面向盾构机实测数据的滑动窗口分层异常值检测及修正方法
2023-10-28王苏杭王一棠李一阳宋学官
王苏杭,王一棠,庞 勇,李一阳,宋学官
(大连理工大学机械工程学院,高性能精密制造全国重点实验室,辽宁大连 116024)
0 引言
城市的地下空间被用于满足日益增长的交通、能源和电信的基建需求,而隧道是常见的地下空间利用方式之一[1-2]。盾构机是一种集光电、机械、液压、计算机技术为一体的数字化大型工程机械装备[3-4],是隧道掘进盾构施工的核心,具有高效、安全和环保等优点,已广泛应用于国内多个重点建设项目。为保障盾构机安全、高效、平稳运行,其智能运维系统将施工现场采集的实测掘进数据进行挖掘和分析,从而对盾构机的性能进行精准预测。然而,由于施工现场环境复杂,实际采集的数据会存在异常值情况,严重降低数据的利用价值。
在隧道掘进过程中,部署在盾构机上的传感器采集信号,通过数字转换和相应的通信技术,存储到计算机或者服务器,即可得到盾构机的实测数据。传感器按照一定的采样频率采集信号,所以盾构机实测数据是严格的时间序列数据。时间序列数据的异常形式一般分为3类:点异常、模式异常和序列异常[5-6]。在盾构机实测数据中,点异常出现较多,而模式异常和序列异常较少见,因此点异常是研究的重点。
当前,面向时间序列异常值检测算法模型一般有基于预测[7]、基于统计[8-9]、基于机器学习和深度学习[10]、基于窗口等方法[11-12]。基于窗口的方法通过设计滑动窗口的大小对时间序列进行分割,对各子时间序列进行特征提取,在各子时间序列中定位异常值点。与其他方法相比,该类方法易于理解且计算简单,降低了时间复杂度,并且能将动态的数据量静态化[13],因此得到广泛的应用。戴慧等[14]提出了一种基于滑动窗口的由粗到细的两阶段探测策略,采用子时间序列的均值和方差作为子时间序列的特征信息,实现了对某变电站各设备表采集数据的异常值检测。高熠飞等[15]计算窗口内子时间序列的中位数以及中位数绝对偏差作为子时间序列的特征信息,较好地消除了滑动窗口内极端异常值对算法的影响,实现了对水文序列异常值的检测。唐向红等[16]计算子时间序列内相邻两点的斜率与设定的斜率范围进行比较,实现了对电流信号的检测。基于数据斜率的方式能较准确描述子时间序列的结构特征,但工程数据中异常数据分布随机性大、波动性大,导致传统的基于斜率的检测方法对数据形态信息利用不充分,而置信区间能够以一定的可靠程度估计总体数据所在的区间。田腾等[17]采用基于子时间序列斜率的置信区间的方式进行特征提取,对盾构机掘进速度的异常值检测取得了良好的效果。陆秋琴等[18]同样采用斜率的置信区间距离半径对污染物子序列特征进行提取,实现了对传感器数据采集中异常值的检测。但其对子时间序列斜率的置信区间半径计算上,采用了传统方式,运算效率有待改进。因此,本文采用一种基于滑动窗口提取子时间序列特征的异常值检测方法,采用快速计算的方式得到子时间序列斜率的置信距离半径作为特征,能够有效利用序列特征进行异常识别,提高了运算效率。同时对检测出的异常值,提出了基于多子时间序列的填补方法。
1 盾构机实测数据点异常处理方法
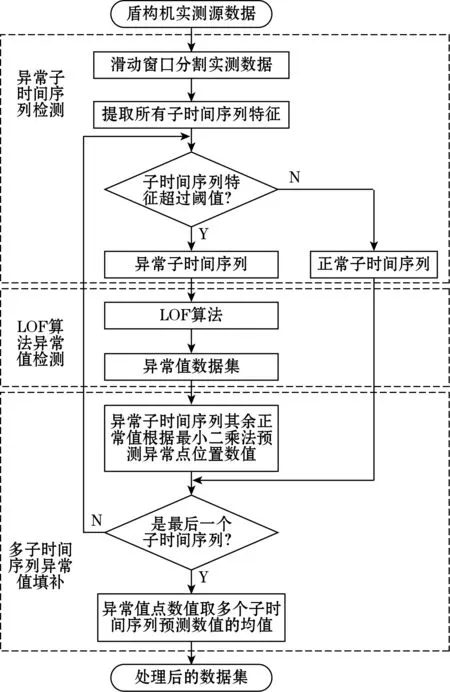
所提方法分为异常值检测和修正2部分。其中异常值检测部分有2个阶段,第1阶段是异常子时间序列检测,采用滑动窗口的方法将未处理的盾构机实测数据划分成若干个子时间序列,随后提取子时间序列的特征,若该特征超过设定的阈值,则认为该序列为异常子时间序列;第2阶段是采用局部离群因子(local outlier factor,LOF)算法检测异常子时间序列中的异常值。异常值修正部分是对异常子序列中正常值点采用最小二乘法建立线性回归模型,预测异常值点数值,最终异常值点数值取多个异常子时间序列预测值的均值。
1.1 异常子时间序列检测
一条时间长度为n的时间序列表示为
X(t)=(x(t1),x(t2),…,x(tn))
式中x(ti)(1≤i≤n)为ti时刻记录的数据,采集时间ti是严格递增的。
采用长度为w(w≪n)的滑动窗口对该时间序列进行等长度分割,步长为r,连续滑动(n-w)/r次,则会形成((n-w)/r)+1个长度为w的子时间序列。
1.1.1 直接方法提取子时间序列特征
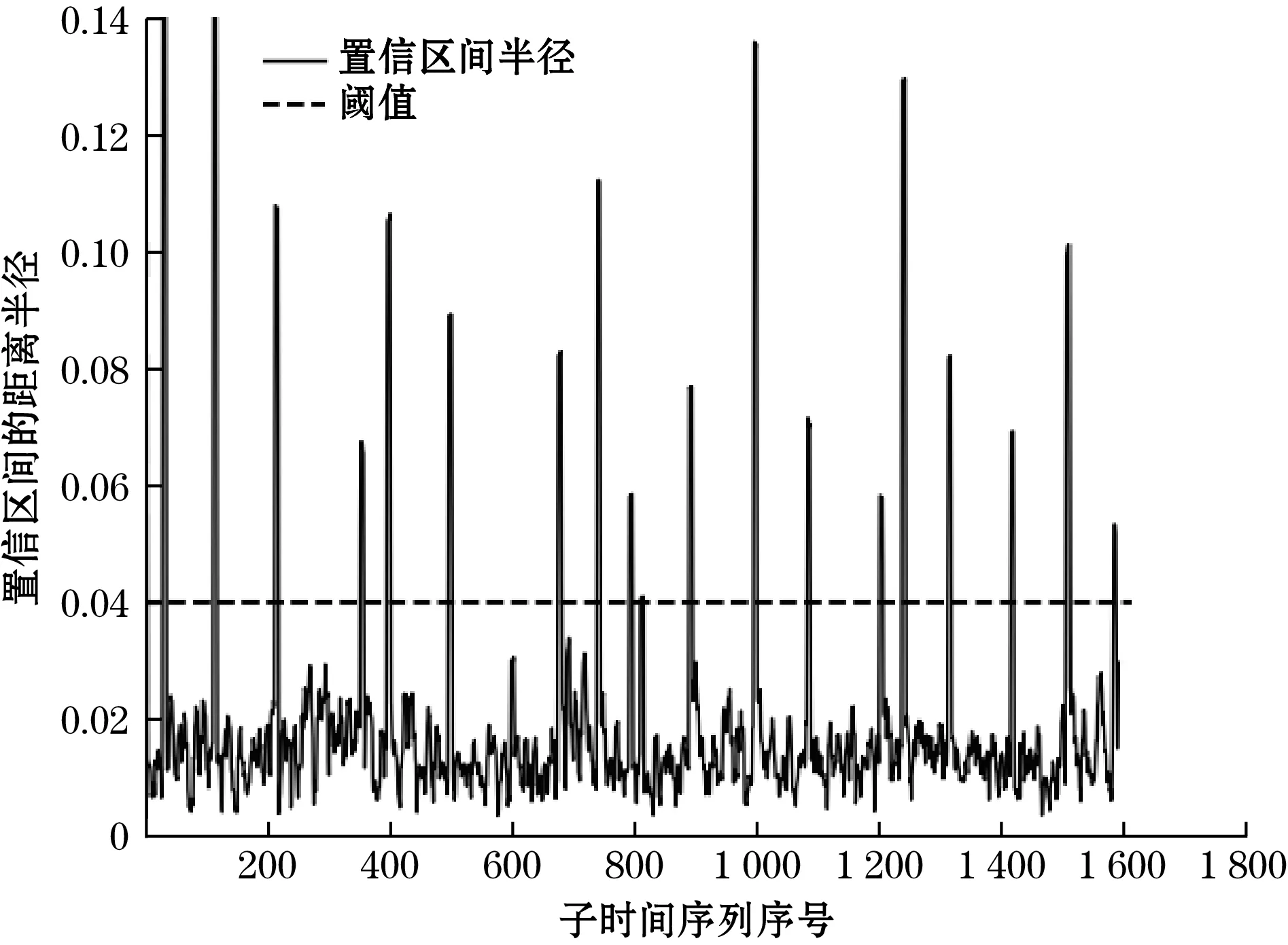
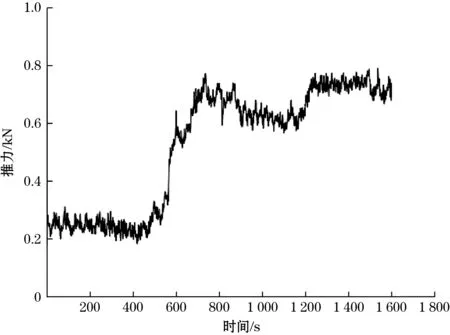
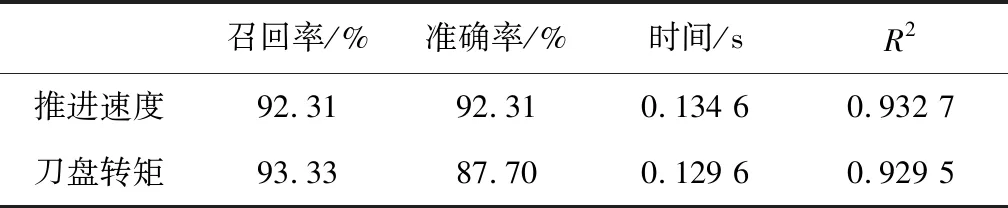
假设时间序列X(t)的某一个子时间序列表示为Xj(1≤j (1) (2) (3) 这样就可计算第j个子时间序列斜率的置信区间半径为 (4) (5) (6) 式中:Z为满足N(0,1)的正态分布随机变量;α为置信水平,本文取α=0.05。 1.1.2 快速方法计算子时间序列斜率均值和均方差 子时间序列特征值提取的关键在于相邻两点斜率的求值k(i),以及后续斜率的均值和均方差的计算。通常情况下时间序列会有较大的长度n,从而就会有(n-w+1)·(w-1)次斜率的计算量,以及(n-w+1)个滑动窗口的斜率均值和均方差的计算量,因此研究如何提高数据的运算效率是非常有必要的。 第j个子时间序列任意两点之间斜率的和与第(j+1)个子时间序列任意两点之间斜率的和之间的关系为 (7) 故第(j+1)个子时间序列只需计算k(j+w)即可。 (8) (9) 式(9)中的分子,由式(8)可得: (10) 将式(10)带入式(9)可得: (11) 式(7)、式(8)和式(11)给出了前后2个子时间序列斜率、斜率均值和斜率均方差之间的关系,通过前一个子时间序列的斜率、斜率均值和斜率均方差计算当前子时间序列的斜率、斜率均值和斜率均方差,会比直接计算更迅速。由表1可知,所提出的快速计算方法与滑动窗口长度w无关,且明显优于直接计算方法。 表1 直接计算和快速计算的时间复杂度 得到子时间序列的特征,即斜率的置信区间半径,若该半径大于阈值γ,则认为该子时间序列为异常子时间序列,其中包含异常值,具体的异常值信息需进一步分析。 根据以上描述,异常子时间序列检测的步骤可总结如下: 输入:长度为n的时间序列,滑动窗口长度w,异常子时间序列判断阈值γ。 输出:异常子时间序列和正常子时间序列。 (1)使用长度为w的滑动窗口对时间序列X(t)进行等长度划分,步长为1,得到若干个子时间序列Xj(1≤j≤n-w+1); (4)将子时间序列斜率的置信区间半径与阈值γ进行比较,初步确定含有异常值的异常子时间序列。 针对每个检测出的异常子时间序列,采用LOF算法[19-20]计算每个数据点的离群因子,以此来识别异常值。 设异常子时间序列为Xl(1≤l≤n-w+1),LOF算法首先计算每个数据点的可达距离,通过可达距离计算数据点的局部可达密度,进一步计算出数据点的局部离群因子。数据点的局部离群因子越大于1,说明该数据点的密度比其邻域内点的平均密度小,该数据点越可能是一个异常值点,反之,则说明该数据点是正常点。在本方法中,计算出异常子数据序列中每个数据点的局部离群因子,采用离群因子中最大值的1/2作为阈值,若一个数据点的离群因子大于阈值,则为异常值点,反之,则为正常点。 点p,o∈Xl,采用式(12)计算出点p到点o的第k可达距离,即: RDk(p,o)=max{k-distance(o),dist(p,o)} (12) 式中:k-distance(o)为点o的K-邻近距离,是指距待测样本点o的最近几个样本中,第k个最近的样本点跟待测检测点o之间的距离;dist(p,o)为点p到点o的欧式距离。 (13) 式中N为数据点的维度。 由式(14)计算点p的局部可达密度为 (14) 式中|Ndistance(p)|为到点p的距离小于k-distance(p)的集合。 由式(15)计算点p的局部离群因子为 (15) 根据以上描述,LOF算法检测异常值步骤可总结如下: 输入:异常子时间序列Xl。 输出:异常子时间序列中的异常值。 (1)使用式(15)计算异常子时间序列中每个数据点的局部离群因子; (2)选取局部离群因子中最大值的1/2作为阈值ρ; (3)将每个数据点的离群因子与阈值ρ进行比较,若大于阈值,则该数据点为异常值,否则为正常值。 最小二乘法[21](least square method,LSM)是通过最小化模型输出与真实值之间的误差平方和计算样本点的最佳匹配模型,在线性回归中,就是试图寻找到一条直线,使得所有样本点到直线上的欧式距离之和最小。 在1.2节中LOF算法从异常子时间序列中检测出具体的异常值点,对异常子时间序列中正常值点采用最小二乘法,建立线性回归模型,预测异常值点位置的数值。本方法中滑动窗口步长r=1,所以异常值点存在于多个子时间序列中,记录异常值点在盾构机实测数据中的索引。若异常值填补数据集中无此索引,则创建该索引和记录该子时间序列中预测异常值点的数值;否则,直接记录该索引位置点的预测值。所有子时间序列检测完后,每个异常值点的最终预测值取其在多个异常子时间序列中的预测值均值。 根据以上描述,基于多子时间序列的异常值填补步骤可总结如下: 输入:异常子时间序列Xl和异常子时间序列中的异常值。 输出:异常值填补数据集。 (1)对输入的异常子时间序列中的正常值采用最小二乘法预测异常值点的数值; (2)记录异常值点在盾构机实测数据中的索引,若异常值填补数据集中无该异常值点索引,则创建该索引和记录预测后的数值,否则,直接记录该索引位置点的预测值; (3)若该子时间序列是最后子时间序列,计算异常值填补数据集中每个异常值点的多个子时间序列预测数值的均值,作为该异常值点最终的填补数据;否则,返回1.1节异常子时间序列检测中步骤(4)。 完整的盾构机实测数据点异常处理方法流程图如图1所示。 图1 盾构机实测数据点异常处理方法流程图 为了评价所提出方法的性能,点异常值检测和异常值填补采用不同的指标衡量。点异常值检测采用召回率R和准确率P,其数值越大,说明方法检测性能越好,计算公式下: (16) (17) 异常值填补采用决定系数R2(coefficient of determination),其数值越接近1,表明填充性能越好,计算公式如下: (18) 为了验证所提方法的有效性和实用性,通过所收集的盾构机实测数据集进行检验。该数据来源于某城市地铁修建中的隧道施工标段,此隧道前段和后端选用盾构掘进施工,中段的硬岩阶段选用传统的矿山法施工。在盾构掘进施工过程中,隧道掘进装备为土压平衡式盾构机,其主要系统参数如表2所示。 表2 盾构机主要系统参数 搭载在该盾构机的数据采集系统采样频率为1次/s。在掘进过程中,传感器采集了刀盘系统、土仓系统、推进系统等子系统运行参数的实测数据。 从盾构机实测数据集中选取88环段分段运行数据进行试验验证。88环段包含1 605个数据样本,选取盾构机推力作为分析对象。在源数据中随机插入20个异常值点,异常值位置依次是6、37、120、221、361、405、506、607、685、749、802、900、1 006、1 094、1 212、1 249、1 324、1 427、1 518、1 595。 本文使用的计算机配置为Windows10操作系统,处理器为Intel(R) Core(TM) i7-6700 CPU @ 3.40 GHz,编程语言为Python3.6.13。 在试验前对源数据采用最小-最大规范化处理,公式如下: (19) 式中:n为盾构机实测数据的数量;min(X)为盾构机实测数据的最小值;max(X)为盾构机实测数据的最大值。 滑动窗口长度为7,步长为1,计算各子时间序列斜率置信区间半径,最优阈值设为γ=0.04,如图2所示。将置信区间半径大于阈值的子时间序列设为异常子时间序列,如图3所示。每个被检测出的异常子时间序列,采用LOF算法识别点异常值,如图4所示。 图2 子时间序列斜率置信区间半径 图3 检测出的异常子时间序列 图4 检测出的异常值点 用准确率、召回率指标和执行时间衡量不同算法的检测结果,将AD-SV-LOF、AD-SV-GG、AD-Variance-LOF、原LOF算法与本文方法进行比较。AD-SV-LOF方法与本文方法都是使用子时间序列斜率置信区间半径作为该子时间序列的特征,但在计算过程中,AD-SV-LOF方法采用直接计算的方式,本文方法采用快速计算的方式。AD-SV-GG方法在异常子识别序列识别阶段与本方法相同,但在异常值识别中采用了Gath-Geva聚类算法,AD-Variance-LOF方法在对异常子时间序列识别中选择传统的置信区间阈值判断。采用10次重复实验,各项指标取其均值,结果如表3所示。 表3 异常检测结果比较 在识别异常子时间序列时,本文方法采用子时间序列斜率的置信区间半径作为子时间序列的特征,能够较好地反映该子时间序列的变化特征,而AD-Variance-LOF方法采用子时间序列的均值和方差描述该子时间序列的结构特征变化情况,不能很好反映子时间序列特征,因此,在召回率R、准确率P评价指标数值上低于本文方法。AD-SV-GG方法在异常值检测阶段采用Gath-Geva聚类算法,Gath-Geva算法的结果会受随机生成的初始矩阵影响[17],只能给出是不是异常值点的判断,相比较而言,基于密度的LOF算法通过给每个数据点都分配一个依赖于邻域密度的离群因子,进而判断该数据点是否为离群点,因此本文方法的评价指标优于AD-SV-GG方法。相对于传统的LOF算法,本文方法在检测过程中考虑到了时间序列数据的结构变化特征,先识别异常子时间序列,再使用LOF算法,因此本文方法的准确率和召回率均优于原LOF算法。 AD-Variance-LOF方法对当前窗口子时间序列进行初步断定时,采用的子时间序列是均值和方差,该方法简单且运行成本低,所以执行时间小于本文方法。AD-SV-LOF在提取子时间序列特征时均采用了直接方法,而本文方法采用了快速方法计算子时间序列的均值和方差,快速计算方法时间复杂度与滑动窗口长度无关,随着数据量的增大,优势越大,所以执行时间比AD-SV-LOF方法少了约0.02 s,但在实际施工过程中,采集的盾构机运行数据量巨大,本文方法的优势会进一步得到体现。 综合以上结果分析,本文方法能够更好地反映窗口内子时间序列的形态信息以及内在变化特征,因此本文方法在召回率R、准确率P评价指标数值上均优于其余 4 种方法。尽管计算成本相比较于AD-Variance-LOF方法有所提升,考虑到本文方法具有较好的异常识别率,且对子时间序列特征采用了快速计算方式,提高了计算效率,故所提出的方法依旧具有较好的实用性。 最后采用基于多子时间序列对异常值进行填补,如图5所示,填补结果的决定系数R2大于0.9,达到了预期。 图5 多子时间序列异常值填补 为进一步验证本文所提方法在盾构机实测数据的适用性,选取盾构机其他重要的2个参数,即推进速度和刀盘扭矩分别进行试验验证。推力、推进速度和刀盘转矩是3种不同的物理量,且具有不同的运行趋势。同样的,对这2种参数随机插入异常值点,用本文方法进行检测和修正试验结果如表4所示。由表4数据可知,本文方法在盾构机其他参数的处理上均取得良好结果,满足了工程数据要求。 表4 盾构机其他参数处理结果 本文针对盾构机实测数据中产生的点异常值进行处理,提出了一种基于滑动窗口的时间序列异常检测方法,通过快速方法计算子时间序列的斜率置信区间半径并识别异常子时间序列,再使用LOF算法对异常子时间序列进行异常值检测。试验结果表明:与以子时间序列均值和方差信息提取子时间序列特征的检测方法和原LOF算法相比,本文方法提高了检测精度;与直接计算子时间斜率置信区间半径的方法相比,本文方法提高了运算效率。针对检测出的异常值点,采用基于多子时间序列对异常值进行填补,试验结果表明,填补效果达到了预期。本文的点异常值检测和修正方法能够满足工程数据的处理要求,但对点异常值的产生原因尚未研究,因此下一步将结合盾构机实测数据的空间相关性对点异常值产生原因进行研究。

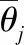






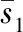
1.2 LOF算法检测异常值
1.3 基于多子时间序列的异常值填补
1.4 评价指标
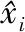
2 试验结果及其分析
2.1 盾构机实测数据基本情况及试验设置

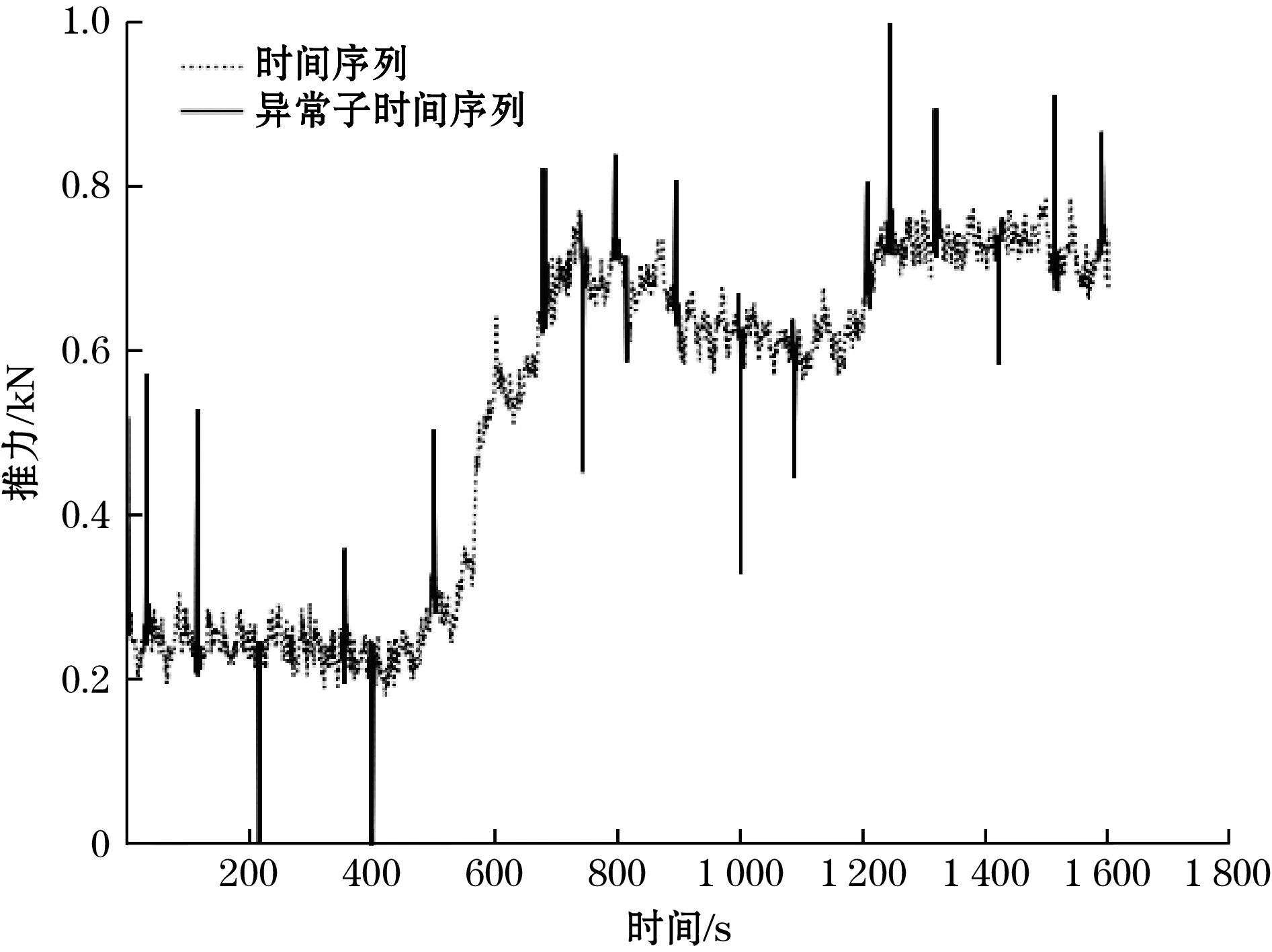
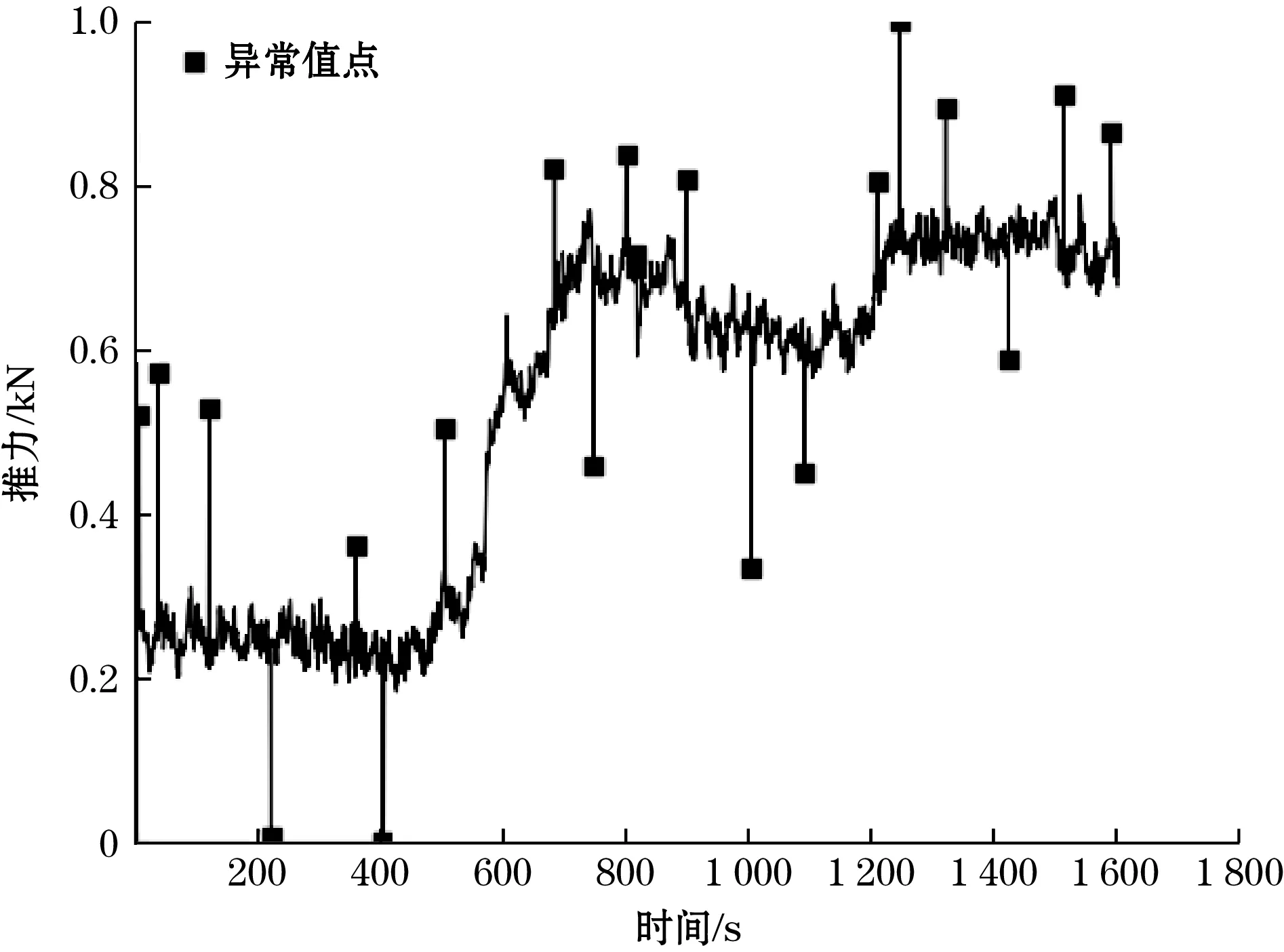
2.2 盾构机实测数据验证

3 结束语
