基于上下文信息的遥感图像目标检测
2023-10-25梁礼明李仁杰朱晨锟
梁礼明, 李仁杰, 董 信, 朱晨锟
(江西理工大学电气工程与自动化学院,江西 赣州 341000)
0 引言
遥感图像目标检测旨在定位和识别感兴趣的目标,是智能解译的关键技术。作为视觉目标检测的重要分支,其在自然灾害检测、军事侦察和城市规划等领域均有着广泛的用途[1]。近年来,随着深度学习和卷积神经网络的快速发展,很多先进的基于深度学习的遥感图像目标检测算法不断涌现[2-3]。例如,文献[4]提出一种基于改进特征金字塔及生成对抗网络的端到端检测算法,该算法将传统的CNN网络替换为特征金字塔网络,并将ResNet50的基础层特征映射划分为两部分,提高小目标识别能力的同时还平衡了检测速度;文献[5]提出一种轻量级目标检测算法,该算法以YOLOv5s 算法为网络基础框架,引入加权融合特征网络,为每层特征图赋予可在训练中不断学习的权重系数,加强深浅层特征融合,将GIoU损失函数替换为 CIoU损失函数,加快网络收敛速度;文献[6]针对特征金字塔逐层传递特征可能产生特征丢失和对现有的注意力容易强化不准确的预测结果的问题,设计了跳跃连接特征金字塔和基于锚框的位置注意力模块,增强其目标的特征提取能力;文献[7]针对高分辨率光学图像中的近海集装箱容易受到结构、阴影、环境等严重干扰,从而导致船体与附近陆地上的集装箱结构非常相似的问题,构建了一种基于Superpixel-Level上下文特征的近海集装箱检测模型,能够通过机器学习对目标和背景超像素进行分类且对分类结果进行细化,实现精确检测;文献[8]针对局部线性模式(LLP)在遥感图像检测中维度较高和相邻像素间联系的问题,构造一种线性逻辑矢量模式特征,能够缩短模型训练时长且提高检测的精度;文献[9]针对感兴趣区域变形器(RoI Trans)在检测排列密集和方向性显著的遥感图像时检测性能较差且推理速度慢等问题,提出一种逐步增强旋转候选框的定位精度和非局部特征增强模块,以提高模型的推理速度和检测性能。虽然这些涌现的检测算法都目标性地解决了一些遥感图像目标检测中所存在的问题,但遥感图像小目标容易出现误检和漏检的情况仍然是当前所面临的难题。
目前主流的目标检测算法中一阶段的有SSD[10]和YOLO[11]系列等,两阶段的有R-CNN[12],Fast R-CNN[13]和Faster R-CNN[14]等。为了提升遥感图像目标检测算法的检测性能,同时考虑遥感图像的检测速度,本文选用YOLOv5s 模型为网络基础框架,提出一种基于上下文信息的目标检测算法降低遥感图像目标检测中小目标的误检率和漏检率,该算法利用上下文模块(CM)丰富网络中的语义信息,之后通过添加坐标注意力(CA)模块[15]提升模型对小目标的检测能力,最后采用空洞空间卷积金字塔(ASPP)模块[16]获取多尺度的物体信息。
1 YOLOv5s目标检测算法
YOLOv5s 模型由Ultralytics公司于2020年6月公开发布,由输入端、特征提取网络、Neck网络和Head检测层4部分组成。
1) 输入端:主要包括Mosaic数据增强、丰富数据集、提升目标检测能力。自适应锚框计算,计算出最佳的锚框值;自适应图片缩放,提升模型推理速度。
2) 特征提取网络:主要由 Focus,BottleneckCSP和SPP网络[17]构成。输入大小为640×640×3的图片,通过Focus模块进行切片后,得到大小为 320×320×32的输出图片。SPP模块对图像分别进行 5×5,9×9和13×13最大池化操作,从多方面提取特征,通过Concat将3组池化后的特征图聚合起来。
3) Neck网络:使用特征金字塔网络(FPN)[18]和金字塔注意力网络(PAN)[19]结构。FPN通过自上而下的上采样传递和融合高层特征信息来传达强大的语义特征。PAN是一个自下而上的特征金字塔传达强大的定位功能。两个都能同时增强网络特征的融合能力。
4) Head检测层:使用CIoU_Loss[20]当作损失函数,然后通过NMS非极大值抑制后处理。
YOLOv5s网络结构如图1所示。
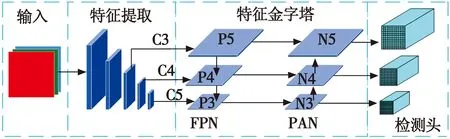
图1 YOLOv5s网络结构
2 改进的YOLOv5目标检测算法
2.1 上下文模块(CM)
为了使网络获得更多的目标特征信息,缓解检测目标由背景复杂且密集带来的特征提取不足问题,本文在原上下文模块(见图2)的基础上设计了新上下文模块,实现对含有不同尺度信息的特征图融合以提高网络对特征的感知范围。最原始的上下文模块(见图2(a))的输入特征图分别经过一个卷积核大小为5×5和7×7的卷积后得到两个包含不同尺度信息的输出特征图,再通过Concat操作实现特征图的融合。之后为了减少计算量,借鉴GoogleNet中用多个3×3卷积层代替5×5和7×7卷积层的做法得到了图2(b)所示的上下文模块。
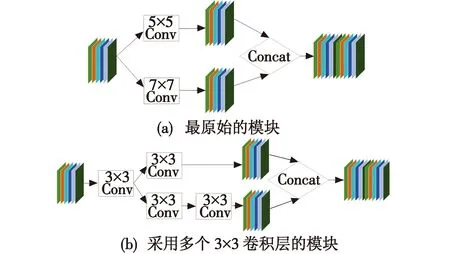
图2 原上下文模块
新上下文模块如图3所示,在上述改变的基础上继续添加一个3×3卷积层通道和对原输入特征图进行拼接的操作,同时将所有的3×3普通卷积全部替换为膨胀率为2的空洞卷积,最后添加一个1×1的卷积。新上下文模块的输入特征图分别通过不同数量的卷积核为3×3的空洞卷积后,得到含有不同尺度感受野信息的特征图,然后将这些特征图与输入特征图进行拼接操作融合,得到包含多尺度信息的特征图,最后经过1×1卷积调整通道数得到最终的输出特征图。相比以前的上下文模块,新上下文模块的输出特征图包含了多尺度信息,且拥有更大的感受野,能够提高网络对重要特征的识别能力。

图3 新上下文模块
2.2 坐标注意力模块
坐标注意力(CA)模块将特征图的位置信息嵌入到通道注意力,其结构如图4所示,输入图像信息后,在水平和垂直方向分别进行平均池化得到两个不同方向的特征图。将特征图拼接后通过BN(BatchNorm)层和非线性模块进行编码后得到水平方向和垂直方向的空间信息,再将两个方向的空间信息分别进行卷积和激活函数的处理,最后将这两个方向的输出结果进行融合。这样就可以考虑到目标通道间的关系和空间方向与位置的敏感信息,从而提升模型对目标的检测精度,降低目标的误检率和漏检率。本文将CA模块和网络结构中的C3模块结合得到C3CA模块,有选择性地添加到主干网络,替换原C3模块。
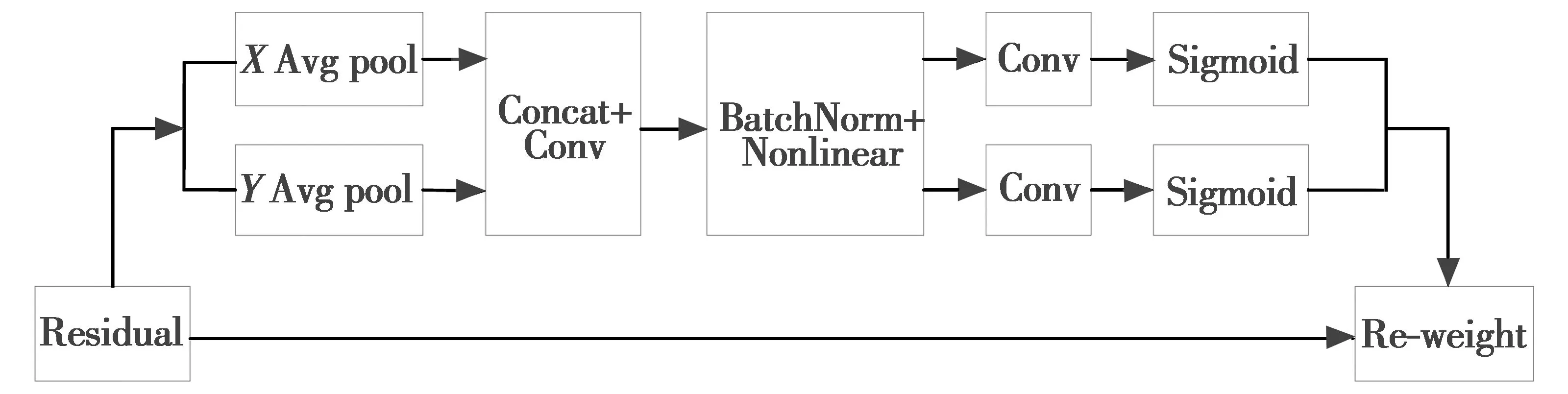
图4 CA模块
2.3 空洞空间卷积金字塔模块
遥感图像中目标尺度差异性大且小目标占比高,感受野的大小会影响目标特征的提取,感受野太小会使网络只能关注局部信息从而忽略全局信息对目标的影响,增大感受野能使网络获取更多的上下文信息,提升检测性能。本文将空间金字塔池化模块替换为空洞空间卷积金字塔(ASPP)模块增大感受野,获取包含多尺度特征的信息。空洞空间卷积金字塔模块如图5所示。

图5 空洞空间卷积金字塔模块
ASPP模块主要由普通卷积、多个不同空洞率的空洞卷积和全局平均池化以并联的方式组成。输入特征图经过普通1×1卷积保持特征图尺度不变的同时可以大幅增加非线性特性;通过3个不同空洞率的3×3空洞卷积对不同尺度的信息进行采样获得多尺度特征信息;经过全局平均池化得到全局信息。再通过Concat操作将得到的包含多尺度特征信息和全局信息的特征图进行融合,得到新的特征图后通过1×1卷积调整通道数从而输出最终包含多种信息的特征图。
2.4 改进后的YOLOv5s网络
综上所述,改进后的YOLOv5s网络结构如图6所示,遥感图像从输入端送进网络后经主干网络提取特征获取上下文信息,随后将不同尺度特征信息传递到颈部网络进行特征的处理和融合,最后将处理后的特征信息输入到头部网络进行检测。

图6 改进后的YOLOv5s网络
3 实验
3.1 实验环境及参数设置
本文实验的配置如下:CPU采用AMD Ryzen 7 5800H,GPU采用的是显存为6 GiB的NVIDIA GeForce RTX 3060,Python的版本为3.9.7,开发工具是Pycharm。训练参数配置如表1所示。

表1 参数配置
3.2 实验数据集
本文算法采用的是武汉大学标注的RSOD数据集[21],包含飞机、油罐、操场和立交桥这4种类型。其中有446张飞机照片包含4993架飞机样本,189张操场照片包含191个操场样本,176张立交桥照片包含180座立交桥样本,165张油箱照片包含1586个油箱样本。图像中背景复杂多样,且存在阴影、畸变、遮挡等干扰。本文实验将数据集按照8∶2分为训练集和验证集。
3.3 实验评价指标
本文以准确率P、召回率R、平均准确率(AP)PAP、平均准确率均值(mAP)PmAP和FPS(每秒能处理的图片帧数)作为实验结果的评价指标。准确率与召回率分别为
(1)
(2)
其中:TP为正确样本数据被正确识别出的目标数量,即被正确识别的遥感图像目标;FP为将非正样本数据识别为正样本目标数量,即误检的遥感图像目标;FN为正样本数据没有被正确识别的目标数量,即漏检的遥感图像目标。
平均准确率PAP和平均准确率均值PmAP用来评价网络模型性能的优劣,其根据模型的准确率和召回率计算得出,算式如下
(3)
(4)
3.4 实验结果与分析
为了客观地评价改进算法的检测性能,在相同的条件下,对比SSD,YOLOv3和YOLOv5s等经典检测算法。算法对比实验数据结果如表2所示。本文算法在模型大小上相比SSD算法和YOLOv3算法的降幅分别为62.3%和70.4%,虽然相比原YOLOv5s算法提高了54.9%,达到36.4 MiB,但对嵌入硬件设备的影响不大;在FPS上相比SSD算法和YOLOv3算法分别提高了30帧、42帧,虽然相比原YOLOv5算法减少了17帧,达到71帧,但仍远大于实时检测所要求的25帧;在mAP50上相比SSD算法、YOLOv3算法和YOLOv5s算法分别提高了8.3,1.4和1.7个百分点,达到97.9%的平均检测精度。

表2 算法对比
同时,为了直观地展现出改进模型的检测性能,从验证集中选出3张具有不同背景的图片与上述经典检测模型做横向对比。经过实验发现,这些模型在操场、油罐和立交桥上的检测效果差不多,所以,选择的3张图片均是以飞机为检测目标的。检测结果对比如图7所示,图7(a)中第1张图片是光线明亮且飞机尺度均匀分布的情况;第2张图片是能见度较低、飞机尺度较小的情况;第3张图片是具有复杂背景、飞机尺度小且分布密集的情况。

图7 检测结果对比
从对比的结果来看,对于图7(a)中的第1张图片,SSD算法出现了较多的漏检以及重叠框的情况;YOLOv3算法则只有重叠框的情况;YOLOv5s算法出现了一次误检的情况;改进算法则精准完美地全部检测出来。对于图7(a)中的第2张、第3张图片,由于遥感图像中飞机的目标小且密集,所以所有算法均不能全部正确检测出目标,其中,SSD算法的检测表现是最差的,对大量的小目标漏检;其他的算法均出现了不同程度的检测框重叠、漏检和误检的情况,但改进算法相比其他3种算法出现误检和漏检的情况是最少的。
以上选出来的3张图片是在较特殊的场景下检测的,在实际生活中,遥感图像目标并不只存在特殊的场景,生活中普通的场景同样是遥感图像检测的主要用地。为了更好地展示改进算法对普通场景的检测效果,从数据集中包含的每个目标种类中都选出2张典型场景图片,共计8张图片,对改进后的算法进行检测实验,如图8所示。从图8的检测结果可知,改进后的算法对于普通情况下的检测效果非常好,每张图片中的检测目标都被精准地检测出来,没有出现误检和漏检的情况。由此可知,改进后的算法不仅适用于特殊的场景情况,对生活中的典型场景也具有非常好的检测效果。

图8 普通情况下的检测结果
3.5 消融实验
本文模型在原YOLOv5s上加入了坐标注意力(CA)模块、上下文模块(CM)和空洞空间卷积金字塔(ASPP)模块,为了验证加入的不同模块对模型检测性能的影响,设计了表3所示的消融实验,其中,“×”和“√”分别表示未添加和添加了该模块。
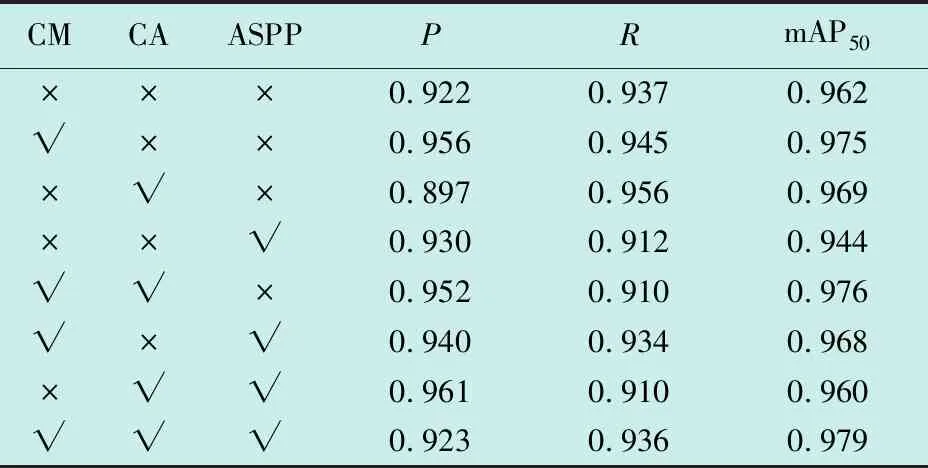
表3 消融实验结果
从表3中可以看出,随着在网络中依次加入各个模块,网络性能会有所提升或者降低,其中,单独加入上下文模块对网络性能的提升贡献最大,使mAP50提高了1.3个百分点;随后,在此基础上加入坐标注意力模块提升模型对目标位置信息的获取能力,mAP50由97.5%提升到97.6%,提高了算法的检测性能;最后加入ASPP模块获取多尺度的目标特征信息,增大感受野,mAP50再次提高了0.3个百分点,达到97.9%,进一步提升了网络的检测性能。说明加入的各个模块都能提升模型的检测性能,证明了加入模块的有效性。
4 结论
为了解决遥感图像中小目标的漏检和误检问题,进一步提升模型的检测能力,本文提出了一种基于上下文信息的YOLOv5s模型,该模型在主干网络最后一层加入上下文模块获取上下文信息,在浅层网络中加入坐标注意力模块,得到对方向感知和位置信息敏感的特征图提升对小目标的检测能力;采用空洞空间卷积金字塔模块替换空间金字塔池化模块,提升模型多尺度特征的提取能力。通过以上改进,模型的平均精度达到97.9%,FPS达到71帧/s,但是模型的大小增加了20 MiB,所以今后将通过引入轻量化主干网络降低模型的体积,方便嵌入硬件设备。
