融合稀疏注意力和时间查询的视频目标检测
2023-10-30梅思怡刘彦隆
梅思怡,刘彦隆
太原理工大学 信息与计算机学院,山西 晋中 030600
视频目标检测是为了解决每一个视频帧中出现的目标如何进行定位和识别的问题[1]。随着智能视频监控[2]、人脸识别门禁系统、自动驾驶[3]、机器人视觉导航等更贴近人们日常生活以及符合现实需求的视频数据的增多,视频目标检测的研究具有更大的现实意义与应用价值。视频是由一系列具有时间连续性和内容相关性的图像组成,相比于静止图像,视频具有高冗余度的特性,包含了大量的时空局部信息。传统的静止图像目标检测方法直接应用于视频目标检测,往往达不到很好的效果,这是因为视频文件容易存在抖动、散焦等问题,会导致单帧图片出现重影、模糊。另一方面,直接用传统方法对视频进行逐帧检测,还会大大影响检测速度,不能满足实时性的要求。因此,如何利用好视频提供的时间上下文信息来提升检测准确度和检测速率等,成为了构建视频目标检测网络的关键因素。
视频目标检测方法主要包括三类:基于运动信息的方法、基于检测和跟踪的方法和基于注意力的方法。基于运动信息的方法主要是通过利用目标运动的光流信息来进行特征聚合。Zhu等人[4]利用光流信息将目标帧的特征聚合到参考帧,以此来获得参考帧的特征图。尉婉青等人[5]提出一种双光流网络指导的视频目标检测模型,利用两种不同的光流网络估计光流场进行多帧图像特征融合。随着跟踪算法的飞速发展,更多的研究者将跟踪算法应用于目标检测。最具有代表性的就是Kang等人[6]提出一种目标检测和跟踪的多阶段检测框架,核心思想是用跟踪算法学习视频序列中目标变化的时间信息,用检测算法学习单帧图像中目标的空间信息,之后将二者有机结合起来提升视频目标检测网络的性能。随着注意力机制在NLP任务上出色的表现,近几年也逐渐被应用到图像相关领域。ViT[7]首先将Transformer[8]体系结构引入图像分类,并取得了很好的效果。Carion等人[9]提出了第一个基于transformer的端到端的目标检测算法DETR,无需锚点和非极大抑制(NMS)等进行候选框的预测和选择,而是直接将目标检测视为集合预测问题。后续提出的Deformable DETR[10]通过引入可形变卷积块,提升了网络的收敛速度,并且一定程度上提升了小目标的检测能力。为了能够满足实时性需求,Zhu[11]、Yao[12]、Jiang[13]等人通过设计一个实时性的特征聚合网络,在满足检测速度的同时,网络检测精度也有所提高。VSTAM[14]通过结合不同位置的参考帧实现目标帧的特征聚合,还引入一种基于聚集的外部存储器更新策略以有效地保存视频长期特征信息。TransVOD[15]是第一个将transformer 应用于视频目标检测任务并建立在DETR 上的网络,提出一种基于transformer 的聚合模块来汇总每个帧的空间对象查询和特征,实现了端到端的视频目标检测,但是基于DETR的框架设计导致网络整体收敛速度慢。基于此,PTSEFormer[16]随后提出了一种具有时空特征聚合设计的端到端的框架,通过渐进地聚合时间和空间特征,更好地利用了上下文信息,同时基于全局的自注意力机制存在注意力分散的问题,导致网络不能很好地区分目标和背景,检测效率低。
针对以上问题,本文提出一种高效的、端到端的网络以提升视频目标检测效率和前景目标边缘检测精度:(1)引入稀疏注意力机制,减少注意分散和复杂背景干扰,提升边缘检测精度。(2)引入时间融合查询模块,逐帧链接时间上下文参考帧的空间特征,强化目标帧特征。(3)改进参考帧的选取,从近距离和远距离稀疏地选取参考帧,补充运动模糊和减少冗余,实现检测前特征细化。(4)调整网络结构,优化检测模型,实现端到端的视频目标检测。
1 算法原理与网络结构
1.1 远近距离参考帧稀疏采样
视频目标检测网络的输入是一个给定的视频帧,目的是通过聚合附近时刻的n个参考帧Rt,在目标帧(关键帧)Ft处检测出对象的类别和边界框。通常的网络通过连续地选取t时刻附近的帧作为参考帧[15],然而检测对象在附近连续时间可能都是运动模糊的,因此会存在附近帧中检测对象变化不大、运动物体检测效果不好的问题,此时更远处的帧往往包含更准确的信息。此外,目标在附近时间的运动是接近的还会导致特征冗余的问题。为了获取更广泛的信息,本文对参考帧的选取做了改进,相对于连续时间的标准密集采样,本文采用稀疏选取的方式,同时对近距离时间和远距离时间的帧进行采样。
通常来说,越靠近目标帧时间的视频帧有用的特征信息就越多,而距离越远的特征相关性越小,因此距离目标帧时间越近选取的参考帧应当越密集。对于给定的参考帧数量n,定义与目标帧的时间差的集合Tsparse如下:Tsparse={2i|0 ≤i<n},定义参考帧Rt={Ft-i|i∈Tsparse},可以有效地收集附近和远处的帧作为参考帧。两种参考帧采样方式分别如图1(a)和(b)所示,其中深蓝色部分为目标帧Ft,也就是当前需要检测的帧;浅蓝色部分为选取的参考帧Rt;灰白色部分为未被选中的视频帧。
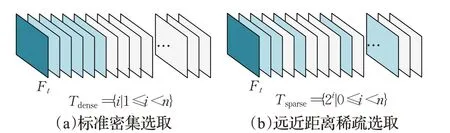
图1 两种参考帧选取方式Fig.1 Two reference frame selection methods
采用远近距离稀疏选取参考帧的方法,在附近时间帧是短时间内的密集选取,可以有效地获得待检测目标在上下文中的特征;而远距离时间帧是稀疏选取,可以在很大程度上补充运动模糊,同时去除冗余。与密集采样相比,远近距离稀疏的参考帧采样方式可以同时获得附近距离和长远距离的时间特征,实现在相同数量参考帧的前提下获得更广泛的信息,同时实现检测前特征细化。
1.2 DETR网络
DETR网络将目标检测看作是集合预测问题,是一种基于注意力机制的、端到端的检测网络,整体结构可分为编码器和解码器两部分。通过CNN获得目标帧和参考帧的图像特征,将它们加上位置编码后展开输入到编码器中。解码器输出每个对象查询特征的空间输出,通过FFN 检测头进行将其转换成每个目标的类别分数和检测框的定位。利用匈牙利算法,在输出的类别分数和地面真实值之间进行一对一匹配,匹配成功则输出最终的检测结果。DETR 的网络结构如图2 所示,其中编码器可叠加N层,解码器可叠加M层。

图2 DETR网络结构Fig.2 DETR network structure
1.3 整体网络框架
本文的方法整体框架如图3所示,主要包括四个部分,分别是特征提取网络、编码器、解码器和检测网络。其中,特征提取网络即CNN卷积神经骨干网络,输出目标帧Ft和参考帧Rt的图像特征,将其展开成一维向量后嵌入位置信息,输入到编码器中。编码器和解码器引入稀疏注意力机制。为了提高计算效率和网络收敛的速度,采用Defomable DETR 作为基础检测网络,编码器的输出通过可形变encoder 得到增强后的目标特征Et,解码器的输出通过TFQ 模块获得带有时间上下文信息的时间融合输出查询。最后,将Et和输入到基础检测网络的可形变decoder,通过一个FFN 获得最终的检测结果。
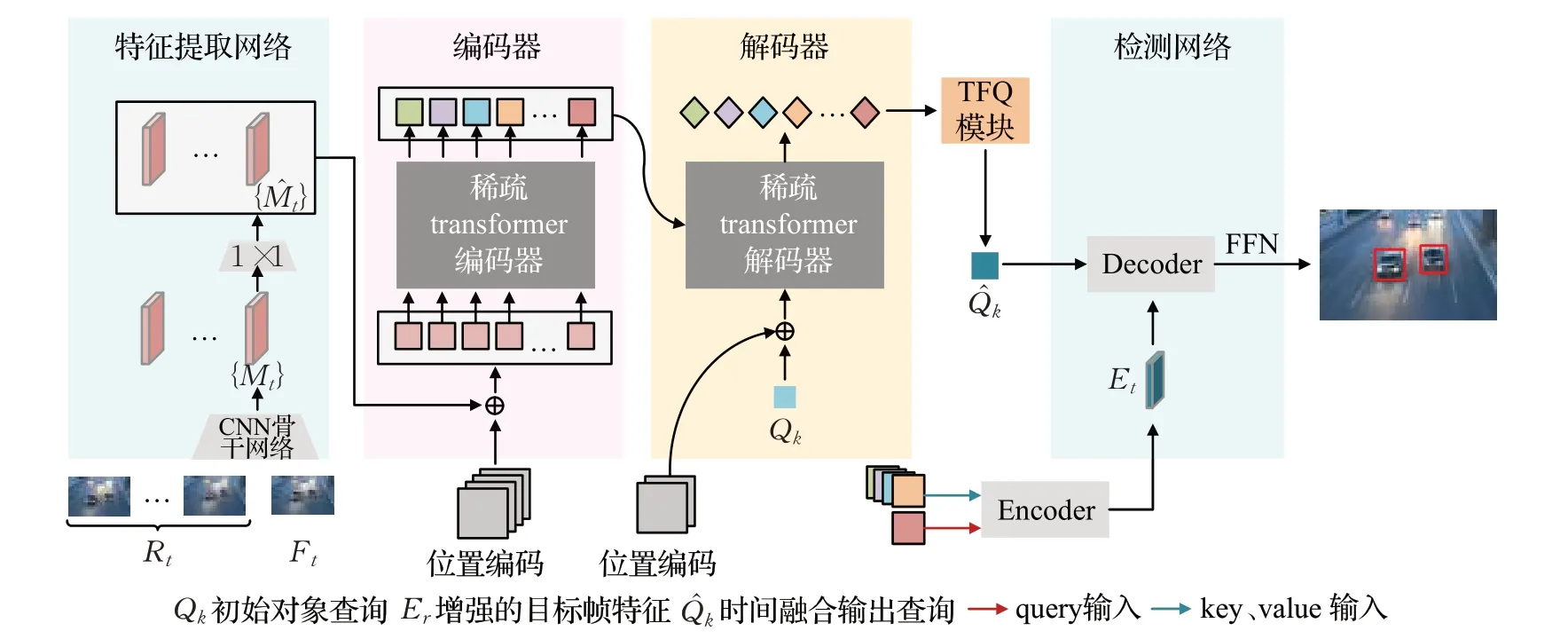
图3 整体网络结构图Fig.3 Overall network structure
1.4 稀疏多头注意力机制
DETR中基于transformer的编码器和解码器主要利用多头自注意力(multi-head self-attention,MSA)和多头交叉注意力(multi-head cross-attention,MCA)来学习特征的依赖性并收集输入序列的信息,是一种全局自注意力机制,考虑了检测区域中所有元素。然而这种全局自注意力机制对检测区域中最相关的特征信息缺乏关注,容易被背景分散注意力,导致背景和目标边缘区分模糊,检测效果较差。另一方面,目标可能在某个时间段内的多个帧中出现在相似的位置,存在大量特征冗余,导致网络整体收敛速度慢。为了解决这些问题,本文受Zhao 等人[17]的启发,引入稀疏多头注意力(spares multi-head attention,SMA)替换网络原本的注意力模块。
在传统的MSA和MCA中,通过输入特征的所有像素值来计算目标特征的每个像素值,导致前景的边缘区域模糊,同时需要消耗大量计算。而在SMA中,目标特征的每个像素值仅由与其最相似的K个值确定,通过在朴素注意的基础之上利用稀疏注意掩码操作M(·) 实现稀疏注意,公式如公式(3)所示:
其中,K、V、Q分别是键、值和查询,dk是值和键的嵌入维度,l是输入序列的长度。稀疏掩码M∈[0,1]l×l的定义如公式(4)所示:
图4所示为两种注意力计算方式的对比,其中图(a)为朴素缩放点积注意力的计算过程,图(b)为稀疏缩放点积注意力的计算过程。在传统的注意力计算中,通过给定的query∈RHW×C,key∈RC×H′W′,value∈RH′W′×C计算查询query和键key之间的相似性,然后将相似性矩阵直接进行归一化,最终与value相乘得到计算结果。而在稀疏注意中,通过增加掩码机制屏蔽与查询query相关性不高的部分,主要流程如下:首先计算查询query和键key之间所有元素的相似性。然后,与传统注意力计算不同,用softmax 函数仅对相似性矩阵每行中的K个最大元素进行归一化,将其他元素置为0,得到带有掩码机制的相似性矩阵。最后与value相乘得到最终的计算结果。
图5 所示是在稀疏缩放点积注意中归一化相似性矩阵的行向量的示例。从图中结果可以看出,上方的朴素缩放点积注意力直接将向量进行归一化,可能会放大原本相对较小的相似性权重,也就是相似度不高的部分。而下方的稀疏缩放点积注意力通过掩码机制将相似度低的位置的权重替换为0,实现让注意力集中关注在相似度高的位置。

图5 归一化相似性矩阵行向量的对比示例Fig.5 Comparative example of normalized similarity matrix row vector
1.5 时间融合查询TFQ模块
在视频目标检测任务中,如何利用好视频帧的时空信息是非常关键的,一般主要通过聚合参考帧的时空信息实现待检测目标的特征增强。在原始DETR中,对象查询在训练过程中会自动学习整个单帧图像数据集的统计特征,这表明空间对象查询在时间上下文的帧之间没有差异,即不包含时间上下文信息。为了获取当前帧中的对象与时间上下文参考帧中的对象之间的相互作用,提出一种时间融合查询模块TFQ(time fusion query),如图6所示。TFQ以主网络解码器的输出作为输入,对所有参考帧的空间输出查询进行增强,并输出当前目标帧带有时空信息的空间输出查询。

图6 时间融合查询模块Fig.6 Time fusion query module
目标帧和参考帧在主网络解码器的输出具有丰富的时空信息,将它们作为模块的输入,进行特征融合。特征融合包括自注意力和交叉注意力的计算。通过逐帧聚合的方式,用上一个参考帧特征增强后的结果对下一帧进行特征强化,以此类推,最后实现不同时间上下文的特征融合。通过链接所有参考帧的空间对象查询,从而学习视频帧的时空信息,最终得到带有时间上下文的目标帧时间融合输出查询。
2 实验结果与分析
2.1 实验设置
2.1.1 数据集
本文主要采用ImageNet VID[18]数据集和UA-DETRAC[19]车辆检测数据集进行实验。图7为数据集的示例,包括视频中物体的遮挡、摄像头不平稳导致的抖动和动物运动导致的模糊。

图7 数据集示例Fig.7 Dataset example
ImageNet VID数据集是用于视频目标检测的大规模基准,主要有30个类别,包括3 862个训练视频和555个测试视频。本文按照通常的方法,使用ImageNet VID 和DET[18]数据集的组合来训练模型,采用IoU 在阈值0.5处的均值平均精度(mAP)作为评价指标。
UA-DETRAC是现实世界交通场景的大规模基准,该数据集包含60个训练视频(约82 085张图片)和40个测试视频(约56 167 张图片),视频以每秒25 帧(fps)的速度录制,分辨率为960×540像素。该数据集包括四种车辆的分类和四种天气的分类,采用IoU 在阈值0.7 处的平均精度(AP)作为评价指标。
2.1.2 实验参数配置
本实验所用设备CPU型号为Platinum 8255C,显卡为RTX 2080 Ti,运行内存为11 GB,深度学习框架为pytorch1.11.0。
设置训练的batch-size 大小为2,对于每个目标帧,在时间窗口大小为n=4 的训练和检测阶段设置参考帧选择。对于所有输入图像都使用和MEGA[20]一样的数据增强,包括随机水平翻转等,调整输入图像的大小使最短的边至少600 像素,最长的边最多1 000 像素。在稀疏注意力中,和通常的方法一样,将多头注意力的头数m设置为8,编码器的层数和解码器的层数都设置为4。设置初始学习率为2×10-4,epoch为15,当使用ResNet-50[21]和ResNet-101[21]作为骨干网络时,学习率在第5 和第6个时期下降。此外,还采用Swin Transformer[22]作为基础检测网络进行对比实验。
2.2 对比实验结果分析
2.2.1 与基础网络比较
为检验本文算法的有效性,将本文方法与近几年发布的视频目标检测算法分别在ImageNet VID 和UA-DETRAC数据集上进行对比,所对比算法的评价指标均来自于各算法的原文献。
在ImageNet VID数据集上基于ResNet-50和ResNet-101的实验结果如表1 和表2 所示。将主流的视频目标检测方法根据其网络结构分为两类,分别是两阶段方法和单阶段方法,以往的端到端的方法也是主要建立在两阶段检测器上,而近年来端到端的方法主要建立在一阶段检测器上。随着近几年注意力机制在视觉任务中的广泛使用,将Deformable DETR作为基础检测器的方法的效果要明显高于以往基于卷积网络的方法。基于此,近期端到端视频目标算法如TransVOD 和PTSEFormer等,在视频目标检测任务上效果有了很大的提升。本文的方法在ResNet-50 的基础上可以获得89.6%的准确率,相比于目前效果最好的端到端的视频目标检测算法PTSEFormer 精度提升2.2 个百分点,而在更强大的ResNet-101基础之上检测准确率为90.7%,相比PTSEFormer提升2.6个百分点。
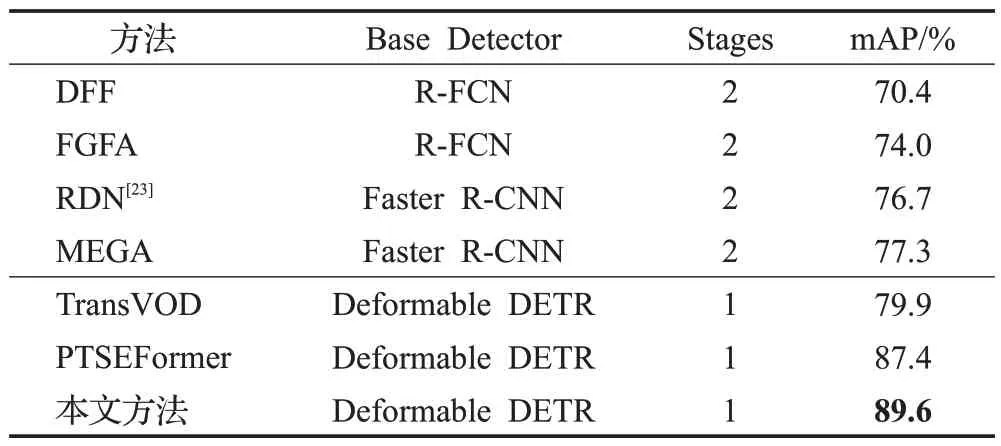
表1 ImageNet VID数据集测试结果比较(主干网络为ResNet-50)Table 1 Comparison of ImageNet VID dataset test results(with ResNet-50 backbone)

表2 ImageNet VID数据集测试结果比较(主干网络为ResNet-101)Table 2 Comparison of ImageNet VID dataset test results(with ResNet-101 backbone)
在UA-DETRA 数据集上的对比结果如表3 所示。此数据集上的YOLOv3-SPP、MSVD_SPP 和SpotNet 等都是静止图像检测方法,主要通过引入空间注意机制来提高视频检测结果的准确性,FFAVOD-SpotNet 则主要通过利用时间信息来提高检测准确性。通过实验结果可以看出,本文方法在ResNet-101 的基础上可以实现90.90%的准确率,相比于表现最好的FFAVOD-SpotNet网络检测精度提升了2.8个百分点。
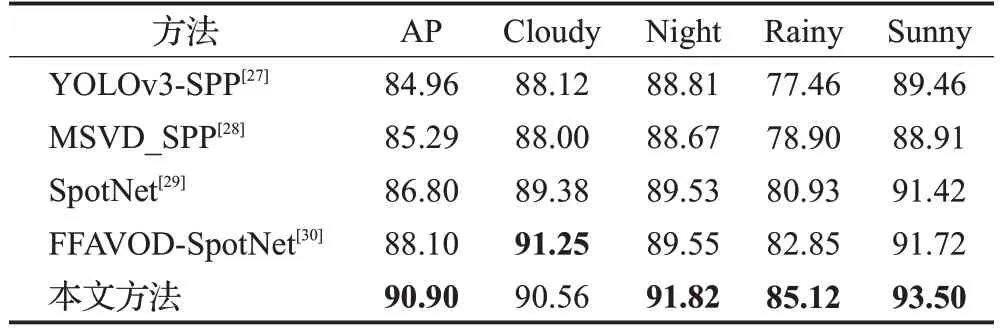
表3 UA-DETRAC数据集测试结果比较Table 3 Comparison of UA-DETRAC dataset test results 单位:%
2.2.2 与其他先进方法比较
将本文的方法与最近几种先进的方法以及带有后处理的方法进行比较,结果如表4所示。比较的网络结构包括单阶段和带有后处理模块的两阶段方法,事实证明,后处理在许多视频目标检测方法中都有很好效果,使用最广泛的后处理方法是Seq-NMS,通过非极大抑制操作可以将检测的准确率提升1~2个百分点。此外,从表中可以看出,传统两阶段网络中表现较好的算法通常都是基于ResNet-101,随着基础网络的改进,以Faster R-CNN 为基础检测网络的模型效果得到进一步提升。为了避免复杂的后处理,近几年更多的方法是一阶段网络,随着transformer 在各领域的广泛应用,更多的模型建立在其基础之上,比如TransVOD、PTSEFormer等,以ResNet-101为基准的模型准确率分别可以达到81.9%和88.1%。而在相同条件下,基于Swin Transformer 的方法能使得检测精度进一步提升,比如最近表现更好的TransVOD++和VSTAM,在以Swin Transformer 作为骨干的模型上检测准确率分别可以达到90.0%和91.1%。从实验结果可以看出,本文所提出的端到端的方法也能实现和上述方法相当的效果,通过引入稀疏注意力机制和时间融合查询模块,以Swin Transformer和Deformable DETR 为基准的模型检测准确率可达92.3%,比相同条件下表现最好的VSTAM 网络提升了1.2 个百分点,证明了所提模型相比于其他模型的优势。
2.3 分解实验及分析
2.3.1 消融实验及分析
考虑到检测速度,主要采用ResNet-50 作为骨干网络进行消融研究。为了验证稀疏多头注意力机制MSA和时间融合查询模块TFQ 的有效性,在ImageNet VID和UA-DETRAC这两个数据集上共进行了4组实验,通过在Deformable DETR网络的基础上逐步添加MSA和TFQ模块进行验证。其中模型1是初始检测网络;模型2是在模型1 的基础之上增加了稀疏注意力模块;模型3是在模型2的基础之上增加时间融合查询模块,也就是本文的算法;模型4 是在模型1 的基础之上只添加时间融合查询模块。消融实验结果如表5所示。
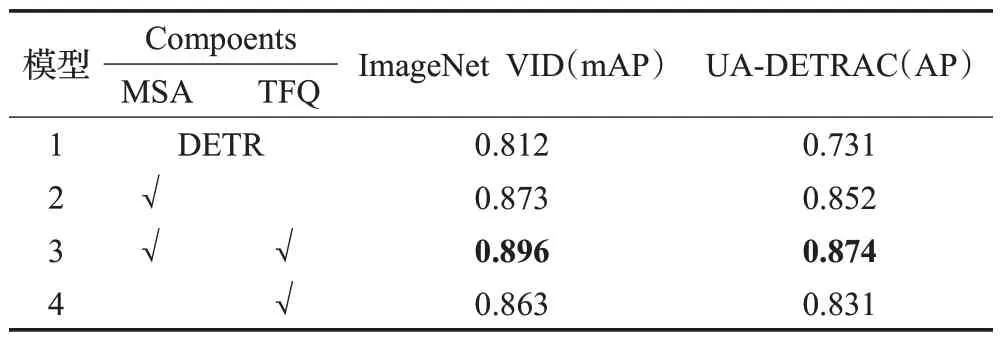
表5 消融实验结果Table 5 Results of ablation experiment
结果显示,相比与基础网络,模型2 增加MSA模块后,检测精度在ImageNet VID 和UA-DETRAC 两个数据集上分别有0.061和0.121的提升,这表明通过引入稀疏注意力机制,可以有效减少背景假阳性和假阴性干扰,降低边缘检测模糊,实现更稳定的检测。模型4 通过添加TFQ模块之后,在两个数据集上分别实现了0.051和0.1 的提升,说明通过融合不同时间上下文视频帧的特征可以更好地利用视频的时间信息,提高检测准确度。模型3 中集成了上述两个模块,也就是本文方法,最终结果相比模型1来说,在两个数据集上分别提升了0.084和0.143,进一步验证了这两个模块对于提升视频目标检测准确度的有效性。
2.3.2 特征聚合方法对比
为了验证远近距离选取参考帧方式的有效性,分别运用了三种不同的方法在UA-DETRAC 数据集上进行对比实验。每一种方法都设置效果最好的参数,只是对特征聚合参考帧的选取方式进行修改,通过使用不同的参考帧选取方法进行横向对比,结果如表6所示。从表中可以看出,在相同网络中,更换参考帧选取方式后,检测精度都有一定的提升,表明远距离时间的特征仍和目标有一定的相关性。

表6 不同方法选取参考帧对比Table 6 Comparison of different methods for selecting reference frames
3 结束语
本文提出了一种基于DETR 的端到端的视频目标检测方法,通过引入稀疏注意力机制和融合不同时间参考帧的空间查询来提高检测性能。该方法首先将稀疏选取的固定数量的参考帧输入到特征提取网络,然后将图片特征输入到带有稀疏注意力的编码、解码模块,获得参考帧的融合特征和融合空间查询输出,将两者输入到解码器中获得最终的检测结果。在ImageNet VID和UA-DETRAC两个数据集上的实验表明,通过引入稀疏注意力机制可以稀疏的聚合特征,有效减少背景干扰,同时节约计算和内存成本。利用浅层编码器融合时间上下文信息可以获得更多的时间信息,实现目标帧的特征增强,提高网络对于劣化图像的鲁棒性。在未来的工作中,需要进一步优化特征融合模块,通过融合不同时间视频帧之间的空间信息使得网络能够更加稳定地随着时间推移继续检测同一类中的同一目标。此外,还需要通过优化网络结构实现轻量化,在保证检测精度的同时提升检测速度,使得模型能够进行实时的视频目标检测,更加贴近现实功能需求。
