基于机器学习的网站漏洞预警研究
——以代购系统为例
2023-10-24邓明体
邓明体
(广西水利电力职业技术学院,广西 南宁 530023)
0 引言
当前,各家代购公司模式竞争众多,竞争激烈,比如专注于海外直邮的公司、代购公司、代售公司等,在市场竞争中人们非常关注品牌的影响力及安全问题。对于代购系统来说,对于未来的发展,除了完善物流服务,畅通的物流链使客户能及时收到货物,提高了消费者的整体体验,还要有技术创新,持续提升技术,建立健全的移动终端等网络代购系统,使购物者可以直接通过手机或电脑进行海外代购,免去了传统繁琐的流程,而保证代购系统的健康安全运行是上述条件的基础。由于代购系统存在漏洞,让不法分子有机乘,可修改程序,破坏系统运行,严重可给公司的运行带来了灾难的打击[1]。因此,及时的修补代购系统的安全漏洞是安全管理员的重要工作之一。漏洞预警是代购系统建设中的重要的一个步骤,越是及时收到漏洞预警信息越能够及时进行响应。比如当阿里云漏洞库更新了一条漏洞预警信息(图1),安全管理员想第一时间收到通知,实现漏洞监控预警具有显著的现实意义。

图1 阿里云漏洞库
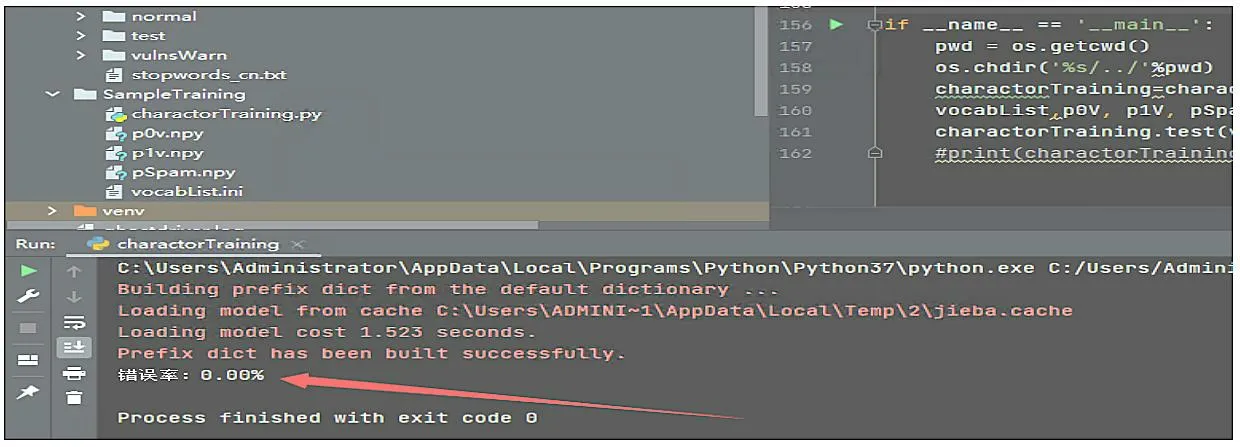
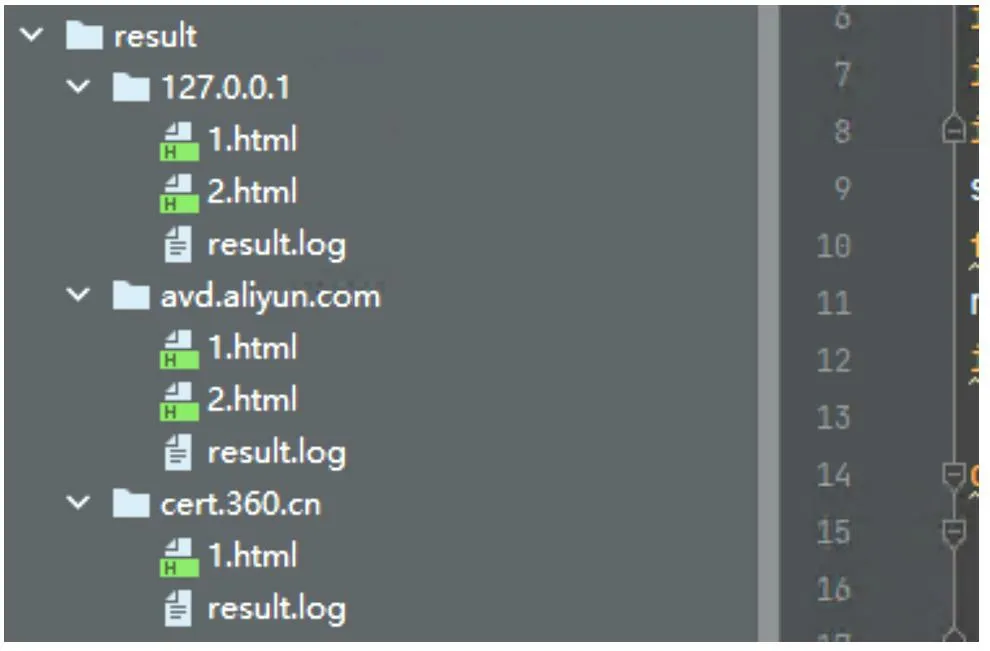
安全管理员传统的做法是设置python 定时爬虫,提取包含漏洞信息的对应 把监控页面变更前后的所有文本变化信息提取出来,再使用基于机器学习识别变更内容是否是漏洞预警信息,在这里方案中使用的机器学习算法是朴素贝叶斯[2]。分类是数据分析和机器学习领域的一个基本问题,现实生活中朴素贝叶斯算法应用广泛,如文本分类、垃圾邮件的分类、钓鱼网站分类等。例如想知道哦一个人的年收入是否达到中产阶级水平,可以收集样本人群的信息,根据年龄、工作单位的性质,学历、受教育时长、职业、家庭情况、性别、资产所得等信息来评估,这样就可以建立分类模型来判断个人的年收入等级。 算法分为有监督、无监督的学习算法,而朴素贝叶斯是有监督算法,它是基于贝叶斯定理与特征条件来假设的分类方法[3]。监督学习它的目的是让模型能够从已知的输入和输出之间的关系中学习,并且能够对新的输入做正确的预测。监督学习有很多种算法,每种算法都有自己的优缺点,适用于不同的问题和数据。比如常见的监督学习算法有线性回归、逻辑回归、决策树、支持向量机、神经网络等。不同的算法适用于不同的问题和数据,选择合适的算法需要考虑很多因素,比如数据的特征、规模、分布、噪声等,以及模型的复杂度、可解释性、稳定性等。一般来说,没有一种算法是万能的,需要根据具体的情况进行比较和测试,才能找到最优的解决方案。在上述方案中,为什么选择朴素贝叶斯算法,原因分析如下:使用逻辑回归算法,缺点是不能处理非线性的关系,也不能处理回归问题。使用决策树算法,缺点是容易出现过拟合,也容易受到噪声和异常值的影响。使用支持向量机,可以出来复杂的关系,但是计算效率低,选择参数困难。综上所述,使用朴素贝叶斯算法效率将优于其他算法。 根据前面的分析,我们需要实现4 个功能:(1)爬虫脚本功能;(2)漏洞预警判断功能;(3)机器学习训练功能;(4)结果信息邮件推送功能。结构关系如图2所示。 图2 功能结构 爬虫脚本功能:主要实现采集网站的信息,并把他转换成文本形式保存到文档中。机器学习训练:主要实现选择合适算法,导入合适的样本数据,训练模型。漏洞预警判断:主要实现采集真实的安全网站信息页面,并把漏洞信息分离出来。结果信息邮件推送:主要实现把漏洞信息通过邮件发送到安全管理员的邮箱中。 我们从国内一些漏洞预警平台(比如:阿里云漏洞库、360 、riskivy)收集漏洞预警样本,基于朴素贝叶斯算法训练程序识别漏洞预警信息特征。每十分钟爬取一次监控页面,对比上一次页面信息,提取差异内容,基于机器学习训练结果让程序判断差异内容是否是漏洞预警信息,如果是则通报。 (1)爬虫脚本采集样本 第一步,我们先使用爬虫脚本采集安全网站上的25 份漏洞预警样本,单独把每一个样本放入文件txt中。在训练漏洞预警样本时,去掉一些高频词,比如“的”“一”“在”,具体去掉的高频词和标点符号整理到stopwords_cn.txt。因为去掉样本中的这些非关键词,后续调用程序判断时,可以提高分类准确率。第二步,我们再整理25 份非漏洞预警样本,单独把每一个样本放入文件txt 中。 (2)机器学习训练-基于朴素贝叶斯算法进行样本 通过上述50 份样本进行训练,保存训练结果到vocabList,p0V,p1V,pSpam 参数中。为了检查训练结果的准确度,我们又整理了10 份漏洞预警信息,10份普通文本信息,测试效果如图3 所示。 图3 测试结果 测试结果:错误率为0%,即正确率为100%。其结果符合预期的要求。 (3)漏洞预警判断 大部分站点页面内容都是基于JS 渲染出来的,简单的requests.get 获取不到页面信息,因此使用phantomjs 模拟浏览器解析JS。phantomjs 是一个基于WebKit 的无界面的浏览器,可以用于自动化网页操作和测试。它具有以下功能:网页截图,可以将网页完整地截图保存为图片文件;页面渲染,可以将网页加载并渲染,获取渲染后的页面内容;页面交互,可以模拟用户的点击、输入等操作,与页面进行交互;网络监控,可以捕获网页中的网络请求和响应,用于网络性能分析和调试;自动化测试,可以用于编写和执行自动化测试脚本,对网页进行功能和性能测试;网络爬虫,可以用于抓取网页内容,进行数据采集和分析。网页性能分析:可以分析网页的加载性能,包括资源加载时间、渲染时间等;脚本执行,可以执行JavaScript 脚本,操作网页元素,修改页面内容等。总之,PhantomJS 提供了一种无界面的浏览器环境,可以用于实现各种网页操作和测试的需求。监控目标列表放在项目根目录下的urls.txt 文件里,默认url 列表如下: https://vti.huaun.com/Vulnerability https://poc.shuziguanxing.com/#/issueList https://avd.aliyun.com/high-risk/list https://nox.qianxin.com/vulnerability https://sec.sangfor.com.cn/security-vulnerability http://www.cnnvd.org.cn/web/vulnerability/querylist.tag 在crawlspider 爬虫脚本目录下面有以下几个文件:monitor.py、phantomjs,上述方案中把功能实现的代码写在monitor.py 中,关键代码如下: #先提取html 文本,再进行比较 def compareHtml(self,file1,file2): text1 = '' text2 = '' with open (file1,'r',encoding='utf-8') as f://读取第一个网页的文本 text1str = f.read() text1=self.filter_tags(text1str) with open (file2,'r',encoding='utf-8') as f://读取第一个网页的文本 text2str = f.read() text2=self.filter_tags(text2str) d = difflib.HtmlDiff() //比较两个网页的文本的不同 htmlContent = d.make_file(text1,text2) with open('diff.html','w',encoding='utf-8')as f: f.write(htmlContent) //把两个网页的文本的不同的地方写入文件 soup = BeautifulSoup (htmlContent,'html.parser') diffContentHtml = soup.find_all ("span",class_="diff_add") diffContent = '' for dif in diffContentHtml: diffContent += HTMLParser(dif.text).text() diffContentHtml = soup.find_all ("span",class_="diff_chg") for dif in diffContentHtml: diftext = dif.text if diftext not in text1str: diffContent += HTMLParser(diftext).text()return diffContent 最后把爬取的结果保存在1.html 和2.html 中,把比较不同的信息保存在result.log 的文件中。例如在爬去取阿里云漏洞库网站的结果如图4 所示。 图4 文件 (4)机器学习核心功能实现 我们使用机器学习判断爬取的信息是否是漏洞信息,爬取的核心代码如下: def samTest(self): .. ... for folder in folder_list: new_folder_path = os.path.join('./Sample/vulnsWarn',folder) with open(new_folder_path,'rb') as f: raws = f.readlines() for raw in raws: wordList = self.textParse(raw) docxList.append(wordList) claList.append(1) # 标记漏洞信息,1 表示是漏洞预警信息 folder_list = os.listdir('./Sample/normal') for folder in folder_list:# 遍历文件夹 new_folder_path = os.path.join('./Sample/normal',folder) with open(new_folder_path,'rb') as f: raws = f.readlines ()# 读取文件 for raw in raws: wordList = self.textParse(raw) docxList.append(wordList) claList.append (0) # 标记非漏洞样本,0 表示不是漏洞预警信息 vocabList = self.createVocabList (docxList)# 建立分词列表 trainMat = []# 训练集矩阵 trainClasses = []# 训练集类别向量 for docIndex in range (len (docxList)):# 遍历训练集 trainMat.append(self.setOfWords2Vec(vocabList,docxList[docIndex])) trainClasses.append(claList[docIndex]) p0V,p1V,pSpam = self.trainNB0(np.array(trainMat),np.array(trainClasses)) # 训练模型 return vocabList,p0V, p1V, pSpam# 返回结果 该程序十分钟爬取一次,将爬虫结果保存下来,1.html 是上一次爬虫结果,2.html 为最新爬虫结果。对比前后十分钟结果,提取新增内容的文本信息,根据机器学习效果判断是否是漏洞预警信息,在result.log里可以看到每次对比信息。其实本身一个站点只监控一个页面,访问频率可以适度加大也没有问题。检测效果如图5 所示。 图5 运行效果 为了提高分类的准确率,方案设计时要从以下几方面去入手。扩大数据集,有实验证明,良好的样本的数据能打败更好的算法。如果想要提高机器学习的分类准确率,首先想到的就是扩大数据集。样本数据足够多,只要机器学习花费的时间在可以接受的范围内,数据集就可以继续扩大,它可以使方案设计时获得更优秀的分类准确率。主要在这几方面改进:(1)训练阶段改进;(2)算法改进。 方案通过分析网页漏洞信息的特征,采用了基于贝叶斯算法的网页漏洞信息的检测,给出了利用该模型进行网页漏洞信息预警推送的设计方案。实验测试数据分析,该方案可以检测出网页漏洞信息,为了提高判定数据的准确率,我们可以增加样本数据。综上所述,代购行业正在经历飞速发展,其增长的空间还是很大的,但要想实现长足发展,还需要继续加强行业的技术创新,优化行业服务,完善有关政策,以推动行业的可持续发展。1 朴素贝叶斯算法
2 功能结构设计

3 关键技术具体实现
4 实验测试

5 基于机器学习的网站漏洞预警的建议
6 结语
