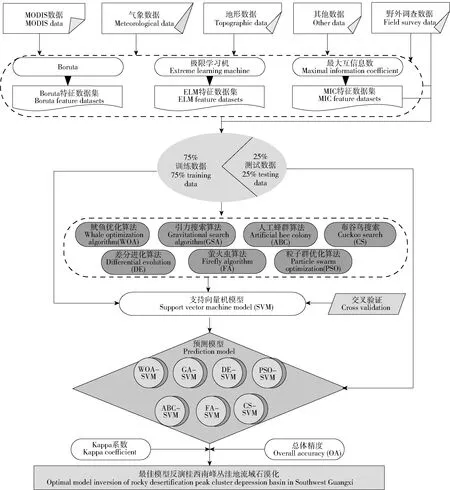
图2 桂西南峰丛洼地流域石漠化程度评估流程
评估流程分为4步:1)数据处理:基于ArcGIS平台对遥感数据、地形数据、气象数据和野外调查数据等数据进行处理;2)特征选择:基于Boruta、MIC和极限学习选择评估石漠化程度的最优特征向量;3)构建混合模型:采用7种优化算法对SVM的输入参数c和g进行优化,并行交叉检验;4)精度分析与评估:对比模型进精度,基于最优模型评估桂西南峰丛洼地流域石漠化程度。
3 结果与分析
3.1 特征选择结果分析
基于3种特征选择算法构建影响石漠化程度评估的多维特征集如表3。可知,Boruta算法中保留5个特征:RE、FVC、SL、FPAR和LAI。ELM算法中保留6个特征:RE、FVC、SL、LAI、FPAR和ST。在MIC算法中,保留5个特征RE、FVC、LAI、PFAR、ET。在所有特征选择算法中,一致表明,影响石漠化程度评估的最重要的特征是RE,其次是FVC。

表3 不同特征选择算法选择的特征数据集及重要性排序
3.2 模型精度分析
笔者将特征数据集和标签数据分为训练集和测试集。模型的训练和交叉验证均在训练集上完成,基于不同的特征集,分别对混合模型循环运行十次,保存最高精度的模型。各特征集对应的各优化模型的评估精度如表4。整体来看,基于Boruta特征数据集的各混合模型的总体精度和Kappa系数最高,性能最优;各模型评估效果差异较小,说明预测结果的可靠性。但从混合模型的学习效率来看,分异显著。混合模型的精度从高到低依次为PSO-SVM、FA-SVM、GSA-SVM、CS-SVM、ABC-SVM、WOA-SVM和DE-SVM,其对应的总体精度值分别为96.2%、95.4%、95.4%、93.1%、93.1%、93.1%和93.1%,Kappa系数分别为0.95、0.93、0.93、0.90、0.90、0.90和0.90。

表4 基于Boruta、MIC、ELM特征集各优化模型的预测模型精度对比
FA-SVM、PSO-SVM和GSA-SVM模型综合性能表现最佳,PSO-SVM模型精度最高。FA-SVM该模型的运行时间最短为3 s左右,收敛最快,效率最高。ABC-SVM、WOA-SVM、CS和DE-SVM模型表现基本一致,分类精度均超过93%,各项评价参数近乎相同。其中ABC-SVM和CS-SVM模型的运行效率相对较好,DE-SVM和WOA-SVM模型耗时较久。
综合分析各石漠化评估模型的运行效率和精度,FA-SVM最优。进一步分析不同石漠化程度的精度(图3)。从用户精度来看,仅有轻度石漠化程度的精度为84.6%,其余均>95%。对于生产者精度,无石漠化和轻度石漠化类型的精度分别为80%和84.6%,其余均分类精度>95%。

NRD:无石漠化,LRD:轻度石漠化,MRD:中度石漠化,SRD:重度石漠化,ESRD:极重度石漠化。下同。NRD: None rocky desertification. LRD: Light rocky desertification. MRD: Moderate rocky desertification. SRD: Severe rocky desertification. ESRD: Extremely severe rocky desertification. The same below.
3.3 石漠化空间分布
基于FA-SVM模型评估桂西南峰丛洼地流域的石漠化程度(图4)。从空间上来看:2000、2005和2010年,流域上游的石漠化程度以极重度石漠化为主,呈大片连续分布;中、下游的石漠化程度以重度石漠化为主,极重度石漠化呈块状分布。2015年,流域上游的石漠化程度以重度和极重度石漠化为主,而中、下游的石漠化程度主要为中度和重度石漠化程度。2020年,流域内重度和极重度石漠化面积较小,分布较散,呈零星分布。

图4 2001—2020桂西南峰丛洼地流域石漠化程度空间分布
从时间上来看:1) 2001—2020年,轻度石漠化和中度石漠化面积增加,重度和极重度石漠化面积减少;2) 2000、2005、2010和2015年桂西南峰丛洼地流域的石漠化程度以重度石漠化为主,2020年的石漠化程度则以轻度和中度石漠化程度为主。
总体来看:2001—2020年,桂西南峰丛洼地流域石漠程度在空间分布上呈现出上游重,中、下游轻的特征。究其原因主要与流域内地形地貌、气候条件和人类活动差异有关。石漠化总面积(轻度以上程度)呈先增加后减少,整体减少趋势。这是由于流域内实施退耕还林和生态工程政策有关,石漠化治理效果较好;其次是城镇化和经济的发展,减少对林地和草地的破坏。
3.4 石漠化面积转移矩阵
表5~8展示桂西南峰丛洼地流域不同程度石漠化相互转移的关系。1) 2001—2005主要是重度石漠化转变成中度石漠化,轻度石漠化转变为中度石漠化,中度石漠化转变为重度石漠化,恶化面积大于改善面积。2) 2005—2010年,重度石漠化转变为中度石漠化、中度石漠化转变为轻度石漠化,石漠化改善面积大于恶化面积,石漠化程改善态势。
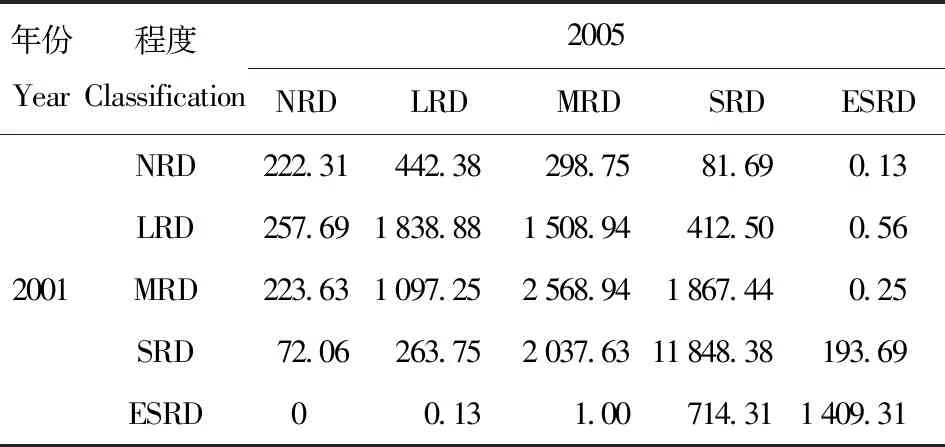
表5 2001—2005年石漠化转移矩阵

表6 2005—2010石漠化转移矩阵

表7 2010—2015年石漠化转移矩阵
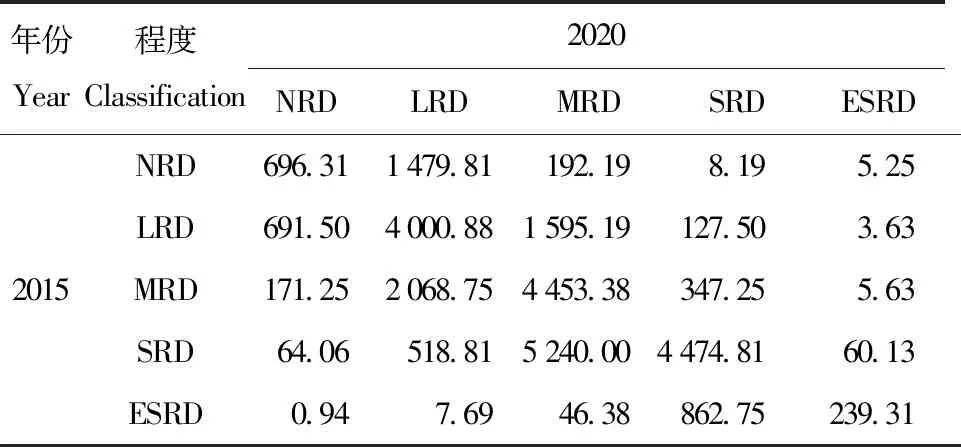
表8 2015—2020石漠化转移矩阵
3) 2010—2015年,重度和中度石漠化进一步得到改善,向低程度转移,其它转移的面积较小。4) 2015—2020年,石漠化面积转移最显著的是重度石漠化转为中度石漠化,改善面积远大于恶化面积。2001—2020年桂西南峰丛洼地流域无石漠化和轻度石漠化面积共计增加4 636.19 km2;重度和极重度石漠化面积共计减少1万1 033.69 km2,石漠化治理效果显著。究其原因为:城镇化发展以及农村太阳能和沼气等供气工程的建设,降低对木材能源的依赖;科学的石漠化治理技术,如水土流失防控与肥力提升、植被修复等方面技术,为石漠化治理奠定技术基础[26];生态工程的建设,植被得以恢复,恢复的植被和土壤的相互作用,影响流域水文过程,改变石漠化结构。
4 讨论
4.1 机器学习算法中石漠化程度评估的影响因素
特征因子过多会降低机器学习模型的运行效率和分类精度,特征因子太少则会导致机器学习模型欠拟合[27]。笔者构建3种特征选择算法用于选择评估石漠化程度的特征因子,3种特征选择方法的结果一致表明,裸岩率和植被覆盖度是石漠化程度评估的重要特征,这是由于裸岩率和植被覆盖度的变化直接反映峰丛洼地岩溶区岩石裸露情况,这也与习慧鹏等[28]观点一致。此外在3种特征选择算法中,LAI和FPAR相比海拔数据更重要,这与李素敏等[29]的研究结果相符,但HUANG等认为坡度和海拔是影响石漠化的关键影响因素。这说明岩溶区地理位置差异、植被类型和季节条件的不同,引起石漠化的驱动因素是不同和多维的。
4.2 评估机器学习算法的效率和敏感性
笔者采用7种优化算法的对SVM超参数进行调整,避免人工选择参数值的不确定性,从而达到更好的分类精度,当采用SVM模型的默认内置参数时,SVM模型的分类的总体精度仅有77%。此外,相较于QIAN(模型总体精度91.1%,Kappa系数为0.86),PU(模型总体精度 85.21%),本文基于优化算法构建的FA-SVM模型(模型总体精度95.4%,Kappa系数为0.93),优于上述结果。就模型的运行效率而言,7种优化算法构建的混合模型的训练时间和运行时间相差很大:其中,FA-SVM算法的训练和运行时间是最短的,而DE-SVR和WOA-SVM算法时间是最长的。这是由于DE算法和WOA算法对参数进行全局搜索导致维度过多问题,从而严重影响模型的运行效率。FA-SVM和PSO-SVM混合模型比其他模型具有更好的评估精度,更高的效率,适合将其应用于大范围大区域的石漠化程度空间分布的评估。
4.3 桂西南石漠化形成的机理和原因
喀斯特地区石漠化的形成与发展是由地形地貌、气象环境和地层岩性等自然因素和人类活动综合作用的结果[7]。桂西南峰丛洼地流域广泛分布着泥盆系、石炭系、二叠系、三叠系碳酸盐岩,以灰岩、灰岩与白云岩互组为主[12],其基底岩石结构和酸不溶物为石漠化的发生提供了客观先决条件。碳酸盐岩地区的成土机制主要是以化学风化作用为主,成土困难,使土壤的厚度比较浅薄、稀少和零星[3]。碳酸盐岩的酸不溶物含量低,溶蚀作用强。该区的地貌多为峰丛洼地和峰林洼地石,加上水文地质条件的催化,使稀薄的土壤和大量的可溶物流失,从而导致水土流失严重、植被覆盖率低、基岩裸露,进而形成石漠化。
气候因素和地形地貌叠加作用同样是导致不同程度的石漠化重要因素。流域的上游位于北热带北缘降雨量较低,在岩性构造的影响下,地表水迅速转化为地下水,导致地表干旱缺水,不利于植被的生长,以草地和灌丛类植被为主。流域的下游位于南亚热带南缘,降雨量较大(图5),虽然可能会加剧水土流失,但同时为植被生长提供所需的水分,促进植被的生长进而又改善了石漠化,这也是上游石漠化程度较重下游轻的原因之一。坡度是诱发石漠化程度另一个重要因素。坡度越大、地形切割深度大,地表物质的稳定性就越差,受降雨的冲刷力,导致水土流失越严重,石漠化的程度加剧[30]。流域的上游、中游峰丛洼地山高坡陡坡,大于25°区域面积较广(图6),极易发生水土流失;而下游丘陵区域坡度较小,石漠化程度轻。
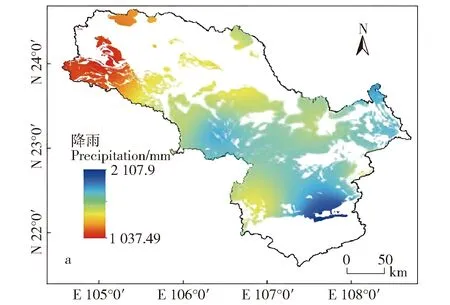
图5 研究区降雨

图6 研究区坡度
人类活动是控制着石漠化的发展趋势重要因素。研究前期流域上游人口密度大、人地紧张,存在着大量乱砍滥伐和过度耕种现象,这是研究前期(2001—2010年)石漠化程度重的主要原因之一。研究后期(2010—2020年),城镇化发展,减少对土地过度开垦,对林地的砍伐和毁坏。并且实施一系列生态修复政策,如2008年岩溶地区石漠化综合治理试点工程(https:∥www.ndrc.gov.cn/),2015年关于全国水土保持规划(2015—2030年)和2017年国家发展改革委岩溶地区石漠化综合治理工程“十三五”建设规划等生态工程建设政策,桂西南峰丛洼地石漠化治理成效显著。因此,需继续实施生态环境治理工程,实现喀斯特区域生态环境重建。
5 结论
1)本研究提出的混合模型在评估峰丛洼地石漠化程度的空间分布具有良好的潜力。ABC、CS、PSO、DE、GWO、GSA和FA7种智能优化算法,可以有效辅助SVM的超参数调优。
2)裸岩率和植被覆盖度在石漠化程度评估中发挥了重要作用,其次是坡度。Boruta构建的特征集具有最佳的降维效果。
3)特征选择和7种优化算法的结合有效地提高了机器学习算法的石漠化程度评估精度。其中,FA-SVM模型运行时长最短,PSO-SVM分类精度最高;虽然WOA-SVM和DE-SVM模型耗时最多,但没有显著改善模型的性能;总体而言,PSO-SVM、FA-SVM、和GSA-SVM混合模型比其他模型具有更好的分类精度,分类的总体精度到达96.2%、95.4%和95.4%,Kappa系数分别为0.96、0.95和0.95,适合将其应用于大范围、大区域的石漠化空间分布的评估。
