基于轻量级AlexNet网络的秦简文字识别算法
2023-10-30陈炳权汪政阳夏蓉陈明
陈炳权,汪政阳,夏蓉,陈明
(1.吉首大学 通信与电子工程学院,湖南 吉首,416000;2.湖南大学 电气与信息工程学院,湖南 长沙,410082)
文字识别是计算机视觉研究领域的分支之一,归属于模式识别和人工智能,是计算机科学的重要组成部分。图像文字识别技术[1]是计算机视觉领域的主要研究内容。手写体字符识别(handwritten character recognition)算法[2]是当前的热点研究方向,现阶段主要集中于对自然场景下或扫描件印刷体的现代中英文文字进行识别,但针对手写体古汉字字符识别的研究相对较少。由于古汉字字形发展年代久远,以及人为手写体差异性的存在,传统方法在对古文字图像进行识别时存在数字化读取困难和识别准确率较低的现象。因此利用图像文字识别技术构建古籍类手写体文字图像的识别模型,最大程度地节省人力、物力在图像识别过程中消耗的同时提高识别准确率具有重要研究意义。
目前采用深度学习算法进行手写体字符识别的研究已经成为图像文字识别技术科研领域的主流[3],提出的一系列深度学习算法,如VGG[4]、DenseNet[5]、 Res2Net[6]、 Vision Transformer[7]和Swin Transformer[8]等均被应用于图像文字识别领域,并取得了很好的效果。然而上述深度学习算法在对文字图像进行特征提取时,存在着文字特征性信息提取不精确导致最终识别准确率较低的问题[9]。秦简文字其本身具有古籍类文字共性存在的字体结构多样、字形变化多端等特点,且个人书法习惯不一,加以文字图像采集过程中出现字迹磨损等现象,导致特征信息提取不精确,这都给秦简文字图像识别带来了挑战。因此,结合秦简文字字形特征与手写体差异性等因素探究有效识别秦简文字图像的深度学习模型,以提高手写秦简字符识别准确率,具有重要的理论与实际意义。
学者针对深度学习模型提出了大量的改善算法,并在不同场景下进行了验证。ZHANG等[10]提出了一种基于小样本量的满文文本识别技术,利用深度卷积神经网络模型进行文本识别,使用滑动窗口代替人工分割,满文文本的识别准确率达到98.84%。仁青东主等[11]利用CRNN+CTC 算法实现了对自然场景下的藏文字符识别,提升了藏文字符的识别效果,识别准确率达93.24%。RAHMATI等[12]提出了一种基于长短时记忆神经网络的波斯语文字识别算法,通过对模型参数优化调整,在字母级的文字识别准确率平均值达99.69%。AlexNet网络模型由于能解决过拟合问题,并且可以利用多GPU 加速计算,因此,在目标分类识别领域也得到了应用。李江等[13]针对弹道椎体目标分类问题,提出了AlexNet网络融合长短期记忆网络的模型结构,实现了对于弹道椎体目标的微动时频图智能分类;郭敏钢等[14]对AlexNet网络的归一化、优化器和激活函数3个方面进行改进,提升了AlexNet模型的训练收敛速度和识别准确率,在MNIST 数据集上的识别准确率达到了98.78%;ZHANG等[15]针对于训练样本量不足的问题,提出一种基于AlexNet网络的自动调制分类方法,实现了对于星座样本数据的扩充,并将分类准确率提高到90.5%;钟桂凤等[16]通过在AlexNet-2 网络中融入注意力机制,并使用Word2Vec 对文本词特征进行嵌入表示和词向量训练,提升了文本分类的性能和运行效率,其在20NG 数据集上的微观F1测度与宏观F1测度分别达到了85.1%和83.2%。然而,传统的AlexNet网络模型架构较为复杂以及参数量过多过大,导致无法在样本量较少的小型数据集上取得满意的性能评估结果。因此,在提升文字识别准确率的同时,应探究AlexNet模型的轻量化改进方法,使其能够在小型数据集上的性能较好。
在秦简文字研究方面,陶珩等[17]针对湘西里耶古镇出土的秦简文字进行了文字检测方面研究,通过计算最稳定极值区域以及非极大值抑制操作,实现了对秦简图像的文本区域检测,但并未对秦简文字识别方面进行深入研究。吴峥[18]采用K-最近邻(K-nearest neighbor,KNN)分类算法实现了秦简文字图像识别,识别准确率达到了70.53%。为了提高秦简文字识别准确率,本文将在AlexNet网络模型的基础之上进行系列改进,提出一种融合Inception V3 模块的秦简文字图像识别方法,该方法与传统深度学习方法相比较,能有效提升对手写体古文字符的识别性能,并在自建的秦简单字数据集(Qin bamboo slips text dataset,QBS text dataset)上进行文字图像识别时,取得了较好的效果,平均识别准确率达99.89%,为后续秦简文字识别研究提供了思路与方法,丰富了手写体古文字符识别的研究领域。
1 AlexNet 网络模型与Inception V3模块
1.1 传统AlexNet网络模型
AlexNet 是基于卷积神经网络(convolutional neural networks,CNN)的深度学习模型。其最大优势体现在将模型部署在GPU 上进行训练,对比用CPU 进行训练时提升了模型的加速训练能力,由于采用计算复杂度更低的ReLU函数作为模型的激活函数,并在全连接层添加Dropout层随机移除神经网络训练元,消除了因模型参数过大而训练样本较少时出现的过拟合现象。另外,该网络由于构建了批量标准化层,减少了奇异训练样本造成的模型梯度弥散问题,大大提升了网络的泛化能力,从而实现了输入数据的分类识别功能。
传统的AlexNet 网络模型包括1 个输入层、5个卷积层、3 个池化层、2 个全连接层与1 个输出层,模型结构如图1所示,其中,s为卷积的步长,采用的卷积方式统一为same卷积。AlexNet模型在对文字进行识别通过多个卷积层的“卷积—激活—池化—归一化”操作,提取到文本区域的特征图,进而送入全连接层并调用分类器,计算输入图像属于某字符类别的概率,最终实现文字图像识别。
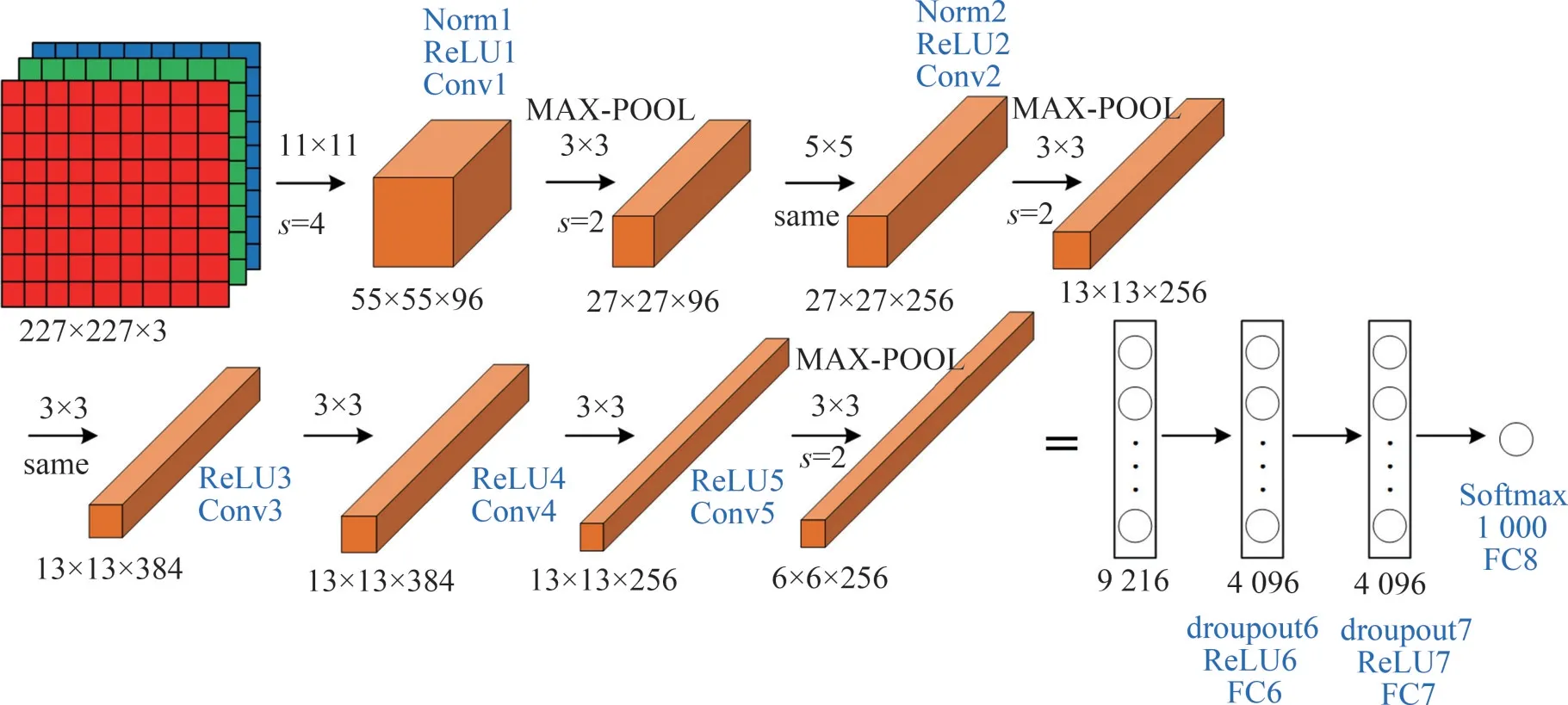
图1 传统AlexNet网络模型结构与参数Fig.1 Traditional AlexNet network model structure and parameters
1.2 Inception V3模块
Inception模块[19]的核心思想是将输入的图像特征分配在多个不同卷积层进行卷积,并将多个卷积结果合并。通过多个卷积层并行卷积操作,然后将得到的特征提取结果连接起来,形成一个深层次的矩阵。在保持原模型结构稀疏性的同时,又利用密集矩阵的高计算性能,提升了模型识别准确率的同时避免了过拟合现象。
Inception V3 模块创新性地引入了分解卷积的概念,替换了在卷积层中一层接一层的传统特征提取操作,把大卷积因式分解成小卷积和非对称卷积,在保持感受野不变的条件下,减少整体模型中参数的计算量。此外,在最大池化下采样的过程中计算输入值的卷积结果和池化结果,并将两者用concat( )方式进行数组合并,在减少计算量的同时降低了信息特征提取的损失量。
Inception V3 模块共有6 种网络结构分支,为符合改进后的AlexNet网络模型属于轻量级网络的要求,本文根据输入的秦简文字图像尺寸以及输入输出通道数等参数,选用InceptionA 与InceptionC 这2 种轻量级模块作为模型改进的基础网络结构(见图2和图3)。
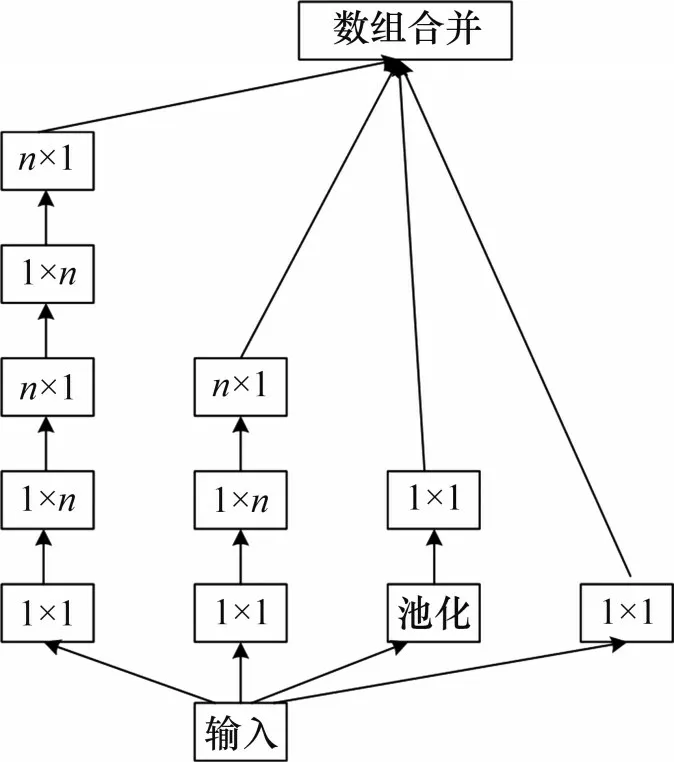
图2 InceptionA网络结构Fig.2 Structure of InceptionA network

图3 InceptionC网络结构Fig.3 Structure of InceptionC network
2 改进的AlexNet网络模型
2.1 AlexNet网络模型结构改进与参数调整
秦简单文字图像相较于文本区域内多文字的图像,其文本特征较易提取,但传统的AlexNet网络模型复杂度较高,难免提高了非必要的训练成本。因此,本文作者根据秦简文字图像特征,将原始AlexNet模型的5层卷积层简化为4层卷积层,通过减少深度以降低模型复杂度,并添加1层池化层,设计成4 层卷积层与4 个池化层的顺序连接。在参数调整上,将输入图像设置为224 像素×224像素×1像素,第1个卷积层设计了11像素×11像素的卷积核,在第2卷积层设计了5像素×5像素的卷积核,在第3、4 个卷积层设计了3 像素×3 像素的卷积核来提取局部图像特征,将池化层的池化设置为2 像素×2 像素,并根据获得的神经元数量添加了一层全连接层,最终实现轻量级网络的搭建。图4所示为本文改进过后的AlexNet网络结构。
图4 改进后的AlexNet网络结构Fig.4 Structure of improved AlexNet network
2.2 Inception V3模块融合策略
Inception V3 共有6 种网络结构分支,本文的秦简文字识别模型在卷积层融入其中的2种分支结构,在前2 层卷积层分别融入InceptionA 和InceptionC结构,以分解卷积的形式代替传统卷积进行特征提取,减少网络计算成本,提升模型识别准确率。
结合秦简图像文本区域内文字为单个文字,进而笔划特征较易提取的特点,在InceptionA结构中,本文分别选用5 像素×5 像素、3 像素×3 像素、1像素×1像素,3种不同尺度的卷积核代替初始的11 像素×11 像素的卷积核进行多通道的特征提取,并计算输入值的池化结果,最后将各通道进行融合。其模块的参数量及计算量变化如表1所示。其中,C为特征图的输入通道数,W为特征图的宽度,H为特征图的高度。使用1 个5 像素×5 像素、2 个3 像素×3 像素和3 个1 像素×1 像素的卷积核代替11 像素×1 像素1 的卷积核作为分解卷积,可使参数量和计算量从121 个单元下降至46 个单元。其具体网络结构参数图如表2所示。输出通道数cout的计算公式如下:

表1 IncepionA结构的参数及计算量变化Table 1 Variation of parameters and computation of InceptionA structure

表2 InceptionA网络结构参数Table 2 InceptionA network structure parameters
式中:cin为输入的特征图像素;p为特征图的填充圈数;f×f为每层所使用的卷积核尺寸。
在InceptionC 结构中,保持底层3 个1 像素×1像素卷积核不变的基础上,使用3组1像素×7像素和7 像素×1 像素的卷积核进行分解卷积,并且根据新输入层的特征图数量,将结构内的通道数增加至96,其模块的参数量及计算量变化如表3所示。
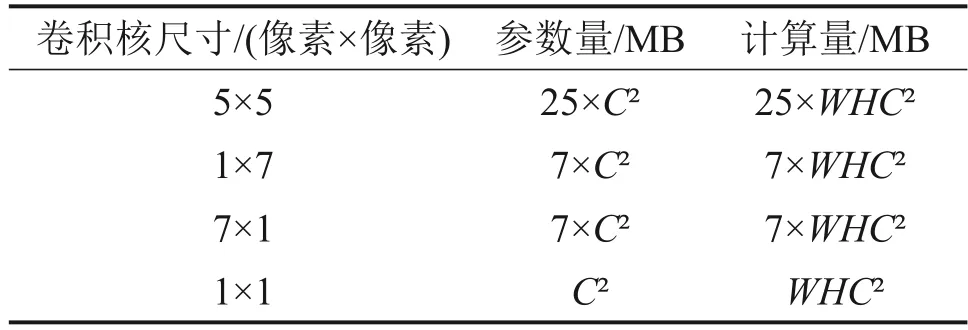
表3 IncepionC结构的参数及计算量变化Table 3 Variation of parameters and computation of InceptionC structure
由表3可知:使用3组1像素×7像素和7像素×1像素的卷积核代替5像素×5像素卷积核进行分解卷积时,可使参数量和计算量从25 个单元下降至21个单元。其具体网络结构参数如表4所示。结果表明采用融合Inception V3 模块策略可以有效降低模型复杂度。

表4 InceptionC网络结构参数Table 4 InceptionC network structure parameters
2.3 秦简文字图像识别算法与模型
秦简文字图像识别算法模型结构与参数调整分别如图5 与表5所示,以AlexNet 模型为基础网络架构,通过在卷积层融合Inception V3 模块实现秦简文字图像识别。具体步骤如下:

表5 秦简文字图像识别网络模型参数Table 5 Qin bamboo slips text image recognition network model parameters

图5 秦简文字图像识别网络结构Fig.5 Structure of Qin bamboo slips text image recognition network
1)对使用的数据集中的秦简文字图像进行预处理操作,包括尺寸归一化、增强去噪、二值化和编码转换等,得到1幅224像素×224像素的单通道二值化图像,以此作为原始图像的输入。
2)对AlexNet 网络模型进行改进,构造4 层卷积层与池化层的顺序连接,并根据获取的神经元数量添加1层全连接层,构建3层全连接层将特征空间更好映射到样本标记空间。
3)在前2层卷积层进行特征提取时,分别融入Inception V3 模块中的InceptionA 与InceptionC 结构,以分解卷积的形式代替传统卷积形式,降低模型权重和提高模型识别精度,以降低识别误差率,并通过池化层降低维度来提升模型容错率。
4)将经过特征提取处理过的特征图像送入全连接层,调用Softmax分类器,计算输入图像属于某字符类别的概率,最终实现秦简文字图像识别。
3 训练与测试
3.1 秦简单字图像数据集的构建
国内外目前尚未有标准统一的秦简文字图像训练与测试数据集,本文参考文献[20]中对于西夏文字单字符样本数据集的设计方案,完成了对秦简文字单字符样本数据集的制作。秦简图像数据主要来源于《里耶秦简壹》《里耶秦简贰》以及《秦简牍合集》,具体制作方法如下。
1)截取图片。将书籍中秦简图片进行扫描制作成电子文档,对扫描图像中的文字区域进行单个截取。
2)按测试要求分类。根据清晰度与测试需求分为模糊图像样本库、低信噪比图像样本库与高信噪比图像样本库。图片分类标准参照信噪比(RSN)参数值设置,RSN<30 dB 归为模糊样本,30 dB≤RSN<50 dB归为低信噪比样本,RSN≥50 dB归为高信噪比样本。最终取得模糊样本图18 057幅,低信噪比样本图34 569幅,高信噪比样本图11 434幅。本文根据测试需求,选取高信噪比样本库中图像进行实验。
3)建立图像-文释对照关系。该对照关系可以准确地检索到图像所对应的书籍出处位置,在图像文件的命名规则上采取了归一化处理,格式统一为:“Unearthed landN_page_Num_num.jpg”,其中Unearthed landN 代表该秦简书籍上所标注的出土地来源,该书籍的页编号用page_Num表示,在该页上所截取的字符编号用num 表示。统一了图像与文释对照关系后,就可以建立每幅文字图像与书籍出处的联系,再按照归一化后的文件命名便可以迅速、准确地找到图像来源。
4)划分测试集和训练集。在整理的高信噪比秦简文字图像中,共有1 131个字符类别,本实验选取其中可释义且样本数量相对较多的50 个类别的字符进行测试,每个类别训练集和测试集的划分比例为4∶1。
3.2 实验环境设置
本文采用自制的秦简文字图像数据集(QBS text dataset)作为秦简文字识别算法的训练和测试数据,其中所有图像均设置为224 像素×224 像素×3 像素,batch size 为100。本次实验中使用的编译语言为Python3.7,网络模型基于Pytorch 深度学习框架建立,并将网络模型加载至GPU 上进行,服务器显卡型号为RTX3070。
对选取的50 个类别的字符样本数量进行归一化处理,将较少的字符样本做数据增广,包括随机翻转、等比例缩放和HSV 变换等,使最终的样本量总数达到149 713。按照4∶1的比例划分出训练集和测试集,训练集有119 770个样本,测试集有29 943个样本。所有图像经过标准化处理,缩放范围为[-1,1],实现字符样本分类识别。
在本文构建的秦简文字图像识别模型中,在4层卷积层中分别选取11像素×11像素、5像素×5像素、3像素×3像素和3像素×3像素的卷积核,最大池化层的池化尺寸设置为2 像素×2 像素,激活函数采用ReLU函数。初始学习率设置为0.01,每隔10 轮训练其学习率调整为原先的0.5,“batch size”设置为100,“epoch”设置为50,并在全连接层使用Dropout层防止出现过拟合现象,对应参数设置为0.5。
实验主要包括2 个部分:其一测试在AlexNet模型当中使用Inception V3 模块与不使用时的仿真结果对比;其二测试改进后的AlexNet模型与其他图像识别算法对于秦简文字图像的识别效果。
3.3 模型损失函数的建立
模型采用softmax 层作为训练的分类器,因此选用softmax 函数的多分类交叉熵作为模型的计算识别损失函数可以保证模型的内聚性,进而判定模型预测值与真实值的偏差程度。原始的交叉熵损失函数公式如下:
式中:L为训练损失;k为批量训练样本大小;n为样本类别数;yi,j为第i个样本在第j类上的真实值;pi,j为第i个样本对第j类的预测值。本文构建的秦简识别模型为多分类模型,因此,交叉熵可以简化为它们的求和平均,公式如下:
式中:Y(i)为第i个样本所属的类别;pi,Y(i)为第i个样本在所属类别上的预测概率。使用softmax 函数将识别模型全连接层的输出结果控制在[0,1]的概率范围内,softmax函数如下:
式中:pi,j为第i个样本对第j类的预测概率;li,j为全连接层对第i个样本在第j类的输出结果。因此,最终本文的秦简文字识别模型所使用的softmax loss整理后公式如下:
式中:li,Y(i)为全连接层对第i个样本在所属类别上的预测结果。
3.4 识别算法评估指标
本文选取4种评估图像识别算法模型优劣的性能指标,分别为准确率(RAccuracy)、精确率(RPrecision)、召回率(RRecall)和F,计算公式如下:
式中:Tp、Fp、FN和TN分别为真实的正值、错误的正值、错误的负值和真实的负值。准确率是评估分类正确样本数量占总样本数量的比例,精确率是评估被模型正确分类到某个类别中的比例,召回率是评估属于某类别的查全比例,F为精确率和召回率的加权调和平均值。为了减小某些异常实验的影响,整个实验结果为50 次图像识别结果的平均值。同时为测试模型的轻量化效果,对模型的平均识别耗时、参数量以及模型大小同时进行测试。
4 结果与分析
4.1 不同Inception模块对网络性能的影响
本文首先对在AlexNet 模型的前2 层卷积层中融合的Inception V3 模块做消融实验测试,前2 层卷积层中感受野分别设置为9 像素×9 像素与5 像素×5 像素,在此条件下分别测试了R1(不含Inception V3 模块)、R2(只融合InceptionA 结构)、R3( 只融合InceptionC 结构)和R4( 同时融合InceptionA与InceptionC结构)的识别准确率与损失值。图6 和图7所示分别为验证集上4 个消融实验的仿真对比。R4实验下秦简文字图像的识别效果如图8所示,实验数据结果如表6所示。

表6 不同Inception V3模块在验证集上测试结果的均值Table 6 Mean values of test results on validation sets for different Inception V3 modules

图6 消融条件下的损失值对比Fig.6 Comparison of loss values at ablation conditions
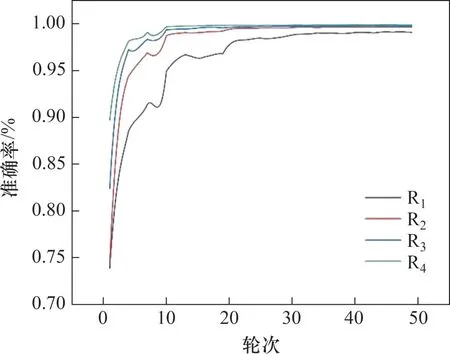
图7 消融条件下的识别准确率对比Fig.7 Comparison of recognition accuracy at ablationconditions

图8 R4模型下的秦简文字图像识别效果Fig.8 Recognition effect of Qin bamboo slips text image based on R4 model
由仿真对比结果可知,在没有融入Inception V3模块的R1模型中,在50 次迭代训练中训练集和测试集的损失值收敛性效果不佳,并且在30 次迭代后准确率才达到较好的效果,测试集中准确率最高时为99.12%;在R2模型中,第20次迭代训练时模型的损失值和准确率已取得较好的收敛性效果,准确率最高时为99.68%,但训练集上最初的损失值比R1模型的略高;R3模型与R2模型的仿真结果相似,均在第20 次迭代训练时便达到较好的收敛效果,但相较于R2模型,其初始的损失值明显降低,准确率最高时为99.80%;在R4模型中,第10次迭代训练时便取得了理想的收敛效果,且最高时的准确率达到了99.89%,相较于前3种对比模型,分别提高了0.77%、0.21%与0.08%,最优时的损失值分别降低了0.026 6、0.011 1与0.004 6。同时在R4模型下进行测试的50 幅秦简文字图像中,有49 幅图像的预测字符类别值与真实值相符。在验证模型的轻量化效果上,R4模型的平均识别耗时为635 ms,较于最长耗时的R1模型提升了24 ms,但受模块数影响,耗时仍比R2与R3模型分别高9 ms 和7 ms,不过识别准确率仍为四者中最优;参数量与模型大小方面,R4模型相较R1模型均有大幅度的下降,但为保证达到最优识别准确率,并未做进一步轻量化处理,因此,相较R2与R3模型,R4模型的权重和复杂度略高。
4.2 本文算法与其他识别算法对比
为了进一步评估本文改进后AlexNet模型的性能,因此选取文献[4-8]、[21-25]共10种经典识别网络模型算法与本文算法进行对比。为了减少某些异常实验的影响,整个实验结果为50 次图像识别结果的平均值。图9所示为各个模型之间损失函数值的对比,表7所示为各个算法之间评估指标的对比结果。
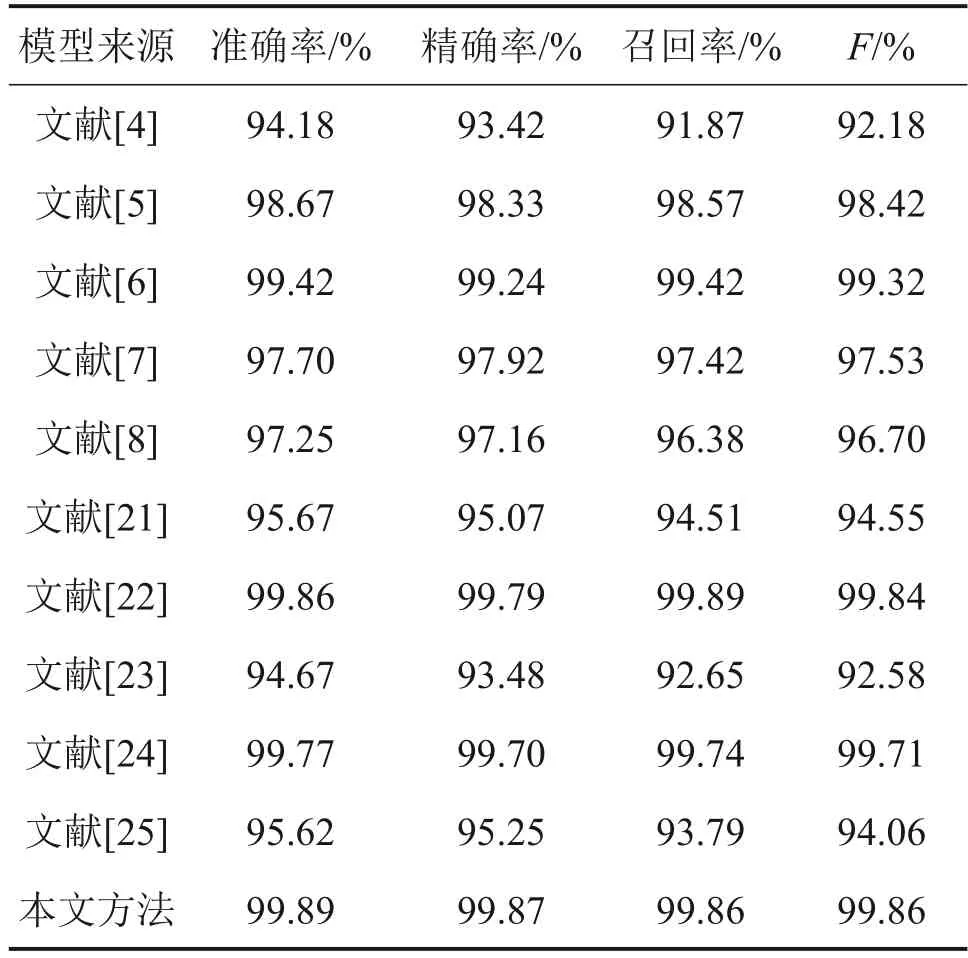
表7 不同模型下文字识别网络评估指标结果对比Table 7 Comparison of evaluation index results of word recognition network under different models

图9 不同模型的损失函数值结果对比Fig.9 Comparison of loss function values of differentmodels
由图9可知:本文方法在损失函数值上达到了10 种对比模型的最优值,相较于次优的文献[5]方法中的损失值降低了0.245 5。由表7可知:在4项识别评估指标对比中,本文方法的3项指标达到了最优。在准确率、精确率和F上相较于次优的文献[23]方法分别提升了0.03%、0.08%和0.02%,在召回率上相较于最优的文献[22]方法相差0.03%。相比于文献[4,21,23,25],本文方法的各项识别指标均有较大提升。综合考虑,本文方法在对高信噪比的秦简文字图像进行识别时相较于其他对比模型可以取得较好的仿真效果。
5 结论
1)自建秦简文字图像数据集(qbs text dataset)。
2)以高信噪比秦简文字图像为研究对象,对AlexNet 网络进行改进,提出了一种基于轻量级AlexNet网络的秦简文字识别算法。
3)模型在具备轻量化特点的同时达到对高信噪比文字图像的高识别准确率,验证了本文方法的有效性。
4)模型对于低信噪比及模糊的秦简文字样本图像识别效果不佳,其泛化能力一般,具体表现在模型在对模糊秦简文字样图像进行特征提取时,获取到的特征图质量较差,因此,最终预测值与真实值的偏差较大。
5)研究相应特征提取方法以进一步优化模型,提高其泛化能力,这将是下一步拟研究的方向与内容。
