基于记录查询布隆过滤器的区块链溯源方案
2023-10-26王金洋阳祥贵
唐 飞,王金洋,阳祥贵,甘 宁
(1.重庆邮电大学 网络空间安全与信息法学院,重庆 400065;2.江西昌河航空工业有限公司 工程技术部,江西 景德镇 333002)
0 引 言
假冒和盗版产品数量在全球范围内呈指数级增长,引发的假冒和盗版产品交易问题是各企业在创新驱动的全球经济中面临的主要挑战之一。2019年,经济合作与发展组织和欧盟知识产权局发布的分析研究[1]称,假冒和盗版产品的国际贸易额从2007年的2 500亿美元增加到2013年的4 610亿美元,约占世界进口额的2.5%。欧盟进口假冒和盗版产品近1 160亿美元,约占欧盟进口额的5%。根据2016年公布的统计数据,假冒和盗版产品的交易量已高达5 090亿美元,占世界贸易的3.3%,占非欧盟国家进口额的6.8%。文献[2]显示,市场和无数品牌产品公司对假冒产品的关注度越来越大。据文献[3]所述,假冒产品的贸易活动在全球化经济中不断蔓延,不仅侵犯了企业的商标和版权,而且对企业的销售和利润产生负面影响,还对经济和安全造成更广泛的不利影响。
为了应对假冒产品日益猖獗的问题,人们需要可信、可追溯且低成本的产品防伪解决方案。传统中心化的防伪溯源方案存在内外部风险。内部风险指的是中心化存储导致的内部人员对溯源数据可进行任意篡改删除,溯源数据的可信度无法保证;外部风险指的是防伪码可能被滥用。文献[4]使用伪造成本高的RFID芯片技术作为防伪协议的认证方式;文献[5]使用衍生于RFID的NFC技术,支持手机扫描,具有更广泛的应用性。这些技术的防伪成本都远远高于条形码,并且防伪标识同样存在被盗用的风险,因此使用这些技术并不能解决假冒产品猖獗的问题。企业和消费者都迫切期盼公信力高、防篡改、成本低的防伪解决方案。
区块链采用分布式存储方式,可以防止数据被恶意篡改。文献[6]使用区块链对供应链全流程数据进行存证,但这样的存储方式会导致数据冗余。星际文件系统(interplanetary file system,IPFS)最初由Benet[7]设计,它是一种基于内容可寻址的对等超媒体分发协议。文献[8]引入了微交易的概念,在区块链共识阶段减少了节点之间的通信开销。布隆过滤器常用于过滤非法请求来提高系统效率,文献[9]在基于有向无环图的区块链系统中使用布隆过滤器查询地址的唯一性,节省访问时间。但这些方案仍存在以下缺陷:1)若防伪码泄露或者可复制,防伪系统认证可信度将大打折扣;2)在区块链节点数量众多的时候,区块链共识效率低下、通信量大、通信时间长、未使用高效的共识算法;3)IPFS与区块链结合不够紧密,没有利用好数据IPFS地址也是数据哈希值这一性质。
本文结合IPFS提出的基于记录查询布隆过滤器的区块链防伪溯源方案,安全高效且具有良好的可扩展性,立足于消除消费者对市场的信任危机,建立良好的市场信任体系,具有实际应用价值。
1 预备知识
1.1 区块链
区块链是按时间戳将数据链接而成的特定数据结构,以密码学保证其不可篡改、不可伪造、去中心化、去信任、匿名性、透明化的性质。区块链的结构如图1所示,其起源于文献[10]提出的比特币电子货币系统。
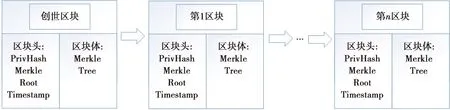
图1 区块链结构Fig.1 Blockchain structure
区块链由单个区块扩展,记录了完整交易历史。区块由区块头和区块体构成,其中区块头存储了前一个区块的哈希值,因此区块数据的更改会导致相应的哈希值的改变,与区块链中存储的历史哈希值就会产生矛盾,这个结构保证了区块的不可篡改性;区块体中存储了一段时间内产生的所有交易,这些交易构成一个Merkle Tree。Merkle Tree的树根值Merkle Root也被保存到区块头中,保证了该区块中所有交易都是不可篡改的;此外,区块头还存有创建区块的时间戳Timestamp。文献[11]提到区块链技术具有防篡改、不可抵赖、分布式一致等特性,特别是它的P2P网络去中心化性质,得到了工业界和学术界的广泛关注;文献[12]利用区块链结合环签密构建了电子证据加密方案;文献[13]使用区块链技术保证医疗资源互联互通。区块链在防伪领域的应用中有着天然的优势。
区块链网络中的节点通过协商一致机制确保交易的有效性和区块本身的有效性。这种协商的过程被称为共识算法,它是大多数(或在某些情况下全部)网络验证者就账本状态达成一致意见的过程,是一组规则和过程,允许在多个参与节点之间维护区块链数据。文献[14]构造了基于有向无环图的区块链共识算法,节省了系统的资源。分布式系统不依赖于中心化服务器,即使特定节点发生故障,区块链网络依旧可以运行。
1.2 IPFS
IPFS基于文件内容进行存储和查询文件,利用网络中的闲置存储资源,建立起一个分布式数据存储系统,将数据分片存储到不同的网络位置,提供快速检索与共享数据的功能,具有防宕机的性质。IPFS利用文件的哈希值作为存储地址,这个特性与区块链存储文件哈希值防篡改的特性天然契合,因此用IPFS存储文件、用区块链存储文件哈希的组合已被广泛接受。
向IPFS上传大于256 KB的文件时,IPFS会自动将文件进行分片处理,每个分片大小为256 K,并将这些分片存储到网络的不同节点上。对于每个分片,都会生成唯一的哈希值。此后,IPFS将所有分片的哈希值串联起来,并计算得到该文件的哈希值。
为了表示文件的哈希,IPFS使用了多哈希格式和Base58编码。存储地址ACID表示为
ACID=Base58(FCode‖Hlength‖Hv)
(1)
(1)式中:多哈希由3部分组成,Hash算法编码FCode、Hash值的长度Hlength、Hash值Hv。
多哈希以固定字节开头,指定使用的哈希算法。IPFS使用SHA-256哈希函数,哈希值长度为32个字节。加上哈希值后,字符串过长,因此,使用Base58编码技术压缩字符串长度,方便存储传播。
1.3 布隆过滤器及其变种
布隆过滤器(bloom filter,BF)由文献[15]在1970年提出。它可以提供成员性证明,具有查询效率高且内存占用小的优点,本文改进了布隆过滤器使其具有记忆功能,并将改进后的布隆过滤器用于过滤非法查询请求以节省服务器资源。
布隆过滤器由m比特的位数组S={x0x1…xm-1}以及k个相互独立的哈希函数{H0H1…Hk-1}构成,初始布隆过滤器的位数组中存储的数值均为0。插入元素ci时,首先,将元素ci输入k个不同的哈希函数中进行计算得到k个哈希值;然后,对哈希值做模运算;最后,将模运算的结果作为位数组中的下标,将k个对应的下标的值设置为1。
判断集合S中是否存在元素x,需要将x通过k个哈希函数计算后,检查对应的k个位置,若k个位置中存在0,则元素x一定不在集合S中;反之,x在集合S中。当x∉S被判定为x∈S时,认为布隆过滤器发生了误判。插入n个元素时,误判率fp表示为
(2)
(2)式中:n为插入元素个数,k为哈希函数个数,m为布隆过滤器长度,fp为布隆过滤器误判率。
计数布隆过滤器[16](counting bloom filter,CBF)是一种在BF的基础上进行改进的数据结构,它将BF中的每一位扩展成一个计数器,插入元素时,如果哈希函数映射到同一位置,将对应位置计数器的值加1;删除元素时,将对应位置计数器的值减1。
光谱布隆过滤器[17](spectral bloom filters,SBF)对CBF进行进一步改造。CBF的设计初衷也不在于能实现计数功能,而是可以实现元素的删除。对于CBF而言,由于每个下标对应的值不一致,但每一个计数器的存储位数一致,因此,若要使用CBF来进行记录插入次数,则要以最大插入次数来设置计数器的大小,这样会造成内存的浪费。SBF使用偏移数组来记录不同长度的计数器在内存中存储的内存起始地址,实现了计数器位数的动态调整。
2 基于区块链的产品防伪溯源方案
2.1 系统模型
本方案采用联盟链和IPFS结合的方式构造方案。联盟链中各节点部署智能合约并共同参与维护区块链账本,为消费者提供查询服务并且保障商家发送数据的真实性。IPFS通过计算上传数据哈希值得到溯源数据地址,可以高效地将数据哈希值上链,并将溯源数据上传到IPFS中。防伪溯源系统结构如图2所示。
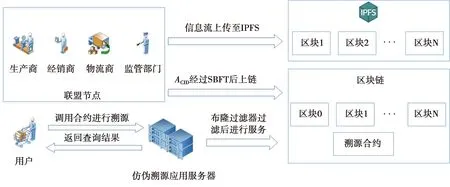
图2 防伪溯源系统结构Fig.2 Structure diagram of anti-counterfeiting traceability system
本方案主体由产生产品溯源数据的生产商、经销商、物流商、监管部门4个节点以及消费者构成。生产商负责产品的生产以及产品防伪码的生成,记录和上传产品的生产溯源数据到IPFS中,并将生产溯源数据在IPFS中的存储地址发起共识上链;经销商对产品的出入库状态信息进行记录和上链;物流商对产品的物流以及出入库信息进行记录和上链;监管部门参与区块链的共识过程,保证上链数据的真实性和不可篡改性;消费者通过防伪标识查询产品溯源数据。
方案的符号以及参数定义如表1所示。

表1 系统主要符号和参数Tab.1 Main symbols and parameters of the system
本方案由以下3个阶段构造完成。
1)系统初始化。各方建立区块链网络,部署链码。
2)溯源数据存储及上链。供应链节点将产生数据上传至IPFS,并将数据在IPFS中的存储地址经过共识过程后完成上链。
3)防伪查询阶段。消费者登录防伪查询平台后,通过扫描产品的条形码进行防伪溯源查询,生产商节点调用布隆过滤器算法,过滤无效的AUID,然后调用智能合约,以条形码中存储的AUID为索引找到溯源数据的ACID集合,然后将ACID集合发送给消费者,消费者利用ACID下载溯源数据即可完成查询。
2.2 系统初始化
1)网络初始化。生产商、经销商、物流商、监管部门组建一个区块链网络。
2)链码部署。方案设计了一个溯源数据查询合约为消费者提供产品的防伪溯源服务,返回给消费者该产品的防伪查询结果以及产品的溯源数据。消费者扫描二维码后得到AUID并发送给服务器进行查询。服务器先将AUID输入具有记录查询功能的布隆过滤器进行计算,若结果是非法AUID则返回查询结果“Fake”;反之,调用溯源数据查询合约查找该AUID对应的溯源数据在IPFS中的存储地址ACID,返回查询结果“Real”以及ACID。
溯源过程通过AUID作为检索关键字对区块链中的溯源数据进行搜索,输出ACID。本方案以Fabric[18]为例,在链码中使用ChaincodeStubInterface接口的GetHistoryForKey方法在StateDB中对指定AUID查询其历史数据。返回的数据是byte数组,需要转换为String,然后再JSON反序列化。溯源数据查询合约设计如下所示。
合约1溯源数据查询
输入为AUID,输出为溯源数据下载地址ACID=ACID1‖ACID2‖…‖ACIDn,具体流程如下。
1.ACID←GetHistoryForKey(AUID)//检索AUID得到ACID集合
2.ACID=String(ACID)//将byte数组转换为String
3.ACID=Deserialize(ACID)//JSON反序列化
4. returnACID
2.3 溯源数据存储及上链
数据存储及上链过程见图3,共识过程使用SBFT算法[19]。

图3 数据存储与上链Fig.3 Data storage and upchain
首先,生产商为产品生成AUID和二维码,并将此AUID广播给其他节点,AUID为检索溯源数据的索引值,以便其他节点在上传关于此产品的数据时也能关联AUID;其次,生产商节点将溯源数据上传至IPFS,得到IPFS返回的ACID;最后,将上传数据的记录进行SBFT共识后上链,后续可以通过检索AUID得到对应产品的ACID。
交易数据生成后,数据拥有者将交易数据、验证数据、参数等打包成交易一起发送至区块链进行广播,所有节点接收并验证交易,经过SBFT共识算法验证后将交易写入区块链网络中。
2.4 防伪溯源查询
消费者溯源查询业务逻辑见图4。
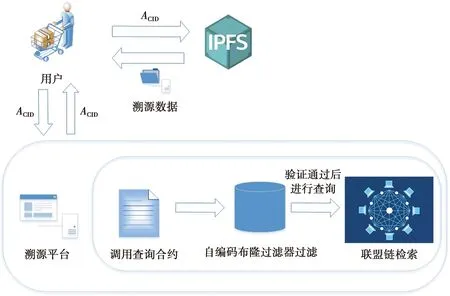
图4 业务逻辑Fig.4 Business logic
产品防伪查询步骤如下。
1)消费者登录溯源平台,扫描产品二维码读取AUID并发送查询请求Request。
2)溯源平台在收到查询请求后,将AUID放入布隆过滤器中进行验证,返回验证结果。
3)若消费者查询的AUID为假冒产品,则直接向消费者返回查询结果。若消费者查询结果为正品,则需要调用溯源数据查询合约,根据产品AUID对溯源数据进行检索,找到产品在IPFS中的存储地址ACID,返回查询结果和ACID。消费者可以通过ACID自行下载溯源数据,节省企业的存储成本和管理成本。
3 具有记录查询功能的布隆过滤器
在不使用布隆过滤器并且AUID非法的情况下进行溯源查询,即便检索整个区块链账本都无法找到符合要求的溯源数据,将极大浪费服务器资源,故使用布隆过滤器对方案中发起的溯源查询请求进行过滤是必要的。
传统的布隆过滤器没有记忆功能,对同一个元素的多次查询无法进行区分。例如,对存在于集合的某个成员进行多次查询都会显示该成员在集合中且会返回相同的结果。在防伪溯源应用场景下,多次查询同一个正品防伪码都会被判断为正品,无法防止防伪码被泄露而造成的防伪码滥用问题,因此,传统的布隆过滤器不适用于防伪方案。CBF和SBF可以记录查询次数,但计数器需要占用较大内存,尤其是某一个元素查询次数较多时所需要消耗的存储空间更大。而对于产品防伪而言,只有第一次的查询具有可信度,当防伪码被泄露则可能出现某个元素被多次查询的情况。因此,只需要记录是否为首次查询即可。
为了让布隆过滤器对查找过的元素有记忆功能,本文将布隆过滤器进行改进设计出一种具有查询记录功能的布隆过滤器(query-recorded bloom filter,QRBF)。本质上是将原本的位组1位对应一个布隆过滤器的下标进行更改,使得位组2位对应QRBF的一个下标,使得QRBF的状态值从2种变为4种。但由于实际的防伪方案中,实际的状态值只需要“0”、“1”、“2”三种状态。QRBF不同状态值以及对应的含义如表2所示。

表2 QRBF状态值定义Tab.2 QRBF status value definition
3.1 初始化
布隆过滤器一般使用Bitmap进行底层实现,Bitmap是一个以位为单位的数组,数组下标对应布隆过滤器计算出的哈希值,数组元素记录布隆过滤器的状态变化。
在传统的布隆过滤器实现中,用1位代表布隆过滤器的状态,32位的Bitmap代表一个m为32的布隆过滤器,初始状态每一位都为0。图5展示的是一个长度为32位的Bitmap。
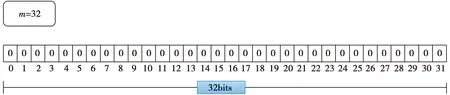
图5 传统布隆过滤器的存储结构Fig.5 Storage structure of traditional bloom filter
QRBF的存储结构设计如图6所示,32位的Bitmap对应了一个m为16的QRBF。第一行为位组的底层结构,第二行为实际QRBF的底层结构。

图6 QRBF的存储结构Fig.6 Storage structure for QRBF
QRBF的初始化合约如下所示。
合约2QBRF初始化
输入为布隆过滤器的字节长度M。输出为初始化后的布隆过滤器Bf。
1. ifM<=0 then
2. return null//检查输入的有效性
3.Bf=allocate(byte[·],M)//使用内存分配函数为Bf分配内存
4. returnBf//返回Bf
3.2 布隆过滤器操作
1)插入。原始布隆过滤器更改位数组的操作只有插入元素,而QRBF中的更改位数组的操作有2个,分别是插入元素和防伪查询。QRBF初始状态为0,产品出厂时,将AUID加入到QRBF中,对应下标的0变为1,若为0之外的状态则保持不变。QRBF的插入合约如下所示。
合约3QBRF插入合约
插入合约的输入为AUID、Bf,输出为插入操作后的Bf。
1. for 0≤i≤k-1//计算k个哈希值,并找到Bf对应位置的值
2. ifBf[hashi(AUID)]==0 then//判断BF中被hashi(AUID)映射的位置是否已被更改过
3.Bf[hashi(AUID)]=1//若未被更改,将对应的位组改为1
4. end for
5. returnBf
图7为对QRBF进行插入的几种情况的演示。
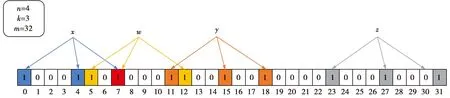
图7 QRBF插入流程Fig.7 Insertion process of QRBF
其中元素x、y、z进行哈希运算后映射到对应下标的值都为0,因此将各自位的值都改为1。w在进行插入时,其中一位下标值更改为1,故不再对该下标对应的值进行修改。
2)查询。消费者进行查询时,将对应下标的1改为2,若对应下标都为2,则说明该AUID已被查询过。注意,消费者查询的AUID对应值为0,说明此AUID为非法AUID,则返回该产品为假冒产品,不对QRBF进行任何修改,此规则可以防止恶意者发起大量非法查询使得QRBF失效。QRBF查询如合约4所示。
合约4QBRF查询合约
输入为产品AUID、Bf,输出查询结果。
1. for 0≤i≤k-1//计算k个哈希值,并找到Bf对应位置的值
2. ifBf[hashi(AUID)]==0 then
3. return "Fake"
4. else ifBf[hashi(AUID)]==1 then
5.Aflag=1//Aflag用于标记哈希对应的位置是否存在等于1的值
6. else ifBf[hashi(AUID)]==2 then
7.Acount++//Acount用于记录等于2的值的个数,若全为2,则证明该AUID已被查询过
8. end for
9. ifAcount==kthen
10. return "Have been queried"
11. ifAflag==1 then//当Aflag=1时,不可能存在等于0的位,因为在插入操作时已经全部置为1;也不可能是被查询过的,因为被查询过的AUID的位全被置为了2;只有在所有位都为1时才会进行变换,即非法查询不能使得布隆过滤器的状态产生变化
12. for 0≤i≤k-1//返回查询结果为正品前需要将这个AUID对应位置的值改为2,以便下次查询时能得到正确的结果
13.Bf[hashi(AUID)]=2
14. end for
15. return "Real"
16. ifAflag==0 then//说明所有位都为0,为非法AUID
17. return "Fake"
图8为对QRBF进行查询的几种情况的演示。其中x、y、z、w已经进行了插入,首先对x进行查询,再对w进行查询,其中对x查询时,每一个映射的下标值都为1,则将每一位对应在BitMap中的值都更新为2。对w进行查询时,第7位上的值已经为2,但其余两位为1,则只更改值为1的其他下标对应位组的元素为2。若查询的结果中k个哈希对应位组的值都为0,说明该AUID为商家没有在布隆过滤器中进行注册的AUID。若查询的k个哈希对应位组的值都为2,则说明该AUID至少进行了2次防伪验证查询。
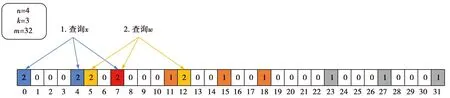
图8 QRBF查询流程Fig.8 Query process of QRBF
对于想证明自己是首次查询的用户,服务器会发送以自己私钥签名的证书,证书定义为Ct=Sign(Qlog,Isk)=(S,H(Qlog)),其中Qlog=T‖Did,Did为唯一设备号,Qlog中包含的信息可以唯一表示用户以及查询行为。
3.3 布隆过滤器误判率
由于QRBF的结构以及更新的方式相比于传统的布隆过滤器都有所不同,所以需要对误判率重新进行分析与计算。使QRBF的值产生变化的布隆过滤器操作有2个,一是出厂登记时将新元素插入到QRBF中,二是查询成功时将记录存储到QRBF中。文献[20]提出了基于门限功能的计数布隆过滤器的概率分析,其结构与QRBF相似,因此使用相同的思路对QRBF进行误判率分析。
在有m个元素的QRBF中,使用哈希函数将n个元素插入到QRBF中,每个元素都被输入到k个哈希函数中,然后根据算出的哈希值递增该位置的值,QRBF中下标值l具有的二项式分布的概率质量函数定义表示为
(3)
对于元素映射对应值为l的误判率表示为
(4)
(4)式中:θ代表布隆过滤器的状态值。

pfp(θ,k,n,m)
(5)
泊松分布的累计质量函数是正则化的不完全gamma函数[21],继续将上式转换成
(6)
QRBF误判率计算如下。根据前述布隆过滤器的设计,状态值θ有0、1、2三种情况。由于布隆过滤器中不会把存在于集合中的元素误判为非集合元素,因此,当θ=0时,fp(θ=0)=0。θ=1和θ=2时的误判率计算式为
(7)
(8)
于是QRBF误判率为
(9)

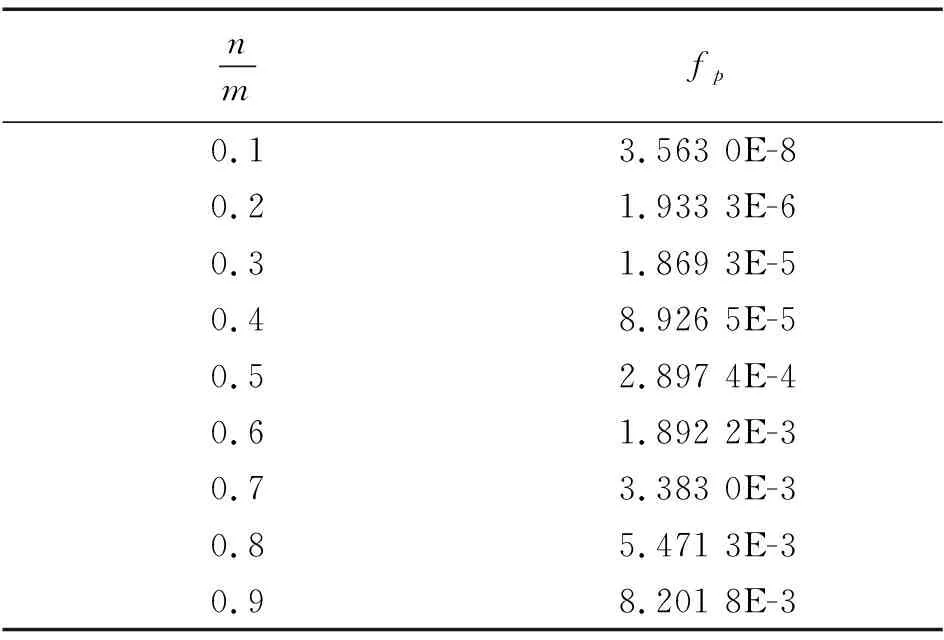
表3 QRBF误判率分析Tab.3 False positive rate analysis of QRBF
QRBF误判率分析如表3所示。由表3可见,当拥挤指数较低时,误判率几乎可忽略不计;当拥挤指数较高时,误判率依旧在可接受的范围内。因此,只要使用者对QRBF具体使用场景中插入元素个数以及元素被查询次数进行提前调研与预估,合理地初始化QRBF的大小,就几乎不会出现误判的情况。
4 方案分析与评估
本实验采用物理机来进行测试。测试平台为HUAWEI MateBook14,操作系统为Ubuntu18.04,处理器为Intel i7-8565U,主频为1.8 GHz,内存为8 GB。
4.1 共识算法性能分析
1)通信量。使用SBFT可以根据恶意节点数量动态切换共识机制,在恶意节点满足快速模式的数量要求时,使用的两阶段共识比三阶段共识的PBFT更高效。
在任何情况下,单轮通信次数都可以由n(n-1)次减小为2n次,大大降低了共识的通信开销,提高了共识效率。
2)签名性能。在共识机制中,任何节点对于自己广播的数据都需要进行签名操作,其他节点通过验签判断数据的真实性,并且SBFT通过门限签名的结果进入不同模式的共识机制,因此签名算法性能的提高对于SBFT性能的提高是有直接影响的。以蚂蚁链为例,系统共有近10亿账户,每天“上链量”超过1亿次,使用的共识机制是PBFT,签名算法使用BLS[22],若使用SM2算法[23],则系统整体的性能将会得到提高,文献[24]也提到了签名算法性能对系统的重要性。本文对签名以及验签进行了实验。BLS以及SM2测试代码基于C语言进行实现,基于双线性对的密码库PBC[25]中所提供。实验结果如表4所示。

表4 P256曲线下的签名效率对比Tab.4 Comparison of signature efficiency P256 curve /ms
4.2 具有记录查询功能的布隆过滤器效率
QRBF插入效率和查询效率的时间开销实验结果如图9—图10所示,插入元素以及查询元素的时间开销都为纳秒级。若使用数据库存储方式,所占用的时间开销将为毫秒级,在亿万级数据量的情形下时间开销将更大。
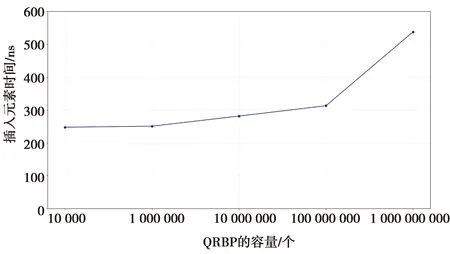
图9 QRBF插入时间开销Fig.9 Insertiontime cost of QRBF

图10 QRBF查询操作的时间开销Fig.10 Insertiontime cost of QRBF
4.3 具有记录查询功能的布隆过滤器的内存开销
本文将QRBF与CBF、SBF进行内存开销的对比。CBF每一个元素都占用相同位数,位数取决于被查询次数最多的元素所对应的计数器占用位数。SBF使用动态调整的位数来存储不同元素的查询次数,使用偏移数组来存储各计数器对应的存储位置。
假设某一产品的防伪码被盗用1万次,则QRBF所使用的内存将是CBF的1/7,也远远少于使用额外偏移数组的SBF。
4.4 功能性分析
文献[26]实现了一种基于区块链的电商平台产品信息追溯和防伪模型,将区块链的去中心化、可溯源、防篡改、防单点故障的特性应用到防伪系统中,不依赖商家提供查询结果。文献[27]将区块链技术和NFC芯片相结合,设计了一种应用于供应链的安全防伪系统,该防伪码不可伪造,但因成本过高不便于推广。文献[28]使用了IPFS存储实际数据,减少了数据在区块链中的冗余存储。表5对上述方案的系统功能进行了对比。
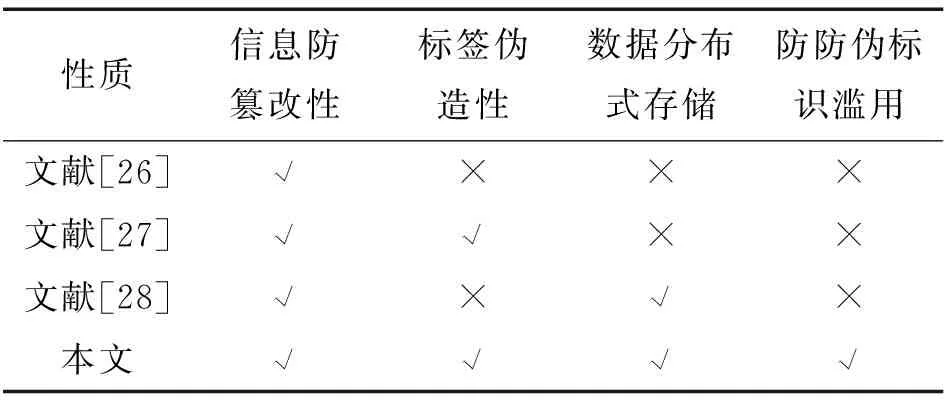
表5 系统功能对比Tab.5 Comparison of system functions
5 结束语
本文研究了基于记录查询布隆过滤器的区块链溯源方案,使用IPFS减小上链数据的负担和运行服务器方的负担;使用SBFT以及SM2算法提高系统效率;还使用自定义的QRBF过滤无效的AUID查询,避免了系统资源的浪费。QRBF可以记录此AUID的查询次数,若不是首次查询,则对消费者进行提醒,一定程度上防止了产品防伪标识的滥用。该方案为商家提供高效率的溯源方案,为消费者提供可信的产品溯源数据,为防伪技术提供解决思路。
