牙齿X线片的图像分割方法综述
2023-10-30韩致远姜玺军刘瑞军
韩致远,姜玺军,王 晨,刘瑞军
1.北京工商大学 计算机学院,北京 100048
2.食品安全大数据技术北京市重点实验室,北京 100048
3.北京大学口腔医院 儿童口腔科,北京 100081
在口腔医学中,牙齿是人体中最坚硬、最强健的组织,早期主要用于法医口腔学进行人体鉴定。目前在口腔医学中,通常利用X线片图像检查牙齿,牙龈、下颚和牙齿骨骼结构的情况等。牙齿X线片主要分为两类,一种其拍摄位置在口腔内,另一种是在患者口腔外获取[1]。在这两类中,有三种最常用于牙齿检查:口腔外全景X线片、口腔内咬合翼X线片和根尖周X线片。这些牙齿X线片通常由医生进行检查,主观判断因素和培训代价都比较高,此外,也可能受到许多因素的影响,比如疲劳,或者其他因素分散注意力,导致结果产生偏差[2]。近些年,为了减轻医生的负担,提高疾病诊断效率,对于牙齿X线片图像的分析已经成为研究的重点和难点[3]。
在口腔图像分析领域,牙齿图像分割是疾病检测和识别的关键技术[4],也是图像处理中最困难的任务之一[5]。图像分割是指将图像分割成若干个具有独特性质的组成区域并提取出感兴趣区域(region of interest,ROI),牙齿诊断领域的图像分割(牙齿分割)是指从相应的牙齿X 线片中分割出牙齿或将其感兴趣区域提取出来[6],最终转化为可供临床诊断的直接或间接的参考依据。牙齿区域的图像分割用于识别部分颌骨、牙齿或其中一部分。但医学图像不同于自然图像那样具有良好清晰度,通常存在噪声、低对比度和不均匀曝光[7]的问题。同时由于人体组织密度的相似性、存在永久性伪影(如牙齿填充物和牙种植体)以及临时伪影(如正畸支架、阻生牙、牙齿拥挤、牙齿间距和缺牙)等,感兴趣区域之间缺乏清晰的界限[8],使得分割过程更具挑战性[9]。现有的一些传统牙齿图像分割方法[10]专注于提升图像的对比度,从而提升分割的准确性,但是其主要是依靠人工提取特征,因此缺乏对图像内部特征的提取和利用[11],往往达不到想要的效果。
近年来,随着计算机视觉领域逐渐将重点转向深度学习(deep learning,DL),深度卷积网络也被广泛应用于图像分割。医学成像领域构建的深度网络模型,也为牙齿图像分割注入了新的源头活水。与需要设置复杂规则的传统手工特征牙齿分割方法相比,数据驱动的深度学习方法具有更强的建模能力和泛化能力,并且对解决多样化细分问题极为有效[12]。根据分割任务的不同,在牙齿图像分割方面主要分为语义分割和实例分割,语义分割会为图像中的每个像素分配一个类别,但是同一类别之间的牙齿不会区分。而实例分割,可以对特定的牙齿进行分类。它们都能够更多地利用浅层信息[13],使得牙齿图像分割得更加精细。
在现有的其他牙齿图像分割综述中,Silva等人[14]和Jader等人[15]只对传统的牙齿分割方法进行了阐述,但是并未对近年来流行的深度学习方法进行总结,Kumar等人[16]侧重于对不同类型的牙齿图像分割方法进行综述,Majanga 等人[17]主要对龋齿分割方法进行了总结,侧重于龋齿检测技术。与上述方法相比,本文主要是从图像特征提取角度出发,将牙齿分割方法分为了基于手工特征提取和利用深度学习特征提取两大类,具体组织方式如下:
1 基于手工特征的牙齿分割方法
经典的牙齿分割方法,一般都是根据人为选定的特征将图像划分为合适大小的区域。到目前为止,牙齿成像的绝大多数研究都依赖于无监督的像素分割。常见的用于牙齿分割的方法有:阈值法、区域法、边缘法、基于机器学习的方法等,下面将对这些方法展开介绍。
1.1 基于阈值的牙齿分割方法
基于阈值的分割算法是通过给定合适的灰度阈值,将图像中各个像素的灰度值和阈值作比较,值超过阈值的像素被放置到该区域中,而值低于阈值的像素则被放置到相邻区域中,最终将每个像素划分到合适的类别中,可以看成一种函数操作,如公式(1)所示:
p(x,y)表示点(x,y)的局部性质,经阈值化处理后的图像g(x,y)定义如公式(2)所示:
标记为1的像素对应于对象,标记为0的像素对应于背景。
常见的阈值分割方法有:最大类间方差法(Otsu)、基于最大熵的阈值分割法以及迭代阈值分割法[18-19]。
在某些情况下,属于感兴趣区域的像素灰度与背景区域的像素灰度有本质上的区别。在这种情况下,通常使用全局阈值分割将感兴趣的对象从背景中分离出来。在文献[20-24]中,分别利用全局阈值分割,完成了牙齿生物识别、龋齿检测等牙齿分割任务,并将其应用于口腔临床实践中。虽然取得了良好的效果,但存在对比度低、噪声等并发症问题。Lin 等人[25]基于Otsu 阈值方法以及边界跟踪法,分割出了根尖周X线片中的每颗牙齿。之后,在文献[26]中又提出了一种混合特征融合的全局阈值分割方法,并通过实验证明,该方法可以有效地定位根尖周X 线片图像中的牙槽骨丢失区域。虽然取得了良好的效果,但仍存在曝光不均匀、对比度低等问题。
但是,基于全局阈值分割的方法通常在图像对比度和光照变化较大时效果不够好,导致许多像素不能准确地划分为正确的区域,于是提出了基于图像像素局部统计的可变阈值方法[27-31],解决了牙齿中像素强度大于背景中像素强度的问题,分割示例图如图1所示。Lin等人[32]利用迭代阈值和积分投影方法分割出牙齿的感兴趣区域。为了进一步提高分割效率,在文献[33]中提出了一种基于局部奇异性的根尖周X线片牙齿分割方法,使用Otsu阈值和连通分量标记进行牙齿识别。Indraswari等人[34]提出了利用抽取-无方向滤波器组阈值(decimationfree directional filter bank thresholding,DDFBT)和多级自适应阈值(multistage adaptive thresholding,MAT)进行牙齿分割的方法。首先使用DDFBT生成垂直和水平方向图像,然后对方向图像进行图像增强以去除图像噪声等,最后使用MAT 进行局部阈值分割。之后,Setianingrum 等人[35]的研究中也证实了,图像增强能够提高阈值分割效果。
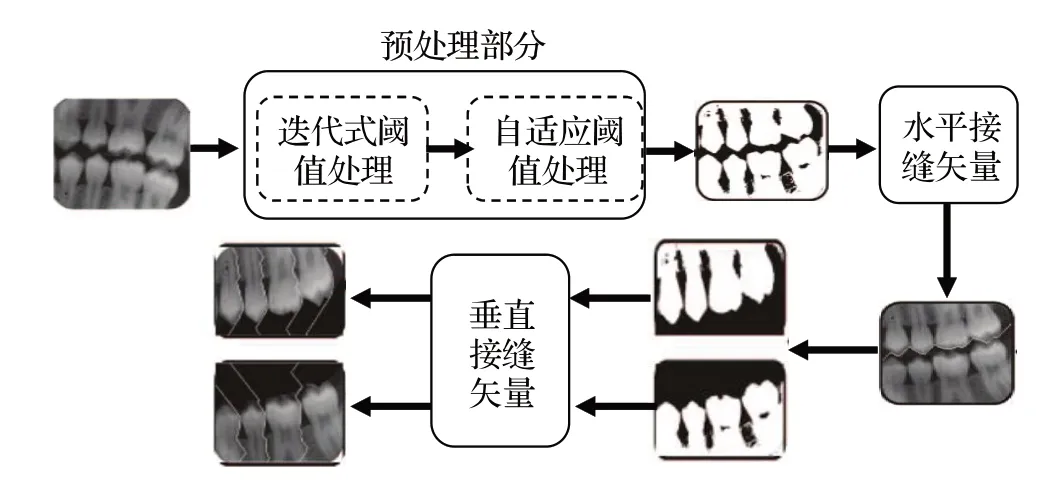
图1 基于可变阈值方法的牙齿分割示例图Fig.1 Sample graph of tooth segmentation based on variable threshold method
为了完成在全景X线片中定位阻生牙、识别未治疗的根管和检测断裂牙齿等分割任务。Mahdi等人[36]提出了基于多阈值的图像分割方法,并将量子粒子群优化算法(quantum particle swarm optimization,QPSO)技术应用于多级图像阈值分割的方法中,提高了分割的稳定性,并缩短了处理时间。但是该方法属于入门技术,针对牙齿问题的检测与识别还并未成熟。
为了解决牙齿图像中的囊肿分割时,存在无法正确划分区域的问题,Devi等人[37]提出了一种基于模糊区域阈值的牙片囊肿分割方法,利用每个像素的模糊隶属函数和邻近像素的局部空间信息,实现混合多区域分割。
由于龋齿分割时,经常发生因牙齿错位而产生牙齿拥挤难以区分的问题,2022 年,Kumari 等人[38]提出了改进融合模糊C均值(fuzzyCmeans,FCM)聚类和二元阈值的龋齿分割方法,并利用Coyote算法优化分割方法的部分参数,提高了分割性能。
除了将阈值分割方法用于二维牙齿图像中,Wang等人[39]还提出基于最优阈值分割三维CBCT(cone-beam computed tomography)牙齿图像的自动分割方法,利用最优阈值进行二值化,提取出切片图像中的牙髓腔区域,但是该方法更侧重于单颗牙齿的牙髓腔区域分割。
虽然基于阈值的分割算法简单常用,但是忽略了空间特征,使得分割性能对噪声和阈值选择极为敏感。并且对于实际图像中目标或背景的灰度分度不均匀,目标和背景之间存在重叠灰度的情况,分割结果往往会出现欠分割或过分割的现象。
1.2 基于区域的牙齿分割方法
在牙齿图像分割中,基于区域分割方法的目标是根据像素强度水平的不连续性将图像划分为多个区域,主要包括区域生长法、区域分裂合并法[40]两种类型[41]。区域生长算法如图2所示,首先在图像中选一个种子区域,再进行区域生长,可以看出种子区域在碰到像素灰度值差值过大时停止生长。区域分裂合并法无需预先指定种子点,而是按某种一致性准则分裂或者合并区域。
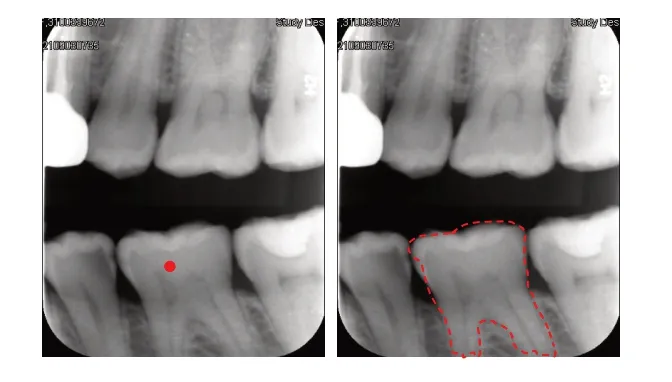
图2 区域分割算法Fig.2 Region segmentation algorithm
在文献[42-43]中,借助区域生长算法和边缘检测寻找牙齿边缘区域,并借助阈值算法或者聚类算法对相似区域进行分组或分类,从而完成牙齿的分割。并且Lurie等人[43]通过分割牙齿的全景X线片图像,能够帮助牙医检测骨质减少和骨质疏松。
由于图像的噪声与骨骼、牙齿的灰度强度相似,不管是对于二维牙齿X线片还是三维CBCT图像,牙齿分割一直都是一项挑战性问题。Indraswari等人[44]提出了一种基于三维区域合并和直方图阈值分割的CBCT 牙齿图像自动分割方法。利用区域合并算法识别出与骨骼具有相似强度的牙齿,并合并牙齿区域使牙齿内部灰度强度分布更均匀。然后利用图像特征进行直方图阈值化,对灰度图像进行二值化,从而分割出牙齿区域。
虽然基于区域的牙齿分割方法,只需要提供少量的种子生长点,就可以为具有清晰边界的原始图像提供良好的分割结果。但是这种方法往往计算开销大,对于噪声敏感,分割结果很大程度上取决于是否选择了合适的区域生长点和相似性度量。并且由于基于阈值和基于区域牙齿分割方法仅仅使用了图像强度或纹理信息的特征,其语义分割的性能受到较大的限制。
1.3 基于边缘的牙齿分割方法
基于边缘的分割方法通过检测不连续的颜色或像素强度来搜索图像中的点和边缘。几种常见的边缘检测算法包括:Roberts、Sobel[45]、Prewitt、Canny 等,Razali等人[46]对几种边缘算法进行了比较,实验结果表明,与Canny算法相比,Sobel算法能够覆盖更多的区域。在文献[47-48]中分别通过在边缘算法中引入遗传算法、统计度量等,实现了牙齿轮廓分割。
还有一种基于边缘的分割方法称为活动轮廓模型[49],主要通过描绘物体外部线进行分割。目标是使能量函数最小化,以便将表示最小能量值的区域对应于最接近物体周长的轮廓线。另一种基于边界的方法是活动轮廓模型的一种变体,称为水平集方法LSM[50(]level set method),通过几何运算进行分割,用来检测拓扑变化的轮廓[51-52]。但是该方法无法满足部分牙齿X线片图像的分割,所以文献[53]提出了混合模型LSM 方法,通过在LSM函数中加入先验形状和灰度约束项对图像进行分割,在文献[54]中,基于该方法实现了牙根的提取。Ji 等人[55]通过加入三个能量项,改进该混合LSM 方法,实现前牙分割。之后,Gan等人[56]采用齿形传播策略,自动初始化水平集函数,完成牙齿轮廓分割。
由于水平集模型对有噪声和边界不明显图像的处理性能较差,Zhong 等人[57]提出了区域一致性约束项来度量边界两侧的区域一致性,该项在一定范围内定义了图像的边界,从而增加了水平集模型的稳定性。Kumar等人[58],考虑到检测牙齿异常情况对于牙齿疾病治疗是十分重要的,他们提出了将模糊聚类与水平集活动轮廓相结合的方法,提取牙齿X 线片图像中的修复部分,利用模糊聚类分割特定区域以识别图像中存在的异常类型。然后,采用水平集活动轮廓方法从牙齿中分割出修复区域。
针对牙根的信噪比较低、牙根与牙槽之间的边缘模糊以及强度不均匀,牙根分割不易,出现假边界的问题。Wang等人[59]提出了一种新的变分水平集混合主动轮廓模型,通过引入LLIF(local likelihood image fitting)能量项,克服边缘模糊和强度不均匀问题;采用具有自适应权重的形状先验能量项,区分水平集函数内部和外部的轮廓演化约束,提高了曲线拓扑变化能力;通过引入RD(reaction-diffusion)能量项,有效地规范了水平集的演化。为了解决势阱函数有时出现“停止或过快演化”的问题,石沁祎等人[60],通过改进势阱函数,并与LSM结合,实现了牙齿及牙槽骨的分割。
虽然基于边缘的牙齿分割方法具有定位准确和速度快的优点,但是它不能保证边缘的连续性和闭合性,经常存在大量的虚线和假边。并且对噪声敏感,所以针对一些高噪声的图像很难实现准确分割。并且当牙齿和背景之间的边界不清楚时,基于边缘的牙齿分割方法可能效果不佳。
1.4 基于机器学习的牙齿分割方法
机器学习(machine learning,ML),通常被称为“人工智能”(artificial intelligence,AI)的一个分支领域,已被证明是一种非常强大的技术,可用于计算机辅助诊断任务。过去几年,随着ML 的迅速发展,在医学领域的应用越来越广泛,在口腔医学领域,ML和人工智能方法展示出了它们卓越的贡献,例如计算机辅助诊断和治疗、X线片图像解释、感染区域检测等,能够帮助医生更准确、更及时地诊断和预测疾病风险。
1.4.1 基于人工神经网络的牙齿分割方法
随着神经网络(neural networks,NN)的提出,由于是受人体中的神经元工作方式的启发,也被称为人工神经网络(artificial neural network,ANN),之后也被用于了临床口腔。如图3 所示,ANN 由节点和几个层组成,每一层都具有激活函数的节点,与下一层完全连接,每个连接均具有权重,各层的输出通过反馈成为下一层的输入。
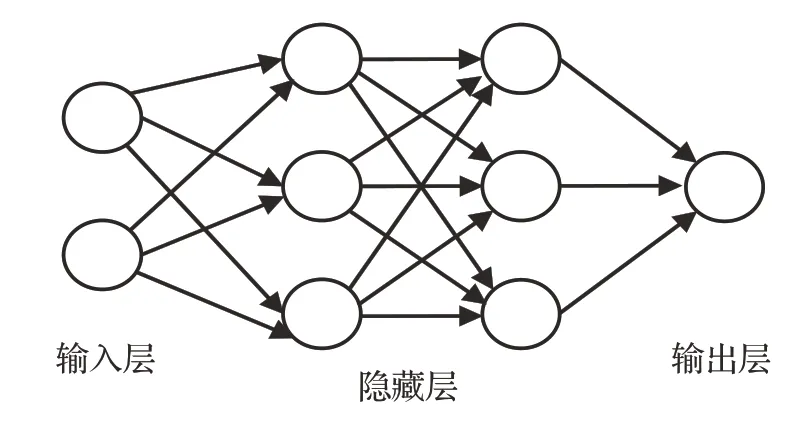
图3 人工神经网络Fig.3 Artificial neural network
Fernandez等人[61]基于人工神经网络,提出了一种牙齿分割系统,并实现了上颌腭视图照片中的牙齿、腭和牙齿间分割。Maghsoudi等人[62]提出了一种基于人工神经网络的智能系统,通过提取特征用于口腔疾病的诊断。
为了实现龋齿区域的精准定位,解决牙齿基本信息容易丢失等问题,Javid 等人[63]利用ANN 和迁移学习方法,提取到了更深层次的牙齿特征和牙齿信息,并识别和标记光学图像中的龋齿区域。虽然借助迁移学习解决了样本数据较少的问题,但是并未针对该任务对迁移学习进行专门的调整。Leo等人[64]考虑到龋齿可以根据其位置和严重程度分为不同的类型,提出将ANN 与深度神经网络(deep neural network,DNN)结合的方法,利用DNN 堆叠稀疏自动编码器进行无监督和监督微调,利用ANN逻辑回归对龋齿受影响程度进行分类。
Deleat-Besson 等人[65]提出了一种自动根管和牙冠分割算法,包括RootCanalSeg阶段和DentalModelSeg阶段。结合了图像处理和机器学习方法,从数据集中自动分割下颌和上颌的根管,为正畸、牙髓修复和牙科修复程序提供牙齿长轴信息。然后从牙冠部分分割牙齿,提供每颗牙齿的临床信息。
人工神经网络可以通过评估和测试数据集来确定系统特征,然后验证从输入数据中获得的特征。使用测试数据集,可以验证算法的精度,并提取有价值的特征,以制定一个强大的训练模型,但是人工神经网络的特征仍需要人工挑选。
1.4.2 基于支持向量机的牙齿分割方法
支持向量机SVM(support vector machine)是一种基于监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM通常通过核函数将输入向量映射到更高维度的特征空间中,从而像线性分类一样高效地执行非线性分类。该模型的显著特点是,在原始空间中不可线性分离的类可以在高维特征空间中线性分离。
目前,支持向量机因其具有完美的归纳和分类能力,已被广泛应用于解决各个领域的疑难问题。在牙齿分割领域,支持向量机主要用于牙齿自动识别系统(automated dental identification system,ADIS),分类和识别测试牙齿图像的正常或异常。ADIS可以将提取出的牙齿图像特征与参考图像进行比较,然后再将参考图像提供给支持向量机进行训练[8]。
Pushparaj 等人[66]基于SVM,提出一种磨牙分类方法,首先基于积分投影和样条函数分离出牙齿,然后利用SVM 将牙齿分类为磨牙或前磨牙,但是当分割牙齿的直线部位时,该方法的拟合效果不够好。为了准确定位牙齿缺陷,Prakash等人[67]开发了一套牙齿缺陷分析系统,利用SVM对图像进行异常决策,但是需要手动提取特征。为了减小牙齿图像中的金属伪影对牙齿分割的影响,Mortaheb 等人[68]基于最小二乘SVM 和均值移位算法进行牙齿分割。Albahbah 等人[69]还提出了一种检测龋齿方法,利用梯度直方图作为特征提取器,从图像中提取特征,将SVM作分类器,使系统能够识别龋齿和非龋齿牙齿。
但是SVM属于二分类的算法,有一定的局限性,而在牙齿分割中,一般要解决多分类问题,而SVM对于多分类问题解决效果并不理想,但是对于简单的二分类问题,可以得到最优分类结果。
1.4.3 基于聚类的牙齿分割方法
聚类是一种根据相似性对数据进行自动分组的动态自适应无监督学习[70]方法,相似度的选择取决于待解决的问题。一般情况下,将待检测的组数作为算法的初始参数,比较常用的方法是K-Means 和模糊C均值FCM[71]。
为了提高聚类算法的性能,Son 等人[72]采用模糊C均值聚类和半监督熵正则化模糊聚类结合的方法,分割咬合翼片和根尖周X 线片图像。但是该方法在聚类过程中不使用牙齿特征,并且图像分割任务的参数值都是由经验得出,需要实验验证以获得最佳结果。
由于牙齿咬合面结构特殊,细菌容易定居并形成咬合面菌斑,这种斑块可能会导致龋齿,可被视为龋齿风险评估的重要标志。在文献[73]中,Koutsouri等人提出利用K-Means算法对RGB牙齿图像中的龋齿区域和咬合面菌斑进行分割。在每个分割区域中,提取形状和纹理特征,最后根据医学规则消除错误区域。但是这种方法不适用于背景不均匀和口腔中存在唾液被反射的情况。于是,Datta等人[74]基于颜色的分割技术从反射的牙龈、嘴唇和舌头区域中找到唯一的牙齿区域。之后,基于边界曲线切线的变化,从整个牙齿区域分割出每个牙齿。最后,根据牙齿的色调值分割出龋齿区域。然而,针对咬合面菌斑和龋齿自动分割,仍未获得临床上使用的标准方法。之后,为了实现完整分割出牙菌斑与牙齿,Sudheera 等人[75]提出基于HSI(hue,saturation and intensity)颜色模型,使用增强型K-Means 无监督聚类算法,实现自动化获得牙菌斑分割结果。但是该方法根据初始种子点的选取,增强K-Means 解可能会导致局部最小值,无法达到全局最优。之后,2021 年,Oltu 等人[76]利用维纳滤波器去除噪声和锐化处理,然后应用FCM算法,确定菌斑位置和龋齿区域。
为了降低图像噪声的影响,Alsmadi 等人[77]研究了一种新的模糊C均值聚类方法(new fuzzyC-mean,NFCM),并对全景X 线片图像中的颌骨病变区域进行分割,将图像分为背景区域和病变区域,减少了图像边界模糊。同样,Fariza 等人[78]也考虑到全景X 线片图像由于噪声、低对比度、不均匀照明和不清晰的分界线等问题,给分割牙齿图像分割造成了困难。他们提出基于高斯核函数的条件空间FCM算法,并结合先验知识,同时加入用户交互输入,能够高效区分牙齿区域和背景区域。但是涉及到了交互式分割,虽然提高了分割效果,却增加用户标记的工作。
针对一些尖角以及拓扑变化,聚类方法一般可以解决,但对图像的空间分布敏感,对于初始化和计算复杂度要求较高,这类模型经常陷入局部最小值中,不利于优化。并且基于聚类的牙齿分割方法中,K值选取不好把握,对于非凸的数据集较难收敛,异常点较敏感。若类别的数据量失衡,或者各类别方差不同,则聚类效果不佳,造成巨大的资源消耗。
1.4.4 基于反向传播神经网络的牙齿分割方法
反向传播神经网络(back propagation neural network,BPNN)是一种计算损失函数斜率的方法,可以采用反向传播算法对给定的数据集进行分类。通过前馈网络对输入进行训练,得到实际输出,然后比较期望输出和输入,并根据误差值对连接权值进行调整,以达到预期的输出。
Ainas 等人[79]使用自相关系数作为特征参数,基于BPNN 诊断龋齿。Sornam 等人[80]提出将线性自适应粒子群算法(linearly adaptive particle swarm optimization,LA-PSO)与BPNN融合在一起,从单个图像的特征提取中对正常或患龋牙齿进行分类。Geetha 等人[81]提出利用反向传播神经网络诊断根尖周X 线片中的龋齿。该方法采用拉普拉斯滤波进行图像增强,采用自适应阈值进行图像分割,利用纹理特征提取和BPNN进行分类。
但是由于BP 算法本质上为梯度下降法,而它所要优化的目标函数又是比较复杂,出现“锯齿形现象”,而降低反向传播算法的效率;并且容易发生网络学习的样本特征细节过多,而不能反映样本主要的规律,产生过拟合的问题。
上述所有基于手工特征的牙齿分割方法,通常都是利用图像的低阶信息,分割效果往往有限,并且不是端到端的算法,分割过程往往复杂混乱,需要大量的人工干预。提取的特征单一,而一般的牙齿图像复杂多变,所以这些基于传统手工设计的方法,没有办法完全表达图像的信息。这些算法中的大多数通常需要在分割和特征提取之前进行图像增强,增加了很大的工作量。并且图像识别的性能显著地取决于提取的特征的质量。尽管某些研究取得了令人满意的结果,但测试集中只包括了少数高质量图像。
2 基于深度学习的牙齿分割方法
深度学习是人工神经网络的一种改进,它具有更多的层次,对数据预测更精确。深度学习可以逐步优化数据结果并提高计算能力[82]。
卷积神经网络(convolutional neural network,CNN)作为深度神经网络前馈架构的典型应用结构,能够从海量数据中自动提取特征且具有良好的泛化能力,并在计算机视觉和图像识别领域,展示出了它强大的“能量”。CNN 最初大约在二十年前发布,2012 年,Krizhevsky 等人[83]提出的Alex-Net 架构获得了ImageNet 大规模图像识别比赛的冠军,从那时起,CNN 迎来了蓬勃发展的“鼎盛时期”。自从CNN 模型出现以来,特征学习方法发生了巨大的转变,在目标检测、图像分割和图像分类领域,基于卷积神经网络的深度学习方法得到越来越多的应用。一个特殊优势是它们以端到端的方式工作,学习过程更为简洁,且可以学习更高层次的特征。比如Alex-Net、VGG-Ne[84]、GoogleNet[85]和Involution-Net[86]等经典的卷积神经网络架构已经被引入到各种图像识别任务中。
为了实现图像语义分割在深度学习领域的快速发展,2015年,Long等人[87]提出了一种端到端的用于图像语义分割的全卷积网络(fully convolutional networks,FCN),与经典的CNN使用全连接层得到固定长度的特征向量不同,FCN 网络将全连接层都替换成了卷积层。解决了传统模型存在的难以大量提取样本特征的问题,提高了语义分割的精度[88]。但FCN 中池化操作会降低特征图的分辨率,Ronneberger 等人[13]提出的U-Net 网络,标志着CNN 真正意义上应用到了医学图像分割领域,牙齿图像分割也进入了一个新的发展时代。广义上,基于卷积神经网络的图像分割模型能够将每个像素分类为不同的对象。通常为每个像素(或超像素)生成像素块,并将像素块用作CNN 模型的输入,用于分类,并将像素的标签用于训练模型。近几年,图像语义分割较为常用的网络模型是由Google 公司提出的DeepLab等网络[89]。Deeplab系列网络能够有效扩大网络的感受野,减少了局部信息的丢失,提高语义分割的准确率。
但是语义分割无法做到区分同一类别中不同物体的,于是提出了实例分割,如Mask R-CNN网络,能够同时利用目标检测和语义分割的结果,在语义分割的基础上区分出同一类别的不同实例。目前,实例分割在医学图像分析领域具有重要的临床应用价值。随着该领域的研究人员提出了越来越多的基于深度学习的图像实例分割框架[90],在牙齿分割领域也取得了比以往传统方法更好的分割效果。
2.1 基于CNN的分割方法
“深度学习”是利用深度神经网络来解决特征表达的一种学习过程。对于图像等复杂情况,最常用的是所谓的卷积神经网络,它可以学习边缘、角、形状和宏观模式等特征。在训练过程中,神经网络对数据(如图像)和相应的标签(如“蛀牙”或图像上出现的龋损区域)进行重复的处理,通过反复调整模型参数和权重,进而提高模型的分割精度。
随着牙科诊断需求的逐年增加和经验丰富的牙医的缺乏,利用计算机技术辅助诊断(computer aided diagnosis,CAD)和治疗牙齿疾病逐渐成为新的研究热点[91]。计算机辅助诊断软件在医学领域通常作为辅助工具使用,但开发传统的CAD系统往往非常费力。最近,已经将深度学习方法引入CAD,为不同的临床应用提供准确的结果[92]。在口腔领域,该研究主要将卷积神经网络模型应用于根尖周X 线片和全景X 线片中的牙周骨丧失检测,根尖周X线片中的根尖病变以及咬合翼片中的龋损部位检测,可以提高分割效率,并达到高准确度。
Patil 等人[93]提出了将卷积神经网络与多维投影变分方法相结合的龋齿检测方法,与原有的CNN 方法相比,在一定程度上提高了龋齿检测的准确性,但仍存在需要大量训练数据和占用原有CNN时间较长的缺点。
Miki 等人[94]基于AlexNet 网络模型并对其进行改进,分割出了切牙、犬齿、磨牙等七种牙齿类型,平均分类准确率达到了88.8%。Oktay 等人[95]也基于AlexNet网络,如图4 所示,训练锥形束CT 图像对牙齿进行分类,包括磨牙、前磨牙、前牙以及背景,该方法的准确度可达90%以上。这两种方法分别对类别和精度进行了提升。2020 年,Lakshmi 等人[96]提出了一种半自动牙齿图像分割方法,利用图切割方法区分前景组织区域和背景牙齿区域,然后利用AlexNet网络进行分割和检测。
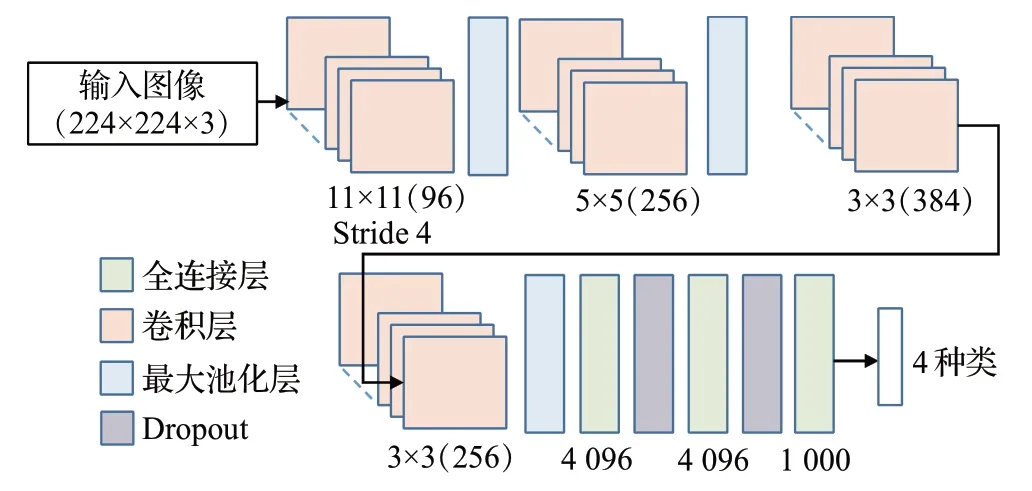
图4 AlexNet网络模型示意图Fig.4 Schematic diagram of AlexNet network model
Choi等人[97]利用全卷积网络估计龋齿概率,以此进行牙齿根尖周图像中邻面龋检测。但是论文中对于牙冠提取仍然采用传统方法,所以针对牙齿数量多、边缘不清晰的复杂图像时,提出的这种方法难以应对。为实现整个牙齿分割过程的全自动化,Banar 等人[98]提出利用YOLO[99]模型,将图像分成相邻的非重叠图像块,检测包含第三磨牙的图像块及其几何中心,并在其周围提取感兴趣区域。然后利用U-Net 网络在ROI内分割出第三磨牙,实现全自动第三磨牙发育阶段的研究。
由于牙齿病变和正常牙齿组织在质地和颜色等特征上相似,这使得难以正确分割牙齿病变区域及其边缘。此外,牙齿病变的分割需要在规定的时间内实现分割的准确性,从而满足诊断设备和海量数据的需求。在文献[100]中,Ma 等人提出了一种改进的图像级联网络(image cascade network,ICNet)分割方法,实现对牙结石、牙龈炎等多种病变类型的分割。将注意力模块(convolutional block attention module,CBAM)集成到ICNet 网络结构中,将空间注意力模块中的大尺寸卷积替换为扩张卷积,在抑制无用特征的同时增强相关特征,解决病灶区域分割不准确的问题。最后,将网络模型中的部分卷积替换为非对称卷积,以减少注意力模块增加的计算量。
为实现精确的牙齿分割,Cui 等人[101]提出了一种基于生成对抗网络结构的深度分割网络ToothPix,用于提取牙齿分割的综合语义信息。将残差块和编码器-解码器结构引入到ToothPix的生成器中,该生成器可以在鉴别器的引导下学习牙齿的灰度和边界特征。在没有真值(ground truth)的情况下,ToothPix中的损失将引导特征提取以混淆鉴别器,同时有效地避免了网络过拟合。
随着越来越多的两阶段(two-stage)模型的提出,在分割和目标检测任务方面,尤其是精度和准确度,获得了越来越优异的结果。虽然一阶段(one-stage)的检测速度更快,但是效果较差、分割准确率不够高。所以很多牙齿分割领域的学者将目光投向了two-stage 网络模型,在自动提取图像特征的同时,得到更好的分割和检测结果。Tuzoff 等人[102]基于Faster R-CNN 模型[103],通过简化pipeline 并优化计算得到牙齿检测结果,作为分割结果,输入到用于分类的VGG-16 网络架构中,该方法未对图像进行图像增强的处理工作,所以检测结果不够准确;同时利用了两种网络组合,不属于端到端方法,网络稳健性也有待提高。之后Chen 等人[104]也使用了Faster R-CNN 网络模型来检测图像中的牙齿并进行编号。但是这类方法,其只提取了牙齿的位置与类别信息,忽略了牙齿形状及语义信息的重要性。
Estai 等人[105]为了更好地对牙齿全景X 线片上的恒牙进行检测和分类,提出了一种基于卷积神经网络的自动检测分类系统。首先,基于U-Net对牙齿感兴趣区域进行初步分割。然后,利用目标检测网络Faster R-CNN[103],在感兴趣区域内识别每颗牙齿。最后,利用VGG-16[84]体系结构将每颗牙齿分为32类,并分配牙齿编号,但是该方法并不是端到端的牙齿分割方法。
为了解决牙齿X 线片图像中对比度整体偏低和边界模糊的问题,Zhao等人[106]基于LSTM(long short-term memory)构建了两阶段注意力机制分割网络(two-stage attention segmentation network,TSASNet),如图5所示。在第一阶段,采用嵌入全局和局部注意力模块的注意力网络,获取上下文信息,定位出大致的牙齿区域。第二阶段,利用全卷积网络进一步分割出准确的牙齿区域。该方法能够自动捕捉牙齿区域,减少用户的干预,还可以缓解牙齿分割中强度分布不均匀的问题。虽然该方法利用了近距离特征点的相似性以获得更多的上下文信息,具有自动检测某些模糊牙齿区域的能力。但是没有考虑到远距离特征邻域间的相关性,当某些牙齿之间没有明显的边界,甚至直接重叠时,难以解决。
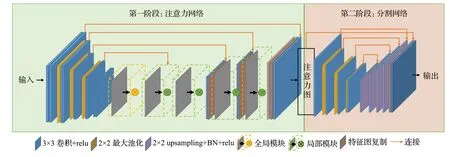
图5 两个阶段组成的TSASNet网络Fig.5 TSASNet network consisting of two stages
于是,为了增强对位置的感知,减少边界差异,Chen等人[107]提出了一种多尺度位置感知网络,网络结构如图6所示,该网络主要包括三个核心部分:(1)在块尺度(patch-level)上,结合多尺度结构相似性损失,减少牙齿的边界损失然后预测。(2)利用位置感知模块(location perception module,LPM)从全局尺度对每个牙齿像素进行定位。(3)采用聚合模块(aggregation module,AM)减少多尺度特征分支之间的语义差距。
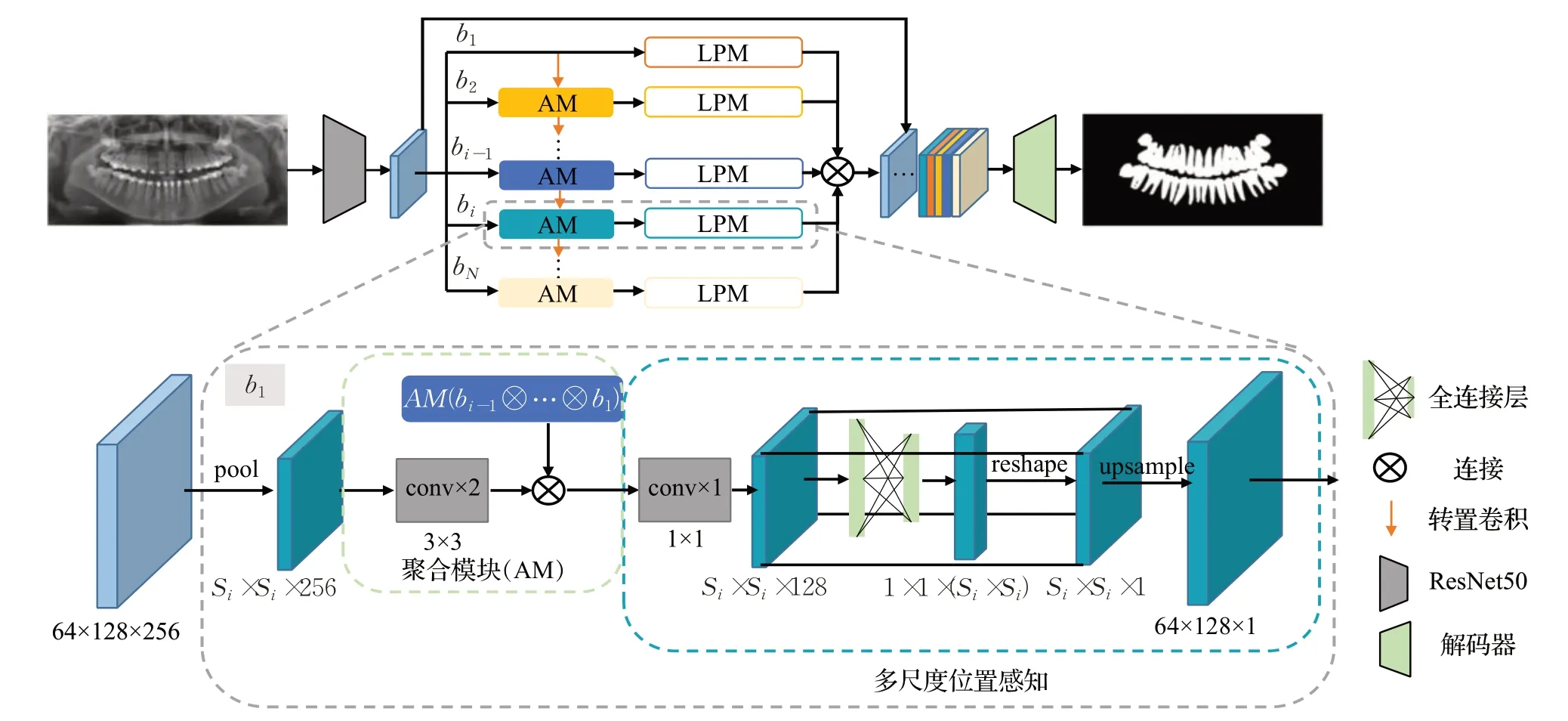
图6 所提方法的流程图Fig.6 Pipeline of proposed method
为了减少正畸治疗的手动干预,Im 等人[108]将卷积神经网络用于三维牙齿分割,开发了一种基于动态图卷积神经网络(dynamic graph convolutional neural network,DGCNN)的算法,也属于一种两阶段性网络。首先,使用DGCNN 将数字牙齿模型细分为牙龈和牙弓。第二阶段,在调整牙龈顶点数量后,使用DGCNN 将数字牙齿模型分割为单个牙齿和牙龈。虽然利用基于曲线的骨架剪枝算法进行分割,以获得清晰的牙齿边缘。但是,在某些情况下,由于扫描数据的曲率不清晰,可能无法形成闭环,或者在错误的区域形成闭环,导致分割精度下降。
2.2 基于U-Net的分割方法
虽然卷积神经网络CNN被广泛用于图像分割与分类工作,但是CNN 通过逐层提取图像特征的过程中丢失了图像中用于识别目标位置和形态等语义信息[109]。语义分割却可以实现对图像中的每一个像素进行分类,既保留图像像素的空间语义信息,又可以对物体进行识别分割,目前被广泛应用于医学图像分割任务。
在生物医学中往往要求算法的输出不仅要包括目标类别的位置,而且图像中的每个像素都应该有类标签。为了满足这些要求,Ronneberger等人[13]提出了U-Net图像语义分割网络,并奠定了医学影像语义分割的基础,它启发了大量研究人员去探索“U”型语义分割网络的上限,它模仿FCN 的编码-解码结构,将编码(特征提取)路径和解码(分辨率恢复)路径嵌入分割网络。
编码和解码(encoder-decoder),早在2006 年就被Hinton 等人[110]提出来并发表在了Nature 上。最初编码解码网络提出的主要作用是压缩图像和去噪声,后来有学者把编码解码网络的思路用在了医学图像分割的问题上。编码器是下采样过程,并且在下采样过程中从输入图像获得高级语义特征图,相当于是图像压缩的过程。解码器是一个上采样的过程,最终恢复成原始图像大小。在医学图像分割的基础上,提出了多种牙齿分割模型。
为检测牙齿全景X 线片中的牙周骨丧失,Kim 等人[111]基于编码-解码架构开发了一种自动诊断系统,所提出的深度神经传输网络(deep neural transfer network,DeNT-Net)不仅可以检测病变,还可以根据牙齿联合表示法提供病变的牙齿编号。该网络能够提供受牙周骨丧失影响的相应牙齿数量,但该方法只能检测一种牙齿问题,存在一定的局限性。
为了研究针对牙齿X线片图像分割的自动化方法,Ronneberger 等人[112]将U-Net 网络引入到牙齿图像分割领域,如图7 所示,最终将64 维特征向量映射到7 种类别。虽然成功完成了将牙齿X 线片图像完全自动分割的任务,但是准确率有待提高。随后2019年,蒋芸等人[113]提出一种改进的咬翼片图像分割方法,引入了条件生成对抗网络对咬翼片进行分割,使判别器与生成器相互优化,获得具有更多上下文信息的分割特征图,该方法在一定程度上提高了分割准确率。

图7 U-Net卷积神经网络结构Fig.7 U-Net convolutional neural network structure
图像质量影响。针对全景X 线片图像存在的质量差,如低对比度或噪声,以及不同患者之间牙齿存在差异的问题,Wirtz 等人[114]提出一种基于二维耦合形状模型和U-Net 网络的自动牙齿分割方法,对牙齿(不包括智齿)进行分割和标记。该模型由每个牙齿的统计形状模型组成,并利用它们的空间关系与所有其他单个模型耦合,保证分割过程更稳定。为了保证提取到更多的细节,改变了U-Net 网络输入图像的分辨率,并将每层通道数量减半。但是由于数据不足,特别是第三磨牙的数据不足,导致分割精度和稳健性较低。Koch 等人[115]也对U-Net进行了修改,去掉了dropout层,在每个池化层、上采样和连接层之前加入批处理规范化,并将其应用于牙齿全景X线片语义分割任务,但是其多任务预测模型的设计和评估存在缺陷。Duong等人[116]还将U-Net网络用于牙齿CBCT 图像中,来实现自动分割牙槽骨结构,和其他半自动分割方法相比分割精度也有了一定的提高。针对图像噪声引起的牙齿各部分之间无法实现完全准确分割的问题,Sivagami等人[117]利用U-Net网络进行牙齿X 线片图像的精确分割,并通过与阈值、聚类等分割方法进行比较,证明了U-Net网络的有效性。
传统的图像分割方法在处理复杂的牙齿图像时经常会遇到分割精度低且耗时的问题。Tao 等人[118]提出了一种基于改进U-Net 和注意力机制的牙齿图像分割方法。首先,利用U-Net 网络构建牙齿图像分割模型,将特征图补充到下采样中以减少信息丢失,同时,解决图像分割中定位不准确的问题。然后,将注意力模块引入U-Net 网络,增加重要信息的权重,提高网络分割的准确率,使用平均池化层代替全局平均池化获取空间特征。
龋齿分割。为了实现龋齿的分割,Cantu 等人[119]提出利用U-Net网络分割咬合翼片中存在的龋损部位,将图像中的每个像素分为两种类别:龋损,不属于龋损,勾勒并突出显示龋损部位。选择EfficientNet-B5[120]网络作为编码器,同时为了提高模型的泛化能力,通过应用几何和像素级别的随机变换进行数据集增强。Zhang 等人[121]基于SSD网络模型(single shot multibox detector)对智能手机拍摄的口腔照片进行龋齿筛查。然而,由于部分口腔区域位置难以捕捉,所以,智能手机并不适合用于临床的龋齿诊断。Kühnisch 等人[122]基于Mobile-NetV2 网络对数码单反相机只捕捉一颗牙齿的口腔照片进行龋齿检测,但是由于实验照片选取严格,导致该模型的泛化性和准确性不高。在文献[123]中,Lian等人通过对牙齿全景X线片进行分割,能够更好地检测龋齿病变区域。然而,对于口腔照片,通过分割牙齿区域从而进行龋齿检测的实验很少。因此,2022 年,Park 等人[124]提出通过开发CNN 算法检测照片中的龋齿,提高牙齿分割的准确性。他们基于U-Net实现牙齿分割,提高整体龋齿检测性能,并基于ResNet-18和Faster R-CNN分别对龋损部位进行分类和定位。
牙齿重叠。前面提到的方法主要通过去除组织和其他邻近牙齿部位,实现牙齿X线片中的牙齿分割。但是相邻牙齿之间可能会出现重叠的现象,而且利用其他组织确定牙齿区域也很困难。因此,针对这一挑战,Fariza等人[125]提出了一种基于U-Net卷积网络的牙齿X线片图像自动分割方法,输入数据为通过手工切割的全景X线片感兴趣区域图像,利用U-Net进行牙齿的细节分割,但是该方法需要手动分割出感兴趣区域,增加研究的工作量。
边界模糊、牙齿错位。现有的分割方法大多关注语义特征提取,而忽略了全景X 线片中边界模糊、牙齿错位等复杂情况。在分割牙齿图像时牙齿边缘的细节是非常重要的,因此Nishitani 等人[126]提出了一种基于UNet网络的牙齿边缘加权损失函数图像分割方法。通过将牙齿边缘区域的交叉熵(cross entropy,CE)添加到整个图像的CE 中,设计出牙齿边缘加权的损失函数。在训练网络时,使用该损失函数提高牙齿边缘的分割精度。在文献[127]中,Muresan等人基于ERFNe(tefficient residual factorized convolutional network)[128]对不同语义类别的牙齿进行分割,然后采用两步标记算法对分割结果进行微调。虽然该方法能够平衡效率和速度的问题,但是不能根据牙齿位置分割每颗牙齿。于是,Hsu等人[129]提出了一种基于U-Net和目标检测的弱监督机制,通过弱监督强化学习改善牙齿定位,实现了对每个牙齿位置的识别。上述方法虽然有效,但仍不能解决牙齿错位、边界模糊的难题。为了解决这些问题,Zhang 等人[130]提出了一种基于边界引导和特征图失真的双子网结构BDU-Net。在编码器中嵌入了具有扭曲特征能力的Disout方法,以获得具有出色泛化能力的多尺度特征映射,进一步提高了边界分割的准确性和网络的泛化能力。然后,将扭曲的特征图提交给两个共享的具有特征金字塔结构的子网络,一个是用于生成区域分割结果的区域子网络,另一个是用于调整分割边界的边界子网络。子网络均采用U-Net结构,通过共享多尺度特征图实现分割。
从方法论上看,大多数研究者的方法都比较单一,Zhao等人[131]提出将数字图像处理和卷积神经网络相结合,实现全面数据采集和分析研究。利用数字图像处理方获得单个牙齿的纹理特征信息,然后,调整U-Net 网络,使其适应图像处理后的数据,最终实现牙齿正常和异常状态的分析。
CNN 在医学中的普遍性尚未得到评估,Krois 等人[132]研究了在全景X 线片上分割和识别根尖病变的专家系统的通用性。使用根管填充数据集对U-Net 进行训练和测试,实验结果表明,实践经验比图像特征更为重要。此外,当分割全景X 线片时,也证明了深度学习架构在泛化性方面存在不足。
2.3 基于Mask R-CNN的分割方法
随着2012年卷积神经网络在ImageNet分类工作中取得了令人满意的结果[133],Girshick 等人分别提出了区域卷积神经网络R-CNN[134]、具有空间金字塔结构的Fast R-CNN[135]和具有区域建议网络的Faster R-CNN[103]。之后,He 等人[136]在Faster R-CNN 基础上提出了Mask R-CNN,具体网络结构如图8所示。

图8 Mask R-CNN网络结构图Fig.8 MASK R-CNN network structure diagram
Mask R-CNN 网络与以往的目标检测和语义分割都不同,它属于实例分割网络。目标检测的任务是对单个目标进行定位和分类。语义分割的目标是将对象的每个像素分类为已知类别,而不区分对象实例。实例分割结合了检测和语义分割这两个经典的计算机视觉任务,其中每个检测到的对象都被分类、定位和分割。对于牙齿图像来说,基于U-Net的语义分割方法只能分割出类别牙齿,但是通过Mask R-CNN实例分割可以将图像中出现的每一颗牙齿分割出来,进而进行后续的研究分析。
由于隐私限制,医疗数据的最大问题是数据分析的可用性。在研究场景中使用时通常需要考虑伦理道德方面的要求,数据通常不被共享。所以目前为止,在临床口腔医学领域缺少具有高可变性的大型公共数据集。2018年,Silva等人[14]构建一种基于牙齿全景X线片的新型数据集,该数据集包含1 500张图像,且可变性较高。并通过将Mask R-CNN 卷积神经网络应用于构建的数据集,以展示深度学习方法在构建出的数据集上分割图像的能力。但是,该数据集的标注相对单一,导致牙齿结构的检测和定位并不准确,难以精确分割每一颗牙齿。
针对在检测牙齿时可能存在的人工制品(如假牙)、牙齿缺失问题,Jader等人[15]提出将Mask R-CNN用于牙齿全景X 线片图像中,并对每颗牙齿、缺失牙齿和假牙进行检测和分割。并对分割结果进行了讨论,虽然和其他无监督的方法相比,Mask R-CNN 的分割效果比较好。但是其分割精度仍然不高,而且会将所有的牙齿都归为一类,忽略了不同牙齿(如门牙与后槽牙)之间的语义差别,无法做到各个牙齿之间的区分。但是在临床牙齿诊断中,医生们会根据牙齿的各个部位来快速分析牙齿的情况,所以对不同牙齿的区分是很重要的。
于是,为了完成详细分割出每个牙齿的任务,2020年,Lee等人[137]通过改进Mask R-CNN网络进行自动牙齿分割,如图9 所示,利用COCO 数据集[138]进行网络预训练,并对超参数进行微调,最后利用微调后的Mask R-CNN 模型对牙齿图像进行分割,能够输出每个牙齿的类别。这种方法既适用于可解释的诊断系统,也适用于需要类似分割任务的法医分类。
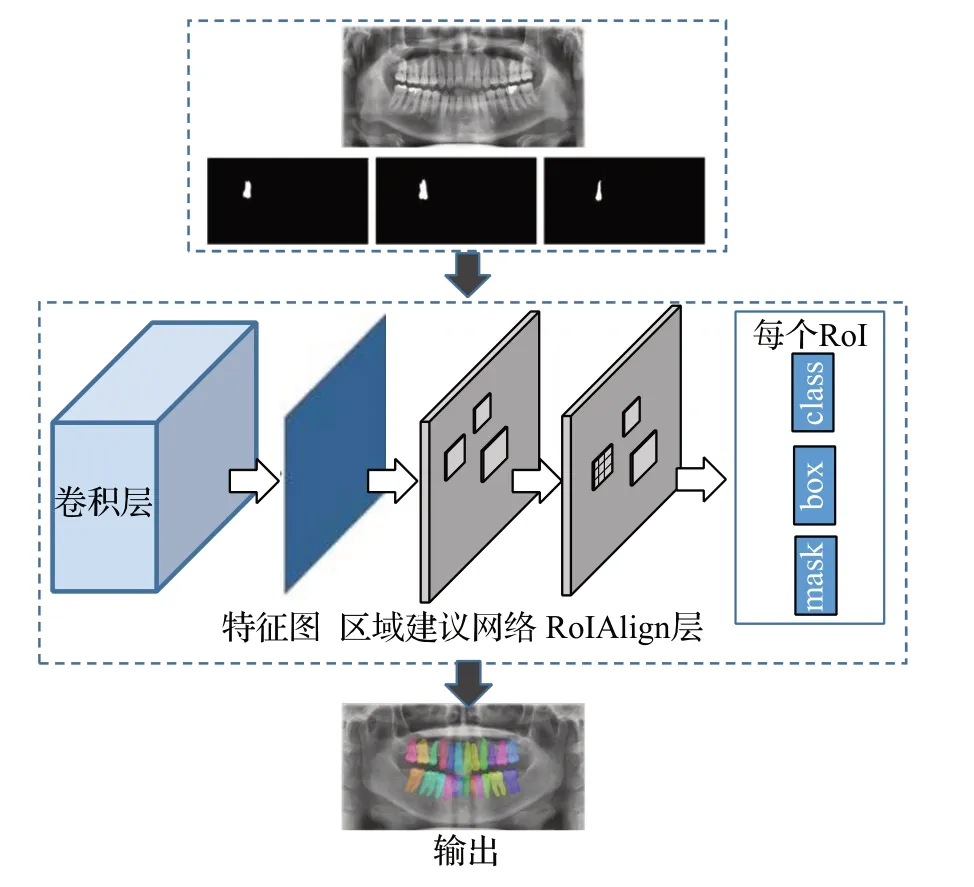
图9 基于Mask R-CNN框架的方法体系结构Fig.9 Method architecture based on Mask R-CNN framework
龋齿最常见的位置是咬合面,但在龋坏的早期阶段,难以发现。为了实现对龋齿严重程度的诊断,Moutselos等人[139]提出基于Mask R-CNN 实现龋齿的实例分割和分类,并借助超像素分割将图像分割成均匀的片段,使网络更容易提取特征和语义映射,从而降低了计算复杂度。
针对CBCT图像中存在的严重金属伪影,阻碍了每个牙齿的精确分割。Chung 等人[140]提出了一种逐像素标记的神经网络,通过重新调整VO(Ivolume-of-interest)、改进检测器等,开发了一个对金属伪影具有鲁棒性的实例分割框架。
考虑到医疗图像在临床使用时,既需要整幅图的全局信息也需要某些特点区域的局部信息。通过对医学图像各个尺度特征信息进行融合,可以在一定程度上增大信息量。赵庶旭等人[141]受到U-Net 模型中通过跳跃连接的启发,提出了利用跳跃连接结构融入多尺度注意力信息对Mask R-CNN 分割分支进行改进,弥补Mask R-CNN 在掩码分支上所缺乏的深层特征,并通过引入注意力机制SE(squeeze and excitation)模块[142]来捕获高级语义信息,改进后的Mask分支如图10所示。
牙齿图像经常出现复杂和拥挤的牙齿结构,Zhu等人[143]和Oktay 等人[144]将Mask R-CNN 网络用于复杂牙齿图像的自动检测、分割和牙齿编号,均表现出良好的分割效果。Silva等人[145]通过研究4种实例分割方法,包括Mask R-CNN、混合任务级联(hybrid task cascade,HTC)、路径聚合网络PANe(tpath aggregation network)和残差神经网络ResNet。结果表明,尽管在某些情况下,所有框架都可以用于估计牙齿的大小、数量和位置,但PANet在特定情况下的准确性优于其他框架。但是,上述模型在牙齿状况良好时表现尚好,但在牙齿受损或标签错误时容易出现失误。
针对之前没有工作同时考虑恒牙和乳牙的分割,Pinheiro 等人[146]基于Mask R-CNN 构建了一个端到端的深度学习架构,用于乳牙分割和编号。并通过引入PointRend 模块[147]生成清晰预测,提高了牙齿边界的分割性能。
基于深度学习的分割和目标检测算法的最新进展已经能够提供预测和实用的识别,以协助评估患者的口腔健康,帮助牙医构建更准确的治疗计划。然而,一直缺乏开发协作模型,通过利用个体模型来提高深度学习的性能。在文献[148]中,Geetha等人提出通过结合独立的牙齿分割模型Mask R-CNN和识别模型Faster R-CNN进行协作提高整体性能,实现协作学习。但是无法正确分割重叠的牙齿和种植牙,仅适用于全景牙齿X 线片,不完全适用于CBCT图像。
一些研究已应用深度学习来检测缺失的牙齿区域,并分割各种解剖结构以进行种植体规划[149-150]。但是,只能检测特定牙齿缺失区域,因此,2022 年,Park 等人[151]利用Mask R-CNN网络实现了同时分割多个缺牙区域,帮助进行种植体放置的同时也提高了检测速度。但是由于口腔结构和牙齿大小因人而异,因此该方法的检测性能有限。
3 数据集
迄今为止,在牙齿分析领域没有可用的大型公共数据集。但是标注详细的数据集和有效的评测指标对高性能牙齿分割模型及方法研究和成果展示起着至关重要的推动作用,为确定和衡量一个牙齿分割模型和网络的质量和性能做出了巨大的贡献,本章将对某些有一定影响的小型数据集和评价指标进行介绍。
3.1 用于深度学习方法的牙齿X线片图像数据集
表1 总结了一些基于深度学习方法进行牙齿图像分割的论文中所使用的数据集。
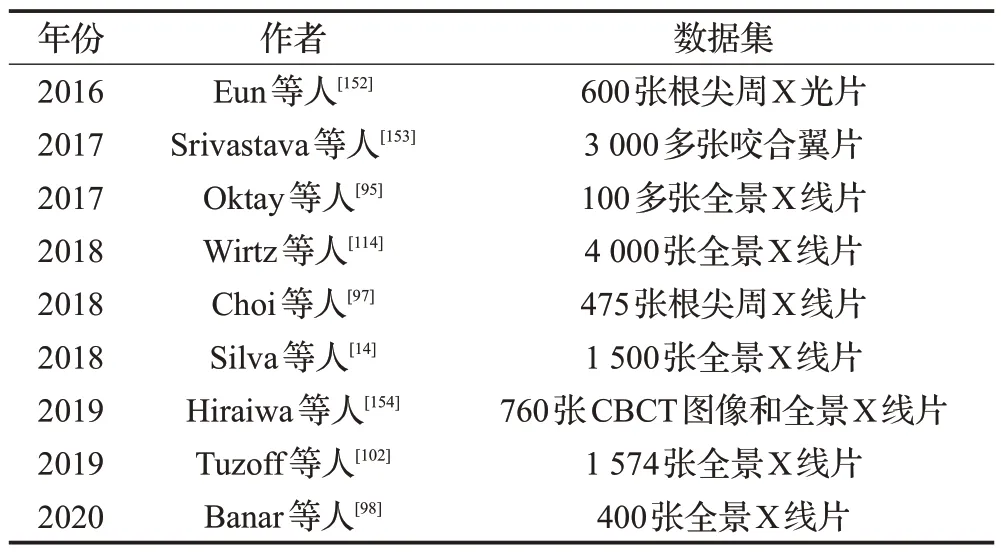
表1 用于深度学习方法的牙齿X线片图像数据集描述Table 1 Description of dental radiograph image dataset for deep learning methods
3.2 评价指标
一般来说,如果某种算法的效率比其他算法效率更高,则说明这种算法优于另一种算法。评估算法性能的好坏需要使用具有普遍性且有效的标准,在牙齿图像分割中常用的评价指标包括以下6个:
(1)准确度:每个标签正确检测的百分比,即所有样本全部预测正确的概率。
其中,TP表示正类预测为正类的样本数;TN表示负类预测为负类的样本数;FP表示负类预测为正类的样本数;FN表示正类预测为负类的样本数。
(2)特异性:实际为负类预测为负类的概率。
(3)召回率:实际为正类预测为正类的概率。
(4)精度(也称为阳性预测值):正类预测为正类的概率。
(5)F1-score(精度和召回率的调和平均值):
(6)骰子分数Dice score(DSR):用于计算两个样本的相似度。
3.3 不同方法进行牙齿分割的比较
近年来,牙齿分割受到越来越多研究者的关注,本节针对第1、2 章介绍的近几年来研究人员对牙齿分割技术的改进成果进行总结,将其基于在3.2 节介绍的评价指标上进行了对比。其中,VOE(volumetric overlap error)为积重叠误差,通过计算分割算法和手动分割结果交集和并集的体积比得到两者的真实重叠度[60]。如表2所示,将基于手工特征的牙齿分割方法和各个方法使用的数据集进行了总结和比较。
表2中的比较结果表明,基于阈值方法是一种比较常用的牙齿分割方法,它能够通过从图像的像素强度中选择阈值实现区域划分,准确率可以到达90%以上,方法简单并且可以实现不错的分割效果。
除了阈值方法以外,随着各种水平集算法的提出,也极大推动了基于边缘分割方法的发展。在基于边缘的牙齿分割方法中,研究人员一般选择积重叠误差VOE作为方法的评价指标,随着越来越多方法的提出,分割误差也在逐年降低,在石沁祎等人[60]提出的方法中VOE的值已经降低到了8.61%。
在基于机器学习的几类牙齿分割方法中,基本分割结果的准确率都可以达到90%,特别是Deleat-Besson等人[65]提出的基于ANN的分割方法中,准确率达到了99%。与基于ANN的牙齿分割方法相比,基于SVM的牙齿分割方法实现了小样本的分类问题,但是难以直接进行牙齿疾病的多分类任务。除此之外,基于聚类的牙齿分割方法数量最多,主要是聚类方法的距离和规则的相似度容易定义,限制较少,也无需预先制定聚类数,受到了研究人员的青睐。虽然基于BPNN的牙齿分割方法较少,在Geetha等人[81]提出的方法中其准确率达到了99.16%,证明了反向传播算法的有效性。
近几年,这些传统的牙齿分割方法在实际应用中,大多是多种方法一起交叉使用。一个好的、准确的分割方法,准确率、精度、特异性和敏感度等的值应接近1。随着各类方法的发展,在各个方面的性能都表现得越来越好。但是由于大多数方法没有使用统一的数据集,所以并不能简单地对各类方法进行纵向对比。但是可以观察出,在几类方法对比后,基于机器学习的方法具有一定的优势,它们能够建立各种算法和统计模型,帮助系统在大量牙齿图像数据特征中找到规律,然后使用可识别这些特征的模型来预测或描述新的牙齿数据。
如表3所示,将部分基于深度学习的牙齿分割方法的分割性能进行了比较与总结。表中几种方法的准确率都可以达到90%以上,证明了基于深度学习方法在牙齿图像分割方面的优势。可以发现,Eatai 等人[105]提出的方法,在各方面性能都比较稳健,也证明了虽然非端到端方法的复杂度变高了,但是性能和灵活度却得到了提升。Ronneberger等人[112]的方法dice指数只有56.4%,可能是数据集较小造成的。Lee 等人[137]提出的方法比Silva等人[14]开发的方法表现出了更好的性能,证明了对Mask R-CNN 的改进是有一定效果的。在精准率上,Geetha等人[148]提出的方法表现最优,在召回率上,Tuzoff等人[102]提出的方法表现最优。
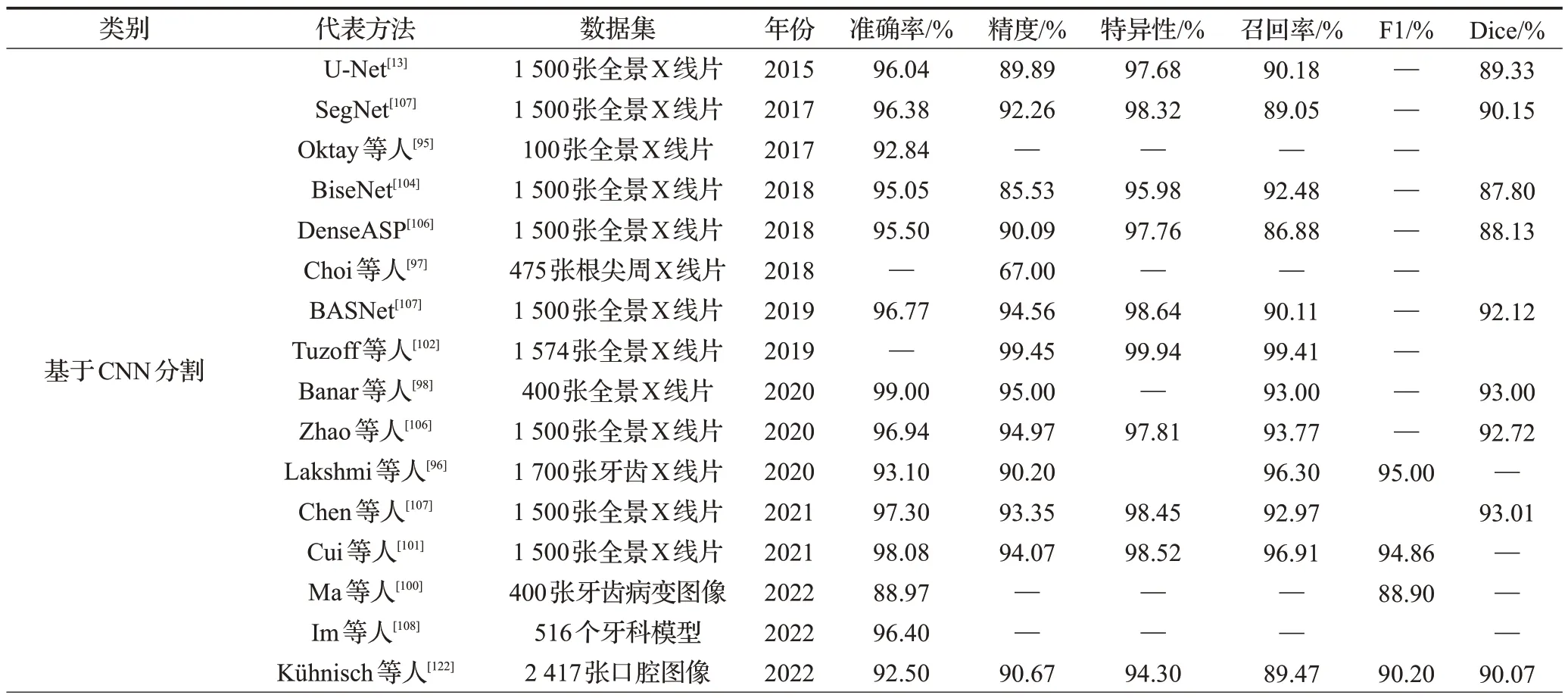
表3 基于深度学习的分割方法的比较Table 3 Comparison of segmentation methods based on deep learning
2018 年,Silva 等人[14]构建了一个包含1 500 张牙齿全景X 光片图像的数据集,该数据集具有高度的可变性,其中包含了10 个不同类别的图像。在Silva 等人构建的数据集上,将基于深度学习的牙齿分割方法和其他传统牙齿分割方法比较结果,如表4所示。
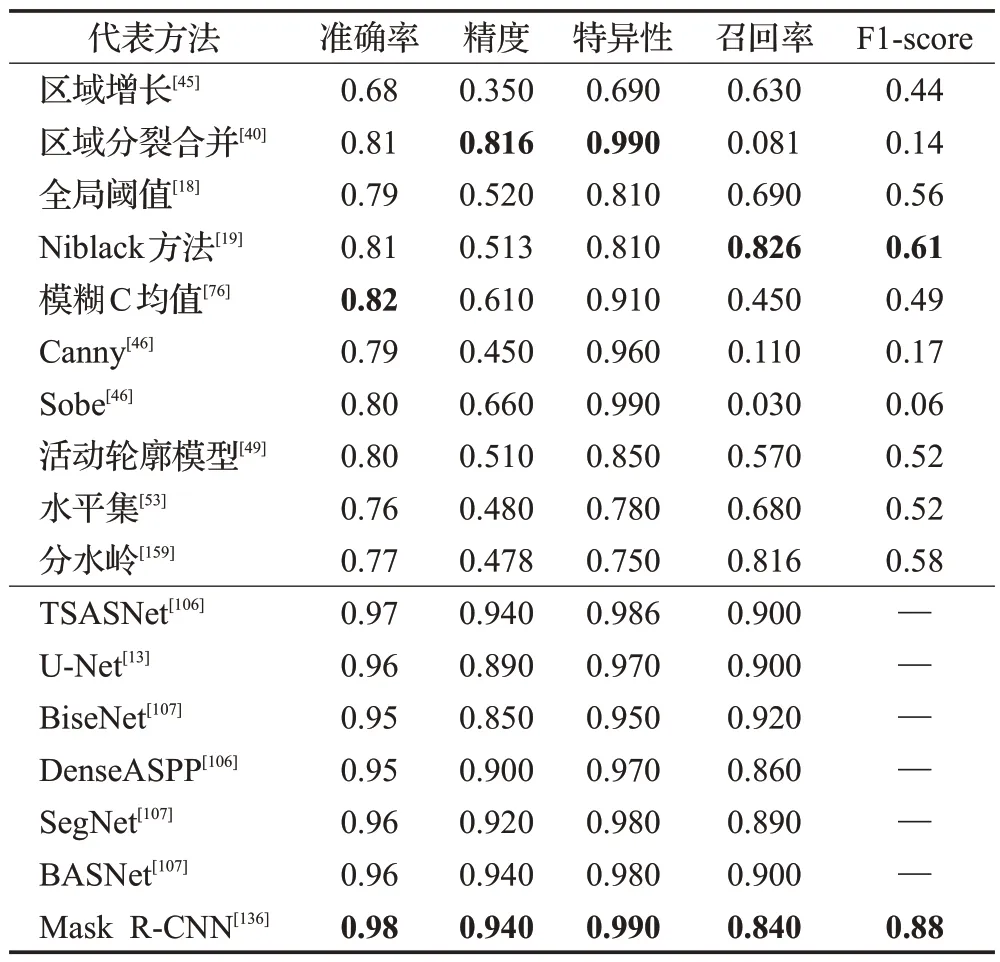
表4 传统方法与深度学习方法的比较Table 4 Comparison between traditional methods and deep learning methods
在表4中,突出显示了两类方法的最佳结果。由表可知,深度学习方法相比于传统图像处理方法有着明显的优势。在特异性上,Mask R-CNN方法的结果接近于区域分裂合并算法,但考虑到其他性能,Mask R-CNN明显更优越。此外,值得注意的是,没有任何一种无监督学习方法能够像深度学习方法一样具有多项高评分指标。
4 总结
回顾了各种牙齿图像分割方法之后,发现目前在牙齿分割领域仍面临多重挑战,所以本文结合目前牙齿分割领域的进展,提出了该领域各方法存在的主要问题,以及其未来的发展方向。
4.1 存在的问题
4.1.1 传统手工特征方法存在的问题
基于传统手工特征的牙齿分割方法往往依赖于先验知识和图像特征,这些方法既耗时又对噪声敏感,且计算复杂度较高。而且传统机器学习方法的性能在很大程度上取决于手工特征,然而,人工设计的手工特征无法充分表达图像的高层语义信息。训练从牙齿感兴趣区域中提取的特征时,很大程度取决于研究人员的技术和经验,因此它的适用性和分割的结果质量一般,并且过度依赖于后续的分割操作。
4.1.2 深度学习方法存在的问题
目前,虽然深度学习相比传统算法有着特征提取能力强、能够学习更多高层语义特征的优点,但是基于深度学习的牙齿分割方法的发展仍然存在一些问题。
首先,网络的发展存在以下挑战:(1)分割模型泛化能力不足,导致同一个网络在不同的分割任务上很难具有同样的性能;(2)大多数基于深度学习的牙齿图像分割方法采用有监督的深度学习模型,需要耗费大量的人力标注病灶区域;(3)虽然U-Net 网络和Mask R-CNN网络在牙齿图像分割上取得了良好的分割效果,但与其他深度学习方法一样面临可解释性低的问题,临床医生无法直接理解其运行机制,对其接受度低;(4)目前,大多数研究为了提高网络分割性能,对网络进行级联或并行改进,以及编码器个数的改进等,但这些方法可能增加了网络的参数量。
其次,在数据方面,深度学习方法需要依靠大量的数据建立分割模型,但是目前牙齿图像处理领域仍然受到医学图像数据特殊性带来的限制,缺少精确标注的大型公共牙齿图像数据集。同时,医学数据一般具有多种模态,需要研发多模态模型算法,针对医学数据的深度学习模型算法仍有着巨大的提升空间。由于目前没有公开的、高质量的大型数据集,在牙齿X 线片图像分割中,许多研究使用几乎相同的架构或网络,但结果却大不相同。
此外,由于牙齿X 线片图像种类繁多,很难找到特定的分割方法。同时由于捕获设备的差异,带来了图像质量不同的问题等。
4.2 未来发展趋势
(1)构建大型数据集。目前,构建高质量、大规模的牙齿X线片图像数据集,是牙齿图像分割领域亟待解决的问题。开发公共存储库,可以保证口腔领域应用数据的一致性,更客观地探讨提出算法的优劣。
(2)定制标准的性能评价指标。虽然一系列的指标可以反映网络的性能,但是有一定的局限性,当类别不平衡时,准确度会有很大的误导性,大多数研究也并没有与临床相关的指标。未来在这方面,需要研究定义出一组标准的性能指标,可以用于口腔领域网络模型的研究。
(3)快速且精准的分割技术。目前大多数牙齿X线片图像分析方法的效率较低,因此在未来的研究中,应该设计效率更高的分割技术进行改善。根据目前的研究结果,在未来依旧要寄希望于深度学习。
(4)设计实时性轻量级的分割网络。现有的深度学习牙齿图像分割方法更关注分割的准确性,但是在实际应用中较小的网络规模以及更快的分割速度可以实时地为口腔科医生提供辅助诊断的分析数据。因此,通过探究牙齿图像的潜在特点压缩网络规模,设计出实时性分割牙齿图像方法是十分值得研究的。
(5)探索新的龋齿检测方法。在最近的研究中,基于深度学习的咬合翼片龋齿分割和检测的应用还比较少。相比于其他牙齿分割任务,目前基于X线片的龋齿分割所面临的挑战主要包括:龋齿间黏连、病变区域边界不清晰、小尺度龋齿漏检等。因此,在未来的工作中应致力于研究龋齿分割和检测新方法。
5 结束语
牙齿图像分割是一个具有挑战的领域,很少受到研究人员的关注。本文对过去近十年中不同研究者提出的不同方法进行了梳理和归纳,根据特征提取方法的不同,将牙齿图像分割研究分为基于手工特征的牙齿分割方法和基于深度学习的牙齿分割方法两种类别,分别阐述了这些算法的发展现状和局限性。另外,本文还对这些方法使用的数据集进行了总结,并比较了两类方法在相关数据集上的实验结果。最后指出了当前牙齿分割方法存在的问题,及未来可能的发展方向。
