基于自适应环境因子熵权决策的多目标特征选择
2023-10-29李涛李佳霖阮宁徐久成
李涛 ,李佳霖 ,阮宁 ,徐久成
(1.河南师范大学计算机与信息工程学院,新乡,453007;2.河南师范大学软件学院,新乡,453007;3.“智慧商务与物联网技术”河南省工程实验室,新乡,453007)
随着大数据技术的迅速发展,日益增加的海量高维数据[1-3]对传统数据分析与处理方法提出了新的挑战.特征选择[4-6]是一种重要的数据降维技术,通过剔除数据集中的无关或冗余特征,形成一个结构上更紧凑的特征子集,从而减少学习模型的训练时间并提高泛化能力.特征选择方法在数据挖掘、机器学习和生物信息学等领域得到广泛应用,取得了较好的成果.
常见的特征选择方法可分为过滤式方法[7]、封装式方法[8-10]和嵌入式方法[11]三大类.过滤式方法在未训练学习器的情况下评估特征子集,虽然其扩展性强且计算成本低,但由于缺少学习器的训练学习导致分类性能较差.封装式方法结合具体学习器的误差来衡量候选特征子集,取得了较好的分类准确性,但其需要计算特征间的交互关系,计算开销较大.嵌入式的方法将特征选择与学习器训练相结合,在学习算法的执行过程中完成最优特征子集的选择.虽然上述三类特征选择方法已有大量探索,但仍存在特征子集陷入局部最优、关键特征选择不准确等问题.假设一个数据集的特征数为n,则存在2n-1(除去空集)种候选特征子集,采用穷举搜索高维数据特征显然不可行.针对高维数据特征选择亟须解决的问题,一是由于维度高导致搜索空间巨大,需要减少评估候选特征子集的计算量;二是特征间存在复杂的互转化关系,需要准确识别与选择关键特征来构造全局最优特征子集.
近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto 解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA-II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto 解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA-Ⅱ与MOPSO 混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA-Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto 最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA-Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体.
上述基于NSGA-Ⅱ的改进与优化方法一定程度上改善了特征子集的分类性能,但NSGA-Ⅱ在处理高维特征选择问题时仍存在不足.一是在设计进化算子时没有考虑自适应性对特征子集选取的影响,多目标进化搜索的Pareto 解集质量差.通常个体交叉和变异过程主要依赖个体适应度,会错误保留冗余特征或删除相关特征,导致特征子集的分类性能不佳.二是Pareto 解集中缺少合理最优解选择策略.尽管多目标优化特征选择方法提供了优秀解决方案,但解决方案的选择往往依赖决策者的主观需求,缺少合理最优解的选择依据,所以选择的特征子集的可解释性较差.
为了解决上述问题,本文提出一种基于自适应环境因子熵权决策的多目标特征选择算法(Adaptive Environmental Factor Entropy Weight Decision-Making-Based Multi-ObjectiveFeature Selection Algorithm,AMFS),主要框架如图1 所示.首先,根据特征关系设计环境因子,依据特征的重要性对候选特征进行自适应赋值;随后,基于环境因子分别提出改进的自适应交叉算子和自适应变异算子,并生成新的种群个体作为候选特征子集;最后,给出基于环境因子的熵权决策来选取最优解.

图1 本文提出的AMFS 算法的框架Fig.1 The framework of the proposed AMFS algorithm
1 相关工作
鉴于过滤式和封装式特征选择方法的优点,相关学者研究两者混合式特征选择[18],并提出众多基于多目标优化的特征选择方法,在处理高维特征选择时表现良好.这主要是由于过滤式阶段能有效剔除大量无关特征及冗余特征,减少特征维度,缩小求解空间;封装式阶段结合具体优化算法,依据目标函数的优化结果来判定特征子集的选择,能获取高精度的特征子集.
Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto 支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging 作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K-means 方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF 过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto 解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K-means 聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳.
2 基础知识
2.1 NSGA-Ⅱ算法NSGA-Ⅱ是经典的多目标进化算法,在处理现实应用领域中的多目标优化问题时表现良好.其采用Pareto 支配关系和拥挤距离[25-27]机制来更新种群,并依据多个优化目标度量选择多个折中解来构成Pareto 前沿.
下面对NSGA-Ⅱ算法的重要概念和基本算子进行描述.
2.1.1 Pareto 支配关系多目标优化问题[28-33]中Pareto 优化解是最常用的优化概念,其定义如下.
定义1Pareto 支配设两个决策变量x1,x2∈Ω.x1Pareto 占优x2,记作x1>x2,当且仅当 ∀i∈{1,2,…,n},fi(x1)≤fi(x2)∧∃j∈{1,2,…,k},fj(x1)≤fj(x2),记作x1≺x2.
定义2 Pareto 最优解解x*∈Ω为解集Ω的Pareto 最优解,当且仅当{x|x≺x*,x∈Ω}=Φ(Φ 为空集).
定义3 Pareto 最优解集对于给定的多目标优化问题,设其定义域为Ω,则Pareto 最优解集X定义为X*={x∈Ω|¬∃x'∈Ω,f(x') ≺f(x)}.Pareto 最优解集在函数空间上对应的集合称为Pareto 前沿[34-36],记作PF.
2.1.2 基本算子
2.1.2.1 非支配排序算子首先,对种群中的每个解p计算支配p的解的数量np和被p支配的解的集合Sp.由于第一层非支配层级上解的支配数记为0,对于每一个np=0 的解,访问Sp中的成员q,并将其支配数减1,如果q的支配数为0,则将其放入一个列表Q中.因此,Q中包含了属于第二层非支配层级的解.接着,对集合Q中的解重复这一过程,直到找到第三层非支配层级.这个过程一直持续到找到所有的非支配层级为止.
2.1.2.2 拥挤度距离算子首先根据每个目标函数的适应度对种群中的个体进行升序排序.然后,对于每个目标函数,其边界解被分配一个无限的距离值,每个中间解也被分配一个距离值,该距离值等于两个相邻解差的绝对值,该过程在不同的目标函数中重复进行.因此,拥挤的距离值即为在每个目标上的距离之和.
2.2 熵权TOPSIS 决策TOPSIS 根据优化目标与Lable 值之间的接近程度进行排序,具有可观、可靠的优点,但也存在权值法受决策者主观影响的问题.熵权TOPSIS 将信息熵引入TOPSIS,利用信息熵计算得到TOPSIS 的权重,减小了主观权重赋值带来的偏差.下面给出熵权TOPSIS 决策的相关定义.
定义4 正则化矩阵根据解的个数m与优化目标的个数n确定相应的决策矩阵X=(xij)m×n.rij表示第i个方案的第j个指标,i=1,2,…,m,j=1,2,…,n.对决策矩阵进行正则化处理得到正则化矩阵R=(rij)m×n,其中,
定义5 熵值第j个指标的熵值:
利用熵值计算第j个指标的权重:
利用第j个指标的权重wj对正则化结果rij进行加权,得到加权正则化后的结果λij=wjrij.
定义6 理想解理想解分正理想解和负理想解,正理想解取各指标的最大值=max{λij},负理想解取各指标的最小值=min{λij}.
定义7 解距决策值与正负理想解之间的解距可采用欧式距离计算,表示为:
定义8 相对贴近度相对贴近度ηi表示各待决策值与正理想解之间的贴近程度,表示为:
对每个解的相对贴近度,按从大到小的降序排序,选取具有相对贴近度最大值的解作为最适解.
3 基于自适应环境因子熵权决策的多目标特征选择
为了解决Pareto 解集中缺少合理最优解选择策略的问题,提出一种基于环境因子的熵权决策,减少决策过程中决策者主观因素的影响,增强合理最优解的选择依据,丰富选择的特征子集的可解释性.针对多目标进化搜索到的Pareto 解集质量差的问题,提出基于环境因子的自适应算子,将个体交叉和变异过程依赖的个体适应度作为自适应依据,删除冗余特征,保留相关特征,增强特征子集的分类性能.
3.1 基于环境因子改进的自适应算子提出一种作用于环境因子下的交叉变异算子的自适应算法环境因子,其形式化如式(1)所示:
对个体g在迭代过程中加入环境因子来控制整体适应度,ng为训练样本中个体g的出现数目,N为迭代次数,fre(g)表示个体g在选择、交叉、变异过程中出现的频率.F(g)是训练样本数据中的类型g与所有类型数据在全体数据中出现频率总和之比,如式(2)所示:
3.1.1 环境因子下的交叉算子在进化迭代中,随着进化迭代次数t的增加,遗传可分为前期和后期.进化前期个体的多样性强,需要快速找出较优的个体;进化后期的个体平均适应度已高度靠近最佳适应度,较大的交叉率可能会带来收敛不稳定性.当个体适应度较集中或较分散时,视为进化个体进入高度集中或高度分散两种极端情况,此时应适当调整交叉率.为此,改进交叉率如式(3)所示:
其中,t为迭代次数.随着迭代的进行,种群逐渐向种群中的最优适应度靠拢,交叉率随着迭代而逐渐减小.(fmax-f')表示种群中个体最大适应度和两个交叉个体中适应度较大的个体的适应度之差,该项表示交叉个体在种群中的离散程度,两者之差越大即表示交叉的两个个体的适应度越低,交叉率随之增大,增加了引入优质样本的概率.(fmax-farg)表示种群中个体最大适应度和种群中所有个体的平均适应度之差,其与(fmax-f') 的比值表示交叉的两个个体的适应度与种群平均适应度的差距,差值越大,意味着这两个个体越接近边界位置,为了增加引入优质样本的概率,交叉率需要随之增大.越大的种群个数N意味着越丰富的种群适应度,即有越大的可能含有优质解,故交叉率随着种群数N的增大而减小.该环境下样本的集中程度μ变大,意味着种群适应度收敛程度变高,交叉率会随之上升,增加引入优质解的概率.
3.1.2 环境因子下的变异算子随着遗传迭代次数t的增加,较大的变异率引入的新样本的波动会影响遗传算法的收敛性,故变异率应随迭代次数增加给予适当改变.个体适应度较集中时,往往意味着平均适应度函数逼近一个极值,但无法确定其是否为最优解,需对变异率进行适当调整,使其不易陷入局部最优.因此,修正变异率如式(4)所示:
与交叉率算子的设计过程相似,综合考虑种群个数、样本集中程度和迭代次数变化的影响,变异率随着N的增大而减小,随着μ的增加而增加,随着迭代次数t的增加而减小.
3.2 基于环境因子熵权的Pareto 最适解选取本节提出基于环境因子赋权重,将AMFS 得到的Pareto 最适解集通过熵权TOPSIS 分析得出在此环境下的最适解,其中,设计的目标函数f1为特征选择率,目标函数f2为特征相关系数.目标函数如式(5)所示:
其中,|Fs|为最终优化特征个数,|F0|为原始特征个数,|Fτ|为所选特征子集,|Fl|为数据集的标签.
特征子集相关性最大化与特征选择率最小化通常被视为特征子集的两个优化目标,值得注意的是,这两个优化目标在大多数场景下存在相互冲突的情况,得到的序列值通常无法判定最优情况,可以通过对序列个体引入环境因子μ并对该环境下的Pareto 解进行信息熵权判断来决策最适解.具体步骤如下:
Step 1.通过AMFS 得到的Pareto 序列构成正则化矩阵:
最后,选取相对贴近度的最大值aμ=max{ηi},则aμ对应的个体为所得最适解.
3.3 所提算法伪代码描述基于以上分析,下面给出基于自适应环境因子熵权决策的多目标特征选择的伪代码.

设n和m分别为原始数据集中的样本数和特征数,N是总体的大小,M是目标的数量,T是迭代次数,n*为Pareto 解集个数.第1~3 行计算每个特征的环境适应度,使两个优化目标能够有效地衡量候选解决方案,其时间复杂度主要依赖于环境因子μ(g)的计算,时间复杂度为O(n×m).第4~6 行计算拥挤距离与非支配排序,其时间复杂度为O(NlgN×M).第8~11 行计算最适解,其时间复杂度为O(n*×M).因此,本文算法AMFS 的时间复杂度为:
3.4 所提算法的收敛性分析根据上述定义,F表示算法可以搜索到的个体空间,B(t)是算法第t次迭代的种群,A(t)为算法归档集,F*=Mf(F,≺ )为空间F的所有非支配解.下面给出本文算法AMFS 的收敛性分析.
定义9定义|A|表示集合A的元素个数,定义δ(A,B)=|A|-|A∩B|.AMFS 算法以概率1收敛于 Pareto 最优解集,当t→∞ 时,δ(A(t),F*)→0 的概率为1.
4 实验与分析
为了验证提出的算法的有效性,采用不同应用领域中的六个高维数据集进行对比实验,其中,最大特征数和最小特征数分别为60 和13,最大样本数和最小样本分别为2310 和178,数据集的具体信息如表1 所示.实验平台为Core i7-10510U,2.30 GHz,16 GB,仿真算法均在Matlab R2016a中实现.

表1 实验使用的数据集Table 1 Datasets used in experiments
为了证明提出的算法表现优越,采用五种现有的多目标特征选择算法与AMFS 进行比较,分别为NSGAFS[37],MOFSBDE[19],FSMOPSO[20],DCDREA[21]和NSGA-Ⅱ[12].算法的相关参数如表2 所示,其中,Nf表示特征的数量,所有比较算法均采用K近邻(KNN)分类器,K设置为5.AMFS 的种群大小Pop=NS,迭代次数T=100.

表2 算法的参数设置Table 2 Algorithm parameter settings
4.1 AMFS 与不同EAs 特征选择性能比较为了评估AMFS 的性能,从最佳分类精度和平均分类精度两方面进行度量,分别记为Best 和Avg.所有算法均独立运行10 次,所有对比算法的Best的值是Pareto 解集中距离原点欧几里得距离最近的解,AMFS 的Best 值是采用基于环境因子熵权计算所得.另外,AD_Best 和AD_Avg 分别为对应算法的Best 和Avg 的平均值.表3 展示了AMFS 与其他五个多目标进化算法的比较结果,表中黑体字表示所有算法中的最优值.此外,采用t检验来验证AMFS 的显著性差异,表3 中Ttest_Best 和T-test_Avg 分别表示对应的P,P<0.05 表示差异显著,记作“+”,P>0.05 表示差异不显著,记作“-”.

表3 AMFS 与五种多目标进化算法的性能比较Table 3 Performance of AMFS and other five multi-objective evolutionary algorithms
由表3 可见,AMFS 在各个数据集上均优于NSGA-Ⅱ,这是由于环境因子加权的自适应算子对全局搜索最优解更具优势.在Ionosphere 数据集上,FSMOPSO 的Best 为100%,AMFS 的Best为99.82%,比FSMOPSO 低0.18%,但AMFS的Avg 比FSMOPSO 高1.10%.AMFS 仅在一个数据集上表现稍弱,在其他数据集上的精度都高于FSMOPSO.在Wine 数据集上,AMFS 的Best比NSGAFS 低,但和其他算法相比是最高的,而且其Avg 是最优的.AMFS 和DCDREA 在各个数据集上的性能都比较接近,仅在个别数据集中可能存在因AMFS 筛选的特征子集包含冗余特征而劣于DCDREA 的情况,但整体来看,AMFS的AD_Best 与AD_Avg 均高于DCDREA.
综上,AMFS 具有优越的性能,其AD_Best和AD_Avg 分别为98.22%和97.11%,这得益于基于环境因子的自适应交叉算子和自适应变异算子可以挖掘更多的优秀的候选个体.此外,t检验的测试结果表明,AMFS 与NSGA-Ⅱ,MOFSBDE 和FSMOPSO 三种多目标进化算法相比,两种指标均有显著差异,与NSGAFS 之间没有显著差距,与DCDREA 仅有一个指标有显著差异.证明AMFS 与现有的大多数多目标特征选择进化算法相比,有明显的竞争性.
4.2 AMFS 的HV 和SP 指标的表现为了进一步检验多目标特征选择算法中的Pareto 解集,使用超体积(HV)和间距(SP)来分析不同多目标特征算法的性能,其中,HV为算法得到的解集中的个体与目标空间中的参考点围成的超立方体的体积.由于AMFS,MOFSBDE,FSMOPSO,NSGAFS,NSGA-Ⅱ和DCDREA 采用两个优化目标,因此参考点设置为(1,1).HV越大,算法的整体性能越好.假设Pareto P1 的HV大于Pareto P2,表示P1 的多样性和收敛性优于P2.对于SP指标,它测量从每个解决方案到其他解决方案的最小距离的标准偏差,SP越小,解集越均匀.表4 和表5 展示了AMFS 和其他五种算法的HV和SP的比较结果,表中黑体字表示结果最优.
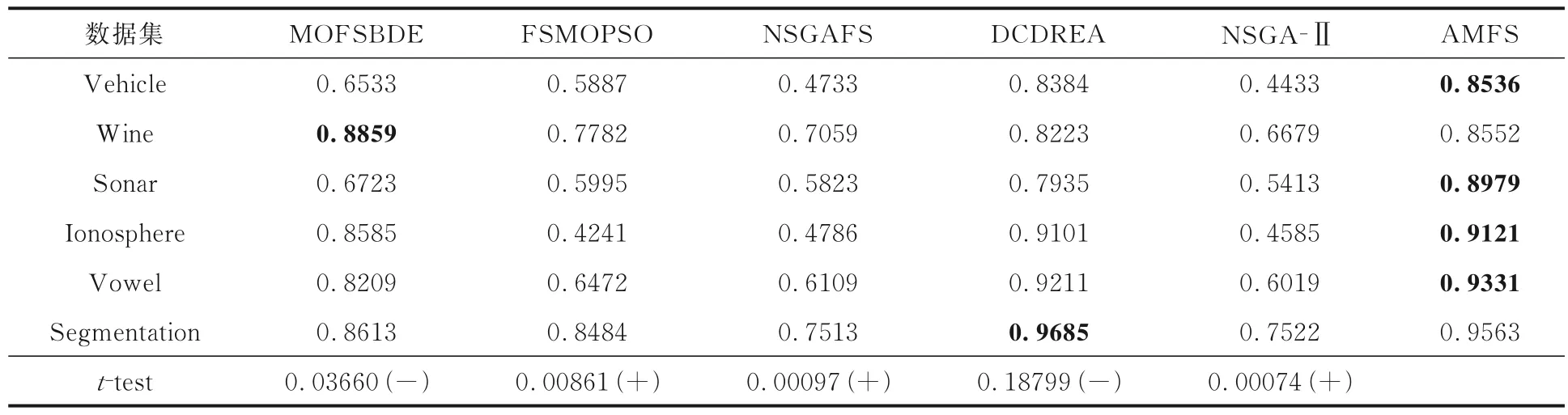
表4 AMFS 算法与五种多目标特征选择进化算法的HV 的比较Table 4 HV of AMFS and other five multi-objective feature selection evolutionary algorithms
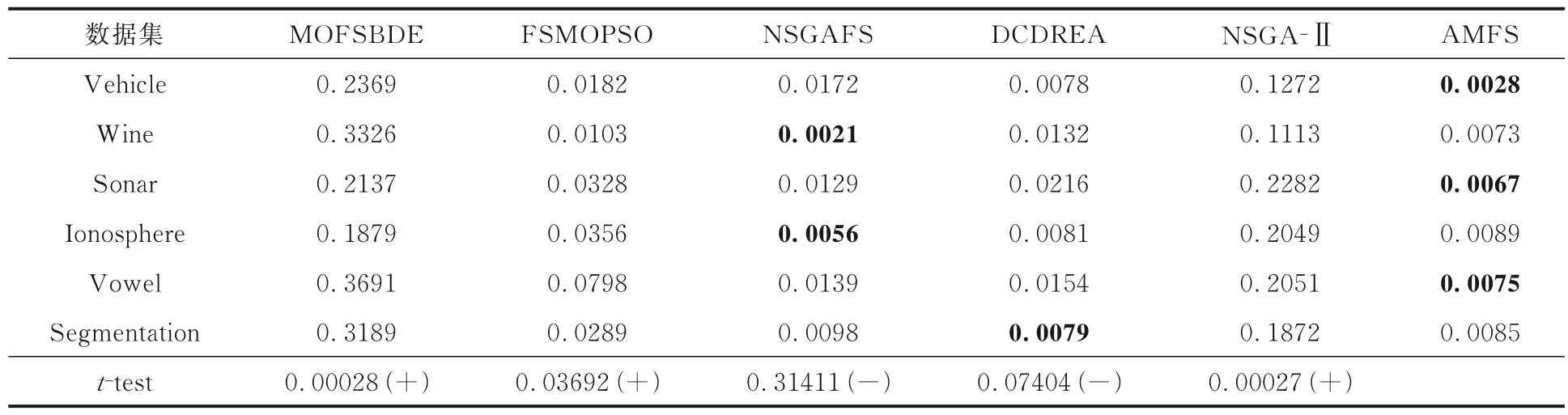
表5 AMFS 算法与五种多目标特征选择进化算法的SP 的比较Table 5 SP of AMFS and other five multi-objective feature selection evolutionary algorithms
如表4 所示,AMFS 算法的HV远远大于FSMOPSO,NSGAFS,NSGA-Ⅱ.在Vowel 数据集上,FSMOPSO,NSGAFS,NSGA-Ⅱ的HV分别为0.6472,0.6109,0.6019,AMFS 的HV是0.9331,分别高0.2859,0.3222,0.3312.在Wine数据集上,MOFSBDE 的HV超过了AMFS,但AMFS 的HV整体上大于MOFSBDE.DCDREA与AMFS 的结果相近,甚至在Segmentation 数据集上,DCDREA 的HV超过了AMFS,但是AMFS 的HV在其他五个数据集上都大于DCDREA.t检验的结果表明,AMFS 的HV明显优于大多数算法,证明AMFS 得到的Pareto 解集与其他算法相比,具有更好的分集和收敛性能.
如表5 所示,AMFS 的SP优于FSMOPSO,MOFSBDE,NSGA-Ⅱ.在Wine 数据集上,NSGAFS 的SP为0.0021,比AMFS 略低了0.0052.类似地,在Ionosphere 与Segmentation 数据集上,DCDREA 的SP比AMFS 算法略低0.0008 和0.0006,但在其余四个数据集上,AMFS 的表现更优.t检验的结果表明,AMFS 的SP明显优于大多数算法,证明由AMFS 获得的Pareto 最优解集具有良好的分布均匀性.
由以上分析可知,本文提出的AMFS 算法在高维数据集上能获得分类精度更高的Pareto 解集并从中选取合理的唯一解,其主要原因:一是将进化过程中的环境因子嵌入改进的自适应交叉和变异算子,有效地动态监测进化个体中不同特征组合的性能表现,避免了主观因素对搜索特征子集的影响,以自适应的方式获得综合性能较好的Pareto 前沿解;二是引入了环境因子熵权,能在不同优化目标下计算信息熵权,自动判别Pareto 前沿中的最佳折中解,减少包含重要特征的进化个体因被支配而错误剔除的可能性,保证全局最优解的搜索效率和精度.
表6 给出了AMFS 与五种对比算法的时间复杂度,由表可见,AMFS 略占优势.这是由于时间复杂度主要依赖于环境因子μ(g)的计算,其环境因子的自适应算子在寻找全局最优解时可加速收敛过程,总体时间复杂度略优于其他五种多目标特征选择算法,但进一步减少计算环境因子的时间开销仍需继续研究.

表6 AMFS 与五种多目标特征选择进化算法的时间复杂度的比较Table 6 Time complexity of AMFS and other five multi-objective feature selection evolutionary algorithms
4.3 AMFS 与不同最适解选择策略的性能比较为了检验AMFS 选择最适解的性能,进行了消融实验,采用TOPSIS、熵权TOPSIS(ETOPSIS)和基于环境因子熵权TOPSIS(BETOPSIS)来赋值权重,根据不同权重对同一实验结果进行选择,判断三种方法选择最适解的能力.使用的数据集为Vehicle,Pop设置为50,迭代次数T=100,权重设置如表7 所示.

表7 AMFS 算法消融实验权重设置Table 7 Weight settings for ablation experiments of AMFS algorithm
图2a 为通过AMFS 获得的Pareto 解集,图2b为用三种不同的获取权重指标方法所选择的最适解,其中青色解为Pareto 最优解,紫色解为TOPSIS 选择解,蓝色解为熵权TOPSIS 选择解,红色解为基于环境因子熵权TOPSIS 选择解.实验结果如表8 所示.由表可见,与TOPSIS 选出的结果相比,BETOPSIS 的特征相关系数仅升高0.2,但特征选择率大幅度缩减了20%;和ETOPSIS 选出的结果相比,BETOPSIS 的特征相关系数降低0.5,特征选择率升高15%.这是因为TOPSIS 权重是人为设置的,偏离值相对较大,且主观因素占比较高;ETOPSIS 在TOPSIS 的基础上去除了主观因素,获得的最适解相对较好;BETOPSIS 在ETOPSIS 的基础上增加了对数据集特征依赖度的判定,选择出的结果既消除了主观因素,又增加了选择权重的可解释性,获得的最适解最优.证明BETOPSIS 对选择最适解有一定幅度的提升.

表8 AMFS 算法的消融实验结果Table 8 Ablation experimental results of AMFS
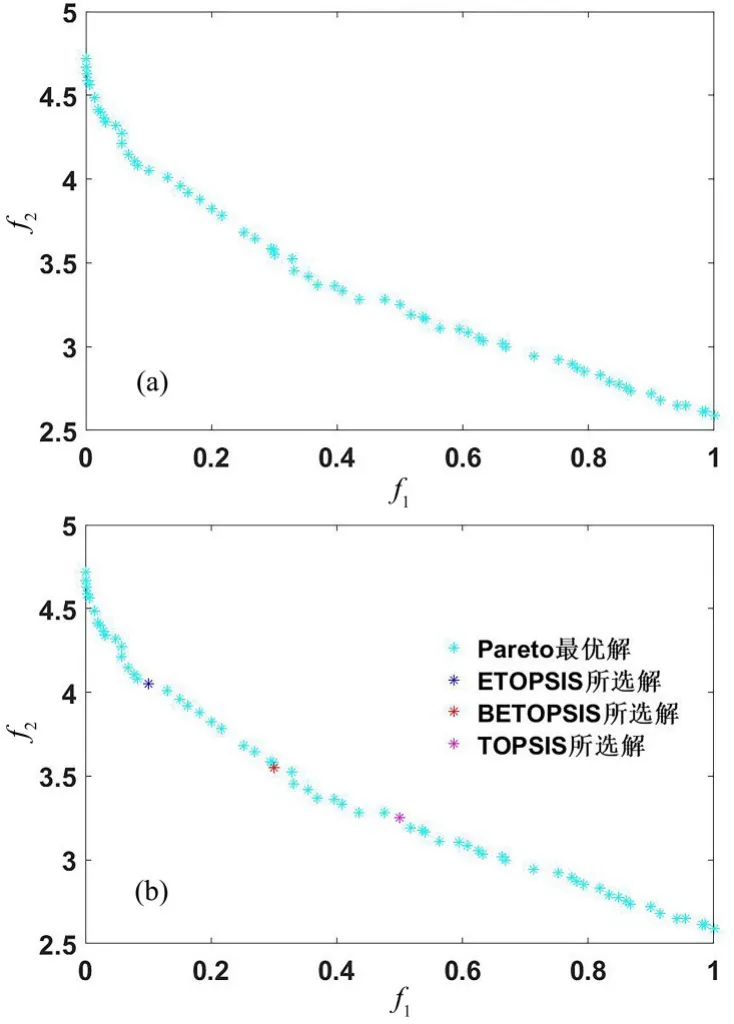
图2 三种方法选择Pareto 解集最适解Fig.2 Three methods for selecting the most suitable Pareto solution set
5 结论
本文提出一种基于自适应环境因子熵权决策的多目标特征选择算法,首先通过加权环境因子来自适应地筛去不相关特征,以提供高质量的候选特征子集空间;然后,将环境因子嵌入改进的交叉算子和变异算子,加速最优特征子集的自适应搜索;最后,利用基于环境因子的熵权分析决策出Pareto 最优解集中的最适解.实验结果表明,针对高维特征选择问题,本文提出的AMFS 的分类精度表现较好.未来将关注多目标优化特征选择搜索策略的高效性,研究低开销的Pareto 求解算子,此外,特征子集的稳定性分析是另一个值得考虑的研究方向.
