一种基于AHP 的无线传感器网络分簇路由算法*
2023-10-26路芳瑞赵冬琴
王 珊,梁 敏,路芳瑞,赵冬琴
(1.山西财经大学实验中心,太原 030006;2.山西财经大学信息学院,太原 030006)
0 引言
无线传感器网络(wireless sensor networks,WSN)广泛应用于军事安全、空间探测、环境监测、智能家居、医疗健康、交通管理等众多领域[1]。但是无线传感器节点一般难以蓄电,有限的能量限制了WSN的生命周期,因此,如何设计节能算法以降低传感器节点能量消耗成为研究的热点问题。分簇路由算法[2]相比平面路由协议,能有效降低能量消耗,因此,对WSN 分簇路由算法的研究具有很好的研究意义和实用价值。
国内外众多专家学者对WSN 分簇路由算法展开了深入研究。HEINZELMAN 等提出了LEACH 算法,该算法执行过程是循环的“轮”,在每一轮中随机初始化簇头,但是簇头选举未考虑节点位置信息[3]。MANJESHWAR 等提出了TEEN 算法,该算法基于阈值,当有特定事件发生时,才发送数据给基站,从而降低能量消耗[4]。LI 等提出了EEUC 算法,簇大小与基站距离成比例,但簇头选举采取竞争机制增加了能耗[5]。SERT 等提出了MOFCA 算法,该算法基于模糊逻辑,改进了簇头选举机制及竞争半径[6]。NEAMATOLLAHI 等提出了一种基于遗传算法的分簇算法,适应度函数考虑节点与簇头节点的总距离以均衡簇头负载[7]。任昌鸿等提出了一种改进粒子群算法,结合分布式空间技术实现均衡分簇[8]。方旺盛等提出了一种改进K-means 分簇算法,以改进分簇效果[9]。可以看出,以上算法有的侧重优化分簇效果,有的侧重优化簇头选举策略,但两者皆考虑的很少。
因此,本文提出了一种基于AHP 的改进K 均值分簇算法(K-means clustering algorithm based on AHP,AHPK),主要思想是改进K-means 聚类,改善分簇效果,同时使用AHP 模型计算簇头选举影响因素权重,改善簇头质量,提升网络生命周期。
1 相关模型
1.1 网络模型
本文对WSN 的网络模型作如下假设:
1)所有传感器节点符合随机分布,地理位置固定不变,有唯一的标识号,节点集表示为V={v1,v2,…,vn};2)基站能量无限且不可移动,能获取每个节点的位置信息vi(xi,yi);3)所有传感器节点同构,能量有限,具有数据融合功能,可相互通信,也可与基站直接通信;4)节点之间的距离可通过接受信号强度指示(received signal strength indication,RSSI)计算得到[10]。
1.2 能耗模型
采用的无线电通信能量模型与文献[11]相同。
1)节点发送数据能耗:节点发送l bit 数据到距离d 位置所消耗的能量为:
式中,Eelec指发送单位比特数据所消耗的能量;εfs和εmp分别指自由空间和多径衰减信道模型功率放大器能量参数;d0指阈值距离,其计算公式为:
2)节点接收数据能耗:节点接收l bit 数据所消耗的能量为:
3)节点融合数据能耗:节点融合l bit 数据所消耗的能量为:
2 AHPK 分簇路由算法
2.1 分簇阶段
通过改进K-means 聚类[12]对节点进行分簇,簇一旦形成不再改变。
2.1.1 确定K 值
本算法K 值依据文献[13]确定,其计算公式为:
其中,N 指网络内节点总数量;L 指区域边长;dtoBS指基站至所有节点的平均距离。可以看出,网络中节点个数越多,区域边长越长,基站距节点的平均距离越短,簇的个数就越多。
2.1.2 优化初始中心点选取
K-means 聚类算法初始中心点是随机选取的,若初始中心点位置比较集中,聚类结果就会比较聚集,导致分簇结果不理想。因此,本算法对初始中心点的选取进行改进,通过计算网络中节点间的最大距离选取K 个中心点,以优化分簇效果。具体选取过程如下:
1)计算网络中距离最大的两个节点,将这两个节点加入初始聚类中心点集C 中,此时C 中节点数目|C|=2;2)若|C|<K,跳转至步骤3);若|C|=K,选取完毕,跳转至步骤4);3)计算C 以外其余节点到C内每个节点的距离之和,选出距离和最大的一个节点加入C,|C|=|C|+1,转至步骤2);4)K-means 聚类。
2.2 簇头选举阶段
AHP 模型是将复杂的问题层次化和量化,对多个影响因素的重要程度进行两两比较建立判断矩阵,计算其最大特征值及对应特征向量,得出不同因素重要性程度权重,为决策者提供依据[14]。WSN 中簇头选举受节点能量、位置、邻居节点密度等多种因素影响,每种因素的权重难以直接确定,因此,引入AHP 模型计算各影响因素权重不失为一个很好的方法。
2.2.1 构建层次结构模型
根据影响簇头选举的因素,本算法建立簇头选举AHP 模型如下页图1 所示。

图1 AHPK 簇头选举层次化模型Fig.1 AHPK cluster head election hierarchical model
第1 层为目标层,计算簇内所有活动节点的综合权值,选取本轮最优簇头;
第2 层为准则层,由影响簇头选举的各因素组成,本文算法选取3 个准则:节点剩余能量度、节点质心度、节点密度。
1)节点剩余能量度:网络运行过程中,簇头节点能量消耗最大,应考虑剩余能量较多的节点。节点剩余能量度E(i)定义如下:
式中,Eres(i)指节点i 的剩余能量;Eave指当前簇内所有节点的平均剩余能量。
2)节点质心度:簇头节点应选取距离簇内质心点位置较近的节点,使得簇内大多数节点至簇头节点的距离较小,以节省传输能耗。节点质心度C(i)定义如下:
式中,di指节点i 至簇内质心点的距离;davg指簇内所有节点至质心点的平均距离。
3)节点密度:节点的邻居数量越多,表明该节点位于簇内节点比较密集的区域中,这样可以避免噪声节点的干扰。节点密度U(i)定义如下:
式中,ni指节点i 的邻居节点数量;n'为当前簇内活动节点数。
第3 层为方案层,由簇内所有活动节点组成。
2.2.2 构造比较判断矩阵
AHP 模型是将两两准则的重要程度比建立判断矩阵,对3 个准则构建比较判断矩阵A 如下:
根据文献[15]表2.1 对A 进行赋值。计算A 的最大特征根max及其对应特征向量W=[w1w2w3]T,随后根据文献[14]中一致性检验方法对A 是否存在逻辑错误进行检验。一致性检验通过后,对W 进行归一化得到W'=[w1' w2' w3']T即为各准则权重,此时节点i 综合权值函数如下:
可见节点的综合权值越大,代表该节点拥有较高的剩余能量,距离质心节点越近、节点的密度越大。因此,节点综合权值最大者当选为本轮簇头。
2.3 AHPK 算法描述
图2 为本文AHPK 算法的流程图,首先计算出初始中心点的位置,使用K-means 聚类将网络中节点划分为K 个簇;然后利用AHP 模型计算影响簇头选举的各因素权重,此后开始每轮工作,每轮工作涉及簇头选举和数据传输两步,簇头选举使用AHP 模型确定各准则权重,利用式(10)计算簇内活动节点综合权值,最大者选为本轮簇头节点,随后普通节点将采集到的数据以单跳方式发送至簇头节点,簇头节点进行数据融合后,传输数据至基站,一轮工作结束。若网络中还有存活节点,则开始下一轮工作。
3 仿真与分析
使用matlab2014a 进行仿真实验。为验证AHPK算法的性能,从分簇结构、生存节点数量、网络能耗3 个方面与LEACH 算法、K-means 算法进行对比。
1)仿真参数设置如表1 所示。

表1 仿真参数设置Table 1 Simulation parameter settings
2)根据文献[15]赋值规则,采用经验法对判断矩阵A 赋值如下:
3.1 分簇结构分析
为更好地验证本文AHPK 算法的分簇性能,将其与LEACH 算法分簇结果和K-means 算法分簇结果进行对比,实验结果如图3 所示。

图3 分簇结构Fig.3 Clustering structure
其中,图3(a)~(d)分别为随机选取的4 组LEACH算法在不同轮次中的分簇结构,可以看出LEACH算法分簇随机性强,数量不固定,这是因为LEACH协议依赖概率模型成簇,因此,簇大小差异较大,分簇效果较差,从而容易造成网络能耗不均衡。图3(e)为K-means 算法分簇结构,5 个簇节点个数分别为21、14、28、24、13,可以看出簇大小相差较大,且有的簇质心位置比较接近,这是由于初始中心点是随机选取造成的。图3(f)为本文AHPK 算法分簇结构,5 个簇内节点个数分别为17、22、20、17、24,簇大小相差不大,簇质心点位置均匀分布在整个网络中,说明通过改进K-means 算法固定初始中心点位置能有效改善分簇效果,从而形成较好的分簇结构。
3.2 生存节点分析
网络中的生存节点个数直观地反映网络生命周期的长短,因此,将本文AHPK 算法与LEACH 算法、K-means 算法从生存节点数量进行比较,实验结果如图4 所示。图4 中,横坐标代表运行轮数,纵坐标代表每轮次相应的存活节点个数,可以看出LEACH 算法、K-means 算法第1 个死亡节点分别是在500 轮和700 轮左右,而AHPK 算法第1 个死亡节点在第850 轮左右,第1 个死亡节点相较于前两种算法延迟上百轮,效率分别提高了近70%和21%,且AHPK 算法在运行至1 000 轮左右的时候存活节点数量高达70%左右,说明使用层次分析法有效设置了剩余能量度、质心度和密度三者的权重关系,从而均衡了网络能耗,延长了簇头节点生存时间。同时LEACH 算法、K-means 算法节点全部死亡分别在1 000 轮和1 150 轮左右,而AHPK 算法节点全部死亡在1 250 轮左右,可以看出,AHPK 算法有效延长了整个网络的生命周期。

图4 生存节点数量对比图Fig.4 Comparison chart of the number of surviving nodes
3.3 网络能耗分析
网络能耗是衡量算法性能的重要指标,本文从每轮能量消耗和网络剩余总能量两方面对3 种算法进行比较,实验结果如图5 和图6 所示。

图5 每轮能量消耗对比图Fig.5 Comparison chart of energy consumption per round
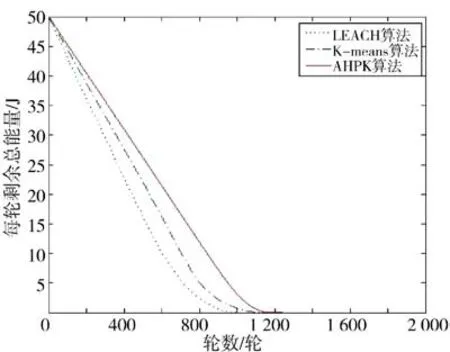
图6 每轮网络剩余能量对比图Fig.6 Comparison chart of remaining energy of each round of network
图5 为每轮能量消耗对比图,横坐标代表运行轮次,纵坐标代表每轮所有节点消耗的总能量,可以看出LEACH 算法和K-means 算法在多个轮次出现能量消耗骤增现象,而AHPK 算法每轮消耗能量较稳定,这是由于LEACH 算法和K-means 算法在簇头选举时只考虑节点的剩余能量造成的;而AHPK 算法在簇头选举时应用层次分析法综合考虑节点剩余能量、位置和密度因素,因此,各轮能量消耗相对均衡。图6 为网络剩余总能量对比图,横坐标代表运行轮次,纵坐标代表每轮所有节点剩余总能量,初始总能量为50 J。如图6 所示LEACH 算法和K-means 算法在360 轮和450 轮左右消耗了网络近一半能量,而AHPK 算法在520 轮左右出现,分别推迟了44.4%和15.6%;同时在算法运行到850 轮时,LEACH 算法剩余总能量不足1.5 J,K-means 算法还剩3.5 J 左右,而AHPK 算法所剩总能量高达10 J 左右,综上可见AHPK 算法通过改进分簇结构,引入层次分析法选举簇头能很好的降低网络能耗,有效延长网络生命周期。
4 结论
本文提出的AHPK 算法通过计算节点间最大距离改进K-means 初始中心点选取,以改善网络成簇效果;之后在每轮运行过程中,引入层次分析法计算节点权重,改进簇头选举机制,以改善簇头选取质量,降低网络能耗。通过仿真实验对比,本文算法相较于LEACH 算法和K-means 算法,分簇效果更好,簇大小更均匀,每轮能量消耗更稳定,网络生命周期有较明显提升。因此,本文算法是一种性能较好的算法。
