结合共现网络的方面级情感分析研究
2023-10-30孙天伟杨长春顾晓清谈国胜
孙天伟,杨长春,顾晓清,谈国胜
常州大学 计算机与人工智能学院,江苏 常州 213164
情感分析[1]中对在线评论进行细粒度情感分析的任务叫作方面级情感分析(aspect based sentiment analysis,ABSA)。换言之,它的目标是在于将一句评论中的方面词提取出来,进行一个或者多个方面的情感极性分析。举个简单的例子:“the food is good,but service is bad”,这句话中出现了两个情感词:good 和bad,但是这两个极性相反的词汇,是对两个词汇进行评价,good对应food,bad 对应service。如果仅仅对一句话进行情感极性分析是不够的,不正确的。因此提出了方面级情感分析,以此用来更严谨,更综合地分析评论。
关于方面级情感分析的研究,国内外已开展了很久。早期的研究人员使用传统的方法来获取情感特征[2],比如支持向量机(support vector machine,SVM)是根据语义特征、情感字典等信息来进行情感分类任务。然而,传统方法的局限性造成了例如泛化能力差、训练耗时耗力、性能瓶颈无突破等问题。
后来随着深度学习的发展,神经网络的模型被应用到方面级情感分析任务上并且取得较好的结果。如Nguyen等人[3]提出的PhraseRNN(phrase recursive neural network)模型,它将句子的依赖关系和组成树都融入ac-count,在分类任务上取得良好成果。之后注意力机制在NLP(natural language processing)领域获得广泛的关注,为更好地关联上下文信息,Bahdanau 等人[4]首次将注意力机制应用于NLP 领域中。Tang 等人[5]提出的深层记忆神经网络,构建多个注意力层来获取方面词的上下文关联信息。Wang 等人[6]提出基于双层注意力机制的LSTM(long short-term memory)模型,通过融合注意力机制,并加入注意力权重参数。Ma等人[7]使用结合注意力机制的交互网络获取方面词与上下文之间的关系和权重。将注意力机制融入进神经网络的方法在方面级情感分析上取得不俗的效果,但上述所提到的模型都没有考虑句子间的句法依赖关系,例如:“So beautiful was the dress but ugly skirt”,根据注意力机制,显然对dress而言,观点词ugly比beautiful更接近,使得ugly与dress两个词关系更加密切。因此这导致了注意力机制在注意力权重计算方面很难得到合适的数值。
随着图神经网络(graph neural network,GNN)的广泛应用,有学者将其与句法依赖关系相结合运用到方面级情感分类任务中,Zhang 等人[8]利用图神经网络通过句法依赖关系来获取信息。Jindian等人[9]使用句法依赖关系,提出基于语法距离和语法距离权重的方法。Rakhlin 等人[10]使用图卷积网络(graph convolutional network,GCN)学习每个节点的特征,再融合注意力机制构建模型。Xue 等人[11]考虑文本中多个方面词的情况,提出了一种可以考虑不同方面词之间的情感联系的方面级情感模型。虽然句法依赖关系与图神经网络相结合的做法已经取得了一定的效果,但这些方法所使用的句法依赖关系对单词之间的关系表达都有欠缺,特别是对词汇间的共现依赖关系。
句法学[12]中认定句法关系有三种,位置关系,替代关系和共现关系。本文所提到的共现关系是指一个句子或句子级中的某个特定组合是由集合中的词汇与该集合的另一词类或集合的词组成而成。简单来说,一般人们认为,在一篇文章中出现的两个人物之间一定具有某种关联。将这一定义应用到方面级情感分析上,一条评论中的两个词之间可能会有某种关联,这种关联是通过统计足够多的相关领域评论后,若两个词在一条评论里同时出现的频率高于一定值,那这两个词就有共现关系,譬如这样一条评论:The restaurant is okay,nothing special。将它交给现有的工具处理,restaurant将和okay相关联,但是nothing 和special 与restaurant 之间就不会有太多的依赖关系,这就产生错误的分析。如果将共现网络考虑进去,nothing special 将会以一个共现词汇对的形式进行分析,这样nothing special 就会作为第二个观点词与restaurant产生依赖关系。
综上所述,本文提出了一种融合共现网络的模型,将其应用在方面级情感分类任务中。在句法依赖关系上,以方面词作为焦点,利用单词共现关系作为辅助信息重构句法依赖关系,再采用词嵌入方法将句法依赖标签映射为向量。其次利用关系图注意力网络聚合邻域范围内单词的特征信息,再通过多头注意力层将标签信息与关系信息相融合,获得最终的分类情感特征。为了评价本文的模型,本文选择使用三个公开数据集,其中两个是SemEval 2014 任务中的Restaurant 和Laptop 数据集,还有一个是Twitter数据集对模型进行实验,实验结果表明本文模型的准确率与F1值均有提升。
本文贡献如下:
(1)利用相关算法分析出单词共现信息,在以方面词为焦点对象的前提下,重新定义句法依赖关系标签以及句法依赖结构,以弥补原始句法依赖关系忽视方面词与共现词汇对之间句法关系的缺点。
(2)使用关系图注意力网络聚合领域间的单词信息,再将依赖关系向量与依赖标签向量相结合,通过多头注意力层实现情感分类。
1 相关工作
方面级情感分析是情感分析领域的一个分支任务,近些年来神经网络在文本领域迅速发展,尤其是文本分类,情感分析领域。Kim[13]为解决句子级分类任务,利用卷积神经网络模型。Kaljahi等人[14]为解决情感分类问题,使用双向长短期记忆网络(bidirectional long short-term memory network,Bi-LSTM)。Kombrink 等人[15]提出层次化RNN用于文本分类。Peng等人[16]结合Bi-LSTM与2 个DNN 构建了一个混合架构模型。但随着模型的叠加,当文本过长并且网络模型过深时,会导致计算时间过长,计算量大等问题,并且文本过长导致模型不能捕捉到较远的意见词与方面词之间的情感联系,注意力机制应运而生。Wang 等人[6]将LSTM 模型融合注意力模型。Tang等人[5]提出具有多跳注意力(Multi-hop)和外部记忆的记忆网络模型。Ma 等人[7]提出一种方面词与上下文交互的注意力神经网络模型。Fan等人[17]提出多粒度注意力网络模型,用于情感细粒度分类任务。Wei等人[11]提出了一种基于CNN 和门控机制的模型,可以根据门控机制,通过给定的aspect 选择性地输出情感特征,并且模型可以并行训练,收敛速度快。之后随着预训练语言模型在自然语言领域内的应用,如谷歌的预训练语言模型Bert[18],在方面级情感分析上也取得不错的效果。
方面级情感分析对句法关系更为关注,最近图神经网络与句法依赖关系相结合的方法取得了不错的效果。Zhang等人[8]提出使用图卷积神经网络从句法依赖关系学习特征表示,并融合其他类型的特征用于方面级情感分析任务上。之后在图卷积网络的基础上提出图卷积记忆网络,更好地利用文本中单词之间的句法信息。Zhang 等人[19]提出全局词汇图的想法,将全局词汇图与层次句法图相融合,以此来处理词汇间不同关系。Wang等人[20]提出R-GAT(relational graph attention network)模型,利用句法依赖关系重构的方法,将方面词作为root,提出新的n:con关系替代原来的依赖关系,加强与方面词语法距离相近单词的重要性,运用多层图注意力网络结果取平均的方式,学习到最终的情感特征向量。其依赖树结构如图1所示。

图1 R-GAT模型的依赖树结构Fig.1 Dependency tree structure of R-GAT model
本文的模型是基于R-GAT 模型的改进,不同于RGAT模型,本文的模型着重于依赖树的重构,在R-GAT的基础上,修改原先模型的剪枝算法,补充定义句法依赖标签,补充共现词汇对与方面词之间的依赖关系。通过在多个数据集上实验证明,本文提出的方法取得更高的准确率。
2 融合共现网络的模型
本文模型由文本嵌入层、句法重构层、关系图注意力网络层、多头注意力层,情感分类层五个层组合而成,模型结构图如图2 所示,假设句子由n个单词组成,则句子可以表示为s={w1,w2,…,wn},方面词为{wt,wt+1,…,wt+k-1},其中t表示方面词在句子中的开始位置,k表示方面词的个数,t+k-1 表示结束位置。
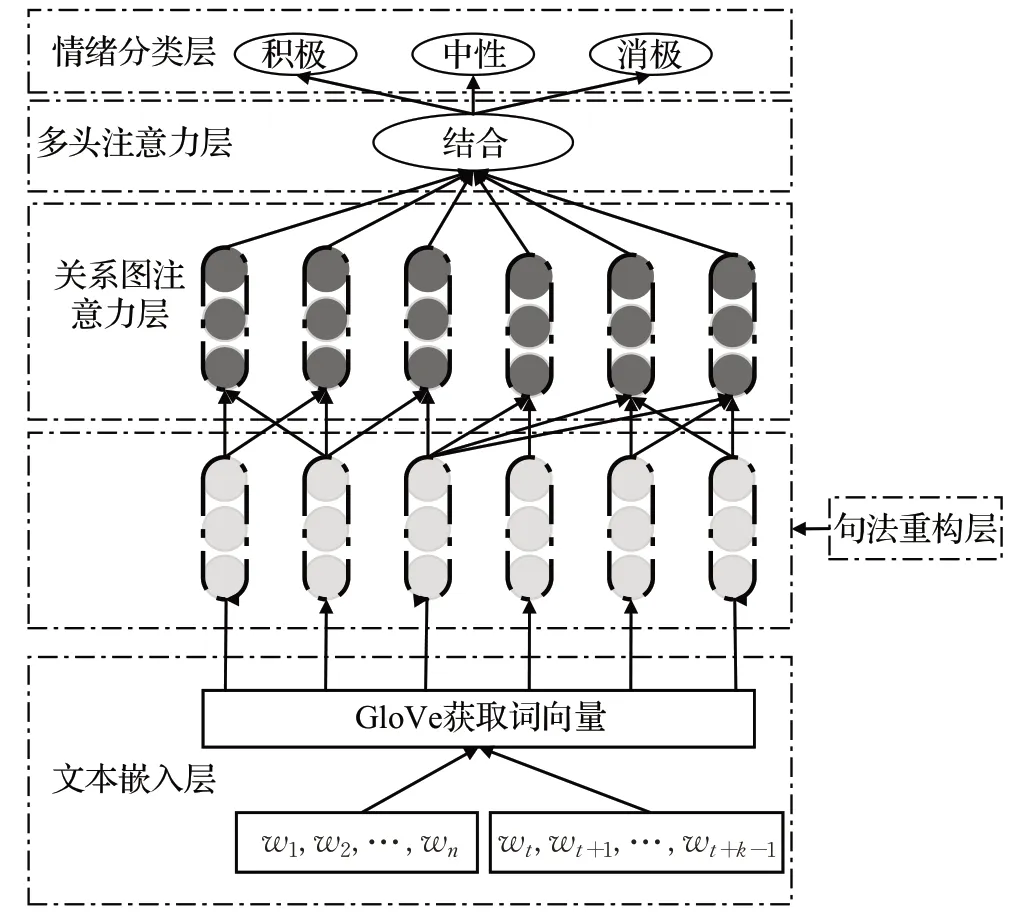
图2 模型的框架图Fig.2 Frame diagram of model
2.1 文本嵌入层
传统的NLP邻域中进行词向量表示一般有两大类:全局矩阵分解方法(例如LSA[21])和局部上下文窗口方法(例如skip-gram[22]),但这两类方法都有明显的缺陷。全局矩阵分解方法不是最优的向量空间结构,而局部上下文窗口方法很少利用语料库的统计数据,因为它们在单独的局部上下文窗口上训练,而不是在全局共现计数上训练。
本文利用Glove[23]模型来获取句子中每个单词的词向量,与全局矩阵分解方法和局部上下文窗口方法不同,Glove不对单个上下文窗口进行训练,而是只训练词与词构建的共现矩阵中的非零元素,这一做法有效地利用了统计信息。
2.2 句法重构层
一个句子的句法结构表示为句法依赖关系,单词之间通过有向边与依赖关系标签表示。利用句法分析工具获得每个句子的原始句法依赖关系,例如句子“The restaurant is okay,nothing special”,处理后结果如图3所示。
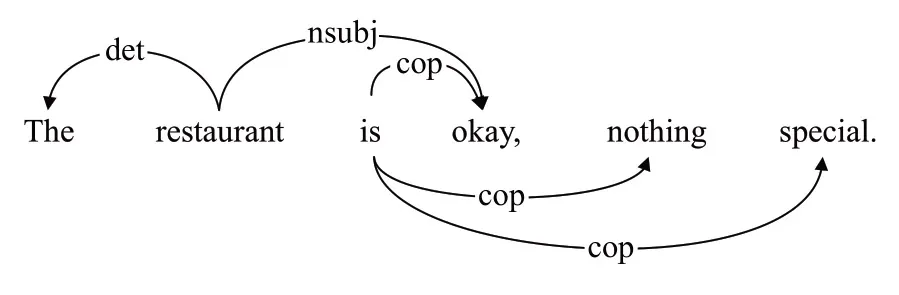
图3 重构前的句法依赖关系Fig.3 Syntactic dependencies before refactoring
为了弥补初始句法树的不足,本文将共现网络融入句法树的重构中,按照句法关系认为,句子中两个单词同时出现的频率若大于等于n(n为超参数),则这两个词汇间有着共现依赖关系。与工具得到的初始句法依赖关系相比,不同点在于,不光保留方面词与词汇之间的关系,而且考虑那些共现依赖权重大的词汇,即对于共现频率大于n的词汇对可以保留。通过共现算法得到“nothing”与“special”之间存在共现关系,重构后的依赖树如图4所示。

图4 重构后的句法依赖关系Fig.4 Reconstructed syntactic dependencies
同时给出重构前后的词汇图进行对比,其中acomp为形容词的补充,amod 为形容词,dep 表示二者有依赖关系。图5(a)中nothing special 之间无特殊依赖关系,图5(b)中经过共现网络处理后,nothing 和special 由于存在共现关系,因此二者之间产生依赖关系。根据图4所示,将二者句法依赖关系定义为tog。

图5 重构前后的词汇图对比Fig.5 Comparison of vocabulary diagrams before and after refactoring
本文在获取句法依赖关系集合R之后,利用重构句法依赖关系算法,对原始句法依赖关系R进行重新构造,同时构建共现词汇对列表T,并且删除语法距离过远的句法依赖关系标签,保留T中权重值大的依赖标签,给予共现关系更多的重要性,重构句法依赖关系算法流程如下所示:
算法1重构句法依赖关系算法
其中构造共现词列表的算法如下所示:
算法2构建共现词列表
2.3 关系图注意力网络层
为聚合邻域内所有节点的信息,图注意网络基于图神经网络,引入多头注意力机制,通过不断地迭代方式来更新每个节点的表示向量,实现邻域内节点的权重分配功能。公式如下所示:
图注意力网络可以聚合某个节点的邻域节点的信息,并沿句法依赖路径来更新此节点的向量表示,如图6所示。
图中以句子“the restaurant is okay,nothing special”为例,使用图注意力网络沿着句法依赖路径更新单词向量,并结合注意力层输出的句法依赖关系标签权重参数,最后将更新后的词向量与文本向量交互融合,得到最终的向量作为情感分类层的输入。
2.4 多头注意力层
图注意力网络可以根据句法依赖关系更新单词向量表示,但是并没有考虑句法依赖标签的作用,因此在关系图注意力网络层中,拼接单词向量时结合注意力机制模块,将重要的单词和依赖关系标签分配更高的权重值,如图7所示,使得模型更加关注权重。计算公式如下:

图7 多头注意层Fig.7 Multi-head attention layer
hti表示依赖标签向量,hri表示依赖关系向量。
2.5 情感分类层
方面级情感分析与一般情感分析一样,属于多分类任务,情感分类层的输入为关系图注意力网络层的输出hα,每个情感标签的概率为p,计算公式如下所示:
其中,Wp和bp为可训练参数,result ∈{积极,中立,消极}。
3 实验结果与分析
3.1 数据集
本文选取三个数据集,分别是Dong[24]等人构建的Twitter 评论数据集和SemEval2014[25]数据集,其中SemEval2014 分别为Restaurant 数据集与Laptop 数据集。三个数据集都是自然语言处理任务中的细粒度情感分析论文中广泛使用的公开数据集,每个数据集中都包含若干评论文本,每条评论语句中包含有着多个方面词以及相对应的情感类型。设置三种情感极性:积极,中立和消极。数据集详细信息如表1所示。
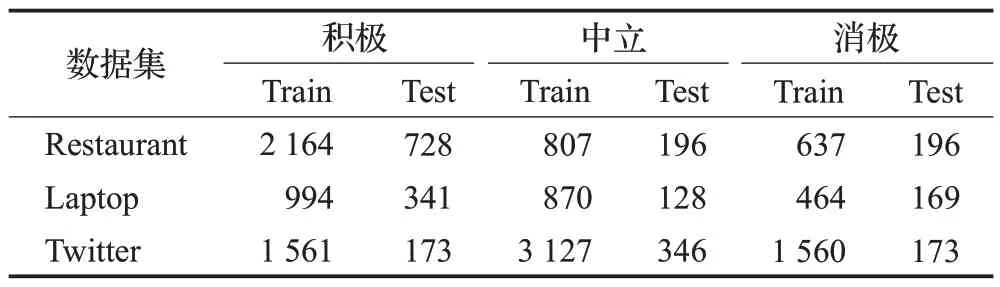
表1 数据集统计Table 1 Dataset statistics
3.2 评价指标与目标函数
本文的评价指标选择准确率、F1 值以及训练每个epoch所花费的时间,标准交叉熵损失用作目标函数。
其中,N表示文本数量,c表示真实的情感极性,c表示预测的情感极性。θ表示可训练参数。
3.3 超参数设置
训练优化器使用Adam优化算法,为避免梯度爆炸或者消失,设定梯度最大范数为1.0。Learning rate设置为10-3。句法依赖关系标签嵌入选择Word2Vec。为防止模型出现过拟合的状况,设置Dropout 值设置为0.1,随机种子设置为2 022,激活函数为Relu。
3.4 基准模型
采用一些用于情绪分析的主流模型进行比较,优化器等参数设置与本文模型一致,所采用的基准模型有:
(1)AS-GCN[24],该模型建立图卷积网络,利用句法信息和单词依存来构建句子依赖树。结合注意力机制与卷积神经网络进行分类。
(2)Bi-LSTM[14],双向长短期记忆网络,在情感分析领域应用广泛。
(3)GAT[25],图注意力网络是对图上的每个节点都进行注意力运算,再将邻域内的节点加权求和。
(4)R-GAT[20],关系图注意力网络是对GAT 模型的改进,以方面词为根节点,考虑方面词与观点词关系,并且对解析树进行筛选,减少计算成本。
(5)GCAE[18],一种基于CNN和门控机制的模型,可以根据门控机制,通过给定的aspect选择性地输出情感特征,并且模型可以并行训练,收敛速度快。
(6)Bi-GCN[19],构建全局词汇图,与句法图相结合,以区分不同类型的依赖关系和词汇对。
3.5 实验结果与分析
对比实验结果统计如表2 所示,模型以准确率(Accuracy)与F1值作为评价指标,实验结果显示本文模型在三个数据集上的准确率均高于其他基准模型。F1值虽然在Laptop 数据集上略低于R-GAT 模型,但差距不大。这是因为一方面Laptop数据集的数据量少,而共现网络是基于数据集构建的共现词汇列表,数据量越多,共现关系构建得越精准。另一方面,共现关系是无向的,它是对依赖关系的补强,若数据集情感标注准确,情感词显著,增加共现关系能增强精准度。通过分析数据集,Laptop数据集相较于其他两个数据集中有更多的隐式情感的样本,这些样本没有明确情感词,因此需要外部判定。但在训练Laptop数据集时,由于数据量的匮乏,构建出的共现词汇列表缺乏完整性和精准度,从而导致F1值下降。从表2实验结果可以看出,训练时间方面,Bi-LSTM 的训练时间最长,本文模型在与其余算法的训练时间相当。虽然本文模型需要计算是否存在共现依赖关系,以及结合依赖关系和依赖标签,通过多头注意力层输出情感特征,但这不会明显增加训练时间成本。这一实验结果表明了本文算法的实用性。
通过分析,Bi-LSTM模型考虑输出与输入的上下文状态,充分联系了上下文,但是对于方面级情感分类任务,因为不能考虑方面词的因素,所以效果不佳。ASGCN模型是面向方面级情感的模型,其思想就是先用LSTM 获取词序的上下文信息得到的输出接入一个多层图卷积结构,通过屏蔽掉非方面词再反馈给LSTM,结果可证明,方面级情感分析性能更好。GCAE模型是基于CNN 与门控机制的,它是对注意力网络的一种改进,通过门控机制对不同方面有选择性地输出情感特征,并且由于CNN 没有时间依赖,门控机制也独立,因此模型可以并行计算,时间成本相应减少。Bi-GCN 是通过构建全局词汇图与句法图相融合,可以处理不同的依赖关系,结果证明,全局词汇图的构建对模型性能是有提升的,但由于词汇图与句法图需要协同工作,计算复杂度提升,时间成本耗费高。GAT模型是图注意力网络,它将输入图的所有节点都进行注意力的计算,不依赖于图的结构,对节点归纳的计算任务很优异,但是缺点在于完全丢弃了图结构这个特征,最后的效果会大打折扣,其次由于GAT是逐顶点计算,因此所需要的运算成本非常高昂。R-GAT是在GAT模型的基础上提出了一种面向方面级的树结构,充分考虑图结构特征,可以看出这种做法是很有效的,它相比GAT 构建的依赖树而言,R-GAT面对方面词所采取的是一个方面词构建一棵独立的依赖树。并且与GAT将观点词作为根节点构建依赖关系不同的是,R-GAT是将目标方面词作为根节点,向外扩展依赖关系。结果证明,R-GAT 的性能更加优异,说明面向方面词构建依赖关系是更有效的。
本文模型的准确率在三个数据集上均高于R-GAT模型,分别提高了0.72、0.94、1.30 个百分点。因为原始依赖树的构造忽视了词汇对之间的共现依赖关系,而共现关系在NLP领域中是个很重要的思想,它表示了两个词汇在所给文本范围内,同时出现的概率。由于这种共现概率,因此认为这两个词汇之间是有着很强的依赖关系。而不光GAT 还是R-GAT 模型构建依赖关系的时候,都忽视了共现关系,它们二者更多地关注于观点词,与方面词有直接依赖关系的词汇,对于其他词汇的关注很少。本文所考虑的是挖掘那些未考虑的词汇之间的关系,通过反复实验发现,若将共现关系融入模型,可以挖掘更深层次的依赖关系。以“the restaurant is okay,nothing special”再举例,GAT 和R-GAT 会将其构建成“restaurant”与“okay”,“restaurant”与“nothing”以及“restaurant”和“special”三种依赖关系,模型会把okay作为情感极性词,导致情感分类成积极。而本文模型会将“nothing”与“special”之间构建联系,使二者成为一组词汇对。在依赖关系方面,除了刚刚提到的三种关系之外还补充了“restaurant”和“nothing special”之间的关系。再通过多头注意力层,给予共现关系一定的权重,使得模型能够正确把例句分类成消极情感。实验结果和理论逻辑均可证明,这种方法对模型的性能带来的影响是优异的。
本文提出将共现网络融入模型,重构句法依赖关系以及依赖标签,为验证共现网络对模型的影响以及共现网络阈值的设置是否会产生影响。首先要考虑数据集的应用,通过分析发现,Restaurant、Laptop 以及Twitter数据集中所包含的句子总量相差不大,因此以Twitter数据集为例,做了对比实验,如图8所示。
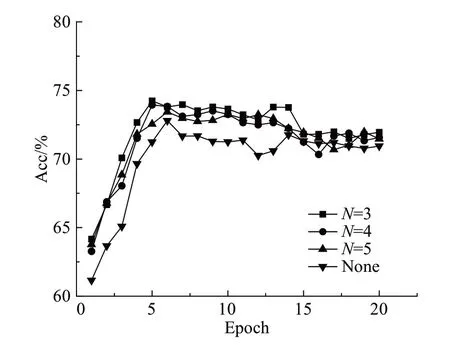
图8 共现网络阈值实验Fig.8 Co-existing network threshold experiment
N表示共现网络的阈值,即词汇对的共现频率大于等于N,None 表示没有结合共现网络,由图可知,当N=3 时,模型的性能最优,当N≥3 时,由于阈值的增加,保留的共现依赖关系分支将会减少,阈值越高造成重构后的依赖关系与重构前的差距缩小,这会导致模型性能的降低。当模型不融入共现网络时,由图可知,模型性能下降明显。由于共现词列表是根据数据集而产生的,因此如果数据集的数据量发生变化,则N所设的值也会随之改变,但对于本文所采用的三个数据集而言,N=3 的效果最好。综上所述,本文选择阈值为3的共现网络。
为验证注意力层是否会对模型性能造成影响,本文将模型的注意力层分别替换成全连接层,单注意力层(传统的注意力机制)以及多头注意力层,以Twitter数据集为例,进行对比实验,如图9所示。
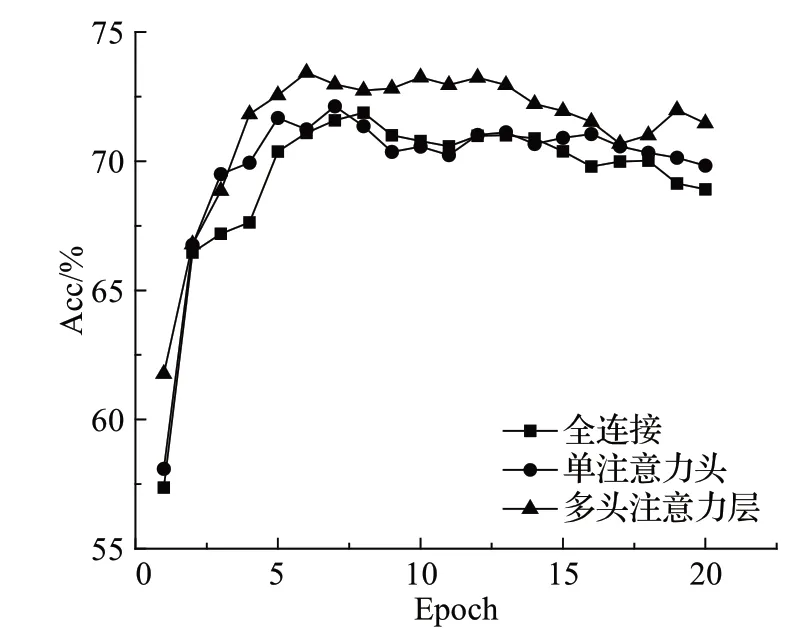
图9 注意力层对模型的影响Fig.9 Effect of attention layer on model
由图可知,单注意力头层因为没有运用到依赖标签,只考虑依赖关系向量,与使用全连接层相比,有提升但是效果不大,二者平均准确率相差不超过0.5%。经过分析,这与方面级情感分类任务有关,虽然剪枝过程中会剪掉与方面词距离过远的关系,对于方面词相关的内容给予更多的权重,但是很多句子中会有多个方面词,每个方面词都有自己的依赖关系,这将导致句子中更多的词汇都给予注意力,因此与全连接相比,会有不大的提升。而多头注意力层,是结合依赖关系向量与依赖标签向量,对一些重要的依赖标签,例如本文所提到的共现关系标签,给予更高的权重。结果证明,多头注意力层对实验性能提升明显。
3.6 消融实验
为了测试不同句法分析器对实验最终结果的影响,进行了消融实验。由表3可知。使用Biaffine分析器会得到更高的情感分类准确率。

表3 不同解析器的实验Table 3 Experiments with different parsers 单位:%
为验证不同词向量对准确率的影响,分别采用Word2vec 和Bert 进行消融实验,并且以Twitter 数据集为例,统计训练时间。实验结果如表4所示,Bert模型的效果很好,但复杂度太高,所以训练时间成本太高。本文模型采用的Glove 词向量与Word2vec 相比,效果更好,并且训练所用的时间更少,这是因为一方面Glove利用了全局信息,因此训练时收敛更快,另一方面Glove词向量事先统计了语料库里固定窗口内的词共现频次,与Word2vec 通过滑动窗口提取特征相比,更符合本文模型中结合共现算法的思路。Word2vec 与Glove 的效果没有太大区别,但由于Glove的复杂度与数据集规模无关,有更好的适用性,并且操作时利用了共现思想,综上所示,本文采用Glove词向量。
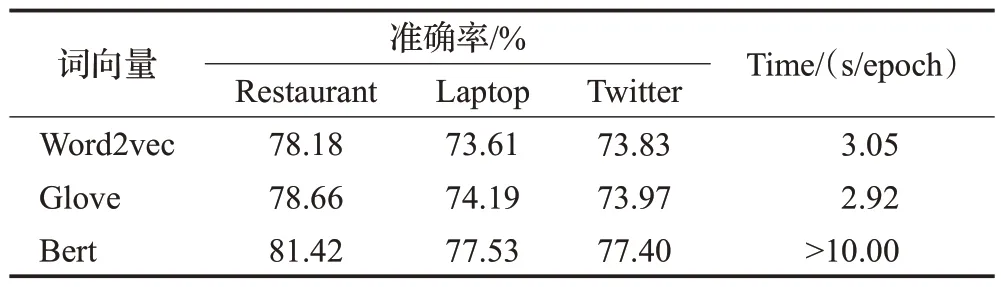
表4 不同词向量的实验Table 4 Experiments with different word vectors
4 结束语
本文提出了融合共现网络的图神经网络模型,该模型的创新点在于重构句法依赖关系,添加共现依赖关系。首先通过Glove模型获取语义特征,结合重构后句法依赖关系,通过图注意力网络聚合每一个单词节点的邻域单词节点的语义信息,再将句法依赖标签与句法依赖关系融合交互,通过多头注意力层得到与方面词相关的情感语义特征,最终实现情感分类。
本文使用SemEval2014 的Restaurant、Laptop 数据集和Twitter 评论数据集,实验结果显示,最高准确率分别达到78.66%、74.19%、73.97%,均比当前主流模型的指标优异。
在未来工作中,将考虑制作全局词汇图与模型相结合。同时发现现有主流模型对局部特征没有充分考虑,接下来会研究模型结合局部特征强化模块。
