面向SD-WAN的OpenFlow分组转发性能模型研究
2023-10-30赵锦元罗文熊兵罗可胡志刚
赵锦元,罗文,熊兵,罗可,胡志刚
(1.长沙师范学院 信息科学与工程学院,湖南 长沙,410199;2.中南大学 计算机学院,湖南 长沙,410083;3.长沙理工大学 计算机与通信工程学院,湖南 长沙,410114)
软件定义网络(software-defined networking,SDN)作为一种新型网络架构,将控制平面与数据平面相分离,并通过OpenFlow 协议灵活定义数据平面的分组转发行为,极大提升了网络的开放性、灵活性和可管控性,成为未来互联网最有前景的发展方向之一[1]。近年来,OpenFlow 的SDN 技术被广泛应用于广域网(WAN)中,有效降低了广域网的部署成本,提高了数据传输效率,改善了应用程序性能[2]。谷歌早在2013年就部署了私有软件定义广域网B4,将其遍布全球的数据中心连接起来。经过不断演进,B4 网络从提供最大限度的内容复制服务发展为电信级可用性服务,且能容纳100倍以上的网络流量,从而满足未来海量数据的发展需求[3]。随着万物互联时代的到来,网络数据流量迅猛增长[4],对广域网的数据传输性能提出了更高的要求。在软件定义广域网(softwaredefined wide-area networks,SD-WAN)中,新流分组到达OpenFlow 交换机后,需发送流安装请求给SDN 控制器,待控制器下发对应的流规则后,再转发该流中的分组,这导致新流分组的转发时延明显较大,增加了网络应用请求的响应时间,进而影响网络应用性能。为保障网络应用性能,有必要在SD-WAN 网络部署前量化评估其性能。在目前已有的性能评估方法中,解析建模能够在短时间内快速且准确地估计系统性能,而不需要进行大量的仿真实验。排队论作为解析建模的主流方法之一,主要关注系统在稳定状态下的平均性能,已广泛应用于网络性能评估。因此,运用排队论评估SD-WAN 网络性能可为其实际部署提供快捷、有效的参考。目前,METTER 等[5-10]对OpenFlow 交换机的分组处理过程进行排队建模,进而估计平均分组转发时延等性能指标,但未区分分组类型,忽略了新流分组触发交换机请求控制器安装流规则的过程。MIAO等[11-16]基于分组优先级建立数据平面优先制排队模型。同时,ALGHADHBAN 等[17-21]对交换机和控制器分别建立排队模型,进而构建OpenFlow 分组转发性能模型,以求解OpenFlow 网络的关键性能参数。然而,上述模型未考虑控制器下发消息的处理过程,忽略了交换机处理不同类型分组的差异性,从而影响了SDN网络性能评估的准确性。
针对软件定义广域网这一典型部署场景,本文通过分析OpenFlow 交换机中的分组处理过程,将到达OpenFlow 交换机的网络分组分为新流分组、旧流分组和消息分组,并考虑OpenFlow 交换机中不同类型分组的处理速率差异性,为OpenFlow交换机的分组处理过程构建M/H3/1排队模型,推导平均逗留时间等关键性能指标的表达式。此外,针对新流分组触发OpenFlow 交换机发送的Packet-in 消息,将其在控制器集群中的处理过程建模为M/M/n 排队模型,在此基础上,建立OpenFlow 分组转发性能模型,并求解平均分组转发时延,为SD-WAN 网络的实际部署提供参考依据。
1 相关工作
目前已有不少研究者利用排队论对SDN 数据平面性能进行评估。METTER 等[5-6]通过建模分析单个流对流表占用率和产生的控制器流量的影响,进而通过调整M/M/∞排队系统扩展到多个流的情形,给出了特定应用参数对消息速率和流表占用率的影响。MONDAL等[7]将OpenFlow交换机分组处理过程建模为C-M/M/1/K 排队模型,分析了OpenFlow 交换机中缓存区的最优数目和最优值。SOOD 等[8]忽略了OpenFlow 交换机与控制器之间的交互,利用M/Geo/1 排队模型分析了OpenFlow交换机的流表、包到达速率、规则数量、规则位置等关键因素。SHEN 等[9]将流表项的生命过程划分为Packet-in消息发送过程、处理过程和流表项服务过程,并分别建模为M/M/1、M/M/1 和M/G/c/c 模型,进而建立流表空间估计模型,在给定路径建立失败的上界概率约束下,预估每个交换机所需流表存储空间的最小值。TAYACHI 等[10]提出了一种具有有限缓冲区的排队模型,假定数据包批到达系统,通过使用类生灭过程获得平均队列大小、阻塞概率和平均逗留时间等性能指标,评估具有多个网络接口卡的虚拟交换机的性能。这些工作重点关注OpenFlow 交换机的分组处理排队模型,但未充分考虑分组的不同类型,导致性能评估结果存在明显偏差。
一些研究者考虑分组优先级,构建了数据平面优先制排队模型,如:MIAO等[11]提出一种SDN数据平面的抢占式分组调度方案,以提高整体公平性,减少丢包率,并建立一个解析模型,量化评估该调度方案的性能,以准确定位SDN 架构的性能瓶颈。为减少失配数据包的平均逗留时间,REN 等[12-13]提出一种SDN 数据平面的优先制服务排队模型,运用大偏差原则LDP 推导排队长度和排队时延的概率分布,以评估SDN 数据平面输入自相似网络流量的服务质量QoS。SINGH 等[14]利用类生灭过程分别对带内部缓冲区的SDN 软件和硬件交换机建立优先制排队模型,求解系统吞吐量和排队长度等关键性能参数,并分析内部缓冲区的最优值。罗可等[15]针对软件定义数据中心网络场景,利用多优先级M/G/1 排队模型刻画OpenFlow 交换机的分组处理过程。RAHOUTI等[16]将SDN 网络建模成带反馈机制的双队列排队系统,将分组划分成多个优先级队列,以提供差异化的QoS 服务。上述模型区分考虑网络分组的不同优先级,但假设OpenFlow 交换机对所有分组的处理时间相同,从而影响了SDN 网络性能评估的准确性。
同时,还有研究人员研究了OpenFlow 网络架构下的分组转发排队模型。ALGHADHBAN 等[17]考虑主动/被动流安装模式对匹配概率的影响,提出一个新流安装过程的时延模型,将数据平面设备和南向通道建模为M/M/1,并采用M/G/1建模控制平面设备,推导评估了系统容量和阻塞概率。熊兵等[18]建立了一个OpenFlow 网络分组转发优先制排队模型,将OpenFlow 交换机的分组转发过程和控制器的Packet-in 消息处理过程分别建模为非抢占优先制的M/M/n/m 和M/M/1/m 排队系统,进而求出平均分组转发时延及其累积分布函数CDF。针对软件定义广域网,ZHAO等[19]分别对OpenFlow交换机的分组转发过程和控制器集群的Packet-in消息处理过程构建M/G/1 和M/M/n 排队系统,并进一步建立了控制器集群部署的优化模型,以此获得最优的控制器数量。上述模型同样忽略了不同分组类型的处理速率差异性。为此,SHANG等[20]以及ABBOU等[21]分别将交换机的分组转发过程和控制器的Packet-in 消息处理过程建模成M/H2/1 排队模型和M/M/1 排队模型。然而,上述工作均忽略了控制器下发的消息分组在OpenFlow 交换机中的处理过程。
2 软件定义广域网
传统网络将控制逻辑和数据转发功能集成在独立且封闭的设备实体中,导致网络设备结构复杂、功能繁多、升级困难,很难直接部署新技术和新协议,阻碍了网络的创新与演进,越来越难以满足未来互联网的发展需求。随着云计算、物联网、边缘计算等新型网络模式的不断涌现,网络流量特性不断改变,需要网络能主动适应业务流量的变化。同时,网络电视、在线直播和短视频共享等数据密集型应用层出不穷,所产生的庞大数据量给广域网的传输性能和服务质量带来了严峻的挑战。SDN 的引入使广域网具有传输独立性、智能路径控制、自动灵活配置等优势,为解决广域网面临的性能问题提供了新思路,促进了软件定义广域网快速兴起。
软件定义广域网的典型部署场景如图1所示。在控制平面中,SDN 控制器集群提供全局网络的拓扑管理、路径计算和策略控制等功能,通过北向接口为应用提供统一的编程接口,从而使得网络用户能够灵活制定并部署各种网络策略,实现资源管理、业务编排、数据可视化、运行情况监测等服务。同时,控制器集群通过以OpenFlow 为代表的南向接口协议对网络交换设备进行集中管理,建立全局网络视图,并制定分组转发策略,以实现网络流量的灵活调度。依据SDN 控制器下发的流规则集合快速转发分组,使数据平面得到了充分简化。OpenFlow 交换机则通过高速链路将移动通信网、企业网、校园网等进行互联,从而实现各种终端、数据中心、服务器及智能设备间网络分组转发处理。

图1 SD-WAN典型部署场景Fig.1 A typical SD-WAN deployment scenario
在上述SD-WAN 场景中,当OpenFlow 交换机收到1个网络分组时,先提取其关键字段,然后查找OpenFlow 流表。若查找成功,则依据命中的流表项中的动作集进行处理;若查找失败,则该分组被判定属于新流。OpenFlow 交换机将数据包信息封装成Packet-in 消息,并发送给SDN 控制器,新流分组则被存入缓冲区等待处理。SDN 控制器根据全局网络视图生成流规则,然后,以Flowmod 或Packet-out 消息下发给流路径上的所有交换机。对于Flow-mod消息,OpenFlow交换机将其中的流规则更新到流表,进而据此处理该流的所有分组,而无需控制器参与。对于Packet-out 消息,OpenFlow交换机依据其中的流规则直接处理分组,而不更新流表。
3 OpenFlow交换机排队建模
3.1 排队模型
在软件定义广域网中,大量网络分组汇聚到OpenFlow 交换机,形成队列等待处理。根据不同OpenFlow 交换机的处理方式,可分为新流分组、旧流分组和消息分组。对于新流分组,流表查找将失败,需将其存入缓冲区,并将其信息封装成Packet-in消息发送给控制器,待对应的流规则下发后再转发处理分组。对于旧流分组,流表查找将成功匹配1条流表项,进而按其中的动作集进行转发处理。对于消息分组,首先从其中提取流规则,然后将其更新到流表中,进而转发处理缓冲区中属于该流的分组。不同类型分组在OpenFlow 交换机中的处理流程如图2所示。

图2 OpenFlow交换机中不同类型分组的处理流程Fig.2 The processing of different types of packets in OpenFlow switches
OpenFlow 交换机对每类分组的处理过程相互独立,处理时间无记忆性,因而,每类分组的处理时间可视为服从负指数分布。上述3类分组在交换机中的处理过程存在差异性,处理速率各不相同,因此,OpenFlow 交换机的分组处理时间可视为服从3阶超指数分布。在广域网中,由于数据分组来源广,流量汇聚程度高,分组在传输过程中的高度复用破坏了其时间相关性,使得到达交换机的分组趋于相互独立,故交换机的分组到达过程可视为服从泊松分布[22]。基于上述排队特性分析,可将OpenFlow 交换机的分组处理过程建模为M/H3/1排队模型。
3.2 模型求解
基于排队论求解OpenFlow交换机的M/H3/1排队模型,其过程为:1)分组到达过程服从泊松分布,且达到速率为λ;2)交换机按先到达先处理原则处理每个分组,且到达过程与处理过程相互独立;3)处理时间服从3 阶超指数分布,新流分组、旧流分组和消息分组的处理速率分别为μ1、μ2、μ3,对应的概率分别为q1、q2、q3,且满足q1+q2+q3=1。
为求解上述排队模型,首先定义OpenFlow 交换机的状态(a,b)。其中,a表示交换机当前正在处理的分组类型,a为0表示没有分组正在处理;a为1、2、3分别表示正在处理的是新流分组、旧流分组、消息分组,因此,a∈{0,1,2,3};b表示交换机内当前正在处理和等待处理的分组总数,若b=0,则表明交换机内没有分组,a=0,即该模型的初始状态。此时,若到达1 个分组,则b=1。因为交换机空闲,可对该分组直接进行处理。根据分组类型不同,新的状态可能有3 种。设第i(i=1,2,3)种类型分组的概率为qi,则状态从(0,0)转移到(i,0)的速率为qiλ。当b≠0 时,后续到达的分组都需要进入队列等待处理,于是,状态从(i,b)转移到(i,b+1)的速率为λ。
此外,当交换机处于处理状态时,若处理完成,则状态会发生转移。当b≥2时,除了正在接受处理的分组外,还有分组等待处理,而即将处理的分组是第l(l=1,2,3)种类型的概率为ql,于是,正在处理的分组服务完毕后,状态从(i,b)转移到(l,b-1)的速率为qlμi。当b=1 时,OpenFlow 交换机只有正在处理的一个分组,故状态从(i,1)转移到(0,0)的速率为μi。图3所示为M/H3/1 排队模型的状态转移图。

图3 M/H3/1排队模型的状态转移图Fig.3 The state transition diagram of M/H3/1 queueing model
用pi(m)表示OpenFlow交换机内有m个分组而正在处理的分组是第i类的概率,其中,m=1,2,…;i=1,2,3。p(0)表示OpenFlow 交换机内没有分组的概率。根据上述状态转移图,可得下列稳态方程:
下面利用概率母函数求解式(1)。用p(m)表示OpenFlow 交换机内有m个分组的概率,则p(m)=p1(m)+p2(m)+p3(m)。定义概率p(m)的母函数P(x)为
同时,定义概率pi(m)的母函数Pi(x)为
则P(x)可以表示为

对式(1)中第一个等式和第二个等式两边分别同时乘以qix和x2,其余等式两边同时乘以xm+1,可得
将式(5)中所有等式两边分别相加,再将式(3)代入,可得
为求解Pi(x),首先求出P1(x)、P2(x)和P3(x)的表达式。对于式(6),分别取i=1,2,3,可得以下三元一次方程组:
令
Ai(x)=λx+μix-λx2;i=1,2,3
于是,求解式(7)中方程组得
由式(6)可知
将P1(x)、P2(x)和P3(x)的解代入式(9),可得Pi(x)的表达式为
然后,利用洛必达法则可求出Pi(1):
对于式(4),令x=1,据式(11)可得P(1)的解为
由于P(1)=1,可得p(0)为
对Pi(x)求导,并利用洛必达法则可解得P′i(1)为
进而可得P′(1)为
将p(0)的解代入式(14),可计算出平均分组队列长度Ls为
利用Little 公式,可进一步求出平均分组逗留时间W(s)为
令ρi=λ/μi,则W(s)可表示为
由于交换机只有1个处理窗口,所以,正在被处理的分组个数为0 或1,对应的概率分别为p(0)和1-p(0)。于是,可计算出平均处理队列长度Ls为
进一步可求得平均分组等待时间Wq为
特别地,当μ1=μ2=μ3=μ时,令ρ=λ/μ,则平均分组逗留时间W(s)可表示为
此时,M/H3/1模型简化为M/M/1模型。
4 OpenFlow分组转发性能模型
在软件定义广域网中,大量OpenFlow 交换机将发送Packet-in 消息到控制平面,形成队列等待处理。为及时处理大量的Packet-in 消息,控制平面通常采用控制器集群部署方式,以增强其处理能力[23]。当Packet-in 消息到达控制器集群时,若存在空闲的控制器,则直接进行处理;否则,按到达顺序加入Packet-in 消息队列等待被处理。对于Packet-in 消息,控制器根据全局网络视图生成流规则,然后以Flow-mod 或Packet-out 消息下发给流路径上的所有交换机。结合上述OpenFlow 交换机排队模型,可建立OpenFlow 网络分组转发性能模型,如图4所示。

图4 OpenFlow分组转发性能模型Fig.4 OpenFlow-based packet forwarding performance model
网络测量结果表明,在广域网中,由于流量汇聚程度高,网络流之间趋于相互独立,流到达过程往往服从泊松分布[22]。对于到达的每条新流,OpenFlow 交换机会发送1 条Packet-in 消息给控制平面。根据上述OpenFlow 交换机排队模型,新流分组的处理时间服从负指数分布。根据泊松流的性质可知,每台交换机发送的Packet-in 消息仍为泊松流。假设所有交换机发送的Packet-in 消息相互独立,根据泊松流的可加性可知,控制器集群的Packet-in 消息到达过程仍服从泊松分布。假设集群中所有控制器的Packet-in消息处理速率相同,处理时间服从负指数分布,且处理过程彼此独立,则可将控制器集群的Packet-in 消息处理过程建模为M/M/n排队模型。

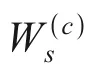

由于平均旧流分组转发时延Wk(old)即为分组在交换机中的平均逗留时间Wk(s),且新流分组概率为qk1,故第k台交换机的平均分组转发时延Wk为
5 实验
5.1 模型对比
为有效评估本文所提出的分组转发性能模型,采用OpenFlow网络仿真工具Mininet 2.1.0,模拟1个简单的SD-WAN拓扑结构,包含3台控制器组成的集群和20台OpenFlow交换机。其中,交换机采用Open vSwitch 2.5.0,控制器采用OpenDaylight Beryllium,OpenFlow协议版本设为1.3。在本实验中,交换机的分组处理速率为30×103个/s,控制器的Packet-in消息处理速率为20×103个/s。每台交换机同时模拟产生不同速率的网络分组,其中新流分组占比q1为4%[24],测得交换机的平均分组逗留时间如图5所示。

图5 交换机中不同分组到达速率下各模型的平均分组逗留时间对比Fig.5 Comparison of average packet sojourn time of various models with different packet arrival rates in switches
由于OpenFlow 交换机接收到新流分组后,请求控制器集群安装流规则,集群将以Packet-out/Flow-mod 消息的形式下发给流路径上的所有交换机。此外,交换机还将收到控制器下发的其他类型消息,因此,交换机收到的消息分组多于新流分组。设消息分组概率q3和新流分组概率q1的关系为q3=cq1+q0,其中,c为权重,q0为常量。在本实验中,c=1.2,q0=0.01,q1=0.04,则q3=0.058,进而得到旧流分组概率q2=1-q1-q3=0.902。新流分组、旧流分组和消息分组的处理速率分别为:μ1=40×103个/s,μ2=30×103个/s,μ3=20×103个/s。将上述参数代入本文所提出的M/H3/1 模型以及现有的M/M/1 模型[17]和Mk/M/1 模型[25],进而估算出交换机的平均分组逗留时间,如图5所示。
从图5可以看出:由本文模型得到的估计时延比现有模型得到的估计时延更接近于测量时延。Mk/M/1 模型假设分组成批到达,平均每个分组的估计排队时延更大,导致其估计时延与测量时延相差较大。在分组到达速率较小时,M/M/1 模型可较准确地估计交换机的分组处理时间。但随着分组到达速率不断增加,数量最少的新流分组处理速率快,排队时延短,而数量较多的旧流分组和消息分组处理速率慢,排队时延越来越长,导致其估计时延偏差越来越大。相比而言,M/H3/1模型考虑了不同类型分组的处理速率差异性,因而,其估计时延更接近于测量时延。此外,当分组到达速率接近于交换机处理速率时,交换机将会逐步丢弃分组,故测量时延不会无限增大。
实验将交换机的分组到达速率设为20×103个/s,将接入集群的交换机数量设为3台,然后,不断增加新流分组概率q1,测得对应的平均分组逗留时间,如图6所示。同时,对于本文所提出的M/H3/1模型,消息分组概率q3和新流分组概率q1的关系保持不变。将上述参数代入本文所提出的M/H3/1模型和现有M/M/1 模型和Mk/M/1 模型,估算出交换机的平均分组逗留时间,如图6所示。

图6 交换机中不同新流分组概率下各模型的平均分组逗留时间对比Fig.6 Comparison of average packet sojourn time of various models with different probabilities of packets in new flows of switches
从图6可以看出:与现有模型相比,本文所提出的模型的估计时延更接近于测量时延;随着新流分组概率增加,测量时延逐渐增大。这是由于当新流分组概率越大时,控制器下发的消息分组数量也越多,且消息分组的数量比新流分组的数量略多,而处理速率更慢,进而导致交换机的平均分组逗留时间增加。本文所提出的模型由于考虑了不同类型分组的处理速率存在差异性,故估计时延也会随之增大,始终接近测量时延。相反,M/M/1和Mk/M/1 模型由于未考虑上述差异性,其估计时延始终保持不变,与测量时延有明显偏差。
5.2 数值分析
采用数值分析方法研究不同参数对交换机的平均分组逗留时间的影响。在实验中,新流分组概率、旧流分组概率和消息分组概率仍分别取值为:q1=0.040,q2=0.902,q3=0.058。这3 种类型分组的处理速率分别默认为:μ1=40×103个/s,μ2=30×103个/s,μ3=20×103个/s,随后调整其中1种处理速率,而其他2 种处理速率不变。根据上述参数设置,可得交换机的平均分组逗留时间与分组到达速率的关系,如图7所示。

图7 交换机平均分组逗留时间与分组到达速率的关系Fig.7 Relationship between the average packet sojourn time and packet arrival rates in switches
从图7可以看出:旧流分组处理速率μ2对交换机的平均分组逗留时间影响最大,消息分组处理速率μ3的影响次之,新流分组处理速率μ1的影响最小,这是因为新流分组概率很小,其分组处理速率的变化对平均分组逗留时间的影响极小,可忽略不计。消息分组概率比新流分组概率略大,其处理速率最慢,所以,提高其处理速率会明显减小平均分组逗留时间,但随着其处理速率持续提高,平均分组逗留时间的下降幅度越来越小。相比而言,旧流分组概率极大,因此,其处理速率提高会显著降低交换机的平均分组逗留时间。
分组处理速率仍为:μ1=40×103个/s,μ2=30×103个/s,μ3=20×103个/s。调整其中1 种处理速率,而其他2种处理速率保持不变。将分组到达速率设为20×103个/s,不断增加新流分组概率q1,且消息分组概率q3和新流分组概率q1的关系保持不变。根据上述参数设置,可得交换机的平均分组逗留时间与新流分组概率的关系,如图8所示。
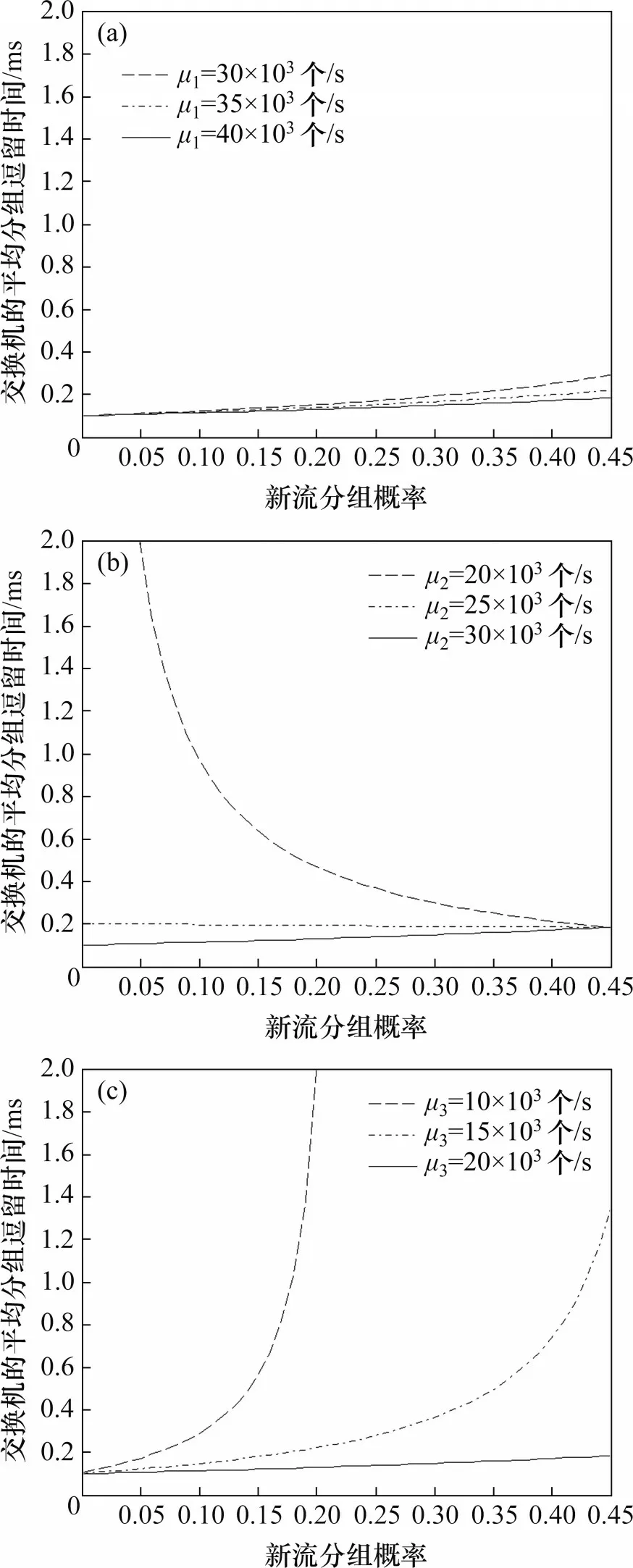
图8 交换机平均分组逗留时间与新流分组概率的关系Fig.8 Relationship between average packet sojourn time and the probability of packets in new flows of switches
从图8可以看出:随着新流分组概率增加,新流分组处理速率μ1对平均分组逗留时间的影响较小,消息分组处理速率μ3的影响急剧增大,而旧流分组处理速率μ2的影响逐渐减小。对于正常网络流量,新流分组概率很小,新流分组处理速率的改变基本上不会影响平均分组逗留时间,而消息分组概率略大于新流分组概率,且消息分组处理速率较慢,因此,提高其处理速率将会明显减少平均分组逗留时间。此时,旧流分组概率很大,其处理速率的变化将对平均分组逗留时间产生显著影响。对于异常网络流量,新流分组概率逐渐变大,消息分组概率随之增大,而旧流分组概率随之变小,此时,新流分组处理速率对平均逗留时间产生的影响较小,消息分组处理速率则产生显著影响,而旧流分组处理速率的影响变小。
将每台交换机的分组到达速率设为20×103个/s,3 种类型分组的处理速率分别为:μ1=40×103个/s,μ2=30×103个/s,μ3=20×103个/s,每个控制器的消息处理速率为20×103个/s。根据上述参数设置,并设置不同的控制器数量,可得平均分组转发时延与交换机数量的关系,如图9所示。

图9 平均分组转发时延与交换机数量的关系Fig.9 Relationship between average packet forwarding delay and the number of switches
从图9可以看出:随着交换机数量增加,平均分组转发时延不断增大。这是因为当交换机数量增加时,发送给控制器集群的Packet-in 消息速率增大,Packet-in消息的平均逗留时间增大,最终导致平均分组转发时延增大。当交换机数量较少时,发送给控制器集群的Packet-in 消息速率较小,Packet-in消息的排队时延小,因此,平均分组转发时延基本保持稳定。当交换机数量增多时,控制器集群的Packet-in 消息到达速率不断增大。当Packet-in消息到达速率接近控制器集群的处理速率时,Packet-in消息的排队时延迅速增大,导致平均分组转发时延急剧增大,此时,需要增加控制器数量以提高集群的处理能力,有效控制平均分组转发时延。
将每台交换机的处理速率设为:μ1=40×103个/s,μ2=30×103个/s,μ3=20×103个/s。共有50 台交换机接入控制器集群,每个控制器的处理速率为20×103个/s。根据上述参数设置,并设置不同的控制器数量,可得交换机平均分组转发时延与分组到达速率的关系,如图10所示。
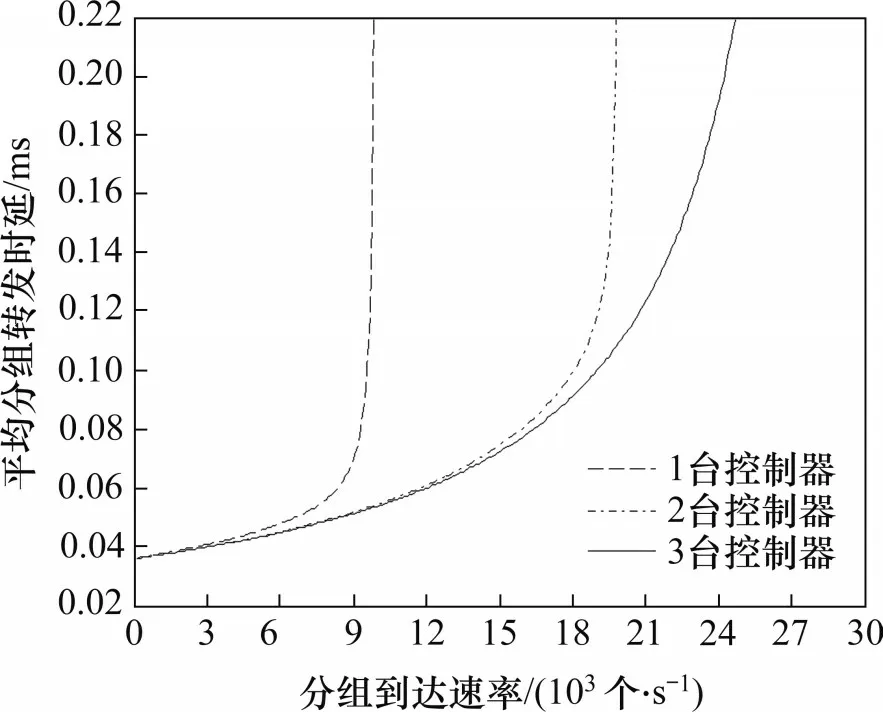
图10 平均分组转发时延与分组到达速率的关系Fig.10 Relationship between average packet forwarding delay and packet arrival rates
从图10 可以看出:随着分组到达速率增加,平均分组转发时延逐渐增大。这是因为当分组到达速率增大时,交换机发送给控制器集群的Packet-in消息速率增大,此时,分组在交换机中的排队时延和Packet-in 消息在控制器集群中的排队时延均会增大,导致平均分组转发时延快速增大。当Packet-in 消息到达速率接近控制器集群的处理速率时,平均分组转发时延急剧增大,有必要增加控制器数量以控制平均分组转发时延。此外,控制器数量越多,平均分组转发时延随分组到达速率增加而增大的速度越缓慢。这是因为控制器集群的Packet-in 消息处理速率明显超出其到达速率,Packet-in消息在控制器集群的排队时延不会太大,而分组在交换机中的排队时延逐步成为平均分组转发时延的主要部分。
6 结论
1)针对软件定义广域网这一典型部署场景,通过分析OpenFlow 交换机中的分组处理过程,将到达OpenFlow 交换机的网络分组分为新流分组、旧流分组和消息分组。考虑到OpenFlow 交换机中不同类型分组的处理速率的差异性,为OpenFlow交换机的分组处理过程构建M/H3/1 排队模型,并推导出平均逗留时间等关键性能指标的表达式。在此基础上,结合控制器集群的Packet-in 消息排队模型,建立OpenFlow 分组转发性能模型,并推导出平均分组转发时延。
2)通过实验验证了本文所提出的模型的分组转发时延比现有模型更接近测量时延。随着新流分组概率增加,测量时延逐渐增大。本文所提出的模型由于考虑了不同类型分组的处理速率的差异性,其估计时延也会随之增大,始终接近测量时延。同时,采用数值分析方法对比各种因素对平均分组转发时延的影响。平均分组转发时延主要取决于旧流分组处理速率和新流分组概率,同时受消息分组处理速率和控制器数量的影响。这可为SD-WAN的实际部署提供参考依据。
