多尺度CNN卷积与全局关系的中文文本分类模型
2023-10-30宋中山
宋中山,牛 悦,郑 禄,帖 军,姜 海
1.中南民族大学 计算机科学学院,武汉 430070
2.湖北省制造企业智能管理工程技术研究中心,武汉 430070
3.农业区块链与智能管理湖北省工程研究中心,武汉 430070
近年来互联网、媒体等行业飞速发展,新闻已经成为了人们了解相关的实事动态、获取相关的社会热点信息的重要途径之一。报纸、新闻杂志等相关纸质新闻文档逐渐向电子化的新闻数据转变。面对互联网产生的海量新闻数据,对其进行快速自动分类,不仅可以实现对新闻文本数据高效的管理,而且在信息检索、新闻秩序的实现、新闻数据的挖掘等方面也有非常重要的作用。
当前,汉语在世界语言体系占有举足轻重的地位,然而,对中文新闻数据分类远不像对英文新闻数据分类那样多。一方面原因是中文新闻数据的语料库相对较少,另一方面是中文相对英文来说结构更加复杂,进行分类时所要考虑的因素比较多。例如,在中英文数据的预处理阶段,相比于英文文本,中文新闻数据的读取需要额外进行分词操作。这也成为了中文新闻数据分类发展相对缓慢的原因之一。
由于中文的结构相对复杂,对于中文新闻分类来说,需要将新闻文本先处理成为计算机能够识别的数据,即先对原始数据进行词向量表示。然后再通过训练模型,提取到有用的特征信息后再利用分类算法进行新闻数据的分类。
随着神经网络的发展,以CNN[1]网络结构为基础而提出的新闻数据分类模型大多都是通过训练模型使之能够学习窗口的局部信息,然后通过局部窗口滑动提取特征进而进行类别的划分。但CNN模型也暴露出了一些问题,CNN忽略了局部信息之间的依赖特征。因此,本文从该角度出发,提出了一种多尺度的双层CNN 和BiLSTM 注意力机制的融合模型(TCNNRes-BiLSTMAttention,TCBA),该模型从文本序列的前后方向获取上下文特征的同时结合双层的多尺度卷积结构。一方面采用双层的TCNN网络进行密集连接,同时通过跳跃连接的方式加深CNN 网络的总体结构,对原始文本与获得的局部特征进行二次卷积以加强局部信息的依赖关系,从而能够提取更丰富的局部特征信息。另一方面将改进后的模型多尺度双重卷积(TCNNRes)结合双向长短时记忆网络[2(]BiLSTM)和注意力机制联合提取新闻文本特征,最后进行特征的融合,再输入进全连接层进行新闻数据的分类。最后采用新浪新闻RSS 订阅频道的公开新闻数据集THUCNews 的新闻主题进行实验,以验证本文模型通过提升局部特征提取能力从而提升准确率的可靠性。
本研究通过优化模型、尽可能利用模型独特优势来提升分类效果,研究内容如下:
通过表4还可以看到,不同基质处理下的根长差异显著。6个景天品种茎段插条在粗砂、珍珠岩、草炭等比混合基质中最长平均根长达6.7cm。珍珠岩和纯草炭基质中对景天茎段扦插生根的根长影响稍低于粗砂、珍珠岩、草炭等比混合基质。本实验中景天扦插平均根长在粗砂表现为最低3.8cm。由粗砂、草碳、珍珠岩混合的基质相比较于单种基质,在基质的通气性、保水、保肥能力方面得到加强,因而在景天插条的平均根长、平均生根数、平均株高等方面都表现出增加的状况。
TCBA 模型在TCNNRes 层和BiLSTM 注意力机制通道均设置为300 维度的词向量,设置dropout 数值为0.5,模型采用ReLu 激活函数以加快TCBA 模型的收敛速度,设置损失函数为交叉熵损失,Epoch为100,每轮输入句子的批量大小设置为128,具体参数如表3、表4所示。
(2)用改进的多尺度双层CNN 和BiLSTM 提取局部信息和全局上下文特征,同时对BiLSTM添加注意力机制使之关注重点单词特征。
(3)将提取到的新CNN 模型特征与BiLSTM 注意力模型进行特征融合,得到最后的特征向量进行文本分类。
那么教师“支架”能起到哪些作用?什么样的教师“支架”才更有效?影响教师“支架”起作用的因素有哪些?本文试图从社会文化理论视角并基于先前实证研究结果对这些问题进行探讨。
1 相关工作
文本分类是自然语言处理的常规任务,也是近些年来重点研究内容之一。文本分类任务就是将海量的文档通过现有的一些方法或手段将它们分成一个或者多个类别。文本分类技术在问题回答、垃圾邮件检测等都有应用。其最核心的内容就是从文本中抽取出最关键的特征信息,然后将特征映射到对应的类别。
传统的提取文本特征的方法主要有基于规则和统计的方法、利用机器学习的方法以及近些年在文本分类领域表现更好的深度学习方法。Jones等[3]利用词频-逆文本频率指数将文本数据进行向量化表达后再结合逻辑回归和支持向量机(support vector machine,SVM)进行建模。Ruan 等[4]提出了一种通过对距离相关系数进行改进,从而改良朴素贝叶斯分类器的方案,与传统随机向量累积分布函数的相关统计度量不同,该方法通过描述联合特征函数与边缘特征函数乘积间的距离来检验随机向量的联合相关性。Hindi等[5]通过改进KNN模型,提出了一种基于反向比级距离度量(ISCDM)和基于数值距离度量(VDN)的新方法,该方法更适用于以词频表示向量的文档。这些方法虽然可以在某些方面提高分类的效果,但由于需要手工提取文本特征同时又忽略了特征之间的关系,但随着深度学习不断发展,这类手工提取文本特征的方法逐渐被自动提取文本特征的方法所取代。Fesseha等[6]通过构建不同的CNN模型等来评价新闻文章,从而实现了对“低资源”语言的分类研究,提高了新闻分类的精确率。有些学者希望能够通过改进CNN 模型来提高该模型提取长距离信息的能力。Kalchbrenner等[7]提出了动态卷积神经网络模型,该网络使用一种线性结构化的全局k-Max池,利用生成的特征图使该网络在处理变长文本语句上能显示捕捉句子之间的依赖关系。循环神经网络(recurrent neural network,RNN)能够高效整合相邻近的位置信息,在许多自然语言任务中表现出色。RNN的一个变体模型长短期记忆网络[8(]long short-term memory,LSTM)通过对时间序列信号进行建模,使模型拥有“存储记忆能力”,能够捕捉语句的远距离的依赖信息,通过选择保存信息来克服RNN梯度爆炸和消失的问题。但LSTM在获得双向语义信息方面无法编码反向信息,因此很多与时序相关的NLP 任务都采用能获得双向文本语义关系的BiLSTM 网络。在此基础上,Zhou 等[9]认为BiLSTM不能准确地度量出每个单词的重要程度,因此,将BiLSTM与注意力机制结合处理文本分类任务,分别从前后两个角度提取上下文语义信息。
当前,文本分类领域中很多学者致力于研究神经网络的构建和优化,单一的神经网络模型结构都存在各自的缺陷。虽然很多学者通过改变BiLSTM 获取信息的流向或者通过增加卷积神经网络的深度来优化模型,以提高分类性能。但这样做很可能会增加模型的运行时间,因此,将CNN网络和循环神经网络及其变体结构结合起来搭建一个混合模型成为了文本分类领域模型优化的一个重要方向。李洋和董红斌[10]融合了CNN 和BiLSTM模型,并将他们的结果拼接为文本的最终表示特征。但该模型对文本相关词汇关键信息的抓取能力不足。针对这个问题,腾金保等[11]进一步融合了CNN和LSTM联合模型,通过为LSTM模型引入注意力机制解决了特征提取时重要特征抓取能力不足的问题,但由于LSTM是单向信息提取模型,因此该模型忽略了文本的前后语义关系。杨兴锐等[12]通过对模型引入了自注意力机制,并利用残差网络来对复合模型BiLSTM-CNN进行优化,将卷积后得到的特征通过自注意力机制赋予相应权重,池化后接入残差网络学习残差信息。Zhou等[13]认为特征向量维度上的各个特征并不是相互独立的,提出了BLSTM-2DPooling 模型,该模型应用二维池操作来为序列建模任务采样,并整合矩阵在双维度上的特征。以上研究虽然都结合了CNN和LSTM各自的优点对模型进行优化,但他们的基础模型都是基于单层的CNN 网络,无法提取到更深层次的局部特征。综上所述,本文通过局部特征跳跃连接对CNN网络进行加深,同时结合BiLSTM 和注意力机制对传统CNN-LSTM 双通道模型进行改进,以此来改进双通道分类模型在CNN 分类通道局部特征提取能力受限的问题,从而达到提升整体文本分类效果的目的。
2 TCBA联合模型
模型的总体结构主要基于两个分支构建,第一个分支由嵌入层、BiLSTM、注意力机制构成,主要进行全局上下文特征提取。第二个分支由嵌入层、双层多尺度CNN构成,进行局部特征提取。总体架构如图1所示。
口语交际作为一种人与人之间有声语言的互动交流,核心就是听说双方的互动过程。因此,口语交际的主体指的就是听者与说者,具体的说就是一个说话人、一个或几个聆听者。

图1 TCBA联合模型Fig.1 TCBA combination model
2.1 词嵌入层
在文本分类任务中,需要先将文本数据进行预处理,通过词嵌入层将词语转换成词向量表示,最初的词向量表示方法为独热编码(one-hot encoding),其原理主要是通过设置寄存器来编码相应的状态。比如对于“[羊”,“狼”],按照上述方式进行编码,由于例子中只有两个特征,因此“羊”表示成10,“狼”表示成01。通过独热编码将特征向量向欧几里德空间进行映射。但如果类别的数量非常庞大,那么所映射的特征空间也会很大,同时,采用这种编码方式无法获取词语之间的语义相关性,例如“深度学习”和“机器学习”由于其学科相同,语义相近,则向量的语义表示应该也是相近的,但One-Hot编码无法表示出语义相似词语之间的关系。为了解决该问题,word2vec[14]方法应运而生,word2vec是一种分布式词向量表示方法,相比于One-Hot 编码,word2vec 从海量文本语料库中进行训练,相似语义的单词在嵌入空间中距离相近。训练后得到的词向量可以很好地表示出词语之间的关系,本文TCBA模型采用word2vec 方法进行单词的向量化表示,其中word2vec模型包含词袋模型(continuous bag of words,CBOW)和跳字模型(skip-gram),模型如图2所示。
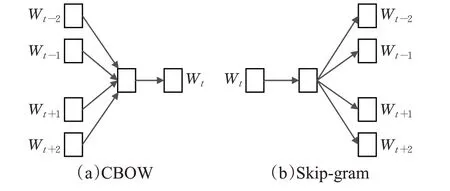
图2 CBOW模型和Skip-gram模型Fig.2 CBow model and skip-gram model
今日头条新闻文本分类数据集,包含民生故事类、文化类、娱乐类等总计15个类别,共计382 688条数据,各数据集如表2所示。
其中,i∈{t-1,t-2,t+1,t+2},Wt为训练的中间词向量,Wi则表示为中间词的上下文词向量。假设原始的输入数据表示为[W1,W2,…,WN],经过词嵌入层后输入数据表示为X=[x1,x2,…,xN],xi∈Rd,d为词向量维度。
2.2 BiLSTM-Attention层
LSTM 模型通过在RNN 网络的每个结构单元中引入遗忘门、输入门、输出门和细胞状态来改进RNN 模型,通过增加多个门控结构单元,使该网络能够充分学习到文本数据的长远距离依赖关系且更加适合建模时序类型数据。而双向的长短时记忆网络BiLSTM 相比于LSTM 模型的优势在于它可以编码文本数据从后向前的信息,使模型得到更加丰富的特征。BiLSTM采用两个不同方向的LSTM分别对文本前后信息进行训练,通过精心设计输入门i、遗忘门f、输出门o、内部记忆单元c等门控结构来选择“遗忘”或是“记忆”信息到细胞状态的能力。模型结构如图3所示。

图3 LSTM模型图Fig.3 LSTM model diagram
假定输入文本的句子表示为X={x1,x2,…,xn},其中xi表示句子中的第i个单词,则在某一时刻t,LSTM结构的更新状态如下:
其中,Wi、Wo、Wc、Wf为模型对应的权重大小,bi、bo、bf、bc为偏置,ct为t时刻的细胞状态,σ为Sigmoid 激活函数,ht表示LSTM模型隐藏状态最终的输出。然后在LSTM模型隐藏状态输出的后面添加注意力机制,通过对每个LSTM隐藏状态权重的计算,使该模型最后将所有计算权重后的隐藏状态向量的加权和作为最终的特征向量。从而得到文本数据的全局上下文特征向量,模型如图4所示。
(1)通过对文本数据利用词嵌入训练词向量,将新闻文本数据表示成空间低维度的稠密矩阵。
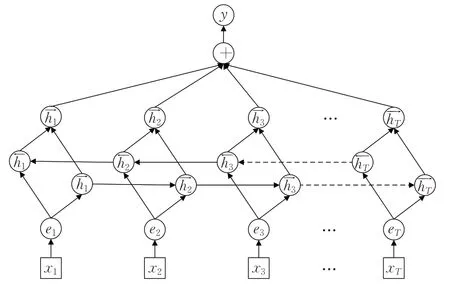
图4 BiLSTM-Attention模型图Fig.4 BiLSTM-Attention model diagram
注意力机制本质上是在文本中给不同的词汇分配不同大小的权重,使计算结果根据权重值大小更有倾向性地选择出更重要的单词特征。将模型的关注点集中在对结果有影响的词汇上能够更好地提升模型的分类准确率。Attention 层首先对每个BiLSTM 模型输出向量相应位置计算各自的词语权重,该部分最终的句子表示为所求出的权重与对应位置特征向量的加权和。
BiLSTM-Attention 层通过引入注意力机制可以让BiLSTM模型更好地关注到重点单词特征,从而可以获得句子更好的语义信息表示。
2.2 2组治疗前后RDQ量表评分比较 2组治疗后反酸、反流、烧心及胸痛等RDQ量表评分比较。中年治疗组与对照组比较,χ2=4.24,P=0.039(P<0.05),差异具有统计学意义;老年治疗组与对照组比较,χ2=10.881,P=0.001(P<0.05),差异具有统计学意义;中老年治疗组比较,χ2=4.9,P=0.028(P<0.05),差异具有统计学意义;中老年对照组比较,χ2=0.60,P=0.438(P>0.05),差异无统计学意义。详见表2。
2.3 多尺度双重卷积(TCNNRes层)
TCNNRes 模型由多个尺度的多个卷积层、Maxpooling 层、上采样层、跳跃连接层、全连接层组成。其中TCNNRes层的卷积部分首先通过设置多尺度的卷积核来对文本特征进行卷积,卷积后的文本特征经过最大池化层进行池化,压缩文本特征图的同时减少相应的计算量,之后采用传统的上采样方式来对池化后的特征进行维度扩展,然后维度扩展后的局部特征采用跳跃连接的方式将原始文本向量与其进行拼接,这样做既可以利用到最大池化后的重要特征,又能减少卷积操作导致的局部特征丢失。模型图如图5所示。
随着汽车行业的发展,汽车已经由奢侈品变为大众化产品,消费者对汽车的需求也从功能性转化为舒适性,车内空气质量成为消费者关注的热点之一。车内空气质量主要通过会产生危害的挥发性有机化合物(VOC)含量以及消费者对车内气味的主观感受来评估。由于汽车内饰零部件很多都是PP注塑件,如何降低PP注塑件的气味和VOC,成为汽车零部件厂家重点研究的课题之一。
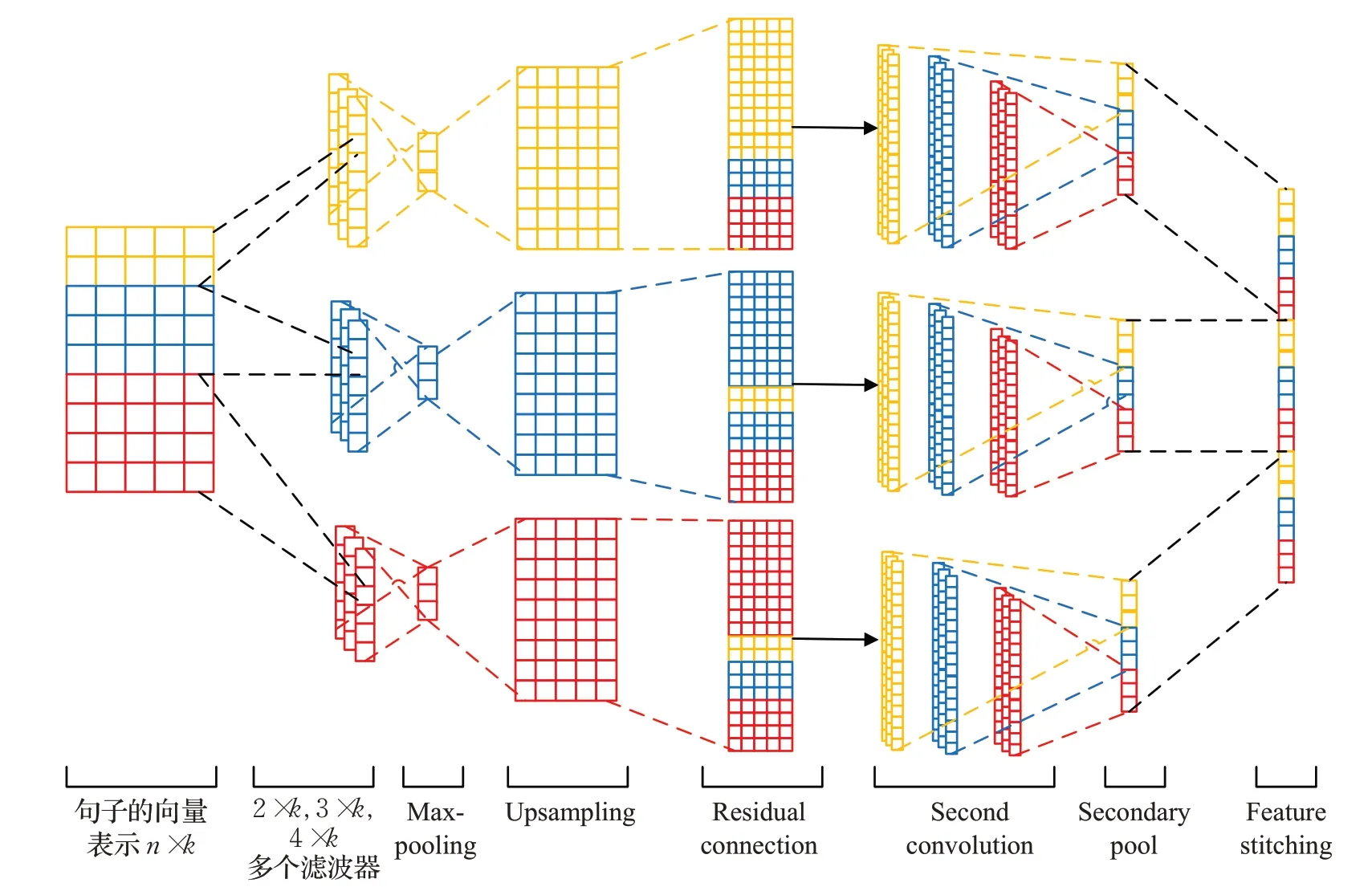
图5 TCNNRes层模型图Fig.5 TCNNRes layer model diagram
将词嵌入后的输入文本X={x1,x2,…,xn}表示成一个n×k的二维矩阵,n表示文本数据的单词数,k固定为词嵌入的维度。分别采用2×k,3×k,4×k尺寸的卷积核对输入向量矩阵进行卷积。目的是使模型能够尽可能地提取到多种尺度的局部文本特征。每次卷积操作后,卷积窗口向下滑动1个单位继续卷积。卷积公式如下:
从上述案例分析中可以看出,在新的个税制度下,案例一的税负有所减少,而且降幅比较大,而案例二的税负反而增加。
式中表示的是二维矩阵D和不同尺度卷积核间的点积,oi为卷积后的输出,w是参数化滤波器的权重矩阵,h为卷积核的高度,D[i:j]表示矩阵D第i行到第j行的子二维矩阵。然后将经过卷积后的特征信息进行池化,将池化后得到的重要特征向量通过使用双线性插值法来实现上采样操作,使卷积后的维度得到扩充,同时正好模拟了池化后如何进行上采样维度扩展的过程,如图6所示。
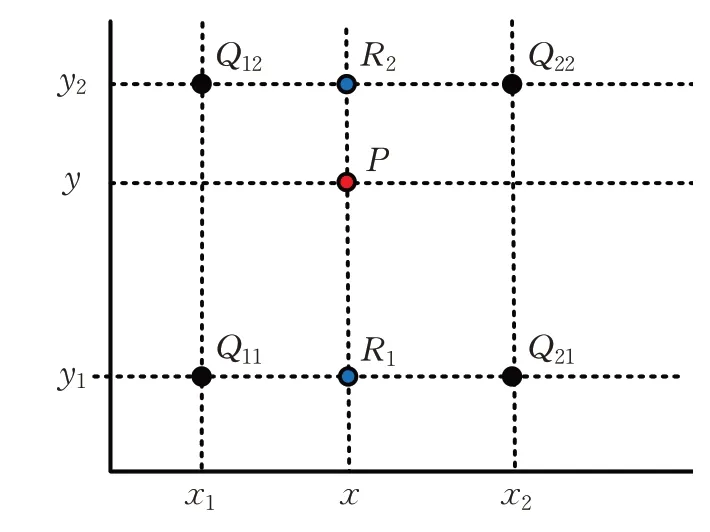
图6 双线性插值Fig.6 Bilinear interpolation
上述公式中,TP表示在预测样本集中预测类别和真实情况样本类别都为正例的样本数量;FN表示真实情况样本类别为正例但预测样本类别为负例的样本数量;TN表示真实情况样本为负例,但预测样本类别也为负例的样本数量;FP表示真实情况样本为负例但预测样本类别为正例的样本数量。
扩展出相同维度的特征需要使用合理的构造算法,在上述公式中,已知函数f(x,y) 在Q11=(x1,y1)、Q12=(x1,y2)、Q21=(x2,y1)、Q22=(x2,y2)四个点的值,计算插值的目的是计算出P点所对应的特征值,算法的过程是先在x轴方向上求出R1点和R2点这两点的像素值,然后在y轴方向上进行一次插值运算。其中:f(Q11)、f(Q12)、f(Q21)、f(Q22)分别为原特征上Q11、Q12、Q21、Q22所对应的值。
这样做既能够将提取到的特征信息与原始输入矩阵保持同维度,同时能够增大文本重要特征的局部感受野。通过合理的上采样算法构造出的文本特征增加了模型分类时的倾向性,方便下层多尺度卷积核能够学到更加关键化的特征信息,使文本的重要特征尽可能多地参与到模型的学习中来,又能够对池化后得到的重要特征进行维度扩展。将同时带有原始文本数据和上采样过后的特征矩阵再次进行二次卷积和二次池化操作,以此来捕获更多水平的特征信息。将二次卷积池化后的结果进行组合拼接作为TCNNRes 层最终的输出结果,将TCNNRes 层得到的多尺度的组合特征与BiLSTMAttention 层得到的全局上下文特征进行特征拼接融合得到最终的多尺度特征向量Z。该向量融合了文本数据的局部关键特征和全局上下文依赖特征。最后,在TCBA模型进行分类前设置dropout,来避免模型出现过拟合现象,提高泛化能力,将文本数据经过全连接层进行最终的新闻文本分类,计算公式如下:
其中,softmax为激活函数,wz为特征向量Z对应的权重矩阵,b为偏置常数。
3 实验与结果分析
3.1 实验环境和数据集
实验中使用准确率(Accuracy)、精度(Precision)、召回率(Recall)和F1 值(F1-measure)作为实验的评估标准。其中Accuracy 指标意为预测样本集合中正确样本数所占总体样本数的比重,Precision评估指标代表预测结果和实际结果都为正例的样本数量占所有预测结果为正例的比重,Recall评估指标代表预测结果和实际结果都为正例的样本数占实际结果为正例的样本数比重,F1 值评估指标代表Recall 和Accuracy 经过加权调整后的平均值。
3.3.2 日照因素分析 在考虑降雨等对椒江径流补充的同时,探讨椒江径流蒸散发的影响.采用椒江流域及周边气象站点的日照数据,表征其1995年、2000年、2005年、2010年及2015年径流水体的蒸发强度,具体统计见图7.

表1 实验环境Table 1 Experimental environment
数据集为新浪RSS 频道根据历史新闻筛选生成的THUCNews 公开数据集。数据集包含财经类、股票类、房地产类等总计14个类别,共计200 000条数据。
CBOW和Skip-gram都是用于实现文本的向量化表示,它们的共性在于模型均由输入层、中间层、输出层构成。但区别在于Skip-gram可以利用句子中的中心词汇将句子中的上下文词汇预测出来,而CBOW 模型恰好相反,CBOW使用文本数据的上下文词汇来对文本的中心词汇进行预测。CBOW 模型虽然在训练速度上具有一定优势,但文本语义表征能力却不如skip-gram。因此本文采用skip-gram模型来训练词向量,计算公式如下:

表2 数据集信息Table 2 Data set information
3.2 实验评估标准
为验证TCBA 模型在新闻文本类别预测方面的优越性,对模型分别设置消融实验及对比实验。实验环境为Linux 系统,CPU 为E5-2630 v4@2.20 GHz,实验环境如表1所示。
在y轴上的计算公式如下:
3.3 参数设置
例如,在语文教材中存在着许多有寓意的古诗文,教师在对其有深刻认识的同时,也应该对现实产生思考,将其应用到现实生活中并尽可能展现给学生。在学习《水调歌头》的时候,教师事先可以了解一些中秋佳节以及月亮的典故,可以在组织赏月活动的时候讲给大家听,让学生在活动中体会思乡之情,体会诗中所蕴含的离情别绪,增强学生对传统文化的了解,实现学生关于传统文化知识的积累,树立正确的价值观。
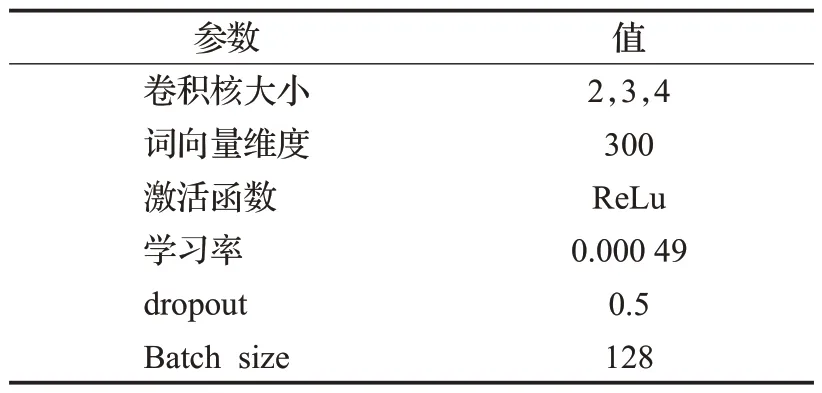
表3 TCNNRes参数设置Table 3 TCNNRes parameters setting
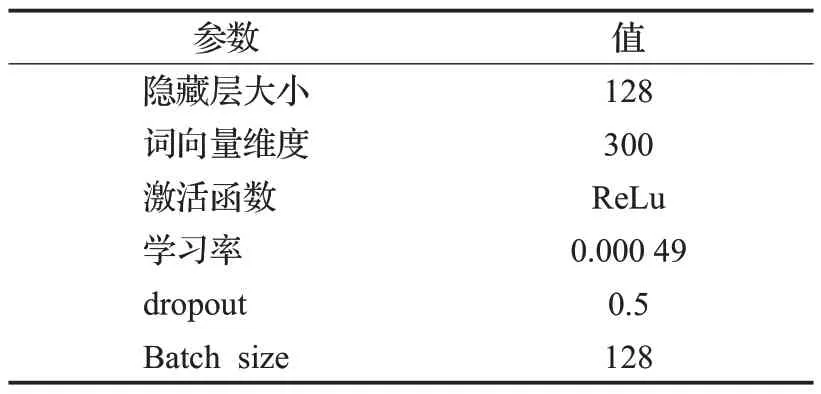
表4 BiLSTM-Att参数设置Table 4 BiLSTM-Att parameter settings
3.4 对比实验
为验证TCBA 模型与其他模型在同等条件下的优越性,本研究设置对比实验,对比模型信息如下:
高等职业院校进行教学方法的变革要在坚持多元化的基础上大胆进行创新,要关注高等职业院校教育主体个性化的基本特点和根本趋势,以学生职业发展、技能提升和素养发展作为目标进行高等职业院校教学方法多元化的尝试和更新,真正将高等职业院校教学与学情、校情、国情紧密地结合在一起,不断通过多元化的路径建设进一步完善高等职业院校教学方法体系,在不断融合和整合大数据技术的前提下创新出高等职业院校更多、更好、更适合实际的教学策略、方法和形式。
(1)LSTM-CNN[15]:先用LSTM 模型提取出文本数据的全局语义关系,再用传统的CNN模型提取由LSTM模型输出的特征信息。
(2)CNN-LSTM[16]:先用CNN 模型提取出新闻文本数据的局部特征信息,再用LSTM 模型接收CNN 输出的特征信息并进一步进行特征提取,最后送入全连接层。
根据公式(1)、(2)、(3),计算得出n值为3.88,考虑到计算误差并四舍五入,推出该段共需布置4口降水井,在盾构隧道两侧间隔8 m均匀布置,每侧降水井间隔20 m。
(3)CNN-LSTM-Attention(CLA)[17]:先用CNN 卷积模型获取新闻文本数据的局部特征信息,再用LSTM模型将CNN 的输出结果作为输入提取全局上下文信息,然后用注意力机制计算分值。
塔巴林,藏语意为“解脱园”,修建于清乾隆三十六年(1771年),相传是噶丹东竹林寺第三世扎唐活佛倡建。当时,在距寺院约有五里的林地中,有一处尼姑庵,只有几名尼姑住在简易木棚中修习。另外在奔子栏镇支央村有一处小的尼姑庵,也只有几名尼姑,僧舍也极其落魄。鉴于迪庆境内没有一座像样的尼姑寺,三世扎唐活佛决定合并两处小的尼姑庵,用内地买来的布匹换下现今的寺址(寺址原来是东竹林寺所在地),并命名为“塔巴林”,为广大女性信徒提供了一处修行地。
在英文中,“blue joke”意思是“下流笑话,低级趣味的笑话”,同义词为“dirty joke”,而“blue”在汉语中没有这样的隐含意义。根据对汉语的语言表达习惯和文化内涵的把握,在汉语中找到有类似语用意义的颜色词“黄色”。经查询,“黄色笑话”意为“腐化堕落的、特别色情的笑话”。对比之后,采取转换译法,译为“黄色笑话”。
(4)LSTM-Attention(LA)[18]:先用LSTM 模型提取出全局语义信息,再用注意力机制算出LSTM模型输出的注意力分值。
(5)CNN-Attention(CA)[19]:先用CNN 模型提取句子局部特征信息,再用注意力机制算出CNN 模型输出的注意力分值。
将TCBA 模型与以上混合基线模型在2 个公开数据集上的实验结果如表5和表6所示。
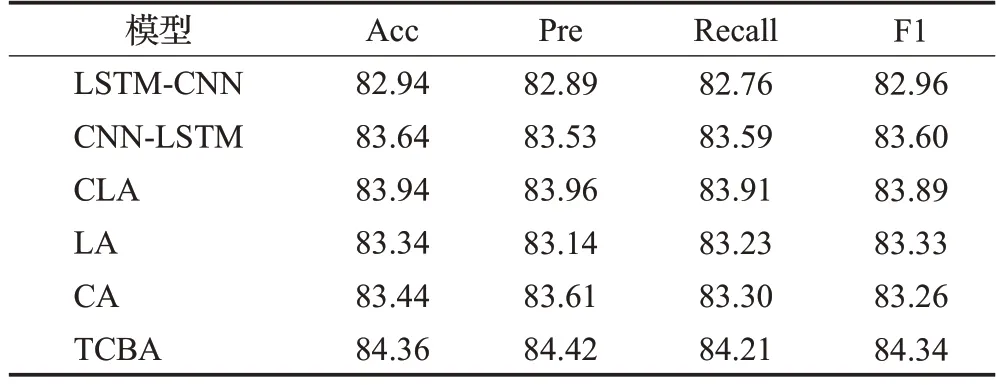
表6 今日头条实验结果对比Table 6 Comparison of experimental results of Toutiao 单位:%
表格中数据显示,在两个新闻数据集下TCBA模型与上述提及的传统深度学习模型相比,分类效果更优,在THUCNews 上,与传统的LSTM、LA、CA 模型相比,分类效果分别提高了3.41、1.5、2.94个百分点。CNNAttention 模型和LSTM-Attention 模型尽管增加了注意力机制,使模型尽可能地去关注关键单词特征,但在提取特征时仍只考虑了局部特征的提取或是对句子的序列化信息更加关注,特征提取能力被局限化。在今日头条数据集上,由于数据集本身在分类前存在较严重的分类不平衡问题,因此今日头条数据集的分类效果相较于THUCNews数据集而言总体偏低,但从模型之间的对比结果可以看出,TCBA 模型相较于其他分类模型,分类效果仍然优于其他对比模型。
综合考虑以上因素,TCBA模型能将新闻文本真实语义特征表征出来。与LSTM-CNN 和CNN-LSTM 联合模型相比,Accuracy 分别提升了1.81 个百分点和2.2个百分点。相比于单一的特征提取模型,CNN和LSTM的混合模型可以提取到文本的全局语义特征和局部关键特征,但LSTM 模型只能提取从前到后的特征,特征的丰富性和多样性较少。且这些混合模型也并没有将注意力放在更重要的单词上,而TCBA模型不但可以有效提取到文本的更深层次的局部关键特征,同时兼顾上下文语义信息和提高重点单词特征的关注度,最终提升整体分类效果。
1.资源开发集约节约化。建筑用石料集中开采区要统一规划开采布局、开采总量,全面综合利用矿山固体废弃物、循环利用矿山用水,基本做到零排放。同时,通过严格实施矿区开发规划,将残留或损毁的山体采平为可供利用的土地。
表5 和表6 中的数据显示,TCBA 模型在新闻数据分类的常用评估指标上均有明显提升。在THUCNews中,以混合模型LSTM-CNN 为例,Accuracy、Precision、Recall、F1值分别提升了1.81、2.27、2.34、2.31个百分点,在今日头条数据集上,则分别提升了1.42、1.53、1.45、1.38个百分点,进一步体现出了TCBA模型的优越性。
实验中对每个模型都分别输入300维的词向量,为深入探究TCBA 模型的分类性能,实验进一步得出了THUCNews验证集的准确率变化曲线,如图7所示。相比于其他模型,CNN-Attention模型的数据波动较大,从第5 个训练轮次才开始收敛,LSTM-CNN 混合模型从第3 个训练轮次开始收敛,TCBA 模型曲线从第4 个训练轮次开始收敛,波动较小,相对来说也更加平缓,总体来说,TCBA 模型训练稳定且准确率更高,在后续的训练中TCBA模型始终处于优势地位,展现了TCBA模型的优越性。
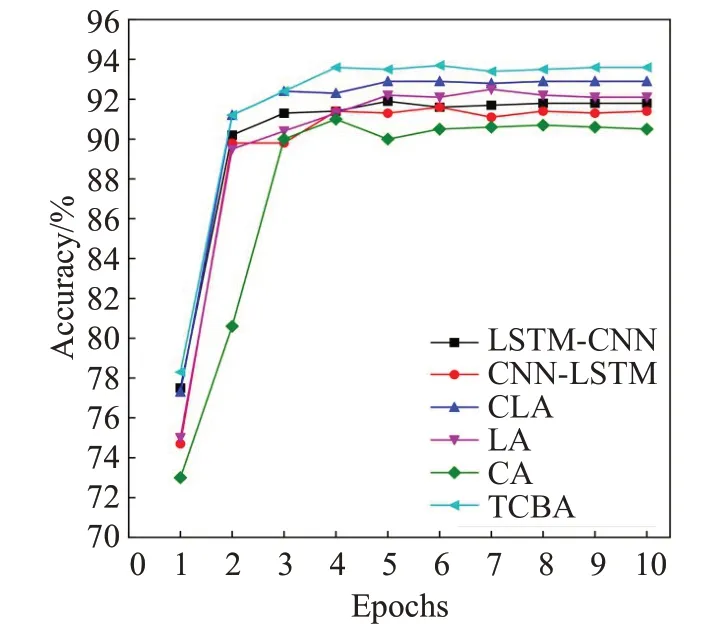
图7 验证集准确率变化曲线Fig.7 Validation set accuracy change curve
尽管分类的准确率是评价模型非常重要的一个指标,但在模型的总体分类评价上,时间消耗也是必不可少的评价指标,本实验另用5 000 条文本数据集在THUCNews 数据集上进行时间消耗测试,实验结果如图8所示。在时间消耗上LSTM-CNN最大,而CA模型时间消耗最小,是因为LSTM 本身的结构相对于CNN更加复杂。TCBA 模型的时间消耗介于中间值,因为TCNNRes 层在传统CNN 的基础上增加了上采样和二次卷积等结构,相比于原CNN模型来说更为复杂,所以时间消耗相比于其他特征提取模型来说更大。
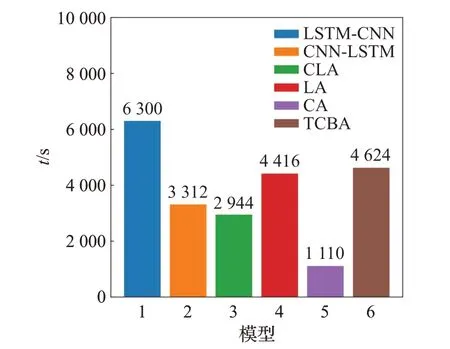
图8 模型在THUCNews上的用时比较Fig.8 Time comparison of model on THUCNews
3.5 消融实验
为验证TCBA模型对分类效果的实用性和有效性,本文设置消融实验,分解TCBA 模型各个局部网络,分别设置BiLSTM、CNN、BiLSTM-Attention、TCNNRes,实验结果如表7和表8所示。

表7 THUCNews数据集消融实验结果Table 7 Results of THUCNews dataset ablation experiment 单位:%

表8 今日头条数据集消融实验结果Table 8 Results of Toutiao dataset ablation experiment 单位:%
从表中可以看出,BiLSTM与CNN模型在分类上的效果相当,TCBA 模型中BiLSTM 在引入注意力机制后又与TCNNRes层的分类效果接近。而总体的TCBA模型的分类效果对比于其他拆分结构的分类效果提升明显。这是因为TCBA 模型在分别利用CNN 模型和BiLSTM模型优势的同时,通过对CNN 模型加强网络结构的深度且尽可能保留更多重要的局部卷积特征来增强模型的局部特征提取能力,通过对BiLSTM模型添加注意力机制使之能够关注学习到关键词汇信息,提高了模型分类的准确率,因此分类的效果要比传统单一的特征提取器效果好。
4 总结
本文提出了一种多尺度的双层CNN 和BiLSTM 注意力机制的融合模型(TCNNRes-BiLSTM-Attention,TCBA),模型不仅能融合文本的局部特征和全局特征,同时也增强了传统混合模型中局部卷积特征提取的能力。模型首先通过词嵌入层将原始新闻文本数据映射成词向量矩阵,再利用双层多尺度的CNN 网络增强卷积的整体感受野并加深卷积深度,进而加强新闻文本数据的局部特征提取能力,同时利用BiLSTM模型结合注意力机制提取全局上下文语义信息。最后再将提取到的所有特征信息融合后送入softmax层进行最终的新闻文本多分类。通过进行对比实验和消融实验显示TCBA在多个评价指标上均有显著提升,证明了TCBA模型的优势,未来的工作中会在减少数据类别不平衡现象展开研究工作,为进一步提升分类效果做贡献。
