霉变小麦气相色谱–离子迁移谱的宽度学习检测模型
2023-10-26廉飞宇
秦 瑶,廉飞宇,潘 泉,张 元
(1.河南工业大学粮食信息处理与控制教育部重点实验室,河南郑州 450001;2.河南工业大学信息科学与工程学院,河南郑州 450001;3.西北工业大学自动化学院,陕西西安 710000;4.信息融合技术教育部重点实验室,陕西西安 710000)
1 引言
粮食安全是国家安全的重要组成部分,其中粮食的储藏安全是粮食安全的重要环节.特别是近年来紧张的国际局势和新冠肺炎疫情影响下,粮食作为重要战略储备物资,其保障国家稳定的基石作用更加凸显.然而,由于产后管理及储藏不当,造成我国每年的粮食产后损失率高达7%∼11%,其中霉变、生虫造成的损失约占粮食损失总量的40.3%,因此必要的储粮霉变检测技术必不可少.
小麦是我国最主要的储粮品种,其霉变检测技术可分为3大类: 电子鼻技术、图像处理技术和光谱技术.1)电子鼻是使用最广泛的小麦霉变检测技术.2004年,邹小波等使用8只日本费加罗公司生产的二氧化锡气敏传感器构成阵列,采用主成分分析和RBF神经网络对小麦进行霉变识别[1],证实了电子鼻在小麦霉变检测中的可用性.此后,Paolesse等[2]、Perkowski等[3]用电子鼻检测小麦中的真菌污染,也取得了一定的效果.但电子鼻检测效果受气体传感器检测类型的影响和制约,仅对小麦霉变时的部分挥发性物质敏感,对霉变早期检测预警的准确度不够.2)图像处理技术可通过对小麦外观图像的直接识别,进行霉变位置预警[4–5].其优势是检测速度快、智能化程度高,但却存在检测结果受光照、清晰度等图像采集质量影响较大,使得霉变识别率不稳定,无法有效地指导仓内防霉干预作业.3)光谱技术近年来在小麦品质检测上的应用逐渐增多,特别是太赫兹光谱技术的成熟和应用,为小麦霉变的早期检测带来契机.葛宏义等[6]研究了太赫兹时域光谱系统在小麦品质检测中的应用,选用AdaBoost 分类器和支持向量机(support vector machine,SVM)方法,建立了小麦品质多项太赫兹光学指标的分类融合模型,为小麦品质的快速检测提供了一种新方法.廉飞宇等[7]研究了利用太赫兹时域光谱技术检测玉米中黄曲霉毒素的方法,建立了相关的主成份分析模型,证实了太赫兹光谱对真菌检测的有效性.然而,光谱技术由于其还缺少相关的行业技术标准,研究多停留在实验上,离实用化还有一定距离.
目前小麦霉变的各种检测方法还不能满足储粮企业的实际需求,因此,研究开发检测精度高、速度快,能够有效实现小麦霉变早期检测预警的新方法十分必要.由于小麦在霉变初期,其挥发性有机物的成分会先于图像、光谱等特征发生变化,因此,本文提出一种基于气相色谱–离子迁移光谱(gas chromatographyion migration spectrum,GC-IMS)的小麦霉变检测技术.该方法是一种新的气相分离检测技术[8],结合了气相色谱响应快速和离子迁移谱灵敏度高的优点,特别适用于挥发性有机物的痕量检测,具有检测速度快、精度高、操作简单的优点,为小麦霉变的检测及分类提供了一种良好的潜在解决方案.
然而,高精度的预测离不开有效的识别方法.目前,对于商业化的GC-IMS系统所提供的样品指纹图谱的识别,常采用传统的机器学习方法,如支持向量机[9],但此类方法提取的特征有限且需要人工设定,分类准确率不能满足应用需求.虽然浅层神经网络也能应对图像识别的问题,但由于其学习能力差,难以提取到识别对象深层次的抽象特征,导致其识别精度低、泛化能力差且更容易欠拟合.近年来,深度学习技术在检测与识别、图像处理领域取得了重大突破.然而,深度学习网络是一个多层神经网络,需要更多的样本,更复杂的网络结构和更长的训练时间才能达到预期的效果.如曹珍贯等[10]采用改进的卷积神经网络对肺结节进行识别,使用了4000张肺部图像,扩增到10000 张图片后对模型进行8000多次的迭代训练;欧巧凤等[11]采用轻量级神经网络YOLOv3 对车检图像进行检测与识别,使用19125 幅车检图像对12 层的YOLOv3 网络进行训练;武文娟[12]等提出了一种轻量级的Emfacenet卷积神经网络,采用10575个不同个体的494414张面部图像进行模型训练.模型采用的数据集都十分庞大.
对于小麦霉变的早期预警研究,从GC-IMS中获得的指纹图集是一个小样本集,数据量远不能满足深度学习的建模要求,会产生严重的过拟合而导致模型的泛化性极差,即所谓的小样本困境[13].此类问题通常的解决办法是数据扩增,如图像翻转、截取、拉伸等[14],但GC-IMS指纹谱图像本身具有一定对称结构,也不适合使用以上的数据扩增方法.
针对深度学习在小样本条件下泛化性能差、网络模型训练速度慢、消耗资源多的问题,文献[15–16]在2017年提出了宽度学习网络(broad learning network,BLN),随后证明了它的通用逼近能力[17].BLN的结构与深度神经网络有很大不同,相比于“深度”结构来说,BLN更倾向于将网络向“宽度”方向构造,而在深度方向上仍保留传统的输入层、隐藏层和输出层的3层结构,使得网络结构比起深度学习大大简化.
本文将宽度学习应用于小麦霉变样品的GC-IMS指纹图谱识别,在宽度学习的隐藏层中引入了注意力机制,提出了一种基于空间注意力机制的宽度学习网络模型(broad learning based on spatial attention mechanism,BLN-SAM).该模型克服了深度学习模型在小样本下带来的过拟合、泛化性差等缺陷,能够在小样本条件下达到甚至优于深度模型的识别率.
2 方法
2.1 宽度学习网络的基本结构
宽度学习网络(BLN)是在随机向量函数链式神经网络(random vector functional-link neural network,RVFLNN)的基础上产生的,其网络结构如图1 所示.BLN 的结构与传统的神经网络相似,也是由输入层、隐藏层和输出层3层组成,不同的是其隐藏层通常由多组特征节点和增强节点组成.需要注意的是,输入数据不是直接与特征节点相连,而是经过某种映射后作为特征节点的值.

图1 宽度学习模型的基本网络结构Fig.1 The basic network model of broad learning
2.1.1 输入层
在BLN的输入层,神经元个数等于输入数据的属性数.如输入数据有M个属性,则第i个输入数据可表示为向量xi=(xi1xi2···xiM)∈RM.如果一共有N条这样的输入数据,则有N个M维的输入向量,可用矩阵表示为X=(x1x2···xi···xN)T∈RN×M.BLN对输入X进行批量处理,送入特征节点进行变换.由于输入数据的各属性具有不同的类型,为了处理方便,输入的原始数据需要经过归一化处理.
2.1.2 隐藏层
由图1的基本结构可知,BLN的隐藏层是由特征节点层和增强节点层组成的.
1)特征节点.假定BLN的特征节点层由n组节点Z1,Z2,···,Zn组成,且第Zi组节点又由q个神经元组成,则输入数据X经过Zi的特征映射后可表示为
式中:φi是激活函数,可以选用常见的Sigmoid函数、ReLU函数等,各组映射的激活函数可以不同;Wei ∈RM×q是网络的权重矩阵,初始值可随机产生;βei ∈RN×q是偏置矩阵,初始值也是随机的,并且这两个矩阵可通过稀疏自编码器微调以提取输入数据中更为稀疏的特征.
2)增强节点.BLN 的增强节点层可表示为H1,H2,···,Hm,假设其中的第j组增强节Hj点包含了r个神经元,则由来自特征节点层的矩阵Zn,经增强节点层后可得
式中:ξj为激活函数,可以选用Sigmoid函数、ReLU等函数;Whj ∈Rnq×r为权重矩阵;βhj ∈RN×r为偏置矩阵,其初始值均为随机值.
2.1.3 输出层
BLN的输出层既可以处理回归问题也可以处理分类问题.对于分类问题,标签的编码可采用独热码.如输入样本xi的标签为yi=(yi1,yi2,···,yiQ)∈RQ,则独热码[0 0 1··· 0]表示输入样本是第3类.所有的标签可表示为
式中:Q为类别数,Y为标签矩阵.输入样本X经过BLN后,得到如下的输出矩阵:
2.2 宽度学习网络的目标函数与正则化
为了解决模型的过拟合,增强其泛化性,同深度学习类似,本文也采用了对损失函数正则化的方法.本文中,宽度学习模型的损失函数仍采用交叉熵损失,定义如下:
其中:n为样本量,tik的取值为0或1(当样本i属于第k个类别时为1,否则为0),yik表示样本xi属于第k个类别的概率.
正则化就是在损失函数中加入被称为正则项的惩罚项.即在模型训练时优化的不再是损失函数,而是损失函数加上正则项,即
其中:Γ(f)为正则化项,λ为正则化系数.
正则化的目的是通过控制权重的大小,降低模型在训练过程中噪声的影响,从而减轻过拟合.常用的正则化方法有L1范数和L2范数.考虑到L1范数会让参数变得更稀疏(更多的参数变为0),且计算偏导数时较复杂,本文使用了L2范数.L2范数是指对向量中各元素的平方和求根后的结果,即
其中:W为权值参数,‖W‖2为对权值参数W求L2范数.
2.3 宽度学习网络中的空间注意力模块
为了增强BLN模型对重要特征的提取,压缩模型对次要特征和无关特征的关注,本文在以上的宽度学习基本网络模型的输入层和隐藏层间引入了空间注意力机制(SAM),并把引入这种基于空间注意力机制的宽度学习网络模型称为BLN-SAM.
注意力机制是机器学习中的一种数据处理方法,它可以使网络能够自动识别出图片中需要注意的地方.从实现的方法上看,注意力机制通过神经网络的操作生成一个掩码Mask,在Mask上给出一个评分(一般由Softmax层给出一个概率值),该评分说明了需要关注的程度.对空间进行掩码的生成并进行评分,则称为空间注意力机制.
注意力机制可以认为是一种连接权重的分配机制,对于评分较高的区域给与更大的连接权重.图2为本文SAM网络的结构图.本文SAM将图像视为图的特殊形式,每个像素代表一个节点.图中结构矩阵用于表达节点之间的结构,并且在计算注意力权重时同时使用了节点的特征信息和结构信息,使得注意网络能够提取更多的且更重要的特征信息,提高了模型的预测性能.

图2 BLN的SAM网络模块Fig.2 Network module of SAM of BLN
图2中:S为n×dz的结构矩阵,n为给定节点的邻节点数;Sj是结构矩阵中的第j行,表示的是一个邻节点的结构向量;dz表示的是每个结构向量的特征维度;xi表示的是输入序列的第i个元素;W为权重矩阵;αij表示的是xi相对xj的注意力权重,其计算公式如式(8)所示.用来比较两个输入元素的缩放点积函数,计算公式如式(9)所示.
根据输入节点特征得到的特征计算公式如式(10)所示,Ni是节点vi的邻节点集.
2.4 模型总体结构
本文模型的总体结构图如图3所示.输入层输入样本的离子迁移指纹图像,SAM模块增强对图像重要区域的特征提取,压缩对次要区域和无关区域的关注;特征节点层和增强节点层构成隐藏层完成特征的提取;全连接层和Softmax层构成输出层,全连接层实现分类,其中的每个神经元采用ReLU作为激活函数,可以看作是一个分类的Softmax层实现逻辑回归,输出各个类别的概率,其节点数与分类的类别数相同.

图3 模型总体结构图Fig.3 Overall structure diagram of model
3 实验
3.1 仪器
GC-IMS分析仪是一种基于GC和IMS技术的仪器,工作原理如图4所示.

图4 GC-IMS工作原理图Fig.4 Working diagram of GC-IMS
首先,仪器将待测物质分子、离子引入线性电场中.在电场中,通过与反向漂移的气体分子碰撞,以及电场力等一系列相互作用,得到一个恒定的速度,称为迁移率.不同物质的离子有不同的迁移率.IMS类似于质谱,但质谱是基于电荷–质量比(m/z),而IMS是基于离子迁移率.因此在IMS中,只要迁移率不同,就可以分离出一些异构体.实验采用了德国G.A.S.公司的FlavourSpec®食品风味分析及质量控制系统.这是一款高端的GC-IMS分析仪器,配套的分析软件包括LAV(labora-tory analytical viewer)、GalleryPlot插件、动态主成分分析插件.LAV用于查看谱图(2D俯视图和3D视图);GalleryPlot插件用于直观、定性地比较不同样品挥发性有机物的差异;动态主成分分析插件用于样本聚类分析和未知样本的快速聚类.
3.2 样品
采集6种小麦样品: 正常小麦(Wheat-01)、虫蚀小麦(Wheat-02)、陈化小麦(Wheat-03)、轻度霉变小麦(Wheat-04)、中度霉变小麦(Wheat-05)和重度霉变小麦(Wheat-06),见表1.所有样品剔除杂质并粉碎,每种样品保留500 g粉末.每5 g粉末作为一个样本,每种样品含有100个样本.在100个样本中,70个用于训练模型,30个用于测试模型.因此,6种小麦样品共产生600个样本,其中420个样本组成训练集,180个样本组成测试集.

表1 实验使用的样品类型Table 1 The types of samples used in experiments
3.3 测试条件
使用G.A.S公司的FlavourSpec®气相–离子迁移谱仪进行测试.在不对样本做任何前处理的前提下,顶空进样后直接加热,快速检测待测样本中的挥发性有机成分.利用配备的软件给出样本气相–离子迁移谱、挥发性有机化合物指纹图谱等,并以此直观显示各样本挥发性成分之间的差异.本文对6种小麦样品测试的仪器参数设置见表2.

表2 工作参数设置Table 2 Parameter settings for instrumental testing
4 结果和讨论
4.1 样品的气相–离子迁移谱
将5 g 样品置于20 ml 取样瓶中,在90◦C 下预热15 min,然后使用气相色谱–离子迁移谱仪Flavor-Spec®进行测试.测试时直接对样品进行顶空取样分析,无需复杂的样品预处理,20 min后获得样品的挥发性成分信息.使用制造商提供的LAV软件可以快速显示和查看样品的GC-IMS谱图,如图5所示.图5是6种小麦样品的GC-IMS的2D俯视图谱.在图5中,垂直坐标是气相的保留时间,水平坐标是离子的漂移时间.整个图的背景是蓝色,左边的红色垂直线是RIP(即反应离子峰,归一化后漂移时间约为7.9 ms).图中的每个点代表一种挥发性有机化合物,颜色表示其浓度,白色表示浓度较低,红色表示浓度较高,颜色越深,浓度越高.

图5 6种小麦样品的气相色谱–离子迁移谱Fig.5 Gas chromatographies-ion mobility spectra of the six type of wheat samples
4.2 人工定性分析
从图5可以看出,不同霉变程度的6种小麦样品挥发性成分存在显著差异.普通小麦的挥发性物质较少,而其他样品的挥发性物质较多.为了更直观地表达不同样品中挥发性物质的变化规律及相对含量,本文利用G.A.S开发的LAV软件的Gallery Plot插件,选择图5中所有需要分析的区域,自动生成样品的GC-IMS指纹图谱,如图6所示.

图6 6种小麦样品的挥发性有机物离子迁移指纹图Fig.6 Ion migration fingerprint of volatile organic compounds from six type of wheat samples
从图6可以看出,正常小麦(1号)中挥发性成分较少,主要为γ–丁内酯、丙醛、苯甲酸甲酯、乙酸、丙酸、2–乙基呋喃,绿框中的成分为霉变小麦产生的特殊挥发性物质.从图6还可以看出,陈化小麦不会增加过量挥发性物质,主要产生乙酸丙酯、糠醛、戊醛等.小麦在霉变和虫蚀过程中产生了大量的挥发性成分,如图6红、黄方框所示.在发霉过程中,一些挥发性物质的浓度先下降后增加.在发霉后期,还会产生一些特殊的挥发性物质,如黑框所示,主要有2–甲基丙醇、2–甲基丁醇、3–甲基丁醇等.利用G.A.S开发的动态主成分分析(principal component analysis,PCA)插件进行分析,如图7所示.PCA分析结果表明,不同的样本是可以区分的,而平行样本紧密聚集在一起,正常小麦和陈化小麦(3号)的挥发性成分相似,而早期霉变小麦和虫蚀小麦的区别非常明显.主成分分析只提供了样本之间的相似性,却无法区分样本的类型.

图7 主成分分析结果Fig.7 Analysis result of PCA
4.3 宽度学习实验设置
本文由于可获得的样本数量偏少,深度学习模型训练不充分,易导致模型识别的过拟合而泛化性差.为此,正如前文所述的,为了克服深度学习的这一不足,获得更佳的识别结果,本文研究开发了上述的基于宽度学习的方法.
为了验证本文提出的宽度学习网络模型的有效性,笔者首先构建了一个由不同性质小麦样品的GC-IMS谱组成的数据集.根据前面的描述,笔者测试了600个样本的GC-IMS指纹图谱,在每次测试中,笔者对每个样本进行2次平行测试,这样,总共得到了1200行GCIMS指纹图谱(如图6显示了其中的一次测试,每两行代表一个样本).为了进一步提高模型的训练水平,提升模型分类性能,根据文献[18]的方法(注: 该文献提出了一种使用生成式对抗网络(generative adversarial network,GAN)扩大GC-IMS数据集的方法),本文利用生成式对抗网络又生成1200个模拟GC-IMS指纹样本,因此,样本总数达到2400行.笔者使用其中的1860个样本作为训练集,剩余的720个样本作为测试集.在本文的BLN训练中,根据图像数据的大小(64×64),仿照文献[19]的方法,将BLN的参数设置为100×10特征节点和1000个增强节点.
实验环境如下: Intel Xeon E5 v3处理器,32 GB内存,NVIDIA GeForce RTX 2080 Ti 11 GB显卡.使用CUDA 10.0架构、Pytorch深度学习框架和Python3.6编程语言.
4.4 实验结果与分析
4.4.1 多种宽度学习模型性能对比分析
实验对比了普通的BLN网络模型[16]、融合局部感受野的宽度学习(broad learning based on local receptive field,BRL-LRF)网络模型[19]和特征节点映射级联的宽度学习(cascade of feature mapping nodes of broad learning,CFBRL)网络模型[19].评估指标采用了平均准确率(mean average precision,mAP)、训练时间和测试时间.对比结果如表3所示.从4种宽度学习网络的比较结果可以看出,BLN-SAM的平均准确率最高,训练和测试的总时间稍长于BRL-LRF网络,但比BLN,CFBRL 网络要短得多.BLN 网络模型的平均准确率与BRL-LRF 相似,但总训练和测试时间是BRL-LRF的两倍,CFBRL网络模型的平均准确率介于BLN-SAM和BRL-LRF之间,在训练和测试时间上长于BLN-SAM.

表3 GC-IMS测试集分类准确率比较Table 3 Comparison of classification accuracy of wheat GC-IMS test set
BLN-SAM算法不仅对上述非增量学习算法有效,而且对增量学习算法(incremental learning algorithm,ILA)更有效.为了证明BLN-SAM网络在增量学习中的有效性,将BLN-SAM的增量学习算法与BLN的增量学习算法以及BRL-LRF的增量学习算法进行比较.接下来,本文只讨论动态添加增强节点的情况.首先,将BLN的初始结构设置为100×10特征节点和1000个增强节点.更新增强节点6次,每次增加500个增强节点.结果如表4所示.

表4 BLN增量学习算法的结果Table 4 Results of the ILA of BLN
将BRL-LRF的初始结构设置为4×4感知域、特征映射和池大小为3,10×10特征节点和100个增强节点,类似地,增强节点更新6次,但每次增加500个增强节点,如表5所示.CFBRL与本文BLN-SAM的初始结构和增强节点添加方式与BLN相同,结果如表6–7所示.

表5 BRL-LRF增量学习算法的结果Table 5 Results of the ILA of BRL-LRF
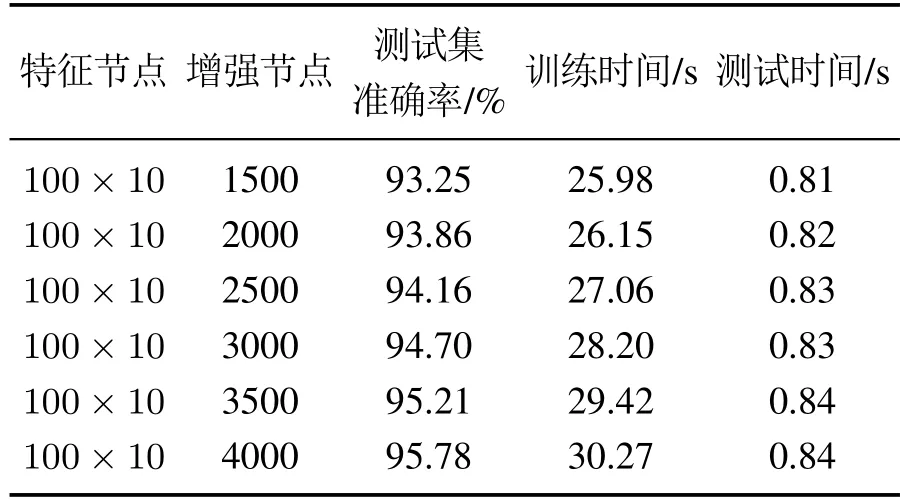
表6 CFBRL增量学习算法的结果Table 6 Results of the ILA of CFBRL
对比表4–6和表7可知,BLN-SAM每次动态更新的准确率高于BLN和BRL-LRF,且每次动态更新所需的时间与BRL-LRF相当,但比BLN短2倍左右.可以看出与BLN、CFBRL和BRL-LRF相比,BLN-SAM对增量学习算法具有更好的增效作用.

表7 BLN-SAM增量学习算法的结果Table 7 Results of the ILA of BLN-SAM
4.4.2 本文模型与深度学习模型性能对比分析
为了更好地证明BLN-SAM的有效性,本文将该网络模型与当前的一些主流算法进行比较.这些方法包括深度置信网络(deep belief networks,DBN)、深度波尔兹曼机(deep Boltzmann machine,DBM)、多层感知(multilayer perception,MLP)[20]算法多结构极限学习机(multi-layer extreme learning machine,MLELM)[21]和多感知极限学习机(multi-perception extreme learning machine,HELM)[22].利用MATLAB2016a 在上述平台下对以上的小麦样品GC-IMS指纹图谱集进行了分类识别,实验结果如表8所示.在测试集的识别准确率方面,虽然提出的方法的准确率(94.28%)不是最高的,但仅次于HELM的95.12%.但在训练时间上,本文方法的训练时间为16.11 s,是所有算法中最短的.但如果对BLN-SAM施加增量学习,则识别准确率则会超过HELM,见表7.对比结果充分表明本文方法识别准确率优于当前的一些主流算法.

表8 BLN-SAM 与各种深度学习算法分类结果比较Table 8 Comparison of classification results between BLN-SAM and various Deep Learnings
4.4.3 小麦早期霉变鉴别实验
小麦早期霉变鉴别就是将早期霉变小麦与普通小麦区分开小麦霉变早期因其外观无明显变化和异物,往往难以人工鉴别.从机器学习角度看,小麦早期霉变鉴别本质上是一个二分类问题.将有早期霉变的小麦定义为阳性,将正常小麦定义为阴性,并使用以下指标来衡量BLN-SAM模型的识别性能:
其中: TP和FP分别代表正确识别和错误识别的真阳性样本数量,TN和FN分别代表正确识别和错误识别的真阴性样本数量.由公式可知:P(Precision)为预测的准确率,表示预测阳性样本中有多少个真实阳性样本;R(Recall)是召回率,表示样本中有多少个正样本被正确预测;F1是基于Precision和Recall的调和平均值.显然,F1值越大,识别效果越好.
以河南工业大学粮食信息处理与控制教育部重点实验室储存的小麦为检测对象.取200个正常样品,放入恒温恒湿培养箱中进行霉菌初期培养.将培养箱设为恒温33◦C,恒湿80%RH.3天后取出样本,选取50个不易识别为霉变的样本组成一个数据集,选取50个正常小麦样本组成另一个数据集.将两个数据集随机分为一个训练数据集和一个测试数据集,分别包含70个训练样本和30个测试样本,每个数据集的阳性样本和阴性样本数量相同以消除样本不平衡带来的影响.利用该训练集对BLN-SAM模型进行迁移训练,然后利用参数微调后的BLN-SAM模型在训练集和测试集中进行分类预测.选取电子鼻、当前流行的深度学习模型Faster-RCNN(faster-regions with convolutional neural network features)[23]、单发多盒检测器(single shot multiBox detector,SSD)[24]和YOLOv3(you only live once-v3)[25]作为比较,检验模型的识别性能.比较的深度学习模型采用在ImageNet预训练好的模型经训练集迁移学习后得到.各模型预测结果如表9所示.

表9 BLN-SAM与流行的深度学习方法在小麦早期霉变预测上的比较结果Table 9 Comparative results of BLN-SAM and popular deep learning methods in predicting early mildew for wheat
由表9可以看出,BLN-SAM在3个指标上的结果最好,其次是Faster-RCNN和SSD,Electronic Nose的准确性和F1值最低.BLN-SAM的F1值达到0.933,比目前最好的YOLOv3网络的F1值提高了6.6%.此外,由于BLN-SAM极大地简化了网络模型的构建和训练过程,因而大大减少了整个训练和预测过程的时间,其空间注意力机制的引入还进一步提高了模型的预测性能.实践表明,利用本文提出的宽度学习模型,小麦早期霉变的检测效率比人工方法约提高了50%∼70%.
为了进一步验证本文的BLN-SAM模型对于早期霉变小麦的分类性能,笔者绘制了BLN-SAM和以上几种深度学习方法的受试者工作特征曲线(receiver operating characteristic curve,ROC),并计算其曲线下面积(area under curve,AUC)值,如图8所示.

图8 ROC曲线图Fig.8 ROC curves
本文根据模型的预测结果对样例进行排序,按此顺序逐个把样本作为阳性进行预测,每次计算出两个最重要的值,分别以它们为横、纵坐标作图,就得到了“ROC曲线”.其纵、横坐标分别为“真阳性率”(TPR)和“假阳性率”(FPR),定义如下:
图8中,对角线对应于随机猜测模型,由于测试样例有限,所以曲线呈锯齿状.如图8所示,本文模型的ROC曲线几乎完全包住了其它模型的ROC曲线,说明本文模型的分类性能优于其它模型.AUC定义为ROC曲线下的面积,AUC 越大则说明模型分类性能越好,各模型AUC值如表10所示.

表10 本文模型与对应模型的AUC值Table 10 AUC values of this model and corresponding models
由表10可见,BLN-SAM具有最大的AUC值,表明其分类性能在比较的几种模型中是最好的.同时AUC值的计算结果也表明各模型的分类性能与表9表示的一致.本文中,BLN-SAM之所以成为最佳的小麦早期霉变检测模型,在于在小样本条件下,由于采用了宽度学习的网络结构,模型的泛化性能相比深度学习有了很大的提高.
4.4.4 本文模型在公开案例上的性能表现
为了进一步评估算法的泛化性能,本文采用了德国G.A.S公司的一个公开的案例[26],对文献中使用的识别GC-IMS图像的方法进行了性能对比.由于目前还缺少关于小麦的GC-IMS的公开数据集,本文选择了G.A.S公司公开的泰国香米和五常大米GC-IMS数据集,以此对不同的方法区分这两种大米的能力进行对比,结果如表11所示.

表11 不同方法区分两种大米的能力比较Table 11 Comparison of the ability of different methods to distinguish two kinds of rice
由表11可见,由于这两种稻米所含有的挥发性物质比较相近,文献[27–29]的方法识别准确率都较低,且远低于文献[30]的方法和本文的方法.虽然文献[30]的方法识别准确率略高于本文方法,但其模型训练时间却远长于本文方法,处理速度远慢于本文方法.综合来看,本文算法整体性能优于现有文献中识别粮食的GC-IMS图像的方法.
5 结论
本文提出了一种气相色谱–离子迁移谱结合宽度学习的贮藏小麦霉变检测识别方法.由于不同霉变程度的小麦样品具有不同的挥发性有机物,但部分挥发性物质具有相同或相似的结构,使样品的气相色谱–离子迁移谱具有很大的相似性,给人工鉴别带来了困难.本文提出的基于空间注意力机制的宽度学习方法对小麦样品中的挥发性有机物进行定性鉴别,克服了深度学习模型需要大量样本训练的缺陷,同时,提高了训练速度和识别性能.实验证明,在样本较少的情况下,小麦早期霉变的检测效率提高了50∼70%,同时,识别的平均准确率(mAP)也得到了相应提高.因此,本文提出的小麦霉变检测方法,为贮藏小麦霉变早期识别预警提供了一种新的有效手段.同时,也为其他种类粮食、农作物的早期霉变检测和预警,提供了一种新的智能分析途径.
