融合注意力机制的YOLOv7遥感小目标检测算法研究
2023-10-30余俊宇刘孙俊
余俊宇,刘孙俊,许 桃
成都信息工程大学 软件工程学院,成都 610225
随着遥感技术领域迅速发展,遥感目标检测技术逐渐成为当下研究的一个热点,其被广泛应用在国防、交通、城市建设发展等方面。对于遥感图像而言,这些图像中的目标通常都是分布密集、尺度差异显著,而且还会因光照、天气和其他建筑的影响造成这些图像的检测背景十分复杂,从而给检测过程带来一定的影响。比如,对于遥感图像中常见的飞机、汽车、油罐、操场等检测目标而言,飞机、汽车不仅分布密集、检测尺度差异显著而且还受一些外形相似的建筑影响,而油罐、操场的检测会受检测背景复杂等因素的影响。
在2012 年的ImageNet 图像分类比赛中,基于深度学习的卷积神经网络表现优异,使得卷积神经网络得到快速发展,在目标检测中,卷积神经网络是目标检测的主要方向,而目前基于深度学习的目标检测算法可以分为两类,一类是基于候选区域的双阶段目标检测算法,另一类是基于回归的单阶段目标检测算法。对于双阶段的目标检测算法通过专门的模块生成候选框并寻找前景和调整候选框,再居于生成的边界框进一步分类及调整,其典型算法主要有SPP-Net[1]、Fast R-CNN[2]系列等,该类检测算法精度高但速度慢;而对于单阶段的目标检测算法是放弃生成候选框的阶段,将检测任务作为一个回归问题,直接对目标进行分类和回归操作,其典型算法主要有SSD[3]、YOLO[4]系列,对于该类算法,不仅具备较高的检测精度同时还有较好的检测速度,所以单阶段的检测算法得到广泛的应用。
由于使用的遥感图像都存在检测背景复杂、目标尺度差异显著以及分布密集等特点,因此对于遥感目标的检测,研究人员都是利用遥感图像实际存在的情况对应用的模型展开具体的改进从而提升网络的检测精度。Xu 等人[5]针对YOLOv3 网络对遥感目标的特征提取能力不足,从而通过增加DenseNet[6]模块提升主干网络对遥感目标的特征提取能力以提升网络的检测精度,但是由于DenseNet 模块有较深的网络结构,包含了大量的参数,会使得改进的网络训练时间变长,而且可能会造成网络出现过拟合的现象;李惠惠等人[7]为了提升网络对遥感目标检测的性能,通过将网络的检测层增加至4个,从而提升网络对目标的检测能力,进一步降低网络对遥感目标的漏检率,但是对于遥感图像中尺寸大小不一的目标其效果也存在缺陷;Qing 等人[8]通过对YOLO模型的主干网络进行优化,其使用RepVGG[9]作为骨干特征提取模块用以提升网络对遥感目标的特征提取能力,对于该模块同样存在Xu 等人[5]出现的问题,加入该模块会增加大量的参数,使得计算变得更复杂,进而影响整个网络的性能;Yang 等人[10]通过将GIOU[11]损失函数替换原网络的损失函数使得改进后的网络对遥感图像中的飞机等检测目标的预测框回归精度和收敛速度都得到提升;同样,高倩等人[12]利用边界框回归之间的向量角度从而引入SIOU[13]损失函数使得模型的检测精度得到提升,但是对于GIOU损失函数而言很容易退化成IOU,无法区分预测框与真实框的相对位置,而SIOU对目标存在遮挡和类似于目标的其他非检测目标的处理效果会出现误差较大的情况;Hou等人[14]针对遥感图像中存在目标分布密集并且检测背景复杂,其通过将卷积注意力机制[15]引入到YOLOv5网络中,以提升网络对密集目标的检测精度,但是由CBAM 可知该模块更适合用于检测大目标,而对于遥感图像中的目标,其中的小目标和细节信息得不到很好的表现。
通过上述可以发现,针对遥感图像普遍存在的分布密集、目标尺度差异显著、检测背景复杂等问题,研究人员基本的改进方法都是通过优化网络的特征提取能力、增加模型对待检测目标的关注度,但大多数方法考虑对目标特征的提取都是停留在层间特征交互这个关系,而没有想过层内特征规则这个关系。因此,本文选择以YOLOv7[16]网络结构为基础,并根据上述的分析来提升网络的检测效果。YOLOv7 模型作为较为优秀的目标检测模型,虽然对于一些大目标而言,其检测效果比较好,但是对于遥感目标,该类目标的图像中存在大量的背景信息,绝大多数都是小目标而且分布密集,存在遮挡,模型很难从全局的角度上完整地提取目标的特征,并且由于大量的背景信息,模型的注意力大都集中在背景信息上,使得模型对遥感目标的检测效果不佳。由于YOLOv7在遥感图像中存在的问题,本文将针对遥感图像中存在大量背景信息、目标特征提取困难等角度对YOLOv7模型进行优化。首先,为了模型能够完整地提取遥感目标的特征,本文通过结合层内特征图的关系,使用集中特征金字塔获取目标的完整特征信息;其次,为了加强模型对待检目标的关注度,并且为了不影响整个模型的性能,本文结合卷积与自注意力机制组成一种混合注意力模块,提升模型对目标的注意力并且通过使用WIOU损失函数提升网络对检测目标的定位能力,进一步提升网络的检测能力。
因此,对于本文所提出的方法,主要工作分为:(1)由于遥感图像存在大量的背景信息而且待检目标尺度差异显著并且分布密集、相互遮挡,本文针对这些问题,对其进行优化,提出一种优化后的目标检测新网络。(2)对于优化的方法,首先结合全局语义与局部语义的思想,通过在YOLOv7网络的颈部使用集中特征金字塔,使网络充分地提取待检目标的特征;其次,为了加强网络对目标的注意力,通过在网络的backbone 中CBS 模块和尾部中使用混合注意力模块,在提升对待检目标的关注度的同时不增加网络的参数;最后通过WIOU 损失函数提升网络对检测目标的定位能力。(3)将改进后的YOLOv7模型在RSOD数据集上进行实验,最终结果表明,本文所改进的方法对aircraft、oiltank、playground 检测的Map相对于原YOLOv7提升了0.068、0.061、0.098。
1 YOLOv7算法介绍
YOLO 系列算法经历一系列迭代,目前最新版本YOLOv7是由Chien-Yao Wang等人于2022年7月提出。该算法主要由三部分组成:第一部分为输入端,输入端是尺寸为640×640三通道的RGB训练图像;第二部分是BackBone 主干网络,与之前YOLO 系列的主干网络不同的是,该版本的主干网络主要是由ELAN模块、MP模块组成,其中ELAN模块主要用于图像的特征提取和通道数控制,MP 模块用于保持输入前和输入后的通道数一致;第三部分是Head结构,该结构是由改进空间池化结构SPP 后提出的SPPCSPC 模块、PaFPN 结构以及输出端组成,该结构通过将高层特征图与底层特征图反复进行特征融合再进行特征提取,最后对生成的特征图进行预测输出。YOLOv7算法的网络结构图如图1所示。
在YOLOv7的网络结构中,采用的卷积核的大小有1×1和3×3两种,在Backbone主干网络中,为了不破坏原有梯度路径的前提下提高网络学习的能力,故YOLOv7提出了一种ELAN 模块,用于加强网络的特征提取能力;在进入到Head部分,网络依旧采用FPN与PANet思想,对生成的三个网络特征层反复融合再提取,最后生成了分别为20×20、40×40、80×80 的特征图分别用来检测图像中存在的大目标、中目标、小目标。
对于生成的特征图,YOLOv7依旧延续YOLO系列的方法去进行类别预测,首先将生成的特征图分为S×S个网格,对于每个网格用来检测物体中心点落入该网格的目标并计算三个目标预测框,对每个的预测框都有五个参数,分别代表框的中心的坐标(x,y)和高宽尺度(w,h)以及预测框的置信度(Confidence)。预测框的置信度代表当前预测框内是否有对象的概率,其计算公式如式(1)所示:
2 改进的YOLOv7网络结构
2.1 集中特征金字塔
对于背景复杂的遥感图像,因其背景范围较大且受光照因素以及图像中其他纹理形状类似的建筑以及检测目标相互遮挡的原因,导致YOLOv7网络对遥感目标特征的提取不够充分,造成YOLOv7对遥感目标的检测效果不佳。因此,本文通过在YOLOv7网络的颈部使用一种集中特征金字塔CFP[17]模块,来加强网络对遥感图像中目标的特征提取能力,如图2为该模块的网络结构图。
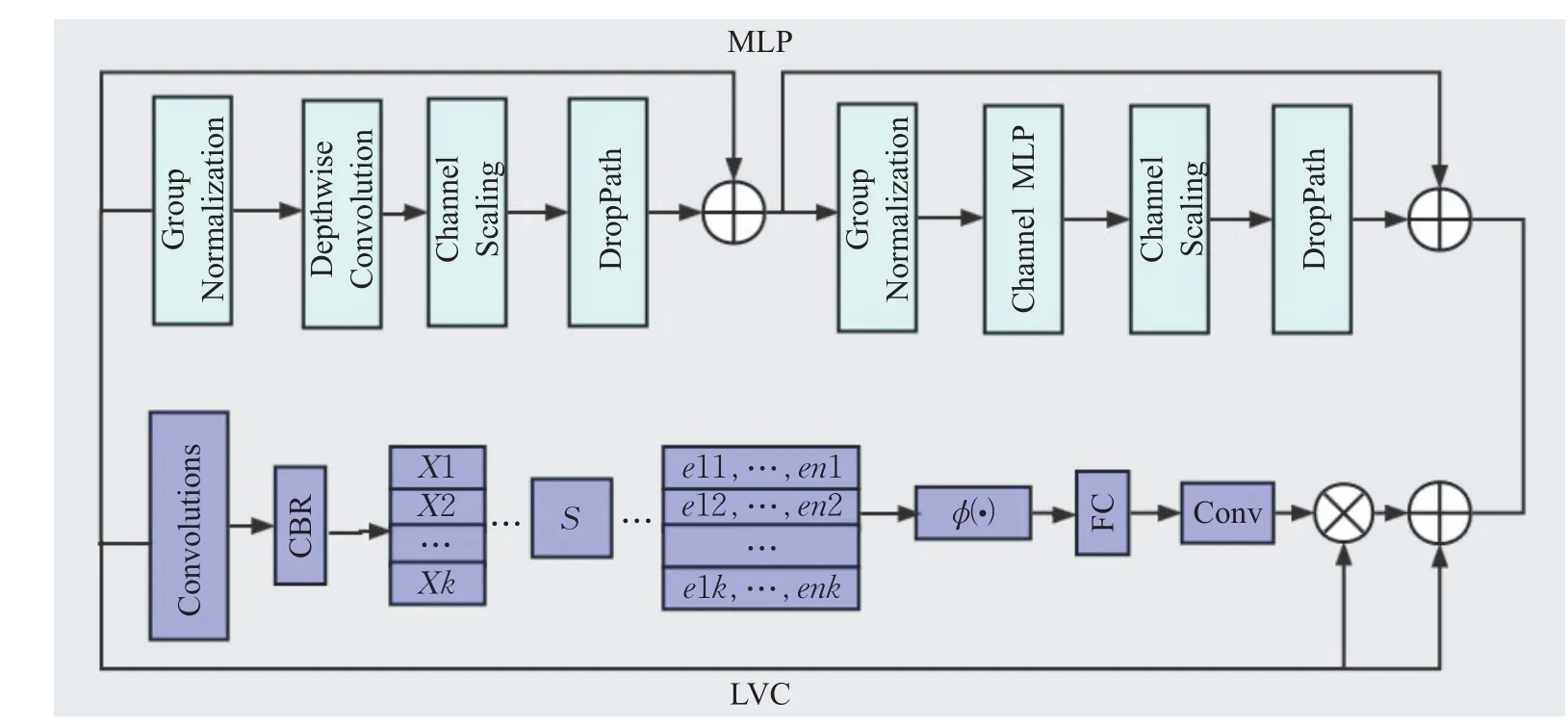
图2 CFP结构图Fig.2 CFP structure diagram
具体而言,在得到网络Backbone 部分输出的深层特征图时,将该深度特征图经过一个stem 模块平滑处理,对特征图上的噪声进行抑制,从而保留特征图的具体细节,之后输入到CFP 模块中,CFP 是由轻量级MLP与视觉中心LVC并行连接的模块而组成的,如图所示。对于CFP 模块中的MLP 而言,其作用是捕获全局的长依赖关系,使用该模块可以获得更全面、更准确的遥感图像中尺度差异较大目标的特征表示,从而提高目标的识别和分类的准确性以及更加准确地对目标进行一个定位。对于该过程可以用于式(2)表示:
对于LVC 而言,该模块主要是由卷积层、全连接层以及字典编码器组成。通过卷积层对输入特征进行编码,并使用具有归一化的卷积和Relu 激活函数组成的CBR模块对编码进行处理并输送到字典编码器当中,使用编码器能够获得关于编码的整个图像的完整信息,之后通过将编码器的输出馈送到全连接层和卷积层以预测突出关键类的特征。在遥感图像中使用LVC模块能够捕获图像的局部角落区域,通过该模块可以更好地辨别出遥感图像中需要检测的目标和那些与目标相似的背景和建筑,可以更好地找出需要检测的目标,而且对于遥感图像而言,需要检测的目标不一定在图像的中心,该模块还可以调整网络的关注的区域,避免出现漏检的现象,从而提高目标检测的准确性。对于该过程可以用于式(3)表示:
其中,Z的计算公式如式(4)所示:
最后通过并行连接MLP 与LVC 的输出结果,最终使得网络能够充分提取遥感目标的具体特征。为了使网络能够充分提取遥感目标的特征,这里通过将CFP模块嵌入到YOLOv7 网络中的颈部,如图3 所示,CFP 不仅通过NLP以全局的角度出发获取顶层特征图中目标的特征,而且还考虑了特征图的局部信息,从而使网络充分提取检测目标的特征信息,提高对目标的检测精度。
2.2 ACmix
对于遥感图像中的小目标而言,在检测该类目标时,往往会因为其特征的表现能力不足,并且分布的空间位置不定,检测网络极易忽略该类小目标,从而导致网络在检测过程中存在一些漏检误检的情况,因此需要使网络能够更加关注该类目标。而目前自注意力机制在自然语言处理(NLP)领域表现突出,于是注意力机制被引入计算机视觉领域,虽然注意力机制拥有较强的模型能力,但是缺乏归纳偏置的特性,所以其泛化性相对于卷积来说处于劣势。文献[18]为了结合transformer与卷积的优点,提出一种新的结构CoAtNet,受该文献启发,本文同样结合自注意力与卷积的优点引入一种新的注意力机制ACmix[19],该模块不仅能够加强网络对遥感图像中目标的敏感度而且还能降低由背景带来的噪声影响。如图4为ACmix的结构图。

图4 ACmix结构图Fig.4 ACmix structure diagram
首先通过将输入的特征图通过投影、分割后并在深度维度上进行连接,得到一组的丰富中间特征集对于采用卷积的路径,中间特征集先通过通道层的全连接对通道进行扩张,之后对其位移,再聚合成对应的维度。该路径能够很好地提取遥感图像中局部的特征信息,并将不同层级的特征进行融合,该路径最终能够得到H×W×C的特征输出。对于采用自注意力的路径,将中间特征聚合为N个组,每一组包含三个特征图并且每个组都是由不同的1×1的卷积产生的特征,之后将这三个特征图作为查询、键、值输入到多头自注意力模块中。该路径不仅从图像的全局考虑而且又充分关注目标存在的区域,该路径最终能够得到H×W×C的特征输出。最后,通过concat操作得到最终输出结果。
因此,原网络通过添加该注意力模块能够更好地关注重要的区域,同时也能关注到其他一些非重要的局部区域,如图5 所示,本文通过将该注意力模块嵌入到主干Backbone 中的CBS 模块以及主干Backbone 的末尾,让网络提升对重要区域内与非重要区域的目标特征的提取能力。例如对分布零散的飞机的注意力更大了,能够减少在检测过程中对飞机漏检的情况。
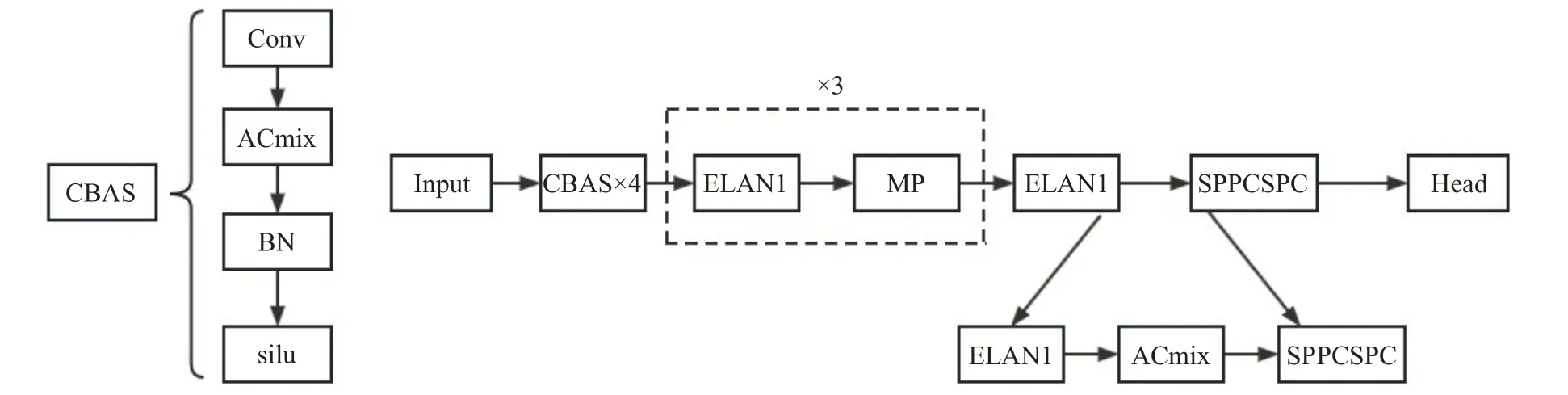
图5 ACmix模块嵌入示意图Fig.5 ACmix module embedding diagram
2.3 损失函数
在原YOLO7 网络中,计算预测框的坐标损失所采用的是CIOU[20]损失函数,其计算如式(5)所示:
虽然CIOU 对于大多数损失函数而言,其考虑了预测框的重叠面积、中心距离、高宽比,但通过上式可以看出当预测框与真实框重合时v=0,此时长宽比的惩罚项没有起到任何作用,并且在预测框的回归中,高质量的预测框一般而言要比低质量的预测框少得多,将影响网络的训练,于是受focal EIOU[21]损失函数的启发,提出动态非单调的聚焦机制,引入WIOU[22]损失函数。其计算公式如式(6)所示:
3 实验结果与分析
3.1 实验平台
本实验训练所用环境为Window10 操作系统,CPU处理器型号为Intel Xeon CPU,显卡型号为NVIDIA TITAN Xp,使用Python语言基于Pytorch框架搭建运行环境,并采用CUDA 11.6加速工具箱。
3.2 实验数据
本实验所用数据集为武汉大学于2017年所制作的RSOD遥感数据集。对于遥感数据集而言,由于其拍摄获取的方式都是由空中对地进行数据的获取,拍摄的角度、方式将使拍摄的目标特征与真实的目标特征不一致,从数据集中可以看出,这些检测的目标通常存在分布密集、大小不一,并且由于光照等因素,将导致数据的检测背景十分复杂,通过考虑数据集的大小以及设备因素,本文将选取RSOD数据集中的包含飞机、油管、操场的数据组成一个新的数据集进行研究。新的数据集总共包含800 张图片,总共7 263 个检测目标,其中飞机5 374个,油罐1 698个,操场191个,如图6所示,因实验考虑将数据依照6∶1∶1 的比例划分为训练集、验证集、测试集。

图6 数据示例图Fig.6 Data example figure
3.3 实验评价指标
在本实验中,对模型性能好坏的评估将采用平均精度率(mean average precision,mAP)和帧率(frame per second,FPS)作为实验结果的评估指标。平均精度率能够检测模型对待检目标的预测框类别和具体位置是否正确,该值是由精确率和召回率共同计算得出,其中精确率是指预测结果中,正确预测样本为正的样本数占总体预测为正样本总数的比例,召回率是指在正确识别的正例样本占实际的正例样本总数的比例。其计算公式如式(7)所示:
式中,TP为将正类预测为正类的数量,FP为将负类预测为正类的数量,FN为将正类预测为负类的数量。对于平均精度均值,是指所使用的数据集中每个类别平均检测精度(AP)的均值,其计算公式如式(8)所示:
式中,n为所有类别的数量,AP的值为召回率-准确率曲线下的面积。
对于另外一个指标帧率,该指标是来评价一个模型的检测速度,其数值越大,表明模型的检测速度越快。
3.4 实验结果分析
通过将原YOLOv7 网络与改进后的网络放在相同的实验平台进行实验,对网络中损失函数的收敛性和迭代过程中mAP值的变化进行对比验证,如图7为两种网络中损失函数loss随网络迭代次数的变化曲线。图8为两种网络的mAP随网络迭代次数的变化曲线。
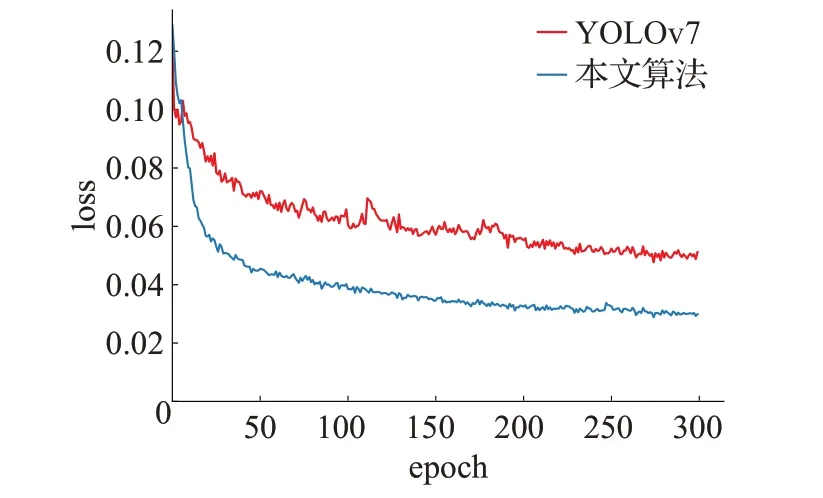
图7 模型的损失函数Fig.7 Loss function of the model
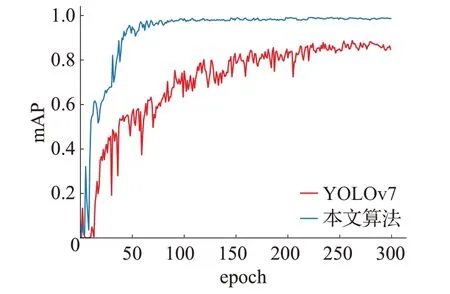
图8 mAP变化的曲线Fig.8 mAP change curve
从图7中可以看出,两种网络都随着迭代次数的增加最终都处于一个收敛的状态,但由图可以看出本文模型损失函数的值比YOLOv7的损失函数的值明显要小,其稳定性也要更高,因此使用本文改进的损失函数将能够提升网络的性能,使网络对边界框的损失更小。图8体现出本文改进算法能够很好地提高对检测目标的检测精度。
为了验证本文所使用的方法在遥感目标检测中的实际效果,本文在RSOD数据集上对改进的模块进行一系列的消融实验。如表1所示,√表示使用该模块。在表中YOLOv7_4、YOLOv7_5、YOLOv7_8分别对应的是添加WIOU、CFP、ACmix 模块;当针对网络的损失函数进行优化时,本文所使用的WIOU从整体效果来说要优于SIOU 和Facal IOU,相比较于原YOLOv7,三个待检目标的mAP 也得到了优化,整体mAP 提升0.007;而为了提升网络对待检目标的注意力,本文使用的混合注意力模块ACmix 相对于CBAM 和SimAM 这两个模块来说,分别提高了0.019、0.006,而对于原YOLOv7,则是提升了0.069;而使用集中特征金字塔CFP 从全局的角度提取待检目标的特征,从表中可以看出,使用该模块相对于原YOLOv7网络,提升了0.059;当同时添加WIOU,CFP,ACmix模块时即本文方法,可以看出,对三个待检目标的效果有明显的提升,相对于原YOLOv7 网络,本文方法整体提升了0.075。从整体上看,本文使用的方法相对于前面的方法,本文检测效果达到最好。因此,实验结果证明了本文所改进的方法在遥感图像目标检测上具有很好的效果。
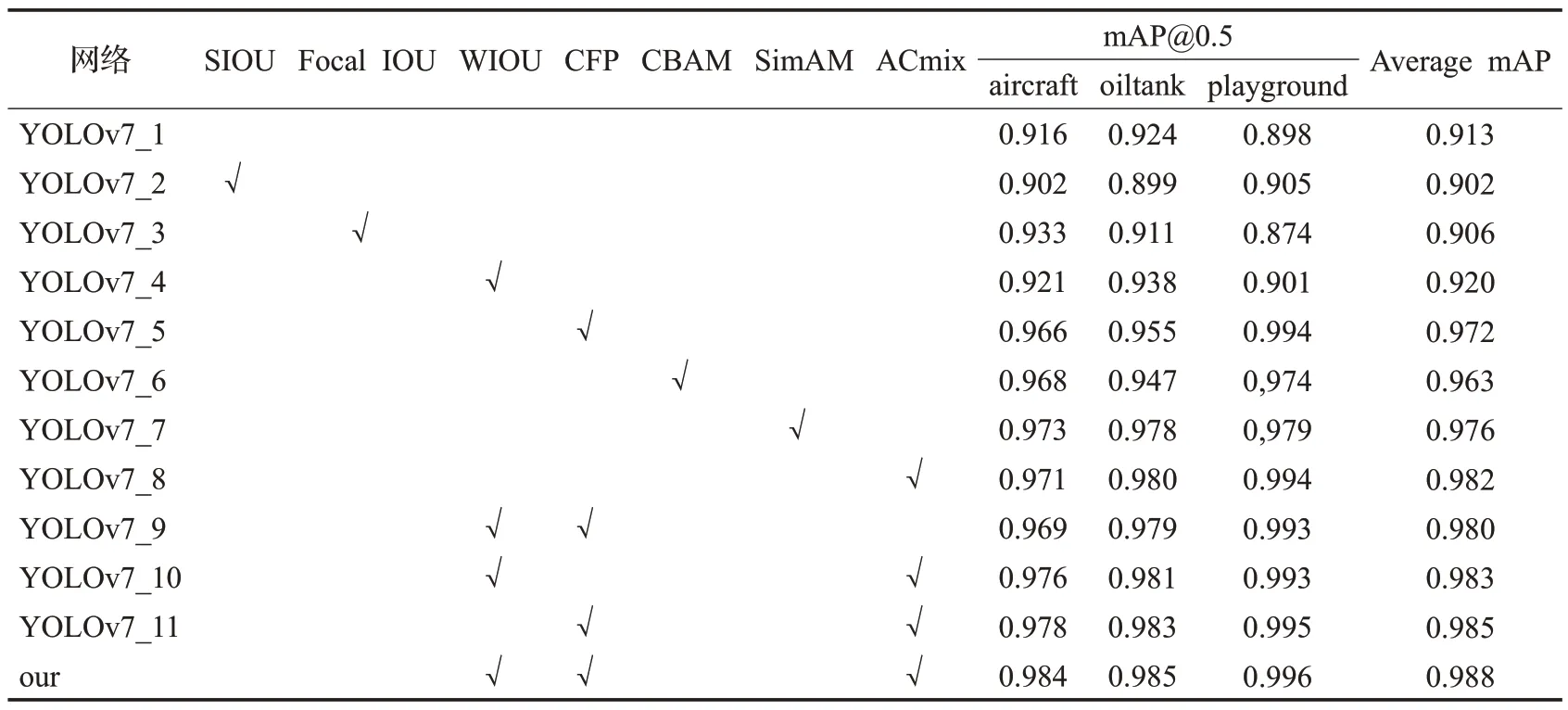
表1 不同模块精度对比Table 1 Precision comparison of different modules
3.5 实验对比
为了验证改进算法对遥感目标的检测性能,将改进的网络与原网络和具有代表性的网络如Faster Rcnn、SSD、YOLOv5、DenseNet-yolov3 等以FPS 和mAP 指标进行对比,其实验结果如表2 所示。从表中可以看出,虽然改进后网络的FPS 指标不及SSD、DC-SPP-YOLO等其他网络,但对于三个检测目标的mAP 值都达到了最好的效果。对于检测的三个目标,YOLOv7系列的网络相对于经典的YOLOv5 网络和优化的YOLOv3 网络而言,三个目标的mAP都有明显的提升,对于YOLOv5而言,原YOLOv7 对于aircraft、oiltank、playground 分别提升了0.015、0.025%和0.053,而本文改进后的网络在此基础上进一步提升了0.068、0.061 和0.098;对于其他研究人员提出的DenseNet-yolov3,本文改进后的网络对于aircraft、oiltank、playground 分别提升了0.12、0.109和0.08。而对于网络检测中的FPS,可以明显地看出,单阶段的检测算法要明显优于双阶段的检测算法,从表中可以看出,由于本文对原网络添加了改进模块从而导致本文改进的网络在检测效率略低于YOLOv7 和YOLOv5,但是总体而言,本文所改进的方法在检测精度方面可以更好地弥补这一缺点带来的影响。

表2 不同网络对比Table 2 Comparison of different networks
为了可以更直观地体现实验效果,分别使用YOLOv7和本文改进的方法对遥感图像进行可视化实验展示,其中包括在小目标、目标尺度差异显著以及背景复杂情况下的目标检测。图9 代表的是小目标并且相同类型的目标之间大小相差较大的aircraft 检测,从图中可以看出,本文改进的方法能够将尺寸极小和尺寸差异较大的aircraft检测出来,而原YOLOv7对于尺寸较小且特征不够明显的目标则会出现漏检的现象;图10 代表的是纹理背景复杂下的playground 检测,相较于YOLOv7 而言,本文算法同样可以将YOLOv7漏检目标全部检测出来,进一步提升检测效果。图11 代表的强光背景复杂下的oiltank 检测,对于该目标的检测,虽然原YOLOv7检测效果不错,但是本文算法检测精度更高,效果更好。因此可以说明,本文使用的方法能够很好地提高检测效果。
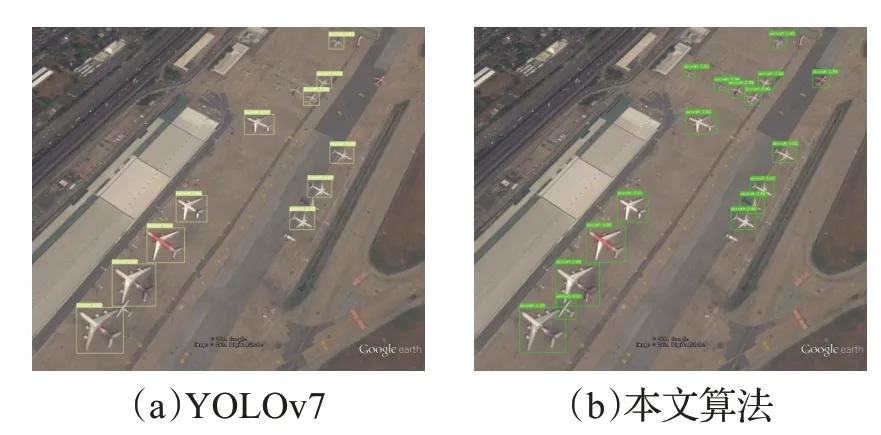
图9 小目标且目标尺度差异较大的aircraft检测Fig.9 Aircraft detection with small targets and significant differences in target scales

图10 纹理复杂背景下的playground检测Fig.10 Playground detection in complex textured backgrounds

图11 强光复杂背景下oiltank的检测Fig.11 Oilbank detection under strong light and complex background
4 结束语
在遥感图像中,因小目标的特征难以捕获,而且相同目标尺寸差异较大所处的检测背景复杂从而加大了检测任务的难度,因此,本文首先从全局的角度出发充分考虑角点区域,通过在网络中加入集中特征金字塔CFP,提升网络对背景复杂下的密集目标的检测能力;其次,为了同时拥有自注意力机制与卷积注意力机制的优点,本文在网络中引入新的注意力模块ACmix,增加网络对小目标的敏感度;最后通过使用新的WIOU损失函数,提升网络对检测目标的定位能力。通过将改进的网络在公开的遥感数据集中进行训练,通过最终的实验表明,改进后的网络要优于其他网络,实现了网络最终优化的一个目的。但在提升的网络中,当对于一些更加微小并外观特征特别接近于待检目标的非检测目标,网络存在一些误检、漏检的情况,接下来的研究方向是通过增加数据集,优化网络对于图像中密集小目标的检测能力。
